c/c++八股文
c++基础
一、指针和引用的区别
-
定义方式:
- 指针是通过
*操作符定义的变量,用于存储另一个变量的地址。例如:int* p = &x; - 引用是通过
&操作符定义的别名,直接引用另一个变量。例如:int& r = x;
- 指针是通过
-
内存占用:
- 指针是一个独立的变量,占用一定的内存空间。
- 引用不是独立的变量,它只是另一个变量的别名,不占用额外的内存空间。
-
赋值和间接访问:
- 指针需要使用
*操作符进行间接访问,例如*p = 10; - 引用可以直接像普通变量一样赋值和访问,例如
r = 10;
- 指针需要使用
-
空值表示:
- 指针可以被赋值为
NULL或nullptr表示空指针。 - 引用不能被赋值为空,必须始终指向一个有效的变量。
- 指针可以被赋值为
-
生命周期:
- 指针的生命周期独立于它所指向的变量。
- 引用的生命周期与它所引用的变量相同。
-
函数参数传递:
- 可以使用指针作为函数参数进行传递。
- 也可以使用引用作为函数参数进行传递。
二、数据类型
在 C++ 中,数据类型定义了变量可以存储的数据的类型和大小。C++ 提供了以下几种基本数据类型:
-
整数类型:
int: 整数类型,通常占用 4 个字节,取值范围为 -2,147,483,648 到 2,147,483,647。short: 短整数类型,通常占用 2 个字节,取值范围为 -32,768 到 32,767。long: 长整数类型,通常占用 4 个字节,取值范围为 -2,147,483,648 到 2,147,483,647。long long: 长长整数类型,通常占用 8 个字节,取值范围为 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807。
-
浮点类型:
float: 单精度浮点数,通常占用 4 个字节。double: 双精度浮点数,通常占用 8 个字节。long double: 扩展精度浮点数,通常占用 16 个字节。
-
字符类型:
char: 字符类型,通常占用 1 个字节,可以存储 ASCII 字符。wchar_t: 宽字符类型,通常占用 2 或 4 个字节,可以存储更广泛的字符集。
-
布尔类型:
bool: 布尔类型,只能存储true或false两个值。
-
void 类型:
void: 空类型,通常用于表示函数没有返回值或指针没有指向任何具体类型的对象。
除了这些基本类型,C++ 还支持用户自定义的复合数据类型,如数组、结构体、联合体和类。此外,C++ 还提供了标准库中的一些常用数据类型,如 string、vector、list 等。
三、常指针和指针常的区别
常指针(const pointer)和指针常(pointer to const)是 C++ 中两个不同的概念,它们在使用上有一些区别:
-
常指针(const pointer):
- 声明方式:
type * const ptr; - 特点:
- 指针本身是常量,不能被修改,但指针所指向的值可以被修改。
- 初始化后,指针变量的地址不能被改变。
- 常指针必须在声明时初始化。
- 声明方式:
-
指针常(pointer to const):
- 声明方式:
const type * ptr;或type const * ptr; - 特点:
- 指针所指向的值是常量,不能被修改,但指针本身可以被修改。
- 可以让指针指向不同的地址,但不能通过指针修改所指向的值。
- 指针本身不是常量,可以在声明后被重新赋值。
- 声明方式:
举例说明:
int x = 10, y = 20;
const int* ptr1 = &x; // 指针常
int* const ptr2 = &y; // 常指针*ptr1 = 30; // 错误,不能修改指针所指向的常量
ptr1 = &y; // 正确,可以让指针指向其他地址*ptr2 = 40; // 正确,可以修改指针所指向的值
ptr2 = &x; // 错误,不能修改常指针本身
总的来说,常指针是指针本身是常量,而指针常是指针所指向的值是常量。在使用时需要根据具体需求选择合适的方式。
四、什么是函数指针,如何定义和使用场景
函数指针是一种特殊的指针变量,它指向一个函数,而不是指向一个数据对象。函数指针可以用来动态调用函数,这在某些情况下非常有用。
定义函数指针的语法如下:
返回类型 (*指针变量名)(参数列表);
例如:
int add(int a, int b) {return a + b;
}int (*ptr_add)(int, int) = add;
在这个例子中, ptr_add 就是一个函数指针,它指向 add 函数。
函数指针的使用场景包括:
-
回调函数(Callback Functions):
- 将函数指针作为参数传递给其他函数,在特定事件发生时调用。
- 常见于事件驱动编程、GUI 编程、排序算法等。
-
动态函数调用:
- 根据运行时的条件,选择不同的函数进行调用。
- 可以实现更灵活的程序结构。
-
函数表:
- 将一组相关的函数组织成一个函数指针数组。
- 可以根据索引快速查找并调用对应的函数。
- 常见于状态机、虚函数表等实现中。
-
函数指针作为结构体成员:
- 将函数指针作为结构体的成员,可以实现面向对象风格的编程。
- 常见于回调机制的实现,如 C 标准库中的
qsort函数。
使用函数指针时需要注意以下几点:
- 函数指针的声明和使用必须与函数签名完全匹配。
- 函数指针可以作为函数参数传递,也可以作为函数的返回值。
- 函数指针可以与
void*进行转换,但需要谨慎使用,以免出现类型不匹配的问题。
总之,函数指针是 C/C++ 中一个强大的特性,可以用于实现更灵活和动态的程序结构。
五、函数指针和指针函数的区别
函数指针和指针函数是两个不同的概念,它们之间有以下区别:
-
定义:
- 函数指针是一种指向函数的指针变量,用于存储函数的地址。
- 指针函数是一个返回指针类型的函数。
-
声明:
- 函数指针的声明形式为:
返回类型 (*指针变量名)(参数列表); - 指针函数的声明形式为:
返回类型* 函数名(参数列表);
- 函数指针的声明形式为:
-
用途:
- 函数指针用于动态调用函数,常见于回调函数、函数表等场景。
- 指针函数用于返回一个指向动态分配内存的指针,常用于实现动态数据结构。
-
使用方式:
- 函数指针通过解引用
(* 函数指针)(参数)来调用函数。 - 指针函数通过直接调用
函数名(参数)来获取返回的指针。
- 函数指针通过解引用
例如:
// 函数指针
int add(int a, int b) {return a + b;
}
int (*ptr_add)(int, int) = add;
int result = (*ptr_add)(3, 4); // 调用函数// 指针函数
int* create_array(int size) {return (int*)malloc(size * sizeof(int));
}
int* arr = create_array(10); // 获取返回的指针
总之,函数指针是一种指向函数的指针变量,而指针函数是一种返回指针类型的函数。它们在使用方式和应用场景上有所不同。
六、struct和class的区别
struct和class在C++中是两个不同的关键字,它们之间有以下主要区别:
-
默认访问权限:
- struct的默认访问权限是public。
- class的默认访问权限是private。
-
继承:
- 从struct继承时,默认继承方式是public。
- 从class继承时,默认继承方式是private。
-
语义上的区别:
- struct通常用于表示一个数据结构,强调的是数据的集合。
- class通常用于表示一个抽象的对象,强调的是数据和行为的封装。
-
历史原因:
- struct最初在C语言中用于定义数据结构,后来被C++沿用。
- class是C++引入的新概念,用于面向对象编程。
除了上述主要区别,在实际使用中,struct和class在语法上也有一些细微差异,比如:
- 构造函数、析构函数、运算符重载等成员函数的定义方式略有不同。
- 模板类的定义方式也略有不同。
总的来说,struct和class在C++中都可以用于定义自定义数据类型,但在语义、默认访问权限和继承方式上有所区别,开发者应根据具体需求选择合适的关键字。
七、静态局部变量、全局变量、局部变量的区别和使用场景
静态局部变量、全局变量和局部变量在C++中有以下区别和使用场景:
-
静态局部变量:
- 定义在函数内部,但使用
static关键字修饰。 - 生命周期贯穿整个程序运行,直到程序结束。
- 只能在定义它的函数内部访问和修改。
- 常用于需要在函数调用之间保持状态的场景,如计数器、缓存等。
- 定义在函数内部,但使用
