Spark 的 Skew Join 详解
Skew Join 是 Spark 中为了解决数据倾斜问题而设计的一种优化机制。数据倾斜是指在分布式计算中,由于某些 key 具有大量数据,而其他 key 数据较少,导致某些分区的数据量特别大,造成计算负载不均衡。数据倾斜会导致个别节点出现性能瓶颈,影响整个任务的完成时间。
Skew Join 的优化机制在 Spark 中主要解决了 JOIN 操作中的数据倾斜问题。为了更好地理解 Skew Join 的原理和实现,我们需要从数据倾斜产生的原因、Spark 如何识别数据倾斜、以及 Skew Join 的优化策略和底层实现等方面来进行详细解释。
一、什么是数据倾斜
数据倾斜指的是当某些 key 关联了异常大量的数据,而其他 key 关联的数据量较少时,数据分布的不均衡会导致计算瓶颈。例如,在 JOIN 操作中,如果表 A 中某个 key 具有大量的数据,而表 B 中同样的 key 也有大量数据,当这两个表基于这个 key 进行 JOIN 时,由于该 key 被分配到一个或少数几个分区,相关的任务会处理大量的数据,而其他分区的任务数据量却较少。这会导致部分任务比其他任务运行时间长,从而影响整个任务的执行时间。
二、Spark 中如何识别数据倾斜
在执行 JOIN 操作时,Spark 会通过数据采样和统计信息来检测是否存在数据倾斜。Spark SQL 可以通过分析数据分布,计算每个 key 的数据量,当发现某些 key 占据了大量的行时,Spark 会将其标记为 "倾斜的 key"。对于这些倾斜的 key,Spark 会进行特殊处理,避免过度集中在某些分区中。
Spark 的 Skew Join 优化主要依赖于配置参数和数据采样来检测并处理这些倾斜的 key。
检测数据倾斜的主要参数:
- spark.sql.autoSkewJoin.enabled: 默认是
false,如果设置为true,Spark 会自动检测和处理数据倾斜的JOIN操作。 - spark.sql.skewJoin.threshold: 用来设定 Spark 如何判断某个分区是否倾斜。该参数设置的值是数据倾斜的阈值,通常是一个比例值,如果某个分区的数据量超过该比例值,则会被视为倾斜的分区。
三、Skew Join 的底层原理
当 Spark 识别出 JOIN 中存在数据倾斜时,Skew Join 会将倾斜的 key 拆分成多个子任务分别处理。具体而言,Skew Join 的主要思想是将倾斜的 key 拆分到多个不同的分区,从而将任务的计算负载均匀分布,避免单个分区处理过多数据。
以下是 Skew Join 的执行流程:
-
普通的非倾斜
对于普通的非倾斜key处理:key,Skew Join没有特别的处理方式,Spark 直接按照key进行Shuffle,将数据发送到相应的分区,并进行JOIN操作。 -
倾斜的
key处理:
对于检测到的倾斜 key,Spark 会进行特殊处理,具体步骤如下:
- Spark 会将倾斜的
key的数据进行重新分片,将大数据量的倾斜key拆分成多个子分区。 - 然后对于每一个子分区,分别与另一个表中的对应数据进行
JOIN。 - 通过多次
JOIN操作,将这些子分区结果合并为最终的JOIN输出结果。
3. Hash Salt(哈希加盐):
为了避免倾斜的 key 被集中到同一个分区,Spark 会通过对倾斜的 key 添加一个随机的 salt(盐值)来打散数据。具体来说,Spark 会将倾斜的 key 拆分成多个子 key,通过附加随机数(salt),使得这些子 key 被分布到不同的分区。
伪代码展示:
// 倾斜 key 的原始 join
tableA.join(tableB, "key")// Skew Join 处理
val skewKeys = getSkewKeys()
for (skewKey <- skewKeys) {val saltedTableA = tableA.filter($"key" === skewKey).withColumn("salt", rand())val saltedTableB = tableB.filter($"key" === skewKey).withColumn("salt", rand())saltedTableA.join(saltedTableB, Seq("key", "salt"))
}
通过引入 salt,可以有效地将数据均匀分布到不同的分区,减少单个分区处理的数据量。
四、Skew Join 的源代码实现
在 Spark SQL 中,Skew Join 是作为 PhysicalPlan 中 Join 的一个优化执行计划。关键类为 EnsureRequirements,其主要职责是对 Join 的物理计划执行前进行必要的调整,包括处理数据倾斜的 Skew Join 优化。
