CVPR最牛图像评价算法!
目录
概述
一、论文思路
1.多任务学习框架:
2.视觉-语言对应关系:
3.动态损失权重:
4.模型优化和评估:
二、模型介绍
三、详细实现方法
1.图像编码器和语言编码器(Image Encoder and Language Encoder)
2.特征嵌入(Feature Embedding)
3.余弦相似度计算(Cosine Similarity Calculation)
4.联合概率计算(Joint Probability Calculation)
5.边际化(Marginalization)
6.损失函数(Loss Functions)
7.最终损失(Final Loss)
四、复现过程
一.代码结构
二.使用方法
环境设置
训练模型
测试模型
1.准备测试数据:
2.加载预训练模型:
3.运行测试脚本:
自己的思考:
可以改进的地方:
演示效果
核心逻辑
概述
这篇论文提出了一种基于视觉-语言对应关系的盲图像质量评估方法,通过多任务学习利用其他两个辅助任务的知识,来预测没有参考信息的图像质量。设计了一个多任务学习方案,通过计算所有标签组合并计算视觉-文本嵌入的余弦相似性来得到联合概率,从而推断出每个任务的预测结果,并设计了数据损失函数进行优化。
在三个任务——盲图像质量评估、场景分类和失真类型识别的综合实验中,结果表明所提出的方法能够从场景分类和失真类型识别任务中受益,并在多个图像质量评估数据集上超越了现有技术水平。
一、论文思路
这篇论文提出了一种基于视觉-语言对应关系的盲图像质量评估方法(BIQA),通过多任务学习方案来提升BIQA的性能。主要思路可以总结如下:
1.多任务学习框架:
作者提出了一种通用的多任务学习方案,将BIQA、场景分类和失真类型识别三个任务联合起来进行训练。通过这种方式,模型可以从其他任务中获取辅助知识,以提高BIQA的性能。
2.视觉-语言对应关系:
作者利用预训练的对比学习视觉-语言模型(CLIP)来获取图像和文本的嵌入表示。通过计算图像嵌入与所有候选文本嵌入之间的余弦相似度,可以得到三个任务的联合概率分布。
3.动态损失权重:
在多任务学习中,作者采用了一种简单而高效的方法来自动确定每个任务的损失权重。这种动态权重分配有助于模型在训练过程中更好地平衡不同任务的重要性。
4.模型优化和评估:
作者在多个BIQA数据集上进行了实验,结果表明所提出的方法在预测准确性、泛化能力和质量注释调整方面都优于现有的BIQA技术。
二、模型介绍
1.任务定义:除了盲图像质量评价BIQA任务外,还定义了场景分类(scene classification)和失真类型识别(distortion type identification)两个辅助任务。
2.数据准备:为现有的IQA数据集补充场景分类和失真类型标签,以便在多任务学习框架下联合训练。

3.视觉-语言表示:使用预训练的对比学习视觉-语言模型(CLIP)来获取图像和文本的嵌入表示。图像通过视觉编码器处理,文本通过语言编码器处理。
4.多任务学习:通过计算图像嵌入与所有候选文本嵌入之间的余弦相似度,得到三个任务的联合概率分布。然后,通过边际化这个联合分布,得到每个任务的边际概率,并进一步将离散的质量等级转换为连续的质量分数。
5.损失函数设计:为BIQA、场景分类和失真类型识别设计了三种类型的损失函数,包括排序损失、二元损失和多类损失,并通过动态权重分配来自动优化这些损失函数。
6.模型优化:在多个IQA数据集上联合优化整个方法,最小化加权损失函数的总和。损失权重根据训练动态自动调整。
7.训练过程:使用AdamW优化器,在多个数据集上训练模型,采用动态调整的学习率和余弦退火策略。

三、详细实现方法
1.图像编码器和语言编码器(Image Encoder and Language Encoder)

2.特征嵌入(Feature Embedding)

3.余弦相似度计算(Cosine Similarity Calculation)

4.联合概率计算(Joint Probability Calculation)

5.边际化(Marginalization)

6.损失函数(Loss Functions)

7.最终损失(Final Loss)

四、复现过程
一.代码结构

1.data文件夹:
这是示例图像文件,供demo代码测试时使用。
2.IQA_Database:
这是一个数据集文件夹,包含了不同的图像质量评估(IQA)数据库,例如 BID, ChallengeDB_release, CSIQ, databaserelase2, kadid10k, koniq-10k。这些数据库用于训练和评估图像质量评估模型。
3.BIQA_benchmark.py:
这是一个benchmark测试脚本,用于在不同的IQA数据库上测试模型的性能。
4.clip_biqa.png:
这是CLIP模型的结构框图。
5.demo.py 和 demo2.py:
这两个文件是演示脚本,展示了如何使用LIQE算法进行图像质量评估.
6.ImageDataset.py 和 ImageDataset2.py:
这些文件定义了图像数据集类,用于加载和处理图像数据,供模型训练和评估使用.
7.LIQE.pt:
这是LIQE模型的预训练权重文件。代码会加载这个文件以使用预训练的模型进行图像质量评估。
8.LIQE.py:
这是主要的LIQE算法实现文件,包含了LIQE算法的核心逻辑。
9.MNL_Loss.py:
这是定义了多类对数损失函数的文件,用于训练图像质量评估模型。
10.OutputSaver.py:
这个文件包含保存模型输出结果的函数,可能用于保存预测结果或中间计算结果。
11.README.md:
这是项目的说明文件,通常包含项目的介绍、安装和使用说明。
12.train_unique_clip_weight.py:
这是用于训练模型的脚本,包含了训练流程的实现。
13.utils.py:
这是包含各种实用函数的文件,可能用于数据预处理、图像操作等。
14.weight_methods.py:
这个文件可能包含了一些与权重处理相关的方法或工具函数。二.使用方法
环境设置
1.安装必要的库:torch 2.1.0,python3
2.下载和解压数据集:下载IQA数据库,并解压到 IQA_Database 文件夹下。
3.修改数据集路径(train_unique_clip_weight.py):


