【机器学习】过拟合与欠拟合——如何优化模型性能
【机器学习】过拟合与欠拟合——如何优化模型性能
1. 引言
在机器学习中,模型的表现不仅依赖于算法的选择,还依赖于模型对数据的拟合情况。过拟合(Overfitting)和欠拟合(Underfitting)是模型训练过程中常见的问题。过拟合意味着模型过于复杂,以至于“记住”了训练数据中的噪声,而欠拟合则意味着模型过于简单,无法捕捉到数据的主要特征。本文将深入探讨过拟合与欠拟合的定义、表现、原因及常见的解决方案,帮助你优化模型性能。

2. 什么是过拟合?
2.1 定义
过拟合是指模型在训练集上表现得非常好,但在测试集或新数据上表现较差。这是因为模型在训练数据上过于复杂,捕捉了数据中的噪声和异常值,而这些并不代表数据的实际分布。
2.2 过拟合的表现:
- 训练集上的误差极低:模型在训练集上表现完美。
- 测试集上的误差较高:模型无法泛化到未见的数据。
- 高方差:模型对训练数据敏感,对测试数据不够鲁棒。
2.3 过拟合的原因:
- 模型过于复杂:参数过多,导致模型能够记住每一个训练数据点。
- 训练数据量过少:数据不足以代表真实情况。
- 特征过多且无正则化:大量不相关的特征增加了模型复杂度。
示例:决策树模型过拟合
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 训练复杂的决策树模型
model = DecisionTreeClassifier(max_depth=None) # 不限制深度,可能导致过拟合
model.fit(X_train, y_train)# 评估模型
train_accuracy = accuracy_score(y_train, model.predict(X_train))
test_accuracy = accuracy_score(y_test, model.predict(X_test))
print(f"训练集准确率: {train_accuracy}")
print(f"测试集准确率: {test_accuracy}")
3. 什么是欠拟合?
3.1 定义
欠拟合是指模型过于简单,无法捕捉到训练数据中的模式。这种情况下,模型的训练误差和测试误差都较高,说明模型既没有学好训练数据,也无法在测试集上表现良好。
3.2 欠拟合的表现:
- 训练集和测试集误差都较高:模型对训练数据和测试数据都不能很好地拟合。
- 高偏差:模型对数据的基本结构理解不到位,表现为过于简化。
3.3 欠拟合的原因:
- 模型过于简单:模型结构无法捕捉数据中的复杂关系。
- 训练时间不足:模型还没有充分学习到数据中的模式。
- 特征不足:输入特征太少,导致模型无法充分学习。
示例:线性回归模型欠拟合
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 加载数据
X, y = load_boston(return_X_y=True)# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 训练简单的线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)# 评估模型
train_error = mean_squared_error(y_train, model.predict(X_train))
test_error = mean_squared_error(y_test, model.predict(X_test))
print(f"训练集均方误差: {train_error}")
print(f"测试集均方误差: {test_error}")

4. 如何避免过拟合?
4.1 减少模型复杂度
通过限制模型的复杂度,可以减少模型过拟合的风险。例如,决策树的深度越大,模型越容易过拟合。
示例:限制决策树深度
model = DecisionTreeClassifier(max_depth=3) # 限制树的最大深度
model.fit(X_train, y_train)
4.2 使用正则化
正则化是在损失函数中添加惩罚项,限制模型的复杂度,从而避免过拟合。常见的正则化方法有 L1 正则化(Lasso)和 L2 正则化(Ridge)。
示例:使用 Ridge 回归进行正则化
from sklearn.linear_model import Ridge# 使用 Ridge 回归
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
4.3 数据扩充
如果训练数据不足,可以通过数据扩充来增加数据量,从而减少过拟合的风险。对于图像数据,数据扩充的方法包括翻转、旋转、缩放等。
4.4 使用交叉验证
交叉验证通过将数据集划分为多个子集来验证模型的性能,避免模型在特定数据上过拟合。
示例:K 折交叉验证
from sklearn.model_selection import cross_val_score# 使用 5 折交叉验证
scores = cross_val_score(model, X, y, cv=5)
print(f"交叉验证得分: {scores}")

