利用 Llama-3.1-Nemotron-51B 推进精度-效率前沿的发展

今天,英伟达™(NVIDIA®)发布了一款独特的语言模型,该模型具有无与伦比的准确性和效率性能。Llama 3.1-Nemotron-51B 源自 Meta 的 Llama-3.1-70B,它采用了一种新颖的神经架构搜索(NAS)方法,从而建立了一个高度准确和高效的模型。在高工作负荷下,该模型只需一个英伟达™(NVIDIA®)H100 GPU 即可运行,因此更易于使用,也更经济实惠。新模型所表现出的出色精度-效率甜点源于对模型架构的改变,这种改变显著降低了内存占用、内存带宽和 FLOPs,同时保持了出色的精度。我们证明,这种方法可以通过在参考模型的基础上创建另一个更小、更快的变体来加以推广。
2024 年 7 月,Meta 发布了 Llama-3.1-70B,这是一种领先的先进大型语言模型(LLM)。今天,我们宣布推出 Llama 3.1-Nemotron-51B-Instruct,它是利用 NAS 和从 “参考模型”–Llama 3.1-70B 中提炼出的知识而开发的。
卓越的吞吐量和工作效率
与参考模型相比,Nemotron 模型的推理速度提高了 2.2 倍,同时保持了几乎相同的精度。该模型减少了内存占用,在推理过程中可以在单个 GPU 上运行 4 倍更大的工作负载,从而带来了一系列新的机遇。
| Accuracy | Efficiency | |||
| MT Bench | MMLU | Text generation (128/1024) | Summarization/ RAG (2048/128) | |
| Llama-3.1- Nemotron-51B- Instruct | 8.99 | 80.2% | 6472 | 653 |
| Llama 3.1-70B- Instruct | 8.93 | 81.66% | 2975 | 339 |
| Llama 3.1-70B- Instruct (single GPU) | — | — | 1274 | 301 |
| Llama 3-70B | 8.94 | 80.17% | 2975 | 339 |
表 1.Llama-3.1-Nemotron-51B-Instruct 的精度和效率概览。
注:速度以每 GPU 每秒令牌数为单位,在配备 8 X NVIDIA H100 SXM GPU 的机器上测量,使用 TRT-LLM 作为运行时引擎进行 FP8 量化。通过张量并行(除非另有说明),每个模型都采用了最佳 GPU 数量。括号中的数字表示(输入/输出序列长度)。
详细的绩效指标见下文。
优化每美元的精确度
基础模型在解决推理、总结等非常复杂的任务时表现出令人难以置信的质量。然而,采用顶级模型的一个主要挑战是其推理成本。随着生成式人工智能领域的发展,准确性和效率(直接影响成本)之间的平衡将成为选择模型的决定性因素。此外,在单个 GPU 上运行模型的能力大大简化了模型的部署,为新应用在任何地方(从边缘系统到数据中心再到云端)的运行提供了机会,并有助于通过 Kubernetes 和 NIM 蓝图为多个模型提供服务。
因此,我们设计了 Llama 3.1-Nemotron-51B-Instruct,以实现这一最佳权衡。下图显示了领先开源模型的准确性与吞吐量之间的关系。吞吐量与价格成反比,因此图中显示的高效前沿模型可实现最佳权衡。如图所示,该模型超越了当前的有效前沿,成为每美元精度最高的模型。

图 1. 与前沿模型相比,Llama-3.1-Nemotron-51B 的精度与吞吐量性能。吞吐量通过并发 25 的 NIM 进行测量(服务吞吐量)。
注:模型质量定义为 MT-Bench 和 MMLU 的加权平均值(10MT-Bench + MMLU)/2,与单个英伟达 H100 80GB GPU 的模型吞吐量相对照。灰点代表最先进的模型,虚线代表 “高效前沿”。*
利用英伟达™(NVIDIA®)NIM 简化推理过程
Nemotron 模型利用 TensorRT-LLM 引擎进行了优化,以实现更高的推理性能,并打包为 NVIDIA NIM 推理微服务,以简化和加速生成式 AI 模型在包括云、数据中心和工作站在内的任何地方的 NVIDIA 加速基础架构中的部署。
NIM 使用推理优化引擎、行业标准 API 和预构建容器来提供高吞吐量的人工智能推理,并可根据需求进行扩展。