-
全局变量:
- 定义在所有函数之外,没有使用
static关键字修饰。 - 生命周期贯穿整个程序运行,直到程序结束。
- 可以在整个程序的任何地方访问和修改。
- 应该尽量避免使用全局变量,因为它们会增加代码的耦合度和复杂度。但在某些特殊情况下,全局变量仍然是合适的选择,如配置参数、常量等。
- 定义在所有函数之外,没有使用
-
局部变量:
- 定义在函数内部,没有使用
static关键字修饰。 - 生命周期仅在函数调用期间,函数返回后即被销毁。
- 只能在定义它的函数内部访问和修改。
- 是最常见的变量类型,用于存储函数内部的临时数据。
- 定义在函数内部,没有使用
总的来说:
- 静态局部变量用于需要在函数调用之间保持状态的场景。
- 全局变量应该尽量避免使用,但在某些特殊情况下仍然是合适的选择。
- 局部变量是最常见的变量类型,用于存储函数内部的临时数据。
开发者应根据具体需求选择合适的变量类型,以提高代码的可读性、可维护性和性能。
八、c++强制类型转换
C++中有以下几种强制类型转换的方式:
-
static_cast:
- 用于基本数据类型之间的转换,如
int到double、char到int等。 - 可以在继承体系中进行上行转换(从派生类到基类)。
- 不能进行无关类型之间的转换,如
int到string。 - 不能进行无效的转换,如
int到bool(0->false, 非0->true)。
- 用于基本数据类型之间的转换,如
-
dynamic_cast:
- 用于在继承体系中进行下行转换(从基类到派生类)。
- 如果转换失败,返回
nullptr(对指针)或false(对引用)。 - 只能用于含有虚函数的多态类型。
-
const_cast:
- 用于去除或添加
const和volatile属性。 - 不能用于基本数据类型之间的转换。
- 用于去除或添加
-
reinterpret_cast:
- 用于任意类型之间的转换,但转换的结果是未定义的。
- 通常用于指针类型之间的转换,如
int*到char*。 - 应该谨慎使用,因为可能会产生未定义的行为。
使用时需要注意以下几点:
- 尽量使用
static_cast,因为它是最安全的转换方式。 - 只有在必要时才使用
dynamic_cast,因为它需要运行时类型检查,会降低性能。 const_cast和reinterpret_cast应该谨慎使用,因为它们可能会产生未定义的行为。- 强制类型转换可能会导致数据丢失或溢出,应该仔细考虑转换的合理性。
总之,C++提供了多种强制类型转换的方式,开发者应根据具体需求选择合适的转换方式,以确保代码的正确性和安全性。
九、const 关键字
-
修饰变量:
- 声明一个常量变量,其值在程序运行期间不能被修改。
- 可以用于全局变量、局部变量、类成员变量等。
- 常量变量必须在定义时初始化。
-
修饰指针:
const T*: 指针指向的对象是常量,但指针本身可以修改。T* const: 指针本身是常量,但指针指向的对象可以修改。const T* const: 指针本身和指针指向的对象都是常量。
-
修饰函数参数:
- 函数参数声明为
const T&可以避免不必要的拷贝。 - 函数参数声明为
const T*或T* const可以防止函数内部修改参数。
- 函数参数声明为
-
修饰函数返回值:
- 函数返回值声明为
const T&可以返回一个常量引用,避免拷贝开销。 - 函数返回值声明为
const T*或T* const可以返回一个常量指针。
- 函数返回值声明为
-
修饰成员函数:
- 成员函数声明为
const表示该函数不会修改类的成员变量。 - 常量对象只能调用常量成员函数。
- 成员函数声明为
-
常量表达式:
- 使用
constexpr关键字声明一个编译时常量表达式。 - 编译器会在编译期间计算并优化这些常量表达式。
- 使用
总之,const 关键字可以帮助我们定义常量、防止意外修改、优化代码性能等。合理使用 const 可以提高代码的安全性和可维护性。
static关键字
-
修饰局部变量:
- 使局部变量具有静态存储期,即在程序的整个生命周期内存在,而不是在函数调用时创建和销毁。
- 静态局部变量在第一次使用时初始化,之后一直保持其值。
-
修饰全局变量:
- 使全局变量具有内部链接属性,即只能在定义该变量的文件内部访问,其他文件无法访问。
- 可以用于实现文件作用域的全局变量。
-
修饰成员变量:
- 使类的成员变量具有静态存储期,即整个程序运行期间只有一个实例。
- 可以通过类名直接访问静态成员变量,而不需要创建对象。
-
修饰成员函数:
- 使类的成员函数具有静态属性,即不需要通过对象来调用,可以直接通过类名调用。
- 静态成员函数只能访问静态成员变量,不能访问非静态成员变量。
-
修饰命名空间:
- 使命名空间具有内部链接属性,即只能在定义该命名空间的文件内部访问,其他文件无法访问。
总之,static 关键字可以用于修饰变量、函数和命名空间,赋予它们静态存储期、内部链接属性等特性,从而实现一些特殊的功能,如实现文件作用域变量、单例模式等。合理使用 static 可以提高代码的可维护性和性能。
c++内存管理
一、堆和栈的区别
栈(Stack)和堆(Heap)是计算机内存管理中两个非常重要的概念,它们之间有以下几个主要区别:
-
内存分配方式:
- 栈:由编译器自动分配释放,存放函数的参数值、局部变量的值等。
- 堆:通过
new/malloc等动态分配的内存,程序员手动控制分配和释放。
-
内存管理方式:
- 栈:遵循后进先出(LIFO)的原则。
- 堆:没有明确的内存管理方式,通常使用链表等数据结构来记录空闲内存块。
-
内存访问速度:
- 栈:由于遵循LIFO原则,访问速度快。
- 堆:由于没有固定的内存管理方式,访问速度相对较慢。
-
内存碎片:
- 栈:由于遵循LIFO原则,不会产生内存碎片。
- 堆:由于动态分配和释放,容易产生内存碎片。
-
使用场景:
- 栈:函数调用,局部变量存储。
- 堆:动态内存分配,如数组、链表、树等复杂数据结构。
-
大小限制:
- 栈:大小受限,由操作系统设定。
- 堆:理论上大小没有限制,受限于可用内存空间。
总的来说,栈和堆是计算机内存管理的两个重要组成部分,它们各有优缺点,开发者需要根据具体需求选择合适的内存管理方式。合理利用栈和堆有助于提高程序的性能和稳定性。
二、c++内存分区
C++程序在内存中的分区主要包括以下几个部分:
-
代码段(Text Segment):
- 存储程序的机器指令代码。
- 通常是只读的,程序执行期间不会被修改。
-
数据段(Data Segment):
- 存储程序中已初始化的全局变量和静态变量。
- 包括初始化的全局变量和静态变量。
-
未初始化数据段(BSS Segment):
- 存储程序中未初始化的全局变量和静态变量。
- 在程序启动时由操作系统自动将这些变量初始化为0。
-
栈(Stack):
- 用于函数调用时的参数传递、返回地址和局部变量存储。
- 遵循后进先出(LIFO)的原则。
- 由编译器自动分配和释放。
-
堆(Heap):
- 用于动态内存分配,如使用
new和malloc等函数分配的内存。 - 程序员手动控制分配和释放。
- 没有固定的内存管理方式,容易产生内存碎片。
- 用于动态内存分配,如使用
-
常量区(Constant Segment):
- 存储程序中的常量数据,如字符串常量等。
- 通常是只读的,程序执行期间不会被修改。
这些内存分区各自有不同的特点和用途,开发者需要了解它们的特点,合理利用这些内存区域,以提高程序的性能和稳定性。例如,尽量减少在堆上的内存分配,充分利用栈来存储局部变量,减少内存碎片的产生。
三、内存泄露?如何避免?
内存泄露是程序在运行过程中,动态分配的内存没有被及时释放而导致的内存占用不断增加的问题。这可能会导致程序运行缓慢甚至崩溃。避免内存泄露的主要方法包括:
-
及时释放动态分配的内存:
- 在使用
new/malloc等分配内存后,要确保在不需要使用时及时调用delete/free等函数释放内存。 - 尤其要注意在异常情况下或者函数提前返回时,也要确保内存被正确释放。
- 在使用
-
使用智能指针:
- 使用
unique_ptr、shared_ptr等智能指针可以自动管理内存的生命周期,避免手动管理内存带来的错误。
- 使用
-
容器类的正确使用:
- 使用
std::vector、std::list等标准容器时,要确保在容器销毁时,容器内部动态分配的内存也被正确释放。
- 使用
-
定期检查内存使用情况:
- 使用内存分析工具(如Valgrind)定期检查程序的内存使用情况,及时发现和修复内存泄露问题。
-
合理设计数据结构和算法:
- 尽量减少不必要的内存分配,合理设计数据结构和算法,减少内存占用。
-
使用内存池技术:
- 通过预先分配一块内存池,并在需要时从中分配内存,可以减少内存碎片和频繁的内存分配/释放操作。
综上所述,避免内存泄露需要开发者对内存管理有深入的理解,并在编码过程中时刻注意内存使用情况,采取适当的措施来规避内存泄露问题。
四、什么是智能指针?有哪些种类?
智能指针是C++中用于管理动态分配内存的一种机制。它们可以自动管理动态分配的内存,避免手动管理内存带来的错误。C++标准库中提供了几种常用的智能指针类型:
-
unique_ptr:
unique_ptr是独占式的智能指针,即一个unique_ptr对象只能拥有一个指向动态分配内存的指针。- 当
unique_ptr对象被销毁时,它会自动调用delete释放所指向的内存。 unique_ptr不支持拷贝操作,但支持移动操作,可以将一个unique_ptr转移给另一个unique_ptr。
-
shared_ptr:
shared_ptr是共享式的智能指针,多个shared_ptr对象可以共享同一块动态分配的内存。- 每个
shared_ptr对象内部都维护一个引用计数,当最后一个shared_ptr对象被销毁时,它会自动调用delete释放所指向的内存。 shared_ptr支持拷贝和赋值操作,每次拷贝都会增加引用计数。
-
weak_ptr:
weak_ptr是一种弱引用智能指针,它不会增加引用计数。weak_ptr通常与shared_ptr配合使用,用于打破shared_ptr之间的循环引用,避免内存泄露。weak_ptr不能直接访问所指向的对象,需要先转换为shared_ptr才能使用。
这三种智能指针各有特点,开发者可以根据具体需求选择合适的智能指针类型来管理动态分配的内存,从而避免手动管理内存带来的错误。
五、new和malloc有什么区别?
new和malloc都是用于动态内存分配的操作,但它们之间有以下几个主要区别:
-
语法和返回类型:
new是C++中的关键字,用于分配内存并初始化对象。它返回一个指向被分配内存的指针,类型与被分配对象的类型相同。malloc是C标准库中的函数,用于分配未初始化的内存块。它返回一个void*指针,需要强制转换为所需的类型。
-
内存管理:
new会自动调用对象的构造函数进行初始化,delete会自动调用对象的析构函数进行清理。malloc分配的内存是未初始化的,需要手动初始化。释放内存时也需要手动调用free函数。
-
异常处理:
- 如果内存分配失败,
new会抛出std::bad_alloc异常。 malloc返回NULL指针表示分配失败,需要手动检查返回值。
- 如果内存分配失败,
-
数组支持:
new[]可以用于分配动态数组,并自动调用每个元素的构造函数。malloc分配的内存是一个连续的内存块,需要手动计算数组元素的大小和偏移量。
总的来说,new和malloc都可以用于动态内存分配,但new提供了更高级的内存管理功能,更适合C++面向对象的编程风格。在C++中,通常建议使用new和delete来管理动态内存,除非有特殊需求才考虑使用malloc和free。
六、delete和free有什么区别?
delete和free都是用于释放动态分配的内存,但它们之间也有一些重要的区别:
-
适用对象:
delete用于释放使用new或new[]分配的内存。free用于释放使用malloc、calloc或realloc分配的内存。
-
内存管理:
delete会自动调用对象的析构函数进行清理,然后释放内存。free只是简单地释放内存,不会调用任何清理函数。
-
数组支持:
delete[]用于释放使用new[]分配的动态数组。free可以用于释放任何使用malloc分配的内存块,包括数组。
-
异常处理:
- 如果
delete或delete[]失败,会抛出std::bad_alloc异常。 free失败时不会抛出异常,只会返回错误码。
- 如果
总的来说,delete和free都是用于释放动态分配的内存,但delete提供了更好的内存管理功能,特别是对于C++中使用new分配的对象。在C++中,通常建议使用delete和delete[]来释放动态内存,除非有特殊需求才考虑使用free。
七、什么是指针,怎么产生的,如何避免
指针是一种特殊的变量,它存储的是另一个变量的内存地址。指针产生的过程如下:
-
声明指针变量:
int* ptr; // 声明一个指向int类型的指针变量 -
获取变量地址:
int x = 10; ptr = &x; // 将变量x的地址赋给指针ptr -
通过指针访问变量:
*ptr = 20; // 通过指针修改变量x的值为20
指针使用时需要注意以下几点,以避免出现问题:
-
初始化:
- 声明指针时要初始化为NULL或有效地址,否则会产生未定义行为。
-
访问未初始化的指针:
- 访问未初始化的指针会导致程序崩溃或产生未定义行为。
-
越界访问:
- 访问超出分配内存范围的指针会导致程序崩溃或产生未定义行为。
-
内存泄漏:
- 动态分配的内存在使用完毕后必须及时释放,否则会导致内存泄漏。
-
悬空指针:
- 指向已经被释放的内存的指针称为悬空指针,访问它会产生未定义行为。
为了避免这些问题,可以采取以下措施:
- 及时初始化指针变量。
- 在使用指针前检查其是否为NULL。
- 使用动态内存分配时,及时释放不再使用的内存。
- 在释放内存后立即将指针设置为NULL。
- 使用智能指针等RAII机制管理动态内存。
总之,指针是一个强大但也容易出错的工具,需要谨慎使用。遵循良好的编程实践可以有效避免指针相关的问题。
c++面向对象
1.面向对象的三大特性
面向对象编程的三大特性是:
-
封装(Encapsulation):
- 封装是将数据和方法绑定在一起,形成一个独立的实体(类)。
- 封装可以隐藏类的内部实现细节,仅对外提供必要的接口,提高代码的可维护性和可重用性。
- 通过访问修饰符(public、private、protected)控制类成员的可见性。
-
继承(Inheritance):
- 继承是一种创建新类的方式,新类(子类)可以继承现有类(父类)的属性和方法。
- 继承可以实现代码的重用,提高开发效率。
- 子类可以重写(override)父类的方法,实现多态性。
-
多态(Polymorphism):
- 多态是指同一操作作用于不同的对象,可以产生不同的执行结果。
- 多态可以通过方法重载(Overloading)和方法重写(Overriding)实现。
- 多态可以提高代码的灵活性和扩展性,使程序更加通用和可维护。
这三大特性是面向对象编程的核心,它们相互关联,共同构建了面向对象编程的基础。
- 封装隐藏了类的内部实现细节,提高了代码的可维护性。
- 继承实现了代码的重用,提高了开发效率。
- 多态提高了代码的灵活性和扩展性,使程序更加通用。
这三大特性共同构成了面向对象编程的基础,是面向对象编程的重要组成部分。
二、简述一下c++的重载和重写,以及它们的区别
TXYZ: C++中的重载(Overloading)和重写(Overriding)是两个不同的概念,它们的区别如下:
- 重载(Overloading):
- 重载是在同一个类中定义具有相同名称但参数列表不同的多个函数。
- 编译器根据函数的参数列表来决定调用哪个函数版本。
- 重载可以发生在函数、运算符、构造函数等上。
- 重载是一种编译时多态性(Compile-time Polymorphism)。
示例:
class Math {
public:int add(int a, int b) {return a + b;}int add(int a, int b, int c) {return a + b + c;}
};
- 重写(Overriding):
- 重写是在派生类中定义一个与基类中虚函数具有相同名称和参数列表的函数。
- 当通过基类的指针或引用调用该虚函数时,会调用派生类中重写的版本。
- 重写是实现运行时多态性(Run-time Polymorphism)的基础。
- 重写要求基类中的函数必须是虚函数。
示例:
class Animal {
public:virtual void makeSound() {cout << "The animal makes a sound" << endl;}
};class Dog : public Animal {
public:void makeSound() override {cout << "The dog barks" << endl;}
};
区别:
-
定义位置:
- 重载发生在同一个类的成员函数中。
- 重写发生在派生类中,重写基类的虚函数。
-
多态性:
- 重载是编译时多态性,编译器根据参数列表决定调用哪个函数版本。
- 重写是运行时多态性,通过虚函数机制实现。
-
函数签名:
- 重载要求函数名相同,但参数列表不同。
- 重写要求函数名、参数列表和返回类型完全相同。
