V3D——从单一图像生成 3D 物体
导言
论文地址:https://arxiv.org/abs/2403.06738
源码地址:https://github.com/heheyas/V3D.git
人工智能的最新进展使得自动生成 3D 内容的技术成为可能。虽然这一领域取得了重大进展,但目前的方法仍面临一些挑战。有些方法速度较慢,产生的结果也不一致,还有一些方法需要在大型 3D 数据集上进行训练,从而限制了高质量图像数据的使用。
这篇评论文章的重点是利用视频扩散模型生成 3D 内容。视频扩散模型是生成详细、一致的视频场景的典型模型。由于许多视频都会从不同角度捕捉物体,因此这些模型有助于理解三维世界。
本文提出了一种名为 V3D 的新方法,它利用视频扩散模型生成物体或场景的多个视点,并根据这些视点重建三维数据。这种方法既适用于单个物体,也适用于大型场景。
在生成3D物体时,使用 360° 旋转的 3D 物体视频来训练模型,以提高准确性。此外,还引入了新的损失和模型结构,以提高生成视点的一致性和质量。
此外,为了使该方法在实际应用中切实可行,还提出了一种根据生成的数据创建三维网格的方法。该方法还扩展到支持场景级三维生成,实现了精确的摄像机路径控制和多输入视点处理。
广泛的实验,包括定性和定量评估,证明了所提出方法的卓越性能。特别是在生成质量和多视角一致性方面,它明显优于以往的研究。预计所提出的方法将克服当前三维生成技术的局限性,为基于人工智能的三维内容生成开辟新的可能性。
算法架构
概述
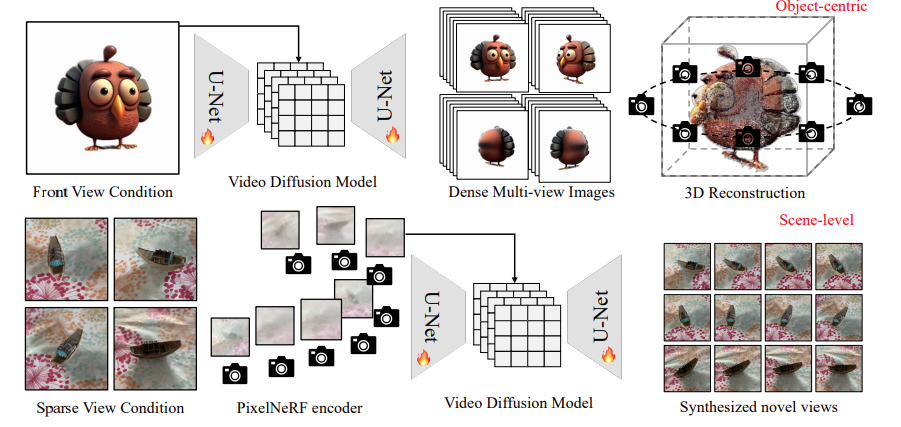
图 1:V3D 概述。
如图 1 所示,V3D 利用视频生成模型,通过利用预先训练的大型视频扩散模型的结构和强大的先验知识,促进一致的多视角生成。
为了从物体图像生成三维图像,利用在固定圆形摄像机位置绘制的合成三维物体的 360° 轨道视频对基础视频扩散模型进行了微调,并提出了适合生成的多视角的重建和网格提取管道。
场景级 3D 生成将 PixelNeRF 编码器纳入基础视频扩散模型,以精确控制生成帧的摄像机位置,使其能够无缝适应任意数量的输入图像。详情如下
根据目标物体的图像生成 360 度视图
为了从单一视角生成多视角图像,V3D 将围绕物体旋转的连续多视角图像解释为视频,并将以正面观看为条件的多视角生成视为一种图像到视频的生成形式。这种方法利用了大规模预训练视频扩散模型提供的对三维世界的全面理解,并解决了缺乏三维数据的问题。它还利用视频扩散模型固有的网络结构,有效生成足够数量的多视角图像。
具体来说,稳定视频扩散(SVD, Blattmann 等人,2023 年)是视频生成的一个代表性模型,在 Objaverse 数据集上进行了微调。为了增强图像到 3D 的适应性,删除了运动桶 ID 和 FPS ID 等无关条件,并使其与高度角无关。取而代之的是,物体被随机旋转,以使生成的模型能够响应非零高度的输入。
稳健的三维重建和网格提取
-三维重建使用微调视频扩散模型获取物体周围的图像后,下一步就是将其重建为三维模型。3D 高斯拼接技术(Kerblet.al, 2023 年)可用于此任务。
确保视图之间每个像素的一致性非常困难,而且会导致三维重建中出现伪影。为了解决这个问题,我们采用了逐像素损失 MSE 的方法。此外,还引入了图像级感知损失和相似性损失,以防止因 MSE 而导致纹理浮动或模糊。最终的损失定义为
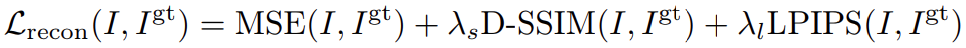
-网格提取为满足实际应用的要求,我们还提出了一个生成视图的网格提取管道。为实现快速曲面重建,采用了使用多分辨率哈希网格的 NeuS(Wang etl.al,2021 年);V3D 使用法线平滑损失和稀疏正则化损失来改进几何形状,从而生成比通常 NeuS 使用情况更少的视图。V3D 使用以下方法改进几何图形。
为改善因生成的图像不一致而导致的纹理模糊,在生成的多视图中使用 LPIPS loss 对纹理进行细化,而几何图形保持不变。通过高效的可微分网格渲染,这一过程可在 15 秒内完成,从而提高最终输出的质量。
扩展到场景级 3D 生成
与对象视图生成不同,场景级 3D 生成需要沿着摄像机的路径生成图像,这就要求精确控制摄像机的方向,并适应多个输入图像。
为了应对这一挑战并保持一致性,V3D将PixelNeRF特征编码器集成到视频扩散模型中,如图 1 底部所示。
这种方法可以无缝支持任意数量的图像。模型的其他设置和结构与以对象为中心的生成类似。
试验
以对象为中心的 3D 生成

