NLP--自然语言处理学习-day1
一.初步认识NLP
自然语言处理(Natural Language Processing, NLP)是计算机科学和人工智能(AI)的一个交叉领域,旨在使计算机能够理解、分析、生成和处理人类语言的能力。它结合了计算语言学、人工智能、机器学习和语言学等多个领域的知识。
NLP的主要任务
-
文本分类:
- 将文本内容分配到一个或多个类别中,例如垃圾邮件分类、情感分析等。
-
命名实体识别(NER):
- 从文本中识别出特定类型的实体,如人名、地名、组织名等。
-
机器翻译:
- 将一种语言的文本自动翻译成另一种语言,如谷歌翻译。
-
文本生成:
- 根据输入文本生成新的文本,例如对话生成、摘要生成等。
-
情感分析:
- 判断文本中表达的情绪,如积极、消极或中立。
-
问答系统:
- 根据用户的自然语言提问,自动提供相关的答案,如智能助手(如Siri、Alexa)。
-
语言建模:
- 预测给定文本序列中下一个单词或字符的概率,用于生成连贯的文本。
-
语音识别:
- 将语音信号转换为文本,是NLP和信号处理的结合。
NLP的应用场景
- 聊天机器人和虚拟助手:用于客户服务、信息获取等。
- 搜索引擎:通过NLP改进信息检索。
- 内容推荐:根据用户兴趣推荐相关内容。
- 社交媒体分析:分析用户反馈、趋势和情绪。
- 医学信息处理:从医疗文档中提取有用信息。
NLP的挑战
- 语言的模糊性:同一词在不同上下文中的意义可能不同。
- 多义性:一个单词在不同情况下可能有多种含义。
- 语法和句法复杂性:各种语言的语法规则差异较大。
- 上下文理解:理解文本的上下文对准确处理语言至关重要。
- 数据稀缺性:对于某些少数语言或领域,标注数据可能不足。
二.NLP的特征工程
特征工程是机器学习和自然语言处理(NLP)中的一个重要步骤,主要指的是从原始数据中提取出具有代表性的特征,以便于模型的训练和预测。在NLP中,特征工程的目标是将文本数据转换为机器学习模型可以理解和处理的形式。以下是一些在NLP中特征工程的常见方法和技术:
1. 文本预处理
在进行特征提取之前,通常需要对文本数据进行预处理,以提高模型的效果:
- 去除噪声:去除标点符号、数字和特殊字符。
- 分词:将文本划分为单词或其他有意义的单位(tokenization)。
- 小写化:将文本统一转换为小写,以减少词汇的多样性。
- 去停用词:去掉常见但信息量小的词(如“的”、“是”、“在”等)。
2. 特征提取方法
在预处理完成后,可以使用以下方法将文本转换为特征向量:
-
TF-IDF(Term Frequency-Inverse Document Frequency):
- 计算每个单词相对于文档的权重,将词频和反向文档频率结合,使得常见词的权重减小,稀有词的权重增加。
-
词嵌入(Word Embeddings):
- 采用预训练的词向量(如Word2Vec、GloVe、FastText等)来表示单词,能够捕捉单词之间的语义关系和相似性。
-
段落或文档嵌入:
- 对整段文本或完整文档进行嵌入,例如使用Doc2Vec或BERT等模型,这样可以捕捉上下文信息。
3. 特征选择
特征选择是找到对模型性能最有贡献的特征并去掉无关特征的过程:
- 基于模型的选择:通过训练模型来评估每个特征的重要性,从而进行选择(例如,使用树模型进行特征重要性评分)。
- 统计测试:利用统计方法来评估特征与目标变量之间的关系。
- 降维技术:如主成分分析(PCA)、线性判别分析(LDA)等,减少特征空间的维度。
三.词向量
词向量(Word Embedding)是将文本中的单词映射到连续向量空间中的一种表示方法。通过词向量,单词之间的语义信息和上下文关系能够被自然地捕捉到。词向量不仅有效降低了文本处理中的高维度问题,还可以在多种NLP任务中提高模型的性能。以下是对词向量的详细介绍:
1. 词向量的基本概念
- 稠密表示:与传统的词袋模型或TF-IDF不同,词向量为每个单词提供了一个低维的稠密向量表示,通常是100维到300维,能够更好地捕捉单词的语义特征。
- 语义相似性:词向量的设计使得相似意义的单词在向量空间中更接近。例如,"king"和"queen"的向量距离比"king"和"apple"的距离要近。
2. 词向量的应用
- 文本分类:提高分类器的输入特征质量。
- 情感分析:捕捉单词之间的语义关系,提升模型性能。
- 机器翻译:增强机器翻译模型对单词的理解能力。
- 问答系统:提升用户问题理解的准确性。
3. 词向量的优缺点
优点:
- 捕捉语义:能够捕捉单词之间丰富的语义关系。
- 降低维度:将稀疏的高维文本表示转换为低维稠密向量,有助于模型的训练。
- 泛化能力:相似的词向量能够帮助模型更好地泛化到新数据。
缺点:
- 静态性:传统词向量(如Word2Vec、GloVe)生成的向量是静态的,即一个单词在所有上下文中的表示都是一样的,无法捕捉多义词的不同含义。