训练模型
1.准备训练数据:
确保 IQA_Database 文件夹中包含了所有需要的训练数据集。
可以根据 ImageDataset.py 和 ImageDataset2.py 文件中的定义来加载和处理图像数据。
2.运行训练脚本:
使用 train_unique_clip_weight.py 进行模型训练。该脚本定义了训练流程,包括数据加载、模型训练、损失计算等步骤。
参数解释:
–data_path:数据集的路径。
–epochs:训练的轮数。
–batch_size:每个批次的图像数量。
–lr:学习率。测试模型
1.准备测试数据:
确保测试图像文件(如 data/6898804586.jpg 和 data/I02_01_03.png)存在于 data 文件夹中。
2.加载预训练模型:
将 LIQE.pt 放置在合适的目录中,并确保代码能够正确加载预训练模型。
3.运行测试脚本:
使用 demo.py 或 demo2.py 进行模型测试,评估图像的质量。
自己的思考:
本文算法取得了很好的效果,且发表在cvpr上,除了算法本身的效果确实很好,而且结合了现在很火的多模态模型CLIP,将CLIP用到了IQA领域,并且结合多任务学习,方法上很新颖;再一个,作者的工作量也很大,为现有的六个质量评价数据集添加了两种标签。
可以改进的地方:
1.退化空间的进一步扩展:
尽管现有的退化空间已经非常大,但可以进一步研究如何通过更多类型和更复杂的退化来扩展这一空间,以更好地模拟真实世界中的复杂情况。2.模型架构优化:
当前的方法主要基于ResNet-50等常见架构,可以尝试使用更复杂或更适合BIQA任务的架构,如更深的神经网络或专门设计的模型,以进一步提高性能。3.对比学习中的噪声处理:
在对比学习过程中,可能存在一些噪声样本(如不同内容但相似质量的样本)。可以研究更有效的噪声处理方法,以进一步提升模型的鲁棒性。
演示效果
训练过程演示:
首先加载csv文件:

开始训练:

demo测试运行结果:
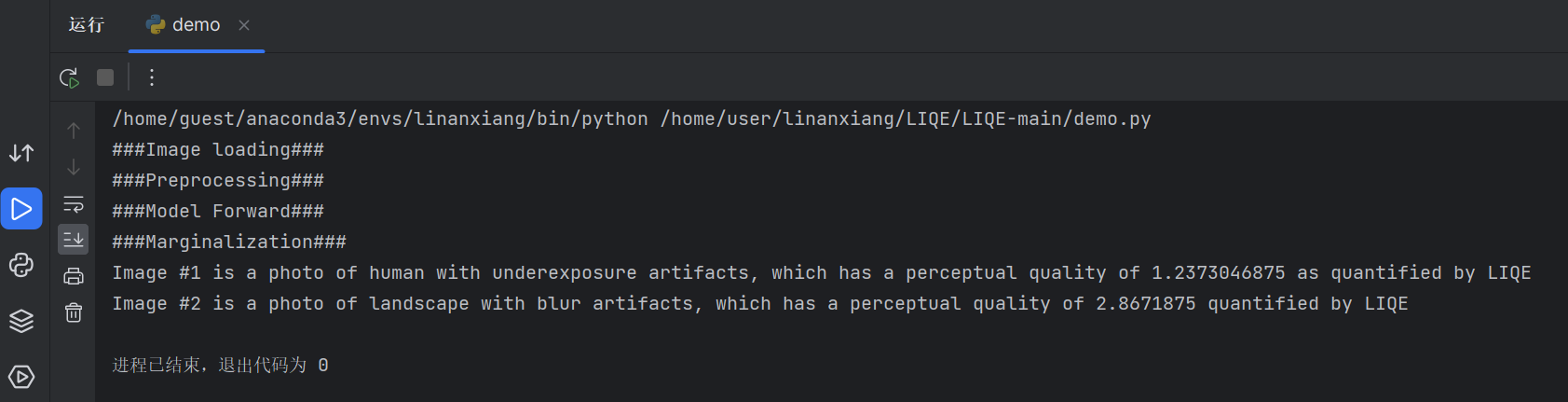
结果说明:
Image1经过LIQE算法后的质量评价结果:图像 #1 是一张曝光不足伪影的人体照片,其感知质量为 1.2373046875,由 LIQE 量化
Image2经过LIQE算法后的质量评价结果:图像 #2 是一张带有模糊伪像的风景照片,其感知质量为 2.8671875,由 LIQE 量化
核心逻辑
LIQE算法的核心逻辑:
class LIQE(nn.Module):
def __init__(self, ckpt, device):
super(LIQE, self).__init__()
self.model, preprocess = clip.load("ViT-B/32", device=device, jit=False)
checkpoint = torch.load(ckpt, map_location=device)
self.model.load_state_dict(checkpoint)
joint_texts = torch.cat(
[clip.tokenize(f"a photo of a {c} with {d} artifacts, which is of {q} quality") for q, c, d
in product(qualitys, scenes, dists_map)]).to(device)
with torch.no_grad():
self.text_features = self.model.encode_text(joint_texts)
self.text_features = self.text_features / self.text_features.norm(dim=1, keepdim=True)
self.step = 32
self.num_patch = 15
self.normalize = Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
self.device = device def forward(self, x):
x = x.to(self.device)
batch_size = x.size(0)
x = self.normalize(x)
x = x.unfold(2, 224, self.step).unfold(3, 224, self.step).permute(2, 3, 0, 1, 4, 5).reshape(-1, 3, 224, 224) sel_step = x.size(0) // self.num_patch
sel = torch.zeros(self.num_patch)
for i in range(self.num_patch):
sel[i] = sel_step * i
sel = sel.long()
x = x[sel, ...] image_features = self.model.encode_image(x) image_features = image_features / image_features.norm(dim=1, keepdim=True) logit_scale = self.model.logit_scale.exp()
logits_per_image = logit_scale * image_features @ self.text_features.t() logits_per_image = logits_per_image.view(batch_size, self.num_patch, -1)
logits_per_image = logits_per_image.mean(1)
logits_per_image = F.softmax(logits_per_image, dim=1) logits_per_image = logits_per_image.view(-1, len(qualitys), len(scenes), len(dists_map))
logits_quality = logits_per_image.sum(3).sum(2) similarity_scene = logits_per_image.sum(3).sum(1)
similarity_distortion = logits_per_image.sum(1).sum(1)
distortion_index = similarity_distortion.argmax(dim=1)
scene_index = similarity_scene.argmax(dim=1) scene = scenes[scene_index]
distortion = dists_map[distortion_index] quality = 1 * logits_quality[:, 0] + 2 * logits_quality[:, 1] + 3 * logits_quality[:, 2] + \
4 * logits_quality[:, 3] + 5 * logits_quality[:, 4] return quality, scene, distortionif __name__ == '__main__':
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
ckpt = './LIQE.pt'
liqe = LIQE(ckpt, device) x = torch.randn(1,3,512,512).to(device)
q, s, d = liqe(x)
感觉不错,点击我,立即使用
相关文章:
CVPR最牛图像评价算法!
本文所涉及所有资源均在 传知代码平台可获取。 目录 概述 一、论文思路 1.多任务学习框架: 2.视觉-语言对应关系: 3.动态损失权重: 4.模型优化和评估: 二、模型介绍 三、详细实现方法 1.图像编码器和语言编码器(Image…...
Spring源码-从源码层面讲解传播特性
传播特性:service:REQUIRED,dao:REQUIRED 两个都是required使用的是同一个事务,正常情况,在service提交commit <tx:advice id"myAdvice" transaction-manager"transactionManager"><tx:attributes&…...

