视频理解大模型最新进展
文章目录
- Video-LLaMA
- Vision-Language Branch
- Audio-Language Branch
- Video-ChatGPT
- MiniGPT4-video
- CogVLM2-Video
- (1)Pre-training
- (2)Post-training
- Qwen2-VL
- MA-LMM
- Chat-UniVi
- 大模型对比
Video-LLaMA
2023:阿里达摩院的一个多模态大语言模型产品
论文:https://arxiv.org/abs/2306.02858
代码:https://github.com/damo-nlp-sg/video-llama
模型结构
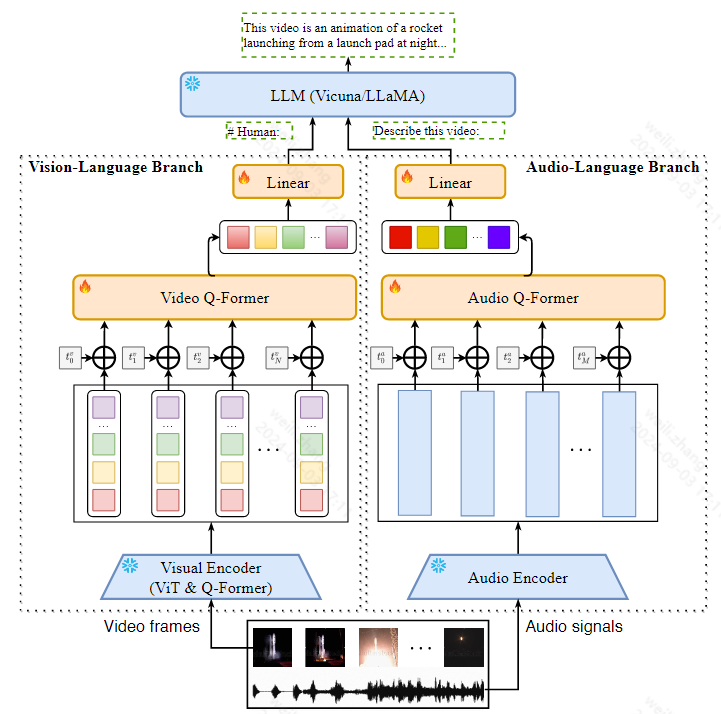
关键改进:
相比于之前的大模型单独处理视觉和语音信息,作者提出的Video-LLaMA可以同时处理视觉和语音信息
解决下述两个挑战来实现视频理解:
①捕捉视觉场景的时间变化:Video-LLaMA提出了一种视频Q-former,将预先训练好的图像编码器组装成视频编码器,并引入视频到文本的生成任务来学习视频语言的对应关系
②整合视觉和语音信息: 利用 ImageBind,一种对齐多种模式的通用嵌入模型,作为预训练的音频编码器,并在 ImageBind 之上引入音频 Q-former 来学习 LLM 模块的合理听觉查询嵌入。
Video-LLaMA包含两个分支,一个Vision-Language Branch,一个Audio-Language Branch
通过这两个分支,将视频帧和语音信号处理成与LLM文本输入兼容的query表示
(1)Vision-Language Branch
它由
-
一个冻结的预训练图像编码器组成,用于从视频帧中提取特征
-
一个位置嵌入层将时间信息注入到视频帧中
-
一个video Q-former来增强帧级表示
-
一个线性层将输出视频表示投影到与llm的文本嵌入相同的维度
其中视觉编码器是来自于EVA-CLIP的ViTG/14
视频Q-former来自BLIP-2的Q-former结构
(2)Audio-Language Branch
它由
-
一个预先训练的音频编码器
-
一个位置嵌入层,将时间信息注入音频段
-
一个音频Q-former来融合不同音频片段的特征
-
一个将音频表示映射到llm的嵌入空间的线性层
其中使用预训练的Imagebind作为音频编码器,首先从视频中统一采样 2 秒短音频剪辑的 M 个片段,然后使用 128 个梅尔谱图箱将每个 2 秒的音频剪辑转换为频谱图,在获得输入音频的频谱图列表后,音频编码器将将每个频谱图映射到一个密集向量
音频Q-former与上述视频的Q-former结构一致
为什么在处理音频的时候要将音频转为梅尔谱图?
-
符合人耳的听觉特性:梅尔频率刻度是一种非线性频率刻度,反映了人类的听觉感知特性。人耳对低频音更加敏感,而对高频音的分辨率较差。梅尔刻度在低频部分具有更高的分辨率,在高频部分具有更低的分辨率,这与人耳对声音的感知方式相似。
-
特征提取:梅尔谱图能够有效地表示音频信号的时频特征。通过傅里叶变换,音频信号从时间域转换到频率域,再通过梅尔滤波器组将频谱转换为梅尔频率刻度,从而得到梅尔谱图。这种表示方式保留了音频的频率成分,同时减少了数据的维度,非常适合用作机器学习和深度学习模型的输入。
-
降维和去噪:相比原始音频波形,梅尔谱图通过对频率进行分组和平滑处理,能够减少高频噪声和冗余信息,有助于模型更好地学习到音频的主要特征,提高模型的性能和泛化能力。
-
更易处理和分析:梅尔谱图是一种视觉上更易解释的二维表示,便于人类观察和分析。它不仅在时间轴上展示了频率变化,还能通过颜色和强度反映出声音的能量变化,使得音频的时频结构一目了然
训练过程
为了将视觉和音频编码器的输出与LLM的嵌入空间对齐,首先在海量视频/图像标题对上训练VideoLLaMA,然后用中等数量但更高质量的视觉指令数据集调整我们的模型
Vision-Language Branch
第一阶段: 使用下述数据集进行预训练
| 数据集 | 描述 |
|---|---|
| Webvid-2M | 一个大规模的短视频数据集 |
| CC595k | CC595k |
在预训练阶段采用视频到文本生成任务,即给定视频的表示,提示冻结的LLM生成相应的文本描述
第二阶段: 使用高质量的指令数据对模型进行微调
数据集:将MiniGPT4的图像细节描述数据集、LLAVA 的图像指令数据集和Video-Chat的视频指令数据集集成在一起
Audio-Language Branch
音频语言分支中可学习参数的目标是将冻结音频编码器的输出嵌入与LLM的嵌入空间对齐
由于音频文本数据的稀缺,作者这里直接将音频与视觉文本数据对齐,进行训练,训练过程同Vision-Language Branch
局限性
-
性能受到当前训练数据集的质量和规模的限制
-
处理长视频的能力有限
-
Video-LLaMA继承了冻结llm的幻觉问题
Video-ChatGPT
2023
论文:https://arxiv.org/abs/2306.05424
代码:https://github.com/mbzuai-oryx/Video-ChatGPT
模型结构
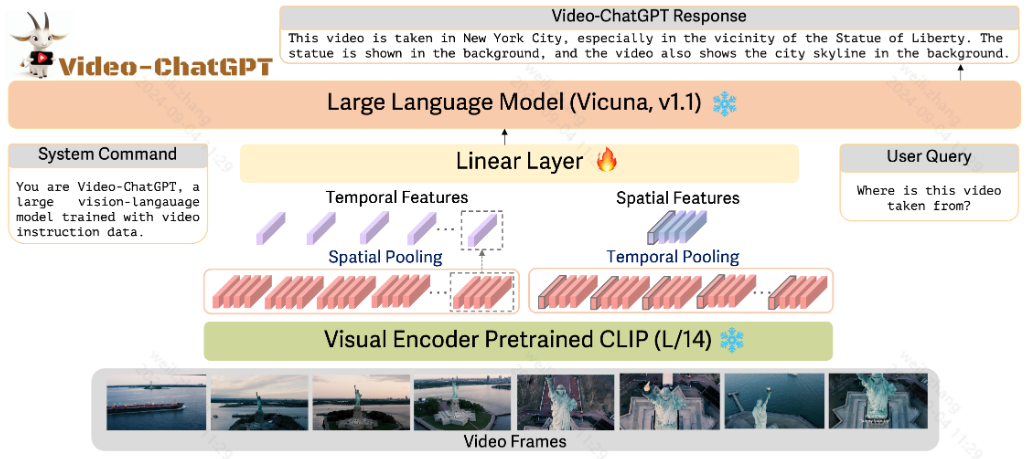
① 使用 LLAVa预训练的CLIP ViT-L/14 作为视觉编码器,将视频帧输入编码器生成帧级表示
② 然后在空间维度上进行池化,得到视频级时间表示
③ 类似地,帧级嵌入沿时间维度平均池化以产生视频级空间表示
④ 将上述得到的视频级时间表示和视频级空间表示进行合并,合并之后的特征通过一个简单的可训练线性层 投影到语言解码器的嵌入空间中,将它们转换为相应的语言嵌入标记
⑤ 使用 LLAVA作为基座模型
训练
Video Instruction Tuning:
微调模板:
USER: <Instruction> <Vid-tokens> #
Assistant:
# ‒ <Instruction>表示与视频相关的问题,从video-question-answer的训练集中随机采样
在训练期间,视频编码器和 LLM 的权重保持不变,并且模型通过调整线性层来最大化预测表示答案的标记的可能性
Video Instruction Data Generation:
-
人工辅助标注,包括专家标注者分析视频内容并提供详细的描述
-
利用半自动注释框架,利用最先进的视觉语言模型,该方法生成广泛的、高容量的注释,从而在不影响质量的情况下大幅提高数据量。
-
具体步骤:
-
① 为所有现成的模型维护一个高预测阈值,以保持准确性
-
② 将BLIP-2 或者 GRiT中生成的帧级描述与Tag2Text生成的帧级标签不匹配的帧级描述过滤掉
-
③ 使用GPT-3.5模型合并上述的帧级描述生成单一的、连贯的视频级描述
-
④ 上述得到的视频级描述会合并到原始描述中,来扩充原始视频描述
-
评估
-
引入了一个基准来评估基于视频的对话模型的文本生成性能,基于 ActivityNet-200 数据集策划了一个测试集,其中包含来自人工注释的丰富、密集的描述性字幕和相关问答对的视频
-
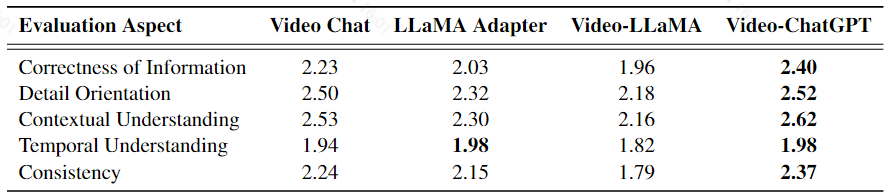
使用 GPT-3.5 模型开发了一个评估管道,该管道评估模型的各种能力,并为生成的预测分配一个1-5的相对分数,包含Correctness of Information、Detail Orientation、Contextual Understanding、Temporal Understanding、Consistency五个方面
不足:
-
不能理解长视频中的时间关系(大于2分钟的视频)
-
不能识别物体细节
MiniGPT4-video
2024
论文:http://arxiv.org/abs/2404.03413.pdf
代码:https://github.com/Vision-CAIR/MiniGPT4-video
在线体验:MiniGPT4 Video - a Hugging Face Space by Vision-CAIR
模型结构
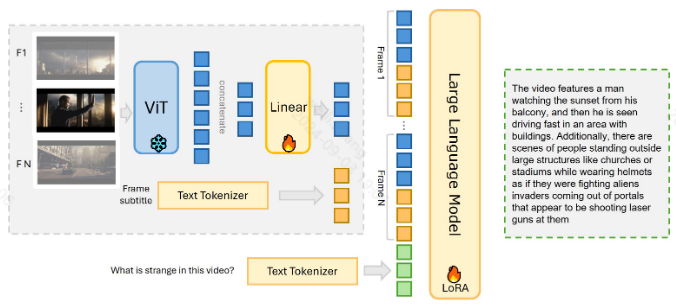
视觉编码器使用的时frozen的EVA-CLIP,大语言模型作者尝试了llama2和Mistral模型
具体流程如下:
① 首先,对视频帧采样,由于LLM上下文窗口施加的限制,每个视频会经历帧子采样,帧数(N)由LLM的上下文窗口决定
② 随后,使用预训练模型EVA-CLIP将视觉帧与文本描述对齐,这里作者还对每帧图片做了细致的处理,与MiniGPT-v2类似,将每个图像中的每四个相邻的视觉标记压缩为单个标记,从而将每张图像的标记计数减少75%,从256减少到64
③ 然后使用线性层映射到大型语言模型空间与文本拼接,进行生成任务
训练
在训练期间,字幕由数据集提供,但在推理时或视频没有字幕时,利用语音到文本模型(如whisper)来生成视频的字幕
第一阶段:Large-scale image-text pair pretraining
只训练了一个线性层,将视觉编码器(EVACLIP )编码的视觉特征投影到具有文本生成损失的 LLM 的文本空间中
第二阶段:Large-scale video-text pair pretraining
在第二阶段,模型的输入为多帧,从每个视频中采样最多 N 帧
采样帧数取决于每个语言模型的上下文窗口,比如 Llama 2,上下文窗口为 4096 个token,用 64 个token表示每张图像。因此,对于 Llama 2,当指定 N=45 帧时,相当于 有2880 个标记。然后字幕分配 1000 个标记,其余标记被标记用于模型输出
使用以下模板中的预定义提示:
<s>[INST]<Img><FrameFeature_1><Sub><Subtitle text_1>... <Img> <FrameFeature_N><Sub><Subtitle text_N><Instruction></INST>
其中:
:由视觉主干编码的采样视频帧
:表示对应帧的字幕
:从预定义的指令集中随机采样的指令,比如”Briefly describe these video“
微调阶段:Video question answering instruction finetuning
在这个阶段,作者采用了第二阶段实现的相同训练策略,但专注于利用高质量的视频问答数据集进行指令微调。这种微调阶段有助于增强模型对输入视频的解释并生成对相应问题的精确响应的能力。模板与第二阶段相同,被Video-ChatGPT数据集中提到的一般问题所取代
数据集:
| 数据集 | 描述 |
|---|---|
| Condensed Movies Video Captions (CMD) | 包含大约 15,938 个视频,每个视频的长度跨越 1 到 2 分钟。然而,CMD 的标题表现出有限的质量,其特征是平均句子长度为 14 个单词 |
| WebVid | 拥有大量 200 万个视频 |
| Video Instruction Dataset | 100,000个问答对分布在13,224个视频中,并且有细致的注释来区分 |
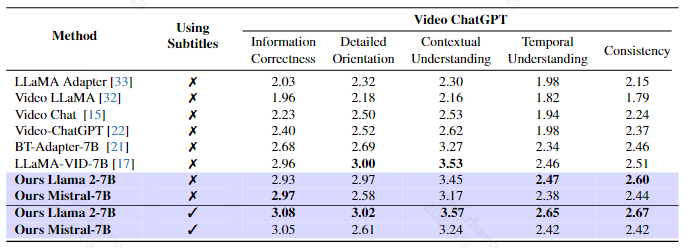
结果:
评估指标用的是video-chatgpt提出的评估指标
CogVLM2-Video
2024:智谱发布
论文:https://arxiv.org/pdf/2408.16500
github:https://github.com/THUDM/CogVLM2/blob/main/README_zh.md
在线体验:http://cogvlm2-online.cogviewai.cn:7868/
模型结构