引擎盖下–利用 NAS 建立模型
设计神经架构的推理和硬件感知方法已成功应用于许多领域。然而,LLM 仍然是作为重复的相同块来构建的,很少考虑这种简化所带来的推理成本开销。为了应对这些挑战,我们开发了高效的 NAS 技术和训练方法,可用于创建非标准变压器模型,以便在特定 GPU 上进行高效推理。
我们的技术可以从巨大的设计空间中选择优化各种约束条件的神经架构,这些设计空间包括非标准变压器模型的动物园,这些模型可以利用不同效率程度的替代注意力和 FFN 块,在极端情况下甚至可以完全消除块。
然后,我们使用分块蒸馏(图 2)框架,对(大型)父 LLM 的所有层并行训练所有这些分块变体。在分块蒸馏的基本版本中,训练数据通过参考模型(也称为教师)传递。对于每个区块,其输入都来自教师,并注入学生的匹配区块。对教师和学生的输出进行比较,然后对学生区块进行训练,使学生区块模仿教师区块的功能。图 2 右图描述了一种更高级的情况,即一个学生区块模仿多个教师区块。

图 2区块蒸馏–对于参考模型(蓝色)的区块,我们为 “学生模型”(黄色)创建了多个变体,这些变体模仿了教师的区块功能。
接下来,我们使用 Puzzle 算法对每个替代 "拼图 "进行高效评分,并在巨大的设计空间中搜索最准确的模型,同时遵守一系列推理约束条件,如内存大小和所需吞吐量。最后,通过将知识蒸馏(KD)损失用于区块评分和训练,我们展示了利用更高效的架构缩小我们的模型与参考模型之间准确率差距的潜力,而训练成本仅为参考模型的一小部分。使用我们在 Llama-3.1-70B 模型上的方法作为参考模型,我们构建了 Llama-3.1-Nemotron-51B-Instruct,这是一个 51B 模型,它在单个英伟达 H100 GPU 上打破了 LLM 的高效前沿(图 1)。
Llama-3.1-Nemotron-51B-Instruct 架构的独特之处在于它的不规则块结构,其中有许多层,在这些层中,注意力和 FFN 被减少或修剪,从而更好地利用了 H100,并凸显了优化 LLM 对于推理的重要性。图 3 以示意图的形式描述了由此产生的架构的不规则结构,并强调了由此节省的计算量,即图中的绿色区域。

图 3.在参考模型的 80 个图层中,Puzzle 为注意力图层(蓝色)和 FFN 图层(红色)所选图块(图层)的运行时间。绿色区域对应的是总体运行时间节省。
我们的创新技术使我们能够开发出重新定义 LLM 高效前沿的模型。最重要的是,我们可以从一个参考模型出发,经济高效地设计多个模型,每个模型都针对特定的硬件和推理场景进行了优化。这种能力使我们能够在当前和未来的硬件平台上保持 LLM 推理的一流性能。
详细结果
模型精度
下表列出了我们评估的所有基准–比较我们的模型和参考模型 Llama3.1-70B。保留的准确度 "是我们的模型得分与教师得分之间的比率。
| Benchmark | Llama-3.1 70B-instruct | Llama-3.1-Nemotron-51B- Instruct | Accuracy preserved |
| winogrande | 85.08% | 84.53% | 99.35% |
| arc_challenge | 70.39% | 69.20% | 98.30% |
| MMLU | 81.66% | 80.20% | 98.21% |
| hellaswag | 86.44% | 85.58% | 99.01% |
| gsm8k | 92.04% | 91.43% | 99.34% |
| truthfulqa | 59.86% | 58.63% | 97.94% |
| xlsum_english | 33.86% | 31.61% | 93.36% |
| MMLU Chat | 81.76% | 80.58% | 98.55% |
| gsm8k Chat | 81.58% | 81.88% | 100.37% |
| Instruct HumanEval (n=20) | 75.85% | 73.84% | 97.35% |
| MT Bench | 8.93 | 8.99 | 100.67% |
表 2. Nemotron 模型与 Llama 3.1-70B-Instruct 在多个行业基准中的精度比较。
性能
下表详细列出了每个 GPU(H100 80GB)每秒的令牌数量。可以看出,在一系列相关情况下(短输入和长输入以及输出),我们的模型比教师模型的吞吐量高出一倍,因此在多种使用情况下都具有成本效益。TPX 描述了并行处理的 GPU 数量。我们还列出了 Llama 3.1-70B 在单 GPU 上的性能,以证明我们的模型在这种情况下的价值。
| Scenario | Input/Output Sequence Length | Llama-3.1- Nemotron- Instruct | Llama-3.1-70B-Instruct | Ratio | Llama (TP1) |
| Chatbot | 128/128 | 5478 (TP1) | 2645 (TP1) | 2.07 | 2645 |
| Text generation | 128/1024 | 6472 (TP1) | 2975 (TP4) | 2.17 | 1274 |
| Long text generation | 128/2048 | 4910 (TP2) | 2786 (TP4) | 1.76 | 646 |
| System 2 reasoning | 128/4096 | 3855 (TP2) | 1828 (TP4) | 2.11 | 313 |
| Summarization/ RAG | 2048/128 | 653 (TP1) | 339 (TP4) | 1.92 | 300 |
| Stress test 1 | 2048/2048 | 2622 (TP2) | 1336 (TP4) | 1.96 | 319 |
表 3.热门用例中模型生成令牌数量的吞吐量比较。所有数字均以每 GPU 每秒生成的令牌数为单位。
决定模型运行成本的主要因素是吞吐量–系统在一秒钟内生成的令牌总数。不过,在某些情况下(如聊天机器人),单个终端用户收到模型响应的速度对用户体验非常重要。这可以用每个用户每秒产生的代币来量化,称为用户端吞吐量。下图显示了用户端吞吐量与不同批次规模下吞吐量的对比图。可以看出,在所有批次规模下,我们的模型都优于 Llama 3.1-70B。

