Pyspark dataframe基本内置方法(4)
文章目录
- Pyspark sql DataFrame
- 相关文章
- RDD
- repartition 重新分区
- replace 替换
- sameSemantics dataframe是否相等
- sample 采样
- sampleBy 分层采样
- schema 显示dataframe结构
- select 查询
- selectExpr 查询
- semanticHash 获取哈希值
- show 展示dataframe
- sort 排序
- sortWithinPartitions 分区按照指定列排序
- stat 返回统计函数类型
- storageLevel 获取存储级别
- subtract 获取差集
- summary 总览
- tail 从结尾获取数据
- take 返回记录
- to 配合schema返回新结构的dataframe
Pyspark sql DataFrame
相关文章
Pyspark下操作dataframe方法(1)
Pyspark下操作dataframe方法(2)
Pyspark下操作dataframe方法(3)
Pyspark下操作dataframe方法(4)
Pyspark下操作dataframe方法(5)
RDD
返回包含ROW对象的rdd
data.show()
+-----+---+---+------+
| name|age| id|gender|
+-----+---+---+------+
| ldsx| 12| 1| 男|
|test1| 20| 1| 女|
|test2| 26| 1| 男|
|test3| 19| 1| 女|
|test4| 51| 1| 女|
|test5| 13| 1| 男|
+-----+---+---+------+
data.rdd
MapPartitionsRDD[12] at javaToPython at NativeMethodAccessorImpl.java:0data.rdd.foreach(lambda x : print(type(x),x))
<class 'pyspark.sql.types.Row'> Row(name='test3', age='19', id='1', gender='女')
<class 'pyspark.sql.types.Row'> Row(name='test4', age='51', id='1', gender='女')
<class 'pyspark.sql.types.Row'> Row(name='test5', age='13', id='1', gender='男')
<class 'pyspark.sql.types.Row'> Row(name='ldsx', age='12', id='1', gender='男')
<class 'pyspark.sql.types.Row'> Row(name='test1', age='20', id='1', gender='女')
<class 'pyspark.sql.types.Row'> Row(name='test2', age='26', id='1', gender='男')
repartition 重新分区
每一个 RDD 包含的数据被存储在系统的不同节点上。逻辑上我们可以将 RDD 理解成一个大的数组,数组中的每个元素就代表一个分区 (Partition) 。
在物理存储中,每个分区指向一个存储在内存或者硬盘中的数据块 (Block) ,其实这个数据块就是每个 task 计算出的数据块,它们可以分布在不同的节点上。
RDD 只是抽象意义的数据集合,分区内部并不会存储具体的数据,只会存储它在该 RDD 中的 index,通过该 RDD 的 ID 和分区的 index 可以唯一确定对应数据块的编号,然后通过底层存储层的接口提取到数据进行处理。
data.show()
+-----+---+---+------+
| name|age| id|gender|
+-----+---+---+------+
| ldsx| 12| 1| 男|
|test1| 20| 1| 女|
|test2| 26| 1| 男|
|test3| 19| 1| 女|
|test4| 51| 1| 女|
|test5| 13| 1| 男|
+-----+---+---+------+
# 选择以某列进行分区
data.repartition('name').rdd.getNumPartitions()
1
# 指定分区数量进行分区(可以指定多列)
data.repartition(7,'name','age').rdd.getNumPartitions()
7data = data.repartition(5,'gender')
data.rdd.glom().collect()[[], [Row(name='ldsx', age='12', id='1', gender='男'), Row(name='test1', age='20', id='1', gender='女'),Row(name='test2', age='26', id='1', gender='男'), Row(name='test3', age='19', id='1', gender='女'),Row(name='test4', age='51', id='1', gender='女'), Row(name='test5', age='13', id='1', gender='男')], [], [], []]# 直接操作rdd只能按数据分区不能按照列分区
data.rdd.repartition(1).glom().collect()
[[Row(name='ldsx', age='12', id='1', gender='男'), Row(name='test2', age='26', id='1', gender='男'), Row(name='test5', age='13', id='1', gender='男'), Row(name='test1', age='20', id='1', gender='女'), Row(name='test3', age='19', id='1', gender='女'), Row(name='test4', age='51', id='1', gender='女')]]data.repartition(2,'id').rdd.glom().collect()