5. 如何避免欠拟合?
5.1 增加模型复杂度
通过增加模型的复杂度,可以帮助模型更好地拟合数据。例如,在神经网络中增加隐藏层或神经元的数量。
示例:增加决策树的深度
model = DecisionTreeClassifier(max_depth=10) # 增加树的深度
model.fit(X_train, y_train)
5.2 训练更长时间
在深度学习中,欠拟合通常意味着模型还没有充分学习。可以通过增加训练的轮数来改善欠拟合。
5.3 增加特征
通过引入更多有意义的特征,可以帮助模型更好地学习数据中的模式。例如,特征工程中的特征生成步骤可以生成多项式或交互特征。
示例:生成多项式特征
from sklearn.preprocessing import PolynomialFeatures# 生成二次多项式特征
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X_train)model.fit(X_poly, y_train)
5.4 使用非线性模型
如果数据存在复杂的非线性关系,线性模型容易欠拟合。可以选择非线性模型(如随机森林、支持向量机)来提升模型表现。
6. 过拟合与欠拟合的权衡
6.1 偏差-方差权衡
优化模型性能的过程中,我们通常要在**偏差(bias)和方差(variance)**之间找到平衡。偏差过高意味着欠拟合,方差过高则意味着过拟合。通过选择合适的模型复杂度,可以在偏差和方差之间取得良好的权衡。
6.2 学习曲线
通过绘制学习曲线,可以帮助我们观察模型是否出现了过拟合或欠拟合。训练误差和验证误差趋于一致且较低时,说明模型表现良好。