图 2:在图像到 3D 任务中与以往研究结果的比较。
本节将评估拟议的 V3D 在图像到 3D 转换中的性能,并描述与其他方法的比较结果。在图 2 的上半部分,V3D 比基于 3DGS 的 TriplaneGaussian 和 LGM 显示出更好的质量。这些方法由于生成的高斯数量有限,会产生模糊的外观。
在图 2 的底部,V3D 在前视图一致性和保真度方面优于基于 SDS 的最新 Magic123 和 ImageDream,Magic123 会产生几何形状不准确和模糊的后视图,而 ImageDream 则会产生过度饱和的纹理。所提出的方法可在不到三分钟的时间内获得结果,速度明显快于基于优化的方法。
同时,还对生成的 3D 物体进行了人体评估研究。具体来说,58 名志愿者被要求在观看根据 30 幅条件图像渲染的 360° 螺旋视频时,对 V3D 和其他方法生成的物体进行评价。两个评价标准是
- (a) 一致性:三维资产与条件图像的匹配程度。
- (b) 保真度:生成物体的逼真程度。
表 1 显示了每种方法在这两个标准上的胜率。
总体而言,V3D 被评为最有说服力的模型,在图像一致性和保真度方面都明显优于其他竞争方法。
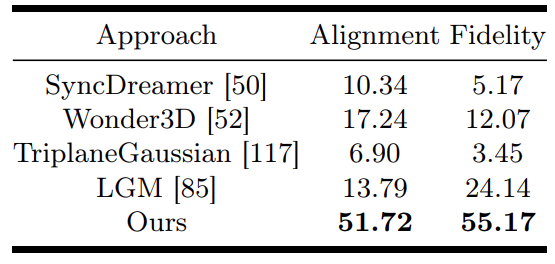
表 1.人类评估结果
场景级 3D 生成
在 CO3D 数据集的 10 个类别子集上测试了提议的 V3D 在场景级 3D 生成中的性能。在每个视频类别中,只对 V3D 的一个历元进行了微调,以便与之前研究中的设置相匹配。
结果见表 2。
所提出的方法在图像指标方面始终优于以往的研究,证明了使用预训练视频扩散模型进行场景级 3D 生成的有效性。零镜头版本的 V3D(完全在 MVImgNet 上训练)也优于之前的大多数研究。
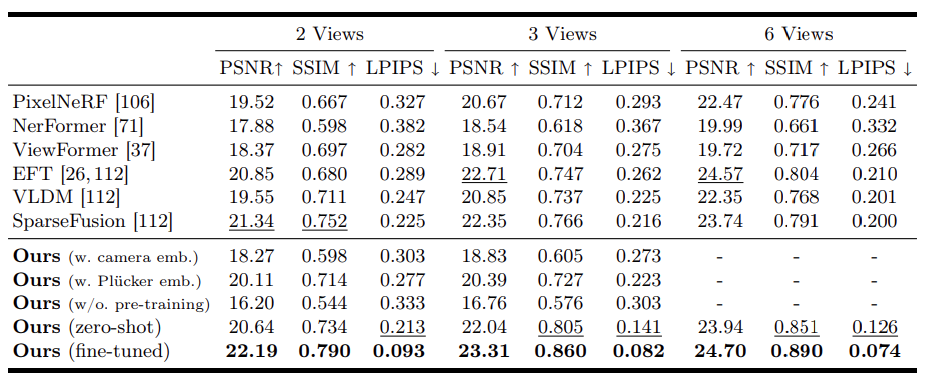
表 2. 与之前 CO3D 研究的比较结果
图 3 显示了 SparseFusion 和 V3D 在 CO3D 数据集的消防栓子集中生成的多视图的定性比较。为了进行更详细的比较,我们在 COLMAP 中使用相机姿态进行了多视角立体重建,图 3 显示了生成的点云中的点数以及与真实图像重建的点云之间的倒角距离。
结果表明,由 V3D 生成的图像重建的点云包含更多的点,而且更接近于由真实图像重建的点云。换句话说,无论是在重建质量还是多视角一致性方面,拟议方法都具有显著优势。