- 缺乏上下文信息:无法处理上下文变化带来的不同含义。
词向量是NLP中的重要工具,通过将单词映射到向量空间中,极大地改善了文本数据的处理和分析能力。从Word2Vec到BERT的发展,展示了词向量表示技术的不断进步和创新,为各种NLP任务提供了强大的支持。随着技术的不断发展,未来的词向量生成方法会更加关注上下文和动态表示的能力。
四.独热编码 one - hot
独热编码(One-Hot Encoding)是一种常见的分类数据编码技术,其目的是将分类特征转换为可用于机器学习模型的数值格式。它将每个类别转换为一个二进制向量,其中只有一个元素为1(表示该类别),其余元素均为0(表示其他类别)。这种编码方式使得算法能够理解和处理分类特征。
1. 独热编码的原理
独热编码的核心思想是为每一个类别创建一个新的特征(列),并在这些特征中使用二进制值来表示该类别的存在与否。给定一个有N个不同类别的特征,独热编码将其转换为一个N维的二进制向量。
例如,如果有一个颜色特征,有三个可能的值:红、蓝、绿。经过独热编码后:
- 红:[1, 0, 0]
- 蓝:[0, 1, 0]
- 绿:[0, 0, 1]
2. 独热编码的步骤
- 确定类别:确定要编码的分类特征的所有唯一值。
- 创建新特征:为每一个类别创建一个新的特征(列)。
- 编码:将每个样本的分类特征转换为独热编码的向量。
3. 优势
- 消除了大小关系:通过将分类变量转换为二进制格式,消除了数据中可能存在的大小关系,使得算法在处理时不会将分类变量的意义误解为数字大小。
- 简单易懂:适用于大多数机器学习算法,易于实现和理解。
4. 劣势
- 维度灾难:如果类别数量极大,会导致特征空间的维度剧增,从而增加计算成本和复杂性,这在深度学习中可能会使模型变得困难以训练并容易过拟合。
- 稀疏表示:独热编码生成的向量大多数元素为0,形成稀疏矩阵,可能导致效率低下。
5. 使用场景
独热编码适用于各种需要对分类特征进行处理的机器学习应用,例如:
- 分类问题(如文本分类、图像分类等)
- 回归问题(当自变量为类别时)
- 无序类别数据(不具有大小关系的类别)
6. Python 中的实现
在Python中,可以使用库如pandas和sklearn轻松进行独热编码。
使用 pandas:
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'颜色': ['红', '蓝', '绿', '蓝', '红']})# 使用 pd.get_dummies 进行独热编码
one_hot_encoded = pd.get_dummies(df, columns=['颜色'])
print(one_hot_encoded)
使用 sklearn:
from sklearn.preprocessing import OneHotEncoder# 创建一个示例数据
data = [['红'], ['蓝'], ['绿'], ['蓝'], ['红']]
encoder = OneHotEncoder(sparse=False)# 进行独热编码
one_hot_encoded = encoder.fit_transform(data)
print(one_hot_encoded)
总结
独热编码是一种有效的数据预处理方法,可以将分类数据转换为模型可用的数值格式。虽然它有一些缺点,如可能导致的维度灾难,但在许多机器学习任务中,它仍然是非常流行和实用的选择。
五.词频-逆文档频率(TF-IDF
词频-逆文档频率(TF-IDF,Term Frequency-Inverse Document Frequency)是一种常用的信息检索和文本挖掘技术,用于评估单词在文档集合中的重要性。TF-IDF结合了两个重要的概念:词频(TF)和逆文档频率(IDF),通过这两者的结合,能够在一定程度上反映出一个单词在特定文档中的重要性。
1. 词频(TF)
词频是指某个单词在文档中出现的频率。TF的计算公式为:
T F ( t , d ) = 词t在文档d中的出现次数 文档d中的总词数 TF(t, d) = \frac{\text{词t在文档d中的出现次数}}{\text{文档d中的总词数}} TF(t,d)=文档d中的总词数词t在文档d中的出现次数
其中,
- ( t ) 是单词,( d ) 是文档。
TF值越高,表示这个单词在该文档中的重要性越高。
2. 逆文档频率(IDF)
逆文档频率是用于衡量某个单词在整个文档集合中的普遍性。IDF的计算公式为:
I D F ( t ) = log ( N 包含词t的文档数量 + 1 ) IDF(t) = \log\left(\frac{N}{\text{包含词t的文档数量} + 1}\right) IDF(t)=log(包含词t的文档数量+1N)