7. 案例:避免房价预测中的过拟合与欠拟合
数据清洗与预处理
# 假设数据已经加载到 data 中
X = data.drop('price', axis=1)
y = data['price']# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
训练 Ridge 回归模型避免过拟合
from sklearn.linear_model import Ridge# 使用正则化的 Ridge 回归
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)# 评估模型
train_error = mean_squared_error(y_train, model.predict(X_train))
test_error = mean_squared_error(y_test, model.predict(X_test))
print(f"训练集均方误差: {train_error}")
print(f"测试集均方误差: {test_error}")
8. 总结
过拟合和欠拟合是机器学习模型中的常见问题。过拟合通常由模型过于复杂或数据不足引起,而欠拟合则是由于模型过于简单或数据特征不足。通过使用正则化、交叉验证、增加数据量和调整模型复杂度等方法,可以有效地优化模型性能。在实际应用中,找到适当的模型复杂度并在偏差和方差之间平衡,是提升机器学习模型性能的关键。
9. 参考资料
- 《Deep Learning》 by Ian Goodfellow
- Coursera 深度学习课程
- TensorFlow 官方文档
使用机器学习分析csdn热榜
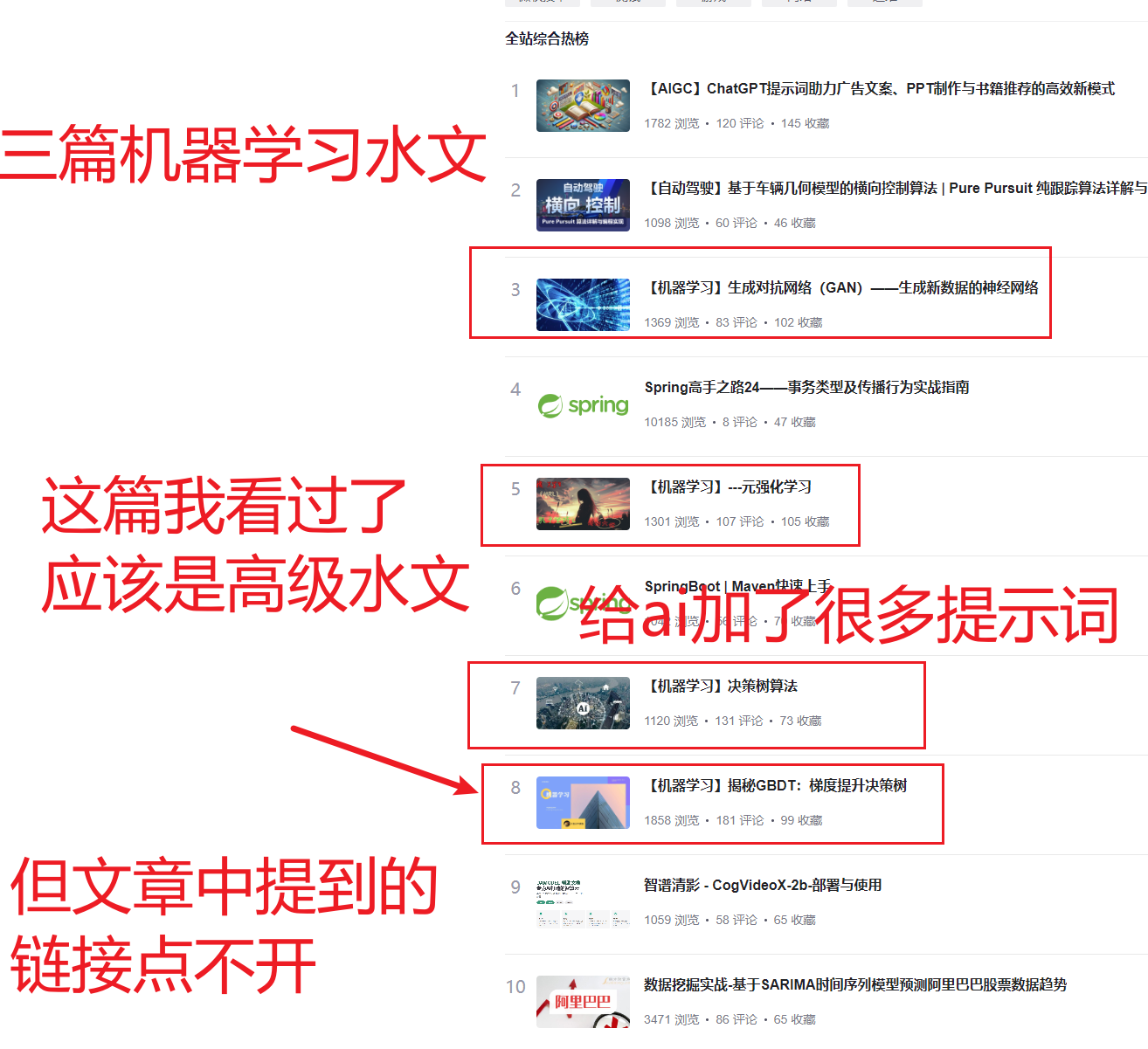
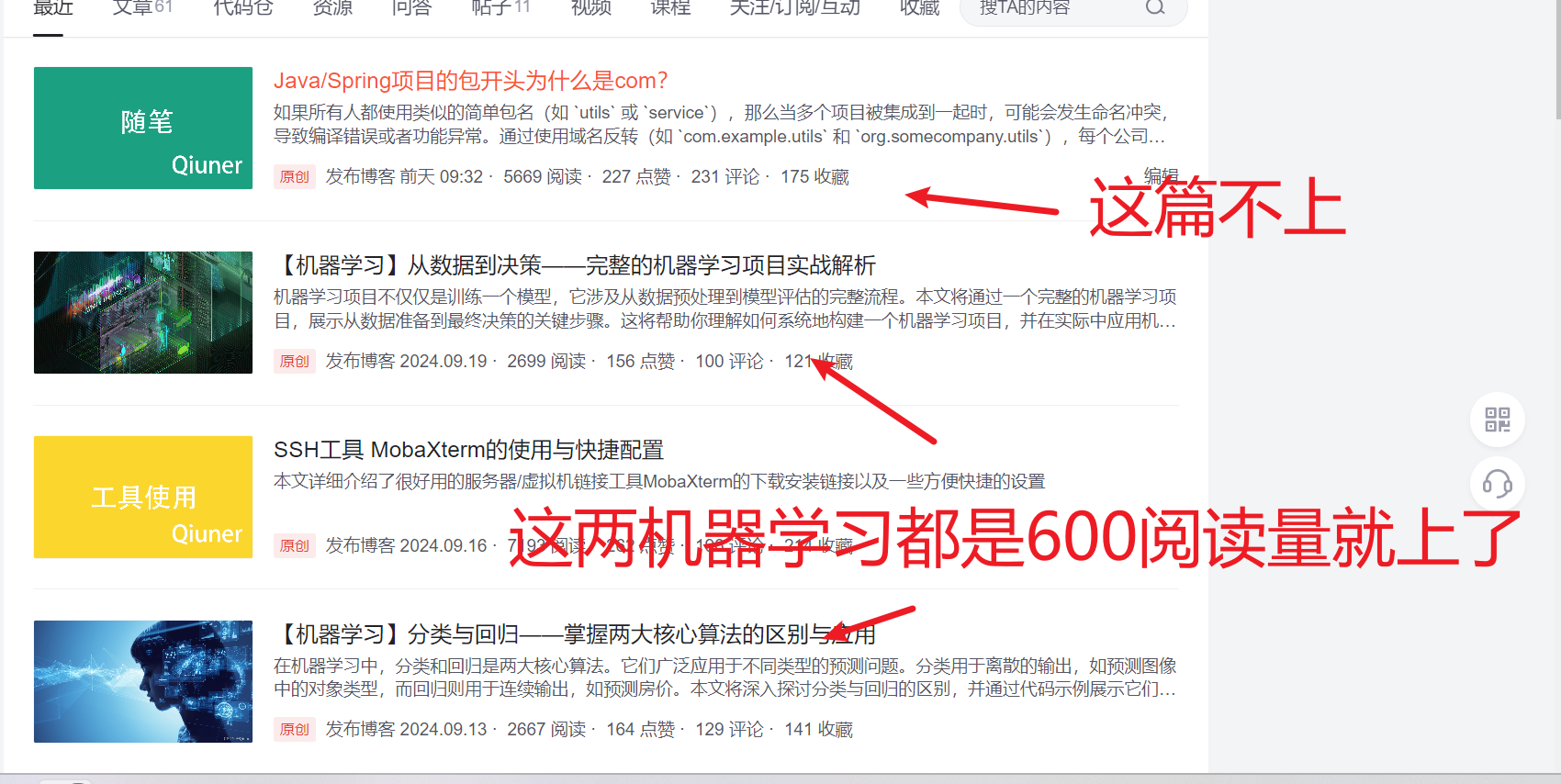
- 也不知道为什么这个热榜对机器学习这么看重,只要你的文章标题是机器学习那就很容易上热榜,但如果不是,那即使你文章流量啊、点赞、评论数上热榜的要求就像翻了倍一样…
- 机器学习和csdn热榜的爹一样
- 就像官方在鼓励你写机器学习水文一样