总之,重载是同一个类中的函数多态性,而重写是派生类中覆盖基类虚函数的机制,两者都是C++中实现多态性的重要手段。
三、什么是多继承
C++中的多继承是指一个类可以继承自多个基类的特性。这是C++相比于其他面向对象语言(如Java和C#)的一个重要特性。
多继承的语法如下:
class DerivedClass : public BaseClass1, protected BaseClass2, private BaseClass3 {// 类定义
};
在上述示例中,DerivedClass继承自三个基类:BaseClass1、BaseClass2和BaseClass3。
多继承的主要特点包括:
-
灵活性:多继承允许一个类从多个基类中继承属性和方法,增加了类的灵活性和功能。
-
代码复用:通过多继承,可以在不同的类层次结构中重用代码,提高开发效率。
-
潜在问题:多继承可能会引入命名冲突、菱形继承等问题,需要开发者谨慎使用。
多继承的常见应用场景包括:
- 实现复杂的类层次结构,如混合类型的对象。
- 在不同的继承体系中重用代码。
- 实现接口继承和实现继承的分离。
需要注意的是,多继承虽然提供了灵活性,但也增加了代码的复杂性和维护难度。因此,在实际开发中,应该权衡利弊,合理地使用多继承特性。
四、c++的多态如何实现
C++中的多态主要通过以下几种方式实现:
-
虚函数(Virtual Functions):
- 在基类中声明虚函数,在派生类中重写该函数。
- 通过基类指针或引用调用虚函数时,会根据实际对象的类型调用相应的函数实现。
- 示例:
class Animal { public:virtual void makeSound() {std::cout << "The animal makes a sound" << std::endl;} };class Dog : public Animal { public:void makeSound() override {std::cout << "The dog barks" << std::endl;} };
-
动态绑定(Dynamic Binding):
- 通过虚函数实现动态绑定,即在运行时确定调用哪个函数实现。
- 动态绑定仅在通过基类指针或引用调用虚函数时才会发生。
-
抽象基类(Abstract Base Classes):
- 包含纯虚函数的类称为抽象基类。
- 抽象基类不能被实例化,只能作为接口被继承。
- 派生类必须实现所有的纯虚函数,才能被实例化。
- 示例:
class Shape { public:virtual double getArea() = 0; };class Circle : public Shape { public:double getArea() override {return 3.14 * radius * radius;}// 其他成员函数 private:double radius; };
-
多态数组和指针:
- 可以使用基类指针或引用指向派生类对象,并调用虚函数。
- 示例:
Animal* animals[] = {new Dog(), new Cat(), new Bird()}; for (Animal* animal : animals) {animal->makeSound(); }
总的来说,C++通过虚函数、动态绑定和抽象基类等机制实现了多态,使得程序能够根据对象的实际类型调用相应的函数实现,提高了代码的灵活性和可扩展性。
五、有哪些访问修饰符
C++中有以下几种访问修饰符:
-
public:
- 被声明为
public的成员可以从任何地方访问。 - 通常用于公共接口和方法。
- 被声明为
-
private:
- 被声明为
private的成员只能在类的内部访问。 - 通常用于类的私有数据成员。
- 被声明为
-
protected:
- 被声明为
protected的成员可以在类的内部以及派生类中访问。 - 通常用于需要被派生类访问的成员。
- 被声明为
-
friend:
friend关键字可以使一个函数或类成为另一个类的友元,从而可以访问该类的私有和保护成员。- 友元关系是单向的,不具有传递性。
-
default (无访问修饰符):
- 如果不显式指定访问修饰符,则默认为
private(对于类)或public(对于结构体)。
- 如果不显式指定访问修饰符,则默认为
访问修饰符的使用规则如下:
public成员可以被任何地方访问。private成员只能被类的成员函数和友元函数访问。protected成员可以被类的成员函数、友元函数以及派生类的成员函数访问。- 友元函数和友元类可以访问类的所有成员,包括私有和保护成员。
合理使用访问修饰符可以帮助我们实现数据封装,提高代码的可维护性和安全性。
六、成员函数、成员变量、静态成员函数、静态成员变量的区别
C++中,成员函数、成员变量、静态成员函数和静态成员变量有以下区别:
-
成员函数:
- 定义在类内部的函数,可以访问类的所有成员(包括私有和保护成员)。
- 每个对象都有自己的一份成员函数副本。
- 可以是普通函数,也可以是虚函数。
-
成员变量:
- 定义在类内部的变量,可以是公有、私有或保护的。
- 每个对象都有自己的一份成员变量副本。
-
静态成员函数:
- 使用
static关键字定义的成员函数。 - 不依赖于任何对象,可以直接通过类名访问。
- 只能访问静态成员变量,不能访问非静态成员变量。
- 没有
this指针。
- 使用
-
静态成员变量:
- 使用
static关键字定义的成员变量。 - 属于整个类,而不是某个对象。
- 可以是公有的,也可以是私有的。
- 在类外必须进行定义和初始化。
- 所有对象共享同一份静态成员变量。
- 使用
总结:
- 成员函数和成员变量依赖于对象,每个对象都有自己的副本。
- 静态成员函数和静态成员变量不依赖于对象,属于整个类。
- 静态成员函数只能访问静态成员变量,不能访问非静态成员变量。
- 合理使用静态成员可以提高内存利用率和代码可维护性。
七、什么是构造函数和析构函数?
在C++中,构造函数和析构函数是特殊的成员函数,它们分别在对象创建和销毁时自动被调用。
-
构造函数:
- 与类同名的成员函数,没有返回值类型。
- 在创建对象时自动被调用,用于初始化对象的成员变量。
- 可以有参数,用于接受外部传入的初始化数据。
- 如果没有定义构造函数,编译器会提供一个默认的无参构造函数。
-
析构函数:
- 与类同名,前面加上波浪号
~的成员函数。 - 在对象销毁时自动被调用,用于释放对象占用的资源。
- 不能有参数,也不能有返回值。
- 如果没有定义析构函数,编译器会提供一个默认的析构函数。
- 与类同名,前面加上波浪号
构造函数和析构函数的作用:
- 构造函数确保对象在使用前被正确初始化。
- 析构函数确保对象在销毁前释放所占用的资源,如动态内存、文件句柄等。
- 构造函数和析构函数可以实现资源的RAII(Resource Acquisition Is Initialization)管理。
示例:
class MyClass {
public:MyClass() { // 构造函数// 初始化成员变量}~MyClass() { // 析构函数// 释放资源}// 其他成员函数
private:// 成员变量
};
八、c++构造函数有哪几种,分别什么作用
C++中构造函数主要有以下几种类型:
-
默认构造函数:
- 没有参数的构造函数。
- 当没有定义任何构造函数时,编译器会提供一个默认的无参构造函数。
- 用于对对象的成员变量进行初始化。
-
带参数的构造函数:
- 带有一个或多个参数的构造函数。
- 用于根据传入的参数对对象的成员变量进行初始化。
-
拷贝构造函数:
- 接受一个与当前类类型相同的引用参数的构造函数。
- 用于创建一个新对象,并将其初始化为另一个同类型对象的副本。
- 形式为
ClassName(const ClassName& other);
-
移动构造函数:
- 接受一个与当前类类型相同的右值引用参数的构造函数。
- 用于创建一个新对象,并将其初始化为另一个同类型对象的移动副本。
- 形式为
ClassName(ClassName&& other);
-
委托构造函数:
- 一个构造函数调用同类中的另一个构造函数来完成初始化。
- 用于减少代码重复,提高可维护性。
- 形式为
ClassName() : ClassName(args) {}
这些构造函数的作用是确保对象在使用前被正确初始化,满足不同的初始化需求。合理使用这些构造函数可以提高代码的健壮性和可读性。
c++新特性
一、c++11新特性有哪些
C++11 的新特性主要包括以下几个方面:
- 自动类型推导
- 统一的初始化语法
- 右值引用和移动语义
- Lambda 表达式
- 线程和并发支持
