高性能分布式搜索引擎Elasticsearch详解
♥️作者:小宋1021
🤵♂️个人主页:小宋1021主页
♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!
🎈🎈加油! 加油! 加油! 加油
🎈欢迎评论 💬点赞👍🏻 收藏 📂加关注+!
目录
初识elasticsearch
认识和安装
安装elasticsearch
安装Kibana
倒排索引
正向索引
倒排索引
正向和倒排
基础概念
文档和字段
索引和映射
mysql与elasticsearch
IK分词器
安装IK分词器
使用IK分词器
拓展词典
总结
在我们的项目之中搜索肯定是访问频率最高的页面之一。目前搜索功能是基于数据库的模糊搜索来实现的,存在很多问题。
首先,查询效率较低。
由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很差。表中仅仅有不到9万条数据,基于数据库查询时,搜索接口的表现如图:

改为基于搜索引擎后,查询表现如下:

需要注意的是,数据库模糊查询随着表数据量的增多,查询性能的下降会非常明显,而搜索引擎的性能则不会随着数据增多而下降太多。目前仅10万不到的数据量差距就如此明显,如果数据量达到百万、千万、甚至上亿级别,这个性能差距会非常夸张。
其次,功能单一
数据库的模糊搜索功能单一,匹配条件非常苛刻,必须恰好包含用户搜索的关键字。而在搜索引擎中,用户输入出现个别错字,或者用拼音搜索、同义词搜索都能正确匹配到数据。
综上,在面临海量数据的搜索,或者有一些复杂搜索需求的时候,推荐使用专门的搜索引擎来实现搜索功能。
目前全球的搜索引擎技术排名如下:

排名第一的就是我们今天要学习的elasticsearch.
elasticsearch是一款非常强大的开源搜索引擎,支持的功能非常多,例如:

通过今天的学习大家要达成下列学习目标:
-
理解倒排索引原理
-
会使用IK分词器
-
理解索引库Mapping映射的属性含义
-
能创建索引库及映射
-
能实现文档的CRUD
初识elasticsearch
Elasticsearch的官方网站如下:
Elasticsearch:官方分布式搜索和分析引擎 | Elastic
本章我们一起来初步了解一下Elasticsearch的基本原理和一些基础概念。
认识和安装
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
-
Elasticsearch:用于数据存储、计算和搜索
-
Logstash/Beats:用于数据收集
-
Kibana:用于数据可视化
整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等等:

整套技术栈的核心就是用来存储、搜索、计算的Elasticsearch,因此我们接下来学习的核心也是Elasticsearch。
我们要安装的内容包含2部分:
-
elasticsearch:存储、搜索和运算
-
kibana:图形化展示
首先Elasticsearch不用多说,是提供核心的数据存储、搜索、分析功能的。
然后是Kibana,Elasticsearch对外提供的是Restful风格的API,任何操作都可以通过发送http请求来完成。不过http请求的方式、路径、还有请求参数的格式都有严格的规范。这些规范我们肯定记不住,因此我们要借助于Kibana这个服务。
Kibana是elastic公司提供的用于操作Elasticsearch的可视化控制台。它的功能非常强大,包括:
-
对Elasticsearch数据的搜索、展示
-
对Elasticsearch数据的统计、聚合,并形成图形化报表、图形
-
对Elasticsearch的集群状态监控
-
它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
安装elasticsearch
通过下面的Docker命令即可安装单机版本的elasticsearch:
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
注意,这里我们采用的是elasticsearch的7.12.1版本,由于8以上版本的JavaAPI变化很大,在企业中应用并不广泛,企业中应用较多的还是8以下的版本。
如果拉取镜像困难,可以直接导入提供的镜像tar包:

安装完成后,访问9200端口,即可看到响应的Elasticsearch服务的基本信息:

安装Kibana
通过下面的Docker命令,即可部署Kibana:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
如果拉取镜像困难,可以直接导入资料提供的镜像tar包:

安装完成后,直接访问5601端口,即可看到控制台页面:

选择Explore on my own之后,进入主页面:

然后选中Dev tools,进入开发工具页面:

倒排索引
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。那么什么是倒排索引呢?
倒排索引的概念是基于MySQL这样的正向索引而言的。
正向索引
我们先来回顾一下正向索引。
例如有一张名为tb_goods的表:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此我们根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
比如用户的SQL语句为:
select * from tb_goods where title like '%手机%';
那搜索的大概流程如图:

说明:
-
1)检查到搜索条件为
like '%手机%',需要找到title中包含手机的数据 -
2)逐条遍历每行数据(每个叶子节点),比如第1次拿到
id为1的数据 -
3)判断数据中的
title字段值是否符合条件 -
4)如果符合则放入结果集,不符合则丢弃
-
5)回到步骤1
综上,根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
倒排索引
倒排索引中有两个非常重要的概念:
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
-
将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
-
创建表,每行数据包括词条、词条所在文档id、位置等信息
-
因为词条唯一性,可以给词条创建正向索引
此时形成的这张以词条为索引的表,就是倒排索引表,两者对比如下:
正向索引
| id(索引) | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
倒排索引
| 词条(索引) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
倒排索引的搜索流程如下(以搜索"华为手机"为例),如图:

流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
-
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
-
-
缺点:
-
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
-
倒排索引:
-
优点:
-
根据词条搜索、模糊搜索时,速度非常快
-
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
-
基础概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
文档和字段
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "华为小米充电器",
"price": 49
}
{
"id": 4,
"title": "小米手环",
"price": 299
}
因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
索引和映射
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等:

所有文档都散乱存放显然非常混乱,也不方便管理。
因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:
商品索引
{
"id": 1,
"title": "小米手机",
"price": 3499
}{
"id": 2,
"title": "华为手机",
"price": 4999
}{
"id": 3,
"title": "三星手机",
"price": 3999
}
用户索引
{
"id": 101,
"name": "张三",
"age": 21
}{
"id": 102,
"name": "李四",
"age": 24
}{
"id": 103,
"name": "麻子",
"age": 18
}
订单索引
{
"id": 10,
"userId": 101,
"goodsId": 1,
"totalFee": 294
}{
"id": 11,
"userId": 102,
"goodsId": 2,
"totalFee": 328
}
-
所有用户文档,就可以组织在一起,称为用户的索引;
-
所有商品的文档,可以组织在一起,称为商品的索引;
-
所有订单的文档,可以组织在一起,称为订单的索引;
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
如图:

那是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长之处:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性

IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
安装IK分词器
方案一:在线安装
运行一个命令即可:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
然后重启es容器:
docker restart es
方案二:离线安装
如果网速较差,也可以选择离线安装。
首先,查看之前安装的Elasticsearch容器的plugins数据卷目录:
docker volume inspect es-plugins
结果如下:
[
{
"CreatedAt": "2024-11-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
找到课前资料提供的ik分词器插件,课前资料提供了7.12.1版本的ik分词器压缩文件,你需要对其解压:

然后上传至虚拟机的/var/lib/docker/volumes/es-plugins/_data这个目录:

最后,重启es容器:
docker restart es
使用IK分词器
IK分词器包含两种模式:
-
ik_smart:智能语义切分 -
ik_max_word:最细粒度切分
我们在Kibana的DevTools上来测试分词器,首先测试Elasticsearch官方提供的标准分词器:
POST /_analyze
{
"analyzer": "standard",
"text": "程序员学习java太棒了"
}
结果如下:
{
"tokens" : [
{
"token" : "程",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "序",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "学",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "习",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "太",
"start_offset" : 11,
"end_offset" : 12,
"type" : "<IDEOGRAPHIC>",
"position" : 8
},
{
"token" : "棒",
"start_offset" : 12,
"end_offset" : 13,
"type" : "<IDEOGRAPHIC>",
"position" : 9
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "<IDEOGRAPHIC>",
"position" : 10
}
]
}
可以看到,标准分词器智能1字1词条,无法正确对中文做分词。
我们再测试IK分词器:
POST /_analyze
{
"analyzer": "ik_smart",
"text": "程序员学习java太棒了"
}
执行结果如下:
{
"tokens" : [
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 3
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 4
}
]
}
拓展词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“泰裤辣”,“传智播客” 等。
IK分词器无法对这些词汇分词,测试一下:
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "传智播客开设大学,真的泰裤辣!"
}
结果:
{
"tokens" : [
{
"token" : "传",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "智",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "播",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "客",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "开设",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "大学",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "真的",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "泰",
"start_offset" : 11,
"end_offset" : 12,
"type" : "CN_CHAR",
"position" : 7
},
{
"token" : "裤",
"start_offset" : 12,
"end_offset" : 13,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "辣",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 9
}
]
}
可以看到,传智播客和泰裤辣都无法正确分词。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
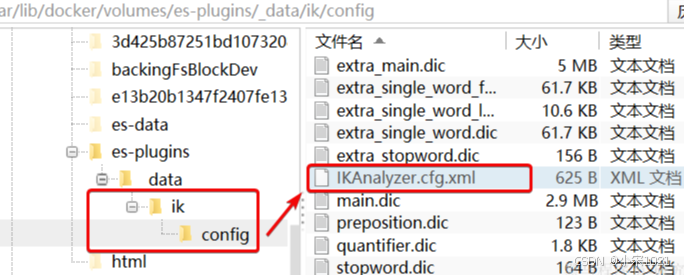
注意,如果采用在线安装的通过,默认是没有config目录的,需要把课前资料提供的ik下的config上传至对应目录。
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
传智播客
泰裤辣
4)重启elasticsearch
docker restart es
# 查看 日志
docker logs -f elasticsearch
再次测试,可以发现传智播客和泰裤辣都正确分词了:
{
"tokens" : [
{
"token" : "传智播客",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "开设",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "大学",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "真的",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "泰裤辣",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 4
}
]
}
总结
分词器的作用是什么?
-
创建倒排索引时,对文档分词
-
用户搜索时,对输入的内容分词
IK分词器有几种模式?
-
ik_smart:智能切分,粗粒度 -
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
-
利用config目录的
IkAnalyzer.cfg.xml文件添加拓展词典和停用词典 -
在词典中添加拓展词条或者停用词条
相关文章:
高性能分布式搜索引擎Elasticsearch详解
♥️作者:小宋1021 🤵♂️个人主页:小宋1021主页 ♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!! 🎈🎈加油! 加油!…...