其中,
- ( N ) 是文档总数。
- 包含词 ( t ) 的文档数量是指包含该单词的文档数量。
IDF值越高,表示单词在文档集合中的稀有性越大。
3. TF-IDF 计算
TF-IDF的计算公式为:
T F − I D F ( t , d ) = T F ( t , d ) × I D F ( t ) TF-IDF(t, d) = TF(t, d) \times IDF(t) TF−IDF(t,d)=TF(t,d)×IDF(t)
通过将词频和逆文档频率相乘,TF-IDF能够同时考虑单词在单个文档中的重要性和在整个文档集合中的稀有性。
4. 特点与优点
- 强调特定性:TF-IDF能够有效地识别特定且稀有的词语,从而提升信息检索的准确性。
- 抑制常用词:常用词(如“是”、“的”等)通常在所有文档中出现频率较高,因此其IDF值较低,从而在TF-IDF的计算中被降低权重,对信息检索无太大帮助。
- 应用广泛:TF-IDF广泛应用于文本分类、文本聚类、信息检索等领域。
5. 使用场景
- 文档检索:可以帮助提高搜索引擎对用户查询的相关性。
- 关键词提取:提供对文档中重要词汇的分析。
- 文本相似度计算:用于衡量不同文档之间的相似度。
6. Python 实现
在Python中,可以使用scikit-learn库来计算TF-IDF,下面是一个简单的示例:
from sklearn.feature_extraction.text import TfidfVectorizer# 示例文档
documents = ["这是一篇关于机器学习的文章。","机器学习是一门热门的学科。","这篇文章介绍了机器学习的基本概念。"
]# 创建TF-IDF向量器
vectorizer = TfidfVectorizer()# 拟合文档并转换为TF-IDF矩阵
tfidf_matrix = vectorizer.fit_transform(documents)# 获取词汇
feature_names = vectorizer.get_feature_names_out()# 转换为数组并打印
tfidf_array = tfidf_matrix.toarray()for i, doc in enumerate(tfidf_array):print(f"文档 {i + 1} 的 TF-IDF: {dict(zip(feature_names, doc))}")
总结
TF-IDF是处理文本数据的有效工具,通过考虑单词在文档中的频率和在整个文档集合中的稀有性,它可以帮助识别文本中最为重要的单词。TF-IDF在信息检索、文本分析和自然语言处理等领域得到了广泛的应用。
六.n-grams
n-grams 是自然语言处理(NLP)中的一种技术,用于从文本中提取和分析相邻的 n 个词(或字符)组合,以捕捉文本的上下文和序列信息。n-grams 可以用来表示文本中词汇的排列模式,通常用于语言建模、信息检索、文本分类、情感分析等任务。
1. n-grams 的定义
-
n-grams 是指将连续的 n 个项提取出来的序列,n 可以是任意正整数。n-grams 可以基于词(word)或字符(character)进行提取。
-
例如,对于文本 “I love natural language processing”:
- 1-grams(unigrams):
["I", "love", "natural", "language", "processing"] - 2-grams(bigrams):
["I love", "love natural", "natural language", "language processing"] - 3-grams(trigrams):
["I love natural", "love natural language", "natural language processing"]
- 1-grams(unigrams):
2. n-grams 的类型
-
Unigrams(1-grams):单个词。例如:{“I”, “love”, “natural”, “language”, “processing”}
-
Bigrams(2-grams):连续的两个词组合。例如:{“I love”, “love natural”, “natural language”, “language processing”}
-
Trigrams(3-grams):连续的三个词组合。例如:{“I love natural”, “love natural language”, “natural language processing”}
-
Higher-order n-grams:这可以继续扩展到更高的 n 值,如 4-grams、5-grams 等。
3. n-grams 的应用