[[Row(name='ldsx', age='12', id='1', gender='男'), Row(name='test1', age='20', id='1', gender='女'), Row(name='test2', age='26', id='1', gender='男'), Row(name='test3', age='19', id='1', gender='女'), Row(name='test4', age='51', id='1', gender='女'), Row(name='test5', age='13', id='1', gender='男')], []]data.repartition(2).rdd.glom().collect()
[[Row(name='test2', age='26', id='1', gender='男'), Row(name='test3', age='19', id='1', gender='女')], [Row(name='test1', age='20', id='1', gender='女'), Row(name='ldsx', age='12', id='1', gender='男'), Row(name='test4', age='51', id='1', gender='女'), Row(name='test5', age='13', id='1', gender='男')]]replace 替换
当替换的值与原本列的数据类型不相同时会报错
df.show()
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
| 5| null| Bob|
|null| 10| Tom|
|null| null| null|
+----+------+-----+
df.fillna({'age':1,'height':'2','name':"sr"}).show()
+---+------+-----+
|age|height| name|
+---+------+-----+
| 10| 80|Alice|
| 5| 2| Bob|
| 1| 10| Tom|
| 1| 2| sr|
+---+------+-----+df.na.replace(['Alice', 'Bob'], ['A', 'B'], 'name').show()
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80| A|
| 5| null| B|
|null| 10| Tom|
|null| null|null|
+----+------+----+df.show()
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
| 5| null| Bob|
|null| 10| Tom|
|null| null| null|
+----+------+-----+df.na.replace(10,12).show()
+----+------+-----+
| age|height| name|
+----+------+-----+
| 12| 80|Alice|
| 5| null| Bob|
|null| 12| Tom|
|null| null| null|
+----+------+-----+sameSemantics dataframe是否相等
当两个 dataframe中的逻辑查询计划相等并因此返回相同的结果时,返回 True。
data.show()
+-----+---+---+------+------+
| name|age| id|gender|new_id|
+-----+---+---+------+------+
| ldsx| 12| 1| 男| 1|
|test1| 20| 1| 女| 1|
|test2| 26| 1| 男| 1|
|test3| 19| 1| 女| 1|
|test4| 51| 1| 女| 1|
|test5| 13| 1| 男| 1|
+-----+---+---+------+------+
data2.show()
+-----+---+---+------+------+
| name|age| id|gender|new_id|
+-----+---+---+------+------+
| ldsx| 12| 1| 男| 2.0|
|test1| 20| 1| 女| 2.0|
|test2| 26| 1| 男| 2.0|
|test3| 19| 1| 女| 2.0|
|test4| 51| 1| 女| 2.0|
|test5| 13| 1| 男| 2.0|
+-----+---+---+------+------+data.sameSemantics(data2)
False
data.sameSemantics(data)
Truesample 采样
withReplacement:是否进行有放回采样,默认为False,表示进行无放回采样;设置为True时,表示进行有放回采样
fraction: 采样比例 float
seed: 随机种子值,值固定后采样获取固定默认为空
# 取样不固定
df.sample(0.1).show()
+---+
| id|
+---+
+---+
df.sample(0.1).show()
+---+
| id|
+---+
| 9|
+---+
df.sample(0.1).show()
+---+
| id|
+---+
| 1|
| 5|
+---+# 随机种子固定,取样固定
df.sample(0.1,1).show()
+---+
| id|
+---+
| 3|
+---+
df.sample(0.1,1).show()
+---+
| id|
+---+
| 3|
+---+sampleBy 分层采样
col:列名
fractions: 采样字典
seed: 随机种子值,值固定后采样获取固定默认为空
ataset = spark.range(0, 100).select((col("id") % 3).alias("key"))
dataset.show()+---+
|key|
+---+
| 0|
| 1|
| 2|
| 0|
| 1|
| 2|
...
...
| 0|
| 1|
| 2|
| 0|
| 1|
+---+# 列为key,中值为0取样10%,值为1取样10%,值为2取样10%
dataset.sampleBy("key", fractions={0: 0.1, 1: 0.1,2:0.1}, seed=0).show()
+---+
|key|
+---+
| 2|
| 0|
| 1|
| 2|
| 1|
| 2|
| 2|
| 1|
| 2|
+---+
# 列为key,中值为0取样10%,值为2取样10%
dataset.sampleBy("key", fractions={0: 0.1,2:0.1}, seed=0).show()
+---+
|key|
+---+
| 2|
| 0|
| 2|
| 2|
| 2|
| 2|
+---+schema 显示dataframe结构
