Redis Sorted Set 跳表的实现原理和分析
跳表(Skip List)是一种随机化的数据结构,基于有序链表,通过在链表上增加多级索引来提高数据的查找效率。它是由 William Pugh 在 1990 年提出的。
为什么 Redis 中的 Sorted Set 使用跳跃表
Redis 的有序集合(Sorted Set)使用跳跃表(Skip List)作为底层实现,主要是因为跳跃表在性能、实现复杂度和灵活性等方面具有显著优势,可以替代平衡树的数据结构。
跳跃表的原理
跳跃表是一种扩展的有序链表,通过维护多个层级的索引来提高查找效率。每个节点包含一个数据元素和一组指向其他节点的指针,这些指针分布在不同的层级。最底层的链表包含所有元素,而每一层的节点数量逐渐减少。这样,查找操作可以从高层开始,快速跳过不需要的元素,减少遍历的节点数,从而提高查找效率。
-
查找过程:从最高层的头节点开始,沿着索引节点向右查找,如果当前节点的下一个节点的值大于或等于查找的目标值,则向下移动到下一层继续查找;否则,向右移动到下一个索引节点。这个过程一直持续到找到目标节点或到达最底层链表。
-
插入和删除操作:跳跃表支持高效的动态插入和删除,时间复杂度均为 O(log n)。插入时,首先找到插入位置,然后根据随机函数决定新节点的层数,最后在相应的层中插入节点。
跳跃表的优势
-
简单性:跳跃表的实现相对简单,易于理解和维护,而平衡树(如红黑树)的实现较为复杂,容易出错。
-
高效的范围查询:跳跃表在进行范围查询时效率更高,因为它是有序的链表,可以直接遍历后继节点,而平衡树需要中序遍历,复杂度更高。
-
灵活性:跳跃表的层数可以根据需要动态调整,适应不同的查询需求。
-
高并发性能:跳跃表的节点可以支持多个线程同时插入或删除节点,而平衡树和哈希表通常需要复杂的并发控制。
-
空间效率:跳跃表的空间复杂度为 O(n),并且通过调整节点的抽取间隔,可以灵活平衡空间和时间复杂度。
正是因为有这些优势,Redis 选择使用跳跃表来实现有序集合,而不是红黑树或其他数据结构。这使得 Redis 在处理有序集合时能够高效地支持插入、删除和查找操作,同时保持元素的有序性,非常适合实现如排行榜、范围查询等功能。
为了讲明白跳表的原理,现在我们来模拟一个简单的跳表实现。
在 Java 中模拟实现 Redis 的 Sorted Set 跳表,我们需要定义跳表的数据结构,包括节点和跳表本身。以下是一个简单的实现:
import java.util.Random;public class SkipList {private static final double P = 0.5; // 节点晋升的概率private static final int MAX_LEVEL = 16; // 最大层数private int levelCount; // 当前跳表的层数private Node head; // 头节点private int size; // 跳表中元素的数量private Random random; // 随机数生成器public SkipList() {this.levelCount = 0;this.size = 0;this.head = new Node(-1, Integer.MIN_VALUE, MAX_LEVEL);this.random = new Random();}// 节点定义private class Node {int value;int key;Node[] forward; // 向前指针数组Node(int value, int key, int level) {this.value = value;this.key = key;this.forward = new Node[level + 1];}}// 随机生成节点的层数private int randomLevel() {int level = 0;while (random.nextFloat() < P && level < MAX_LEVEL) {level++;}return level;}// 搜索指定值的节点public Node search(int key) {Node current = head;for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i]; // 沿着当前层的指针移动}}current = current.forward[0]; // 移动到第0层return current;}// 插入节点public void insert(int key, int value) {Node[] update = new Node[MAX_LEVEL + 1];Node current = head;// 查找插入位置for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}update[i] = current;}int level = randomLevel(); // 随机生成层数if (level > levelCount) {levelCount = level;for (int i = levelCount - 1; i >= 0; i--) {update[i] = head;}}current = new Node(value, key, level);for (int i = 0; i < level; i++) {current.forward[i] = update[i].forward[i];update[i].forward[i] = current;}size++;}// 删除节点public void delete(int key) {Node[] update = new Node[MAX_LEVEL + 1];Node current = head;// 查找要删除的节点for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}update[i] = current;}current = current.forward[0];if (current != null && current.key == key) {for (int i = 0; i < levelCount; i++) {if (update[i].forward[i] != current) {break;}update[i].forward[i] = current.forward[i];}size--;while (levelCount > 0 && head.forward[levelCount - 1] == null) {levelCount--;}}}// 打印跳表public void printList() {Node current = head.forward[0];while (current != null) {System.out.println(current.key + ":" + current.value);current = current.forward[0];}}// 主函数测试跳表public static void main(String[] args) {SkipList list = new SkipList();list.insert(3, 100);list.insert(6, 300);list.insert(4, 400);list.insert(7, 700);list.insert(5, 500);list.printList();list.delete(3);list.printList();}
}
下面,V 哥来解释一下:
-
跳表节点:每个节点包含一个值、一个键和一个向前指针数组。向前指针数组存储了指向同一层下一个节点的引用。
-
随机层数:每个节点的层数是根据预设的概率
P随机生成的,这样可以模拟出不同高度的索引层。 -
搜索操作:从最高层开始,沿着当前层的指针移动,直到找到插入点或到达底层。
-
插入操作:首先找到插入位置,然后根据随机生成的层数创建新节点,并更新每一层的指针。