Rust调用tree-sitter解析C语言
文章目录 一、Rust 调用 tree-sitter 解析 C 语言代码1. 设置 Rust 项目2. 添加 tree-sitter 依赖3. 编写 Rust 代码4. 运行程序5. 编译出错 二、解决步骤1. 添加 tree-sitter 构建依赖2. 添加 tree-sitter-c 源代码3. 修改 build.rs 以编译 tree-sitter-c 库4. 修改 Cargo.tom…...

奇瑞汽车—经纬恒润 供应链技术共创交流日 成功举办
2024年9月12日,奇瑞汽车—经纬恒润技术交流日在安徽省芜湖市奇瑞总部成功举办。此次盛会标志着经纬恒润与奇瑞汽车再次携手,深入探索汽车智能化新技术的前沿趋势,共同开启面向未来的价值服务与产品新篇章。 面对全球汽车智能化浪潮与产业变革…...
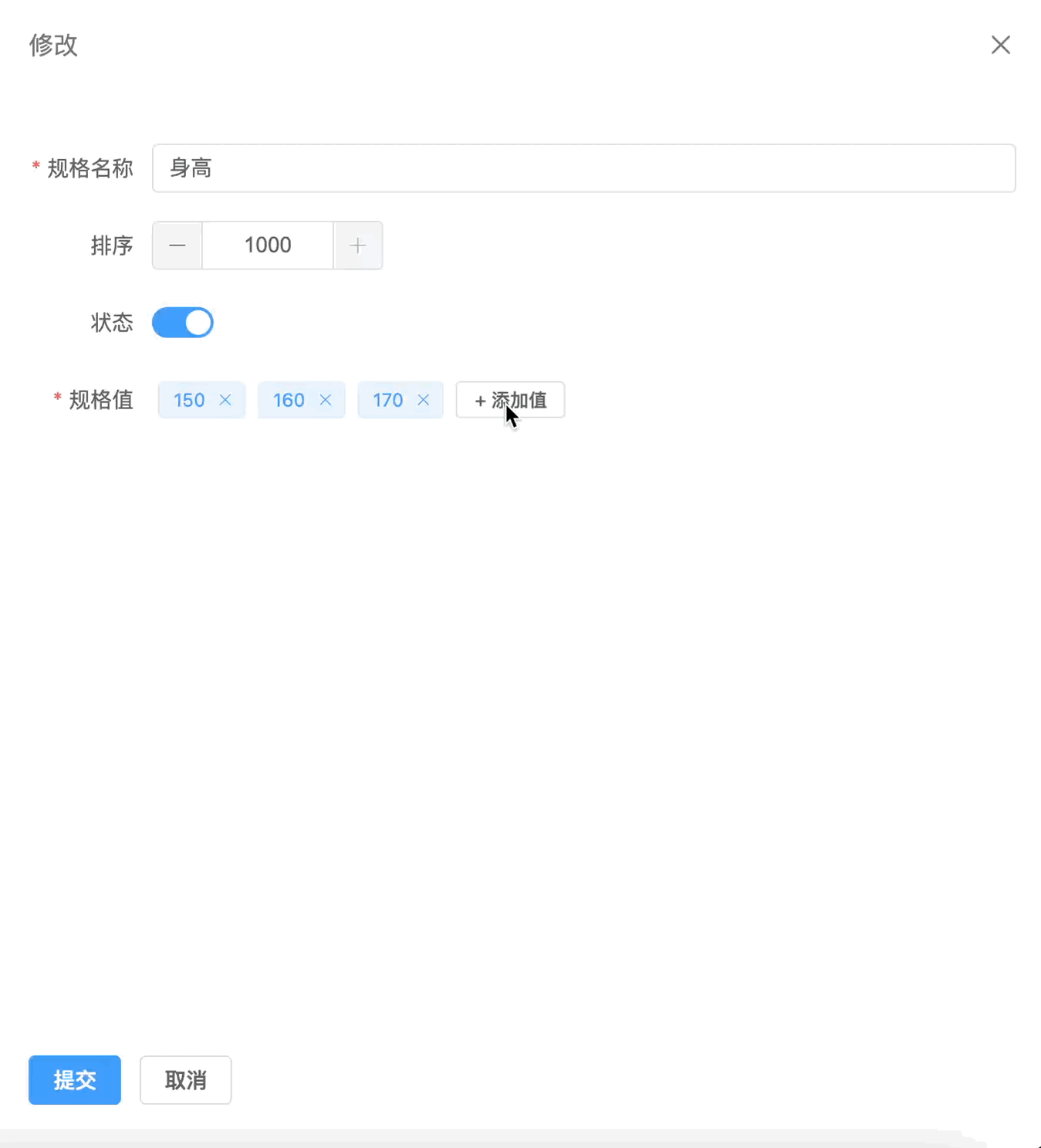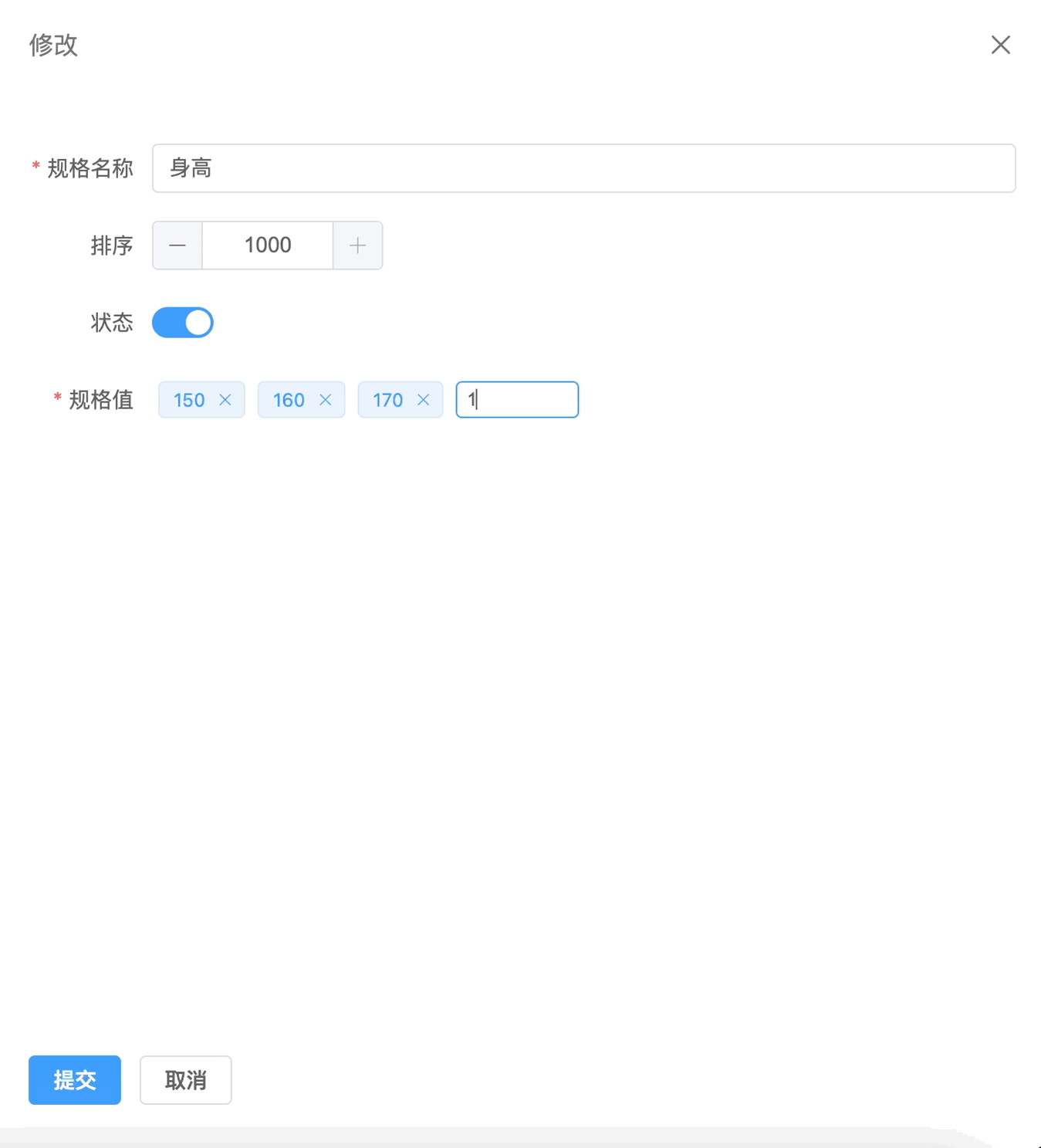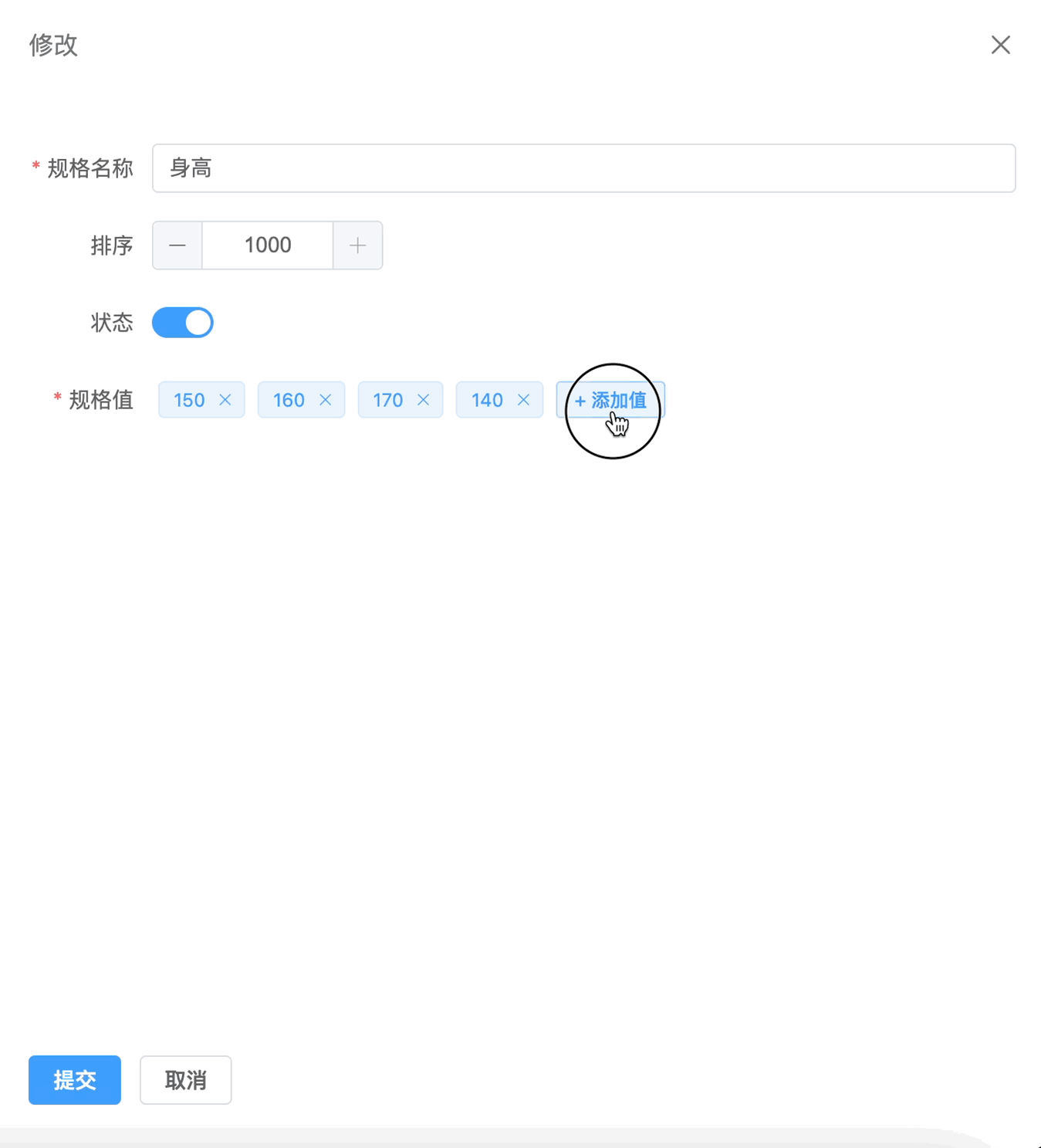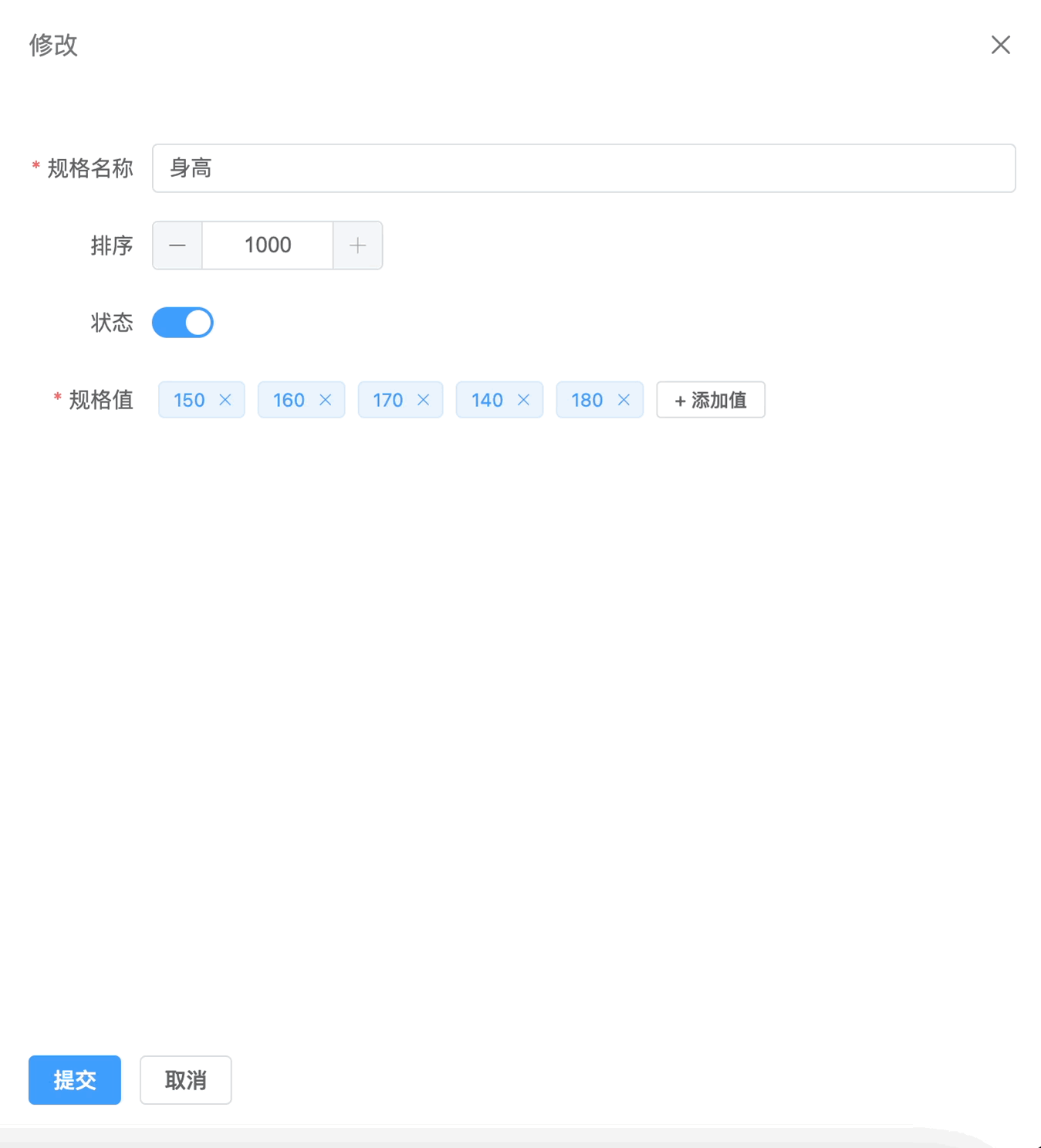
vue3 TagInput 实现
效果 要实现类似于下面这种效果 大致原理 其实是很简单的,我们可以利用 element-plus 组件库里的 el-tag 组件来实现 这里我们可以将其抽离成一个公共的组件,那么现在有一个问题就是通讯问题 这里我们可以利用父子组件之间的通讯,利用 v-model 来实现,父组件传值,子组…...

