机器学习框架(含实例说明)

机器学习框架是用于开发和部署机器学习模型的软件库和工具集。它们提供了一系列的算法、工具和基础设施,帮助开发者更高效地构建、训练和部署机器学习模型。以下是一些主要的机器学习框架及其详细介绍:
1. TensorFlow
TensorFlow 是由Google开发的开源机器学习框架,广泛应用于深度学习和机器学习领域。
-
特点:
- 灵活性:支持多种编程语言(如Python、C++、Java)。
- 分布式计算:支持在多GPU和多服务器上进行分布式训练。
- 可视化:提供TensorBoard工具,用于模型可视化和调试。
- 生态系统:拥有丰富的扩展库和工具,如Keras(高级API)、TFX(生产化工具)。
-
应用场景:
- 图像识别
- 自然语言处理
- 推荐系统
- 强化学习
2. PyTorch
PyTorch 是由Facebook开发的深度学习框架,以其动态计算图和易用性著称。
-
特点:
- 动态计算图:支持动态定义和执行计算图,便于调试和实验。
- Pythonic:与Python语言紧密集成,代码简洁易读。
- 分布式训练:支持多GPU和多节点分布式训练。
- 生态系统:拥有丰富的扩展库,如TorchVision、TorchText、TorchAudio。
-
应用场景:
- 计算机视觉
- 自然语言处理
- 生成对抗网络(GAN)
- 强化学习
3. Keras
Keras 是一个高级神经网络API,最初作为独立框架开发,后被集成到TensorFlow中。
-
特点:
- 易用性:提供简单直观的API,适合快速原型设计和实验。
- 模块化:支持多种神经网络层、损失函数和优化器。
- 兼容性:可以与TensorFlow、Theano、CNTK等后端兼容。
-
应用场景:
- 快速原型设计
- 深度学习入门
- 小型项目
4. Scikit-learn
Scikit-learn 是一个基于Python的机器学习库,提供了广泛的机器学习算法和工具。
-
特点:
- 易用性:API设计简单,文档详尽,适合初学者。
- 丰富的算法:涵盖分类、回归、聚类、降维等多种机器学习算法。
- 集成性:与NumPy、Pandas等数据处理库无缝集成。
-
应用场景:
- 数据挖掘
- 数据分析
- 传统机器学习任务
5. MXNet
MXNet 是由Apache基金会开发的开源深度学习框架,以其高效性和灵活性著称。
-
特点:
- 高效性:支持多种编程语言(如Python、R、Scala),并优化了计算性能。
- 灵活性:支持静态和动态计算图。
- 分布式训练:支持多GPU和多节点分布式训练。
-
应用场景:
- 大规模图像识别
- 自然语言处理
- 推荐系统
6. Caffe
Caffe 是一个专注于计算机视觉的深度学习框架,由Berkeley Vision and Learning Center开发。
-
特点:
- 高效性:针对图像处理进行了优化,计算速度快。
- 模块化:支持多种网络层和损失函数。
- 社区支持:拥有活跃的社区和丰富的预训练模型。
-
应用场景:
- 图像分类
- 目标检测
- 图像分割
7. Theano
Theano 是一个基于Python的数值计算库,特别适合用于定义、优化和评估数学表达式。
-
特点:
- 符号计算:支持符号微分和自动求导。
- GPU加速:支持在GPU上进行计算,提高计算效率。
- 灵活性:可以与NumPy等库无缝集成。
-
应用场景:
- 深度学习研究
- 科学计算
- 数值优化
8. PaddlePaddle
PaddlePaddle 是由百度开发的开源深度学习框架,专注于工业级应用。
-
特点:
- 高效性:针对大规模分布式训练进行了优化。
- 易用性:提供丰富的API和工具,便于快速开发。
- 生态系统:拥有丰富的扩展库和预训练模型。
-
应用场景:
- 自然语言处理
- 推荐系统
- 图像识别
机器学习框架是用于开发和部署机器学习模型的软件库和工具集。它们提供了一系列的算法、工具和基础设施,帮助开发者更高效地构建、训练和部署机器学习模型。以下是一些主要的机器学习框架及其详细介绍:
1. TensorFlow
TensorFlow 是由Google开发的开源机器学习框架,广泛应用于深度学习和机器学习领域。
-
特点:
- 灵活性:支持多种编程语言(如Python、C++、Java)。
- 分布式计算:支持在多GPU和多服务器上进行分布式训练。
- 可视化:提供TensorBoard工具,用于模型可视化和调试。
- 生态系统:拥有丰富的扩展库和工具,如Keras(高级API)、TFX(生产化工具)。
-
应用场景:
- 图像识别
- 自然语言处理
- 推荐系统
- 强化学习
2. PyTorch
PyTorch 是由Facebook开发的深度学习框架,以其动态计算图和易用性著称。
-
特点:
- 动态计算图:支持动态定义和执行计算图,便于调试和实验。
- Pythonic:与Python语言紧密集成,代码简洁易读。
- 分布式训练:支持多GPU和多节点分布式训练。
- 生态系统:拥有丰富的扩展库,如TorchVision、TorchText、TorchAudio。
-
应用场景:
- 计算机视觉
- 自然语言处理
- 生成对抗网络(GAN)
- 强化学习
3. Keras
Keras 是一个高级神经网络API,最初作为独立框架开发,后被集成到TensorFlow中。
-
特点:
- 易用性:提供简单直观的API,适合快速原型设计和实验。
- 模块化:支持多种神经网络层、损失函数和优化器。
- 兼容性:可以与TensorFlow、Theano、CNTK等后端兼容。
-
应用场景:
- 快速原型设计
- 深度学习入门
- 小型项目
4. Scikit-learn
Scikit-learn 是一个基于Python的机器学习库,提供了广泛的机器学习算法和工具。
-
特点:
- 易用性:API设计简单,文档详尽,适合初学者。
- 丰富的算法:涵盖分类、回归、聚类、降维等多种机器学习算法。
- 集成性:与NumPy、Pandas等数据处理库无缝集成。
-
应用场景:
- 数据挖掘
- 数据分析
- 传统机器学习任务
5. MXNet
MXNet 是由Apache基金会开发的开源深度学习框架,以其高效性和灵活性著称。
-
特点:
- 高效性:支持多种编程语言(如Python、R、Scala),并优化了计算性能。
- 灵活性:支持静态和动态计算图。
- 分布式训练:支持多GPU和多节点分布式训练。
-
应用场景:
- 大规模图像识别
- 自然语言处理
- 推荐系统
6. Caffe
Caffe 是一个专注于计算机视觉的深度学习框架,由Berkeley Vision and Learning Center开发。