n-grams 被广泛应用于自然语言处理的多个领域,例如:
- 语言模型:用于预测下一个词,或者生成相似的句子结构。
- 文本分类:用来提取特征,从而进行情感分析、主题识别等。
- 信息检索:提升搜索引擎的准确性,通过匹配 n-grams 来找出相关文档。
- 拼写纠正:利用 n-grams 的上下文信息帮助识别和更正拼写错误。
- 机器翻译:在翻译过程中,通过 n-grams 识别和生成标准的短语。
4. 优势与劣势
优势:
- 上下文信息:通过提取相邻的词或字符,n-grams 能够捕捉到文本的上下文和结构信息。
- 简单易用:n-grams 是容易理解和实现的特征提取方法。
劣势:
- 稀疏性:许多 n-grams 的组合可能在语料中出现次数较少,导致数据稀疏问题。
- 计算复杂度:随着 n 值的增加,n-grams 的数量会指数级增长,导致计算和存储成本增加。
- 上下文丢失:较大的 n 值虽然提供了更多上下文信息,但可能会忽略全局上下文。
5. Python 中的实现
在 Python 中,可以 sklearn 等库来实现 n-grams 的提取。以下是一个示例:
使用 Scikit-learn
from sklearn.feature_extraction.text import CountVectorizer# 示例文本
documents = ["I love natural language processing.","Natural language processing is fascinating."
]# 创建 CountVectorizer,用于提取 bigrams
vectorizer = CountVectorizer(ngram_range=(2, 2))
X = vectorizer.fit_transform(documents)# 得到特征名称
bigrams = vectorizer.get_feature_names_out()
print("Bigrams:", bigrams)
Bigrams: ['is fascinating' 'language processing' 'love natural' 'natural language''processing is']
n-grams 是 NLP 中一种重要的特征提取技术,通过提取连续的 n 个词或字符组合,能成功捕捉上下文信息。这种方法在多个语言处理任务中都有广泛的应用。尽管 n-grams 也存在一些局限性,但在许多场景下,它们仍然是分析和理解文本的重要工具。
七.稠密编码
稠密编码(Dense Encoding),通常在自然语言处理(NLP)与机器学习中被称为特征嵌入(Feature Embedding),是一种将高维稀疏特征转换为低维稠密向量的技术。这种表示方式可以更有效地捕捉数据中的重要结构和语义信息,特别是在文本和图像处理中非常常见。
1. 什么是特征嵌入
特征嵌入是将离散的(通常是高维的)特征映射到一个连续的、低维的向量空间。通过这种方式,我们能够将复杂的对象(例如单词、句子、图像等)表示为实数向量,便于进行计算和处理。
例如,在文本处理中,单词通过嵌入技术可以被表示为一个固定维度的向量,这个向量捕捉到了单词的语义信息和上下文关系。
2. 特征嵌入的优势
- 低维表示:与稀疏编码相比,特征嵌入将高维空间映射到低维空间,从而减少计算复杂度和内存消耗。
- 语义相似性:相似的对象会被映射到相近的向量,从而能够捕捉到更深层次的语义关系。
- 增强模型性能:在许多任务中,嵌入表示可以显著改善模型的性能,特别是在处理自然语言和图像数据时。
3. 使用示例
以下是如何使用 gensim 库中的 Word2Vec 实现特征嵌入的简单示例:
import gensim
from gensim.models import Word2Vec# 示例语料库
sentences = [["I", "love", "natural", "language", "processing"],["Natural", "language", "processing", "is", "fun"],["I", "enjoy", "learning", "new", "things"]]# 训练 Word2Vec 模型
model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, sg=1)# 获取单词的嵌入向量
vector = model.wv['natural']
print("自然的嵌入向量:", vector)# 查找相似词
similar_words = model.wv.most_similar('natural', topn=5)
print("类似于“自然”的词:", similar_words)
相关文章:

