04 B-树
目录
- 常见的搜索结构
- B-树概念
- B-树的插入分析
- B-树的插入实现
- B+树和B*树
- B-树的应用
1. 常见的搜索结构
| 种类 | 数据格式 | 时间复杂度 |
|---|---|---|
| 顺序查找 | 无要求 | O(N) |
| 二分查找 | 有序 | O( l o g 2 N log_2N log2N) |
| 二分搜索树 | 无要求 | O(N) |
| 二叉平衡树 | 无要求 | O( l o g 2 N log_2N log2N) |
| 哈希 | 无要求 | O(1) |
以上结构适合用于数据量相对不是很大,能够一次性存放在内存中,进行数据查找的场景。如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了,如果放在磁盘上,有需要搜索某些数据,那么如果处理呢?那么我们可以考虑将存放关键字及其映射的数据的地址放到一个内存中的搜索树的节点中,那么要访问数据时,先取这个地址去磁盘访问数据。


使用平衡二叉搜索树的缺陷:
平衡二叉搜索树的高度是logN,这个查找次数在内存中时最快的。但是当数据都在磁盘中时,访问磁盘速度很慢,在数据量很大时,logN次的磁盘访问,是一个难以接受的结果
使用哈希表的缺陷:
哈希表的效率很高是O(1),但是一些极端场景下某个位置冲突很多,导致访问次数剧增
那如何加速对数据的访问?
1.提高IO的速度(SSD相比传统机械硬盘快了不少,但是还没有得到本质性的提升)
2.降低树的高度–多叉平衡树
2. B树概念
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(后面有一个B的改进版本B+树,然后有些地方的B树写的的是B-树,注意不要误读成"B减树")。一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
1.根节点至少有两个孩子
2.每个分支节点都包含k-1个关键字和k个孩子,其中ceil(m/2) <= k <= m,ceil则是向上取整函数
3.每个叶子结点都包含k-1个关键字,其中ceil(m/2) ≤ k ≤ m
4.所有的叶子节点都在同一层
5.每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
6.每个节点的结构为:{n,A0,K1,A1,K2,A2.。。,Kn,An}其中,K(1≤i≤n)位关键字,且Ki < Ki+1 (1≤i≤n)为指向子树根节点的指针。且Ai所指子树所有节点中的关键字均小于Ki+1
n为节点中关键字的个数,满足ceil(m/2)-1≤n≤m-1
3. B-树的插入分析
为了简单起见,假设M=3,即三叉树,每个节点中存储两个数据,两个数据可以将区间分割成三个部分,因此节点应该有3个孩子,节点结构如下:

注意:孩子永远比数据多一个
用序列{53,139,75,49,145,36,101}构建B树的过程如下:







3.1 结构设计
b树的节点,用n记录已经保存的数据数量,用数组保存关键字,孩子数量比关键字多一个,再用一个指针保存当前节点的父亲,方便插入
template <class K, size_t M>
struct BTreeNode
{size_t _n; // 记录存储多少个关键字K _keys[M]; struct BTreeNode<K, M>* _subs[M + 1]; // 孩子struct BTreeNode<K, M>* _parent; // 父亲BTreeNode(){for (size_t i = 0; i < M; i++){_keys[i] = K();_subs[i] = nullptr;}_n = 0;_subs[M] = nullptr;_parent = nullptr;}
};
B树保存一个根节点
template <class K, size_t M>
class BTree
{typedef struct BTreeNode<K, M> node;private:node* _root = nullptr;
};
3.2 查找
要实现插入,先提供一个查找关键字存不存在的功能
两个循环,内部循环用来在一个节点中查找,如果key比当前值大,key就++,如果小,就跳到它的左子树。找到返回地址和下标,找不到返回它的父节点方便插入
// 返回指针和节点中的位置
std::pair<node*, int> Find(const K& key)
{node* parent = nullptr;node* cur = _root;while (cur){// 一个节点中查找size_t i = 0;while (i < cur->_n){if (key > cur->_keys[i]){i++;}else if (key < cur->_keys[i]){break;}else{return std::make_pair(cur, i);}}parent = cur;// 往孩子跳cur = cur->_subs[i];}return std::make_pair(parent, -1);
}



