[深度学习]循环神经网络
1 自然语言处理概述
- 语料:一个样本,句子/文章
- 语料库:由语料组成
- 词表:分词之后的词语去重保存成为词表
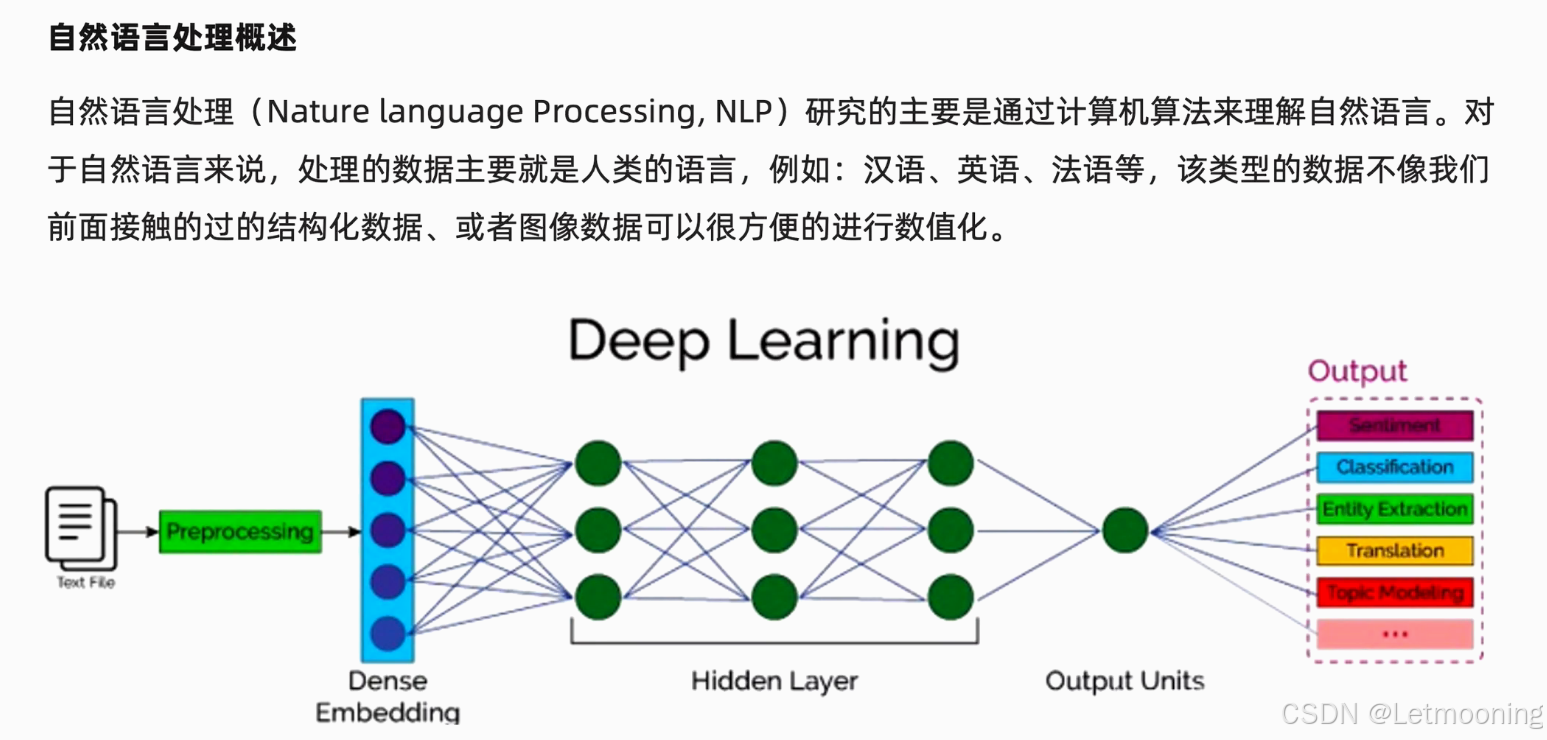