包含四个模块:
-
视觉转换器 (ViT) 编码器:CogVLM-17B预训练的EVA2-CLIP-E
-
adapter 适配器:a two-layer MLP
-
预训练的大型语言模型 :使用LLaMA3-8B作为基座模型
-
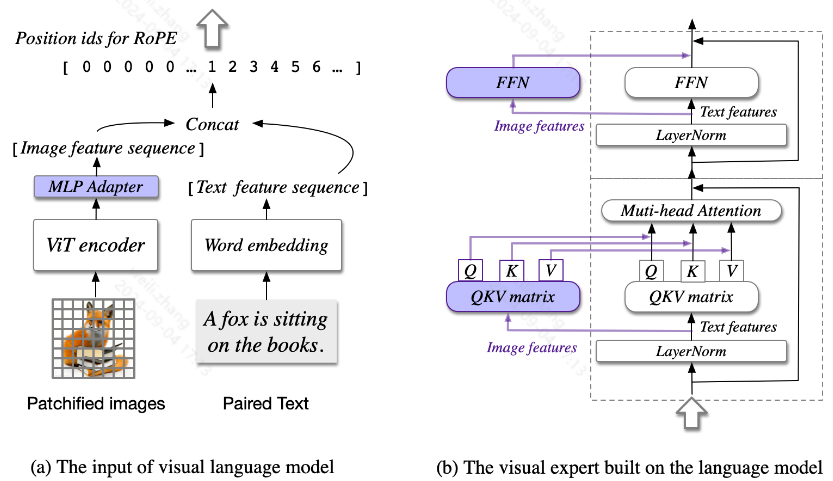
视觉专家模块:在每一层都添加了一个视觉专家模块,以实现深度视觉语言特征对齐。具体来说,每一层的视觉专家模块由 QKV 矩阵和每一层的 MLP 组成。QKV 矩阵和 MLP 的形状与预训练语言模型的形状相同,并从它们初始化。动机是语言模型中的每个注意力头都捕获了语义信息的某个方面,而可训练的视觉专家可以转换图像特征以与不同的头部对齐,从而实现深度融合。
关键改进:
在视频中感知时间戳信息,从而实现时间定位和相关的问答,具体来说,从输入视频片段中提取帧并用时间戳信息对其进行注释,从而允许后续的语言模型准确地知道每帧对应于原始视频的确切时间
解决下述挑战:
-
现有方法虽然有效地压缩了视频信息,但缺乏时间定位、时间戳检测和总结关键时刻的能力
-
使用现有的时间真实注释数据训练的视频理解模型受到数据范围和固定格式的限制,导致缺乏开放域问答和处理能力
训练
(1)Pre-training
现有图像-文本对数据集包含很多噪声,作者提出下述两种处理方法:
- Iterative Refinement
① 首先,初始模型在公开可用的数据集上进行训练
② 用上述训练后的模型重新标记一批新数据
③ 对新数据进行细致的手动校正以确保其准确性
④ 随后使用校正后的数据迭代地改进和增强模型的未来版本
这个迭代过程促进了训练数据质量的不断提高,因此模型的性能也是如此
- Synthetic Data Generation
根据特定规则合成数据或利用高级工具生成高质量的图像-文本对来创建部分数据集
预训练方法:
方法①:在预训练阶段,逐步启用更多的可训练参数;确保模型可以在不损害其预先存在的语言能力的情况下无缝地集成图像模态
方法②:同时训练所有参数,但同时使用语言预训练数据和视觉语言预训练数据;确保模型接触到平衡的数据类型混合,从而保持其语言能力,同时有效地结合视觉信息
方法③:逐渐增加输入图像分辨率;这种分辨率的逐渐增加允许模型捕获和理解图像中更精细的细节,从而增强其整体视觉理解能力
(2)Post-training
因为视频-文本数据集非常稀缺,但是标注成本非常昂贵,作者开发了一个全自动视频问答数据生成过程:

具体流程如下:
① 首先从视频中提取帧,然后用CogVLM2为每个帧生成图像描述
② 然后使用GPT-4o来评估每个视频的图像描述序列,识别场景内容变化显著的视频描述序列,过滤掉场景内容变化较小的视频描述序列
③ 最后,使用few-shot方法,GPT-4o根据图像描述序列生成与时间相关的问答对,构建了数据集TQA
Image Supervised Fine-tuning:
采用了两阶段 SFT 训练方法:
在第一阶段,利用所有 VQA 训练数据集和 300K 对齐语料库来增强模型的基本能力,解决了预训练对图像字幕任务的局限性
在第二阶段,选择了 VQA 数据集的子集和 50K 偏好对齐数据来优化模型的输出风格,与人类偏好密切相关
**Video Supervised Fine-tuning:**训练过程包括两个阶段:指令调优和时间序列调优
-
在指令调优阶段,主要使用VideoChat2中提供的指令数据,还收集了一个内部视频 QA 数据集,以实现更好的时间理解,在指令调整中总共使用了 330k 个视频样本
-
在时间序列调优阶段,在 TQA 数据集上进行训练
数据集:
评估
评估指标:
| 指标 | 说明 |
|---|---|
| MVBench | 由20项单帧无法有效解决的视频任务组成,用于全面评测现有多模态模型的视频理解能力 |
| VideoChatGPTBench | VideoChatGPT中提出的基于5个方面对视频理解大模型进行打分的评测指标 |
| LVBench | 由公开来源的视频组成,包含一系列旨在理解长视频和提取信息的不同任务,旨在检测多模态模型的长期记忆和扩展理解能力 |
评估结果:

Qwen2-VL
2024
在线体验:https://huggingface.co/spaces/Qwen/Qwen2-VL
github:https://github.com/QwenLM/Qwen2-VL
论文待公开
模型架构
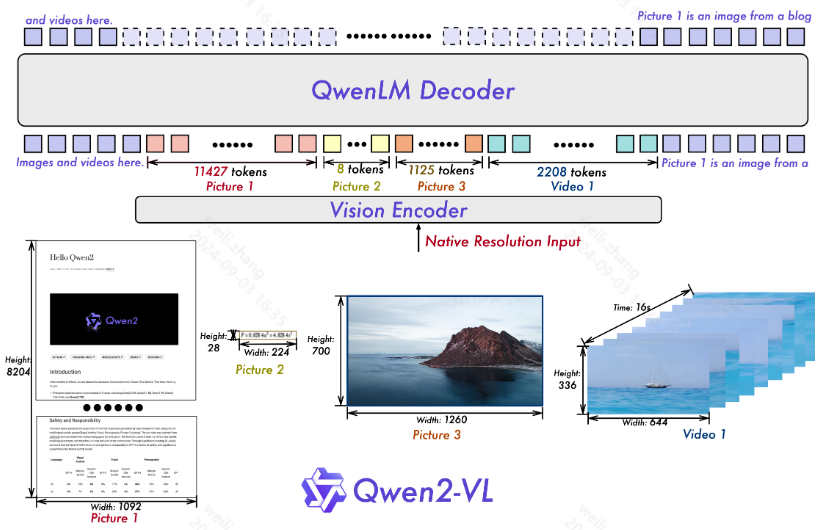
核心架构:Vision Transformer (ViT) 模型和 Qwen2 语言模型
关键改进:
-
实现了 Naive Dynamic Resolution 支持,wen2-VL 可以处理任意图像分辨率,将它们映射到动态数量的视觉标记,从而确保模型输入与图像中固有信息之间的一致性。这种方法更接近于人类视觉感知,使模型能够处理任何清晰度或大小的图像
-
实现了**多模态旋转位置嵌入 (M-ROPE),**通过将原始旋转嵌入解构为代表时间和空间(高度和宽度)信息的三个部分,M-ROPE 使 LLM 能够同时捕获和整合 1D 文本、2D 视觉和 3D 视频位置信息
具体实现
待补充
MA-LMM
论文:https://arxiv.org/pdf/2404.05726
代码:GitHub - boheumd/MA-LMM: (2024CVPR) MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
模型框架
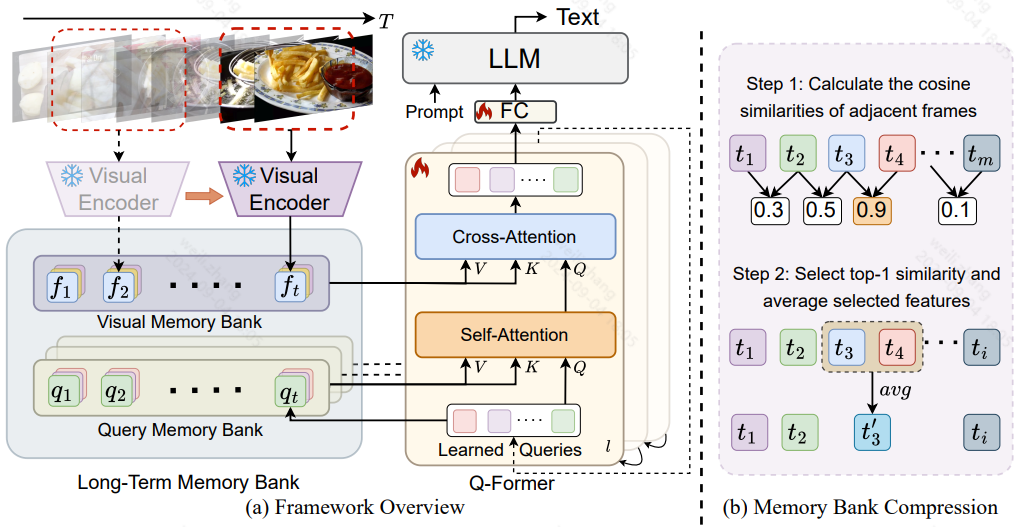
作者创新点:
为了解决长视频理解问题,不同于现有工作同时处理多帧,作者提出一个在线处理的方法,通过memory bank来存储之前的视频信息,使模型能够参考历史视频内容进行长期分析,而不会超出LLMs的上下文长度限制或 GPU 内存限制
模型架构被分为三部分:
①用一个冻结的视觉特征编码器来提取视觉特征:EVA-CLIP预训练的ViT-G/14
②使用可训练Q-Former(来自InstructBLIP)进行长期时间建模,以对齐视觉和文本嵌入空间
③ 一个冻结的大语言模型作为解码器:Vicuna-7B
Long-term Temporal Modeling:
-
对于当前时间步 t,visual memory bank包含过去视觉特征的串联列表,给定输入查询 Q,视觉memory bank充当键和值
-
visual memory bank累积了每个时间步的输入查询,通过存储这些查询,维护模型对截至到当前步骤的每一帧理解和处理的动态内存
Memory Bank Compression:
利用相邻特征之间的相似性,随着时间的推移聚合和压缩视频信息,从而保留早期历史信息,这种方法有效地压缩了记忆库中的重复信息,同时保留了判别特征
具体操作:
①维护一个memory bank长度(一般是预定义的)
②如果新加入一个视频帧,超过了上述长度,则计算加入之后的所有memory bank里面的视频帧之间的相似度
③选择相似度最大的两个帧进行合并,合并方式是相加除以2
④通过这种方式能保留最具区分性的特征
数据集:
长期视频理解:包括 LVU、Breakfast 和 COIN ,将 top1 分类准确率作为评估指标进行报告。
Chat-UniVi
论文:https://arxiv.org/pdf/2311.08046
模型架构
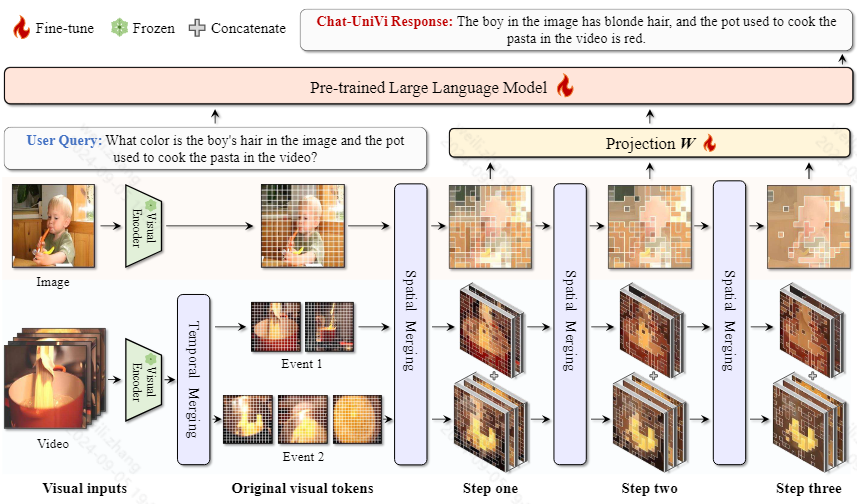
作者创新点:
在有限的视觉tokens场景下,现存方法在同时处理图像和视频方面存在挑战