你好,我是Qiuner. 为帮助别人少走弯路而写博客 这是我的 github https://github.com/Qiuner⭐ gitee https://gitee.com/Qiuner 🌹
如果本篇文章帮到了你 不妨点个赞吧~ 我会很高兴的 😄 (^ ~ ^) 。想看更多 那就点个关注吧 我会尽力带来有趣的内容 😎。
代码都在github或gitee上,如有需要可以去上面自行下载。记得给我点星星哦😍
如果你遇到了问题,自己没法解决,可以去我掘金评论区问。私信看不完,CSDN评论区可能会漏看 掘金账号 https://juejin.cn/user/1942157160101860 掘金账号
更多专栏:
📊 一图读懂系列
📝 一文读懂系列
⚽ Uniapp
🌟 持续更新
🤩 Vue项目实战
🚀 JavaWeb
🎨 设计模式
📡 计算机网络
🎯 人生经验
🔍 软件测试
掘金账号 CSDN账号
感谢订阅专栏 三连文章
相关文章:
【机器学习】过拟合与欠拟合——如何优化模型性能
【机器学习】过拟合与欠拟合——如何优化模型性能 1. 引言 在机器学习中,模型的表现不仅依赖于算法的选择,还依赖于模型对数据的拟合情况。过拟合(Overfitting)和欠拟合(Underfitting)是模型训练过程中常…...