- 智能指针
- 模板元编程的增强
- 标准库的扩展
二、智能指针
可以得出以下关于 C++ 智能指针的信息:
智能指针是 C++ 中一种特殊的指针类型,它们能够自动管理内存,避免手动分配和释放内存带来的问题,如内存泄漏和悬空指针等。
智能指针的使用可以提高代码的可靠性和安全性,但同时也会带来一些性能开销。研究表明,智能指针的使用会对客户端代码产生一定的影响。
此外,智能指针的错误使用也可能导致一些常见的内存相关问题,如内存泄漏和悬空指针等。为了避免这些问题,需要正确地使用和管理智能指针。
总的来说,智能指针是 C++ 中一种非常有用的特性,可以帮助开发者更好地管理内存,提高代码的可靠性和安全性。但在使用时也需要注意一些潜在的问题,并采取相应的措施来避免。
三、类型推导
类型推导是C++中一个重要的概念。它涉及以下几个方面:
-
自动类型推导(auto关键字)和decltype关键字可以帮助编译器自动推导变量的类型,减少手动指定类型的需求 。
-
模板类型推导可以让编译器根据函数参数自动推导模板参数的类型,避免了手动指定模板参数 。
-
类型推导在C++中有很多应用场景,包括函数重载、模板编程、泛型编程等 。
-
类型推导的实现涉及复杂的类型系统和类型推导算法,需要编译器进行复杂的类型分析和推导 。
-
类型推导可以提高代码的可读性和可维护性,但同时也可能带来一些潜在的问题,需要开发者谨慎使用 。
总之,类型推导是C++中一个重要的语言特性,为开发者提供了更灵活和便捷的编程方式,但同时也需要开发者对其原理和使用方法有深入的理解。
四、右值引用
根据搜索结果,与查询"右值引用"相关的内容如下:
C++中的右值引用是一种特殊的引用类型,它引用的是临时对象或将要被销毁的对象。右值引用可以用于实现移动语义,提高程序的性能。具体来说:
右值引用是一种特殊的引用类型,它引用的是临时对象或将要被销毁的对象。右值引用可以用于实现移动语义,提高程序的性能。
函数模板get可以从一个元组对象中返回一个对其中某个值的引用,这个引用可以是左值引用也可以是右值引用。
对于"输入"参数,可以通过值传递便宜复制的类型,而对于其他类型则可以通过传递const引用的方式来避免不必要的复制。
总之,右值引用是C++中一个重要的语言特性,它可以用于实现移动语义,提高程序的性能。开发者需要了解右值引用的使用方法和注意事项,以充分利用这一特性。
五、nullptr
nullptr 是 C++11 引入的一个常量,用于表示空指针。它具有以下特点:
- nullptr 不是一种类型,不能对它进行类型操作,如 sizeof(nullptr)、throw nullptr 等 。
- nullptr 可以安全地赋值给任何指针类型,避免了使用 NULL 可能导致的未定义行为 。
- 使用 nullptr 可以提高代码的可读性和安全性,相比于使用原始指针更加安全和可靠 。
- 现代 C++ 代码应该尽量避免使用原始指针,而是使用智能指针等安全的指针类型 。
- 为了进一步提高代码的安全性,可以使用 not_null<T*> 等工具来确保指针不为空 。
六、范围for循环
范围for循环是C++11引入的一种新的循环语法,它可以更简洁地遍历容器中的元素。与传统的for循环相比,范围for循环可以自动推断容器的类型,并且不需要手动管理迭代器。
范围for循环的语法如下:
for (元素类型 元素变量 : 容器表达式) {// 循环体
}
其中,元素类型是容器中元素的类型,元素变量是循环中使用的变量名,容器表达式是要遍历的容器。
范围for循环的使用可以大大简化代码,提高可读性。它被广泛应用于遍历各种标准库容器,如vector、list、array等。
此外,编译器也可以对范围for循环进行优化,以提高性能。一些编译器支持将范围for循环转换为更高效的形式,如使用SIMD指令等。
总之,范围for循环是C++11引入的一个非常有用的语言特性,可以大大简化代码,提高可读性和性能。
c++STL
一、什么是STL,包含哪些组件
STL (Standard Template Library) 是 C++ 标准库的一部分,包含了大量常用的数据结构和算法。它提供了一系列通用的容器类型,如 vector、list、deque 等,以及各种常用的算法,如排序、搜索、遍历等。STL 的设计遵循了泛型编程的思想,使得代码更加通用和可复用。
指出,面向对象编程只有在充分利用 STL 的原理时才能发挥其全部优势。 认为 STL 将成为 C++ 标准库的重要组成部分,并广泛应用于各种 C++ 项目中。 介绍了 C++ 17 STL 的各种实用配方,帮助开发者充分利用 STL 的强大功能。 则展示了如何优雅和复杂地使用 STL。
总的来说,STL 是 C++ 标准库的重要组成部分,提供了大量常用的数据结构和算法,遵循泛型编程的思想,使得代码更加通用和可复用。开发者可以通过学习和掌握 STL,提高自己的 C++ 编程能力。
二、常见的STL容器
STL 中常见的容器包括以下几种:
-
顺序容器:
vector: 动态数组,支持随机访问。list: 双向链表,支持高效的插入和删除操作。deque: 双端队列,支持在头尾高效插入和删除。array: 固定大小的数组。
-
关联容器:
set: 有序集合,元素唯一且有序。multiset: 有序集合,元素可重复。map: 关联数组,键值对有序存储。multimap: 关联数组,键可重复。
-
无序容器:
unordered_set: 无序集合,元素唯一。unordered_multiset: 无序集合,元素可重复。unordered_map: 无序关联数组,键值对无序存储。unordered_multimap: 无序关联数组,键可重复。
-
容器适配器:
stack: 栈,先进后出。queue: 队列,先进先出。priority_queue: 优先队列,按优先级出队。
这些容器各有特点,适用于不同的场景。开发者可以根据需求选择合适的容器,并利用 STL 提供的丰富算法进行操作。
三、pair容器
std::pair 是 C++ 标准库中提供的一个简单的容器,用于存储两个元素。它定义在 <utility> 头文件中。
std::pair 的主要特点如下:
-
定义:
std::pair<T1, T2> p;其中
T1和T2是两个不同类型的元素。 -
访问元素:
- 第一个元素通过
p.first访问。 - 第二个元素通过
p.second访问。
- 第一个元素通过
-
初始化:
- 使用花括号初始化:
std::pair<int, string> p = {1, "hello"}; - 使用
make_pair()函数初始化:auto p = std::make_pair(1, "hello");
- 使用花括号初始化:
-
比较:
pair支持比较运算符<、>、<=、>=、==、!=。比较规则是先比较first,再比较second。
-
应用场景:
- 作为函数返回值,返回两个相关的值。
- 作为
map或unordered_map的键值对。 - 在需要存储两个相关元素的地方使用。
总之,std::pair 是一个简单实用的容器,在 C++ 开发中使用广泛。
四、vector容器实现与扩充
std::vector 是 C++ 标准库中最常用的动态数组容器之一。它的实现和扩充机制如下:
-
实现原理:
std::vector内部使用连续的内存块存储元素。- 通过维护三个指针来管理内存:
begin: 指向第一个元素。end: 指向最后一个元素的下一个位置。end_of_storage: 指向内存块的末尾。
-
内存分配:
- 初始时,
vector会分配一块足够容纳n个元素的内存空间。 - 当需要添加新元素时,如果当前内存空间不足,
vector会自动分配一块更大的内存空间,并将原有元素拷贝到新空间。
- 初始时,
-
扩充机制:
- 默认情况下,
vector会以当前容量的 2 倍来扩充内存空间。 - 可以通过
reserve()函数手动指定扩充后的容量。
- 默认情况下,
-
元素插入:
- 在尾部插入元素使用
push_back()。 - 在指定位置插入元素使用
insert()。 - 插入元素时,如果内存空间不足,会触发内存重分配。
- 在尾部插入元素使用
-
元素删除:
- 删除尾部元素使用
pop_back()。 - 删除指定位置的元素使用
erase()。 - 删除元素后,
vector会收缩内存空间,以减少内存占用。
- 删除尾部元素使用
-
时间复杂度:
- 尾部插入/删除的时间复杂度为 O(1)。
- 中间插入/删除的时间复杂度为 O(n)。
- 随机访问的时间复杂度为 O(1)。
总之,std::vector 通过动态分配内存、自动扩充等机制,提供了一个灵活高效的动态数组容器。开发者可以根据需求灵活使用 vector 的各种功能。
相关文章:

