52 文本预处理_by《李沐:动手学深度学习v2》pytorch版
系列文章目录
例如:第一章 Python 机器学习入门之pandas的使用
文章目录
- 系列文章目录
- 一、理论部分
- 二、代码
- 读取数据集
- 词元化
- 词表
- 整合所有功能
- 小结
- 练习
一、理论部分
对于序列数据处理问题,我们在序列处理中评估了所需的统计工具和预测时面临的挑战。
这样的数据存在许多种形式,文本是最常见例子之一。
例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。
本节中,我们将解析文本的常见预处理步骤。
这些步骤通常包括:
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元(如单词和字符)。
- 建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
二、代码
import collections
import re
from d2l import torch as d2l
读取数据集
首先,我们从H.G.Well的时光机器中加载文本。
这是一个相当小的语料库,只有30000多个单词,但足够我们小试牛刀,而现实中的文档集合可能会包含数十亿个单词。
下面的函数(将数据集读取到由多条文本行组成的列表中),其中每条文本行都是一个字符串。
为简单起见,我们在这里忽略了标点符号和字母大写。
# 将时间机器数据集的下载链接和哈希值添加到数据仓库中
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')def read_time_machine(): #@save"""将时间机器数据集加载到文本行的列表中"""# 打开下载的时间机器文本文件with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines() # 读取所有行# 使用正则表达式清洗每一行文本,去掉非字母字符,并转换为小写return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]# 调用函数读取数据集
lines = read_time_machine()# 输出文本总行数
print(f'# 文本总行数: {len(lines)}')# 输出第一行和第十行的内容
print(lines[0])
print(lines[10])
# 文本总行数: 3221
the time machine by h g wells
twinkled and his usually pale face was flushed and animated the
词元化
下面的tokenize函数将文本行列表(lines)作为输入,列表中的每个元素是一个文本序列(如一条文本行)。
[每个文本序列又被拆分成一个词元列表],词元(token)是文本的基本单位。
最后,返回一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
def tokenize(lines, token='word'): #@save"""将文本行拆分为单词或字符词元"""# 如果指定的词元类型是 'word'if token == 'word':# 将每一行拆分为单词,返回一个包含单词列表的列表return [line.split() for line in lines]# 如果指定的词元类型是 'char'elif token == 'char':# 将每一行拆分为字符,返回一个包含字符列表的列表return [list(line) for line in lines]else:# 如果词元类型未知,打印错误信息print('错误:未知词元类型:' + token)# 调用 tokenize 函数,将文本行拆分为词元,默认使用单词作为词元
tokens = tokenize(lines)# 打印前 11 行的词元
for i in range(11):print(tokens[i])
['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
[]
[]
[]
[]
['i']
[]
[]
['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him']
['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。
现在,让我们[构建一个字典,通常也叫做词表(vocabulary),用来将字符串类型的词元映射到从 0 0 0开始的数字索引中]。
我们先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计,得到的统计结果称之为语料(corpus)。
然后根据每个唯一词元的出现频率,为其分配一个数字索引。
很少出现的词元通常被移除,这可以降低复杂性。
另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“<unk>”。
我们可以选择增加一个列表,用于保存那些被保留的词元,例如:填充词元(“<pad>”);序列开始词元(“<bos>”);序列结束词元(“<eos>”)。
class Vocab: #@save"""文本词表"""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):# 初始化词表,接受词元列表、最小频率和保留词元if tokens is None:tokens = [] # 如果未提供词元,则初始化为空列表if reserved_tokens is None:reserved_tokens = [] # 如果未提供保留词元,则初始化为空列表# 按出现频率统计词元counter = count_corpus(tokens) # 统计词元频率# 下面这行代码的作用是将词元的频率进行排序。self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)"""1. counter.items()counter 是一个字典,包含了词元及其对应的频率。items()方法返回一个包含字典中所有键值对的视图,每个键值对以元组的形式表示,例如('word', frequency)。2. sorted(..., key=lambda x: x[1], reverse=True):sorted() 函数用于对可迭代对象进行排序。这里对 counter.items() 返回的元组列表进行排序。key=lambda x: x[1]:key`参数指定了排序的依据。这里使用了一个匿名函数(lambda 函数),它接受一个元组 `x`,并返回该元组的第二个元素(即频率)。因此,排序将基于频率进行。reverse=True:设置为 `True` 表示按降序排序,即频率高的词元排在前面。