PyTorch VGG16手写数字识别教程
手写数字识别教程:使用PyTorch和VGG16
1. 环境准备
确保你已安装以下库:
pip install torch torchvision
2. 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
3. 数据预处理
我们需要对MNIST数据集进行转换,使其适合输入VGG16模型。由于VGG16的输入要求为224x224的图像,因此我们需要调整图像大小,并进行标准化处理。
transform = transforms.Compose([transforms.Resize((224, 224)), # 将图像大小调整为224x224transforms.ToTensor(), # 将图像转换为张量transforms.Normalize((0.5,), (0.5,)) # 标准化处理,均值和标准差
])# 下载并加载训练和测试数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
4. 定义VGG16模型
VGG16由多个卷积层和全连接层组成。我们将调整输入通道以适应单通道的MNIST数据。
class VGG16(nn.Module):def __init__(self):super(VGG16, self).__init__()# 定义卷积层self.vgg = nn.Sequential(nn.Conv2d(1, 64, kernel_size=3, padding=1), # 将输入通道设置为1(灰度图)nn.ReLU(), # 激活函数nn.MaxPool2d(kernel_size=2, stride=2), # 最大池化层,减小特征图尺寸nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)# 定义全连接层self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096), # 第一个全连接层nn.ReLU(),nn.Dropout(), # 随机失活,防止过拟合nn.Linear(4096, 4096), # 第二个全连接层nn.ReLU(),nn.Dropout(),nn.Linear(4096, 10) # 输出层,10个类(数字0-9))def forward(self, x):x = self.vgg(x) # 通过卷积层x = x.view(x.size(0), -1) # 展平特征图x = self.classifier(x) # 通过全连接层return x
5. 训练模型
我们将使用交叉熵损失函数和Adam优化器,并训练模型。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 检测可用的设备
model = VGG16().to(device) # 实例化模型并移动到设备上
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器# 训练循环
for epoch in range(5): # 训练5个epochmodel.train() # 设置为训练模式for images, labels in train_loader:images, labels = images.to(device), labels.to(device) # 移动到设备optimizer.zero_grad() # 清空梯度outputs = model(images) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数print(f'Epoch [{epoch+1}/5], Loss: {loss.item():.4f}') # 输出当前epoch的损失
6. 测试模型
在测试阶段,我们将计算模型的准确率。
model.eval() # 设置为评估模式
with torch.no_grad(): # 禁用梯度计算correct = 0total = 0for images, labels in test_loader:images, labels = images.to(device), labels.to(device) # 移动到设备outputs = model(images) # 前向传播_, predicted = torch.max(outputs.data, 1) # 获取预测结果total += labels.size(0) # 统计总样本数correct += (predicted == labels).sum().item() # 统计正确预测的数量print(f'Accuracy: {100 * correct / total:.2f}%') # 输出准确率
总结
这个教程详细介绍了如何使用VGG16模型对MNIST数据集进行手写数字识别。通过调整网络参数和训练轮数,你可以进一步提高模型的性能。希望这个教程能帮助你更好地理解PyTorch及深度学习的应用!
相关文章:

PyTorch VGG16手写数字识别教程
手写数字识别教程:使用PyTorch和VGG16 1. 环境准备 确保你已安装以下库: pip install torch torchvision2. 导入必要的库 import torch import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms import tor…...

安卓13删除下拉栏中的设置按钮 android13删除设置按钮
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.问题分析3.代码分析4.代码修改5.编译6.彩蛋1.前言 顶部导航栏下拉可以看到,底部这里有个设置按钮,点击可以进入设备的设置页面,这里我们将更改为删除,不同用户通过这个地方进入设置。也就是下面这个按钮。 2.问题分析…...

FDA辅料数据库在线免费查询-药用辅料
在药物制剂的研制过程中,需要确定这些药用辅料的安全用量。而美国食品药品监督管理局(FDA)的辅料数据库(IID)提供了其制剂研发中的关键参考资源,使得更多的医药研发相关人员及企业单位节省试验环节及时间成…...

git pull 报错 refusing to merge unrelated histories
这个对我来说非常常见,因为我都是先由本地项目,再想着传到github上去。 在本地项目中执行 git init git add . git commit -m “xxx” 在github上创建项目,添加了 README.md 文件。 git remote add origin https://github.com/raoxiaoya/x…...

STM32G431RBT6(蓝桥杯)串口(发送)
一、基础配置 (1) PA9和PA10就是串口对应在单片机上的端口 注意:一定要先选择PA9的TX和PA10的RX,再去打开异步的模式 (2) 二、查看单片机的端口连接至电脑的哪里 (1)此电脑->右击属性 (2)找到端…...