-
删除操作:找到要删除的节点,然后逐层更新指针,最后减少跳表的层数。
-
打印跳表:从底层的头节点开始,遍历打印每个节点的键和值。
从这个简化版的跳表实现可以看到跳表的基本操作。可以帮助我们理解跳表实现的原理。
如何在 Java 中实现跳表的并发操作?
在 Java 中实现跳表的并发操作需要考虑线程安全问题。可以通过以下方法来实现:
-
使用同步块:在每个公共方法中使用
synchronized关键字来确保同一时间只有一个线程可以执行方法。 -
使用锁:使用
ReentrantLock或其他并发锁来控制对跳表的并发访问。 -
使用原子引用:使用
AtomicReference或AtomicReferenceArray来确保节点的原子更新。 -
使用并发集合:使用
ConcurrentHashMap等并发集合作为辅助工具来实现线程安全的跳表。
以下是一个使用 synchronized 关键字实现线程安全的跳表的示例:
import java.util.Random;public class ConcurrentSkipList {private static final double P = 0.5; // 节点晋升的概率private static final int MAX_LEVEL = 16; // 最大层数private int levelCount; // 当前跳表的层数private Node head; // 头节点private int size; // 跳表中元素的数量private Random random; // 随机数生成器public ConcurrentSkipList() {this.levelCount = 0;this.size = 0;this.head = new Node(-1, Integer.MIN_VALUE, MAX_LEVEL);this.random = new Random();}private class Node {int value;int key;Node[] forward; // 向前指针数组Node(int value, int key, int level) {this.value = value;this.key = key;this.forward = new Node[level + 1];}}private int randomLevel() {int level = 0;while (random.nextFloat() < P && level < MAX_LEVEL) {level++;}return level;}public synchronized Node search(int key) {Node current = head;for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}}current = current.forward[0];return current;}public synchronized void insert(int key, int value) {Node[] update = new Node[MAX_LEVEL + 1];Node current = head;for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}update[i] = current;}int level = randomLevel();if (level > levelCount) {for (int i = levelCount; i < level; i++) {update[i] = head;}levelCount = level;}current = new Node(value, key, level);for (int i = 0; i < level; i++) {current.forward[i] = update[i].forward[i];update[i].forward[i] = current;}size++;}public synchronized void delete(int key) {Node[] update = new Node[MAX_LEVEL + 1];Node current = head;for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}update[i] = current;}current = current.forward[0];if (current != null && current.key == key) {for (int i = 0; i < levelCount; i++) {if (update[i].forward[i] != current) {break;}update[i].forward[i] = current.forward[i];}size--;while (levelCount > 0 && head.forward[levelCount - 1] == null) {levelCount--;}}}public synchronized void printList() {Node current = head.forward[0];while (current != null) {System.out.println(current.key + ":" + current.value);current = current.forward[0];}}public static void main(String[] args) {ConcurrentSkipList list = new ConcurrentSkipList();list.insert(3, 100);list.insert(6, 300);list.insert(4, 400);list.insert(7, 700);list.insert(5, 500);list.printList();list.delete(3);list.printList();}
}
在这个示例中,我们使用了 synchronized 关键字来确保 search、insert 和 delete 方法是线程安全的。这会锁定当前对象,确保同一时间只有一个线程可以执行这些方法。
请注意,虽然 synchronized 可以提供线程安全,但它也可能导致性能瓶颈,特别是在高并发环境下。在实际应用中,可以考虑使用更细粒度的锁,如 ReentrantLock,或者使用原子引用和其他并发工具来提高性能。
使用 ReentrantLock 的实现方式
使用 ReentrantLock 实现跳表的并发操作可以提供比 synchronized 更细粒度的锁定,从而提高并发性能。ReentrantLock 允许您在不同的方法中锁定和解锁,甚至可以在不同的类中使用同一个锁对象。
以下是使用 ReentrantLock 实现线程安全的跳表的示例:
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;public class ConcurrentSkipList {private static final double P = 0.5; // 节点晋升的概率private static final int MAX_LEVEL = 16; // 最大层数private final Lock lock = new ReentrantLock(); // 创建一个 ReentrantLock 对象private int levelCount; // 当前跳表的层数private Node head; // 头节点private int size; // 跳表中元素的数量private Random random; // 随机数生成器public ConcurrentSkipList() {this.levelCount = 0;this.size = 0;this.head = new Node(Integer.MIN_VALUE, MAX_LEVEL);this.random = new Random();}private class Node {int value;int key;Node[] forward; // 向前指针数组Node(int key, int level) {this.key = key;this.forward = new Node[level + 1];}}private int randomLevel() {int level = 0;while (random.nextFloat() < P && level < MAX_LEVEL) {level++;}return level;}public void search(int key) {lock.lock(); // 加锁try {Node current = head;for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}}current = current.forward[0];// ... 处理找到的节点} finally {lock.unlock(); // 释放锁}}public void insert(int key, int value) {lock.lock(); // 加锁try {Node[] update = new Node[MAX_LEVEL + 1];Node current = head;for (int i = levelCount - 1; i >= 0; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}update[i] = current;}int level = randomLevel();if (level > levelCount) {levelCount = level;}current = new Node(value, key, level);for (int i = 0; i < level; i++) {current.forward[i] = update[i].forward[i];update[i].forward[i] = current;}size++;} finally {lock.unlock(); // 释放锁}}public void delete(int key) {lock.lock(); // 加锁try {Node[] update = new Node[MAX_LEVEL + 1];Node current = head;for (int i = levelCount - 1; i >= 1; i--) {while (current.forward[i] != null && current.forward[i].key < key) {current = current.forward[i];}update[i] = current;}current = current.forward[0];if (current != null && current.key == key) {for (int i = 0; i < levelCount; i++) {if (update[i].forward[i] != current) {break;}update[i].forward[i] = current.forward[i];}size--;while (levelCount > 0 && head.forward[levelCount - 1] == null) {levelCount--;}}} finally {lock.unlock(); // 释放锁}}public void printList() {lock.lock(); // 加锁try {Node current = head.forward[0];while (current != null) {System.out.println(current.key + ":" + current.value);current = current.forward[0];}} finally {lock.unlock(); // 释放锁}}public static void main(String[] args) {ConcurrentSkipList list = new ConcurrentSkipList();list.insert(3, 100);list.insert(6, 300);list.insert(4, 400);list.insert(7, 700);list.insert(5, 500);list.printList();list.delete(3);list.printList();}
}
在这个示例中,我们使用了 ReentrantLock 对象来控制对跳表的并发访问。每个公共方法在执行之前都会调用 lock.lock() 加锁,并在执行完毕后(包括正常执行和异常退出)调用 lock.unlock() 释放锁。
使用 ReentrantLock 的好处是它提供了比 synchronized 更灵活的锁定机制,例如:
-
可中断的锁定:
ReentrantLock允许线程在尝试获取锁时被中断。 -
尝试非阻塞锁定:
ReentrantLock提供了tryLock()方法,允许线程尝试获取锁而不无限等待。 -
超时获取锁:
ReentrantLock还提供了tryLock(long timeout, TimeUnit unit)方法,允许线程在指定时间内等待锁。 -
公平锁:
ReentrantLock可以选择是否使用公平锁,公平锁会按照线程请求锁的顺序来分配锁。 -
多个条件变量:
ReentrantLock可以与多个Condition对象配合使用,而synchronized只能与一个条件变量配合使用。
理解了以上代码实现原理后,我们再来理解 Redis Sorted Set 就不难了。
Redis 的 Sorted Set 是一种包含元素和关联分数的数据结构,它能够根据分数对元素进行排序。Sorted Set 在 Redis 中的内部实现可以是跳跃表(Skip List)和字典(Hash Table)的组合,或者是压缩列表(Zip List),具体使用哪种实现取决于 Sorted Set 的大小和元素的长度。
跳跃表 + 字典实现
当 Sorted Set 的元素数量较多或者元素长度较长时,Redis 使用跳跃表和字典来实现 Sorted Set。跳跃表是一种概率平衡的数据结构,它通过多级索引来提高搜索效率,类似于二分查找。字典则用于快速查找和更新操作。
跳跃表的每个节点包含以下信息:
- 元素(member)
- 分数(score)
- 后退指针(backward)
- 多层前进指针(forward),每一层都是一个有序链表
字典则存储了元素到分数的映射,以便快速访问。
压缩列表实现
当 Sorted Set 的元素数量较少(默认小于128个),并且所有元素的长度都小于64字节时,Redis 使用压缩列表来存储 Sorted Set。压缩列表是一种连续内存块的顺序存储结构,它将所有的元素和分数紧凑地存储在一起,以节省内存空间。
应用场景
Sorted Set 常用于以下场景:
- 排行榜:例如游戏中的玩家分数排名。
- 范围查询:例如获取一定分数范围内的用户。
- 任务调度:例如按照任务的优先级执行。
- 实时排名:例如股票价格的实时排名。
代码分析
在 Redis 源码中,Sorted Set 的实现主要在 t_zset.c 文件中。插入操作(zaddCommand)会根据 Sorted Set 的编码类型(跳跃表或压缩列表)来执行不同的逻辑。如果是跳跃表编码,那么插入操作会涉及到字典的更新和跳跃表节点的添加。如果是压缩列表编码,则会检查是否需要转换为跳跃表编码。
总结
Sorted Set 是 Redis 提供的一种强大的有序数据结构,它结合了跳跃表和字典的优点,提供了高效的插入、删除、更新和范围查询操作。通过合理的使用 Sorted Set,可以有效地解决许多实际问题。如何以上内容对你有帮助,恳请点赞转发,V 哥在此感谢各位兄弟的支持。88,洗洗睡了。
相关文章:

Redis Sorted Set 跳表的实现原理和分析
跳表(Skip List)是一种随机化的数据结构,基于有序链表,通过在链表上增加多级索引来提高数据的查找效率。它是由 William Pugh 在 1990 年提出的。 为什么 Redis 中的 Sorted Set 使用跳跃表 Redis 的有序集合(Sorted …...

新手教学系列——在MySQL分表中批量调整表结构的实践与优化
在当今的互联网业务中,随着数据量的不断增长,单个数据库的处理能力往往难以满足高并发、高性能的要求。因此,分库分表已经成为解决数据库扩展性问题的主流方案之一。然而,分表虽然能有效提升数据库的读写性能,但也带来了一个新的挑战:当业务需求变化时,需要对大量分表进…...
解决事务提交延迟问题:Spring中的事务绑定事件监听机制解析
目录 一、背景二、事务绑定事件介绍三、事务绑定事件原理四、结语 一、背景 实际工作中碰到一个场景,现存系统有10w张卡需要进行换卡,简单来说就是为用户生成一张新卡,批量换卡申请需要进行审核,审核通过后异步进行处理。 为什么…...

Python 异步编程的秘密武器:Asyncio
python编程中,异步编程是一个重要概念。它允许我们在等待某些操作(如网络请求或文件读写)时,不阻塞程序的其他部分运行。 在 Python 中,asyncio 是实现异步编程的强大工具。今天,我们将一同探索 asyncio 的…...

10年计算机考研408-计算机网络
【题33】下列选项中,不属于网络体系结构所描述的内容是() A.网络的层次 B.每一层使用的协议 C.协议的内部实现细节 D.每一层必须完成的功能 解析: 本题考查的是网络体系结构相关的概念。 图1描述了网络的7层架构以及每一层所要完成…...