2 词嵌入层



import jieba
import torch.nn as nn
import torch
# 文本数据
text='北京东奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
# 分词
words=jieba.lcut(text)
print(words)
# 构建词表
uwords=list(set(words))
print(uwords)
words_num=len(uwords)
print(words_num)
# 构建词向量矩阵
embed=nn.Embedding(num_embeddings=words_num,embedding_dim=5)
print(embed(torch.tensor(1)))
# 输出结果
for i,word in enumerate(uwords):print(word,end=' ')print(embed(torch.tensor(i)))['北京', '东奥', '的', '进度条', '已经', '过半', ',', '不少', '外国', '运动员', '在', '完成', '自己', '的', '比赛', '后', '踏上', '归途', '。']
['自己', '运动员', '外国', '在', '后', '比赛', ',', '已经', '。', '过半', '不少', '进度条', '归途', '东奥', '踏上', '北京', '完成', '的']
18
tensor([-0.0293, -0.5446, -0.4495, -0.4013, -0.8653],grad_fn=<EmbeddingBackward0>)
自己 tensor([-0.0907, -0.6044, 1.9097, 1.1630, -0.4595],grad_fn=<EmbeddingBackward0>)
运动员 tensor([-0.0293, -0.5446, -0.4495, -0.4013, -0.8653],grad_fn=<EmbeddingBackward0>)
外国 tensor([ 1.9382, -1.3591, -0.2884, -1.4880, -0.2400],grad_fn=<EmbeddingBackward0>)
在 tensor([ 1.0954, 0.2975, -0.5151, -0.4355, 0.3870],grad_fn=<EmbeddingBackward0>)
后 tensor([-0.1857, -0.4351, 0.3869, -0.6311, -1.5527],grad_fn=<EmbeddingBackward0>)
比赛 tensor([-1.7570, -1.1983, -0.7864, 0.7223, -0.5285],grad_fn=<EmbeddingBackward0>)
, tensor([-0.2706, 1.7983, 0.9599, -0.5464, 0.7365],grad_fn=<EmbeddingBackward0>)
已经 tensor([ 1.4934, -0.7174, 1.1466, -0.3617, 0.6748],grad_fn=<EmbeddingBackward0>)
。 tensor([ 0.7996, -0.5406, -0.6476, 0.3923, 0.5128],grad_fn=<EmbeddingBackward0>)
过半 tensor([ 1.2070, 0.9933, 0.2634, 0.3173, -0.2273],grad_fn=<EmbeddingBackward0>)
不少 tensor([ 0.6716, 1.6509, 0.7375, 0.7585, -0.6289],grad_fn=<EmbeddingBackward0>)
进度条 tensor([ 0.4440, 1.9701, 0.6437, -0.2500, -0.8144],grad_fn=<EmbeddingBackward0>)
归途 tensor([-0.5646, 0.8995, -0.5827, -1.0231, 1.3692],grad_fn=<EmbeddingBackward0>)
东奥 tensor([-0.8312, 0.2083, 1.3728, 0.2860, 0.2762],grad_fn=<EmbeddingBackward0>)
踏上 tensor([ 0.0955, 0.5528, -0.5286, 0.6969, -0.7469],grad_fn=<EmbeddingBackward0>)
北京 tensor([ 0.4739, 0.6474, 0.3765, -1.9607, -1.1079],grad_fn=<EmbeddingBackward0>)
完成 tensor([ 1.2215, -0.3468, -0.1432, 0.5908, 1.2294],grad_fn=<EmbeddingBackward0>)
的 tensor([ 0.3083, 0.0163, 1.4923, -0.2768, 0.0904],grad_fn=<EmbeddingBackward0>)
3 循环网络RNN
- 激活函数为tanh
- 隐藏状态:当前词前面的信息
- [batch,seqlen(句子长度),词向量维度]
- pytorch框架的[seq_len,batch,input_size]