3. self._token_freqs = ..:将排序后的结果赋值给 `self._token_freqs`,这是一个包含词元及其频率的列表,按频率从高到低排列。总结:这行代码的主要功能是生成一个按频率降序排列的列表,方便后续处理,例如在构建词表时可以优先考虑高频词元。"""# 未知词元的索引为0self.idx_to_token = ['<unk>'] + reserved_tokens # 初始化索引到词元的映射self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)} # 初始化词元到索引的映射# 添加高频词元到词表for token, freq in self._token_freqs:if freq < min_freq: # 如果频率低于最小频率,则停止添加breakif token not in self.token_to_idx: # 如果词元不在词表中self.idx_to_token.append(token) # 添加词元到索引列表self.token_to_idx[token] = len(self.idx_to_token) - 1 # 更新词元到索引的映射def __len__(self):"""返回词表中词元的数量"""print("调用了len函数") # 打印调试信息return len(self.idx_to_token) # 返回词元数量def __getitem__(self, tokens):"""根据词元返回其索引"""if not isinstance(tokens, (list, tuple)): # 如果输入不是列表或元组return self.token_to_idx.get(tokens, self.unk) # 返回词元的索引,若不存在则返回未知词元索引return [self.__getitem__(token) for token in tokens] # 对于列表或元组,递归调用获取每个词元的索引def to_tokens(self, indices):"""根据索引返回词元"""if not isinstance(indices, (list, tuple)): # 如果输入不是列表或元组return self.idx_to_token[indices] # 返回对应索引的词元return [self.idx_to_token[index] for index in indices] # 对于列表或元组,返回每个索引对应的词元@propertydef unk(self): # 未知词元的索引为0return 0 # 返回未知词元的索引@propertydef token_freqs(self):"""返回词元的频率"""return self._token_freqs # 返回统计的词元频率def count_corpus(tokens): #@save"""统计词元的频率"""# 这里的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list): # 如果tokens为空或是二维列表# 将词元列表展平成一个列表tokens = [token for line in tokens for token in line] # 展平列表,提取所有词元return collections.Counter(tokens) # 返回词元频率的计数器我们首先使用时光机器数据集作为语料库来[构建词表],然后打印前几个高频词元及其索引。
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])
[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
现在,我们可以(将每一条文本行转换成一个数字索引列表)。
for i in [0, 10]:print('文本:', tokens[i])print('索引:', vocab[tokens[i]])
文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
索引: [1, 19, 50, 40, 2183, 2184, 400]
文本: ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
整合所有功能
在使用上述函数时,我们[将所有功能打包到load_corpus_time_machine函数中],
该函数返回corpus(词元索引列表)和vocab(时光机器语料库的词表)。
我们在这里所做的改变是:
- 为了简化后面章节中的训练,我们使用字符(而不是单词)实现文本词元化;
- 时光机器数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的
corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
def load_corpus_time_machine(max_tokens=-1): #@save"""返回时光机器数据集的词元索引列表和词表"""# 读取时光机器数据集的文本行lines = read_time_machine()# 将文本行拆分为字符词元tokens = tokenize(lines, 'char')# 创建词表对象vocab = Vocab(tokens)# 将所有文本行展平到一个列表中,获取每个字符的索引corpus = [vocab[token] for line in tokens for token in line]# 如果指定了最大词元数,则截取前 max_tokens 个词元if max_tokens > 0:corpus = corpus[:max_tokens]# 返回词元索引列表和词表return corpus, vocab# 调用函数加载时光机器数据集,并获取词元索引列表和词表
corpus, vocab = load_corpus_time_machine()# 输出词元索引列表和词表的长度
len(corpus), len(vocab) #前面的值为170580,后面的为28调用了len函数
(170580, 28)
list(vocab.token_to_idx.items())[:10]
[('<unk>', 0),(' ', 1),('e', 2),('t', 3),('a', 4),('i', 5),('n', 6),('o', 7),('s', 8),('h', 9)]
小结
- 文本是序列数据的一种最常见的形式之一。
- 为了对文本进行预处理,我们通常将文本拆分为词元,构建词表将词元字符串映射为数字索引,并将文本数据转换为词元索引以供模型操作。
练习
- 词元化是一个关键的预处理步骤,它因语言而异。尝试找到另外三种常用的词元化文本的方法。
- 在本节的实验中,将文本词元为单词和更改
Vocab实例的min_freq参数。这对词表大小有何影响?
相关文章:

52 文本预处理_by《李沐:动手学深度学习v2》pytorch版
系列文章目录 例如:第一章 Python 机器学习入门之pandas的使用 文章目录 系列文章目录一、理论部分二、代码读取数据集词元化词表整合所有功能小结练习 一、理论部分 对于序列数据处理问题,我们在序列处理中评估了所需的统计工具和预测时面临的挑战。 …...

【python】字符串扩展-格式化的精度控制
字符串扩展 字符串的三种定义方式字符串拼接字符串格式化格式化的精度控制字符串格式化方式2对表达式进行格式化 学习目标 掌握格式化字符串的过程中做数字的精度控制 字符串格式化 name "小明" set_up_year 2006 stock_price 19.99 message "我是&…...

C++第一次练习
题目1 class Solution { public:bool isletter(char s){if(s<z&&s>a)return true;if(s>A&&s<Z)return true;return false;}string reverseOnlyLetters(string s) {if(s.empty()){return s;}int left,right;left0;rights.size()-1;while(left<ri…...

计算机毕业设计 基于Python的医疗预约与诊断系统 Django+Vue 前后端分离 附源码 讲解 文档
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

JAVA基础:正则表达式,String的intern方法,StringBuilder可变字符串特点与应用,+连接字符串特点
1 String中的常用方法2 1.1 split方法 将字符串按照指定的内容进行分割,将分割成的每一个子部分组成一个数组 分割内容不会出现在数组中 实际上该方法不是按照指定的简单的符号进行分割的,而是按照正则表达式进行分割 1.2 正则表达式 用简单的符号组合…...

前端接口报错302 [已解决]
前端接口报错302 [已解决] 在前端开发中,与后端接口的交互是项目成功的关键。然而,遇到如302这样的状态码报错时,可能会让开发者感到困惑。本文将通过详细解析和多个代码案例,帮助你深入理解前端接口报错302,并提供有效…...

【网络安全】利用未授权API接口实现创建Support Ticket
未经许可,不得转载。 文章目录 正文目标为一个技术平台,客户可以通过该平台预订不同类型的服务。 正文 redacted.com 是主域,但所有流量都通过 api.redacted.com。我过去曾使用该公司预订了一些服务,因此我的帐户中有预订历史。 我对我的订单开具了 Support Ticket,此时…...