图 4.Nemotron 模型和 Llama-3.1-70B 在不同批次规模下的服务器吞吐量与用户端吞吐量对比图。
为不同需求量身定制 LLM
NAS 方法为用户提供了在精度和效率之间选择最佳平衡点的灵活性。为了展示这种灵活性,我们在同一参考模型的基础上创建了另一个变体,这次优先考虑的是速度和成本。Llama-3.1-Nemotron-40B-Instruct 采用相同的方法开发,但在 "拼图 "阶段修改了速度要求。
与原模型相比,该模型的速度提高了 3.2 倍,但准确性略有下降。下表列出了具有竞争力的性能指标。
| Accuracy | Speed | |||
| MT bench | MMLU | Text generation(128/1024) | Summarization/ RAG (2048/128) | |
| Llama-3.1- Nemotron-40B-instruct | 8.69 | 77.10% | 9568 | 862 |
| Llama-3.1- Nemotron-51B-instruct | 8.99 | 80.20% | 6472 | 653 |
| Llama 3.1-70B-Instruct | 8.93 | 81.72% | 2975 | 339 |
| Gemma2-27B | 8.88 | 76.54% | ADD | ADD |
表 4.Llama-3.1-Nemotron-40B-Instruct 的精度和效率概览。
总结
Llama 3.1-Nemotron-51B-Instruct 为希望使用高精度地基模型的用户和公司提供了一系列新的机会,同时又能控制成本。通过在精度和效率之间进行最佳权衡,我们相信该模型对建筑商来说是一个极具吸引力的选择。此外,这些结果证明了 NAS 方法的有效性,并打算将该方法扩展到其他模型。
相关文章:
利用 Llama-3.1-Nemotron-51B 推进精度-效率前沿的发展
今天,英伟达™(NVIDIA)发布了一款独特的语言模型,该模型具有无与伦比的准确性和效率性能。Llama 3.1-Nemotron-51B 源自 Meta 的 Llama-3.1-70B,它采用了一种新颖的神经架构搜索(NAS)方法&#…...

SpringBoot+Thymeleaf发票系统
> 这是一个基于SpringBootSpringSecurityThymeleafBootstrap实现的简单发票管理系统。 > 实现了用户登录,权限控制,客户管理,发票管理等功能。 > 并且支持导出为 CSV / PDF / EXCEL 文件。 > 本项目是一个小型发票管理系统…...

Updates were rejected because the tip of your current branch is behind 的解决方法
1. 问题描述 当我们使用 git push 推送代码出现以下问题时: 2. 原因分析 这个错误提示表明当前本地分支落后于远程分支,因此需要先拉取远程的更改。 3. 解决方法 1、拉取远程更改 在终端中执行以下命令,拉取远程分支的更新并合并到本地…...