使用 typed-rest-client 进行 REST API 调用
typed-rest-client 是一个用于 Node.js 的库,它提供了一种类型安全的方式来与 RESTful API 进行交互。其主要功能包括: 安装 typed-rest-client 要使用 typed-rest-client,首先需要安装它,可以通过 npm 来安装: $ n…...

在Ubuntu 14.04上安装Solr的方法
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 Solr 是基于 Apache Lucene 的搜索引擎平台。它用 Java 编写,并使用 Lucene 库来实现索引。可以通过各种 REST API&am…...
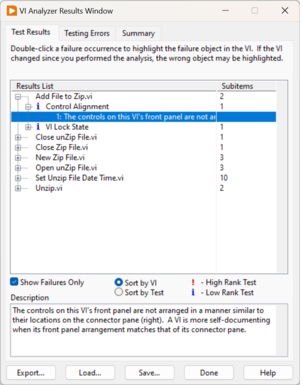
LabVIEW提高开发效率技巧----使用LabVIEW工具
LabVIEW为开发者提供了多种工具和功能,不仅提高工作效率,还能确保项目的质量和可维护性。以下详细介绍几种关键工具,并结合实际案例说明它们的应用。 1. VI Analyzer:自动检查代码质量 VI Analyzer 是LabVIEW提供的一款强大的工…...
)
Pyspark dataframe基本内置方法(4)
文章目录 Pyspark sql DataFrame相关文章RDDrepartition 重新分区replace 替换sameSemantics dataframe是否相等sample 采样sampleBy 分层采样schema 显示dataframe结构select 查询selectExpr 查询semanticHash 获取哈希值show 展示dataframesort 排序sortWithinPartitions 分区…...

配置win10开电脑时显示可登录账号策略
有1台公用的windows10电脑,电脑上有N多用户,使用人员登录时选择相应的账号登录即可。但在某次使用脚本加固后,发现之前显示的用户都不能显示了。检查加固脚本,是脚本启用了“交互式登录:不显示上次登录”策略。因此&am…...
01-Mac OS系统如何下载安装Python解释器
目录 Mac安装Python的教程 mac下载并安装python解释器 如何下载和安装最新的python解释器 访问python.org(受国内网速的影响,访问速度会比较慢,不过也可以去我博客的资源下载) 打开历史发布版本页面 进入下载页 鼠标拖到页面…...

24 C 语言常用的字符串处理函数详解:strlen、strcat、strcpy、strcmp、strchr、strrchr、strstr、strtok
目录 1 strlen 1.1 函数原型 1.2 功能说明 1.3 案例演示 1.4 注意事项 2 strcat 2.1 函数原型 2.2 功能说明 2.3 案例演示 2.4 注意事项 3 strcpy 3.1 函数原型 3.2 功能说明 3.3 案例演示 3.4 注意事项 4 strcmp 4.1 函数原型 4.2 功能说明 4.3 案例演示 …...

数据驱动农业——农业中的大数据
橙蜂智能公司致力于提供先进的人工智能和物联网解决方案,帮助企业优化运营并实现技术潜能。公司主要服务包括AI数字人、AI翻译、埃域知识库、大模型服务等。其核心价值观为创新、客户至上、质量、合作和可持续发展。 橙蜂智农的智慧农业产品涵盖了多方面的功能&…...

学习《分布式》必须清楚的《CAP理论》
分布式的理论基础CAP理论 当学习分布式的redis、mq等中间件时,都会看到有提到CAP。 CAP理论是学习分布式必备的一个概念知识点。 CAP理论由三个特性组成,分别是一致性(Consistency)、可用性(Availability࿰…...

navicat无法连接远程mysql数据库1130报错的解决方法
出现报错:1130 - Host ipaddress is not allowed to connect to this MySQL serve navicat,当前ip不允许连接到这个MySQL服务 解决当前ip无法连接远程mysql的方法 1. 查看mysql端口,并在服务器安全组中放开相应入方向端口后重启服务器 sud…...

JetPack01- LifeCycle 监听Activity或Fragment的生命周期
前提 阅读本文的前提是要了解观察者模式。本文没有讲述反射相关的内容,功能中有使用反射。 简介 监听Activity/Fragment的生命周期,使用观察者模式,Activity/Fragment是被观察者。 监听的生命周期有onCreate、onStart、onResume、onPause…...

