《CUDA编程》2.CUDA中的线程组织
0 来自GPU的hello world
在visua studio 中新建一个CUDA runtime项目,然后把kernel.cu中的代码删掉,输入以下代码
#include"cuda_runtime.h"
#include"device_launch_parameters.h"#include<stdio.h>__global__ void hello_from_gpu(void) {printf("Hello from GPU!\n");
}int main(void) {hello_from_gpu<<<1, 1>>>();cudaDeviceSynchronize();return 0;
}
hello_from_gpu<<<1, 1>>>();该条代码可能会飘红标错,可以不用管
输出结果如下

如果创建了CUDA runtime项目依旧无法直接运行,请确保是否正确安装了CUDA,或者在项目设置中添加以下三个cuda文件路径


1 只有主机函数的CUDA程序
CUDA程序的编译器驱动(compilerdriver)nvcc支持编译纯粹的C++代码,所以可以写一个C++代码,然后修改后缀为.cu,然后使用nvcc去编译(nvcc会把C++的部分交给C++编译器去编译,然后其余部分则自己编译)
请打开一个记事本,输入以下代码,然后保存为后缀为.cu的文件

#include<stdio.h>int main(void)
{printf("Hello world!");return 0;
}
在该文件目录下打开终端,输入nvcc hello.cu -o hello,会把hello.cu文件,使用nvcc将其编译为一个hello的.exe文件,输入.\hello,输出结果如下

2 使用核函数的CUDA程序
上一个例子只是使用nvcc编译器进行编译,但是并没有调用GPU,下面将介绍如何在GPU中的输出Hello world!,在《CUDA编程》1.GPU硬件与CUDA环境搭建中已经介绍了,GPU必须在CPU的控制之下,才能进行运算,所以一个典型的、简单的CUDA程序的结构具有下面的形式:

hsot对device的调用是通过核函数(kernel function)来实现的。
CUDA中的核函数与C++中的函数必须被限定词__global__ 修饰,前后是双下划线,核函数的返回类型必须是void,void和__global__次序随意,下面是一个核函数。
__global__ void hello_from_gpu(void) {printf("Hello from GPU!\n");
}
2.1 分析hello world代码
请关注main()函数部分
#include"cuda_runtime.h"
#include"device_launch_parameters.h"#include<stdio.h>__global__ void hello_from_gpu(void) {printf("Hello from GPU!\n");
}int main(void) {hello_from_gpu<<<1, 1>>>();cudaDeviceSynchronize();return 0;
}
2.1.1 核函数的调用格式
①hello_from_gpu<<<1, 1>>>();与C++格式函数hello_from_gpu();相比,多一个一对三尖括号,里面还有用逗号隔开的两个数字。因为一个GPU中有多个核心,即可以支持多线程(thread),所以host在调用一个核函数时,必须指明需要在设备中指派多少个线程
核函数中的线程常组织为若干线程块(thread_block):三括号中的第一个数字可以看作线程块的个数,第二个数字可以看作每个线程块中的线程数。
一个核函数的全部线程块构成一个网格(grid),而线程块的个数就记为网格大小(grid_size)。每个线程块中含有同样数目的线程,该数目称为线程块大小(block_size),则
核函数中总的线程数 = Grid_size x Block_size
所以三尖括号意义是<<<Grid_size , Block_size>>>,所以,在上述程序中,主机只指派了设备的一个线程,网格大小和线程块大小都是1,即1 x 1 = 1
② 核函数中也支持printf(),但只支持<stdio.h>,不支持C++的
③cudaDeviceSynchronize();是调用了一个CUDA的runtime的函数API,去掉这个函数就打印不出字符串,作用是同步主机与设备,所以能够促使缓冲区刷新,后面会详解该函数
3 CUDA中的线程组织
3.1 核函数中使用多个线程
一个GPU往往有几千个计算核心,而总的线程数必须至少等于计算核心数时才有可能充分利用GPU中的全部计算资源。
实际上,总的线程数大于计算核心数时才能更充分地利用GPU中的计算资源,因为这会让计算和内存访问之间及不同的计算之间合理地重叠,从而减小计算核心空闲的时间。
假设线程我们要使用8个线程进行运算,代码如下
#include"cuda_runtime.h"
#include"device_launch_parameters.h"#include<stdio.h>__global__ void hello_from_gpu(void) {printf("Hello from GPU!\n");
}int main(void) {hello_from_gpu<<<2, 4>>>();cudaDeviceSynchronize();return 0;
}
输出结果如下,会输出8行 Hello from GPU!:

核函数中代码的执行方式是“单指令-多线程”,即每一个线程都执行同一串指令。
3.2 使用线程索引
每个线程在核函数中都有一个唯一的身份标识,代码中使用了grid_size 、block_size,所以可以使用这两个参数来表明每个线程。
#include"cuda_runtime.h"
#include"device_launch_parameters.h"#include<stdio.h>__global__ void hello_from_gpu(void) {const int tid = threadIdx.x;//线程idconst int bid = blockIdx.x;//线程块idprintf("Hello from GPU! tid:%d bid:%d\n",tid,bid);
}int main(void) {hello_from_gpu<<<2, 4>>>();cudaDeviceSynchronize();return 0;
}
输出结果如下,便可以看出每一句输出来自于拿哪一个线程块的哪一个线程:

注意:每个线程块的计算是相互独立的,所以有时候会是bid:1先执行完,有时会是bid:0先执行完
3.3 推广至多维网络
blockIdx 和 threadIdx 是类型为 uint3 的变量,即结构如下:

即可以用结构体dim3定义“多维”的网格和线程块,例如我们要定义一个2 x 2 x 1的grid和2 x 3 x 1的block,结果如下:
而在核函数中的线程组织图如下所示:

grid的形状为2 x 2 x 1,所以有4个block;
block的形状是3 x 2 x 1,所以每个block中有6个线程
一个线程块中的线程还可以细分为不同的线程束(threadwarp),目前所有的GPU架构都是32,所以,一个线程束就是连续的32个线程。即一个线程块中第0到第31个线程属于第0个线程束,第32到第63个线程属于第1个线程束,依此类推。

修改代码如下:
#include"cuda_runtime.h"
#include"device_launch_parameters.h"#include<stdio.h>__global__ void hello_from_gpu(void) {const int tidx = threadIdx.x;const int tidy = threadIdx.y;const int bid = blockIdx.x;printf("Hello from tid:(%d,%d) bid:%d\n",tidx,tidy,bid);
}int main(void) {hello_from_gpu<<<2, 4>>>();cudaDeviceSynchronize();return 0;
}
输出结果是:

3.4 网格与线程块大小的限制
CUDA中对能够定义的网格大小和线程块大小做了限制。
- 网格大小在x、y和z这3个方向的最大允许值分别为2^31-1、65535和65535。
- 线程块大小在x、y和z这3个方向的最大允许值分别为1024、1024和64。
- 线程块总的大小,即blockDim.x、blockDim.y和blockDim.z的乘积不能大于1024,即不管如何定义,一个线程块最多只能有1024个线程。
4 CUDA中的头文件
在使用nvcc编译器驱动编译.cu文件时,将自动包含必要的CUDA头文件,如<cuda.h>和<cuda_runtime.h>,且为<cuda.h>包含了<stdlib.h>,但在visual studio里编写时,需要手动添加
5 用nvcc编译CUDA程序时,计算能力问题
CUDA的编译器驱动(compilerdriver)nvcc先将全部源代码分离为host代码和device代码。主机代码完整地支持C++语法,但设备代码只部分地支持C++。
nvcc先将设备代码编译为PTX伪汇编代码,再将PTX代码编译为二进制的cubin目标代码。
在将源代码编译为PTX代码时,需要用选项-arch=compute_XY指定一个虚拟架构的计算能力;在将PTX代码编译为cubin代码时,需要用选项-code=sm_ZW指定一个真实架构的计算能力
真实架构的计算能力必须等于或者大于虚拟架构的计算能力
所以

