Hbase日常运维
1 Hbase日常运维
1.1 监控Hbase运行状况
1.1.1 操作系统
1.1.1.1 IO
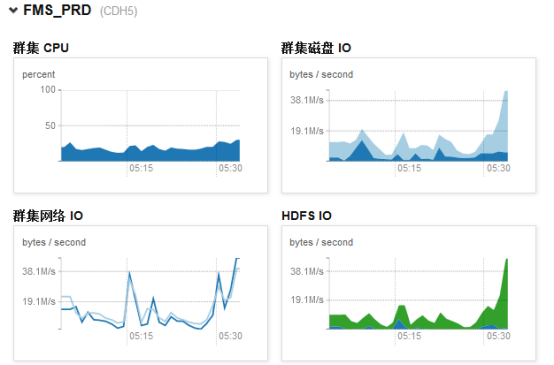
- 群集网络IO,磁盘IO,HDFS IO
IO越大说明文件读写操作越多。当IO突然增加时,有可能:1.compact队列较大,集群正在进行大量压缩操作。
2.正在执行mapreduce作业
可以通过CDH前台查看整个集群综合的数据或进入指定机器的前台查看单台机器的数据:
-
Io wait
磁盘IO对集群的影响比较大,如果io wait时间过长需检查系统或磁盘是否有异常。通常IO增加时io wait也会增加,现在FMS的机器正常情况io wait在50ms以下
跟主机相关的指标可以在CDH前台左上角先点“主机”选项卡然后选要查看的主机:
1.1.1.1 CPU
如果CPU占用过高有可能是异常情况引起集群资源消耗,可以通过其他指标和日志来查看集群正在做什么。
1.1.1.2 内存
1.1.1 JAVA
GC 情况
regionserver长时间GC会影响集群性能并且有可能会造成假死的情况
1.1.2 重要的hbase指标
1.1.2.1 region情况
需要检查
- region的数量(总数和每台regionserver上的region数)
- region的大小
如果发现异常可以通过手动merge region和手动分配region来调整
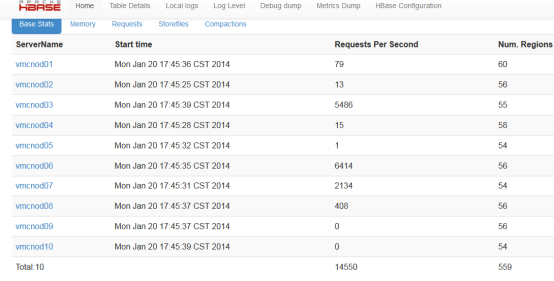
从CDH前台和master前台以及regionServer的前台都可以看到region数量,如master前台:
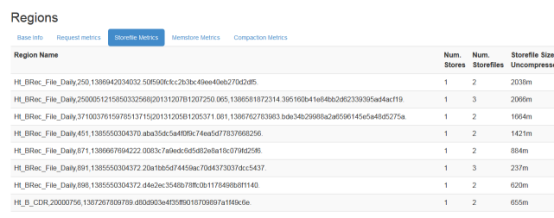
在region server前台可以看到storeFile大小:
1.1.1.1 缓存命中率
缓存命中率对hbase的读有很大的影响,可以观察这个指标来调整blockcache的大小。
从regionserver web页面可以看到block cache的情况:
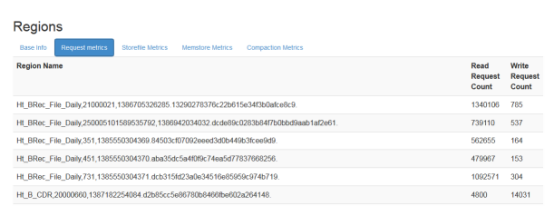
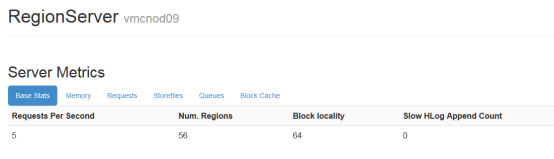
1.1.1.2 读写请求数
通过读写请求数可以大概看出每台regionServer的压力,如果压力分布不均匀,应该检查regionServer上的region以及其它指标
master web上可以看到所以regionServer的读写请求数
regionServer上可以看到每个region的读写请求数
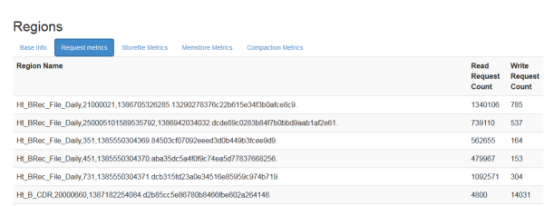
regionServer上可以看到每个region的读写请求数
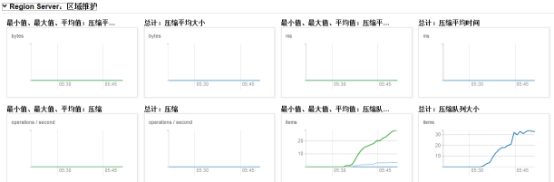
1.1.1.3 压缩队列
压缩队列存放的是正在压缩的storefile,compact操作对hbase的读写影响较大
通过cdh的hbase图表库可以看到集群总的压缩队列大小:
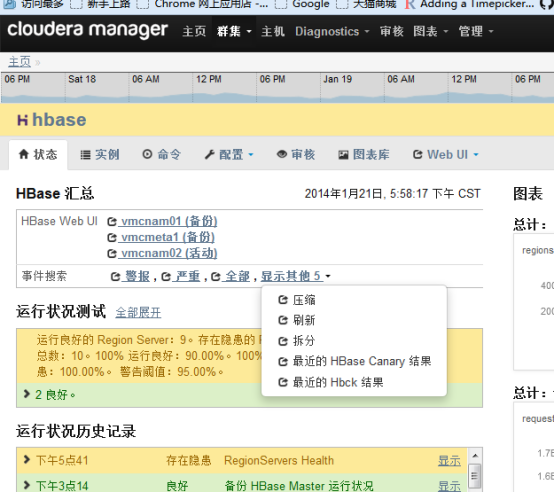
可以通过CDH的hbase主页查询compact日志:
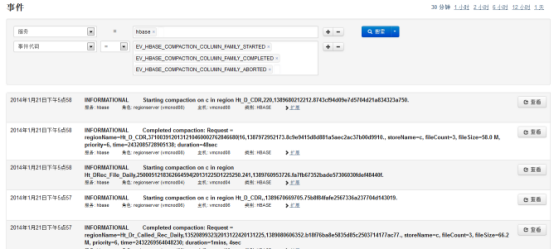
点击“压缩”进入:
1.1.1.1 刷新队列
单个region的memstore写满(128M)或regionServer上所有region的memstore大小总合达到门限时会进行flush操作,flush操作会产生新的storeFile
同样可以通过CDH的hbase前台查看flush日志:
1.1.1.1 rpc调用队列
没有及时处理的rpc操作会放入rpc操作队列,从rpc队列可以看出服务器处理请求的情况
1.1.1.2 文件块保存在本地的百分比
datanode和regionserver一般都部署在同一台机器上,所以region server管理的region会优先存储在本地,以节省网络开销。如果block locality较低有可能是刚做过balance或刚重启,经过compact之后region的数据都会写到当前机器的datanode,block locality也会慢慢达到接近100:
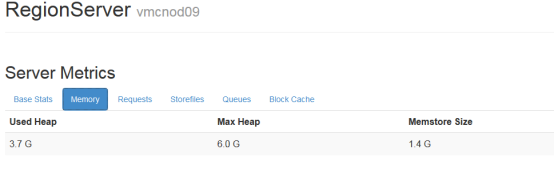
1.1.1.1 内存使用情况
内存使用情况,主要可以看used Heap和memstore的大小,如果usedHeadp一直超过80-85%以上是比较危险的
memstore很小或很大也不正常
从region Server的前台可以看到:
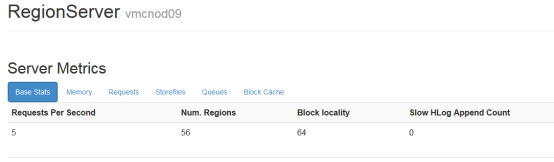
1.1.1.1 slowHLogAppendCount
写HLog过慢(>1s)的操作次数,这个指标可以作为HDFS状态好坏的判断
在region Server前台查看:
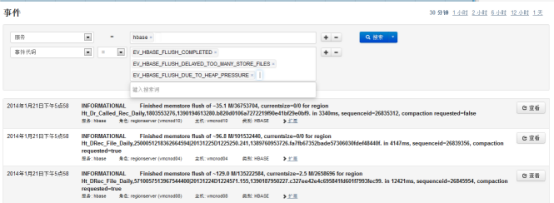
1.1.1 CDH检查日志
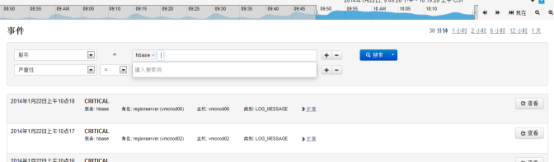
CDH有强大的系统事件和日志搜索功能,每一个服务(如:hadoop,hbase)的主页都提供了事件和告警的查询,日常运维除了CDH主页的告警外,需要查看这些事件以发现潜在的问题:
选择“事件搜索”中的标签(“警报”、“严重”)可以进入相关的事件日志,如“严重”:
1.1 检查数据一致性以及修复方法
数据一致性是指:
- 每个region都被正确的分配到一台regionserver上,并且region的位置信息及状态都是正确的。
- 每个table都是完整的,每一个可能的rowkey 都可以对应到唯一的一个region.
1.1.1 检查
hbase hbck
注:有时集群正在启动或region正在做split操作,会造成数据不一致
hbase hbck -details
加上–details会列出更详细的检查信息,包括所以正在进行的split任务
hbase hbck Table1 Table2
如果只想检查指定的表,可以在命令后面加上表名,这样可以节省操作时间
CDH
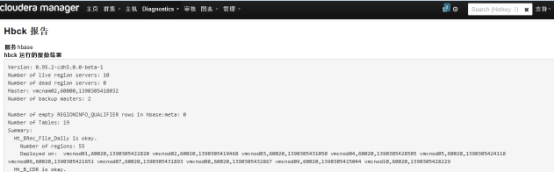
通过CDH提供的检查报告也可以看到hbck的结果,日常只需要看CDH hbck的报告即可:
选择“最近的Hbck结果”:
1.1.1 修复
1.1.1.1 局部的修复
如果出现数据不一致,修复时要最大限度的降低可能出现的风险,使用以下命令对region进行修复风险较低:
1.1.1.1.1 hbase hbck -fixAssignments
修复region没有分配(unassigned),错误分配(incorrectly assigned)以及多次分配(multiply assigned)的问题
1.1.1.1.1 hbase hbck -fixMeta
删除META表里有记录但HDFS里没有数据记录的region
添加HDFS里有数据但是META表里没有记录的region到META表
1.1.1.1.2 hbase hbck -repairHoles
等价于:hbase hbck -fixAssignments -fixMeta -fixHdfsHoles
-fixHdfsHoles的作用:
如果rowkey出现空洞,即相邻的两个region的rowkey不连续,则使用这个参数会在HDFS里面创建一个新的region。创建新的region之后要使用-fixMeta和-fixAssignments参数来使用挂载这个region,所以一般和前两个参数一起使用
1.1.1.1 Region重叠修复
进行以下操作非常危险,因为这些操作会修改文件系统,需要谨慎操作!
进行以下操作前先使用hbck –details查看详细问题,如果需要进行修复先停掉应用,如果执行以下命令时同时有数据操作可能会造成不可期的异常。
1.1.1.1.1 hbase hbck -fixHdfsOrphans
将文件系统中的没有metadata文件(.regioninfo)的region目录加入到hbase中,即创建.regioninfo目录并将region分配到regionser
1.1.1.1.1 hbase hbck -fixHdfsOverlaps
通过两种方式可以将rowkey有重叠的region合并:
- merge:将重叠的region合并成一个大的region