基于上述问题,作者提出:
-
一种统一的视觉语言模型,能够通过统一的视觉表示理解和参与涉及图像和视频的对话。
-
具体来说,作者使用一组动态视觉标记来统一表示图像和视频。该表示框架使模型能够有效地利用有限数量的视觉标记来同时捕获图像所需的空间细节和视频所需的综合时间关系。
-
此外,利用多尺度表示,使模型能够感知高级语义概念和低级视觉细节。
-
值得注意的是,ChatUniVi 在包含图像和视频的混合数据集上进行训练,允许直接应用于涉及两种媒体的任务,而不需要任何修改
Dynamic Visual Tokens for Image and Video:
这里,作者认为vit在划分图像的时候,认为每个部分的重要性都是相同的,即所有patch的重要程度一样,作者认为可以合并非必要的标记
具体合并操作:
① 首先用CLIP提取一个初步的视觉特征
② 然后再利用DPC-KNN,基于最近邻的密度峰值聚类算法,对视觉标记进行聚类
③ 找到聚类中心,根据欧式距离将对应的token分配到最近的聚类中心
④ 最后,利用每个集群内的平均toekn来表示相应的集群,合并token的视觉区域是对应簇中视觉区域的并集。
Temporal Visual Token Merging:
论文里面这一块好像跟上面没什么特别的,得到视频中每一帧的特征表示,然后对帧表示执行跟上述token一样的操作
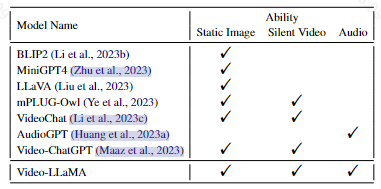
大模型对比
| 模型 | 视觉编码器 | 对齐模块 | 生成器 | 优点 | 缺点 | 训练数据量 |
|---|---|---|---|---|---|---|
| Video-LLaMA | vit+qformer | 一个简单的线性层 | llama | 加入了语音信息 | * 性能受到当前训练数据集的质量和规模的限制 * 处理长视频的能力有限 * Video-LLaMA继承了冻结llm的幻觉问题 | |
| Video-ChatGPT | CLIP ViT-L/14 +分别提取视觉特征的空间维度的特征和时间维度的特征 | 简单的线性层 | llava | 开发了第一个用于对视频对话模型进行基准测试的定量视频对话评估框架 | * 不能理解长视频中的时间关系(大于2分钟的视频) * 不能识别物体细节 | |
| MiniGPT4-video | EVA-CLIP+视觉token处理(四个一组进行压缩) | 简单的线性层 | llama2或者Mistral | 将视频中的语音转成文本用进来了 | 长视频处理能力有限(不到三分钟) | |
| CogVLM2-Video | vit | 通过注意力和 FFN 层的可训练视觉专家模块弥合冻结预训练语言模型和图像编码器之间的差距 | LLaMA3-8B | 考虑了视频中的时间戳信息,充分的利用了时间维度 | ||
| Qwen2-VL | vit | / | qwen2 | 支持任意图像分辨率输入;多模态旋转位置嵌入 |
相关文章:
视频理解大模型最新进展
文章目录 Video-LLaMAVision-Language BranchAudio-Language Branch Video-ChatGPTMiniGPT4-videoCogVLM2-Video(1)Pre-training(2)Post-training Qwen2-VLMA-LMMChat-UniVi大模型对比 Video-LLaMA 2023:阿里达摩院的…...

