LLM - 理解 多模态大语言模型(MLLM) 的 幻觉(Hallucination) 与相关技术 (七)
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/142463789
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
多模态大语言模型(MLLM) 系列:
- 理解 多模态大语言模型(MLLM) 的 发展(Timeline) 与相关技术 (一)
- 理解 多模态大语言模型(MLLM) 的 架构(Architecture) 与相关技术 (二)
- 理解 多模态大语言模型(MLLM) 的 预训练(Pre-training) 与相关技术 (三)
- 理解 多模态大语言模型(MLLM) 的 指令微调(Instruction-Tuning) 与相关技术 (四)
- 理解 多模态大语言模型(MLLM) 的 对齐微调(Alignment) 与相关技术 (五)
- 理解 多模态大语言模型(MLLM) 的 评估(Evaluation) 与相关技术 (六)
- 理解 多模态大语言模型(MLLM) 的 幻觉(Hallucination) 与相关技术 (七)
多模态幻觉(Hallucination) 是多模态大语言模型的生成回复与图像内容不一致的现象。多模态幻觉包括 3 种类型,即:
- 存在幻觉(Existence Hallucination),最基本形式,模型错误地声称图像中存在一些对象。
- 属性幻觉(Attribute Hallucination),以错误的方式描述对象的属性,例如未能正确识别狗的颜色。通常与存在幻觉相关联,因为属性的描述是基于图像中存在的对象。
- 关系幻觉(Relationship Hallucination),更复杂的类型,也基于对象的存在,对象之间关系的错误描述,例如相对位置和互动。
Hallucination: Multimodal hallucination refers to the phenomenon of responses generated by MLLMs being inconsistent with the image content.
缓解多模态幻觉的方式:
- 预校正(Pre-correction),对于幻觉问题,直观且直接的解决方案是收集专门的数据,例如,负样本数据,使用这些数据进行微调,从而,得到具有较少幻觉反应的模型,参考 LRV。
- 过程校正(In-process-correction),在架构设计或特征表示上,进行改进,探索幻觉产生的原因,设计相应的补救措施,以在生成过程中减轻幻觉,参考 VCD & HACL。
- 后校正(Post-correction),以补救的方式减轻幻觉,在输出生成之后,再纠正幻觉,参考 Woodpecker & LURE。
参考论文:
- LRV-Instruction - Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning, ICLR-2024, Microsoft (预先矫正)
- GitHub: https://github.com/FuxiaoLiu/LRV-Instruction.git
- POPE - Evaluating Object Hallucination in Large Vision-Language Models
- VCD - Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding, CVPR-2024, DAMO Alibaba, 2023.11, 过程矫正
- HACL - Hallucination Augmented Contrastive Learning for Multimodal Large Language Model,CVPR-2024, Alibaba & Peking, 2024.2
- LURE - Analyzing and Mitigating Object Hallucination in Large Vision-Language Models, ICLR-2024, UNC-Chapel Hill 北卡罗来纳大学教堂山分校 (University of North Carolina at Chapel Hill)
1. 预矫正(Pre-correction) - LRV
LRV(Large-scale Robust Visual,大规模鲁棒视觉),引入视觉指令调整数据集,除了常见的正指令外,数据集还精心设计不同语义层面的负指令,以鼓励响应忠实于图像内容。数据集包含由 GPT4 生成的 40 万个视觉指令,涵盖 16 个具有 开放式(Open-Ended) 指令和答案的视觉与语言任务。
输入图片和人类指令,引入 GPT4 辅助视觉指令评估(GPT4-Assisted Visual Instruction Evaluation, GAVIE),评估当前大型多模态模型(LMM) 的输出,例如 MiniGPT4 和 mPLUG-Owl。蓝色表示 LMM 无法准确遵循人类指令,而红色表示存在幻觉问题。使用 LRV-指令数据集 进行微调之后,当前的 LMM 可以生成更加鲁棒的答案。即:

LRV-指令数据集:正向和负向样本的示例,红色表示负向指令中的不一致元素。即:

大语言模型的训练数据集对比,如下:
- 困难的负向指令 (Hard Negative Instructions)
- 自生成指令数量 (Self Generated Instruction)
- 解决幻觉 (Address Hallucination)
- 不包含模版指令 (NOT Template Instruction)
- 视觉语言任务数量 (VL Tasks)
即:

在 POPE 数据集评估零样本目标幻觉,图像中不存在的对象,采用三种不同的策略进行采样。
- 随机(Random Set):随机采样
- 流行(Popular Set):MS-COCO 中出现频率最高的前 k 个对象
- 对抗性(Adversarial Set):首先,根据共现频率将对象进行排名,然后,采样出现频率最高的前 k 个对象
Ours-7B 是使用 LRV-指令数据集 微调过的 mPLUG-Owl-7B 模型。

其中 POPE(Polling-based Object Probing Evaluation,
基于轮询的目标探测评估) 的评估流程:
- 输入图像,POPE 根据人类注释中提取图像中的真实对象,或者借助于类似 SEEM 这样的自动分割工具的帮助。
- POPE 在 随机(Random) / 流行(Popular) / 对抗性(Adversarial) 设置下,对于图像中不存在的对象进行负采样。
- 最后,将 真实(Ground-Truth) 对象和不存在(Non-Existent) 对象,组成问题模板,使用 LVLM 投票选择 Yes 获 No。
即:

2. 过程校正(In-process-correction) - VCD & HACL
VCD(Visual Contrastive Decoding,视觉对比解码):大型视觉语言模型(LVLM) 在视觉识别和语言理解方面,取得显著进步,能够生成既连贯又符合上下文的内容。LVLM 仍然存在对象幻觉问题,即模型生成的输出,看起来合理,但是包含图像中不存在的对象。为了解决这个问题,引入视觉对比解码(Visual Contrastive Decoding,简称 VCD) 的方法,简单且无需训练的方法,即通过比较 原始(original) 和 扭曲(distorted) 之间视觉输入产生的输出分布,有效减少对于 统计偏差(statistical bias) 和 单模态先验(unimodal priors) 的过度依赖,而这两种因素是对象幻觉的主要原因。这种调整确保生成的内容与视觉输入紧密相关,从而产生上下文准确的输出。实验表明,无需额外训练或使用外部工具,就能显著减轻不同 LVLM 家族中的对象幻觉问题。VCD不仅减轻了对象幻觉,还在一般 LVLM 基准测试中表现出色,突显了其广泛的适用性。图像加噪声的过程,使用高斯噪声(Gaussian Noise)。
VCD(视觉对比解码) 示例,幻觉对象 冲浪板(Surfboards),用红色标出,在生成过程中,通过与倾向于幻觉的输出分布进行对比,将其消除,即:

其中,视觉不确定性(Visual Uncertainty) 放大 语言先验(Language Priors) 的示例。输入图片,包括一串黑色的香蕉,和其他彩色的水果,随着视觉不确定性的增加,大型视觉语言模型(LVLM) 更倾向于更常见的香蕉颜色,例如黄色和绿色。真实颜色的 黑色在概率 l o g p ( y ∣ x , v ′ ) logp(y|x,v′) logp(y∣x,v′) 中,随着扭曲的加剧而降低,这使得 LVLM 过度依赖于 大语言模型(LLM) 预训练中的语言先验,通常将香蕉与黄色或绿色联系起来,如图:

HACL(Hallucination Augmented Contrastive Learning, 幻觉增强的对比学习) 研究视觉和语言的嵌入空间,基于观察,设计了一种对比学习方案,将 成对跨模态(Paired Cross-Modal) 表征拉近,同时,推开非幻觉和幻觉文本表征。从表征学习的视角来解决 多模态大语言模型(MLLM) 中的幻觉问题。首先分析 MLLM 中文本和视觉标记的表征分布,揭示 2 个重要发现:
- 文本和视觉表征之间存在显著差距,表明跨模态表征对齐的 不满意(Unsatisfactory);
- 包含和不包含幻觉的文本表征,纠缠(Entangled) 在一起,这使得区分变得具有挑战性。
HACL 将对比学习引入到 多模态大语言模型(MLLM) 中,使用包含幻觉的文本作为困难负例(Hard Negative Examples),自然地将非幻觉文本和视觉样本的表征拉近,同时推开非幻觉和幻觉文本的表征。
图(a) 和 图(b) 显示 大语言模型(LLM) 为视觉或文本标记序列产生的最后一个标记的表征分布。蓝色图标代表图像,绿色图标代表真实描述,红色代表由 GPT-4 生成的幻觉描述。HACL,即幻觉增强对比学习。在 图(a) 中,文本和视觉表征存在跨模态语义差距,而非幻觉和幻觉文本表征混合在一起。这一现象通过 HACL 得到缓解,如 图(b) 所示。子图© 显示幻觉评估基准 MMhal-Bench 的经验结果以及模型性能评估指标 MME。即:

图(a) 展示 HACL 框架,使用 GPT-4 来生成幻觉描述,作为图像到文本对比学习中的困难负例,图(b) 展示 HACL 的训练范式(Paradigm),即:

3. 后校正(Post-correction) - LURE
LURE(LVLM hallUcination REvisor, LVLM 幻觉修订):
- 橙色阴影部分显示 LURE 的训练范式,其中黑色边框部分代表幻觉数据生成阶段,包括引入 共现对象(Co-Occurring Objects) 以及替换描述中不确定的对象或后面位置的对象。
- 紫色边框部分表面 修订者(Revisor) 训练过程,其中 Masking 过程,橙色阴影部分展示 LURE 推理阶段的一个示例。
即:

相关文章:
LLM - 理解 多模态大语言模型(MLLM) 的 幻觉(Hallucination) 与相关技术 (七)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/142463789 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 多模态…...

如何在C++中实现RDP协议的屏幕更新功能?
在C++中实现RDP协议的屏幕更新功能涉及多个步骤,包括接收RDP服务器发送的屏幕更新PDU(协议数据单元)、解析这些PDU以获取图像数据,以及将这些图像数据渲染到本地显示设备上。以下是一个简化的流程,指导你如何在C++中处理这一功能: 1. 监听和接收屏幕更新PDU 首先,你的…...

Tornado 是一个 Python 异步网络库和 web 框架
Tornado 是一个 Python 异步网络库和 web 框架,它最初由 FriendFeed 开发,后来被 Facebook 收购并开源。Tornado 因其非阻塞的 I/O 操作和优秀的性能而广受欢迎,特别是在需要处理大量并发连接的应用中。Tornado 的底层实现主要依赖于 Python …...

