使用微服务Spring Cloud集成Kafka实现异步通信(消费者)
1、本文架构
本文目标是使用微服务Spring Cloud集成Kafka实现异步通信。其中Kafka Server部署在Ubuntu虚拟机上,微服务部署在Windows 11系统上,Kafka Producer微服务和Kafka Consumer微服务分别注册到Eureka注册中心。Kafka Producer和Kafka Consumer之间通过Kafka Server实现异步通信。
出于便于测试的目的,我通过浏览器触发Kafka Producer发送消息,观察Kafka Consumer的后台是否打印出接收到的消息内容。
Ubuntu 上部署Kafka Server,详见博文:Ubuntu下Kafka安装及使用-CSDN博客
Eureka注册中心的搭建过程和完整代码,详见博文:微服务1:搭建微服务注册中心(命令行简易版,不使用IDE)-CSDN博客
Kafka Producer微服务的完整代码,详见博文:使用微服务Spring Cloud集成Kafka实现异步通信-CSDN博客
本文的重点是实现下图中的深蓝色部分:Kafka Consumer微服务。

2、创建Spring boot项目(Kafka Consumer微服务项目):
mvn archetype:generate -DgroupId=com.test -DartifactId=microservice-kafka-consumer -DarchetypeArtifactId=maven-archetype-quickstart
项目代码的完整目录如下图所示:

编辑pom.xml,添加依赖包:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.test</groupId><artifactId>microservice-kafka-consumer</artifactId><packaging>jar</packaging><version>1.0-SNAPSHOT</version><name>microservice-kafka-consumer</name><url>http://maven.apache.org</url><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.0.RELEASE</version><relativePath/> </parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId></dependency> <dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>3.8.1</version><scope>test</scope></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-stream-binder-kafka</artifactId></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>Hoxton.SR4</version><type>pom</type><scope>import</scope></dependency> </dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
编辑application.yml,配置kafka消费者:
consumer:
#消费的主题
topic: test-topic
#消费者组id
group-id: test-group
#是否自动提交偏移量
enable-auto-commit: true
#提交偏移量的间隔-毫秒
auto-commit-ms: 1000
#客户端消费的会话超时时间-毫秒
session-timeout-ms: 10000
#实现DeSerializer接口的反序列化类键
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
#实现DeSerializer接口的反序列化类值
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
server:port: 8030
spring:application:name: microservice-kafka-consumerkafka:bootstrap-servers: 192.168.23.131:9092consumer:group-id: test-groupenable-auto-commit: trueauto-commit-ms: 1000session-timeout-ms: 10000key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializereureka:client:serviceUrl:defaultZone: http://localhost:8080/eureka/instance:prefer-ip-address: true
App.java的完整代码如下:
package com.test;import org.springframework.boot.ApplicationRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.kafka.annotation.KafkaListener;@SpringBootApplication
@EnableDiscoveryClient
public class App
{@KafkaListener(topics = "mydemo1")public void listen(String msg) throws Exception {System.out.println( "-----> Recv a msg: " + msg );}public static void main( String[] args ){System.out.println( "Hello World!" );SpringApplication.run(App.class, args);}
}
3、测试
在浏览器输入,触发Kafka Producer向Kafka Server发送消息:
http://localhost:8020/kafka/sendMsg?msg=测试消息testmsg在Kafka Consumer的后台打印出收到的消息:

相关文章:
使用微服务Spring Cloud集成Kafka实现异步通信(消费者)
1、本文架构 本文目标是使用微服务Spring Cloud集成Kafka实现异步通信。其中Kafka Server部署在Ubuntu虚拟机上,微服务部署在Windows 11系统上,Kafka Producer微服务和Kafka Consumer微服务分别注册到Eureka注册中心。Kafka Producer和Kafka Consumer之…...

docker pull 超时Timeout失败的解决办法
当国内开发者docker pull遇到如下提示时,不要惊讶 [rootvm /]# docker pull postgres Using default tag: latest Error response from daemon: Get "https://registry-1.docker.io/v2/": dial tcp 128.121.146.235:443: i/o timeout [rootvm /]# 自2024…...

YOLOv7改进之主干DAMOYOLO结构,结合 CReToNeXt 结构,打造高性能检测器
一、DAMOYOLO理论部分 论文地址:2211.15444 (arxiv.org) 在本报告中,我们提出了一种快速准确的对象检测方法,称为 DAMO-YOLO,它实现了比最先进的 YOLO 系列更高的性能。DAMO-YOLO 是从 YOLO 扩展而来的,具有一些新技术,包括神经架构搜索 (NAS)、高效的重新参数化广义 …...