mysql中的json查询
首先来构造数据 查询department里面name等于研发部的数据 查询语句跟普通的sql语句差不多,也就是字段名要用到path表达式 select * from user u where u.department->$.name 研发部 模糊查询 select * from user u where u.department->$.name like %研发%…...
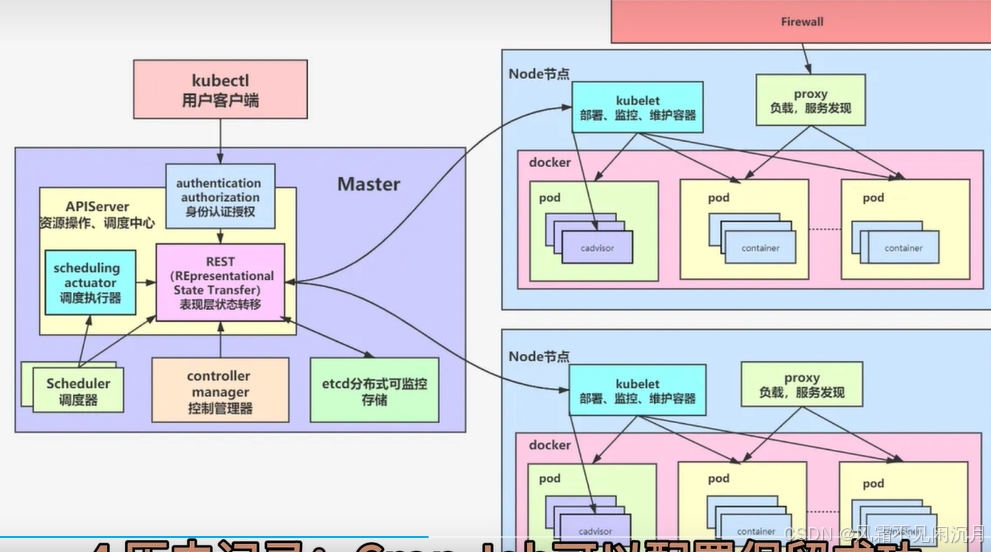
Etcd权限认证管理
1 查看是否开启权限认证 ctl auth status 2 开启权限认证 ctl auth enable。开启后每一条命令都要加上用户 --userroot:root(root默认最高权限) 3 创建其他用户 ctl user add user1 --user用户名:密码 4 创建角色 ctl role add testR --user 5 为角色添加权限 ctl role g…...