以下是 EnsureRequirements 中处理数据倾斜的相关部分源代码:
private def applySkewJoin(plan: SparkPlan): SparkPlan = plan match {case join @ ShuffledHashJoinExec(_, _, _, _, left, right) =>// 检查是否有数据倾斜if (isSkewed(join)) {// 处理 skew join,使用 hash salt 拆分倾斜的 keyval skewJoin = handleSkewJoin(join)skewJoin} else {join}case other => other
}
在 EnsureRequirements 中,applySkewJoin 函数会检测当前的 JOIN 是否存在数据倾斜问题。如果检测到数据倾斜,handleSkewJoin 函数会对数据进行处理,创建一个带有 salt 的 Skew Join 执行计划。
具体实现步骤:
-
检测数据倾斜:
isSkewed(join)函数负责检测JOIN中的分区是否有数据倾斜。通常,通过采样和统计每个分区的数据量,来判断某个分区的数据量是否超出设定的阈值(spark.sql.skewJoin.threshold)。 -
处理倾斜数据:
handleSkewJoin(join)函数是Skew Join的核心实现。它会通过对倾斜的key添加salt进行打散,使得数据均匀分布到多个子分区。
private def handleSkewJoin(join: ShuffledHashJoinExec): SparkPlan = {val skewKeys = getSkewKeys(join)val saltedLeft = splitAndSalt(join.left, skewKeys)val saltedRight = splitAndSalt(join.right, skewKeys)saltedLeft.join(saltedRight)
}private def splitAndSalt(plan: SparkPlan, skewKeys: Seq[KeyType]): SparkPlan = {// 对每个倾斜 key 进行拆分并添加 saltplan.transform {case rdd: RDD[_] => rdd.mapPartitionsInternal { iter =>iter.flatMap { row =>val key = getJoinKey(row)if (skewKeys.contains(key)) {val salt = Random.nextInt(numSplits) // 随机生成 saltSome((key, salt, row))} else {Some((key, row))}}}}
}
在上面的代码中,splitAndSalt 函数将每个倾斜的 key 拆分成多个子 key,并为它们添加随机 salt,从而打散数据,均匀分布到不同的分区。
五、Skew Join 的优化策略
Spark 中 Skew Join 的优化需要考虑以下几个方面:
-
自动启用 Skew Join:通过设置
spark.sql.autoSkewJoin.enabled为true,Spark 会自动检测并处理倾斜的JOIN操作。对于那些倾斜的分区,Spark 会自动进行Skew Join优化。 -
调优 salt 值:
salt的值影响了倾斜数据被打散的粒度。通过调节salt的随机范围,可以控制数据的打散程度。如果salt的范围太小,数据可能仍然集中在某些分区;如果范围太大,则可能会产生过多的小分区,导致计算开销增加。 -
采样优化:通过调整采样参数,Spark 可以更好地识别出数据倾斜的
key,从而提高Skew Join的处理效率。spark.sql.skewJoin.threshold参数允许用户设定数据倾斜的阈值。 -
数据预处理:在某些场景中,用户可以通过在数据加载和预处理阶段手动解决数据倾斜问题。例如,用户可以通过聚合或者过滤数据的方式,减少倾斜
key的数据量。
六、总结
Skew Join 是 Spark 中为了解决数据倾斜问题而提供的一种重要优化机制。其核心思想是通过检测数据倾斜的 key,并对这些 key 进行分片和哈希加盐处理,使得倾斜的数据被均匀分布到不同的分区,从而避免计算负载的不均衡。通过 Skew Join,Spark 可以显著提高 JOIN 操作的性能,尤其是在数据倾斜严重的场景下。
合理的参数调优和数据预处理是确保 Skew Join 有效的关键。
相关文章:

Spark 的 Skew Join 详解
Skew Join 是 Spark 中为了解决数据倾斜问题而设计的一种优化机制。数据倾斜是指在分布式计算中,由于某些 key 具有大量数据,而其他 key 数据较少,导致某些分区的数据量特别大,造成计算负载不均衡。数据倾斜会导致个别节点出现性能…...

讯飞星火编排创建智能体学习(一)最简单的智能体构建
目录 开篇 智能体的概念 编排创建智能体 创建第一个智能体 编辑 大模型节点 测试与调试 开篇 前段时间在华为全联接大会上看到讯飞星火企业级智能体平台的演示,对于拖放的可视化设计非常喜欢,刚开始以为是企业用户才有的,回来之后查…...

mac-m1安装nvm,docker,miniconda
1.安装minicondaMAC OS(M1)安装配置miniconda_mac-mini m1 conda-CSDN博客 2.安装nvm(用第二个方法)Mac电脑安装nvm(node包版本管理工具)-CSDN博客 3.安装docker dmg下载链接docker-toolbox-mac-docker-for-mac安装包下载_开源镜像站-阿里云 教程MacOS系…...

STM32F407之Flash
寄存器分类 一般寄存器分为只读存储器 (ROM) 随机存储器(RAM) 只读存储器 只读存储器也被称为ROM 在正常工作时只能读不能写。 只读存储器经历的阶段 ROM->PROM->EPROM->EEPROM ->Flash 优点:掉电不丢失,解构简单 缺点:只适…...
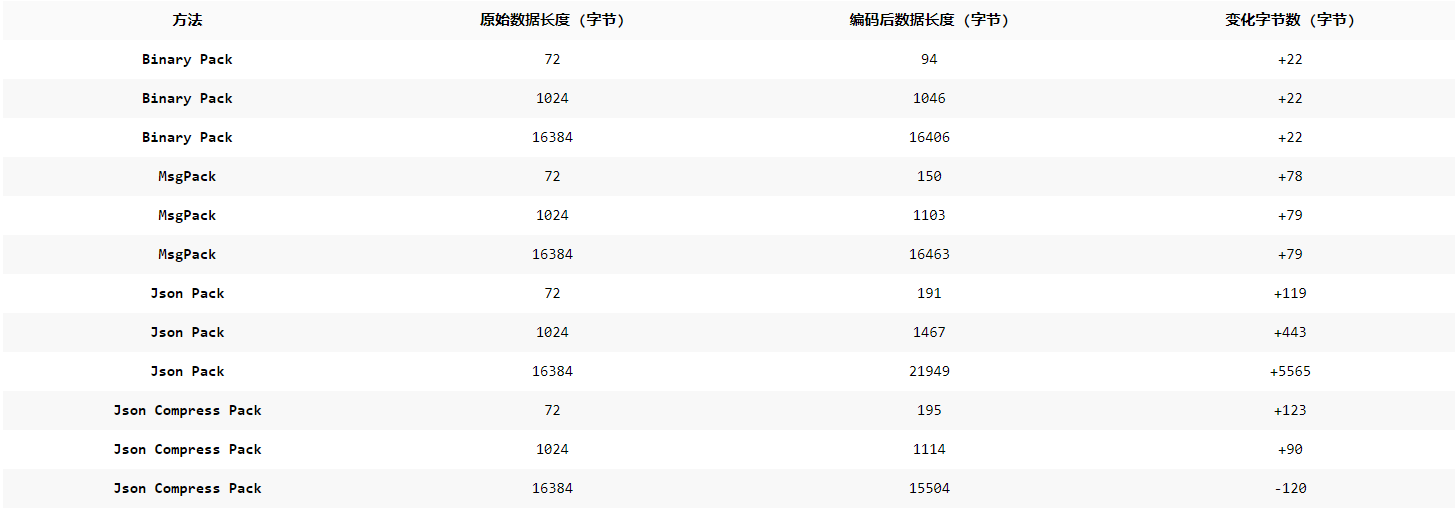
优化 Go 语言数据打包:性能基准测试与分析
场景:在局域网内,需要将多个机器网卡上抓到的数据包同步到一个机器上。 原有方案:tcpdump -w 写入文件,然后定时调用 rsync 进行同步。 改造方案:使用 Go 重写这个抓包逻辑及同步逻辑,直接将抓到的包通过网…...