进度条(倒计时)Linux
\r回车(回到当前行开头) \n换行 行缓冲区概念 什么现象? 什么现象?? 什么现象??? 自己总结: #pragma once 防止头文件被重复包含 倒计时 在main.c中,windows.h是不可以用的&…...

[每周一更]-(第117期):硬盘分区表类型:MBR和GPT区别
文章目录 1. **支持的磁盘容量**2. **分区数量**3. **引导方式**4. **冗余和数据恢复**5. **兼容性**6. **安全性**7. **操作系统支持**8. 对比 国庆假期前补一篇 在一次扫描机械硬盘故障的问题,发现我本机SSD和机械硬盘的分类型不一样,分别是GPT和MBR&a…...
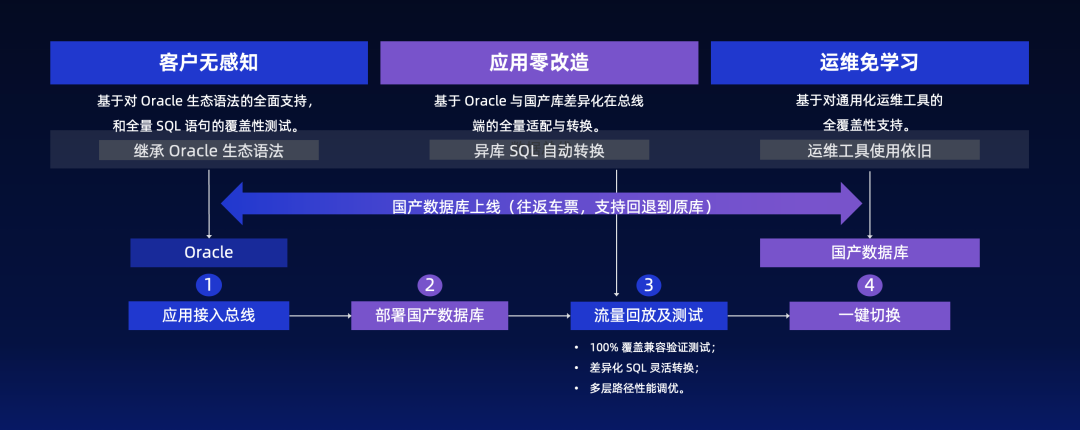
河南移动:核心营业系统稳定运行超300天,数据库分布式升级实践|OceanBase案例
河南移动,作为电信全业务运营企业,不仅拥有庞大的客户群体和业务规模,还引领着业务产品与服务体系的创新发展。河南移动的原有核心营业系统承载着超过6000万的庞大用户量,管理着超过80TB的海量数据,因此也面临着数据规…...

22.1 k8s不同role级别的服务发现
本节重点介绍 : 服务发现的应用3种采集的k8s服务发现role 容器基础资源指标 role :nodek8s服务组件指标 role :endpoint部署在pod中业务埋点指标 role :pod 服务发现的应用 所有组件将自身指标暴露在各自的服务端口上,prometheus通过pull过来拉取指标但是promet…...

OpenCV计算机视觉库
计算机视觉和图像处理 Tensorflow入门深度神经网络图像分类目标检测图像分割OpenCVPytorchNLP自然语言处理 OpenCV 一、OpenCV简介1.1 简介1.2 OpenCV部署1.3 OpenCV模块 二、OpenCV基本操作2.1 图像的基本操作2.1.1 图像的IO操作2.1.2 绘制几何图像2.1.3 获取并修改图像的像素…...

CentOS 系统中的文件挂载 U 盘
要将 CentOS 系统中的文件保存到 U 盘,可以按照以下步骤进行操作: 一、插入 U 盘并确定设备名称 将 U 盘插入 CentOS 系统的 USB 接口。使用 fdisk -l 命令查看系统中的磁盘和分区情况,确定 U 盘的设备名称。通常 U 盘会显示为类似于 /dev/…...
)
Lumerical脚本语言-变量操作(Manipulating variables)
下面的命令用来创建和存取变量。 命令描述= 赋值操作符 :数组操作符 []创建矩阵 % 创建包含空格的变量名称 linspace 创建线性空间数组 matrix 创建一个全为 0 的矩阵 randmatrix 创建一个所有元素为 0~1 之间的一个随机数的矩阵 randnmatrix 创建一个所有元素为平均值为 0…...

一个基本的包括爬虫、数据存储和前端展示框架0
创建一个完整的网络爬虫和前端展示页面是一个涉及多个步骤和技术的任务。下面我将为你提供一个基本的框架,包括爬虫代码(使用Python和Scrapy框架)和前端HTML页面(伏羲.html)。 爬虫代码 (使用Scrapy) 首先,你需要安装Scrapy库:bash pip install scrapy 然后,创建一个新…...