可以编译,但下面的设置则不能编译,因为虚拟架构计算能力小于真实架构

本文的程序在编译时并没有通过编译选项指定计算能力。这是因为编译器有一个默认的计算能力。

设置计算能力的必要性:
- 兼容性:不同的 GPU 架构有不同的指令集和硬件特性。通过设置计算能力,你可以确保生成的代码能够在特定的 GPU 上运行。如果不设置计算能力,nvcc 默认可能会生成针对最新架构的代码,这可能导致代码在旧的 GPU 上无法运行。
- 性能优化:不同的 GPU 架构有不同的优化策略。设置计算能力可以确保 nvcc 生成的代码针对特定的 GPU 进行优化,从而提高性能。
以下是一些常见的计算能力及其对应的 GPU 架构:

相关文章:
《CUDA编程》2.CUDA中的线程组织
0 来自GPU的hello world 在visua studio 中新建一个CUDA runtime项目,然后把kernel.cu中的代码删掉,输入以下代码 #include"cuda_runtime.h" #include"device_launch_parameters.h"#include<stdio.h>__global__ void hello_…...
)
学习篇 | Dockerized GitLab 安装使用(简单实操版)
1. 详细步骤 1.1 安装启动 postgresql 服务 docker pull sameersbn/postgresql:14-20230628docker run --name gitlab-postgresql -d \--env DB_NAMEgitlabhq_production \--env DB_USERgitlab --env DB_PASSpassword \--env DB_EXTENSIONpg_trgm,btree_gist \--volume /srv/…...
Linux服务器磁盘扩容
文章目录 扩容挂载 扩容 [rootserver8 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 1T 0 disk ├─vda1 252:1 0 1G 0 par…...

Redis的一些数据类型(一)
(一)数据类型 我们说redis是key value键值对的方式存储数据,key是字符串,而value是一些数据结构,那今天就来说一下value存储的数据。 我们数据结构包含,String,hash,list,set和zest但…...

论文复现:考虑电网交互的风电、光伏与电池互补调度运行(MATLAB-Yalmip-Cplex全代码)
论文复现:考虑电网交互的风电、光伏与电池储能互补调度运行(MATLAB-Yalmip-Cplex全代码) 针对风电、光伏与电化学储能电站互补运行的问题,已有大量通过启发式算法寻优的案例,但工程上更注重实用性和普适性。Yalmip工具箱则是一种基于MATLAB平台的优化软件工具箱,被广泛应用…...

HTTP 协议介绍
基本介绍: HTTP(Hyper Text Transfer Protocol): 全称超文本传输协议,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。 HTTP 是一种应用层协议,是基…...

解决windows上VMware的ubuntu虚拟机不能拷贝和共享
困扰多时的VMware虚拟机不能复制拷贝和不能看到共享文件夹的问题,终于解决了~ 首先确定你已经开启了复制拷贝和共享文件夹,并且发现不好用。。。 按照下面方式解决这个问题。 1,删除当前的vmware tools。 sudo apt-get remove --purge ope…...

Python+rust会是一个强大的组合吗?
今天想和大家讨论一个在技术圈子里越来越火的话题——Python和Rust的组合。 不少程序员都开始探索这两个语言的结合,希望能借助Python的简洁和Rust的高性能,来打造出既易用又强大的软件。 那么,这对CP(编程组合)真的…...