气压高度加误差的两种方法(直接添加 vs 换算到气压误差),附MATLAB程序
在已知高度真实值时,如果需要计算此高度下的气压计误差,可考虑本文所述的两种方法 气压高度 气压与高度之间的关系可以用大气压的垂直变化来描述。随着高度的增加,气压通常会下降。这是因为空气的密度在高度增加时减少,导致上方空气柱对下方空气施加的压力减小。 主要关系…...
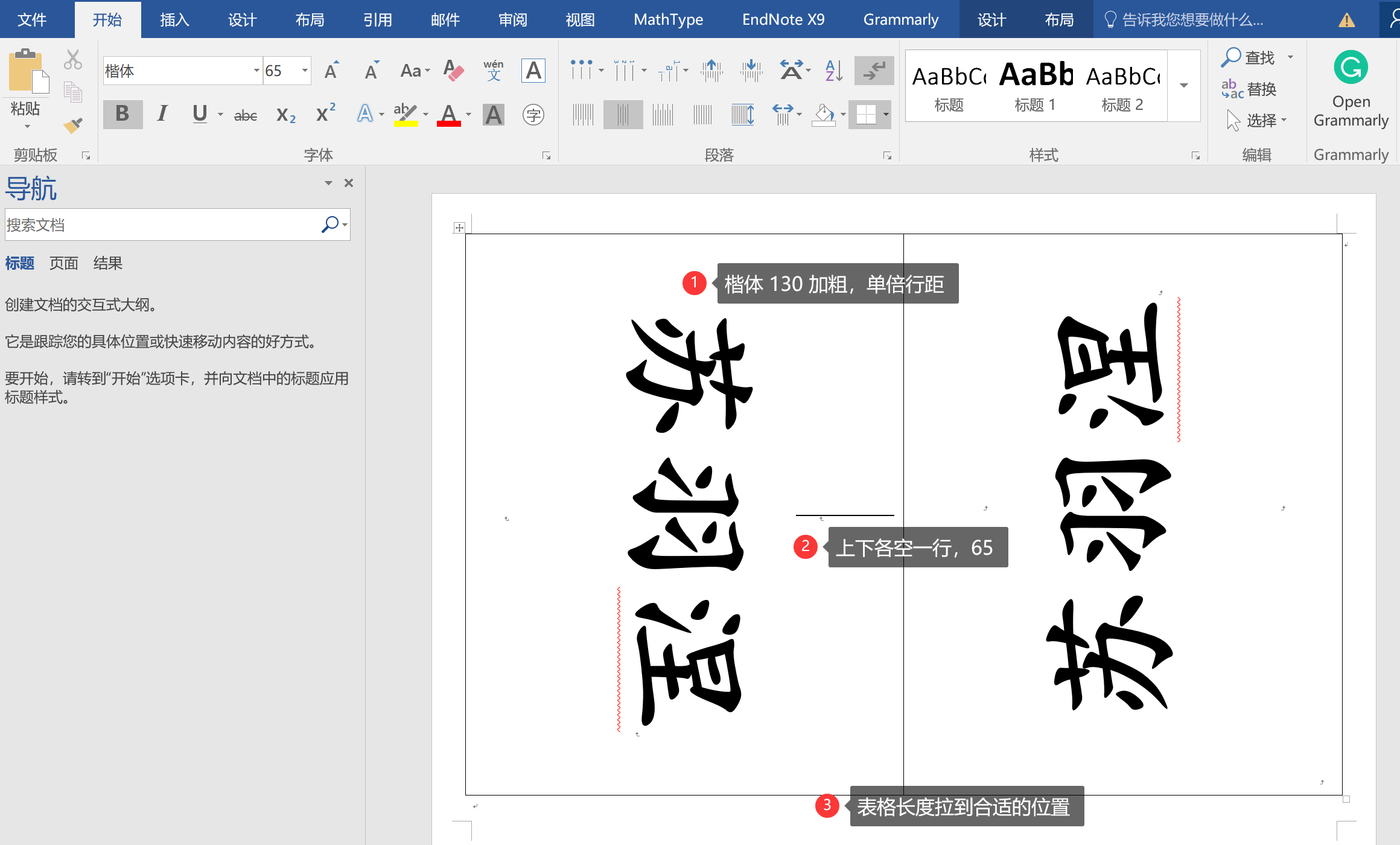
Word 制作会议名牌教程
文章目录 Part.I IntroductionPart.II 制作步骤 Part.I Introduction 本文详细介绍了如何用 Word 制作会议名牌,附有笔者制作好的一个成品(戳我下载~)。 下面是一些常识 会议名牌尺寸:100mm 180mm Part.II 制作步骤 1、新建文…...

浮动静态路由
浮动静态路由 首先我们知道静态路由的默认优先级是60,然后手动添加一条静态路由优先级为80的路由作为备份路由。当主路由失效的备份路由就会启动。 一、拓扑图 二、基本配置 1.R1: <Huawei>system-view [Huawei]sysname R1 [R1]interface GigabitEthernet…...

JavaWeb初阶 day1
目录 tomcat目录结构 tomcat:web服务器软件 项目部署的方式 直接将项目放到webapps下 配置conf/server.xml文件 在conf\Catalina\localhost创建任意名称的xml文件。在文件中编写 静态项目和动态项目 Servlet Servlet执行原理 Servlet方法(生命周期&#x…...

OpenAPI鉴权(二)jwt鉴权
一、思路 前端调用后端可以使用jwt鉴权;调用三方接口也可以使用jwt鉴权。对接多个三方则与每个third parth都约定一套token规则,因为如果使用同一套token,token串用可能造成权限越界问题,且payload交叉业务不够清晰。下面的demo包…...

【Rust练习】16.模式
文章题目来自:https://practice-zh.course.rs/pattern-match/patterns.html 1 🌟🌟 使用 | 可以匹配多个值, 而使用 … 可以匹配一个闭区间的数值序列 fn main() {} fn match_number(n: i32) {match n {// 匹配一个单独的值1 > println!(…...
:torch.nn.Module)
深度学习(4):torch.nn.Module
文章目录 一、是什么二、nn.Module 的核心功能三、nn.Module 的基本用法1. 定义自定义模型2. 初始化模型3. 模型的使用 四、nn.Module 的关键特性1. 自动注册子模块和参数2. forward 方法3. 不需要定义反向传播 五、常用的内置模块六、示例:创建一个简单的神经网络1…...

(14)关于docker如何通过防火墙做策略限制
关于docker如何通过防火墙做策略限制 1、iptables相关问题 在Iptables防火墙中包含四种常见的表,分别是filter、nat、mangle、raw。 filter:负责过滤数据包。 filter表可以管理INPUT、OUTPUT、FORWARD链。 nat:用于网络地址转换。 nat表…...

