spark 大表与大表join时的Shuffle机制和过程
在 Spark 中,当处理大表与大表的 JOIN 操作时,通常会涉及到 Shuffle 机制,这是分布式计算中用于重新分布数据的关键步骤。Shuffle 的本质是将数据按照某种方式重新分组,使得相同 key 的数据能够被发送到同一个计算节点进行后续的操作。以下是详细的 Shuffle 机制在大表与大表 JOIN 操作中的工作过程,涵盖底层原理和源代码相关内容。
一、Shuffle 基本原理
Shuffle 是 Spark 中用于处理需要跨多个分区(节点)计算的任务的关键机制。大体分为以下几个阶段:
- Map 阶段:将数据进行分区,并根据
key(用于JOIN的 key)进行 hash 分布。 - Shuffle 阶段:将 Map 阶段输出的数据发送到不同的 Reduce 任务中。每个 Reduce 任务负责处理特定的 key。
- Reduce 阶段:对相同 key 的数据进行操作,完成
JOIN、GROUP BY等计算。
在大表与大表 JOIN 时,数据量大且分布不均的 key 会导致 Shuffle 中的网络IO传输数据量巨大,因此这部分成为性能瓶颈的关键。
二、Shuffle 在 Join 中的工作流程
对于大表与大表 JOIN 的情况,常见的操作类型是基于 key 的 equi-join(等值连接)。具体的执行过程如下:
-
第一步:读入数据
Spark 会从数据源(如 HDFS、Hive 表等)中读取两个大表的数据,分别分布在不同的分区上。每个分区的数据是局部的,不包含全局的信息。 -
第二步:Map 阶段进行数据分区
在JOIN操作中,Spark 会根据key值进行数据的哈希分区。每个分区根据key进行 hash,然后将相同 hash 值的 key 数据分发到相同的 Reduce 节点。例如,如果两个表都要根据user_id进行连接,Spark 会对user_id进行 hash 计算。在代码中,这一部分对应
RDD的partitionBy操作(对于 DataFrame/Dataset 则是底层物理计划的分区操作)。ShuffledRDD负责这一逻辑的实现。伪代码展示:
// 对表A和表B的key进行分区 val partitionedTableA = tableA.partitionBy(new HashPartitioner(numPartitions)) val partitionedTableB = tableB.partitionBy(new HashPartitioner(numPartitions)) -
第三步:Shuffle 过程
Shuffle是一个将 Map 阶段计算的结果数据从一个计算节点发送到另一个计算节点的过程。对于JOIN操作,Shuffle 的目的是确保相同 key 的数据被分发到相同的节点上。在
Shuffle过程中,Spark 会使用shuffle write将本地数据写到磁盘或网络中,然后通过网络将这些分区数据发送到目标节点。接着,shuffle read负责从其他节点上读取相应分区的数据。ShuffleMapTask是负责执行 Shuffle 写阶段的任务类型,ShuffleManager管理整个 Shuffle 的过程,默认实现为SortShuffleManager。伪代码展示:
// 执行 shuffle,将 A 和 B 按照 key hash 之后分布到不同节点 partitionedTableA.join(partitionedTableB)Shuffle 的详细步骤:
- Shuffle Write: 每个 map 任务计算完局部数据后,会将数据写入本地磁盘的文件系统或存储在内存中。数据以 partition 为单位写出,针对每个分区分别存储。
- Shuffle Read: Reduce 任务会根据分区信息从其他节点拉取数据,读取与自己分区匹配的数据块进行处理。
-
第四步:Reduce 阶段进行 JOIN 计算
在Shuffle结束后,每个节点已经得到了自己负责的分区数据。接下来,Spark 会执行JOIN操作。对于 equi-join,Spark 会对每个分区中的数据进行匹配(类似于merge join或者hash join)。因为相同 key 的数据已经被分布到同一个分区,所以可以直接进行连接操作。在源码层面,
ShuffledRowRDD是Shuffle Read后构造的 RDD,ShuffleRowJoinExec是执行实际JOIN操作的物理计划节点。 -
第五步:输出结果
Reduce 阶段完成JOIN操作后,结果会写入到相应的输出位置(如内存、磁盘、或是其他表中)。
三、代码层面关键类和函数
-
Shuffle 相关类和接口
ShuffleManager: 管理 Shuffle 过程的接口,决定如何进行数据的 Shuffle。默认实现为SortShuffleManager,其主要负责将数据按 key 排序后写入并读取。ShuffleDependency: 定义了数据 Shuffle 的依赖关系,描述了需要Shuffle的 RDD 和其 Partitioner。ShuffleMapTask: 执行 Shuffle 写操作的 Task。ShuffledRowRDD: 负责处理 Shuffle 读取后的数据。
-
Join相关类ShuffleExchangeExec: 执行 Shuffle 数据的交换操作,用于分区。BroadcastHashJoinExec: 当JOIN其中一张表较小时,可以采用广播机制避免 Shuffle。SortMergeJoinExec: Spark 默认的大表与大表JOIN算法,适合排序后的数据。ShuffledHashJoinExec: 基于 Shuffle 后的哈希 Join,适合大数据量。
-
关键函数
partitionBy: 根据给定的 Partitioning 函数对 RDD 进行重新分区。shuffle: 将RDD按 key 进行 shuffle,涉及到数据的写入和读取。join: DataFrame API 中的join函数封装了不同的JOIN算法,包括 Sort-Merge Join 和 Broadcast Join。
四、优化 Shuffle 的策略
由于大表 JOIN 时的 Shuffle 会产生大量的磁盘 I/O 和网络传输,以下是一些常见的优化策略:
-
Broadcast Join(广播连接):当一张表很小而另一张表很大时,可以使用广播机制避免
Shuffle,即将小表广播到每个节点。这避免了大表的Shuffle操作,极大提高性能。通过设置:
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 10 * 1024 * 1024) // 10MB -
Partition 数量的调优:合理设置分区数量(
spark.sql.shuffle.partitions)可以减少单个分区的数据量过大或过小的问题,进而减小 Shuffle 阶段的网络开销。 -
合并小文件:启用
spark.shuffle.file.buffer和spark.reducer.maxSizeInFlight来优化 Shuffle 文件的缓冲区和网络传输时的最大文件大小,以减少磁盘 I/O 的次数。 -
Skew Join 处理:对于数据倾斜的场景,可以采用 Skew Join(倾斜 Join)的方式,将倾斜的 key 拆分到多个分区进行处理,减小单个 Reduce 任务的压力。
五、总结
在 Spark 的大表 JOIN 过程中,Shuffle 机制是核心的步骤,其主要职责是重新分发数据使得相同 key 的记录能够分布到同一个节点。Shuffle 的开销主要在于数据的网络传输和磁盘 I/O,因此有效的分区策略、数据倾斜处理以及 JOIN 算法选择都是优化此过程的关键。通过对 Shuffle 源码和物理执行计划的理解,可以帮助开发者更好地调优 Spark 应用的性能。
相关文章:

spark 大表与大表join时的Shuffle机制和过程
在 Spark 中,当处理大表与大表的 JOIN 操作时,通常会涉及到 Shuffle 机制,这是分布式计算中用于重新分布数据的关键步骤。Shuffle 的本质是将数据按照某种方式重新分组,使得相同 key 的数据能够被发送到同一个计算节点进行后续的操…...

大厂面试真题:简单说下Redis的bigkey
什么是bigkey bigkey是指key对应的value所占的内存空间比较大,例如一个字符串类型的value可以最大存到512MB,一个列表类型的value最多可以存储23-1个元素。 如果按照数据结构来细分的话,一般分为字符串类型bigkey和非字符串类型bigkey。 字…...
18 vue3之自动引入ref插件深入使用v-model
自动引入插件后无需再引入ref等 使用自动引入插入无需在import { ref, reactive } from "vue"做这样的操作 npm i unplugin-auto-import - D vite配置 import AutoImport from unplugin-auto-import/vite //使用vite版本 export default defineConfig({plugins: [v…...

【Spring】lombok、dbUtil插件应用
一、lombok插件 1. 功能:对实体类自动,动态生成get、set方法,无参、有参构造..... 2. 步骤: (1)idea安装插件(只做一次) (2)添加坐标 (3)编写注解 NoArgsCo…...

【学习笔记】WSL
WSL 1、 介绍 1.1、概述 1.2、版本 1.3、配置安装 2、 基本 2.1、基本命令 1、 介绍 1.1、概述 WSL 是 Windows Subsystem for Linux 的缩写,中文称为 Windows 下的 Linux 子系统。它是微软在 Windows 上提供的一种功能,允许用户在 …...

python assert 断言用法
语法: try:assert 条件表达式, "可选的错误消息" except AssertionError as error:print(f"断言失败:{error}")其中, try...except是异常处理语法结构,try可以测试代码块中的错误,并在出现异常时…...