引用和指针的区别
引用(reference)和指针(pointer)都是 C 中用来间接访问内存中对象的机制,但它们有一些重要的区别。以下是它们在语法、用法和特性上的详细区别。 下面从7个方面来详细说明引用和指针的区别 1. 定义与语法区别 引用&…...
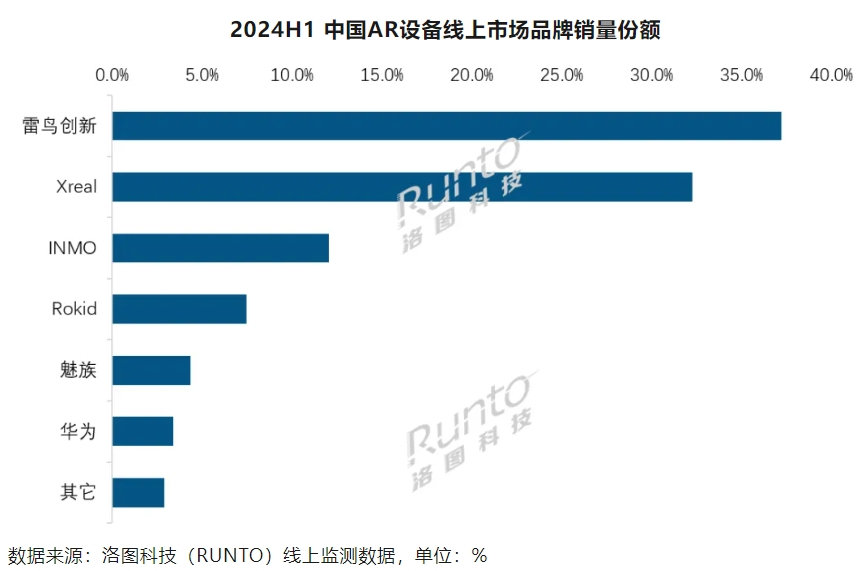
内容生态短缺,Rokid AR眼镜面临市场淘汰赛
AR是未来,但在技术路径难突破、生态系统难建设,且巨头纷纷下场的背景下,Rokid能坚持到黎明吗? 转载:科技新知 原创 作者丨王思原 编辑丨蕨影 苹果Vision Pro的成功量产和发售,以及热门游戏《黑神话》等在A…...

【论文阅读】StoryMaker | 更全面的人物一致性开源工作
文章目录 1 Motivation2 背景 相关工作 Related work3 Method 方法4 效果 1 Motivation 背景是 Tuning-free personalized image generation methods无微调的个性化图像生成方式在维持脸部一致性上取得了显著性的成功。这里我不是很了解 然而,在多个场景中缺乏整…...

读构建可扩展分布式系统:方法与实践14流处理系统
1. 流处理系统 1.1. 时间就是金钱 1.1.1. 从数据中提取有价值的知识和获得洞见的速度越快,就能越快地响应系统所观察的世界的变化 1.1.2. 信用卡欺诈检测 1.1.3. 网络安全中异常网络流量的捕获 1.1.4. 在支持GPS的驾驶应用程序中进行的实时路线规划 1.1.5. 社交…...
)
C++第2课——取余运算符的应用、浮点型和字符型(含视频讲解)
文章目录 1、课程笔记2、课程视频 1、课程笔记 /* #include<iostream> using namespace std; int main(){//cout<<"hello,world!";//运算符的优先级 () * / % -// 3/2 1...1 3%21 5%32 3%53 -3%2-1 3%-21//cout<<6/4%2;//int 向下取整6…...

SQL常用技巧总结
查询优化基本准则 1、ORACLE 的解析器按照从右到左的顺序处理 FROM 子句中的表名,因此 FROM 子句中写在最后的表(基础表 driving table)将被最先处理。 在FROM 子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。 例如: 表 T…...
)
AJAX(简介以及一些用法)
AJAX 1. 简介 什么是 Ajax Ajax 的全称是 Asynchronous JavaScript And XML (异步 JavaScript 和 XML )我们可以理解为:在网页中 利用 XMLHttpRequest 对象和服务器进行数据交互的方式就是 Ajax ,它可以帮助我们轻松实现网页…...

美畅物联丨GB/T 28181系列之TCP/UDP被动模式和TCP主动模式
GB/T 28181《安全防范视频监控联网系统信息传输、交换、控制技术要求》作为我国安防领域的重要标准,为视频监控系统的建设提供了全面的技术指导和规范。该标准详细规定了视频监控系统的信息传输、交换和控制技术要求,在视频流传输方面,GB/T 2…...

机器学习之实战篇——图像压缩(K-means聚类算法)
机器学习之实战篇——图像压缩(K-means聚类算法) 0. 文章传送1.实验任务2.实验思想3.实验过程 0. 文章传送 机器学习之监督学习(一)线性回归、多项式回归、算法优化[巨详细笔记] 机器学习之监督学习(二)二元逻辑回归 …...