-
特点:
- 高效性:针对图像处理进行了优化,计算速度快。
- 模块化:支持多种网络层和损失函数。
- 社区支持:拥有活跃的社区和丰富的预训练模型。
-
应用场景:
- 图像分类
- 目标检测
- 图像分割
7. Theano
Theano 是一个基于Python的数值计算库,特别适合用于定义、优化和评估数学表达式。
-
特点:
- 符号计算:支持符号微分和自动求导。
- GPU加速:支持在GPU上进行计算,提高计算效率。
- 灵活性:可以与NumPy等库无缝集成。
-
应用场景:
- 深度学习研究
- 科学计算
- 数值优化
8. PaddlePaddle
PaddlePaddle 是由百度开发的开源深度学习框架,专注于工业级应用。
-
特点:
- 高效性:针对大规模分布式训练进行了优化。
- 易用性:提供丰富的API和工具,便于快速开发。
- 生态系统:拥有丰富的扩展库和预训练模型。
-
应用场景:
- 自然语言处理
- 推荐系统
- 图像识别
为了更好地理解机器学习框架的应用,以下是几个具体的实例,展示了如何在不同的框架中实现常见的机器学习任务。
1. TensorFlow 实例:图像分类
在这个实例中,我们将使用TensorFlow和Keras构建一个简单的图像分类模型,用于识别手写数字(MNIST数据集)。
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
数据预处理
train_images = train_images.reshape((6, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((1, 28, 28, 1)).astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
构建模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(1, activation='softmax')
])
编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
训练模型
model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_split=.2)
评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'Test accuracy: {test_acc}')
2. PyTorch 实例:图像分类
在这个实例中,我们将使用PyTorch构建一个简单的图像分类模型,用于识别手写数字(MNIST数据集)。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((.137,), (.381,))
])
加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=False)
定义模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 1)
def forward(self, x):
x = self.conv1(x)
x = torch.relu(x)
x = self.conv2(x)
x = torch.relu(x)
x = torch.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
output = torch.log_softmax(x, dim=1)
return output
model = Net()
定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=.1)
训练模型
for epoch in range(5):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
评估模型
model.eval()
test_loss =
correct =
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 1. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss}, Accuracy: {accuracy}%')
3. Scikit-learn 实例:线性回归
在这个实例中,我们将使用Scikit-learn构建一个简单的线性回归模型,用于预测房价。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
生成模拟数据
np.random.seed()
X = 2 * np.random.rand(1, 1)
y = 4 + 3 * X + np.random.randn(1, 1)
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2, random_state=42)
构建线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
预测
y_pred = model.predict(X_test)
评估模型
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
可视化结果
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, y_pred, color='blue', linewidth=3)
plt.xlabel('X')
plt.ylabel('y')
plt.title('Linear Regression')
plt.show()
总结
选择合适的机器学习框架取决于具体的应用场景、开发需求和团队的技术栈。TensorFlow和PyTorch是目前最流行的深度学习框架,适用于大多数深度学习任务。Scikit-learn则适合传统机器学习和数据分析任务。其他框架如MXNet、Caffe、Theano和PaddlePaddle也各有特色,适用于特定的应用场景。
相关文章:
机器学习框架(含实例说明)
机器学习框架是用于开发和部署机器学习模型的软件库和工具集。它们提供了一系列的算法、工具和基础设施,帮助开发者更高效地构建、训练和部署机器学习模型。以下是一些主要的机器学习框架及其详细介绍: 1. TensorFlow TensorFlow 是由Google开发的开源…...