深信服校招面试总结
许久没有更新博客,这两个月里发生的事情有些多。最近稍微稳定下来了,应该可以重新开始吧。 背景 首先感觉自己的笔试做的还行,除了第三个编程题没做出来,其他的应该都做出来了。当时忘记并查集的路径压缩怎么写了,加上…...

【LeetCode热题100】模拟
这篇博客记录了模拟相关的题目,也就是按照题目的描述写代码,很锻炼代码实现能力,包括了替换所有的问号、Z字形变换、外观数列、数青蛙4道题。 class Solution { public:string modifyString(string s) {int n s.size();for(int i 0 ; i <…...
如何在Chrome最新浏览器中调用ActiveX控件?
小编最近登陆工商银行网上银行,发现工商银行的个人网银网页,由于使用了ActiveX安全控件,导致不能用高版本Chrome浏览器打开,目前只有使用IE或基于IE内核的浏览器才能正常登录网上银行,而IE已经彻底停止更新了ÿ…...

一款好用的远程连接工具:MobaXterm
在日常工作中,作为开发者或运维人员,你是否经常需要远程连接服务器进行调试和管理?传统的SSH工具常常不够灵活,操作繁琐,无法满足日益复杂的工作需求。而MobaXterm的出现,带来了远程连接工具的全新体验。它…...
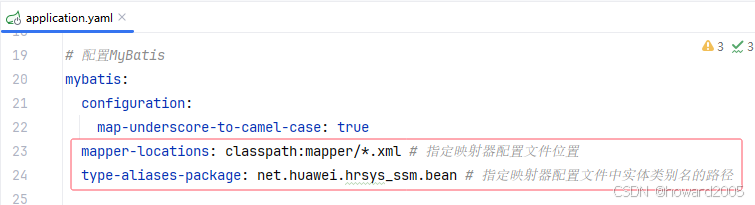
Spring Boot使用配置方式整合MyBatis
文章目录 一、实战目标二、步骤概览1. 创建部门映射器接口2. 创建映射器配置文件3. 配置全局映射器4. 测试映射器接口 三、详细步骤1、创建部门映射器接口2、创建映射器配置文件3、配置全局映射器4、测试映射器接口 四、结语 一、实战目标 在本实战课程中,我们将学…...

HarmonyOS第一课-应用程序框架基础习题答案
声明:本题库为最新的HarmonyOS第一课的学习题库,仅供参考学习! 一、判断题 1. 在基于Stage模型开发的应用项目中都存在一个app.json5配置文件、以及一个或多个module.json5配置文件。(正确) 正确(True) 错误(False) -…...

滚雪球学SpringCloud[10.2讲]:微服务项目的性能优化与调优
全文目录: 前言性能优化与调优概述性能优化的核心目标常见的性能瓶颈来源 性能瓶颈分析与调优策略1. 服务间通信优化优化策略: 2. 数据库优化优化策略: 3. 线程池优化优化策略: 4. 缓存优化优化策略: 常见问题的排查与解决1. 慢查…...
EasyExcel将数据库里面的数据生成excel文件
EasyExcel官方文档 1.在model模块导入依赖 <!-- 生成报表--> <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>4.0.3</version> </dependency> 2.修饰实体类 package…...
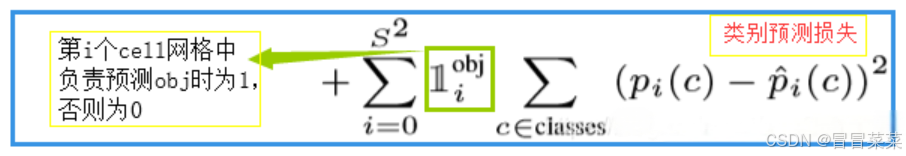
【YOLO学习】YOLOv1详解
文章目录 1. 概述2. 算法流程3. 网络结构4. 损失函数 1. 概述 1. YOLO 的全称是 You Only Look Once: Unified, Real-Time Object Detection。YOLOv1 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box 的位置和 bounding box 所属的类别。简单…...
HarmonyOS应用开发(组件库)--组件模块化开发、工具包、设计模式(持续更新)
致力于,UI开发拿来即用,提高开发效率 常量格式枚举enum格式正则表达式...手机号校验...邮箱校验 文件判断文件是否存在 网络下载下载图片从沙箱中图片转为Base64格式从资源文件中读取图片转Base64 组件输入框...矩形输入框...输入框堆叠效果(…...