将此DataFrame的架构作为pyspark.sql.types返回
df.schema
StructType([StructField('id', LongType(), False)])df.printSchema()
root|-- id: long (nullable = false)
select 查询
查询并返回新dataframe,可结合多方法使用是。
df = spark.createDataFrame([(2, "Alice"), (5, "Bob")], schema=["age", "name"])df.select('*').show()
+---+-----+
|age| name|
+---+-----+
| 2|Alice|
| 5| Bob|
+---+-----+df.select(df.name, (df.age + 10).alias('age')).show()
+-----+---+
| name|age|
+-----+---+
|Alice| 12|
| Bob| 15|
+-----+---+
selectExpr 查询
接受sql表达式并执行
df = spark.createDataFrame([(2, "Alice"), (5, "Bob")], schema=["age", "name"])
df.show()
+---+-----+
|age| name|
+---+-----+
| 2|Alice|
| 5| Bob|
+---+-----+
df.selectExpr('age * 2','age+2').show()
+---------+---------+
|(age * 2)|(age + 2)|
+---------+---------+
| 4| 4|
| 10| 7|
+---------+---------+df.selectExpr('age * 2 as ldsx','age+2').show()
+----+---------+
|ldsx|(age + 2)|
+----+---------+
| 4| 4|
| 10| 7|
+----+---------+
semanticHash 获取哈希值
df.selectExpr('age * 2 as ldsx','age+2').semanticHash()
-2082183221
df.semanticHash()
1019336781
show 展示dataframe
展示前n行数据到控制台,默认展示20行
df.show(1)
+---+-----+
|age| name|
+---+-----+
| 2|Alice|
+---+-----+
only showing top 1 row
sort 排序
按照指定列排序
from pyspark.sql.functions import desc, asc
# 下面方式效果一致
df.sort(desc('age')).show()
df.sort("age", ascending=False).show()
df.orderBy(df.age.desc()).show()
+---+-----+
|age| name|
+---+-----+
| 5| Bob|
| 2|Alice|
| 2| Bob|
+---+-----+# 使用两列排序,一列降序,一列默认(升序)
df.orderBy(desc("age"), "name").show()
+---+-----+
|age| name|
+---+-----+
| 5| Bob|
| 2|Alice|
| 2| Bob|
+---+-----+
# 使用两列排序,都为降序
df.orderBy(desc("age"), desc("name")).show()
+---+-----+
|age| name|
+---+-----+
| 5| Bob|
| 2| Bob|
| 2|Alice|
+---+-----+# 两列都为降序
df.orderBy(["age", "name"], ascending=[False, False]).show()
+---+-----+
|age| name|
+---+-----+
| 5| Bob|
| 2| Bob|
| 2|Alice|
+---+-----+
sortWithinPartitions 分区按照指定列排序
df.sortWithinPartitions('age').show()
+---+-----+
|age| name|
+---+-----+
| 2|Alice|
| 2| Bob|
| 5| Bob|
+---+-----+
stat 返回统计函数类型
df.stat
<pyspark.sql.dataframe.DataFrameStatFunctions object at 0x7f55c87669e8>
storageLevel 获取存储级别
df.storageLevel
StorageLevel(False, False, False, False, 1)
df.cache().storageLevel
StorageLevel(True, True, False, True, 1)
subtract 获取差集
返回一个新的DataFrame,其中包含此DataFrame中的行,但不包含另一个DataFrame中。d1.subtarct(d2),获取d1的差集。
df1 = spark.createDataFrame([("a", 1), ("a", 1), ("b", 3), ("c", 4)], ["C1", "C2"])
df2 = spark.createDataFrame([("a", 1), ("a", 1), ("b", 3)], ["C1", "C2"])
df1.show()
+---+---+
| C1| C2|
+---+---+
| a| 1|
| a| 1|
| b| 3|
| c| 4|
+---+---+
df2.show()
+---+---+
| C1| C2|
+---+---+
| a| 1|
| a| 1|
| b| 3|
+---+---+
df1.subtract(df2).show()
+---+---+
| C1| C2|
+---+---+
| c| 4|
+---+---+summary 总览
计算数值列和字符串列的指定统计信息。可用的统计数据有:-count-mean-stddev-min-max-指定为百分比的任意近似百分位数
如果没有给出统计数据,此函数将计算计数、平均值、标准偏差、最小值、近似四分位数(百分位数分别为25%、50%和75%)和最大值。
df.show()
+-----+---+------+------+
| name|age|weight|height|
+-----+---+------+------+