vue2与vue3知识点
1.vue2(optionsAPI)选项式API 2.vue3(composition API)响应式API vue3 setup 中this是未定义(undefined)vue3中已经开始弱化this vue2通过this可以拿到vue3setup定义得值和方法 setup语法糖 ref > …...

从源码中学习动态代理模式
动态代理模式 动态代理是 Java 反射(Reflection)API 提供的一种强大机制,它允许在运行时创建对象的代理实例,而不需要在编译时静态地创建。 Java 提供了两种主要的方式来实现动态代理: 基于接口的动态代理:…...

谷歌浏览器完美清除缓存
1.在页面上按下键盘的F12,打开控制台。 2.鼠标放到刷新图标上,点击鼠标右键,选择‘清空缓存并硬性重新加载’。 这样浏览器对网站页面的缓存就彻底被清理干净了。 目前支持该操作方式的浏览器有谷歌和Edge浏览器。 有的浏览器不支持该方式操…...

《如何高效学习》
有道云笔记 第一部分 整体性学习策略 结构 结构就像思想中的一座城市,有很多建筑物,建筑物之间有道路相连,有高大而重要的与其他建筑有上百条路相连,无关紧要的建筑只有少数泥泞的小道与外界相通。 建立良好的知识结构就是绘制…...

阿里云ACP认证考试题库
最近有好些同学,考完阿里云ACP了,再来跟我反馈:自己花700买的阿里云ACP题库,结果答案是错的! 或者考完后发现,买的阿里云ACP题库覆盖率只有50%! 为避免大家继续踩坑,给大家分享一个阿…...

学习经验分享【38】YOLOv11解读——最新YOLO版本
YOLO算法更新速度很快,已经出到V11版本,后续大家有想发论文或者搞项目可更新自己的baseline了。后续将改进YOLOv11算法,有需要的朋友可关注,我会持续进行更新。 YOLO11是Ultralytics YOLO系列实时目标检测器的最新迭代版本&#x…...

电商选品/分析| 亚马逊常见插件爬虫实战之-helium插件
说明 插件爬虫相当于二次爬虫,二次加工信息,因为大部分插件信息也是从正规网上去获取数据,这次列举helium插件爬虫案例,其他插件爬虫也是类似这个方式. 需求 1、⽤⾕歌浏览器,下载chrome extension:“Helium 10 2、登录helium10 3、打开 打开Amazo…...