图文组合商标部分驳回后优化后初审通过!
这几天以前有个企业的商标初审下来了,以前是加了图形个别部分没有通过初审,后面是把图形去掉重新用文字申请下来初审。 图形与文字同时申请,会分别审查有一个元素过不了,整体就会过不了,所以平常就会建议分开申请注册商…...

【最新华为OD机试E卷-支持在线评测】爱吃蟠桃的孙悟空(100分)多语言题解-(Python/C/JavaScript/Java/Cpp)
🍭 大家好这里是春秋招笔试突围 ,一枚热爱算法的程序员 💻 ACM金牌🏅️团队 | 大厂实习经历 | 多年算法竞赛经历 ✨ 本系列打算持续跟新华为OD-E/D卷的多语言AC题解 🧩 大部分包含 Python / C / Javascript / Java / Cpp 多语言代码 👏 感谢大家的订阅➕ 和 喜欢�…...
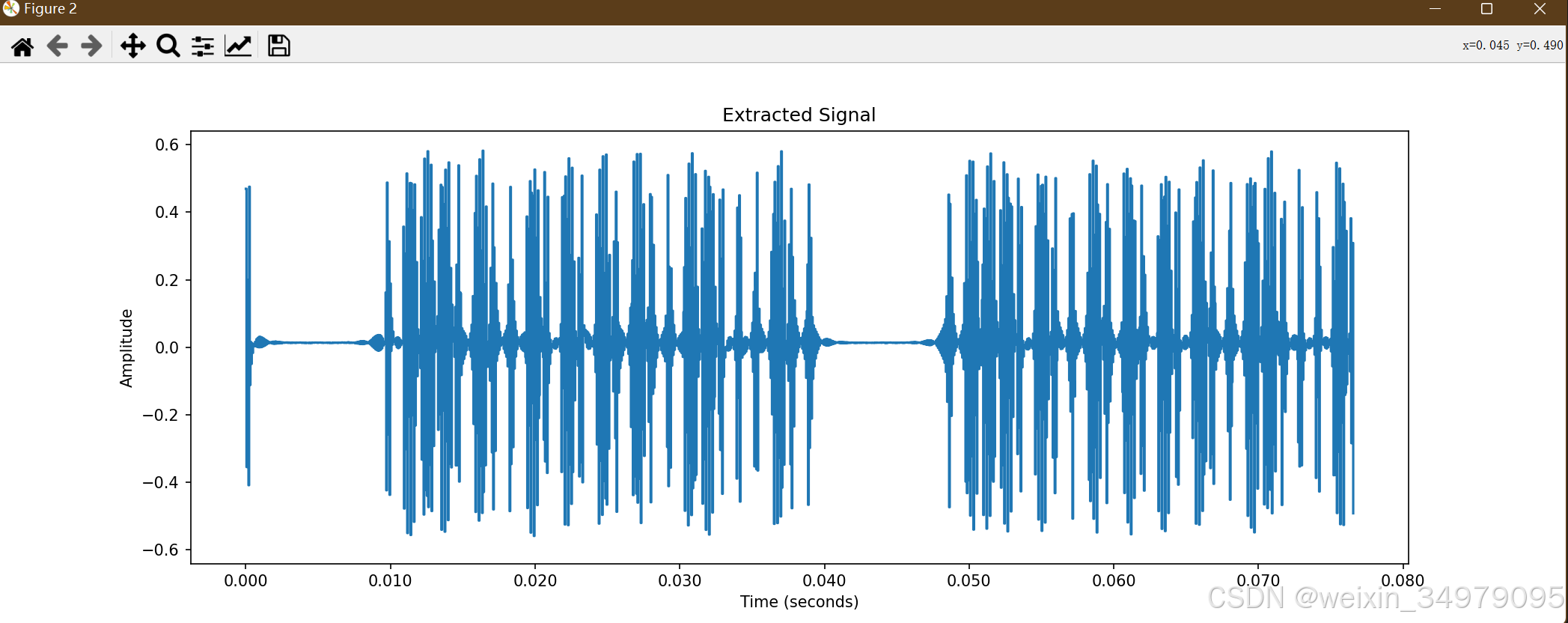
BUUCTF [SCTF2019]电单车详解两种方法(python实现绝对原创)
使用audacity打开,发现是一段PT2242 信号 PT2242信号 有长有短,短的为0,长的为1化出来 这应该是截获电动车钥匙发射出的锁车信号 0 01110100101010100110 0010 0前四位为同步码0 。。。中间这20位为01110100101010100110为地址码0010为功…...
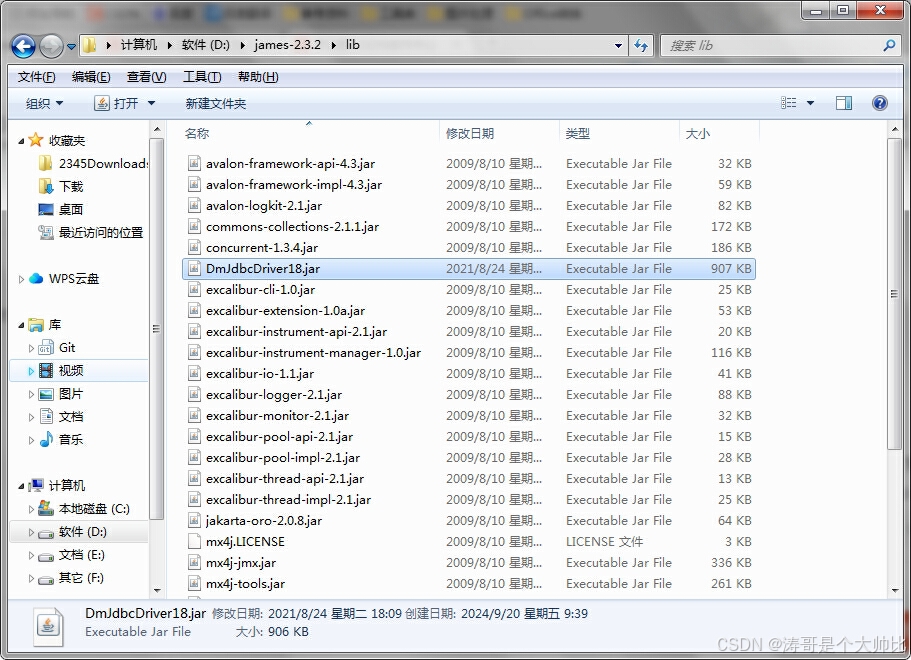
Apache James配置连接达梦数据库
项目场景: Apache James配置连接达梦数据库,其他配置中不存在的数据库也可参考此方案。 配置步骤 1、把需要的jar包导入到James 把DmJdbcDriver18.jar复制到下面lib目录下 james-2.3.2\lib 2、 修改连接配置 james-2.3.2\apps\james\SAR-INF\confi…...