- sideline:将region重叠的部分去掉,并将重叠的数据先写入到临时文件,然后再导入进来。
如果重叠的数据很大,直接合并成一个大的region会产生大量的split和compact操作,可以通过以下参数控制region过大:
-maxMerge <n> 合并重叠region的最大数量
-sidelineBigOverlaps 假如有大于maxMerge个数的 region重叠, 则采用sideline方式处理与其它region的重叠.
-maxOverlapsToSideline <n> 如果用sideline方式处理重叠region,最多sideline n个region .
1.1.1.1.1 hbase hbck -repair
以下命令的缩写:
hbase hbck -fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile –sidelineBigOverlaps
可以指定表名:
hbase hbck -repair Table1 Table2
1.1.1.1.2 hbase hbck -fixMetaOnly –fixAssignments
如果只有META表的region不一致,则可以使用这个命令修复
1.1.1.1.1 hbase hbck –fixVersionFile
Hbase的数据文件启动时需要一个version file,如果这个文件丢失,可以用这个命令来新建一个,但是要保证hbck的版本和Hbase集群的版本是一样的
1.1.1.1.2 hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair
如果ROOT表和META表都出问题了Hbase无法启动,可以用这个命令来创建新的ROOT和META表。
这个命令的前提是Hbase已经关闭,执行时它会从hbase的home目录加载hbase的相关信息(.regioninfo),如果表的信息是完整的就会创建新的root和meta目录及数据
1.1.1.1.1 hbase hbck –fixSplitParents
当region做split操作的时候,父region会被自动清除掉。但是有时候子region在父region被清除之前又做了split。造成有些延迟离线的父region存在于META表和HDFS中,但是没有部署,HBASE又不能清除他们。这种情况下可以使用此命令重置这些在META表中的region为在线状态并且没有split。然后就可以使用之前的修复命令把这个region修复
1.1 手动merge region
进行操作前先将balancer关闭,操作完成后再打开balancer
经过一段时间的运行之后有可能会产生一些很小的region,
需要定期检查这些region并将它们和相邻的region合并以减少系统的总region数,减少管理开销
合并方法:
- 找到需要合并的region的encoded name
- 进入hbase shell
- 执行merge_region ‘region1’,’region2’
1.1 手动分配region
如果发现台regionServer资源占用特别高,可以检查这台regionserver上的region是否存在过多比较大的region,通过hbase shell将部分比较大的region分配给其他不是很忙的regions server:
move ‘regionId’,’serverName’
例:
move '54fca23d09a595bd3496cd0c9d6cae85','vmcnod05,60020,1390211132297'
1.1 手动major_compact
进行操作前先将balancer关闭,操作完成后再打开balancer
选择一个系统比较空闲的时间手工major_compact,如果hbase更新不是太频繁,可以一个星期对所有表做一次 major_compact,这个可以在做完一次major_compact后,观看所有的storefile数量,如果storefile数量增加到 major_compact后的storefile的近二倍时,可以对所有表做一次major_compact,时间比较长,操作尽量避免高锋期
注:fms现在生产上开启了自动major_compact,不需要做手动major compact