遇到慢SQL、SQL报错,应如何快速定位问题 | OceanBase优化实践
在数据库的使用中,大家时常会遇到慢SQL,或执行出错的SQL。对于某些SQL问题,其错误原因显而易见,但也有不少情况难以直观判断。面对这类问题,我们应当如何应对?如何准确识别SQL错误的根源?是否需…...
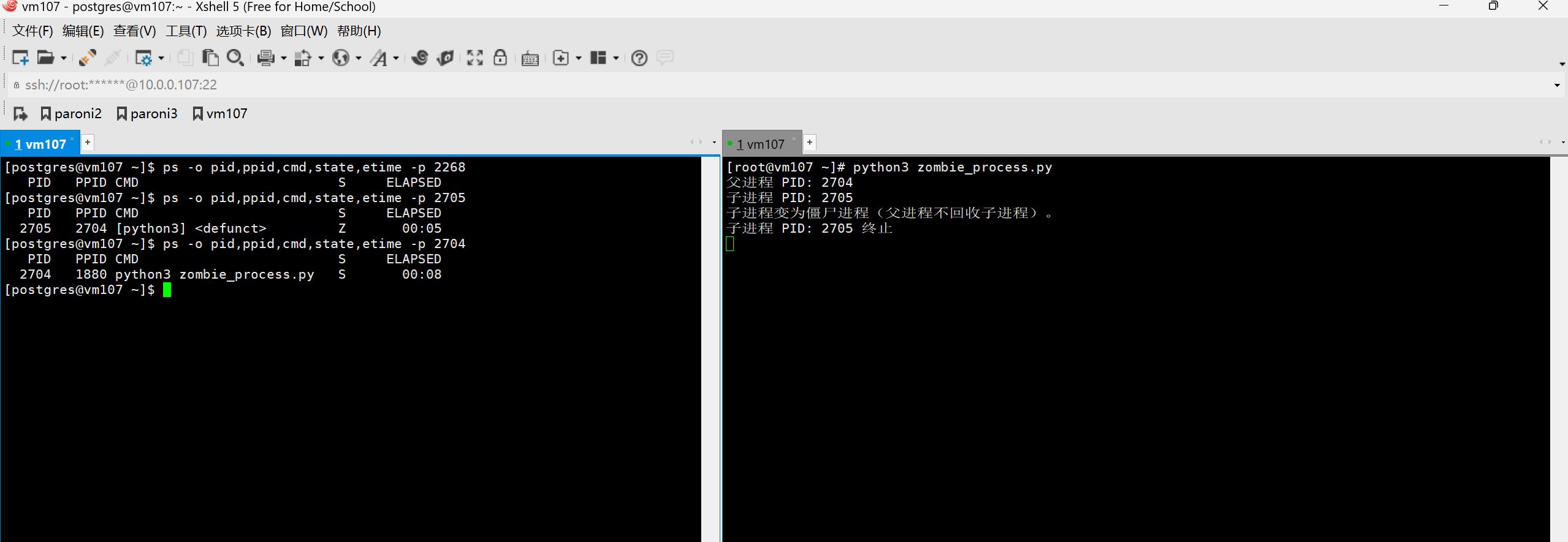
postgresql僵尸进程的处理思路
简介 僵尸进程(zombie process)是指一个已经终止但仍然在进程表中保留条目的进程。正常情况下,当一个进程完成执行并退出时,操作系统会通过父进程调用的wait()或waitpid()系统调用来收集该子进程的退出状态。如果父进程未及时调用…...

Springboot 练习
Springboot练习——分页查询 Emp类 package com.wzb.pojo20240930;import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor;import java.time.LocalDate; import java.time.LocalDateTime;Data NoArgsConstructor AllArgsConstructor public…...

ISA-95制造业中企业和控制系统的集成的国际标准-(3)
ISA-95 文章目录 ISA-95ISA-95设备对象模型一、设备对象模型是什么?二、设备对象模型常见组织 ISA-95设备对象模型 ISA-95 标准中的设备对象模型侧重于表示制造和生产过程中使用的物理和逻辑设备及资源。 一、设备对象模型是什么? 设备对象模型提供了…...

MATLAB中图形导出功能的详细使用指南
在MATLAB中,图形的导出是一个常见的需求,无论是为了报告、演示还是进一步的分析。MATLAB提供了多种方式来导出图形,包括使用图形用户界面(GUI)的工具,以及通过编程方式使用特定的函数。本文将详细介绍如何在MATLAB中导出图形&…...

助农小程序|助农扶贫系统|基于java的助农扶贫系统小程序设计与实现(源码+数据库+文档)
助农扶贫系统小程序 目录 基于java的助农扶贫系统小程序设计与实现 一、前言 二、系统功能设计 三、系统实现 5.1.1 农户管理 5.1.2 用户管理 5.1.3 订单统计 5.2.1 商品信息管理 5.3.1 商品信息 5.3.2 订单信息 5.3.3 商品评价 5.3.4 商品退货 四、数据库设计 1、…...