插入过程总结:
1.如果树为空,直接插入新节点,该结点为树的根节点
2.树非空,找待插入元素在树中的插入位置(注意:找到的插入节点位置一定在叶子节点中)
3.检测是否找到插入位置(假设树中的key唯一,即该元素已经存在不插入)
4.按照插入排序的思想将该元素插入到找到的节点中
5.检测该结点是否满足B-树的性质:即该节点中的元素个数是否等于M,如果小于则满足
6.如果插入后节点不满足B树的性质,需要对该节点分裂
- 申请新及诶点
- 找到该节点的中间位置
- 将该节点的中间位置右侧的元素以及孩子搬移到新节点中
- 将中间位置元素以及新节点往该节点中的双亲节点中插入,即继续
7.如果向上已经分裂到根节点的位置,插入结束
4. B树的插入实现
分为两个部分,一个函数用来找到插入位置插入,一个函数进行后续的调整,分裂保证B树特征
4.1 插入数据
插入的时候走的是插入的逻辑,挪动数据的同时要挪动孩子,插入成功还要连接父亲
// 找到节点中的插入位置插入数据
void InsertKey(node* cur, const K& key, node* child)
{int end = cur->_n - 1;while (end >= 0){if (key < cur->_keys[end]){// 挪动key和它的右孩子cur->_keys[end + 1] = cur->_keys[end];cur->_subs[end + 2] = cur->_subs[end + 1];end--;}else{break;}}cur->_keys[end + 1] = key;cur->_subs[end + 2] = child;// 第一次可能为空if (child){child->_parent = cur;}cur->_n++;
}
4.2 调整
需要注意清空原数据和孩子和父亲的连接
// 插入的分裂等补充
bool Insert(const K& key)
{if (_root == nullptr){node* new_node = new node;new_node->_keys[0] = key;_root = new_node;_root->_n++;return true;}// key已经存在,不允许插入std::pair<node*, int> ret = Find(key);node* parent = ret.first;if (ret.second >= 0){return false;}// 如果没有找到,find顺便带回了要插入的叶子节点// 循环每次往cur插入,newkey和childK new_key = key;node* child = nullptr;while (1){InsertKey(parent, new_key, child);// 没满结束if (parent->_n < M){return true;}// 满了分裂node* brother = new node;size_t j = 0;// 分裂一半[mid + 1, M - 1]给兄弟size_t mid = M / 2;size_t i = mid + 1;// 拷贝key,还要拷贝孩子for (; i < M; i++){brother->_keys[j] = parent->_keys[i];brother->_subs[j] = parent->_subs[i];// 孩子不为空,更新父亲if (parent->_subs[i]){parent->_subs[i]->_parent = brother;}j++;parent->_keys[i] = K();parent->_subs[i] = nullptr;}// 还有最后一个右孩子brother->_subs[j] = parent->_subs[i];if (parent->_subs[i]){parent->_subs[i]->_parent = brother;}parent->_subs[i] = nullptr;brother->_n = j;parent->_n -= brother->_n + 1;K mid_key = parent->_keys[mid];parent->_keys[mid] = K();// 说明刚刚分裂的是头节点if (parent->_parent == nullptr){_root = new node;_root->_keys[0] = mid_key;_root->_subs[0] = parent;_root->_subs[1] = brother;_root->_n = 1;parent->_parent = _root;brother->_parent = _root;return true;}else{// 转换成往parent->parent 去插入parent->[mid] 和 brothernew_key = mid_key;child = brother;parent = parent->_parent;}}
}
4.3 B-树的简单验证
对B树中序遍历,如果得到一个有序的序列,说明插入正确。和搜索二叉树类似,先左,再根,再往右移动
void _Inorder(node* cur)
{if (cur == nullptr){return;}// 左 根 左 根 。。。 右size_t i = 0;for (; i < cur->_n; i++){_Inorder(cur->_subs[i]); // 左子树std::cout << cur->_keys[i] << " "; // 根}// 最后的那个右子树_Inorder(cur->_subs[i]);
}void Inorder()
{_Inorder(_root);
}
4.5 B-树的性能分析
对于一棵节点为N,度为M的B-树,查找和插入需要 l o g ( M − 1 ) N log(M-1)N log(M−1)N~ l o g ( M / 2 ) N log(M/2)N log(M/2)N次比较:对于度为M的B-树,每一个节点的子节点个数为M/2 ~ M-1之间,因此树的高度应该在 l o g ( M − 1 ) N log(M-1)N log(M−1)N和 l o g ( M / 2 ) N log(M/2)N log(M/2)N之间,在定位到该结点后,再采用二分查找的方式可以很快的定位到该元素
B-树的效率是很高的,对于N=62*1000000000个节点,如果度M为1024,则 l o g M / 2 N log_{M/2}N logM/2N <= 4,即在620亿个元素中,如果这棵树的度为1024,则需要小于4次即可定位到该结点,然后利用二分查找可以快速定位到该元素,大大减少了读取磁盘的次数
4.6 B-树的删除
学习B树的插入足够帮助理解B树的特性,删除可以参考《算法导论》和《数据局结构-殷人昆》-C++
5. B+树和B*树
B+树是B树的变形,在B树基础上优化的多路平衡搜索树,B+树的规则跟B树基本类似,但是又在B树的基础上做了以下几点改进优化:
1.分支节点的子树指针与关键字个数相同(相当于取消了最左的子树)
2.分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1]]区间之间
3.所有叶子节点增加一个连接指针连接在一起
4.所有关键字及其映射数据都在叶子节点出现