二进制日志gtid模式
# --skip-gtids,使用mysqlbinlog截取时添加该参数,会执行已经执行的事务 mysqlbinlog --skip-gtids --include-gtidsa56fdfdc-7699-11ef-8f40-000c297f81d5:40 /data/binlog/mysql-bin.000003 > gtid.sql # --skip-gtids,使用mysqlbinlog截…...

华硕主板开启TPM 2.0
安装Windows11系统,需要打开TPM 安装 Windows 11 的方法 电脑健康状况检查应用验证最低系统要求 在电脑上启用 TPM 2.0 查看主板型号 winr msinfo32 查看 tpm 进入Advanced Mode(F7) 选择Security,进入Secure Boot,我…...

Linux 一键部署Mysql 8.0.37
mysql 前言 MySQL 是一个基于 SQL(Structured Query Language)的数据库系统,SQL 是一种用于访问和管理数据库的标准语言。MySQL 以其高性能、稳定性和易用性而闻名,它被广泛应用于各种场景,包括: Web 应用程序:许多动态网站和内容管理系统(如 WordPress)使用 MySQL 存…...

Elasticsearch可视化工具ElasticHD
目录 介绍 ElasticHD应用程序页面 安装 基本用法 独立可执行文件 ES版本支持 SQL特性支持: 超越SQL功能支持: SQL的用法 Docker快速入门: 下载地址 介绍 ElasticHD是ElasticSearch可视化管理工具。它不需要任何软件。它在您的Web浏览器中工作,允许您随时随地管理…...

Chrome截取网页全屏
1.使用Chrome开发者工具 Chrome自带的开发者工具,可以进行网页整页截图, 首先打开你想截图的网页, 然后按下 F12,调出开发者工具, 接着按Ctrl Shift P。 紧接着输入指令 capture, 它会提示有三个选项,如…...

Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
文章汇总 本文的作者针对了提示学习的结构设计进行了分析,发现了一些规律: 1)固定的类名令牌为模型的优化提供了强正则化,减少了由噪声样本引起的梯度。 2)从多样化和通用的web数据中学习到的强大的预训练图像文本嵌入为图像分类提供了强大…...

C++ 折叠表达式
C 折叠表达式(Fold Expression)是在 C17 引入的一种语法,用于简化与可变参数模板的操作。折叠表达式的作用是对参数包(parameter pack)进行递归处理。 折叠表达式有四种类型: 一元左折叠 (Unary Left Fol…...
双控开关接入NVBoard
导入NVBoard git仓库:https://github.com/NJU-ProjectN/nvboard 按照ysyx手册的要求,初始化NVBoard项目。 由于GitHub在国外,可能会超时无响应: 解决方案是修改代理。 当前的运行环境是VM VirtualBox虚拟机,网卡是…...

聊一聊软件系统性能测试的重要性
目录 性能测试的分类 为什么要进行性能测试呢? 性能测试曲线对比参数 虚拟用户数 vs 时间: 响应时间 vs 虚拟用户数: 吞吐量 vs 虚拟用户数: 错误率 vs 虚拟用户数: 资源使用情况 vs 时间: 组合视图 上图曲线图关键点介绍 性能测试的重要性主要体现在以下…...

双十一有哪些好物值得入手?五款超值数码好物分享!
在如今这个科技飞速发展的时代,数码产品已经成为我们生活中不可或缺的一部分。双十一作为一年一度的购物狂欢节,为我们提供了一个绝佳的机会,可以以更优惠的价格入手心仪的数码好物。下面就为大家分享五款超值数码好物,让你的生活…...

uniapp监听滚动实现顶部透明度变化
效果如图: 实现思路: 1、使用onPageScroll监听页面滚动,改变导航条的透明度; 2、关于顶部图片的高度: 如果是小程序:使用getMenuButtonBoundingClientRect获取胶囊顶部距离和胶囊高度; 如果…...