【SQL】未订购的客户
目录 语法 需求 示例 分析 代码 语法 SELECT columns FROM table1 LEFT JOIN table2 ON table1.common_field table2.common_field; LEFT JOIN(或称为左外连接)是SQL中的一种连接类型,它用于从两个或多个表中基于连接条件返回左表…...

Qt(9.28)
widget.cpp #include "widget.h"Widget::Widget(QWidget *parent): QWidget(parent) {QPushButton *btn1 new QPushButton("登录",this);this->setFixedSize(640,480);btn1->resize(80,40);btn1->move(200,300);btn1->setIcon(QIcon("C:…...

javascript-冒泡排序
前言:好久没学习算法了,今天看了一个视频课,之前掌握很好的冒泡排序居然没写出来? <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport"…...

第九届蓝桥杯嵌入式省赛程序设计题解析(基于HAL库)
一.题目分析 (1).题目 (2).题目分析 按键功能分析----存储位置的切换键 a. B1按下切换存储位置,切换后定时时间设定为当前位置存储的时间 b. B2短按切换时分秒高亮,设置完成后,长按把设置的时…...

MATLAB云计算集成:在云端扩展计算能力
摘要 MATLAB云计算集成是指将MATLAB的计算能力与云平台的弹性资源相结合,以实现高性能计算、数据处理和算法开发。本文详细介绍了MATLAB云计算的基本概念、优势、配置要点以及编程实践。 1. 云计算概述 云计算是一种通过互联网提供计算资源(如服务器、…...

基于BeagleBone Black的网页LED控制功能(flask+gpiod)
目录 项目介绍硬件介绍项目设计开发环境功能实现控制LED外设构建Webserver 功能展示项目总结 👉 【Funpack3-5】基于BeagleBone Black的网页LED控制功能 👉 Github: EmbeddedCamerata/BBB_led_flask_web_control 项目介绍 基于 BeagleBoard Black 开发板…...

【C语言】单片机map表详细解析
1、RO Size、RW Size、ROM Size分别是什么 首先将map文件翻到最下面,可以看到 1.1 RO Size:只读段 Code:程序的代码部分(也就是 .text 段),它存放了程序的指令和可执行代码。 RO Data:只读…...

Java中的继承和实现
Java中的继承和实现在面向对象编程中扮演着不同的角色,它们之间的主要区别可以从以下几个方面进行阐述: 1. 定义和用途 继承(Inheritance):继承是面向对象编程中的一个基本概念,它允许我们定义一个类&…...

uniapp云打包
ios打包 没有mac电脑,使用香蕉云编 先登录香蕉云编这个工具,新建csr文件——把csr文件下载到你电脑本地: 然后,登录苹果开发者中心 生成p12证书 1、点击+号创建证书 创建证书的时候一定要选择ios distribution app store and ad hoc类型的证书 2、上传刚才从本站生成的…...

端口安全技术原理与应用
目录 概述 端口安全原理 端口安全术语 二层安全地址配置 端口模式下配置 全局模式下配置 动态学习 二层数据包处理流程 三层安全地址配置 三层数据包处理流程 端口安全违例动作和安全地址老化时间 查看命令 端口安全的注意事项 小结 概述 园区网的接入安全关系着…...

数据集-目标检测系列-鲨鱼检测数据集 shark >> DataBall
数据集-目标检测系列-鲨鱼检测数据集 shark >> DataBall 数据集-目标检测系列-鲨鱼检测数据集 shark 数据量:6k 数据样例项目地址: gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview github: https://github.com/Te…...

数字乡村解决方案-3
1. 国家大数据战略与数字乡村 中国第十三个五年规划纲要强调实施国家大数据战略,加快建设数字中国,推进数据资源整合和开放共享,保障数据安全,以大数据助力产业转型升级和提高社会治理的精准性与有效性。 2. 大数据与数字经济 …...