连锁收银系统的五大功能 选择开源收银系统三要素
连锁收银系统的五大功能,很多新手是不清楚的,老手也只是知道一些大概,今天,商淘云为大家分享收银系统的五大功能,尤其是第五个,大部分人不清楚,有的企业前面选了不合适的收银系统,导…...

虚幻引擎解决构建问题
1.Intermediate 文件夹 在 Unreal Engine中,Intermediate 文件夹扮演着构建过程中的临时存储角色。具体来说,Intermediate 文件夹用于存放在编译和构建项目过程中生成的中间文件,这些文件包括但不限于: 编译中间文件:…...

C++基础知识:C++中读文件的四种简单方式
1.读取文件的步骤: 读文件步骤如下: 1.包含头文件 #include <fstream> 2.创建流对象 ifstream ifs; 3.打开文件并判断文件是否打开成功 ifs.open(“文件路径”,打开方式); 4. 读数据 四种方式读取 5.关闭文件 ifs.close(); 读取方法一: #include…...

【人工智能】多模态AI:如何通过融合文本、图像与音频重塑智能系统未来
1. 引言 在人工智能领域,多模态AI 是一项令人兴奋的新兴技术,旨在通过结合文本、图像和音频等多种数据模态,打造更加智能化和人性化的系统。随着深度学习和自然语言处理(NLP)的飞速发展,多模态AI正在为下一…...

通过重写QStyle控制QT控件样式
文章目录 创建自定义 QStyle 子类重写绘制方法调整大小和边距使用自定义样式在Qt应用程序中,QStyle类是负责所有控件(如按钮、滚动条、复选框等)的外观和行为的基类。重写QStyle允许你自定义控件的外观和感觉,实现独特的界面设计。下面介绍一下如何通过重写QStyle控制QT控件的…...

WPF入门教学十八 动画入门
WPF(Windows Presentation Foundation)是微软推出的一种用于创建Windows客户端应用程序的用户界面框架。WPF 提供了丰富的动画支持,可以通过XAML或者代码来实现各种动画效果。以下是一个简单的WPF动画入门教学,我们将使用XAML来创…...

电信光猫破解记录
设置桥接上网什么的都需要光猫超级管理员密码,记录一下自己破解电信光猫超级管理员密码的过程 1、MAC转初始密码串 记录MAC地址 MAC地址在光猫背后 生成密码串 把MAC地址中的横杠删除,得到一个密码串 2、windows开启 tel功能 打开控制面板 进入程序和…...

鸿蒙界面开发(九):列表布局 (List)
列表布局 当列表项达到一定数量,内容超过屏幕大小时,可以自动提供滚动功能。它适合用于呈现同类数据类型或数据类型集,例如图片和文本。在列表中显示数据集合是许多应用程序中的常见要求(如通讯录、音乐列表、购物清单等…...

微服务远程调用(nacos及OpenFeign简单使用)
问题:在微服务中,每个项目是隔离开的,当有一个项目请求其他项目中的数据时,必须发起网络请求,本文即对此问题展开讨论。 1.使用restTemplate发送请求 //发送请求ResponseEntity<List<ItemDTO>> response …...