SpringBoot上传图片实现本地存储以及实现直接上传阿里云OSS
一、本地上传 概念:将前端上传的文件保存到自己的电脑 作用:前端上传的文件到后端,后端存储的是一个临时文件,方法执行完毕会消失,把临时文件存储到本地硬盘中。 1、导入文件上传的依赖 <dependency><grou…...

git clone或repo init 时报错:fatal: 协议错误:错误的行长度 xxx
执行repo init或git clone时报错:protocol error: bad line length 或协议错误:错误的行长度 系统版本:Ubuntu20.04 repo version v2.47 repo launcher version 2.45 git version 2.25.1 报错信息 fatal: 协议错误:错误的行长度 948 fatal: 远端意外挂断了 repo: err…...
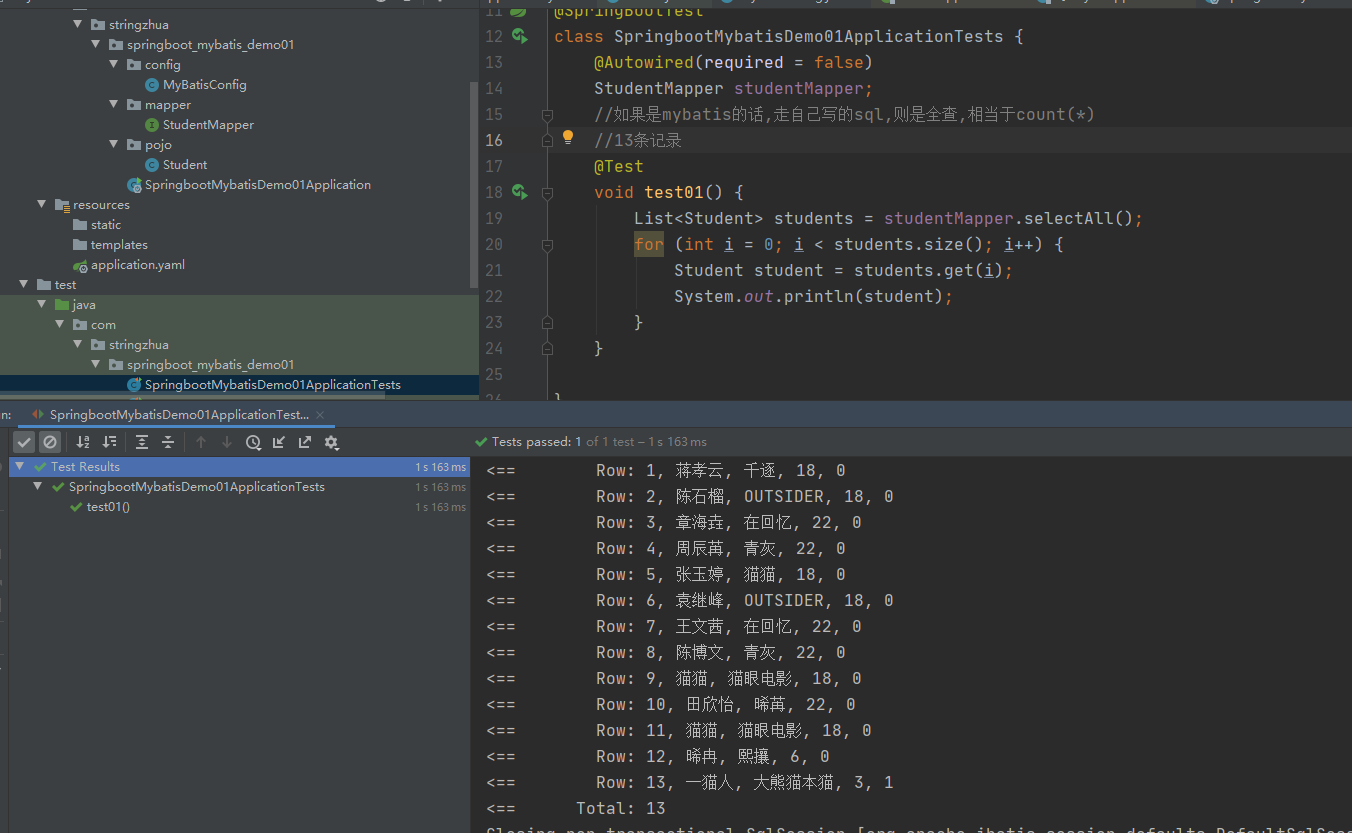
SpringBoot2(Spring Boot 的Web开发 springMVC 请求处理 参数绑定 常用注解 数据传递 文件上传)
SpringBoot2(Spring Boot 的Web开发 springMVC 请求处理 参数绑定 常用注解 数据传递 文件上传) 一、Spring Boot的Web开发 1.静态资源映射规则 总结:只要静态资源放在类路径下: called /static (or /public or /resources or …...