# RNN层API
import torch.nn as nn
import torch
# 词向量维度128,隐藏向量维度256
rnn=nn.RNN(input_size=128,hidden_size=256,num_layers=2)
# 第一个数字:seq_len,句子长度,也就是词语个数
# 第二个数字:batch,批量个数,也就是句子的个数
# 第三个数字:input_size,词向量的维度
# [seq_len,batch,input_size]
x=torch.randn([32,10,128])
# 第一个数字:num_layers,隐藏层的个数
# 第二个数字:batch,批量个数,也就是句子的个数
# 第三个数字:hidden_size,隐藏向量的维度
# [num_layers,batch,hidden_size]
h0=torch.zeros([2,10,256])
output,hn=rnn(x,h0)
# [seq_len,batch,hidden_size]
print(output.shape)
# [num_layers,batch,hidden_size]
print(hn.shape)
4 文本生成案例

import jieba# 构建词表
all_words = []
unique_words = []
for text in open('jaychou_lyrics.txt', 'r', encoding='utf8'):words = jieba.lcut(text)all_words.append(words)for word in words:if word not in unique_words:unique_words.append(word)word2idx = {word: idx for idx, word in enumerate(unique_words)}
# print(all_words)
# print(unique_words)
# print(word2idx)
print(len(unique_words))
corpus_ids = []
for words in all_words:temp = []for word in words:temp.append(word2idx[word])temp.append(word2idx[' '])corpus_ids.extend(temp)
print(corpus_ids)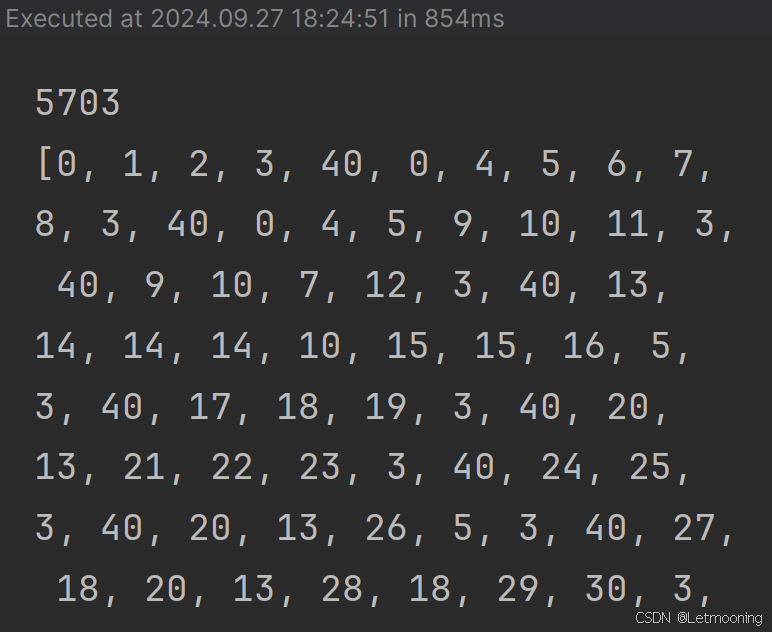
from torch.utils.data import Datasetclass textDataset(Dataset):def __init__(self, corpus_ids, seq_len):self.corpus_ids = corpus_idsself.seq_len = seq_lenself.word_count = len(self.corpus_ids)self.number = self.word_count // self.seq_lendef __len__(self):return self.numberdef __getitem__(self, idx):# idx指词的索引,并将其修正索引到文档的范围里面start = min(max(idx, 0), self.word_count - self.seq_len - 2)x = self.corpus_ids[start:start + self.seq_len]y = self.corpus_ids[start + 1:start + 1 + self.seq_len]return torch.tensor(x), torch.tensor(y)dataset = textDataset(corpus_ids, 5)
print(dataset.__getitem__(1))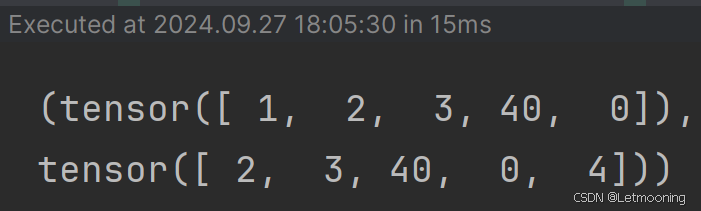
相关文章:
[深度学习]循环神经网络
1 自然语言处理概述 语料:一个样本,句子/文章语料库:由语料组成词表:分词之后的词语去重保存成为词表 2 词嵌入层 import jieba import torch.nn as nn import torch # 文本数据 text北京东奥的进度条已经过半,不少外…...