c/c++八股文
c基础 一、指针和引用的区别 定义方式: 指针是通过 * 操作符定义的变量,用于存储另一个变量的地址。例如: int* p &x;引用是通过 & 操作符定义的别名,直接引用另一个变量。例如: int& r x; 内存占用: 指针是一个独立的变量,占用一定的内存空间。引用不是独立的…...

Docker配置代理解决pull超时问题
操作系统: CentOS Linux 8 Docker版本: 26.1.3 前置:你需拥有🐱 1. 配置 proxy.conf 1.1 创建配置文件目录 创建 docker.service.d,进入到 docker.service.d 中打开 proxy.conf (没有文件打开会自动创建)。 注意:每个人的路径可…...

ECharts的特点
ECharts是一款基于JavaScript的数据可视化图表库,由百度团队开源,并于2018年初捐赠给Apache基金会,成为ASF孵化级项目。ECharts提供了直观、生动、可交互、可个性化定制的数据可视化图表,广泛应用于数据分析和展示领域。以下是关于…...

JVM OutOfMemoryError 与 StackOverflowError 异常
目录 前言 堆溢出 虚拟机栈和本地方法栈溢出 方法区溢出 前言 JVM规范中规定, 除了程序计数器之外, 其他的运行时数据区域, 例如堆栈, 方法区, 都会出现OutOfMemoryError异常. 那么到底是怎么样的代码, 才会引起堆溢出, 栈溢出, 或者是方法区的溢出呢? 如果遇到了又该如何…...