OpenCSG推出StarShip SecScan:AI驱动的软件安全革新
OpenCSG 导读 如今,IT 技术迅速发展,软件安全不仅是企业稳健运营的基础,更是整个社会经济体系安全的保障。加强软件安全,尤其是在开发阶段识别和修补漏洞,是企业必须重视的问题。国际数据公司(IDC…...

占道经营检测-目标检测数据集(包括VOC格式、YOLO格式)
占道经营检测-目标检测数据集(包括VOC格式、YOLO格式) 数据集: 链接:https://pan.baidu.com/s/1e4Ydsb7FaUeWcQ-76ClTpQ?pwdq7n7 提取码:q7n7 数据集信息介绍: 共有 1143 张图像和一一对应的标注文件 标…...

828华为云征文 | 云服务器Flexus X实例:RAG 开源项目 FastGPT 部署,玩转大模型
目录 一、FastGPT 简介 二、FastGPT 部署 2.1 下载启动文件 2.2 开放端口权限 2.3 启动 FastGPT 三、FastGPT 运行 3.1 登录 FastGPT 3.2 知识库 3.3 应用 四、总结 本篇文章主要通过 Flexus云服务器X实例 部署 RAG 开源项目 FastGPT,通过 FastGPT 可以使…...

MySQL之基本查询(一)(insert || select)
目录 一、表的增删查改 二、表的增加insert 三、表的读取select where 条件子句 结果排序 筛选分页结果 一、表的增删查改 我们平时在使用数据库的时候,最重要的就是需要对数据库进行各种操作。而我们对数据库的操作一般来说也就是四个操作,CRUD :…...

机器学习入门实战指南:从零搭建环境到完成第一个分类项目
1. 项目概述:从零开始的机器学习之旅“机器学习”这个词,听起来是不是既酷炫又让人望而生畏?你可能在新闻里看到它驱动着自动驾驶汽车,在手机里体验过它带来的智能推荐,甚至听说它正在改变各行各业。但当你真正想自己动…...

基于CW32F030的BLDC电机控制:从国产MCU到完整评估方案
1. 项目概述:从一颗国产MCU到一套完整的BLDC评估方案最近在做一个直流无刷电机(BLDC)的小项目,选型时发现了一款挺有意思的国产MCU——武汉芯源的CW32F030C8T6,以及围绕它打造的一套完整的评估套件CW32_BLCD_EVA。对于…...

网盘直链下载助手:一键获取9大网盘真实下载地址,告别限速烦恼
网盘直链下载助手:一键获取9大网盘真实下载地址,告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中…...

初次使用 Taotoken 从注册获取 Key 到完成第一次 API 调用的全过程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 从注册获取 Key 到完成第一次 API 调用的全过程 对于初次接触大模型 API 的开发者来说,从一个新平台…...

【亲测免费】 Python Qt 图形界面编程资源下载
Python Qt 图形界面编程资源下载 【下载地址】PythonQt图形界面编程资源下载 《Python Qt 图形界面编程》课程涵盖了PySide2、PyQt5、PyQt和PySide等框架的使用,帮助学习者掌握Python图形化界面编程的核心知识。课程内容详实,适合初学者入门,…...

5分钟极速上手:用Open-Lyrics让AI为你的音频自动生成专业字幕
5分钟极速上手:用Open-Lyrics让AI为你的音频自动生成专业字幕 【免费下载链接】openlrc Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。…...

基于朴素贝叶斯算法的情感文本分析与分类:快速上手情感分析
基于朴素贝叶斯算法的情感文本分析与分类:快速上手情感分析 【下载地址】基于朴素贝叶斯机器学习算法的情感文本分析与分类 本资源文件提供了一个基于朴素贝叶斯机器学习算法的情感文本分析与分类的实现。该实现包含了数据集和预训练的中文分词模型,帮助…...

MAA智能助手:5分钟掌握《明日方舟》全自动日常管理终极方案
MAA智能助手:5分钟掌握《明日方舟》全自动日常管理终极方案 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https:…...

taotoken用量看板如何帮助开发者清晰掌握各模型消耗详情
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken用量看板如何帮助开发者清晰掌握各模型消耗详情 对于使用多个大模型进行开发的团队或个人而言,成本管理是一个…...

HEC-RAS 5.0.7实战:从模型结果到ArcGIS,一步步教你生成并导出淹没范围SHP文件
HEC-RAS 5.0.7与ArcGIS联合作战:专业级淹没分析全流程指南 水利工程师在完成HEC-RAS模型计算后,常面临一个关键挑战:如何将模拟结果转化为实际项目所需的GIS数据?本文将以HEC-RAS 5.0.7为例,详细拆解从模型结果到ArcGI…...