Redis桌面工具:Tiny RDM
1.Tiny RDM介绍 Tiny RDM(Tiny Redis Desktop Manager)是一个现代化、轻量级的Redis桌面客户端,支持Linux、Mac和Windows操作系统。它专为开发和运维人员设计,使得与Redis服务器的交互操作更加便捷愉快。Tiny RDM提供了丰富的Red…...

【Java】酒店管理系统
一 需求: 编写程序 模拟酒店管理系统 : 预订和退订以及查看所有房间 1 需要有一个酒店类 2 需要有一个房间类 3 需要有一个客户端类 public class Test { } 二 分析: 客户端 : 1 先打印所有房间 2 等待用户输入,根据输入情况 判断是预订还是退订 3 等待用户输入房间号 …...

【数据库】Java 中 MongoDB 使用指南:步骤与方法介绍
MongoDB 是一个流行的 NoSQL 数据库,因其灵活性和高性能而广泛使用。在 Java 中使用 MongoDB,可以通过 MongoDB 官方提供的 Java 驱动程序来实现。本文将详细介绍在 Java 中使用 MongoDB 的步骤以及相关方法。 1. 环境准备 1.1 安装 MongoDB 首先&…...

MySQL之内置函数
目录 一、日期函数 二、字符串函数 三、数学函数 四、其它函数 一、日期函数 常见的日期函数如下: 函数名称说明current_date()获取当前日期current_time()获取当前时间current_timestamp()获取当前时间戳date_add(date, interval d_value_type)在date中添加日…...
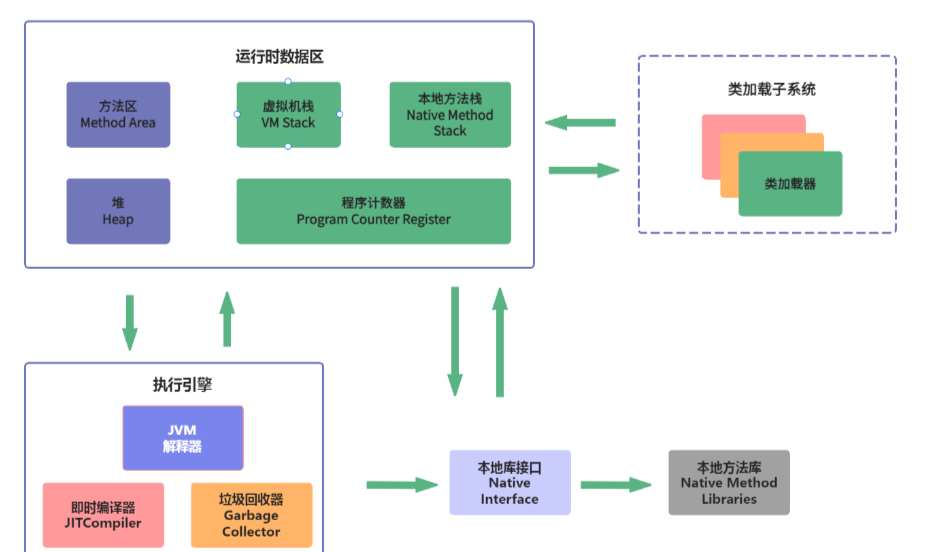
JVM 基本组成
1.为什么要学习JVM? 未来在工作场景中,也许你会遇到以下场景:线上系统突然宕机,系统无法访问,甚至直接OOM;线上系统响应速度太慢,优化系统性能过程中发现CPU占用过高,原因也许是因为…...

Ubuntu 离线安装 docker
1、下载离线包,网址:https://download.docker.com/linux/ubuntu/dists/xenial/pool/stable/ 离线安装docker需要下载3个包,containerd.io ,docker-ce-cli,docker-ce 2、下载完毕后拷贝到ubuntu上用 dpkg 命令安装&am…...

【C++】set详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! 📢本文由 JohnKi 原创,首发于 CSDN🙉 📢未来很长&#…...