鹏哥C语言49---第5次作业:选择语句 if 和 switch
#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> //---------------------------------------------------------------------------------第 5 次作业:选择语句 if 和 switch //-----------------------------------------------------------------1.输…...
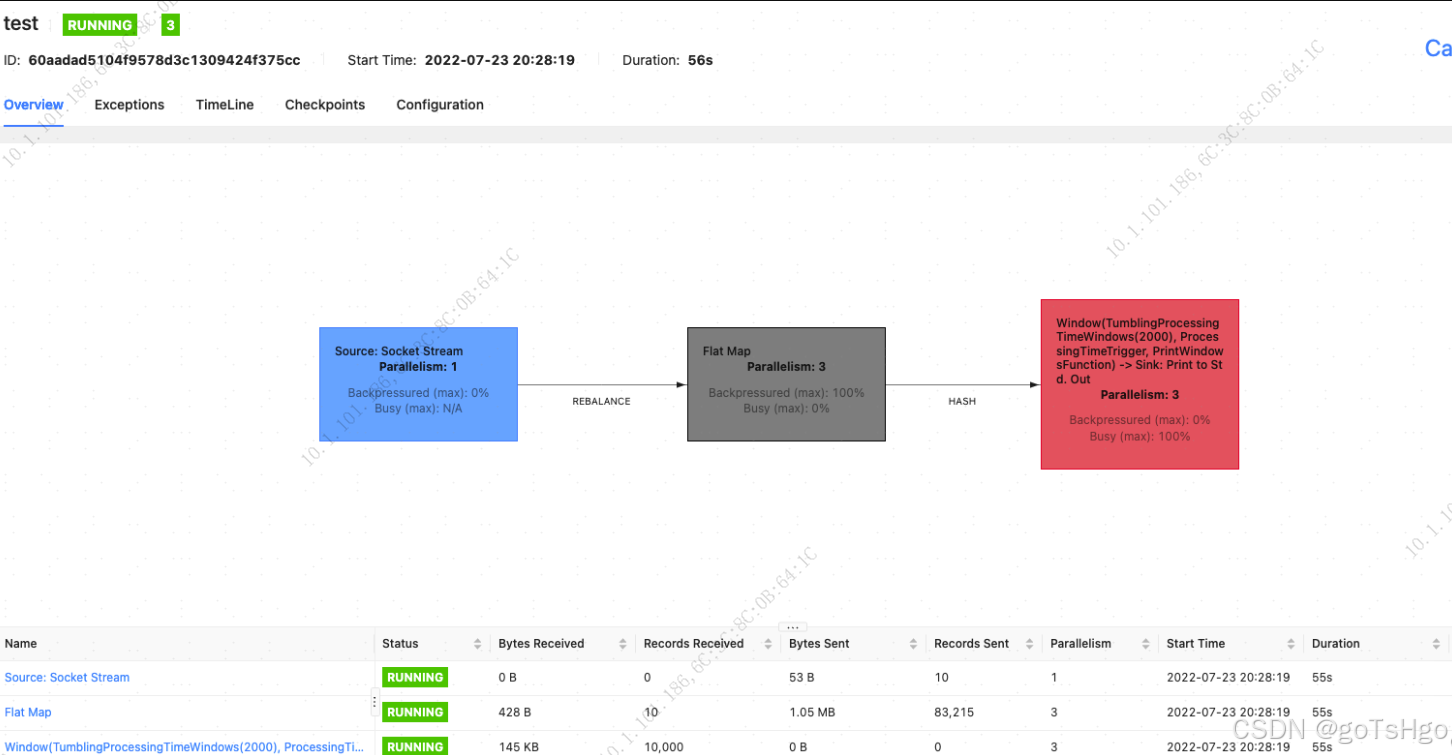
通过 Flink 的火焰图定位反压
在 Apache Flink 中,Web UI 提供了丰富的监控工具来帮助用户分析和解决作业性能问题,其中火焰图(Flame Graph)是用于分析反压问题的一个强有力的工具。反压可能是由于作业中某些算子处理速度过慢,或者资源耗尽导致的。…...

初识爬虫8
1.selenium的作用和工作原理 2. 使用selenium,完成web浏览器调用 # -*- coding: utf-8 -*- # 自动化测试工具,降低难度,性能也降低 from selenium import webdriverdriver webdriver.Edge()driver.get("https://www.itcast.cn/")…...

Unity SRP 可编程渲染管线的基本用法
可编程渲染管线使用教程 SRP 可以处理Canvas为Screen Space - Overlay的渲染 安装插件 首先进入package manager,下载Core RP Lib组件 创建渲染管线 编写渲染管线逻辑脚本 新建脚本取名为MPipeLine,该脚本用于实现渲染管线的处理逻辑 using Unity…...

AutoX.js向后端传输二进制数据
android的JavaScript自动化软件用过Hamibot和AutoX.js 不过在向后端传输二进制数据时都有些限制,不如浏览器前端那么自由。Hamibot的http按文档应该时能支持传字节数组,但是实际上应该还没有支持。AutoX.js的http也是这样,但是AutoX.js还支持…...

lvgl学习笔记--基础对象1
【LVGL学习笔记】(三)控件使用_学习_煜个头头-GitCode 开源社区 LVGL 基础对象|极客笔记 #include "../../../lv_examples.h"void lv_ex_obj_1(void) {lv_obj_t * obj1;obj1 lv_obj_create(lv_scr_act(), NULL);lv_obj_set_size(obj1, 100, …...