NLP--自然语言处理学习-day1
一.初步认识NLP 自然语言处理(Natural Language Processing, NLP)是计算机科学和人工智能(AI)的一个交叉领域,旨在使计算机能够理解、分析、生成和处理人类语言的能力。它结合了计算语言学、人工智能、机器学习和语言…...

ER论文阅读-Incomplete Multimodality-Diffused Emotion Recognition
基本介绍:NeurIPS, 2024, CCF-A 原文链接:https://proceedings.neurips.cc/paper_files/paper/2023/file/372cb7805eaccb2b7eed641271a30eec-Paper-Conference.pdf Abstract 人类多模态情感识别(MER)旨在通过多种异质模态&#x…...

Matlab自学笔记36:日期时间型的概念、分类和创建方法
1.概念 日期时间型(Dates and Time)数据具有灵活的显示格式和高达毫微秒的精度,并且可以处理时区、夏令时和平闰年等特殊因素 2.日期时间型数据有以下三种表示方式 (1)Datetime型,表示日期时间点&#x…...

Spring Boot自定义配置项
Spring Boot自定义配置项 配置文件 在application.properties文件添加需要的配置 比如: file.pathD:\\flies\\springboot\\ConfigurationProperties 注解 使用注解ConfigurationProperties将配置项和实体Bean关联起来,实现配置项和实体类字段的关联&…...

【C++篇】C++类与对象深度解析(六):全面剖析拷贝省略、RVO、NRVO优化策略
文章目录 C类与对象前言读者须知RVO 与 NRVO 的启用条件如何确认优化是否启用? 1. 按值传递与拷贝省略1.1 按值传递的概念1.2 示例代码1.3 按值传递的性能影响1.3.1 完全不优化 1.4 不同编译器下的优化表现1.4.1 Visual Studio 2019普通优化1.4.2 Visual Studio 202…...

什么时候用synchronized,什么时候用Reentrantlock
文章目录 使用 synchronized 的场景使用 ReentrantLock 的场景综合考虑 使用 synchronized 的场景 synchronized 是 Java 内置的同步机制,使用起来比较简单且常用于如下场景: 1、简单的同步逻辑:当你的同步逻辑非常简单,比如只需…...

[ffmpeg]音频格式转换
本文主要梳理 ffmpeg 中的音频格式转换。由于采集的音频数据和编码器支持的音频格式可能不一样,所以经常需要进行格式转换。 API 调用 常用 API struct SwrContext *swr_alloc(void); int swr_init(struct SwrContext *s); struct SwrContext *swr_alloc_set_opt…...