cocos creator 使用 protobuf 的步骤与注意事项
移除可能曾安装过的protobuf // 移除全局 npm remove -g protobufjs npm remove -g protobufjs-cli npm remove -g pbjs // 移除项目中的 npm remove --save protobufjs npm remove --save protobufjs-cli npm remove --save pbjs全局安装 npm i -g protobufjs //或者 cnpm …...

mac访达查找文件目录
mac访达查找文件目录 在Mac上使用访达(Finder)查找文件或目录的方法如下: 打开访达。 在访达窗口的侧边栏中,选择“ Go to Folder”(转到文件夹)选项,或者使用快捷键ShiftCommandG打开一个对…...

【数据结构】点分治 点分树
求树上长度小于等于k的路径 #include <iostream> #include <cstring> #include <algorithm>using namespace std;const int N 10010, M N * 2;int n, m; int h[N], e[M], w[M], ne[M], idx; //邻接表 bool st[N]; //记录每个点是否被删掉 int p[N]; //存储…...

K8s Calico替换为Cilium,以及安装Cilium过程(鲁莽版)
迁移CNI插件的3种办法: 1、创建一个新的集群,通过Gitops的方式迁移负载,然而,这可能涉及大量的准备工作和潜在的中断。 2、另一种方法是重新配置/etc/cni/net.d/指向Cilium。但是,现有的pod仍将由旧的…...

背景图鼠标放上去切换图片过渡效果
文章目录 css鼠标放上去之前效果鼠标放上去时效果 css <li class"message"></li>.message {width: 22px;height: 22px;background-image: url(/assets/message-01.png);background-size: cover;background-position: center;transition: background-ima…...

【Linux】当前进展
驱动层日志添加了下文件目录,函数,代码行的打印(这里要小心,驱动目录源代码打印日志里边添进程号可能有问题,因为在驱动初始化的时候,内核还没有创建进程,不过猜测可以先不打印进程相关信息&…...

阿里云云效多个ssh密钥对配置
实现功能 windows本地多个ssh密钥对,分别对应不同的阿里云账号的云效 实现办法 1.生成ssh密钥对 ssh-keygen -t rsa -f C:\xxx\id_rsa_customname(我这里C:\Users\admin\.ssh\id_rsa_customname) 2.配置.ssh目录的config文件 # ruiyi Host customnameHostName codeup.al…...

前后端跨域问题及其在ThinkPHP中的解决方案
在现代Web开发中,前后端分离的架构越来越普遍,但这也带来了跨域问题。跨域指的是在一个域下的网页试图请求另一个域的资源,浏览器出于安全考虑会限制这种行为。本文将探讨如何在ThinkPHP中解决跨域问题。 #### 1. 什么是跨域? 跨…...
)
基于CentOS7上安装MicroK8s(最小生产的 Kubernetes)
简介 MicroK8s是一个轻量级的Kubernetes发行版,其内存和存储要求远低于全尺寸Kubernetes集群。它可以在几分钟内通过一条命令快速创建功能齐全的Kubernetes集群,极大地简化了部署过程。 兼容性:MicroK8s与Kubernetes全面兼容,确保用户可以无缝迁移和扩展他们的应用程序。 …...