TDengine 在业务落地与架构改造中的应用实践!
前言 在物联网和大数据时代,时序数据的管理和分析变得至关重要。TDengine,作为一款专为时序数据设计的开源数据库,以其卓越的存储和查询效率,成为众多企业优化数据架构的优选。本文将分享我将TDengine成功应用于实际业务的经验&am…...

Python3爬虫教程-HTTP基本原理
HTTP基本原理 1,URL组成部分详解2,HTTP和HTTPS3,HTTP请求过程4,请求(Request)请求方法(Request Method)请求的网址(Request URL)请求头(Request H…...

竹云赋能“中国·贵州”全省统一移动应用平台建设,打造政务服务“新引擎”
近日,2024中国国际大数据产业博览会在贵州贵阳圆满落幕。会上,由贵州省政府办公厅牵头建设的“中国贵州”全省统一移动应用平台正式发布,聚焦民生办事、政务公开、政民互动、扁平高效、数据赋能五大模块,旨在打造公平普惠的服务平…...

【MySQL 04】数据类型
目录 1.数据类型分类 2.数值类型 2.1 tinyint 类型 2.2 bit类型 2.3 float类型 2.4decimal 3.字符串类型 3.1 char类型 3.2 varchar类型 4.日期和时间类型 6. enum和set类型 6.1.enum和set类型简介: 6.2.enum和set的一般使用方法 6.3.用数字的方式…...

夹耳式蓝牙耳机哪个牌子最好,教你如何不踩雷
近年来,夹耳式耳机备受众人喜爱。主要原因在于其不入耳的特性,既能保护听力健康,又能让人享受到极致的音乐体验。久而久之,人们对入耳式耳机反而感到不习惯了。然而,一些想要入手夹耳式耳机的小伙伴却犯了难࿰…...

亿发零售云解析:新零售破局与年轻群体消费趋势变化
近年来,随着数字化、智能化的快速发展,“新零售”概念逐渐成为商业领域的热门话题。相比传统零售,新零售通过线上与线下的深度融合,利用大数据、人工智能等技术,赋能消费者与品牌之间的互动。尤其在年轻消费群体中&…...

zabbix“专家坐诊”第257期问答
问题一 Q:zabbix5.0监控项里的键值,怎么设置变量值?{#ABC} {$ABC} 都识别不到变量。 A:可以参考一下这个。 问题二 Q:我想问一下用odbc创建监控项,生成了json格式,如何创建一个触发器去判断里面…...

【代码笔记】
1级 第一课——cout /* C01.L01.程序的基本结构、cout语句 杨彦彬 2024.9.23日作业 (2024.9.23做) */ //调用头文件 #include<bits/stdc.h> //使用标准名字空间 using namespace std; //代码主体 int main(){//输出数字cout<<25;cout<&…...

CentOS上使用Mosquitto实现Mqtt主题消息发布和订阅mqtt主题消息连同时间戳记录到文件
场景 CentOS上使用rpm离线安装Mosquitto(Linux上Mqtt协议调试工具)附资源下载: CentOS上使用rpm离线安装Mosquitto(Linux上Mqtt协议调试工具)附资源下载-CSDN博客 上面介绍了mosquitto的离线安装。 如果业务场景中需要订阅某mqtt主题的消息并将收到消息的时间以…...

COMTRADE 录波文件 | 可视化工具 | 电能质量查看软件
COMTRADE 录波文件 | 可视化工具 | 电能质量查看软件 主要功能介绍 支持 IEEE Std C37.111-1991/1999/2013 规范。读取 ASCII 或二进制 COMTRADE 文件。查看来自 COMTRADE 配置文件的模拟和数字通道列表。将图表导出为 SVG、BMP、JPEG 和 PNG 图形格式。将显示的观察结果以 C…...