1.1 balance_switch
balance_switch true 打开balancer
balance_switch flase 关闭balancer
配置master是否执行平衡各个regionserver的region数量,当我们需要维护或者重启一个regionserver时,会关闭balancer,这样就使得region在regionserver上的分布不均,这个时候需要手工的开启balance。
1.1 regionserver重启
graceful_stop.sh --restart --reload --debug nodename
进行操作前先将balancer关闭,操作完成后再打开balancer
这个操作是平滑的重启regionserver进程,对服务不会有影响,他会先将需要重启的regionserver上面的所有 region迁移到其它的服务器,然后重启,最后又会将之前的region迁移回来,但我们修改一个配置时,可以用这种方式重启每一台机子,对于hbase regionserver重启,不要直接kill进程,这样会造成在zookeeper.session.timeout这个时间长的中断,也不要通过
bin/hbase-daemon.sh stop regionserver去重启,如果运气不太好,-ROOT-或者.META.表在上面的话,所有的请求会全部失败
1.1 regionserver关闭下线
bin/graceful_stop.sh nodename
进行操作前先将balancer关闭,操作完成后再打开balancer
和上面一样,系统会在关闭之前迁移所有region,然后stop进程。
1.1 flush表
所有memstore刷新到hdfs,通常如果发现regionserver的内存使用过大,造成该机的 regionserver很多线程block,可以执行一下flush操作,这个操作会造成hbase的storefile数量剧增,应尽量避免这个操 作,还有一种情况,在hbase进行迁移的时候,如果选择拷贝文件方式,可以先停写入,然后flush所有表,拷贝文件
1.2 Hbase迁移
1.2.1 copytable方式
bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable --peer.adr=zookeeper1,zookeeper2,zookeeper3:/hbase 'testtable'
这个操作需要添加hbase目录里的conf/mapred-site.xml,可以复制hadoop的过来。
1.1.1 Export/Import
bin/hbase org.apache.hadoop.hbase.mapreduce.Export testtable /user/testtable [versions] [starttime] [stoptime]
bin/hbase org.apache.hadoop.hbase.mapreduce.Import testtable /user/testtable
1.1.2 直接拷贝hdfs对应的文件
首先拷贝hdfs文件,如bin/hadoop distcp hdfs://srcnamenode:9000/hbase/testtable/ hdfs://distnamenode:9000/hbase/testtable/
然后在目的hbase上执行bin/hbase org.jruby.Main bin/add_table.rb /hbase/testtable
生成meta信息后,重启hbase
1 Hadoop日常运维
1.1 监控Hadoop运行状况
- nameNode、ResourseManager内存(namenode要有足够内存)
- DataNode和NodeManager运行状态
- 磁盘使用情况
- 服务器负载状态
1.2 检查HDFS文件健康状况
命令:hadoop fsck
1.1 开启垃圾箱(trash)功能
trash功能它默认是关闭的,开启后,被你删除的数据将会mv到操作用户目录的".Trash"文件夹,可以配置超过多长时间,系统自动删除过期数据。这样一来,当操作失误的时候,可以把数据mv回来
2 本项目场景下的hbase参数调整