| Bob| 13| 40.3| 150.5|
|Alice| 12| 37.8| 142.3|
| Tom| 11| 44.1| 142.2|
+-----+---+------+------+df.summary().show()
24/09/19 11:24:13 WARN package: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields'.+-------+-----+----+------------------+-----------------+
|summary| name| age| weight| height|
+-------+-----+----+------------------+-----------------+
| count| 3| 3| 3| 3|
| mean| null|12.0|40.733333333333334| 145.0|
| stddev| null| 1.0| 3.172275734127371|4.763402145525822|
| min|Alice| 11| 37.8| 142.2|
| 25%| null| 11| 37.8| 142.2|
| 50%| null| 12| 40.3| 142.3|
| 75%| null| 13| 44.1| 150.5|
| max| Tom| 13| 44.1| 150.5|
+-------+-----+----+------------------+-----------------+
tail 从结尾获取数据
运行尾部需要将数据移动到应用程序的驱动程序进程中,如果使用非常大的num,可能会导致驱动程序进程因OutOfMemoryError而崩溃。
df.show()
+-----+---+------+------+
| name|age|weight|height|
+-----+---+------+------+
| Bob| 13| 40.3| 150.5|
|Alice| 12| 37.8| 142.3|
| Tom| 11| 44.1| 142.2|
+-----+---+------+------+
df.tail(2)
[Row(name='Alice', age=12, weight=37.8, height=142.3), Row(name='Tom', age=11, weight=44.1, height=142.2)]
take 返回记录
head 调用的就是take,take调用的limit
# 源码def take(self, num: int) -> List[Row]:"""Returns the first ``num`` rows as a :class:`list` of :class:`Row`... versionadded:: 1.3.0.. versionchanged:: 3.4.0Supports Spark Connect.Parameters----------num : intNumber of records to return. Will return this number of recordsor all records if the DataFrame contains less than this number of records..Returns-------listList of rowsExamples-------->>> df = spark.createDataFrame(... [(14, "Tom"), (23, "Alice"), (16, "Bob")], ["age", "name"])Return the first 2 rows of the :class:`DataFrame`.>>> df.take(2)[Row(age=14, name='Tom'), Row(age=23, name='Alice')]"""return self.limit(num).collect()
to 配合schema返回新结构的dataframe
from pyspark.sql.types import StructField, StringType
df = spark.createDataFrame([("a", 1)], ["i", "j"])
df.show()
+---+---+
| i| j|
+---+---+
| a| 1|
+---+---+
df.schema
StructType([StructField('i', StringType(), True), StructField('j', LongType(), True)])# 设置新的scheam
schema = StructType([StructField("j", StringType()), StructField("i", StringType())])
df.schema
StructType([StructField('i', StringType(), True), StructField('j', LongType(), True)])# df使用新的scheam进行转换,查看scheam
df.to(schema).schema
# 顺序改变,字段类型改变
StructType([StructField('j', StringType(), True), StructField('i', StringType(), True)])
df.to(schema).show()
+---+---+
| j| i|
+---+---+
| 1| a|
+---+---+# 当schema设置原df不存在的列,则会默认补充null
schema = StructType([StructField("q", StringType()), StructField("w", StringType()),StructField("i", StringType())])
df.to(schema).show()
+----+----+---+
| q| w| i|
+----+----+---+
|null|null| a|
+----+----+---+
相关文章:
)
Pyspark dataframe基本内置方法(4)
文章目录 Pyspark sql DataFrame相关文章RDDrepartition 重新分区replace 替换sameSemantics dataframe是否相等sample 采样sampleBy 分层采样schema 显示dataframe结构select 查询selectExpr 查询semanticHash 获取哈希值show 展示dataframesort 排序sortWithinPartitions 分区…...