C++游戏开发:构建高性能、沉浸式游戏体验的关键
引言 C作为游戏开发的核心语言,凭借其卓越的性能和灵活性,已成为许多现代游戏引擎和开发项目的首选。在游戏开发中,C不仅可以实现复杂的游戏逻辑,还能有效管理资源和优化性能。本文将深入探讨C在游戏开发中的应用,结合…...
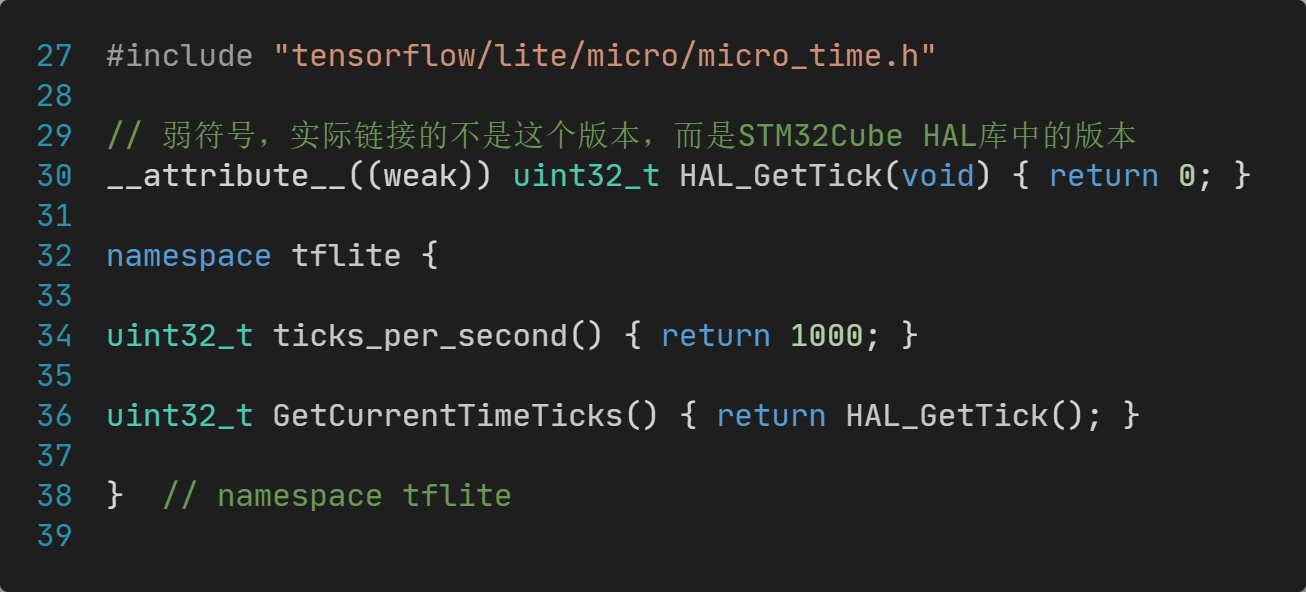
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【上篇】
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【上篇】 一、TFLM是什么?二、TFLM开源项目2.1 下载TFLM源代码2.2 TFLM基准测试说明2.3 TFLM基准测试命令 三、TFLM初步体验3.1 PC上运行Keyword基准测试3.2 PC上运行Person detection基准测试3.3 No module nam…...
第三方供应商不提供API接口?教你四步破解集成难题
API开放需求 在企业数字化转型过程中,异构系统之间的连接是信息化阶段不可或缺的一环。通过应用API,企业能够实现不同系统、平台和应用之间的数据交换与功能调用,从而形成端到端的业务流程协同。然而,很多企业在集成第三方供应商…...

WebAssembly 为什么能提升性能,怎么使用它 ?
文章目录 简介:起源:前端性能提升历史JIT(Just-In-Time)编译器(即时编译) 为什么需要WebAssembly:WebAssembly能做什么:经常说WASM的性能高,为什么高??使用方法:Emscript…...
:init函数,匿名函数,闭包,defer)
golang学习笔记13-函数(二):init函数,匿名函数,闭包,defer
注:本人已有C,C,Python基础,只写本人认为的重点。 这个知识点基本属于go的特性,比较重要,需要认真分析。 一、init函数 每个文件都可以定义init函数,它会在main函数执行前被调用,无论它的定义…...

HAproxy,nginx实现七层负载均衡
环境准备: 192.168.88.25 (client) 192.168.88.26 (HAproxy) 192.168.88.27 (web1) 192.168.88.28 (web2) 192.168.88.29 (php1) 192.168.88.30…...

ps aux | grep smart_webrtc这条指令代表什么意思
这条指令是在Linux系统中使用的命令,它的含义是列出所有正在运行的进程,并通过grep命令筛选出包含"smart_webrtc"关键字的进程。 具体解释如下: ps 是一个用于报告当前系统进程状态的命令。aux 是ps命令的选项,其中&a…...