图 3. CO3D 中的定性评估。
总结
本文介绍了 V3D,它能从单张图像生成 3D 物体。
V3D 利用视频生成模型,利用大型预训练视频扩散模型的结构和丰富的先验知识,实现一致的多视角生成。此外,还提出了一种新的重建管道和学习损失,以实现一致且高精度的三维物体重建。
通过广泛的定性、定量和人工评估,证明了所提出方法的卓越性能。特别是在生成质量和多视角一致性方面,它明显优于以往的研究。所提出的方法有望突破当前三维生成技术的限制,为基于人工智能的三维内容生成开辟新的可能性。
相关文章:
V3D——从单一图像生成 3D 物体
导言 论文地址:https://arxiv.org/abs/2403.06738 源码地址:https://github.com/heheyas/V3D.git 人工智能的最新进展使得自动生成 3D 内容的技术成为可能。虽然这一领域取得了重大进展,但目前的方法仍面临一些挑战。有些方法速度较慢&…...

计算机网络期末复习真题(附真题答案)
前言: 本文是笔者在大三学习计网时整理的笔记,哈理工的期末试题范围基本就在此范畴内,就算真题有所更改,也仅为很基础的更改数值,大多跑不出这些题,本文包含简答和计算等大题,简答的内容也可能…...

Unity 的 UI Event System 是一个重要的框架
Unity 的 UI Event System 是一个重要的框架,用于处理用户界面中的输入事件。以下是它的主要特点和功能: 1. 事件管理 UI Event System 负责捕获和管理来自用户的输入事件,如鼠标点击、触摸、键盘输入等。 2. 事件传播 事件通过层次结…...

第十三章 集合
一、集合的概念 集合:将若干用途、性质相同或相近的“数据”组合而成的一个整体 Java集合中只能保存引用类型的数据,不能保存基本类型数据 数组的缺点:长度不可变 Java中常用集合: 1.Set(集):集合中的对象不按特定方式排序&a…...