配置win10开电脑时显示可登录账号策略
有1台公用的windows10电脑,电脑上有N多用户,使用人员登录时选择相应的账号登录即可。但在某次使用脚本加固后,发现之前显示的用户都不能显示了。检查加固脚本,是脚本启用了“交互式登录:不显示上次登录”策略。因此&am…...
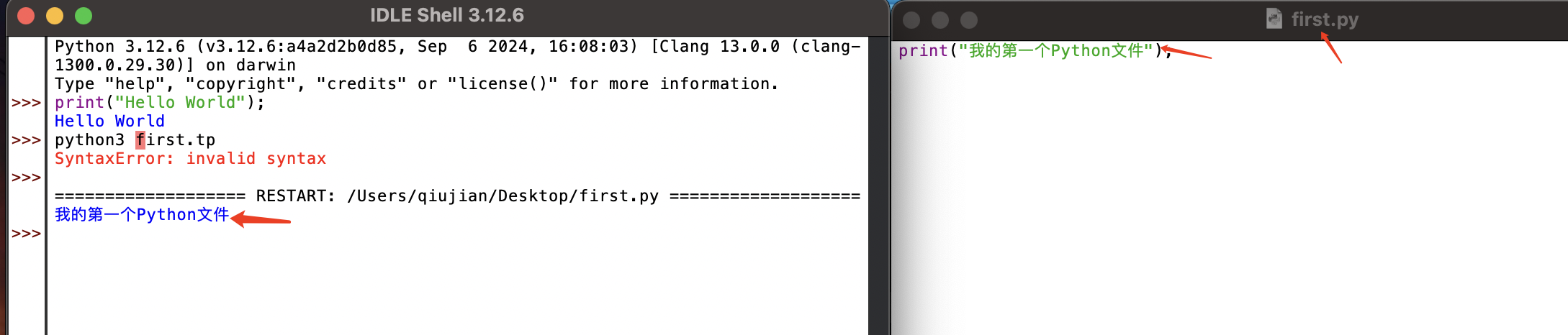
01-Mac OS系统如何下载安装Python解释器
目录 Mac安装Python的教程 mac下载并安装python解释器 如何下载和安装最新的python解释器 访问python.org(受国内网速的影响,访问速度会比较慢,不过也可以去我博客的资源下载) 打开历史发布版本页面 进入下载页 鼠标拖到页面…...