SSRF工具类-SsrfTool
为了帮助开发人员和安全研究人员检测和修复SSRF(Server-Side Request Forgery)漏洞,存在 多种工具。这里我将给出一个简单的工具类示例,这个工具类可以用来检查一个给定的URL是否可 能引发SSRF攻击。请注意,这个工具类主要用于教育目的,并不意味着它可以完全防止所有的…...

python集合运算介绍及示例代码
Python 中的集合(set)是一种数据类型,用于存储唯一元素的无序集合。集合支持多种运算,如并集、交集、差集和对称差集,方便执行数学上的集合操作。 1. 创建集合 可以使用大括号 {} 或者 set() 函数创建集合࿱…...
『功能项目』按钮的打开关闭功能【73】
本章项目成果展示 我们打开上一篇72QFrameWork制作背包界面UGUI的项目, 本章要做的事情是制作打开背包与修改器的打开关闭按钮 首先打开UGUICanvas复制button按钮 重命名为ReviseBtn 修改脚本:UIManager.cs 将修改器UI在UGUICanvas预制体中设置为隐藏 运…...

Linux 常用命令 - more 【分页显示文件内容】
简介 more 命令源自英文单词 more, 表示 “更多”,它是一个基于文本的程序,用于查看文本文件的内容。该命令会逐页显示文件内容,允许用户按页浏览大型文本文件。当用户完成当前页的阅读后,可以通过按键(空格键或回车键…...

Kotlin Android 环境搭建
Kotlin Android 环境搭建 1. 引言 Kotlin 已成为 Android 开发的官方语言之一,因其简洁、表达性强和易于维护的特点而受到广大开发者的喜爱。在本教程中,我们将详细介绍如何在您的计算机上搭建 Kotlin Android 开发环境。 2. 系统要求 在开始搭建 Kotlin Android 开发环境…...

常见协议及其默认使用的端口号
在网络通信中,端口号用于标识特定的应用程序或服务。IANA(Internet Assigned Numbers Authority)负责分配和管理这些端口号。端口号分为三个范围: 熟知端口(Well-Known Ports):0到1023…...
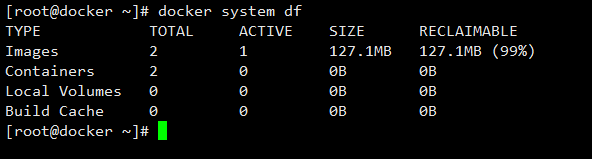
04-Docker常用命令
04-Docker常用命令 启动类命令 启动docker systemctl start docker停止docker systemctl stop docker重启docker systemctl restart docker查看docker状态 systemctl status docker开机启动docker systemctl enable docker帮助类命令 查看docker版本 docker version查…...

数字化转型中的供应链管理优化
在当今全球化和数字化的浪潮下,企业供应链管理面临着前所未有的挑战和机遇,企业在数字化转型过程中,如何优化供应链管理成为提升竞争力的关键。通过应用先进技术如RPA机器人流程自动化、大数据分析、物联网等,企业可以显著提高物流…...

【Python报错已解决】SyntaxError: invalid syntax
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 专栏介绍 在软件开发和日常使用中,BUG是不可避免的。本专栏致力于为广大开发者和技术爱好者提供一个关于BUG解决的经…...

树上差分+lca 黑暗的锁链
//** 太久不写了,感觉很难受。。。比赛最近打得也不好,课内任务又重,还要忙着做项目。何去何从。 今天又写了一题,用了树上差分的知识。下面来整理整理。 1.首先让我们学一下lca(最小公共父节点) 我用的…...

opencv4.5.5 GPU版本编译
一、安装环境 1、opencv4.5.5 下载地址:https://github.com/opencv/opencv/archive/refs/tags/4.5.5.ziphttps://gitee.com/mirrors/opencv/tree/4.5.0 2、opencv-contrib4.5.5 下载地址:https://github.com/opencv/opencv_contrib/archive/refs/tags/4…...
线性跟踪微分器TD详细测试(Simulink 算法框图+SCL完整源代码)
1、ADRC线性跟踪微分器 ADRC线性跟踪微分器(ST+SCL语言)_adrc算法在博途编程中scl语言-CSDN博客文章浏览阅读784次。本文介绍了ADRC线性跟踪微分器的算法和源代码,包括在SMART PLC和H5U平台上的实现。文章提供了ST和SCL语言的详细代码,并讨论了跟踪微分器在自动控制中的作用…...
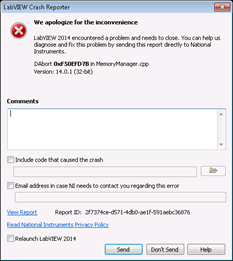
LabVIEW闪退
LabVIEW闪退或无法启动可能由多个原因引起,特别是在使用了一段时间后突然发生的问题。重启电脑后 LabVIEW 和所有 NI 软件都无法打开,甚至在卸载和重装时也没有反应。这种情况通常与系统环境、软件冲突或 NI 软件组件的损坏有关。 1. 检查系统和软件冲突…...