景联文科技精准数据标注:优化智能标注平台,打造智能未来
景联文科技是一家致力于为人工智能提供全面数据标注解决方案的专业公司。 拥有一支由经验丰富的数据标注师和垂直领域专家组成的团队,确保数据标注的质量和专业性。 自建平台功能一站式服务平台,提供从数据上传、标注、审核到导出的一站式服务࿰…...

商场促销——策略模式
文章目录 商场促销——策略模式商场收银软件增加打折简单工厂实现策略模式策略模式实现策略与简单工厂结合策略模式解析 商场促销——策略模式 商场收银软件 时间:2月27日22点 地点:大鸟房间 人物:小菜、大鸟 “小菜,给你…...

万字长文,AIGC算法工程师的面试秘籍,推荐收藏!
目录先行 AI绘画基础: 什么是DreamBooth技术?正则化技术在AI绘画模型中的作用? 深度学习基础: 深度学习中有哪些常用的注意力机制?如何寻找到最优超参数? 机器学习基础: 判别式模型和生成…...

一些超好用的 GitHub 插件和技巧
聊聊我平时使用 GitHub 时学到的一些插件、技巧。 浏览器插件 在我的另一篇博客 浏览器插件推荐 里提到过跟 GitHub 相关的一些插件,这里重复下: Sourcegraph:在线打开项目,方便阅读,将 GitHub 变得和 IDE …...

记Flink SQL 将数据写入 MySQL时的一个优化策略
Flink SQL 将数据写入 MySQL 时,如果主分片数较少,可以通过调整 MySQL 的主分片数来提高读写性能 1. 检查当前的分片设置 在 MySQL 中,使用以下 SQL 查询来查看当前的分片情况: SHOW VARIABLES LIKE innodb_buffer_pool_size; …...

QT-自定义信号和槽对象树图形化开发计算器
1. 自定义信号和槽 核心逻辑: 需要有两个类,一个提供信号,另一个提供槽。 然后在窗口中将 信号和槽 链接起来。 示例目标: 创建一个 Teacher 类,提供信号。 创建一个 Student 类,提供槽。 实现步骤&…...

C# 字符串(String)的应用说明一
一.字符串(String)的应用说明: 在 C# 中,更常见的做法是使用 string 关键字来声明一个字符串变量,也可以使用字符数组来表示字符串。string 关键字是 System.String 类的别名。 二.创建 String 对象的方法说明&#x…...

Redis缓存淘汰算法详解
文章目录 Redis缓存淘汰算法1. Redis缓存淘汰策略分类2. 会进行淘汰的7种策略2.1 基于过期时间的淘汰策略2.2 基于所有数据范围的淘汰策略 3. LRU与LFU算法详解4. 配置与调整5. 实际应用场景 LRU算法以及实现样例LFU算法实现1. 数据结构选择2. 访问频率更新3. 缓存淘汰4. 缓存插…...