新React开发人员应该如何思考
React是一个用于构建用户界面的流行JavaScript库,通过使开发人员能够创建可重用组件并有效管理复杂的UI,彻底改变了前端开发。然而,采用正确的心态对于新开发人员驾驭React独特的范式至关重要。让我们来探索塑造“React思维模式”的基本原则和…...

解密.bixi、.baxia勒索病毒:如何安全恢复被加密数据
导言 在数字化时代,数据安全已成为个人和企业面临的重大挑战之一。随着网络攻击手段的不断演进,勒索病毒的出现尤为引人关注。其中,.bixi、.baxia勒索病毒是一种新型的恶意软件,它通过加密用户的重要文件,迫使受害者支…...

开源 AI 智能名片与 S2B2C 商城小程序:嫁接权威实现信任与增长
摘要:本文探讨了嫁接权威在产品营销中的重要性,并结合开源 AI 智能名片与 S2B2C 商城小程序,阐述了如何通过与权威关联来建立客户信任,提升产品竞争力。强调了在当今商业环境中,巧妙运用嫁接权威的方法,能够…...
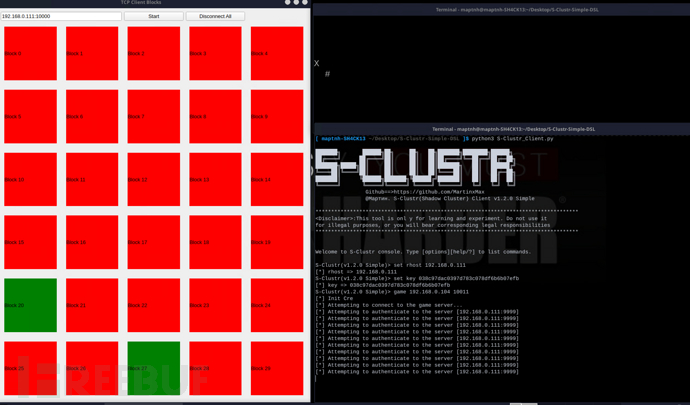
S-Clustr-Simple 飞机大战:骇入现实的建筑灯光游戏
项目地址:https://github.com/MartinxMax/S-Clustr/releases Video https://www.youtube.com/watch?vr3JIZY1olro 飞机大战 按键操作: ←:向左移动 →:向右移动 Space:发射子弹 这是一个影子集群的游戏插件,可以将游戏画面映射到现实的设备,允许恶…...

MySQL:存储引擎简介和库的基本操作
目录 一、存储引擎 1、什么是存储引擎? 2、存储引擎的分类 关系型数据库存储引擎: 非关系型数据库存储引擎: 分布式数据库存储引擎: 3、常用的存储引擎及优缺点 1、InnoDb存储引擎 2、MyISAM存储引擎 3、MEMORY存储引擎 …...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...

m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕
m4s-converter终极指南:如何无损转换B站缓存视频并保留弹幕 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容日益丰富的今天…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...

5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南
5分钟掌握浏览器串口调试:提升嵌入式开发效率300%的终极指南 【免费下载链接】SerialAssistant A serial port assistant that can be used directly in the browser. 项目地址: https://gitcode.com/gh_mirrors/se/SerialAssistant 你是否还在为串口调试工具…...

ARM Debug Interface v5.1架构解析与调试实践
1. ARM Debug Interface v5.1架构深度解析1.1 调试接口技术演进与核心价值ARM调试接口(ADI)技术历经多次迭代,v5.1版本作为当前主流标准,在嵌入式系统调试领域确立了关键地位。调试接口本质上是处理器核与外部调试工具之间的标准化通信桥梁,其…...

基于容器技术的在线代码沙盒:架构设计与安全实践
1. 项目概述:一个开箱即用的在线代码运行沙盒最近在折腾一些需要快速验证代码片段、或者给团队做技术分享的场景,我发现一个痛点:环境配置太麻烦了。你想让新人跑个Python脚本,他可能得先装Python、配环境变量、装依赖库ÿ…...

DOM 浏览器
DOM 浏览器 引言 DOM(文档对象模型)是浏览器中处理HTML和XML文档的标准方式。它允许开发人员通过编程方式访问和操作网页内容。本文将详细介绍DOM的概念、其在浏览器中的运用以及相关的编程技巧。 DOM简介 什么是DOM? DOM(Document Object Model)是一种跨平台和语言独…...