Protobuf vs Thrift: 高性能序列化框架的对比与分析
Protobuf(Protocol Buffers)和Thrift都是高性能、跨语言的序列化框架,它们在数据通信和服务开发中扮演着重要角色。下面从多个方面对它们进行详细对比: 一、概述 1. Protobuf 简介:Protobuf是Google开发的一种语言中…...

LeetCode Hot100 C++ 哈希 1.两数之和
LeetCode Hot100 C 1.两数之和 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按…...

Windows下安装Neo4j流程
Neo4j简介 Neo4j 是一个基于图形结构的 NoSQL 数据库,专门用于存储和管理图数据。与传统的关系型数据库不同,Neo4j 使用 图(graph)的形式来表示数据,其中数据点(称为 节点)通过 边(…...

Spring IDEA 2024 自动生成get和set以及toString方法
1.简介 在IDEA中使用自带功能可以自动生成get和set以及toString方法 2.步骤 在目标类中右键,选择生成 选择Getter和Setter就可以生成每个属性对应的set和get方法, 选择toString就可以生成类的toString方法,...

部署my2sql
binlog解析及闪回工具 MySQL闪回工具简介 及 binlog2sql工具用法 安装: unzip my2sql-master.zip cd my2sql-master go build . 使用要求: 1、使用回滚/闪回功能时,binlog格式必须为row,且binlog_row_imagefull, DML统计以及大…...

Android Studio 真机USB调试运行频繁掉线问题
一、遇到问题 Android Studio使用手机运行项目时,总是频繁掉线,连接很不稳定,动不动就消失,基本上无法使用 二、问题出现原因 1、硬件问题:数据线 换条数据线试试,如果可以,那就是数据线的…...

如何通过费曼技巧理解复杂主题
在软件工程领域,知道某件事的名称和真正理解其工作原理之间存在巨大差异。 你可能知道某台机器或某个软件的名称,但你是否真的理解它是如何运作和完成任务的? 在如此复杂且不断发展的领域中,这种区别至关重要。 通过“教学反馈…...

Golang优雅关闭gRPC实践
本文主要讨论了在 Go 语言中实现gRPC服务优雅关闭的技术和方法,从而确保所有连接都得到正确处理,防止数据丢失或损坏。原文: Go Concurrency — Graceful Shutdown 问题 我在上次做技术支持的时候,遇到了一个有趣的错误。我们的服务在 Kubern…...

Maven笔记(一):基础使用【记录】
Maven笔记(一)-基础使用 Maven是专门用于管理和构建Java项目的工具,它的主要功能有: 提供了一套标准化的项目结构 Maven提供了一套标准化的项目结构,所有IDE(eclipse、myeclipse、IntelliJ IDEA 等 项目开发工具) 使…...

[vulnhub] Jarbas-Jenkins
靶机链接 https://www.vulnhub.com/entry/jarbas-1,232/ 主机发现端口扫描 扫描网段存活主机,因为主机是我最后添加的,所以靶机地址是135的 nmap -sP 192.168.75.0/24 // Starting Nmap 7.93 ( https://nmap.org ) at 2024-09-21 14:03 CST Nmap scan…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

开发者专属提示词库:提升AI协作效率的实战指南
1. 项目概述:一个为开发者量身定制的提示词宝库如果你是一名开发者,无论是前端、后端、运维还是算法工程师,我相信你都或多或少地接触过像 ChatGPT 这类大型语言模型。它们能写代码、解 Bug、解释概念,甚至帮你设计架构。但很多时…...

深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化
深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish是《环世界》(Rim…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

终极指南:如何在Mac上免费备份和导出微信聊天记录
终极指南:如何在Mac上免费备份和导出微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而懊恼?或是需要…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

Python与ChatGPT构建智能办公自动化:从任务分解到智能体系统
1. 项目概述:用Python与ChatGPT联手,让办公自动化“开口说话”如果你每天还在重复着打开Excel、复制粘贴数据、手动写邮件、整理报告这些枯燥的活儿,那这个项目可能就是你的“数字员工”入职通知书。Sven-Bo/automate-office-tasks-using-cha…...

OpenClaw 小龙虾智能体联动 DeepSeek 大模型部署实操攻略
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常启动OpenClaw,右上角 Gateway 状态显示在线设备网络通畅,可正常访问 DeepSeek 开放平台拥有可接收验证码的手机号 / 微信,用于平…...

DIY便携FPV地面站:从电路设计到3D打印的完整制作指南
1. 项目概述:为什么需要一个便携式FPV地面站?玩FPV(第一人称视角)飞行,无论是竞速穿越还是航拍探索,最核心的体验就是那块屏幕。大多数飞手依赖FPV眼镜带来的沉浸感,但在很多场景下,…...