Sklearn 与 TensorFlow 机器学习实用指南
Sklearn 与 TensorFlow 机器学习实用指南 Scikit-learn(Sklearn) 1. 简介 2. 特点 3. 基本用法 TensorFlow 1. 简介 2. 特点 3. 基本用法 选择指南 总结 🎈边走、边悟🎈迟早会好 关于使用 Scikit-learn(Sk…...

RabbitMQ 界面管理说明
1.RabbitMQ界面访问端口和后端代码连接端口不一样 界面端口是15672 http://localhost:15672/ 后端端口是 5672 默认账户密码登录 guest 2.总览图 3.RabbitMq数据存储位置 4.队列 4.客户端消费者连接状态 5.队列运行状态 6.整体运行状态...

设备管理与点巡检系统
在现代企业管理中,设备的高效运作至关重要。为此,我们推出了设备管理与点巡检系统,通过自动化管理提升设备使用效率,保障生产安全。 系统特点 设备全生命周期管理 系统涵盖设备的各个阶段,从设备管理、点检、巡检、保…...

计算机网络的整体认识---网络协议,网络传输过程
计算机网络背景 网络发展 独立模式: 计算机之间相互独立; 网络互联: 多台计算机连接在一起, 完成数据共享; 局域网LAN: 计算机数量更多了, 通过交换机和路由器连接在一起; 广域网WAN: 将远隔千里的计算机都连在一起;所谓 "局域网" 和 "广域网" 只是一个相…...

Battery management system (BMS)
电池管理系统(BMS)是一种专门用于监督电池组的技术,电池组由电池单元组成,在电气上按照行x列矩阵配置进行排列,以便在预期的负载场景下,在一段时间内提供目标范围的电压和电流。 文章目录 电池管理系统是如…...
)
和GPT讨论ZNS的问题(无修改)
主题:ZNS相关的疑问讨论,GPT逻辑回答,要是开高阶版本估计回答的更明智些。 ZNS的写和传统写的区别 ChatGPT 说: ChatGPT ZNS(Zoned Namespace)与传统写入方式的主要区别体现在以下几个方面: …...

6.8方框滤波
基本概念 方框滤波(Box Filter)是一种基本的图像处理技术,用于对图像进行平滑处理或模糊效果。它通过在图像上应用一个固定大小的方框核(通常是矩形),计算该区域内像素值的平均值来替换中心像素的值。这种…...

携手SelectDB,观测云实现性能与成本的双重飞跃
在刚刚落下帷幕的2024云栖大会上,观测云又一次迎来了全面革新。携手SelectDB,实现了技术的飞跃,这不仅彰显了观测云在监控观测领域的技术实力,也预示着我们可以为全球用户提供更加高效、稳定的数据监测与分析服务。这一技术升级&a…...

Redis 五大基本数据类型及其应用场景进阶(缓存预热、雪崩 、穿透 、击穿)
Redis 数据类型及其应用场景 Redis 是什么? Redis是一个使用C语言编写的高性能的基于内存的非关系型数据库,基于Key/Value结构存储数据,通常用来 缓解高并发场景下对某一资源的频繁请求 ,减轻数据库的压力。它支持多种数据类型,如字符串、…...

如何在ChatGPT的帮助下,使用“逻辑回归”技巧完成论文写作?
学境思源,一键生成论文初稿: AcademicIdeas - 学境思源AI论文写作 逻辑回归作为一种统计分析工具广泛应用,以解决研究中的分类问题。其主要作用在于探讨和量化自变量对因变量的影响,从而揭示潜在的因果关系。 在论文写作中&…...

MySQL 临时表
MySQL 临时表 引言 在数据库管理中,临时表是一种非常有用的工具,尤其是在进行复杂的数据处理和查询时。MySQL 作为一种流行的关系型数据库管理系统,提供了对临时表的支持。本文将详细介绍 MySQL 临时表的概念、用途、创建方法以及管理技巧。 什么是 MySQL 临时表? MySQ…...