【面试宝典】面试基础指导
目录 🍔 简历怎么写 🍔 ⾯试前针对项⽬撰写完成项⽬⽂档 🍔 ⾯试前 🍔 ⾯试中 4.1 投递简历当天没有收到⾯试邀约 4.2 讲解项⽬ 4.3 讲解知识 4.4 ⾯试中关于技术选型的演变 🍔 ⾯试后 🍔 小结 &…...

对比自行维护多个API与使用Taotoken聚合平台在运维复杂度上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个API与使用Taotoken聚合平台在运维复杂度上的差异 在构建基于大模型的应用时,开发者常常需要接入多个不…...

VK视频下载器:三步实现VKontakte视频永久保存的实用方案
VK视频下载器:三步实现VKontakte视频永久保存的实用方案 【免费下载链接】VK-Video-Downloader Скачивайте видео с сайта ВКонтакте в желаемом качестве 项目地址: https://gitcode.com/gh_mirrors/vk/VK-Video…...
模仿学习新思路:拆解ACT算法中的CVAE与Transformer如何联手生成平滑动作序列
模仿学习新范式:ACT算法中CVAE与Transformer的协同进化 在机器人精细操作领域,如何生成连贯平滑的动作序列一直是核心挑战。斯坦福ALOHA团队提出的动作分块算法ACT(Action Chunking with Transformers)通过融合条件变分自编码器&…...

STK Connectors接口函数全解析:如何用MATLAB脚本自动化你的航天仿真流程
STK Connectors接口函数全解析:如何用MATLAB脚本自动化你的航天仿真流程 航天仿真领域的工作者常常面临一个矛盾:STK提供了强大的轨道计算和场景可视化能力,但手动操作界面进行复杂任务时效率低下;MATLAB擅长处理复杂逻辑和批量计…...
第2小节:国内外技术参数差距)
0502光刻机破局 第五卷:EUV光源系统(S级 长期死磕突破)第2小节:国内外技术参数差距
第五卷:EUV光源系统(S级 长期死磕突破) 第2小节:国内外技术参数差距(全量化对标,ASML vs 国产,死磕数据) 前置硬核声明 本节100%量化、100%对标、100%无修饰,直接把 ASML…...

AB3DMOT性能优化技巧:10个提升跟踪精度的关键参数
AB3DMOT性能优化技巧:10个提升跟踪精度的关键参数 【免费下载链接】AB3DMOT (IROS 2020, ECCVW 2020) Official Python Implementation for "3D Multi-Object Tracking: A Baseline and New Evaluation Metrics" 项目地址: https://gitcode.com/gh_mirr…...

如何用jStat轻松实现电商数据分析和科学研究:JavaScript统计库的10个实际应用案例
如何用jStat轻松实现电商数据分析和科学研究:JavaScript统计库的10个实际应用案例 【免费下载链接】jstat JavaScript Statistical Library 项目地址: https://gitcode.com/gh_mirrors/js/jstat jStat是一个功能强大的JavaScript统计库,它为开发者…...

Polar SI9000实战:从叠层规划到阻抗计算,一次讲清四层板到八层板的阻抗控制核心
Polar SI9000实战:从叠层规划到阻抗计算,一次讲清四层板到八层板的阻抗控制核心 在高速PCB设计中,阻抗控制早已从"锦上添花"变成了"不可或缺"的基础要求。无论是USB3.0的90欧姆差分对,还是DDR4的40欧姆单端走…...

通过用量看板与账单追溯实现团队 AI 成本精细化管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板与账单追溯实现团队 AI 成本精细化管理 对于技术团队而言,将大模型能力集成到产品与研发流程中已成为常态…...

简历投了全石沉大海?实测3个免费AI简历神器,HR秒通过、面试翻3倍!
3个实测免费的AI简历神器,不用花钱、不用登录,直接让简历过ATS、获面试,应届生/职场人闭眼冲!简历优化本身就讲究精准度,尤其是ATS筛选逻辑,很多工具要么收费高,要么改完还是不贴合JD࿰…...