简历制作面试篇
一.面试技巧分析 模板: 推荐使用简洁一点的模板,不要太花哨,能够让HR和面试官清楚,快速知道信息就可以,太花哨容易分散别人的注意力。 格式: 一般选用PDF,不要用WORD。 照片: 技术岗一般不用贴照片,推进写上自己的联系方式或者微信。 专业技能: 描述专业技能…...
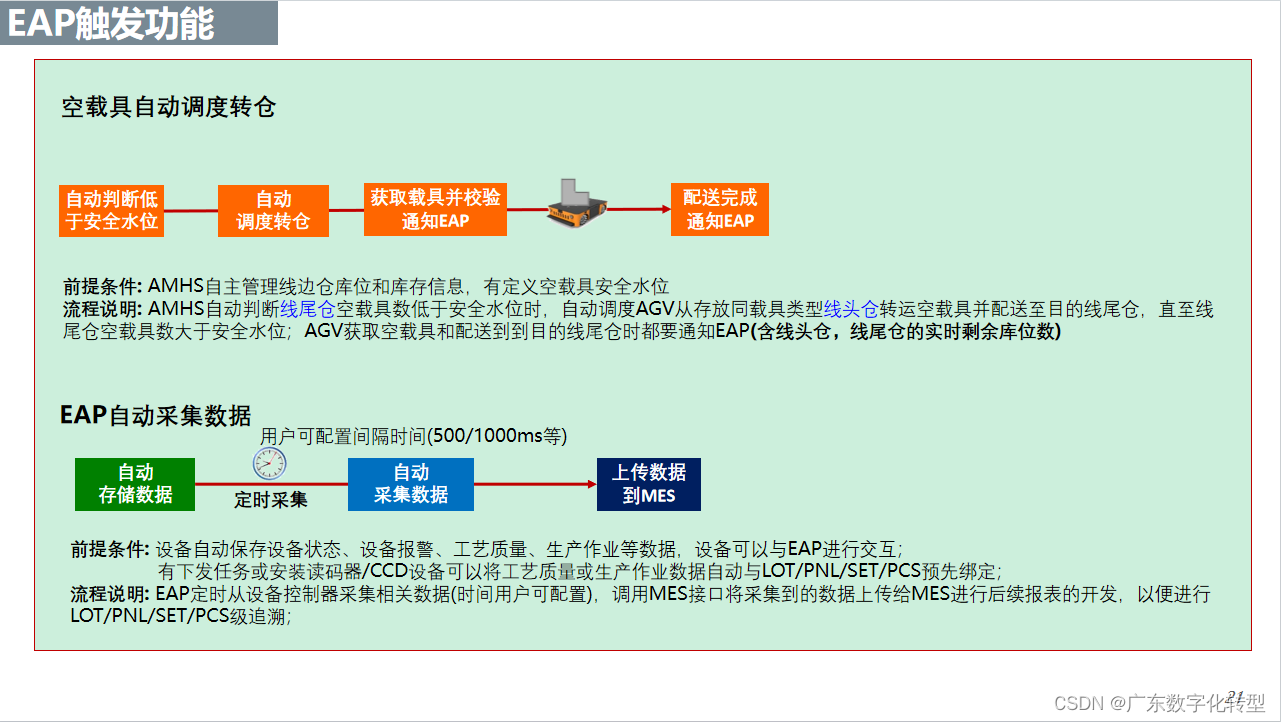
智能制造--EAP设备自动化程序
EAP是设备自动化程序(Equipment Automation Program)的缩写,他是一种用于控制制造设备进行自动化生产的系统。EAP系统与MES系统整合,校验产品信息,自动做账,同时收集产品生产过程中的制程数据和设备参数数据…...
LabVIEW混合控制器质量检测
随着工业自动化水平的提高,对控制器的精度、稳定性、可靠性要求也在不断上升。特别是在工程机械、自动化生产、风力发电等领域,传统的质量检测方法已无法满足现代工业的高要求。因此,开发一套自动化、精确、可扩展的混合控制器质量检测平台成…...

新技术浪潮下的等保测评:云计算、物联网与大数据的挑战与机遇
随着信息技术的飞速发展,云计算、物联网(IoT)和大数据等新兴技术正以前所未有的速度改变着我们的生活和工作方式。这些技术的广泛应用不仅为信息系统带来了前所未有的性能提升,同时也对等保测评(信息安全等级保护测评&…...