MySQL事务、索引、数据恢复和备份
MySQL事务、索引、数据恢复和备份 1.MySQL的事务处理 事务就是将一组SQL语句放在同一批次内去执行 如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行 MySQL的事务实现方法 : SET AUTOCOMMIT 使用SET语句来改变自动提交模式 SET AUTOCOMMIT 0; # 关…...

什么是chatgpt?国内有哪些类gpt模型?
什么是ChatGPT? “ChatGPT”这个名字越来越多地出现在我们的生活中。简单来说,ChatGPT是OpenAI开发的一种人工智能对话模型。它基于GPT(Generative Pre-trained Transformer,生成式预训练变换模型)架构,能…...
)
ISP基本框架及算法介绍 ISP(Image Signal Processor)
ISP基本框架及算法介绍 ISP(Image Signal Processor),即图像处理,主要作用是对前端图像传感器输出的信号做后期处理,主要功能有线性纠正、噪声去除、坏点去除、内插、白平衡、自动曝光控制等,依赖于ISP才能在不同的光学条件…...

Stable Diffusion 的 ControlNet 主要用途
SD(Stable Diffusion)中的ControlNet是一种条件生成对抗神经网络(Conditional Generative Adversarial Network, CGAN)的扩展技术,它允许用户通过额外的输入条件来控制预训练的大模型(如Stable Diffusion&a…...

矩阵分析 学习笔记4 内积与Gram矩阵
内积 定义 由于对称,第二变元线性那第一变元也线性了。例如这个:...

iOS 消息机制详解
应用 解决NSTimer、CADisplayLink循环引用。 二者都是基于runloop的定时器,由于处理事件内容不一样,runloop 每运行一次运行耗时就不一样,无法准确的定时触发timer的事件。 NSProxy 与 NSObject 如果继承自NSProxy 直接开始消息转发&…...

深入理解Spring Data JPA与接口编程
目录 1. 什么是Spring Data JPA? 2. 如何使用Spring Data JPA? 3. 示例代码 4. 使用Query注解 5. 拓展知识:接口编程的好处 6. 结论 在软件开发领域,接口(Interface)是一种定义了方法签名但没有实现的…...
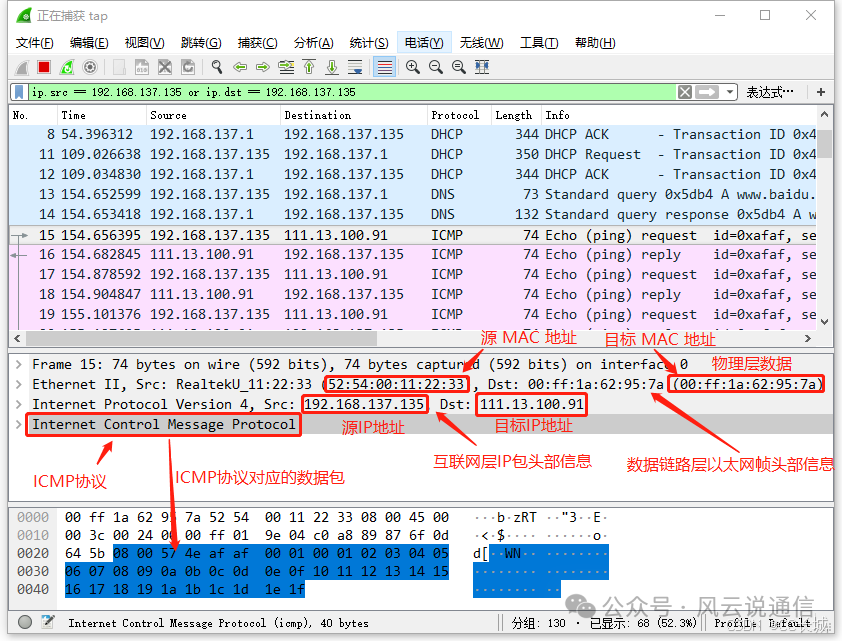
Wireshark学习使用记录
wireshark 是一个非常好用的抓包工具,使用 wireshark 工具抓包分析,是学习网络编程必不可少的一项技能。 原理 Wireshark使用的环境大致分为两种:一种是电脑直连互联网的单机环境,另外一种就是应用比较多的互联网环境,也就是连接…...

OpenCV特征检测(9)检测图像中直线的函数HoughLines()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在二值图像中使用标准 Hough 变换查找直线。 该函数实现了用于直线检测的标准 Hough 变换或标准多尺度 Hough 变换算法。详见 http://homepages…...