手把手教你模拟登录淘宝并爬取订单数据:从Cookie维护到反爬突破的完全指南
目录 一、技术选型:为什么最终选择了Playwright? 1.1 那些年被抛弃的方案 1.2 Playwright的优势 1.3 完整的依赖清单 二、登录流程的完整实现 2.1 两种登录方案的权衡 2.2 扫码登录的完整代码 2.3 Cookie持久化机制详解 三、订单列表爬取的两种思路 3.1 方式一:页…...

CellProfiler:生物图像分析的瑞士军刀,让科研更智能更高效
CellProfiler:生物图像分析的瑞士军刀,让科研更智能更高效 【免费下载链接】CellProfiler An open-source application for biological image analysis 项目地址: https://gitcode.com/gh_mirrors/ce/CellProfiler 你是否曾经面对成百上千张细胞图…...

048路径总和III
路径总和 III 题目链接:https://leetcode.cn/problems/path-sum-iii/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: Map<Long,Integer> map new HashMap<>();//key:前缀和 value:前缀和的个数 publ…...

深兰科技签约乌兹别克斯坦智慧城市项目,推动中国AI出海规模化
2026年5月11日,深兰人工智能科技(上海)股份有限公司与乌兹别克斯坦合作方在上海张江总部举行签约仪式。双方将围绕乌兹别克斯坦新塔什干新城(Yangi Toshkent)智慧城市建设展开合作,深兰科技通过控股乌兹别克项目公司,围绕智慧城市、智慧住宅、…...

AI 写作进入长篇记忆时代,AI让小说创作更可控
AI 写小说最常被讨论的问题,是写得快不快、文笔好不好。但对于真正写长篇的作者来说,还有一个更重要的问题:AI 记不记得住。 一部网文写到几十章、几百章后,人物关系会越来越复杂,伏笔会越来越多,世界观设…...

高性能系统发育计算库:BEAGLE 库完整安装与优化指南
高性能系统发育计算库:BEAGLE 库完整安装与优化指南 【免费下载链接】beagle-lib general purpose library for evaluating the likelihood of sequence evolution on trees 项目地址: https://gitcode.com/gh_mirrors/be/beagle-lib BEAGLE(Broa…...

怎么判断铝合金熔炼炉价格才合理?
在选购铝合金熔炼炉时,价格只是一个参考。需要关注市场行情、熔炼炉厂家信誉、设备性能与售后服务等多方面因素。铝熔炼炉若性能更好,初期投入虽高,长期使用能提升产能并降低单位成本。不同类型的冶金熔炼炉各有特点,会影响选型与…...

用操作系统类比彻底搞懂 AI Agent:进程、系统调用与上下文窗口
用操作系统类比彻底搞懂 AI Agent:进程、系统调用与上下文窗口 引言 很多人第一次接触 AI Agent,会立刻被一堆新词包围:Tool Use、Function Calling、RAG、Memory、Orchestrator、Multi-Agent、Context Compression。 这些词看起来很新&#…...

从稀疏重构到精准定位:OMP-CS算法在DOA估计中的实战解析
1. 从稀疏信号到空间定位:OMP-CS算法的核心逻辑 第一次接触OMP-CS算法时,我盯着那堆数学公式发呆了半小时。直到把天线阵列想象成麦克风阵列,事情突然变得简单——这不就是通过多个麦克风判断声音方向的升级版吗?在雷达和通信系统…...

网易云音乐增强脚本架构解析:基于用户脚本技术的云音乐生态扩展方案
网易云音乐增强脚本架构解析:基于用户脚本技术的云音乐生态扩展方案 【免费下载链接】myuserscripts 网易云音乐油猴脚本:歌曲下载、转存云盘、云盘歌曲快传、云盘匹配纠正... 项目地址: https://gitcode.com/gh_mirrors/my/myuserscripts 项目愿景与价值主张…...