微信小程序技术框架选型
“近期在对团队的微信小程序进行技术框架选型,故对目前主流的微信小程序技术框架进行了一些分析和比较,包括各框架的维护团队、社区链接、GitHub star数、优缺点对比等方面,为团队提供技术框架选型参考” 一、引言 随着移动互联网的快速发展…...

SQL学习3
24.10.3学习目录 一.c语言操作数据库 一.c语言操作数据库 (1)打开、关闭数据库函数 //打开数据库 int sqlite3_open(char *db_name,sqlite3 **db);db_name:数据库文件名,若文件名中有ASCLL码中以外的字符,其必须为UT…...

Linux:进程控制(一)
目录 一、写时拷贝 1.创建子进程 2.写时拷贝 二、进程终止 1.函数返回值 2.错误码 3.异常退出 4.exit 5._exit 一、写时拷贝 父子进程,代码共享,不作写入操作时,数据也是共享的,当任意一方试图写入,便通过写时拷…...

初识算法 · 双指针(3)
目录 前言: 和为s的两数之和 题目解析: 编辑 算法原理: 算法编写: 三数之和 题目解析 算法原理 算法编写 前言: 本文通过介绍和为S的两数之和,以及三数之和,对双指针算法进行深一步…...
)
【AI知识点】近似最近邻搜索(ANN, Approximate Nearest Neighbor Search)
近似最近邻搜索(ANN, Approximate Nearest Neighbor Search) 是一种用于高维数据检索的技术,目标是在给定查询的情况下,快速找到距离查询点最近的数据点,尽管结果可能并不完全精确。这种方法特别适用于高维数据&#x…...

深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战
深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在电…...
)
嵌入式调试进阶:JScope RTT模式移植与性能实测(对比HSS,速度提升千倍)
嵌入式调试革命:JScope RTT模式深度优化与高频数据采集实战 在电机控制、电源管理和高速信号处理等嵌入式应用场景中,开发人员经常需要实时监控关键变量的变化趋势。传统调试工具往往面临采样率低、数据延迟大等问题,而SEGGER JScope的RTT模式…...

AntiDupl.NET:告别数字杂乱,让图片管理回归优雅
AntiDupl.NET:告别数字杂乱,让图片管理回归优雅 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾经在整理照片时,发现手机里…...

工程思维跨界精酿:从电路板到啤酒桶的系统化创新实践
1. 项目概述:从电路板到啤酒桶的跨界创业在圣保罗的某个欢乐时光里,几位刚结束一天工作的电气工程师,一边喝着工业拉格,一边抱怨着市面上千篇一律的啤酒风味。他们聊着示波器、PCB布线和信号完整性,也聊着麦芽的甜度、…...

Adobe-GenP 3.0:三步解锁Adobe全家桶的终极指南
Adobe-GenP 3.0:三步解锁Adobe全家桶的终极指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 还在为昂贵的Adobe Creative Cloud订阅费而烦恼吗&#…...

2025年英雄联盟国服内存级换肤技术深度解析:R3nzSkin架构设计与实现
2025年英雄联盟国服内存级换肤技术深度解析:R3nzSkin架构设计与实现 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 你是否曾想过ÿ…...

Android数据存储终极指南:SharedPreferences与ContentProviders完全解析
Android数据存储终极指南:SharedPreferences与ContentProviders完全解析 【免费下载链接】android-best-practices Dos and Donts for Android development, by Futurice developers 项目地址: https://gitcode.com/gh_mirrors/an/android-best-practices 在…...
)
告别虚拟机!Windows 11下用Conda一键安装GNU Radio 3.10(附国内镜像加速)
Windows 11下用Conda极速部署GNU Radio 3.10全攻略 在软件无线电(SDR)领域,GNU Radio一直是开源工具链中的标杆。但许多Windows用户在初次接触时,往往被复杂的依赖关系和繁琐的安装过程劝退。虚拟机卡顿、版本兼容性问题、依赖冲突…...

硬件对齐的稀疏注意力机制:原理、优化与实践
1. 硬件对齐的稀疏注意力机制概述在自然语言处理领域,Transformer架构已成为主流,但其核心组件——注意力机制的计算复杂度随序列长度呈平方级增长,这成为处理长文本的主要瓶颈。传统全注意力(Full Attention)需要计算每个查询(Query)与所有键…...

【灶台导航】 RAG系统的容错设计:从向量搜索到关键词降级,一个都不能少
当三个外部依赖都可能随时挂掉时,如何保证用户永远有响应?问题:完美主义害死人 做RAG系统时,我们很容易陷入一种思维定势:向量检索要准、LLM要强、整个链路要丝滑。但现实是——任何一个外部服务挂了,用户就…...