24 C 语言常用的字符串处理函数详解:strlen、strcat、strcpy、strcmp、strchr、strrchr、strstr、strtok
目录 1 strlen 1.1 函数原型 1.2 功能说明 1.3 案例演示 1.4 注意事项 2 strcat 2.1 函数原型 2.2 功能说明 2.3 案例演示 2.4 注意事项 3 strcpy 3.1 函数原型 3.2 功能说明 3.3 案例演示 3.4 注意事项 4 strcmp 4.1 函数原型 4.2 功能说明 4.3 案例演示 …...

数据驱动农业——农业中的大数据
橙蜂智能公司致力于提供先进的人工智能和物联网解决方案,帮助企业优化运营并实现技术潜能。公司主要服务包括AI数字人、AI翻译、埃域知识库、大模型服务等。其核心价值观为创新、客户至上、质量、合作和可持续发展。 橙蜂智农的智慧农业产品涵盖了多方面的功能&…...

学习《分布式》必须清楚的《CAP理论》
分布式的理论基础CAP理论 当学习分布式的redis、mq等中间件时,都会看到有提到CAP。 CAP理论是学习分布式必备的一个概念知识点。 CAP理论由三个特性组成,分别是一致性(Consistency)、可用性(Availability࿰…...

navicat无法连接远程mysql数据库1130报错的解决方法
出现报错:1130 - Host ipaddress is not allowed to connect to this MySQL serve navicat,当前ip不允许连接到这个MySQL服务 解决当前ip无法连接远程mysql的方法 1. 查看mysql端口,并在服务器安全组中放开相应入方向端口后重启服务器 sud…...

JetPack01- LifeCycle 监听Activity或Fragment的生命周期
前提 阅读本文的前提是要了解观察者模式。本文没有讲述反射相关的内容,功能中有使用反射。 简介 监听Activity/Fragment的生命周期,使用观察者模式,Activity/Fragment是被观察者。 监听的生命周期有onCreate、onStart、onResume、onPause…...

OpenCSG推出StarShip SecScan:AI驱动的软件安全革新
OpenCSG 导读 如今,IT 技术迅速发展,软件安全不仅是企业稳健运营的基础,更是整个社会经济体系安全的保障。加强软件安全,尤其是在开发阶段识别和修补漏洞,是企业必须重视的问题。国际数据公司(IDC…...

占道经营检测-目标检测数据集(包括VOC格式、YOLO格式)
占道经营检测-目标检测数据集(包括VOC格式、YOLO格式) 数据集: 链接:https://pan.baidu.com/s/1e4Ydsb7FaUeWcQ-76ClTpQ?pwdq7n7 提取码:q7n7 数据集信息介绍: 共有 1143 张图像和一一对应的标注文件 标…...

828华为云征文 | 云服务器Flexus X实例:RAG 开源项目 FastGPT 部署,玩转大模型
目录 一、FastGPT 简介 二、FastGPT 部署 2.1 下载启动文件 2.2 开放端口权限 2.3 启动 FastGPT 三、FastGPT 运行 3.1 登录 FastGPT 3.2 知识库 3.3 应用 四、总结 本篇文章主要通过 Flexus云服务器X实例 部署 RAG 开源项目 FastGPT,通过 FastGPT 可以使…...

MySQL之基本查询(一)(insert || select)
目录 一、表的增删查改 二、表的增加insert 三、表的读取select where 条件子句 结果排序 筛选分页结果 一、表的增删查改 我们平时在使用数据库的时候,最重要的就是需要对数据库进行各种操作。而我们对数据库的操作一般来说也就是四个操作,CRUD :…...