力扣 中等 445.两数相加 II
文章目录 题目介绍题解 题目介绍 题解 首先反转两个链表,再调用 2. 两数相加 链接的代码,得到链表,最后将其翻转即可。 class Solution {public ListNode addTwoNumbers(ListNode l1, ListNode l2) {l1 reverseList(l1);l2 reverseList(l…...

华为云徐峰:AI赋能应用现代化,加速软件生产力跃升
2024年9月19日,在华为全联接大会2024的“AI赋能应用现代化,加速软件生产力跃升”论坛上,华为云PaaS服务产品部部长徐峰发表了主题演讲,介绍了未来应用智能化演进趋势,分享了智能化应用的行业实践,并发布了华…...

C发送邮件技巧:如何批量发送个性化邮件?
C发送邮件的高效步骤指南?C语言怎么实现SMTP发邮件? 为了提高邮件营销的效果,掌握C发送邮件的技巧,特别是如何批量发送个性化邮件,显得尤为重要。AokSend将详细介绍C发送邮件的技巧,帮助您在邮件营销中取得…...

基于python+spark的外卖餐饮数据分析系统设计与实现(含论文)-Spark毕业设计选题推荐
博主介绍: 大家好,本人精通Java、Python、C#、C、C编程语言,同时也熟练掌握微信小程序、Php和Android等技术,能够为大家提供全方位的技术支持和交流。 我有丰富的成品Java、Python、C#毕设项目经验,能够为学生提供各类…...

权限维持——Linux
前提 已经提权到管理员权限 一、创建账户 1、创建一个自定义密码的账户 已知,Linux中所有的用户的信息 存储在/etc/passwd这个文件中 。可以利用管理员权限修改这个文件, 添加一个账户 。 利用linux中的密码的编码算法 生成对应密码 (不知…...

BG3ModManager:博德之门3模组管理终极解决方案
BG3ModManager:博德之门3模组管理终极解决方案 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager 你是否曾经为《博德之门3》的模组管理而烦…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

OpenSpire:开源贡献者协作平台的设计理念与实战指南
1. 项目概述:一个面向开源贡献者的协作平台最近在和一些刚接触开源的朋友交流时,发现一个挺普遍的现象:很多人对参与开源项目充满热情,但第一步“如何找到合适的项目并上手”就卡住了。GitHub上项目浩如烟海,一个新手面…...
:启动时快稍后慢,断断续续哥还在)
车载以太网之要火系列 - 第46篇:郭大侠学SOME/IP (offer Service):启动时快稍后慢,断断续续哥还在
写在开篇蓉儿继续挖坑上回说到,郭靖搞清楚了Offer Service的基本原理——服务端广播“我会啥,我在这”,TTL告诉客户端有效期。郭靖合上笔记本,突然皱起眉头:“蓉儿,我有个问题——如果每个ECU都每隔1.5秒发…...

如何在Chrome浏览器中快速生成与解析二维码:Chrome QRCode插件终极指南
如何在Chrome浏览器中快速生成与解析二维码:Chrome QRCode插件终极指南 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的…...

OneQuery:统一异构数据源查询的抽象层设计与实战
1. 项目概述:一个查询,无限可能最近在折腾一个数据聚合项目,需要从多个异构数据源里捞数据,然后统一处理。这活儿听起来简单,但真干起来,每个数据源都有自己的查询语法、连接方式和返回格式,光是…...

Hermes Agent 连接 Taotoken 自定义供应商,完成环境变量配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 连接 Taotoken 自定义供应商,完成环境变量配置 基础教程类,指导用户在使用 Hermes Agent 时&…...

RTX 5090功耗传闻解析:600W显卡对PC生态的挑战与应对
1. 项目概述:从一则功耗新闻到显卡生态的深度思考最近,英伟达下一代旗舰显卡RTX 5090的功耗传闻在硬件圈里炸开了锅。消息称其TGP(总图形功耗)可能高达600W,相比RTX 4090的450W,直接激增了150W。这不仅仅是…...
)
ElevenLabs菲律宾语语音突然变卡顿?紧急排查清单:DNS劫持、Token过期、区域节点错配(含curl诊断脚本)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾语语音突然变卡顿?紧急排查清单:DNS劫持、Token过期、区域节点错配(含curl诊断脚本) 当ElevenLabs API在调用菲律宾语(fil-P…...