第十三届蓝桥杯真题Python c组D.数位排序(持续更新)
博客主页:音符犹如代码系列专栏:蓝桥杯关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 问题描述 小蓝对一个数的数位之和很感兴趣, 今天他要按照数位之和给数排序。…...

【RabbitMQ】RabbitMq消息丢失、重复消费以及消费顺序性的解决方案
RabbitMq消息丢失主要是有三种情况:生产者消息未发送到服务端、服务端消息没有做持久化导致丢失、消费端未收到消息。解决方案依次如下: 开启事务或使用确认机制。对于一些重要的消息,生产者可以开启事务,确保消息发送成功后再提…...

海陆钻井自动化作业机器人比例阀放大器
海陆钻井自动化作业机器人是现代海洋石油勘探与钻井领域的关键装备,它通过自动化和无人化技术显著提高了钻井效率和安全性。海陆钻井自动化作业机器人主要用于在海上和陆地的钻井平台上进行自动化、无人化的一体化作业。这种设备能够自动切换钻杆,极大地…...

告别答辩PPT焦虑:百考通AI如何智能化解你的毕业展示难题
当你终于为论文画上最后一个句号,准备迎接毕业的曙光时,答辩PPT的制作却往往成为压垮学生的最后一根稻草。面对这份看似简单却暗藏玄机的任务,百考通AI为你提供智能解决方案。 深夜,当你的论文最后一个字终于落定,一种…...

告别桌面混乱!Ubuntu 16.04 多桌面+Terminator分屏,打造程序员高效工作流
Ubuntu 16.04多桌面与Terminator分屏:构建程序员的高效工作流 作为一名长期在Ubuntu环境下工作的开发者,我深刻体会到工作环境配置对效率的影响。桌面混乱、窗口堆叠、频繁切换不仅浪费时间,还会打断编程的"心流"状态。经过多次迭代…...

对比官方价格体验Taotoken活动价带来的直接成本节省
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价格体验 Taotoken 活动价带来的直接成本节省 在开发与使用大模型 API 的过程中,成本是每个开发者与团队都需要…...

知识图谱与智能体如何革新小说创作:graphify-novel项目深度解析
1. 项目概述:用知识图谱为你的小说创作装上“第二大脑”如果你是一位小说创作者,无论是网文作者、传统文学写作者,还是游戏叙事设计师,你一定经历过这样的痛苦时刻:写到第30章,突然想不起某个配角在第5章出…...

Hermes Agent 可视化监控与文档生成工具 hermes-dashboard 详解
1. 项目概述与核心价值如果你正在使用 Hermes Agent 进行 AI 智能体开发,或者对 Agent 的内部运行状态感到好奇,那么你很可能需要一个“上帝视角”。hermes-dashboard正是这样一个工具,它为你提供了一个实时的监控仪表盘和一个自动生成的、可…...

AI代理技术如何赋能新生儿护理:从数据记录到个性化模式学习
1. 项目概述:当AI成为新手父母的“第二大脑”孩子出生的头三个月,被无数过来人称为“生存模式”。这不是夸张。在那些昼夜颠倒、睡眠被切割成碎片、大脑因极度疲惫而停摆的日子里,新手父母面对的不仅仅是新生儿的啼哭,更是一场信息…...

ZeroAPI:基于订阅与任务感知的AI模型智能路由插件设计与实践
1. 项目概述:ZeroAPI,一个为AI订阅服务而生的智能路由插件如果你和我一样,手头订阅了不止一个AI服务——比如OpenAI的ChatGPT Plus、月之暗面的Kimi、智谱AI的GLM,可能还有MiniMax或者通义千问——那你一定遇到过这个烦恼…...

别再傻傻分不清了!舵机、步进、无刷、永磁同步,这四种电机到底怎么选?
机器人开发者必读:四大电机选型实战指南 当你在深夜调试机器人关节时,是否曾被电机的异常啸叫声惊醒?三年前我参与四足机器人项目时,就因选错电机类型导致整机功耗超标。本文将用真实项目经验,帮你避开电机选型的那些坑…...

微信消息自动转发:5分钟实现跨群智能消息同步
微信消息自动转发:5分钟实现跨群智能消息同步 【免费下载链接】wechat-forwarding 在微信群之间转发消息 项目地址: https://gitcode.com/gh_mirrors/we/wechat-forwarding 在微信群管理和团队协作中,你是否经常需要将重要消息手动转发到多个群聊…...

5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南
5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 你…...