基于深度学习的多智能体协作
基于深度学习的多智能体协作是一种通过多个智能体相互协作完成复杂任务的框架,利用深度学习技术来优化智能体之间的合作与决策过程。多智能体系统广泛应用于自动驾驶、机器人群体、游戏AI、资源调度、无人机编队等领域,其中每个智能体通常具有自主性&…...

Nmap网络扫描器基础功能介绍
怎么快速知道网络中存在哪些设备呢?我们可以借用扫描工具Nmap来实现这个功能。 下载 Windows系统可以前往Nmap官网下载安装包。 Linux使用对应的包管理器可以直接安装,命令如下 # Debian/Ubuntu apt install nmap# RedHat/Fedora yum install nmap …...

idea 编辑器常用插件集合
SequenceDiagram 用于生成时序图的插件,支持一键生成功能。 使用:选择某个具体的方法,点击右键菜单,选择“Sequence Diagram” 便可生成相应的时序图 例子: 效果: Code Iris Code Iris可以根据代码自动…...

如何优化Java商城系统的代码结构
前言 优化Java商城系统的代码结构可以提高代码的可维护性、可读性和性能。以下是一些建议: 一、模块化设计 将系统拆分为多个模块,每个模块负责特定的功能。例如,可以将用户管理、商品管理、订单管理等功能分别放在不同的包中。 二、分层…...

两数之和、三数之和、四数之和
目录 两数之和 题目链接 题目描述 思路分析 代码实现 三数之和 题目链接 题目描述 思路分析 代码实现 四数之和 题目链接 题目描述 思路分析 代码实现 两数之和 题目链接 LCR 179. 查找总价格为目标值的两个商品 - 力扣(LeetCode) 题目…...
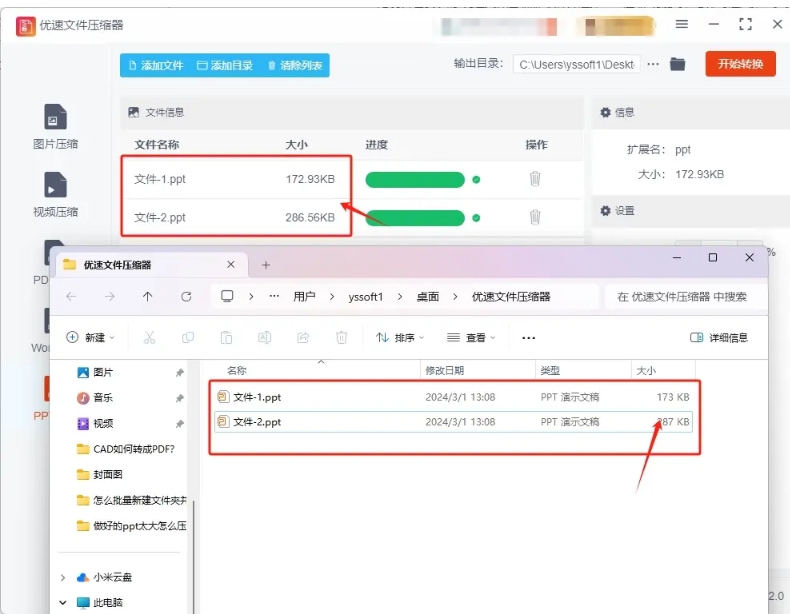
这几个方法轻松压缩ppt文件大小,操作起来很简单的压缩PPT方法
这几个方法轻松压缩ppt文件大小。在当今信息化迅速发展的时代,PPT已成为工作和学习中必不可少的工具。然而,随着内容的增加,文件体积常常变得庞大,影响了分享和传输的便利性。过大的文件不仅占用存储空间,还可能导致演…...

【nvm管理多版本node】下载安装以及常见问题和解决方案
nvm管理多版本node nvm 下载安装下载安装 nvm 常用命令其他常用命令 常见问题 nvm 下载安装 下载 nvm下载地址 每个版本下都有Assets,根据需要下载一个。 node下载地址 根据自己需要,可以下载可执行文件或者压缩包 安装 按提示安装即可。 安装过程中ÿ…...