B树的特性:
1.所有关键字都出现在叶子结点的链表中,且链表中的节点都是有序的
2.不可能在分支节点命中
3.分支节点相当于是叶子节点的索引,叶子节点才是存储数据的
5.2 B+树
B*树是B+树的变形,在B+树中的非跟和非叶子点再增加指向兄弟节点的指针

B+树的分裂
当一个节点满时,分配一个新的节点,并将原节点中1/2的数据复制到新节点,最后在父节点中增加新及诶点的指针,B+树的分裂只影响原节点和父节点,而不会影响兄弟节点,所以它不需要指向兄弟的指针
B*树的分类
当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针。所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
5.3 总结
B树:有序数组+平衡多茶树
B+树:有序数组链表+平衡多叉树
B*树:一颗丰满的,空间利用率更高的B+树
内存查找B树没有优势:
1.空间利用率低。消耗高
2.插入删除数据时,分裂和合并节点,必然挪动数据
3.虽然高度更低,但是在内存而言,和哈希和平衡搜索树还是一个量级
6. B树的应用
6.1 索引
B-树最常见的应用就是用来做索引。索引通俗的说就是为了方便用户快速找到所寻之物,比如:书籍目录可以让读者快速找到相关信息,hao123网页导航网站,为了让用户能够快速的找到有价值的分类网站,本质上就是互联网页面中的索引结构。
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构,简单来说:索引就是数据结构。
当数据量很大时,为了能够方便管理数据,提高数据查询的效率,一般都会选择将数据保存到数据库,因此数据库不仅仅是帮助用户管理数据,而且数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法,该数据结构就是索引。
6.2 MySQL索引简介
mysql是目前非常流行的开源关系型数据库,不仅是免费的,可靠性高,速度也比较快,而且拥有灵活的插件式存储引擎

索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式不同
注意:索引是基于表的,而不是基于数据库的
6.2.1 MyISAM
MyISAM引擎是MySQL5.5.8版本之前默认的存储引擎,不支持事物,支持全文检索,使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,其结构如下:

上图是以以Col1为主键,MyISAM的示意图,可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果想在Col2上建立一个辅助索引,则此索引的结构如下图所示:

同样也是一棵B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。MyISAM的索引方式也叫做“非聚集索引”的。
6.2.2 InnoDB
InnoDB存储引擎支持事务,其设计目标主要面向在线事务处理的应用,从MySQL数据库5.5.8版本开始,InnoDB存储引擎是默认的存储引擎。InnoDB支持B+树索引、全文索引、哈希索引。但InnoDB使用B+Tree作为索引结构时,具体实现方式却与MyISAM截然不同。第一个区别是InnoDB的数据文件本身就是索引文件。MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而InnoDB索引,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。

上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录,这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。
第二个区别是InnoDB的辅助索引data域存储相应记录主键的值而不是地址,所有辅助索引都引用主键作为data域。