python测试开发---前后端交互Axios
Axios 是一个基于 Promise 的 HTTP 客户端,常用于浏览器和 Node.js 中发送 HTTP 请求。它封装了 XMLHttpRequest 和 Node.js 的 http 模块,使得处理网络请求更加简单和直观,尤其适合处理异步请求。以下是 Axios 的基础概念和使用方法…...

删除视频最后几帧 剪切视频
删除视频最后几帧 剪切视频 remove_last.py import subprocess def remove_last_frame(input_file, output_file, frame_rate):command_duration [ffprobe,-v, error,-show_entries, formatduration,-of, defaultnoprint_wrappers1:nokey1,input_file]try:total_duration fl…...

SSM框架学习(四、SpringMVC实战:构建高效表述层框架)
目录 一、SpringMVC简介和体验 1.介绍 2.主要作用 3.核心组件和调用流程理解 4.快速体验 二、SpringMVC接收数据 1.访问路径设置 (1)精准路径匹配 (2)模糊路径匹配 (3)类和方法上添加 RequestMapp…...

戴尔笔记本电脑——重装系统
说明:我的电脑是戴尔G3笔记本电脑。 第一步:按照正常的装系统步骤,配置并进入U盘的PE系统 如果进入PE系统,一部分的硬盘找不到,解决办法:U盘PE系统——出现部分硬盘找不到的解决办法 第二步:磁…...

领夹麦克风哪个品牌音质最好,主播一般用什么麦克风
在这个信息爆炸的时代,清晰的声音传达显得尤为重要。无论是激情澎湃的演讲,还是温馨动人的访谈,一款优质的无线领夹麦克风都能让声音清晰的传播。但市场上产品繁多,如何挑选出性价比高、性能卓越的无线领夹麦克风呢?本…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

Zotero插件市场:三步快速上手的插件管理神器
Zotero插件市场:三步快速上手的插件管理神器 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 想象一下&a…...

AI Agent执行链路的安全机制:权限控制与沙箱隔离方案
AI Agent执行链路安全深度解析:权限控制与沙箱隔离全栈落地方案 摘要/引言 你有没有遇到过这些场景:刚上线的企业内部运维Agent被恶意Prompt注入后,直接调用了删除生产库的工具;你做的数据分析Agent被诱导执行了恶意Python代码,把公司的用户隐私数据传到了境外黑客服务器…...

基于Docker部署OpenOffice无头服务实现文档自动化处理
1. 项目概述与核心价值最近在折腾文档处理自动化流程,发现很多老项目或者特定场景下,对Office文档的兼容性要求极高,尤其是那些需要处理.doc、.xls、.ppt等老格式的场景。直接用现代办公套件(比如LibreOffice)去处理&a…...

All in Token,移动,电信,联通,百度,阿里,字节,华为,Token战争,Token无用:李彦宏用DAA终结了AI的度量衡之争
今年4月,AI行业出现了一组让投资人坐立难安的数据:Anthropic年化营收突破300亿美元,正式超过OpenAI的约250亿美元。但反常的是,据第三方机构估算,Claude的月活用户仅约为ChatGPT的2.44%。以及,Anthropic的模…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

从单体智能到组织智能:AgentOrg多智能体系统架构与实战
1. 项目概述:从单体智能到组织智能的范式跃迁最近在AI Agent领域,一个名为“AgentOrg”的开源项目引起了我的注意。这个由Angelopvtac发起的项目,其核心思想非常吸引人:它不再将AI Agent视为一个孤立的、执行单一任务的智能体&…...

Python邮件自动化实战:基于mymailclaw的监控报警与Slack集成
1. 项目概述与核心价值最近在折腾邮件自动化处理的时候,发现了一个挺有意思的开源项目,叫psandis/mymailclaw。乍一看这个名字,你可能会联想到“邮件抓取”或者“邮件爬虫”。没错,它的核心定位就是一个用 Python 写的邮件客户端自…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...