A Learning-Based Approach to Static Program Slicing —— 论文笔记
A Learning-Based Approach to Static Program Slicing
OOPLSA’2024
文章目录
- A Learning-Based Approach to Static Program Slicing
- 1. Abstract
- 2. Motivation
- (1) 为什么需要能处理不完整代码
- (2) 现有方法局限性
- (3) 验证局限性: 初步实验研究
- 实验设计
- 何为不完整代码
- 实验结果
- (4) 为什么这个工作可以处理不完整代码
- 3. Method
- 训练集构造
- 训练:
- 4. Empirical Evaluation
- RQ1: NS-Slicer在完整代码上的有效性
- 1. 训练集构造:
- 数据集: IBM CodeNet(Puri et.al 2021) 4053
- 2. 训练:
- 3. 指标
- 4. 结果
- RQ2: 在不完整代码上的有效性
- 1. 数据集构造
- 2. 结果
- RQ3: 消融实验
- RQ4: 探究PLM对变量别名对理解
- 1. 实验方法
- RQ5: 在漏洞检测任务上的性能
- 数据集构造
- 数据集: CrossVul跨语言漏洞数据集
- 5. Limitations
1. Abstract
-
背景: 程序切片: 传统程序切片技术在漏洞检测中很关键, 但是处理不完整代码表现不佳
-
方法: 提出NS- Slicer, 一种基于学习的新颖方法能够预测完整代码和不完整代码的静态程序切片.
使用预训练的大模型(PLM), 利用模型对源代码中细粒度依赖(Token级别的依赖?)的理解对每个token生成富含上下文信息的向量, 利用这些向量, NS-Slicer会分别确定语句是属于向后切片还是向前切片 -
结果:
- 在完整代码上, 后向切片和前向切片分别达到97.41%和95.82%的F1分数,
并且在85.2%的例子中, NS-Slicer精确预测了整个切片 - 在部分代码上, 达到了94.66%-96.62%(实验摘掉了不同数量的代码)的F1分数
- 在漏洞检测的任务上, 检测Java代码达到了73.38%的F1分数
- 实验证明能同时处理完整/不完整代码, 对任何切片起点进行切片, 对能容忍少部分不精确结果的任务比较有效, 能获得规模, 时间和对不完整代码的处理能力为权衡
- 在完整代码上, 后向切片和前向切片分别达到97.41%和95.82%的F1分数,
2. Motivation
(1) 为什么需要能处理不完整代码
比如这样一个第13行有漏洞的, 来自StackOverflow #16180130回答的不完整代码, 被用在了Hadoop中产生了一个CVE, 类型CWE-395 Null Pointer Exception

顺便解释一下工作中所说的“不完整”指的是什么, 看这个代码片段, 没有被函数包裹, 中间的一些变量也没有声明, 整个代码片段都是没有上下文的
所以尽早检测类似stackoverflow这样的不完整代码漏洞是有必要的.
但是, 整个stackoverflow回答就这15行, 没有变量定义也没有外部库的信息, 没有任何上下文
(2) 现有方法局限性
而现有的方法需代码是带有完整依赖的, 至少是在函数层面上是完整的
-
比如基于程序分析的: SDG的javaslicer和基于CPG的joern都不行
-
基于深度学习的PDG生成方法NeuralPDA, 提供的依赖是语句级别的, 粒度不够细, 不能提供生成切片必要的变量和语句之间的依赖(因为切片起点是个变量)
所以这些方法在stackoverflow上检测代码小片段的能力有限,
(3) 验证局限性: 初步实验研究
做了一个小实验来说明现有基于程序分析的sota(joern)解决不了不完整代码
实验设计
从stackoverflow上找99个不完整的代码小片段(没有说是随机挑的), 输入给joern, 人工检查joern生成的CFG/PDG看是否正确
何为不完整代码
有几种类型
- 有未知类型的数据
- 缺少头文件的外部API/方法/类/类型
- 引用的变量无变量定义
- 缺少类的层次结构
举例:

实验就是直接输入这么一小段, 没有inclue包含std::string, std::transform的头文件, 所以这里都是未知的数据类型和API
另一个例子
工作中还用了没有函数签名的stackoverflow的代码小片段
比如, 这是一个来自stackoverflow上, 没有函数签名的代码片段, 实验会给其加上没有参数的的函数签名, 再输入给joern, 排除由于没有函数签名导致joern无法输入