如何在5分钟内制作专业滚动歌词?LRC Maker免费在线工具终极指南
如何在5分钟内制作专业滚动歌词?LRC Maker免费在线工具终极指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾为制作歌词时间轴而烦恼&#x…...

使用Taotoken聚合端点一个月,我的API调用延迟与稳定性观察记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken聚合端点一个月,我的API调用延迟与稳定性观察记录 1. 项目背景与接入动机 我最近的一个个人项目需要持续…...

从 0 到 1:构建一个供 AI Agent 使用的图像生成技能系统
前言 当我们把 AI Agent 接进工作流后,几乎每天都会遇到一个痛点:图像生成这件事,每次都要靠 Agent 自己拼提示词。没有风格库、没有模板、没有搜索——结果全靠"手感",输出质量参差不齐。 image-craft 这个项目&…...

OPNsense安装选UFS还是ZFS?从硬件选择到文件系统性能的完整决策指南
OPNsense安装选UFS还是ZFS?从硬件选择到文件系统性能的完整决策指南 在部署OPNsense防火墙时,文件系统选择往往被忽视,却直接影响系统性能、数据安全和运维效率。UFS和ZFS的抉择不仅关乎安装时的选项勾选,更关系到长期运行的稳定性…...

不止于安装:用Docker在5分钟内快速搭建可复用的ROS Noetic开发环境
5分钟构建可移植ROS开发环境:Docker容器化实战指南 在机器人开发领域,环境配置一直是令人头疼的问题。不同项目依赖的ROS版本冲突、系统库不兼容、团队协作时环境不一致…这些痛点消耗着开发者宝贵的时间。传统安装方式就像在主机上直接"装修"…...

缠论分析工具终极指南:如何在通达信中实现可视化技术分析
缠论分析工具终极指南:如何在通达信中实现可视化技术分析 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 还在为复杂的缠论分析而头疼吗?想要在通达信软件中轻松识别分型、笔、线…...

DPM-Solver代码架构解析:从模型包装器到求解器核心
DPM-Solver代码架构解析:从模型包装器到求解器核心 【免费下载链接】dpm-solver Official code for "DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps" (Neurips 2022 Oral) 项目地址: https://gitcode.…...

Configor 自动重载功能深度解析:实现配置热更新的终极指南
Configor 自动重载功能深度解析:实现配置热更新的终极指南 【免费下载链接】configor Golang Configuration tool that support YAML, JSON, TOML, Shell Environment 项目地址: https://gitcode.com/gh_mirrors/co/configor Configor 是 Golang 生态系统中一…...
添加远程桌面控制功能)
libvncserver实战:给你的嵌入式Linux设备(如树莓派)添加远程桌面控制功能
libvncserver嵌入式实战:为树莓派等设备构建轻量级远程桌面方案 在工业控制、智能家居和边缘计算场景中,嵌入式设备的远程可视化操作需求日益增长。传统方案如SSH仅能提供命令行交互,而完整的桌面环境又过于臃肿。本文将展示如何利用libvncse…...

STM32 SPI驱动W25Q128避坑指南:CubeMX配置、时序模式与读写超时那些事儿
STM32 SPI驱动W25Q128实战避坑指南:从时序陷阱到性能调优 1. 当SPI遇上Flash:硬件工程师的暗礁地带 在嵌入式存储解决方案中,W25Q128系列SPI Flash凭借其紧凑封装和简单接口,已成为众多STM32项目的标配外设。但看似简单的四线接口…...