linux防火墙学习
Linux 防火墙配置(iptables和firewalld) Linux 防火墙配置(iptables和firewalld)_iptables配置文件位置-CSDN博客 Linux查看防火墙状态及开启关闭命令_linux 查看防火墙-CSDN博客...

Java面试篇基础部分- Java中的阻塞队列
首先队列是一种前进后出的操作结构,也就是说它只允许从队列前端进入,从队列后端退出。这个前端和后端看个人如何理解,也就是通常所说的入队和出队,队头和队尾。 阻塞队列和一般队列的不同就在于阻塞队列是可以阻塞的,这里所说的并不是说队列中间或者队头队尾被拦截了,而是…...

Go语言并发编程之Channels详解
并发编程是Go语言的一大特色,而channel(通道)则是Go语言中用于实现并发的核心工具之一。它源于CSP(Communicating Sequential Processes)的概念,旨在让多个goroutine之间能够高效地进行通信和同步。本文将深入探讨channel的用法、原理和最佳实践,通过丰富的示例代码和详…...

【Java集合】LinkedList
概要 LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问速度比较慢。另外,他还提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。 链表 链表是…...

大模型之基准测试集(Benchmark)-给通义千问2.0做测评的10个权威测基准测评集
引言 在去年(2023)云栖大会上,阿里云正式发布千亿级参数大模型通义千问2.0。据现场介绍,在10个权威测评中,通义千问2.0综合性能超过GPT-3.5,正在加速追赶GPT-4。以下是通义千问在MMLU、C-Eval、GSM8K、HumanEval、MATH等10个主流…...

解决selenium爬虫被浏览器检测问题
文章目录 专栏导读1.问题解析2.代码解析(Edge/Chrome通用)2.1 设置Edge浏览器选项:2.2 尝试启用后台模式2.3 排除启用自动化模式的标志2.4 禁用自动化扩展2.5 设置用户代理2.6 实例化浏览器驱动对象并应用配置2.7 在页面加载时执行JavaScript代码 3.完整代码(可直接…...

计算机前沿技术-人工智能算法-大语言模型-最新论文阅读-2024-09-17
计算机前沿技术-人工智能算法-大语言模型-最新论文阅读-2024-09-17 1. Large Language Models in Biomedical and Health Informatics: A Review with Bibliometric Analysis H Yu, L Fan, L Li, J Zhou, Z Ma, L Xian, W Hua, S He… - Journal of Healthcare …, 2024 生物…...

LLM - 理解 多模态大语言模型(MLLM) 的 幻觉(Hallucination) 与相关技术 (七)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/142463789 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 多模态…...

如何在C++中实现RDP协议的屏幕更新功能?
在C++中实现RDP协议的屏幕更新功能涉及多个步骤,包括接收RDP服务器发送的屏幕更新PDU(协议数据单元)、解析这些PDU以获取图像数据,以及将这些图像数据渲染到本地显示设备上。以下是一个简化的流程,指导你如何在C++中处理这一功能: 1. 监听和接收屏幕更新PDU 首先,你的…...

Tornado 是一个 Python 异步网络库和 web 框架
Tornado 是一个 Python 异步网络库和 web 框架,它最初由 FriendFeed 开发,后来被 Facebook 收购并开源。Tornado 因其非阻塞的 I/O 操作和优秀的性能而广受欢迎,特别是在需要处理大量并发连接的应用中。Tornado 的底层实现主要依赖于 Python …...