本文里没有给具体例子, 我觉得应该是这个意思, 图也是在这个作者另一篇针对不完整代码的文章里找的
void DUMMY_METHOD_SIGNATURES(){std::shared_ptr<FILE> pipe(popen(cmd, "r"), pclose);if (!pipe) return "ERROR";char buffer[128];std::string result = "";while (!feof(pipe.get())) {if (fgets(buffer, 128, pipe.get()) != NULL)result += buffer;}
}
实验结果
-
47/99个例子: 缺少或预测不正确的数据/控制依赖
-
30/99个例子: joern报错, 比如“Could not find type member, type = XYZ, member = abc”
-
7/99: joern生成了一个空CFG/PDG
Joern生成不好CFG/PDG的主要原因是
- 未知数据类型的变量的依赖会全部被Joern忽略
- 各种原因导致的(比如缺少头文件导致的)对unresolved的外部API/方法/类/类型的引用和对象构造会报错, 或者直接跳过
- 缺少变量的声明, 变量类型/类的声明
- 缺少类的层级(继承)结构
- 不能处理template和typedef
(4) 为什么这个工作可以处理不完整代码
所以要利用预训练大模型(PLM)的优势
为什么可以处理不完整代码, 是PLM输入的序列性: 一个Token只要被输入都会被考虑上下文和数据流关系, 而不会像传统工具一样限制变量一定要声明过才会追溯数据流信息
并且PLM能捕捉到代码的语义信息, 适合切片任务, 这源于预训练任务的性质
- 掩码语言建模(Masked Lang Modeling: Feng et.al 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In EMNLP),
- 边预测(Edge Prediction: Guo et.al 2021. GraphCode{BERT}: Pre-training Code Representations with Data Flow. In International Conference on Learning Representations.)和节点对齐(Node Align), 这两个预训练在GraphCodeBERT中也叫学习数据流知识
- 一些工作已经证明有助于PLM学习代码中的语法结构和数据流信息, 他说PLM在语句捕捉依赖性级别有好表现
由于GraphCodeBERT的预训练目标有编码变量来自何处, 因此适合处理部分代码, 在其上做静态切片
3. Method
后面有五个实验方法有小差异, 这里简单概述共通的

训练集构造
用传统的基于程序分析的切片方法切出来的切片作为ground truth
<源程序, 切片起点, 前/后向切片集合(现有的切片方法)>
训练:
给定一个源程序
-
tokenize: 把源程序语句切成文本形式的token序列
-
Variable-statement Dependency Learning(用PLM模拟PDG的生成):
- 嵌入: 把文本形式的token序列送入预训练的大模型(CodeBERT/GraphCodeBERT), 大模型捕捉token序列间的依赖关系, 对每一个token生成含有上下文信息的向量表示
- 池化: 将属于同一语句的token向量表示应用平均值池化, 计算每一条语句的向量表示, 特别的, 将切片起点的变量单独池化
-
切片: (用学习方法模拟对PDG的遍历)
对每一条语句, 将这条语句的向量表示 和切片起点变量的向量表示输入到预测前/后向切片的二分类MLP里(这条语句在切片起点前就输入到前向切片分类器, 在后面同理), 预测这条语句是否是切片起点的前/后向切片
最后计算预测的前/后向切片集合与数据集的ground truth的前/后向切片交叉熵损失之和 训练
为什么要训练两个因为前后向不一样
4. Empirical Evaluation
RQ1: NS-Slicer在完整代码上的有效性
1. 训练集构造:
CodeNet, 有大约75,000个Java代码样本
使用JavaSlicer(Galindo et.al 2022)对每个样本中的每一个变量作为起点切片, 剔除掉空的切片
因为定义为二分类问题, 还做了一个样本均衡的筛选, 就是挑选切出来的语句数量是原代码的0.3-0.7的样本
最后保留了43,000个Java样本, 每个样本5-69个切片
8:1:1划分
数据集: IBM CodeNet(Puri et.al 2021) 4053
https://developer.ibm.com/exchanges/data/all/project-codenet/
简介: CodeNet提供了一个oj, 有4,053个问题,代码都是使用者提交并通过IBM审核后加入数据库的, 14,000,000个代码样本, 五十多种语言, 样本不光包括代码, 还包括runtime和报错
2. 训练:
首先,选择现成的 GraphCodeBERT 预训练版本。在 NS-Slicer 的训练阶段,分PLM 中的参数是固定的和微调两种,PLM 中的标记/语句表示原封不动地用于训练前后向切分 MLP 头. 对CodeBERT 模型[Feng 等人,2020],做同样的事情。
两个PLM总共128M个参数, 每个epoch 32min
3. 指标
在语句级别计数TP, FP啥的
-
Accuracy(A-S), Precision, Recall, F1
-
A-EM(Accuracy-ExactlyMatched): 预测出的切片和GroundTruth一摸一样的比例
-
A-D(Accuracy-D):
Finally, we report Dependence Accuracy (i.e., Accuracy-D) to assess how accurately the interstatement dependencies are predicted, causing a particular statement to be included in the slice.
Accordingly, we define Accuracy-D for a particular program as the ratio of the correctly predicted dependencies to the actual dependencies across all slicing criteria for that program, finally reporting the mean across all programs in the dataset.
文章里没说具体怎么衡量是否找对了Dependency, 代码找了个遍也没找到
4. 结果
Table1:

可能由于工作缺乏切片的数据集, groundtruth是JavaSlicer, 这个结果只能表示有多接近JavaSlicer的性能, 可以看到最好的情况下, 有百分之85.20的例子生成的切片是和JavaSlicer一摸一样的, F1是96.77%
可以看出用GraphCodeBERT比CodeBERT效果好, 作者说是因为GraphCodeBERT考虑到了代码的数据流信息
还探究了模型对切片在整个程序中占比的敏感程度

RQ2: 在不完整代码上的有效性
1. 数据集构造
和RQ1相同的数据集, 先用完整代码生成切片
同时摘掉前后百分之P的来模拟部分代码, 和切片有关的语句
PLM方面只使用GraphCodeBERT, 其余和RQ1一样
2. 结果

RQ3: 消融实验
B1: 探究在源代码上预训练对结果的影响: 使用在自然语言——英语上预训练的模型RoBERTa-base作为PLM
B2: 探究数据流预训练(GraphCodeBERT进行了边预测和节点对齐的额外预训练, 即数据流预训练)对结果的影响: 使用CodeBERT作为PLM
B3: 把平均值池化换成最大值池化
结果:

对比B1, B2可以看出在源代码上预训练比在数据流上预训练更重要, 对部分代码影响更大(是文章中直接说的, 没有表)
RQ4: 探究PLM对变量别名对理解
variabe aliasing指的是, 多个引用用来表示同一个对象并且只想同一块内存
1. 实验方法
在切片起点变量所在的那条语句后面插入一条赋值语句来给切片起点变量起一个别名, 后续所有语句中的切片起点变量全部都改成别名
平均只有42.86的语句含有变量别名

然后作者对, 不同变量别名占切片比例的样本进行分层观察, 发现这个比例和NS-Slicer的预测能力没有直接关联
推测这可能是由于在源代码上预训练的PLM在内存级别缺乏对源代码的理解,因为当前的预训练任务主要只关注源代码的词法方面。因此,对特定源代码的预训练还能进一步提高 PLM 的程序切片性能。
RQ5: 在漏洞检测任务上的性能
数据集构造
从563个Java的commit中只有574个有漏洞函数的文件, 为了保证样本平衡从13, 565个无漏洞的文件中抽了574个, 用NS-Slicer生成了1476个代码小工具, 由于数据有限, 先在BigVul上Joern+VulDeePecker训练, 然后把Joern换掉, 数据集也换成CrossVul继续训练
数据集: CrossVul跨语言漏洞数据集
结果:

5. Limitations
模型的输入限制在了512个tokens, 然而LongCoder(Guo et.al 2023, 最多4096个token的限制)可以很容易的嵌入NS-Slicer
相关文章:
A Learning-Based Approach to Static Program Slicing —— 论文笔记
A Learning-Based Approach to Static Program Slicing OOPLSA’2024 文章目录 A Learning-Based Approach to Static Program Slicing1. Abstract2. Motivation(1) 为什么需要能处理不完整代码(2) 现有方法局限性(3) 验证局限性: 初步实验研究实验设计何为不完整代码实验结果…...

掌握 C# 中的委托与事件机制
C# 中的委托和事件为开发者提供了处理回调、异步编程以及发布订阅模式的强大工具。委托与事件机制在实际应用中非常常见,特别是在事件驱动编程和 GUI 应用中。本文将带你深入理解委托的定义、匿名方法、Lambda 表达式、事件机制以及多播委托的使用。 1. 委托&#x…...

使用微服务Spring Cloud集成Kafka实现异步通信(消费者)
1、本文架构 本文目标是使用微服务Spring Cloud集成Kafka实现异步通信。其中Kafka Server部署在Ubuntu虚拟机上,微服务部署在Windows 11系统上,Kafka Producer微服务和Kafka Consumer微服务分别注册到Eureka注册中心。Kafka Producer和Kafka Consumer之…...

docker pull 超时Timeout失败的解决办法
当国内开发者docker pull遇到如下提示时,不要惊讶 [rootvm /]# docker pull postgres Using default tag: latest Error response from daemon: Get "https://registry-1.docker.io/v2/": dial tcp 128.121.146.235:443: i/o timeout [rootvm /]# 自2024…...