聚簇索引这种实现方式使得主键的搜索十分高效,但是辅助索引需要检索两变索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录,如用id和名字分别查找
B+树主键索引相比B树的优势
1.B+树所有值都在叶子,遍历很方便,方便区间查找
2.对于没有建立索引的字段,全表扫描的遍历也很方便
3.分支节点值存储key,一个分支节点空间占用更小,可以尽可能加载到内存
B树不用叶子就能找到值,B+树一定要到叶子。这是B树的优势,但是B+树高度足够低,所以差别不大
参考资料:
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
相关文章:
04 B-树
目录 常见的搜索结构B-树概念B-树的插入分析B-树的插入实现B树和B*树B-树的应用 1. 常见的搜索结构 种类数据格式时间复杂度顺序查找无要求O(N)二分查找有序O( l o g 2 N log_2N log2N)二分搜索树无要求O(N)二叉平衡树无要求O( l o g 2 N log_2N log2N)哈希无要求O(1) 以…...

计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-27
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-27 目录 文章目录 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-09-27目录1. VisScience: An Extensive Benchmark for Evaluating K12 Educational Multi-modal Scientific Reasoning VisScience:…...

恋爱辅助应用小程序app开发之广告策略
恋爱话术小程序带流量主广告开启,是一个有效的盈利模式,可以增加小程序的收入来源。以下是对此的详细分析 一、流量主广告的定义与优势 流量主广告是指在小程序中嵌入广告位,通过展示广告内容来获取广告主的付费。对于恋爱话术小程序而言&am…...

iTextPDF中,要实现表格中的内容在数据长度超过边框时自动换行
在iTextPDF中,要实现表格中的内容在数据长度超过边框时自动换行,你可以使用Phrase对象并设置其HyphenationEvent,或者使用Chunk对象并设置其setSplitCharacter方法。以下是一些方法来实现这一功能: 1. 使用Phrase对象:…...

Unreal Engine 5 C++: 插件编写03 | MessageDialog
在虚幻引擎编辑器中编写Warning弹窗 准备工作 FMessageDialog These functions open a message dialog and display the specified informations there. EAppReturnType::Type 是 Unreal Engine 中用于表示应用程序对话框(如消息对话框)返回结果的枚举…...

【前端面试题】Vue 3 生命周期钩子的执行顺序详解
前言 在 Vue 3 中,生命周期钩子的执行顺序与 Vue 2 有所不同,特别是 setup 函数取代了传统的生命周期钩子 beforeCreate 和 created。本文将详细解析 Vue 3 的生命周期钩子执行顺序,帮助你更好地理解 Vue 3 的组件生命周期及其工作机制。 V…...
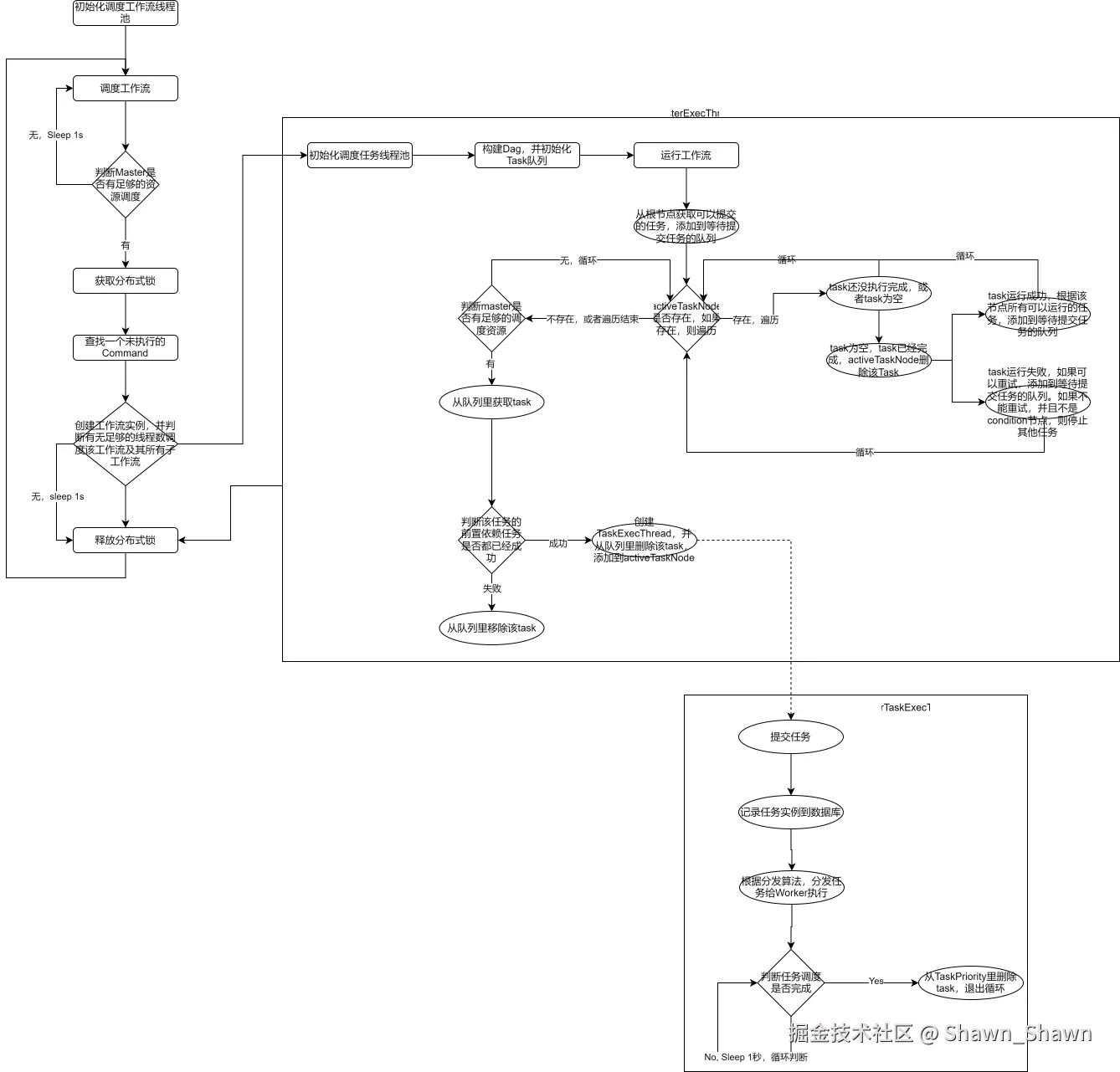
Apache DolphinScheduler-1.3.9源码分析(一)
引言 随着大数据的发展,任务调度系统成为了数据处理和管理中至关重要的部分。Apache DolphinScheduler 是一款优秀的开源分布式工作流调度平台,在大数据场景中得到广泛应用。 在本文中,我们将对 Apache DolphinScheduler 1.3.9 版本的源码进…...