相关文章:
Hbase日常运维
1 Hbase日常运维 1.1 监控Hbase运行状况 1.1.1 操作系统 1.1.1.1 IO 群集网络IO,磁盘IO,HDFS IO IO越大说明文件读写操作越多。当IO突然增加时,有可能:1.compact队列较大,集群正在进行大量压缩操作。 2.正在执行…...

鸿蒙开发的基本技术栈及学习路线
随着智能终端设备的不断普及与技术的进步,华为推出的鸿蒙操作系统(HarmonyOS)迅速引起了全球的关注。作为一个面向多种设备的分布式操作系统,鸿蒙不仅支持手机、平板、智能穿戴设备等,还支持IoT(物联网&…...

【算法】反向传播算法
David Rumelhart 是人工智能领域的先驱之一,他与 James McClelland 等人在1986年通过其著作《Parallel Distributed Processing: Explorations in the Microstructure of Cognition》详细介绍了反向传播算法(Backpropagation),这一…...

外贸非洲市场要如何开发
刚不久前中非合作峰会论坛之后,取消了非洲33国的进口关税,中非贸易一直以来都还不错,这次应该会更上一个台阶。今天就来给大家分享一下,关于非洲市场的一些分析和开发方法。 一、非洲市场情况 非洲是一个广阔的大陆,由…...
)
python去除空格join()
sinput().split() print( .join(s)) input().split()的作用: split()是字符串对象的方法。当对一个字符串调用split()方法时,它会根据指定的分隔符将字符串分割成多个子字符串,并将这些子字符串以列表的形式返回。如果不指定分隔符…...

git push错误:Out of memory, malloc failed (tried toallocate 947912704 bytes)
目录 一、错误截图 二、解决办法 一、错误截图 因项目文件过大,http.postBuffer设置的内存不够,所以报错。 二、解决办法 打开cmd窗口,执行如下命令即可 git config --global http.postBuffer 1024000000 如图所示 执行完成以后&#…...
)
web平台搭建-LAMP(CentOS-7)
一. 准备工作 环境要求: 操作系统:CentOS 7.X 64位 网络配置:nmtui字符终端图形管理工具或者直接编辑配置文件 关闭SELinux和firewalld防火墙 防火墙: 临时关闭:systemctl stop firewalld 永久关闭:systemc…...

2024.9.21 Python与C++的面试八股文整理,类与对象,内存规划,默认函数,虚函数,封装继承多态
1.什么是类,什么是面向对象 (1)类是一种蓝图或者模板,用于定义对象的属性和行为,类通常包括:属性,也就是静态特征,方法,也就是动态特征。属性描述对象的特征,…...

2024 vue3入门教程:02 我的第一个vue页面
1.打开src下的App.vue,删除所有的默认代码 2.更换为自己写的代码, 变量msg:可以自定义为其他(建议不要使用vue的关键字) 我的的第一个vue:可以更换为其他自定义文字 3.运行命令两步走 下载依赖 cnpm i…...

[go] 状态模式
状态模式 允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类。 模型说明 上下文 (Context) 保存了对于一个具体状态对象的引用, 并会将所有与该状态相关的工作委派给它。 上下文通过状态接口与状态对象交互&…...

uniapp沉浸式导航栏+自定义导航栏组件
在 UniApp 中实现沉浸式导航栏并结合自定义导航栏组件 一、沉浸式导航栏设置 在pages.json中配置页面样式 在需要设置沉浸式导航栏的页面的style选项中进行如下配置: {"pages": [{"path": "pages/pageName/pageName","style&qu…...

光伏仿真:排布设计如何优化用户体验?
1、屋顶绘制精准 光伏系统的性能直接受到屋顶结构的影响,因此,屋顶绘制的精准性是光伏仿真设计的首要任务。现代光伏仿真软件通过直观的界面和强大的图形编辑功能,使得用户能够轻松导入或绘制出待安装光伏系统的屋顶形状。无论是平面屋顶、斜…...