轴承介绍以及使用
轴承(Bearing)是在机械传动过程中起固定、旋转和减小载荷摩擦系数的部件。也可以说,当其它机件在轴上彼此产生相对运动时,用来降低运动力传递过程中的摩擦系数和保持转轴中心位置固定的机件。 轴承是当代机械设备中一种举足轻重的…...

【JAVA】算法笔记
一、ArrayList ArrayList类是一个可以动态变化的数组,与普通数组的区别就是它没有固定的长度。 ArrayList<String> arrList new ArrayList<String>(); arrList.add("吐泡泡"); System.out.println(arrList.get(0)); arrList.set(0,"J…...

Gnu Radio抓取WiFi信号,流程图中模块功能
模块流程如图所示: GNURadio中抓取WiFi信号的流程图中各个模块的功能: UHD: USRP Source: 使用此模块配置USRP硬件进行信号采集。设置频率、增益、采样率等参数。Complex to Mag^2: 将复数IQ数据转换为幅度的平方。Delay…...

终极指南:Windows平台APK安装器如何让安卓应用无缝运行
终极指南:Windows平台APK安装器如何让安卓应用无缝运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows电脑上运行安卓应用曾经是一个技术难题&am…...

Agent OS:AI智能体开发的操作系统级解决方案
1. 项目概述:一个为AI智能体而生的操作系统最近在AI智能体开发圈子里,一个名为“Agent OS”的项目热度持续攀升。它来自Rivet.dev团队,定位非常清晰:一个专为构建、运行和管理AI智能体而设计的操作系统。如果你正在尝试将大语言模…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...

多智能体强化学习环境PettingZoo:从核心概念到工程实践
1. 项目概述:从零理解PettingZoo如果你正在寻找一个能让你快速上手、高效构建多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)实验环境的工具,那么Farama Foundation旗下的PettingZoo项目,绝对是你绕不开…...

用Ruby实现RISC-V模拟器:从指令集架构到交互式教学工具
1. 项目概述:一个为Ruby语言量身打造的RISC-V模拟器如果你是一名Ruby开发者,或者对RISC-V这个新兴的指令集架构充满好奇,那么你很可能已经听说过RuriOSS/rurima这个名字。简单来说,这是一个用Ruby语言实现的RISC-V指令集模拟器。但…...

基于容器技术的在线代码沙盒:架构设计与安全实践
1. 项目概述:一个开箱即用的在线代码运行沙盒最近在折腾一些需要快速验证代码片段、或者给团队做技术分享的场景,我发现一个痛点:环境配置太麻烦了。你想让新人跑个Python脚本,他可能得先装Python、配环境变量、装依赖库ÿ…...

基于Go的轻量级自托管IM系统OpenWhisp部署与架构解析
1. 项目概述:一个开源的即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个轻量级的即时通讯模块。市面上成熟的方案不少,但要么是SaaS服务,数据不在自己手里,心里不踏实;要么是像Rocket.Chat、Matt…...

开源大语言模型实战指南:从部署到微调的全流程解析
1. 项目概述:一个为开源大语言模型而生的知识库最近在折腾各种开源大语言模型(LLM)的朋友,估计都遇到过类似的烦恼:模型太多了,从Meta的Llama系列、微软的Phi,到国内的一众优秀模型,…...

基于vLLM与OpenAI API的LLM生产部署框架实战指南
1. 项目概述:一个面向生产环境的LLM部署框架最近在折腾大语言模型(LLM)的部署,发现了一个挺有意思的项目:run-llama/llama_deploy。这名字乍一看,可能会让人以为它只是用来部署Meta的Llama系列模型的&#…...

GPT-4 API交互式实验场:开发者如何自建安全可控的Playground
1. 项目概述:一个面向开发者的GPT-4交互式实验场如果你是一名开发者,或者对大型语言模型(LLM)的应用开发感兴趣,那么你很可能已经不止一次地思考过:如何能更高效、更直观地测试GPT-4的API能力?如…...