高级java每日一道面试题-2024年9月29日-数据库篇-索引怎么定义,分哪几种?
如果有遗漏,评论区告诉我进行补充 面试官: 索引怎么定义,分哪几种? 我回答: 在Java高级面试中,尤其是涉及数据库和数据结构的部分,索引(Index)是一个核心概念。索引的目的是提高数据库表中数据的检索速度,从而加快…...
现代LLM基本技术整理
0 开始之前 作者:hadiii,北京大学 电子信息硕士在读 本文从Llama 3报告出发,基本整理一些现代LLM的技术。基本,是说对一些具体细节不会过于详尽,而是希望得到一篇相对全面,包括预训练,后训练&…...

EasyX与少儿编程:轻松上手的编程启蒙工具
EasyX:开启少儿编程的图形化启蒙之路 随着科技发展,编程逐渐成为孩子们教育中重要的一部分。如何让孩子在编程启蒙阶段更容易接受并激发他们的兴趣,成为许多家长和老师关心的问题。相比起传统的编程语言,图形化编程工具显得更直观…...

【C语言指南】数据类型详解(上)——内置类型
💓 博客主页:倔强的石头的CSDN主页 📝Gitee主页:倔强的石头的gitee主页 ⏩ 文章专栏:《C语言指南》 期待您的关注 目录 引言 1. 整型(Integer Types) 2. 浮点型(Floating-Point …...

视频汇聚/视频存储/安防视频监控EasyCVR平台RTMP推流显示离线是什么原因?
视频汇聚/视频存储/安防视频监控EasyCVR视频汇聚平台兼容性强、支持灵活拓展,平台可提供视频远程监控、录像、存储与回放、视频转码、视频快照、告警、云台控制、语音对讲、平台级联等视频能力。 EasyCVR安防监控视频综合管理平台采用先进的网络传输技术࿰…...