Vue使用axios二次封装、解决跨域问题
1、什么是 axios 在实际开发过程中,浏览器通常需要和服务器端进行数据交互。而 Vue.js 并未提供与服务器端通信的接口。从 Vue.js 2.0 版本之后,官方推荐使用 axios 来实现 Ajax 请求。axios 是一个基于 promise 的 HTTP 客户端。 关于 promise 的详细介…...

鸿萌数据恢复:如何降低 RAM 故障风险,以避免数据丢失?
天津鸿萌科贸发展有限公司从事数据安全服务二十余年,致力于为各领域客户提供专业的数据恢复、数据备份解决方案与服务,并针对企业面临的数据安全风险,提供专业的相关数据安全培训。 RAM 可能因多种原因而发生故障,并将设备和数据置…...

使用java实现ffmpeg的各种操作
以实现如下功能 1、支持音频文件转mp3;2、支持视频文件转mp4;3、支持视频提取音频;4、支持视频中提取缩略图;5、支持按时长拆分音频文件; 1、工具类 由于部分原因,没有将FfmpegUtil中的静态的命令行与Ty…...

【ArcGIS微课1000例】0122:经纬网、方里网、参考格网绘制案例教程
文章目录 一、ArcGIS格网类型二、绘制经纬网三、绘制方里网四、绘制参考格网五、注意事项一、ArcGIS格网类型 在ArcMap中,可以创建三种类型的格网: 经纬网——将地图分割为经线和纬线。经纬网是用来标识准确地理位置的方式,由经线和纬线构成,相对于经纬线,分别有的经度和…...

电路板上电子元件检测系统源码分享
电路板上电子元件检测检测系统源码分享 [一条龙教学YOLOV8标注好的数据集一键训练_70全套改进创新点发刊_Web前端展示] 1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 项目来源AACV Association for the Advancement of Comp…...

综合体第三题(DHCP报文分析)
DHCP工作流程(一般情况下) 例二(无忧/22) 下图为DHCP客户机获取IP地址等配置信息时,使用Wareshark软件捕获报文中编号为2〜5的4条报文,图中对编号为3的报文进行了解析。分析图中的信息并补全图中①〜⑤处的…...

企业级-pdf预览-前后端
作者:fyupeng 技术专栏:☞ https://github.com/fyupeng 项目地址:☞ https://github.com/fyupeng/distributed-blog-system-api 留给读者 本文 一、介绍 对于PDF预览,有很多开发者都遇到过头疼的难题,今天给大家介绍…...

为什么 qt 成为 c++ 界面编程的第一选择?
一、前言 为什么现在QT越来越成为界面编程的第一选择,笔者从事qt界面编程已经有接近8年,在这之前我做C界面都是基于MFC,也做过5年左右。当时为什么会从MFC转到QT,主要原因是MFC开发界面想做得好看一些十分困难,引用第…...
)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点) 作为一名刚接触粒子探测器仿真的研究生,我花了整整两周时间才成功将SolidWorks设计的模型导入Geant4进行模拟。这个过程远比想象中复杂&#x…...

ARMv8-AArch64 异常处理实战:从寄存器解析到调试技巧
1. ARMv8-AArch64异常处理入门指南 第一次接触ARMv8架构的异常处理时,我被那一堆寄存器搞得头晕眼花。ELR、ESR、FAR...这些缩写看起来就像天书一样。但经过几个实际项目的磨练后,我发现只要掌握几个关键点,异常处理其实并没有想象中那么难。…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...
)
STM8硬件IIC驱动BNO055传感器避坑指南(附完整代码)
STM8硬件IIC驱动BNO055传感器实战解析与优化 BNO055作为一款集成了9轴传感器融合算法的智能芯片,能够直接输出姿态角数据,极大简化了嵌入式系统中姿态解算的复杂度。然而在实际应用中,许多开发者发现使用STM32等常见MCU的模拟IIC接口难以稳定…...

Path of Building:3个步骤从Build小白到规划大师的完整指南
Path of Building:3个步骤从Build小白到规划大师的完整指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building作为流放之路玩家最信赖的Build规…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

Mantic.sh:AI驱动的智能命令行工具,让自然语言生成终端命令
1. 项目概述:一个为开发者打造的智能终端伴侣 如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你一定对效率有着近乎偏执的追求。敲命令、查日志、管理进程、部署服务……这些重复且琐碎的操作…...