Java实现栈
一、栈Stack 1.1 概念 一种特殊的线性表,只允许在固定的一段进行插入和删除元素操作。进行数据的插入和删除操作的一段称为栈顶,另一端称为栈低。栈中的元素遵循后进先出 LIFO(Last In First Out)的原则。 进栈 出栈 举例:在word中…...

数据结构—栈
栈 概念 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。 压栈:栈…...

服务设计原则介绍
在Java或任何软件开发中,设计服务时遵循一些核心原则是非常重要的,这些原则不仅有助于构建高质量、可维护的软件系统,还能提高系统的可扩展性和可重用性。以下是一些关键的服务设计原则: 单一职责原则(SingleResponsib…...

【Qualcomm】高通SNPE框架的使用 | 原始模型转换为量化的DLC文件 | 在Android的DSP端运行模型
目录 ① 激活snpe环境 ② 设置环境变量 ③ 模型转换 ④ run 首先,默认SNPE工具已经下载并且Setup相关工作均已完成。同时,拥有原始模型文件,本文使用的模型文件为SNPE 框架示例的inception_v3_2016_08_28_frozen.pb文件。image_file_list…...

爬虫的流程
爬虫的流程 获取网页提取信息保存数据自动化程序能爬怎样的数据 获取网页 获取网页就是获取网页的源代码,源代码里包含了网页的部分有用信息,所以只要把源代码获取下来,就可以从中提取想要的信息浏览器访问网页的本质:浏览器向服…...

Git之如何删除Untracked文件(六十八)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【…...