WPF文本框无法输入小数点
问题描述 在WPF项目中,文本框BInding双向绑定了数据Text“{UpdateSourceTriggerPropertyChanged}”,但手套数据是double类型,手动输入数据时,小数点输入不进去 解决办法: 在App.xaml.cs文件中添加语句: …...

R开头的后缀:RE
RE表示方位上的向后,一种时空上的折返,和表示否定意味的不。 68.re- 空间顺序 ①表示"向后,相反,不" RE表示正向抵抗的力的词语,和情绪的词语,用来表示一种极力的反抗和拒绝,包括…...

Vue2配置环境变量的注意事项
在实际开发中时常会遇到需要开发环境与生产环境中一些参数的替换,为了方便线上线下环境变量切换可以利用node中的process进行环境变量管理 实现步骤如下: 1.在 根目录 新增环境文件 .env.development 和 .env.production 注意文件名称保持一致( 需要强调的是文件中的变量名切…...

做电力仪器选显示屏踩坑3年,终于摸透这四个选型标准
我是电力仪器设备厂的生产测试主管,干这行快7年了,前前后后负责过继保测试仪、变比测试仪、互感器校验仪等七八款产品的配件选型,光显示屏就换过四家供应商,踩过强电磁下跳数、低温黑屏、交期拖垮项目的坑,直到用上恒域…...

AI系统行为治理:构建确定性护栏与运行时安全控制
1. 项目概述:为AI系统构建确定性的行为护栏如果你正在构建一个会“动手”的AI应用——无论是能帮你写代码的智能助手,还是能操作数据库的自动化流程,甚至是部署在物理设备上的机器人——那么你迟早会面临一个核心问题:如何确保它只…...

AMD Carrizo架构解析:SoC集成与HSA异构计算如何重塑移动处理器
1. 从“胶水粘合”到“原生融合”:Carrizo与Carrizo-L的架构革命2014年底,当AMD在新加坡的“计算的未来”活动上拿出Carrizo和Carrizo-L这两颗芯片时,现场的反应可能比预想的要平静一些。毕竟,对于习惯了每年“挤牙膏”式升级的行…...

JDspyder:京东自动化抢购解决方案的技术实现与实战指南
JDspyder:京东自动化抢购解决方案的技术实现与实战指南 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商秒杀和限量商品抢购的激烈竞争中,技术手段…...

在Windows电脑上体验酷安社区:酷安UWP桌面版完全指南
在Windows电脑上体验酷安社区:酷安UWP桌面版完全指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否曾经想过,如果能在电脑上刷酷安会是怎样的体验…...

Sutton《苦涩的教训》早已预言:一切**人工精巧设计的专用智能系统**,终将被算力与数据驱动的通用范式无情取代
《The Bitter Lesson》《苦涩的教训》3条极简核心背诵版 人类总爱把领域知识、手工设计、精巧架构塞进AI,短期有用,长远全没用。AI 历史规律:通用规模化(算力数据大模型)永远碾压 人工定制智能小系统。未来趋势&#x…...

HGO-YOLO:轻量级实时异常行为检测算法解析
1. 项目概述:轻量级异常行为检测的突破性方案在智能监控和公共安全领域,实时检测异常行为(如跌倒、斗殴、吸烟)一直是个技术难点。传统方案要么依赖人力监控效率低下,要么计算资源消耗过大难以落地。我们团队开发的HGO…...

FPGA阵列信号处理矩阵算子高性能实现【附代码】
✨ 长期致力于自动驾驶、阵列信号处理、矩阵特征值分解、Jacobi旋转、三角矩阵求逆、序列排序、序列部分排序研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&…...

别再死记硬背了!手把手教你选对PPP定位模型:UC、UD、UofC、SD到底怎么用?
精密单点定位模型实战指南:如何根据场景选择UC、UD、UofC与SD 在GNSS高精度定位领域,精密单点定位(PPP)技术已成为科研与工程应用的核心工具。面对UC、UD、UofC、SD四种主流模型,许多工程师常陷入选择困境——不同模型…...

为你的Nodejs后端服务快速集成大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Nodejs后端服务快速集成大模型能力 当你的Node.js应用需要添加智能对话或内容生成功能时,直接对接各大模型厂商的…...