从《GTA5》的反外挂斗争看网络安全的重要性
摘要: 在网络游戏的世界里,外挂(作弊软件)一直是破坏游戏公平性和玩家体验的一大难题。作为一款深受全球玩家喜爱的游戏,《GTA5》(Grand Theft Auto V)在线模式也不例外地遭遇了外挂问题。本文将…...

python如何将字符转换为数字
python中的字符数字之间的转换函数 int(x [,base ]) 将x转换为一个整数 long(x [,base ]) 将x转换为一个长整数 float(x ) 将x转换到一个浮点数 complex(real [,imag ]) 创建一个复数 str(x ) 将对象 x 转换为字…...

TikTok流量不佳:是网络环境选择不当还是其他原因?
TikTok,作为全球短视频社交平台的佼佼者,每天都有海量的内容被上传和分享。然而,很多用户和内容创作者发现,他们的TikTok视频流量并不理想。这引发了一个问题:TikTok流量不佳,是因为网络环境选择不当&#…...

QT菜单栏设计(二级菜单栏)
目的:创建一级菜单栏,添加对应选项,并向一级菜单栏中添加二级菜单栏选项。 #include "mainwindow.h" #include "ui_mainwindow.h"MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), ui(new Ui::MainWindo…...

网站建设中,常用的后台技术有哪些,他们分别擅长做什么网站平台
PHP、Python、JavaScript、Ruby、Java和.NET各自适用于不同类型的网站平台。以下是对这些编程语言适用场景的具体介绍: PHP Web开发:PHP是一种广泛使用的开源服务器端脚本语言,特别适合Web开发。全球有超过80%的网站使用PHP作为服务器端编程语…...

【线程】POSIX信号量---基于环形队列的生产消费者模型
信号量概念 这篇文章是以前写的,里面讲了 System V的信号量的概念,POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。 但POSIX可以用于线程间同步。 信号量的概念 POSIX信号量的接口 初始化…...

Excel 设置自动换行
背景 版本:office 专业版 11.0 表格内输入长信息,发现默认状态时未自动换行的,找了很久设置按钮,遂总结成经验帖。 操作 1)选中需设置的单元格/区域/行/列。 2)点击【开始】下【对齐方式】中的【自动换…...

UNI-SOP使用说明
UNI-SOP提供了两个集成客户端:SpringBoot2.x/JAVA1.8和SpringBoot3.x/JAVA17,满足不同项目的集成需求。 平台接入 使用UNI-SOP之前,业务平台需要进行接入,完成校验后才能正常使用,先引入客户端开发SKD包。 <depen…...

记录-java web 生成并下载zip文件
java生成zip文件,zip文件分两种:一种是包含文件夹、一种是不包含文件夹 生成zip文件的方式 ZipOutputStream zipOutputStream new ZipOutputStream(response.getOutputStream());// 文件夹名称String folder "download/";ZipEntry ze new Z…...

大数据集群部署文档
大数据集群部署文档 注意:需配合大数据集群启动&检查文档进行部署,以便可以检验每一个组件是否部署成功。 文章目录 大数据集群部署文档一、部署前准备1. 确保所有机器可以访问外网2. 配置root用户ssh连接3. 解决Vmware ESXi 6.5 Ubuntu虚拟机ssh连…...

开发者专属提示词库:提升AI协作效率的实战指南
1. 项目概述:一个为开发者量身定制的提示词宝库如果你是一名开发者,无论是前端、后端、运维还是算法工程师,我相信你都或多或少地接触过像 ChatGPT 这类大型语言模型。它们能写代码、解 Bug、解释概念,甚至帮你设计架构。但很多时…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具
ncmdumpGUI:解锁网易云音乐格式限制的智能解密工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,我们经常面临一个尴…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

AI驱动的Web可访问性审查:LLM如何成为你的自动化无障碍专家
1. 项目概述:一个为AI智能体而生,却意外照亮了所有人的可访问性审查工具 最近在折腾AI智能体(AI Agent)的开发,一个老问题又浮上水面:怎么确保我造出来的这个“数字员工”,能真正服务好所有人&…...

CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题
CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/…...
)
中文长文本语音崩溃?ElevenLabs API超时/截断/静音突变?20年语音架构师紧急发布的6行容错重试+分段重对齐代码(已验证10万+字符稳定输出)
更多请点击: https://intelliparadigm.com 第一章:中文长文本语音崩溃的根因诊断与现象复现 中文长文本语音合成(TTS)在处理超长段落(如 >3000 字)时频繁出现进程中断、内存溢出或静音输出,…...

Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率
Seraphine终极指南:英雄联盟智能助手如何提升您的游戏胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的激烈对局中,错过对局接受、BP阶段犹豫不决、缺乏队友对手信息&a…...

AXI交叉开关IP核:SoC内部高并发数据传输的核心枢纽设计与实战
1. 项目概述:一个高效、可配置的片上总线交叉开关在复杂的数字系统设计,尤其是片上系统(SoC)领域,多个主设备(如CPU、DMA控制器)需要同时访问多个从设备(如内存、外设控制器…...

基于RAG的智能知识库问答系统:从原理到部署实战
1. 项目概述:当AI大模型遇见知识库,一个开源的智能问答解决方案 最近在折腾一个很有意思的开源项目,叫 zhimaAi/chatwiki 。光看名字,你大概能猜到它的核心: chat 代表对话, wiki 代表知识库。没错&a…...