子非线程池中物
线程池,又好上了 有任务队列 任务要处理就直接放到里面 预先创建好线程,本质上也是一个生产消费模型 线程池真是麻烦啊 我们可以直接沿用之前写过的代码,Thread.hpp: #pragma once #include <iostream> #include <functional&…...

Unraid的cache使用btrfs或zfs?
Unraid的cache使用btrfs或zfs? 背景:由于在unraid中添加了多个docker和虚拟机,因此会一直访问硬盘。然而,单个硬盘实在难以让人放心。在阵列盘中,可以通过添加校验盘进行数据保护,在cache中无法使用xfs格式…...

微服务实战——平台属性
平台属性 中间表复杂业务 /*** 获取分类规格参数(模糊查询)** param params* param catelogId* param type type"base"时查询基础属性,type"sale"时查询销售属性* return*/ Override public PageUtils listByCatelogId…...

半监督学习与数据增强(论文复现)
半监督学习与数据增强(论文复现) 本文所涉及所有资源均在传知代码平台可获取 文章目录 半监督学习与数据增强(论文复现)概述算法原理核心逻辑效果演示使用方式 概述 本文复现论文提出的半监督学习方法,半监督学习&…...

css3-----2D转换、动画
2D 转换(transform) 转换(transform)是CSS3中具有颠覆性的特征之一,可以实现元素的位移、旋转、缩放等效果 移动:translate旋转:rotate缩放:scale 二维坐标系 2D 转换之移动 trans…...

SQL进阶技巧:统计各时段观看直播的人数
目录 0 需求描述 1 数据准备 2 问题分析 3 小结 如果觉得本文对你有帮助,那么不妨也可以选择去看看我的博客专栏 ,部分内容如下: 数字化建设通关指南 专栏 原价99,现在活动价39.9,十一国庆后将上升至59.9&#…...

Stream流的终结方法
1.Stream流的终结方法 2.forEach 对于forEach方法,用来遍历stream流中的所有数据 package com.njau.d10_my_stream;import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.function.Consumer; import java.util…...

JavaWeb——Vue组件库Element(4/6):案例:基本页面布局(基本框架、页面布局、CSS样式、完善布局、效果展示,含完整代码)
目录 步骤 基本页面布局 基本框架 页面布局 CSS样式 完善布局 效果展示 完整代码 Element 的基本使用方式以及常见的组件已经了解完了,接下来要完成一个案例,通过这个案例让大家知道如何基于 Element 中的各个组件制作一个完整的页面。 案例&am…...

【c++】 模板初阶
泛型编程 写一个交换函数,在学习模板之前,为了匹配不同的参数类型,我们可以利用函数重载来实现。 void Swap(int& a, int& b) {int c a;a b;b c; } void Swap(char& a, char& b) {char c a;a b;b c; } void Swap(dou…...

R 语言 data.table 大规模数据处理利器
前言 最近从一个 python 下的 anndata 中提取一个特殊处理过的单细胞矩阵,想读入R用来画图(个人比较喜欢用R可视化 ),保存之后,大概几个G的CSV文件,如果常规方法读入R,花费的时间比较久&#x…...

Java 静态代理详解:为什么代理类和被代理类要实现同一个接口?
在 Java 开发中,代理模式是一种常用的设计模式,其中代理类的作用是控制对其他对象的访问。代理模式分为静态代理和动态代理,在静态代理中,代理类和被代理类都需要实现同一个接口。这一机制为实现透明的代理行为提供了基础…...
OpenCV C++霍夫圆查找
OpenCV 中的霍夫圆检测基于 霍夫变换 (Hough Transform),它是一种从边缘图像中识别几何形状的算法。霍夫圆检测是专门用于检测图像中的圆形形状的。它通过将图像中的每个像素映射到可能的圆参数空间,来确定哪些像素符合圆形状。 1. 霍夫变换的原理 霍夫…...

H.264编解码介绍
一、简介 H.264,又称为AVC(Advanced Video Coding),是一种广泛使用的视频压缩标准。它由国际电信联盟(ITU)和国际标准化组织(ISO)联合开发,并于2003年发布。 H.264的发展历史可以追溯到上个世纪90年代。当时,视频压缩技术的主要标准是MPEG-2,但它在压缩率和视频质…...