联想电脑怎么开启vt_联想电脑开启vt虚拟化教程(附intel和amd主板开启方法)
最近使用联想电脑的小伙伴们问我,联想电脑怎么开启vt虚拟。大多数可以在Bios中开启vt虚拟化技术,当CPU支持VT-x虚拟化技术,有些电脑会自动开启VT-x虚拟化技术功能。而大部分的电脑则需要在Bios Setup界面中,手动进行设置ÿ…...

手把手教你使用YOLOv11训练自己数据集(含环境搭建 、数据集查找、模型训练)
一、前言 本文内含YOLOv11网络结构图 训练教程 推理教程 数据集获取等有关YOLOv11的内容! 官方代码地址:https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11 二、整体网络结构图 三、环境搭建 项目环境如下…...
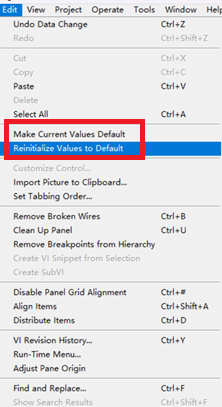
LabVIEW界面输入值设为默认值
在LabVIEW中,将前面板上所有控件的当前输入值设为默认值,可以通过以下步骤实现: 使用控件属性节点:你可以创建一个属性节点来获取所有控件的引用。 右键点击控件,选择“创建” > “属性节点”。 设置属性节点为“D…...

【Android 14源码分析】Activity启动流程-1
忽然有一天,我想要做一件事:去代码中去验证那些曾经被“灌输”的理论。 – 服装…...

Java 中 synchronized 和 Thread 的使用场合介绍
在 Java 编程中,synchronized 和 Thread 是处理并发与多线程编程的关键工具。多线程编程是为了在单一程序中并行执行多个任务,Java 提供了丰富的 API 和关键字以实现这一目标,而其中 synchronized 和 Thread 是非常基础和重要的部分。 synch…...

爬虫库是什么?是ip吗
爬虫库通常指的是用于网页爬虫(Web Scraping)开发的代码库或框架,它不是IP地址。以下是关于爬虫库的详细解释: 爬虫库的定义 爬虫库是一些用于简化网络数据抓取过程的工具和框架,通常提供了一系列函数和类࿰…...
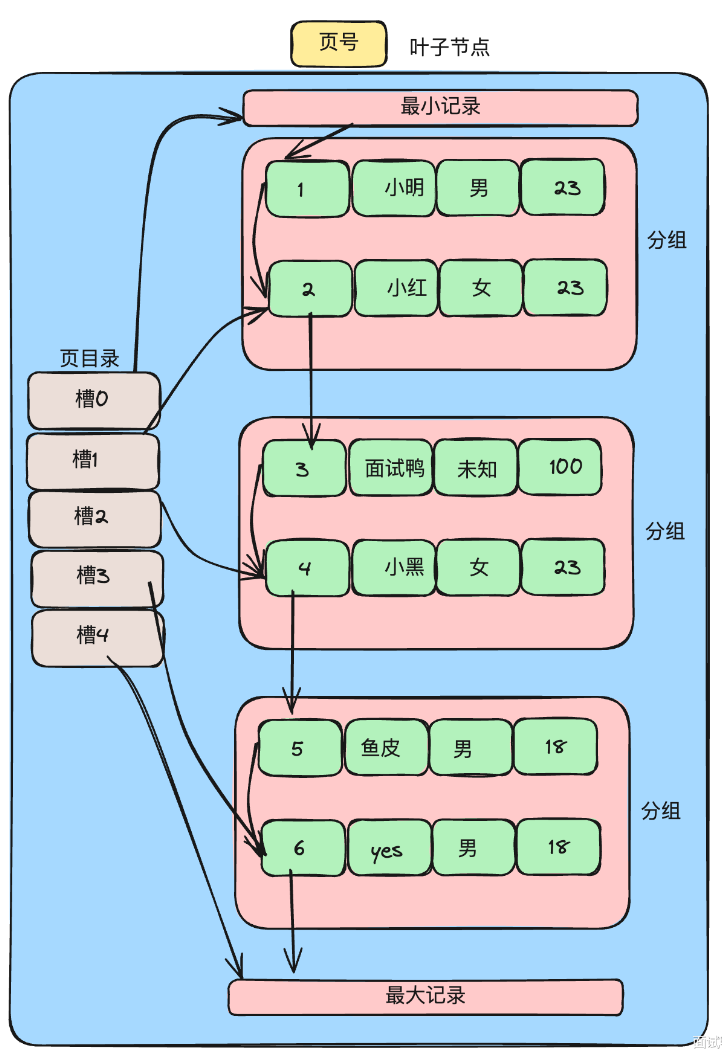
【MySQL】查询原理 —— B+树查询数据全过程
使用B树作为索引结构的原因: 一种自平衡树: B树在插入和删除的时候节点会进行分裂和合并操作,以保持树的平衡,存在冗余节点,使得删除的时候树结构变化小,更高效。 高度不会增长过快,查询磁盘I…...