成都网安周暨CCS2024 | 大模型安全与产业应用创新研讨活动成功举办
9月11日-12日,作为2024年国家网络安全宣传周成都系列活动的重磅活动之一,CCS 2024成都网络安全系列活动在成都举行。“大模型安全与产业应用创新研讨活动”同期举办,本场活动由百度安全、成都无糖信息联合承办,特邀云安全联盟CSA大…...

React 解释常见的 hooks: useState / useRef / useContext / useReducer
前言 如果对 re-render 概念还不清楚,建议先看 React & 理解 re-render 的作用、概念,并提供详细的例子解释 再回头看本文。 如果对 React 基础语法还不熟练,建议先看 React & JSX 日常用法与基本原则 再回头看本文。 useState useS…...

telnet发送邮件教程:安全配置与操作指南?
telnet发送邮件的详细步骤?怎么用telnet命令发邮件? 尽管现代邮件客户端和服务器提供了丰富的功能和安全性保障,但在某些特定场景下,了解如何使用telnet发送邮件仍然是一项有价值的技能。AokSend将详细介绍如何安全配置和操作tel…...

告别OpenAI API费用:手把手教你用本地BGE模型+FAISS搭建LangChain私有知识库
零成本构建企业级知识库:基于BGE与FAISS的私有化LangChain解决方案 在AI应用开发领域,数据隐私和成本控制正成为越来越多开发者的核心考量。当OpenAI等商业API按调用次数收费时,频繁的查询请求可能让个人开发者和小型团队不堪重负。更关键的是…...

别再只用命令行!华为防火墙USG6000V的Web界面到底怎么玩?eNSP实战演示
华为USG6000V防火墙Web界面高效操作指南:从CLI到图形化的思维转换 对于习惯了命令行操作的老牌网络工程师来说,第一次接触华为USG6000V防火墙的Web管理界面时,往往会陷入一种矛盾心理——既惊叹于可视化操作的直观,又担心图形化界…...

**NPU设计新范式:基于RISC-V的可配置计算单元实现与性能优化实践**在人工智能加速领域,
NPU设计新范式:基于RISC-V的可配置计算单元实现与性能优化实践 在人工智能加速领域,NPU(神经网络处理单元) 正从专用硬件向灵活可编程架构演进。本文将深入探讨一种基于 RISC-V指令集扩展 的轻量级NPU设计方案,并通过实…...

深度解析Synology Photos面部识别补丁:从技术原理到实战部署完整指南
深度解析Synology Photos面部识别补丁:从技术原理到实战部署完整指南 【免费下载链接】Synology_Photos_Face_Patch Synology Photos Facial Recognition Patch 项目地址: https://gitcode.com/gh_mirrors/sy/Synology_Photos_Face_Patch Synology Photos Fa…...

ISL29125 RGB环境光传感器驱动与嵌入式应用实战
1. ISL29125 RGB环境光传感器技术解析与嵌入式驱动开发实践ISL29125 是 Intersil(现属 Renesas)推出的一款高精度、低功耗、IC 接口的 RGB 环境光传感器(Ambient Light Sensor, ALS),专为智能手机、平板电脑、可穿戴设…...

如何用ImageGlass替代Windows默认图片查看器:90+格式支持的完整指南
如何用ImageGlass替代Windows默认图片查看器:90格式支持的完整指南 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 在Windows系统中寻找一款能够完美替代默认图…...

利用AI写教材,掌握低查重方法,让你的教材脱颖而出!
许多教材编写者常常会有一种失落感:在花费大量心血完成了主体内容后,配套资源的不足却影响了整体的教学效果。针对课后练习的题型设计,常常缺乏创新的思路;想要制作直观的教学课件,却没有相应的技术能力;对…...

Switch模拟器Ryujinx全攻略:从安装到优化的跨平台游戏体验
Switch模拟器Ryujinx全攻略:从安装到优化的跨平台游戏体验 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Switch模拟器Ryujinx是一款用C#编写的开源项目,它能让…...

达梦DCA认证必看:主从同步原理与ARCH_WAIT_APPLY参数深度实验
达梦DCA认证核心考点解析:主从同步机制与ARCH_WAIT_APPLY实战指南 1. 主从同步架构设计原理 达梦数据库的主从同步机制建立在MAL(Message Automatic Load)通信框架之上,这是实现高可用性的核心技术底座。通过Wireshark抓包分析可以…...
Windows 11 任务栏透明美化神器:TranslucentTB 完全使用指南
Windows 11 任务栏透明美化神器:TranslucentTB 完全使用指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 想要让 Windows …...