C++(学习)2024.9.23
目录 运算符重载 1.概念 2.友元函数运算符重载 3.成员函数运算符重载 4.特殊运算符重载 1.赋值运算符重载 2.类型转换运算符重载 5.注意事项 std::string字符串类: 模板与容器 模板 1.函数模板 2.类模板 类内实现 类内声明类外实现 运算符重载 1.概念…...

OpenClaw 中最经典的 6 款skill,真正能进工作流的 skills
2026 开年至今,AI 圈里两个词出镜率最高:龙虾 和 Skill。 龙虾更像一阵风——话题来得快,讨论散得也快;Skill 却在慢慢变成能天天用的东西:装一次,反复省时间。 可惜市面上不少 Skill 推荐文不太耐看&…...

Linux入门指南:从内核到终端,掌握核心命令与文件操作
1. 从内核到终端:理解Linux的运作逻辑很多刚接触Linux的朋友,包括我当年,都会觉得它是一堆神秘命令的集合。输入几个字母,敲下回车,系统就乖乖听话了。但要想真正用好Linux,而不是死记硬背命令,…...

藏在Modbus‘写寄存器’请求里的秘密:用Python+pyshark复现CISCN2023流量分析
藏在Modbus‘写寄存器’请求里的秘密:用Pythonpyshark复现CISCN2023流量分析 当生产网络流量中出现异常数据包时,传统的手动分析方式往往效率低下。本文将带你用Pythonpyshark构建自动化分析流水线,从海量Modbus协议数据中快速定位可疑通信模…...

电磁仿真进阶--CST空心电感建模与实测验证全流程
1. 空心电感建模与仿真的工程价值 空心电感作为高频电路中的核心无源器件,其性能直接影响射频前端、滤波电路等关键模块的工作表现。与传统带磁芯的电感不同,空心电感避免了磁饱和问题,但同时也面临着建模复杂度高、高频特性难以准确预测的挑…...

3步掌握QQ音乐解析:Python工具免费获取全网音乐资源
3步掌握QQ音乐解析:Python工具免费获取全网音乐资源 【免费下载链接】MCQTSS_QQMusic QQ音乐解析 项目地址: https://gitcode.com/gh_mirrors/mc/MCQTSS_QQMusic 你是否曾为音乐平台的各种限制而烦恼?付费会员、下载限制、跨平台不兼容……这些痛…...

【亲测免费】 ADS1118驱动程序
ADS1118驱动程序 【下载地址】ADS1118驱动程序 本仓库提供了专用于ADS1118模数转换器(ADC)的驱动程序。ADS1118是一款高性能、高精度的16位模拟到数字转换器,广泛应用于需要精准测量的应用场景中,例如传感器数据采集系统、医疗设备…...

Discovery与Kubernetes深度集成:实现容器化微服务注册发现的终极指南
Discovery与Kubernetes深度集成:实现容器化微服务注册发现的终极指南 【免费下载链接】discovery A registry for resilient mid-tier load balancing and failover. 项目地址: https://gitcode.com/gh_mirrors/discov/discovery 在当今云原生时代࿰…...

统一去马赛克与降噪技术:ESUM模型解析与应用
1. 项目概述:统一去马赛克与降噪技术研究 在数字图像处理领域,去马赛克(Demosaicing)是图像信号处理(ISP)流水线中最关键的步骤之一。这项技术负责将传感器捕获的原始拜耳模式(Bayer Pattern&am…...
)
2023B卷,跳格子(1)
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,跳格子(1) 。 1.1 ☘️题目详情 题目: 小明和朋友…...

突破60帧限制!《原神》帧率解锁工具完全指南
突破60帧限制!《原神》帧率解锁工具完全指南 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 还在为《原神》的60帧限制感到困扰吗?想让你的高刷新率显示器发挥真正…...