系统设置 WIFI输入框被挡住解决方案
文章目录 问题点复现的场景机器横屏可复现,竖屏不存在跟density 相关的。 解决问题方案设置输入模式路径 部分源码跟踪方法 延伸思考设置输入模式设置主题 问题点 进入系统设置-网络和互联网-WLAN-点击WIFI item ,密码输入框被遮挡,输入的密码不可见.如…...

功率MOSFET工作原理与电力电子应用解析
1. 功率MOSFET基础概念解析 功率MOSFET(金属氧化物半导体场效应晶体管)是现代电力电子系统的核心开关器件。与普通MOSFET不同,功率MOSFET专为处理高电压(通常>60V)和大电流(>1A)而设计。其…...

DDSP与神经音频合成:AI如何复刻经典合成器音色
1. 项目概述:当AI遇见经典合成器如果你和我一样,是个对复古合成器声音着迷,同时又对现代AI技术充满好奇的音乐制作人或开发者,那么最近在GitHub上出现的martinic/DrMixAISynth项目,绝对值得你花上一个下午的时间好好研…...

oh-my-prompt:模块化终端提示符引擎的设计、配置与性能优化
1. 项目概述:一个为现代终端量身定制的提示符引擎如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那么一个高效、美观且信息丰富的命令行提示符(Prompt)绝对能让你事半功倍…...

不止于仿真:用Multisim14.0的BUCK电路案例,手把手教你理解CCM/DCM模式与电感计算
从波形到公式:用Multisim 14.0解锁BUCK电路CCM/DCM模式的本质理解 当我们第一次翻开电力电子教材,那些关于BUCK电路工作模式的描述往往显得抽象而晦涩。"连续导通模式(CCM)"、"断续导通模式(DCM)"、"临界电感值"——这些概…...

spawnfile:轻量级进程编排工具,提升本地开发与测试效率
1. 项目概述:一个被低估的进程管理利器如果你在Linux或macOS环境下做过开发,尤其是需要频繁启动、停止、监控一堆后台服务(比如微服务架构下的多个组件),那你一定对进程管理工具不陌生。从最基础的nohup加&&#x…...

解锁B站宝藏:一款让你轻松下载无水印高清视频的神器
解锁B站宝藏:一款让你轻松下载无水印高清视频的神器 【免费下载链接】BiliDownload B站视频下载工具 项目地址: https://gitcode.com/gh_mirrors/bil/BiliDownload 你是否经常在B站发现精彩视频,却苦于无法保存到本地?是否因为右上角的…...

自动驾驶人机交接:DMS与安全验证如何破解控制权转移困局
1. 自动驾驶人机交接的核心困境与行业分野最近几年,自动驾驶(AV)和高级驾驶辅助系统(ADAS)无疑是汽车科技领域最炙手可热的话题。无论是传统车企的“新四化”转型,还是科技公司的颠覆性入局,大家…...

Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法
更多请点击: https://intelliparadigm.com 第一章:Gemini实时字幕在Google Meet中延迟超800ms?揭秘谷歌内部SRE监控数据与3步毫秒级调优法 谷歌内部SRE团队近期公开的一组匿名化监控数据显示:在高并发(>500人&…...

深入STM32F429 LTDC双图层与DMA2D:打造流畅UI界面的性能优化指南
STM32F429 LTDC与DMA2D深度优化:构建60FPS工业级UI的实战指南 在工业HMI和医疗设备等对显示性能要求严苛的场景中,流畅的UI动画和实时数据可视化往往成为系统瓶颈。STM32F429的LTDC控制器配合DMA2D加速器,通过合理的架构设计可实现媲美专业GP…...

5步精通:Windows风扇智能控制终极指南
5步精通:Windows风扇智能控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanControl.Rel…...