k8s集群自动化管理
项目地址 https://github.com/TimeBye/kubeadm-ha准备安装包 # 离线安装环境 curl -LO https://oss.choerodon.com.cn/kubeadm-ha/kubeadm-ha-base-amd64.tar # 集群运行所需的镜像 curl -LO https://oss.choerodon.com.cn/kubeadm-ha/kubernetes-1.30.2-images-amd64.tgz # …...
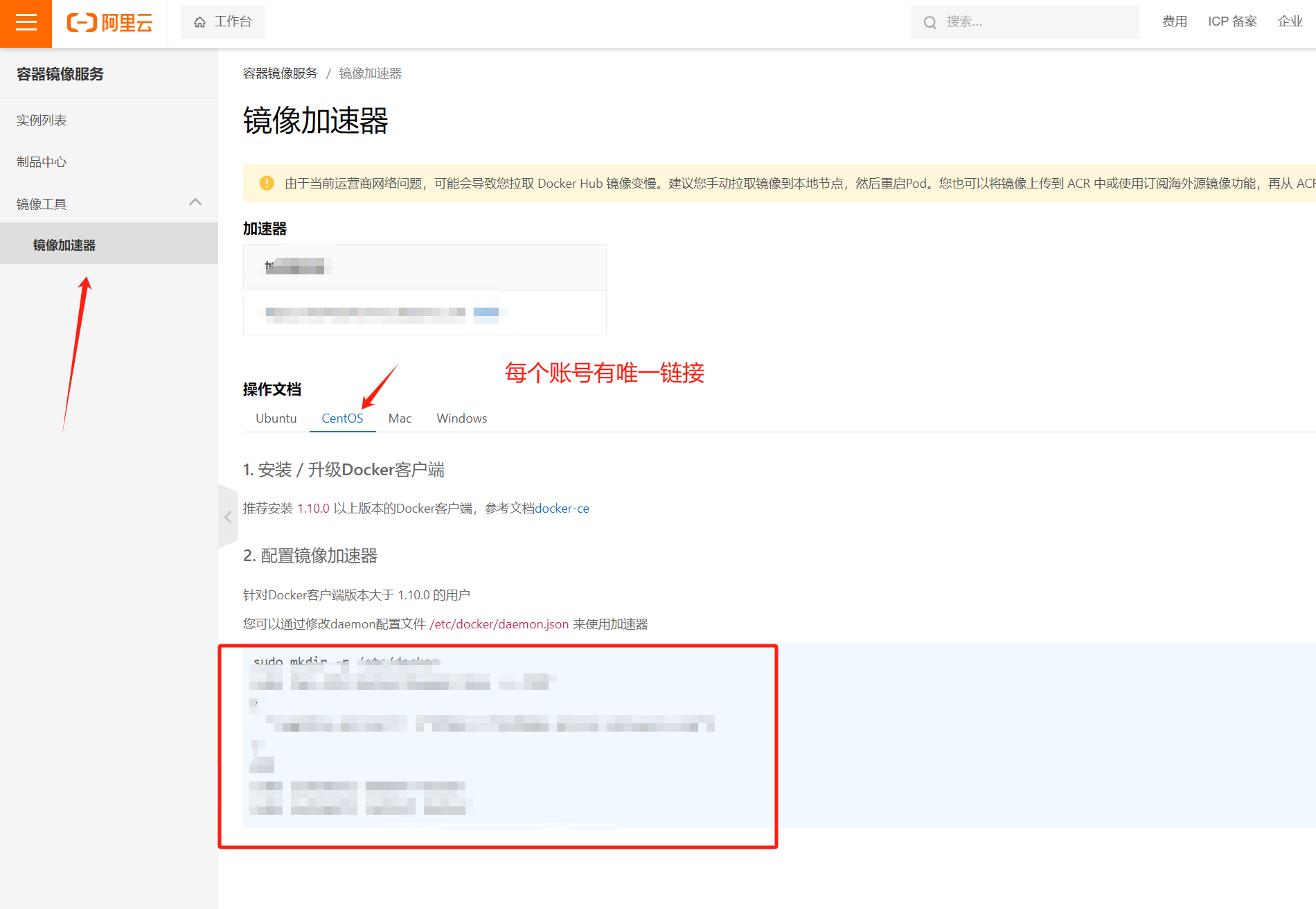
yum库 docker的小白安装教程(附部分问题及其解决方案)
yum库 首先我们安装yum 首先在控制台执行下列语句 首先切换到root用户,假如已经是了就不用打下面的语句 su root #使用国内的镜像,不执行直接安装yum是国外的,那个有问题 curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.al…...
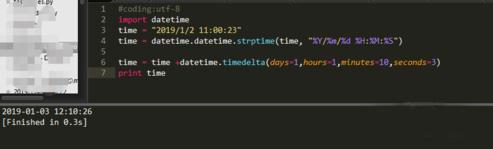
python如何实现日期加减
首先通过import datetime,导入日期处理库。 然后把日期转化成datetime标准格式,使用datetime.datetime.strptime()方法将字符串格式的时间转化为标准格式。 其中"%Y/%m/%d %H:%M:%S"为time字符串的时间格式:Y为年,m为月…...

5G 网络优化工程师是骗局吗?从业15年资深老工程师实话实说
01 5G 网优岗位,本身真实靠谱很多人一刷到 5G 网络优化工程师这个岗位,第一反应都是犹豫、怀疑:这到底是不是收割小白的骗局?我在通信行业深耕整整 15 年,也拿到过华为高级工程师认证,今天以业内老兵的身份…...

为什么你的Linux桌面还缺少一个触手可及的OCR助手?
为什么你的Linux桌面还缺少一个触手可及的OCR助手? 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库…...

Awesome-LLM-Apps:大语言模型应用开发实战指南与开源项目宝库
1. 项目概述:一个大型语言模型应用的开源宝库如果你最近在折腾大语言模型,想找点现成的、能跑起来的应用来学习或者直接部署,那你大概率在GitHub上见过这个项目。awesome-llm-apps, 一个由开发者Shubham Saboo维护的仓库ÿ…...

基于Emissaries框架构建多AI智能体协作系统:从原理到实践
1. 项目概述:一个基于AI的智能体协作框架最近在开源社区里,一个名为muinyc/emissaries的项目引起了我的注意。乍一看这个名字,你可能会联想到“使者”或“特使”,这其实非常贴切地揭示了它的核心定位。简单来说,Emissa…...

C#上位机与三菱PLC通信实战:从零构建GX Works3仿真平台
1. 为什么需要搭建GX Works3仿真平台 第一次接触三菱PLC开发的朋友们,可能都有这样的困惑:手头没有实体PLC设备,怎么测试自己写的控制程序?买一台FX5U PLC动辄几千元,对个人开发者来说成本太高。这时候仿真平台就成了最…...

如何彻底移除Windows Defender:13项核心服务完整卸载与系统性能优化终极指南
如何彻底移除Windows Defender:13项核心服务完整卸载与系统性能优化终极指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitco…...

200万像素GC2145摄像头怎么玩?手把手教你用AiPi-Cam-D200开发板快速搭建无线图传
200万像素GC2145摄像头实战指南:零代码玩转AiPi-Cam-D200无线图传 当你拆开AiPi-Cam-D200开发板的包装,看到那块小巧的GC2145摄像头时,可能既兴奋又忐忑——这个看起来像玩具的设备,真能实现专业级的无线图传吗?作为创…...

终极HiveWE魔兽地图编辑器:如何用现代化工具打造专业级游戏地图
终极HiveWE魔兽地图编辑器:如何用现代化工具打造专业级游戏地图 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和繁琐的操作而烦恼吗࿱…...

企业内网开发环境通过Taotoken安全调用外部大模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网开发环境通过Taotoken安全调用外部大模型API 对于许多企业开发团队而言,在内部研发流程中引入大模型能力已成为…...

Nacos高可用集群部署实战:从架构设计到生产运维全解析
1. 项目概述:为什么Nacos集群部署是微服务架构的“定海神针”在微服务架构的实践中,服务注册与发现、配置管理是两大基石。Nacos作为Spring Cloud Alibaba生态的核心组件,集这两大功能于一身,其稳定性和可用性直接决定了整个微服务…...