Humanoid 3D Charactor_P08_Federica
3D模型(人形装备)女孩 “P08_联邦” 内容仅为3D人物模型。 图片中的背景和家具不包括在内。 由Blender制作 包括: 1. 人形机器人3D模型和材质。 2. “Unity-chan!”着色器。 性别:女 装备:人形 皮肤网格:4个骨骼权重 多边形: 20000~40000 纹理分辨率:2K纹理 混合形状:…...

TikTok直播推流不精准该怎么办?跟IP有关系吗?
TikTok,这款风靡全球的短视频社交平台,其直播功能已成为众多创作者与品牌宣传的利器。然而,不少用户却遭遇了直播推流不精准的难题,这直接影响到直播的曝光和互动效果。那么,面对这一问题,我们该如何应对&a…...

Docker Registry API best practice 【Docker Registry API 最佳实践】
文章目录 1. 安装 docker2. 配置 docker4. 配置域名解析5. 部署 registry6. Registry API 管理7. 批量清理镜像8. 其他 👋 这篇文章内容:实现shell 脚本批量清理docker registry的镜像。 🔔:你可以在这里阅读:https:/…...

便捷点餐:Spring Boot 点餐系统
第三章 系统分析 3.1 系统设计目标 网上点餐系统主要是为了用户方便对美食信息、美食评价、美食资讯等信息进行查询,也是为了更好的让管理员进行更好存储所有数据信息及快速方便的检索功能,对系统的各个模块是通过许多今天的发达系统做出合理的分析来确定…...

研一上课计划2024/9/23有感
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、学位课1.应用数理统计(学3 开卷考试)2.最优化方法(学3 开卷考试)3.新中特(学2 三千五百字的品读…...
【H2O2|全栈】关于CSS(6)CSS基础(五)
目录 CSS基础知识 前言 准备工作 网页项目规范 创建项目 布局 补充一部分属性 outline border-radius 预告和回顾 后话 CSS基础知识 前言 本系列博客将分享层叠样式表(CSS)有关的知识点。 本期博客主要分享的是网页项目规范,ou…...

网页护眼宝——全方位解析 Chrome Dark Reader 插件
网页护眼宝——全方位解析 Chrome Dark Reader 插件 1. 基本介绍:Chrome 插件的力量与 Dark Reader 的独特之处 随着现代浏览器的功能越来越强大,Chrome 插件为用户提供了极大的定制化能力。从广告屏蔽、性能优化到页面翻译,Chrome 插件几乎…...

C++ 构造函数和析构函数抛出异常的详细说明
1. 构造函数 功能:用于初始化对象的成员变量和分配资源。抛出异常: 当构造函数抛出异常时,构造的对象不会被创建,分配的资源会被释放。这意味着在构造函数抛出异常后,对象的状态是未定义的,调用者需要处理…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...

从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧
从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧 在射频模块或高精度ADC供电设计中,电源的纯净度直接决定系统性能上限。当输出电压纹波超出ADC的LSB范围,或EMI噪声耦合到敏感信号链时,工程师往往需要重新审视D…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案
ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况ÿ…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

紧急更新!Midjourney 6.2.1已悄然修复碳素印相的硫化银衰减模拟缺陷——但97%用户仍在用旧参数,立即校准你的工作流
更多请点击: https://intelliparadigm.com 第一章:碳素印相的视觉本质与Midjourney 6.2.1修复的底层动因 碳素印相的物质性光感逻辑 碳素印相并非数字渲染的模拟,而是一种基于明胶-碳黑颗粒物理沉积的连续调成像工艺。其高密度阴影区呈现哑…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

详解C++作用域与生命周期
Pascal之父Nicklaus Wirth曾经提出一个公式,展示出了程序的本质:程序算法数据结构。后人又给出一个公式与之遥相呼应:软件程序文档。这两个公式可以简洁明了的为我们展示程序和软件的组成。程序的运行过程可以理解为算法对数据的加工过程&…...