Java | Leetcode Java题解之第450题删除二叉搜索树中的节点
题目: 题解: class Solution {public TreeNode deleteNode(TreeNode root, int key) {TreeNode cur root, curParent null;while (cur ! null && cur.val ! key) {curParent cur;if (cur.val > key) {cur cur.left;} else {cur cur.rig…...

【CViT】Deepfake Video Detection Using Convolutional Vision Transformer
文章目录 Deepfake Video Detection Using Convolutional Vision Transformerkey points**卷积视觉变压器**FLViT实验总结Deepfake Video Detection Using Convolutional Vision Transformer 会议/期刊:2021 作者: key points 提出了一种用于检测深度伪造的卷积视觉变压器…...

安卓主板_MTK4G/5G音视频记录仪整机及方案定制
音视频记录仪方案,采用联发科MT6877平台八核2* A78 6* A55主频高达2.4GHz, 具有高能低耗特性,搭载Android 12.0智能操作系统,可选4GB32GB/6GB128GB内存,运行流畅。主板集成NFC、双摄像头、防抖以及多种无线数据连接,支…...

QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换
QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&am…...

Pandas数据合并:concat vs append,选哪个?用真实‘幸福指数’数据集测给你看
Pandas数据合并实战:concat与append深度性能对比 在数据分析工作中,数据合并是最基础也最频繁的操作之一。Pandas提供了多种合并数据的方法,其中concat和append是最常用的两种纵向合并方式。但很多开发者并不清楚它们在实际项目中的性能差异和…...

Go Web框架ratine:轻量高性能设计、核心功能与生产实践指南
1. 项目概述:一个轻量级、高性能的Web框架 最近在折腾一个内部工具的后端,需要快速搭建一个API服务,性能要求不低,但又不希望引入Spring Boot那种“全家桶”式的重量级框架。在社区里翻找时, goweft/ratine 这个项目…...

如何用Mermaid Live Editor构建企业级实时图表系统:架构师的技术选型指南
如何用Mermaid Live Editor构建企业级实时图表系统:架构师的技术选型指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/m…...

高效Kolmogorov-Arnold网络:PyTorch实现终极指南 [特殊字符]
高效Kolmogorov-Arnold网络:PyTorch实现终极指南 🚀 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan Kolmogor…...

《Java 100 天进阶之路》第1篇:编程语言类型有哪些?我心中的TOP1编程语言,什么是Java跨平台性?
第1篇:编程语言类型有哪些?我心中的TOP1编程语言,什么是Java跨平台性? 一、核心知识点 编程语言的三大类型:机器语言、汇编语言、高级语言Java为什么是“一次编写,到处运行”(跨平台原理&…...

TrollInstallerX终极指南:3分钟搞定iOS 14-16.6.1 TrollStore安装
TrollInstallerX终极指南:3分钟搞定iOS 14-16.6.1 TrollStore安装 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是当前iOS 14.0至16.6.1设…...

Blender 3MF插件:5分钟掌握3D打印文件格式转换的完整方案
Blender 3MF插件:5分钟掌握3D打印文件格式转换的完整方案 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 你是否曾经在Blender中精心设计了完美的3D模型&…...

企业/学校如何自建在线“慕课“教学平台?Moodle 开源 LMS 初识与部署全攻略
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 0x00 前言简述 背景说明 出于内部学习平台搭建需要,领导吩咐我去探究部署一些开源学习平台,要求支持Office协同文档、学习课程发布、学习记录反馈和支持 OAuth2 客户端以对…...

轻量级视频稳定技术:EfficientMotionPro与OnlineSmoother解析
1. 轻量级视频稳定技术概述视频稳定技术是现代计算机视觉领域的重要研究方向,其核心目标是消除因相机抖动导致的画面不稳定现象。传统视频稳定方法通常依赖于复杂的光流计算或3D场景重建,这些方法虽然效果稳定,但计算开销巨大,难以…...