鹏哥C语言49---第5次作业:选择语句 if 和 switch
#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> //---------------------------------------------------------------------------------第 5 次作业:选择语句 if 和 switch //-----------------------------------------------------------------1.输…...
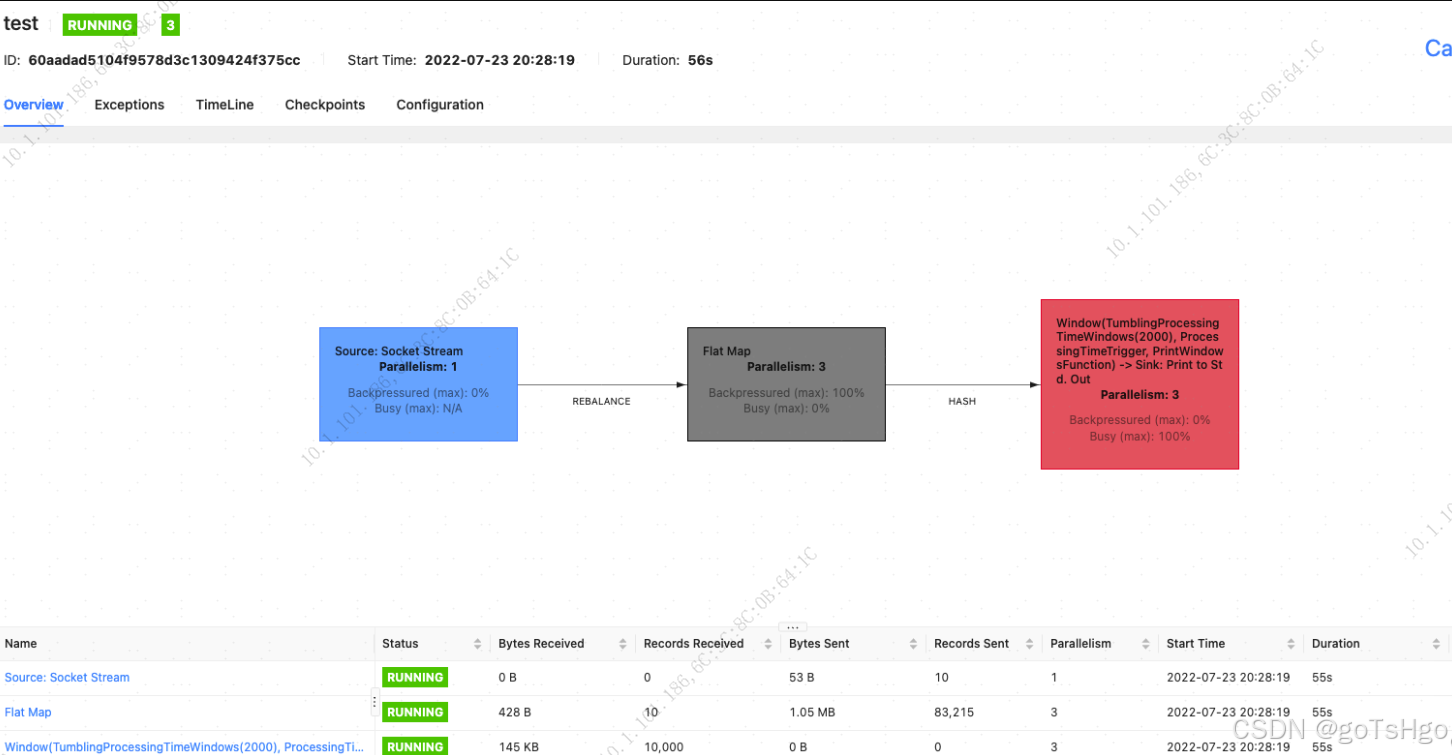
通过 Flink 的火焰图定位反压
在 Apache Flink 中,Web UI 提供了丰富的监控工具来帮助用户分析和解决作业性能问题,其中火焰图(Flame Graph)是用于分析反压问题的一个强有力的工具。反压可能是由于作业中某些算子处理速度过慢,或者资源耗尽导致的。…...

初识爬虫8
1.selenium的作用和工作原理 2. 使用selenium,完成web浏览器调用 # -*- coding: utf-8 -*- # 自动化测试工具,降低难度,性能也降低 from selenium import webdriverdriver webdriver.Edge()driver.get("https://www.itcast.cn/")…...

Unity SRP 可编程渲染管线的基本用法
可编程渲染管线使用教程 SRP 可以处理Canvas为Screen Space - Overlay的渲染 安装插件 首先进入package manager,下载Core RP Lib组件 创建渲染管线 编写渲染管线逻辑脚本 新建脚本取名为MPipeLine,该脚本用于实现渲染管线的处理逻辑 using Unity…...

AutoX.js向后端传输二进制数据
android的JavaScript自动化软件用过Hamibot和AutoX.js 不过在向后端传输二进制数据时都有些限制,不如浏览器前端那么自由。Hamibot的http按文档应该时能支持传字节数组,但是实际上应该还没有支持。AutoX.js的http也是这样,但是AutoX.js还支持…...

lvgl学习笔记--基础对象1
【LVGL学习笔记】(三)控件使用_学习_煜个头头-GitCode 开源社区 LVGL 基础对象|极客笔记 #include "../../../lv_examples.h"void lv_ex_obj_1(void) {lv_obj_t * obj1;obj1 lv_obj_create(lv_scr_act(), NULL);lv_obj_set_size(obj1, 100, …...

Inter字体终极指南:为什么这款开源字体能重新定义数字界面设计
Inter字体终极指南:为什么这款开源字体能重新定义数字界面设计 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为现代数字屏幕设计的开源无衬线字体,通过科学优化的字形设计…...

如何彻底摆脱网盘限速:8大主流网盘直链下载助手完整指南
如何彻底摆脱网盘限速:8大主流网盘直链下载助手完整指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天…...

状态机——枚举实现简单状态机
枚举实现简单状态机1、业务场景:订单状态流转2、代码实现3、上下文对象(Context)4、测试运行5、总结在 Java 中,使用枚举(Enum)来实现状态机(State Machine)是一种非常优雅且高效的做…...

SQL注入技术详解:从联合查询到盲注实战
前言: 继续开始我们的SQL注入吧!本文详细讲解SQL注入的各类技术,包括联合查询、报错注入、布尔盲注、时间盲注、UA注入、Referer注入等,涵盖漏洞判断、利用方法和实战步骤。内容基于MySQL 5.0以上环境,围绕information…...

深入解析PCI中断路由:从硬件引脚到操作系统中断处理的完整链路
1. 项目概述与核心问题在计算机硬件系统里,中断机制是设备与处理器高效通信的生命线。它允许设备在需要处理器服务时,主动“打断”处理器当前的工作流,而不是让处理器不断地去“询问”设备的状态。对于PCI(Peripheral Component I…...

嘎嘎降AI和去AIGC深度对比:2026年按次计费和按篇计费哪个更划算完整评测分析
嘎嘎降AI和去AIGC深度对比:2026年按次计费和按篇计费哪个更划算完整评测分析 总有人问嘎嘎降AI,这篇文章把主流几款对比清楚。 综合推荐嘎嘎降AI(www.aigcleaner.com),4.8元,99.26%达标率。不同需求有不同…...
)
别再为JDK版本头疼了!用Adoptium JRE 13搞定OpenTCS 5.11开发环境(附完整变量配置)
开源AGV调度系统OpenTCS 5.11开发环境配置实战指南 在自动化物流系统开发领域,OpenTCS作为一款功能强大的开源交通控制系统,正逐渐成为AGV(自动导引车)调度解决方案的热门选择。然而对于初次接触该系统的开发者而言,J…...

基于Adafruit NeoTrellis M4的电子鼓机与步进音序器DIY指南
1. 项目概述与核心价值如果你对电子音乐制作、硬件DIY或者嵌入式编程感兴趣,但又觉得门槛太高,那么今天聊的这个项目,绝对能让你眼前一亮。我们不是要复刻一台动辄上万的经典鼓机,而是要用一块巴掌大的开发板——Adafruit NeoTrel…...

DxO PureRAW中文破解版
🔥RAW图像降噪神器!DxO PureRAW中文破解版来了!🚀哈喽,各位摄影老铁们好呀!👋👋 今天给大家安利一款超级硬核的RAW图像处理工具—— ✨ DxO PureRAW ✨ 这可是 DxO Labs 旗下的行业领…...

终极Elsevier审稿追踪指南:5分钟实现智能投稿监控的完整方案
终极Elsevier审稿追踪指南:5分钟实现智能投稿监控的完整方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 还在为Elsevier期刊投稿后的漫长等待而焦虑吗?每天反复登录系统查看审稿进度&…...