YOLOv7改进之主干DAMOYOLO结构,结合 CReToNeXt 结构,打造高性能检测器
一、DAMOYOLO理论部分 论文地址:2211.15444 (arxiv.org) 在本报告中,我们提出了一种快速准确的对象检测方法,称为 DAMO-YOLO,它实现了比最先进的 YOLO 系列更高的性能。DAMO-YOLO 是从 YOLO 扩展而来的,具有一些新技术,包括神经架构搜索 (NAS)、高效的重新参数化广义 …...

进度条(倒计时)Linux
\r回车(回到当前行开头) \n换行 行缓冲区概念 什么现象? 什么现象?? 什么现象??? 自己总结: #pragma once 防止头文件被重复包含 倒计时 在main.c中,windows.h是不可以用的&…...

[每周一更]-(第117期):硬盘分区表类型:MBR和GPT区别
文章目录 1. **支持的磁盘容量**2. **分区数量**3. **引导方式**4. **冗余和数据恢复**5. **兼容性**6. **安全性**7. **操作系统支持**8. 对比 国庆假期前补一篇 在一次扫描机械硬盘故障的问题,发现我本机SSD和机械硬盘的分类型不一样,分别是GPT和MBR&a…...
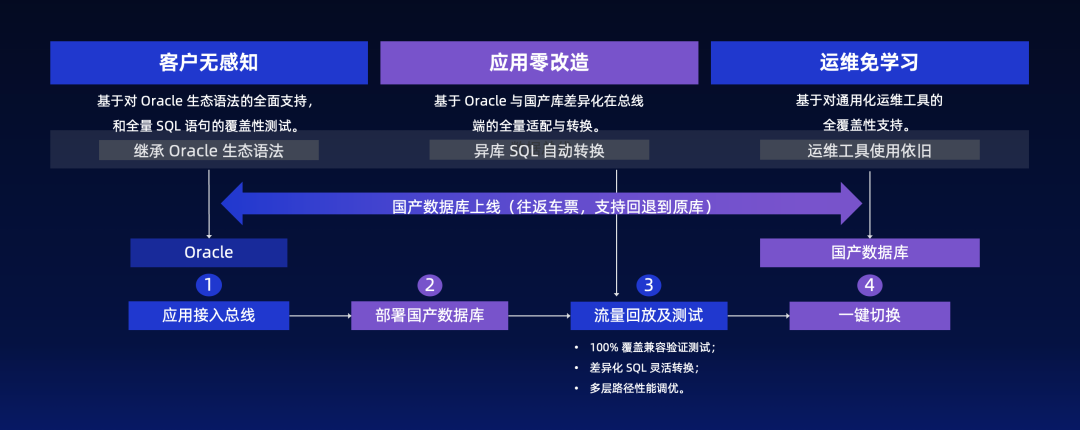
河南移动:核心营业系统稳定运行超300天,数据库分布式升级实践|OceanBase案例
河南移动,作为电信全业务运营企业,不仅拥有庞大的客户群体和业务规模,还引领着业务产品与服务体系的创新发展。河南移动的原有核心营业系统承载着超过6000万的庞大用户量,管理着超过80TB的海量数据,因此也面临着数据规…...

22.1 k8s不同role级别的服务发现
本节重点介绍 : 服务发现的应用3种采集的k8s服务发现role 容器基础资源指标 role :nodek8s服务组件指标 role :endpoint部署在pod中业务埋点指标 role :pod 服务发现的应用 所有组件将自身指标暴露在各自的服务端口上,prometheus通过pull过来拉取指标但是promet…...

OpenCV计算机视觉库
计算机视觉和图像处理 Tensorflow入门深度神经网络图像分类目标检测图像分割OpenCVPytorchNLP自然语言处理 OpenCV 一、OpenCV简介1.1 简介1.2 OpenCV部署1.3 OpenCV模块 二、OpenCV基本操作2.1 图像的基本操作2.1.1 图像的IO操作2.1.2 绘制几何图像2.1.3 获取并修改图像的像素…...

CentOS 系统中的文件挂载 U 盘
要将 CentOS 系统中的文件保存到 U 盘,可以按照以下步骤进行操作: 一、插入 U 盘并确定设备名称 将 U 盘插入 CentOS 系统的 USB 接口。使用 fdisk -l 命令查看系统中的磁盘和分区情况,确定 U 盘的设备名称。通常 U 盘会显示为类似于 /dev/…...
)
Lumerical脚本语言-变量操作(Manipulating variables)
下面的命令用来创建和存取变量。 命令描述= 赋值操作符 :数组操作符 []创建矩阵 % 创建包含空格的变量名称 linspace 创建线性空间数组 matrix 创建一个全为 0 的矩阵 randmatrix 创建一个所有元素为 0~1 之间的一个随机数的矩阵 randnmatrix 创建一个所有元素为平均值为 0…...

一个基本的包括爬虫、数据存储和前端展示框架0
创建一个完整的网络爬虫和前端展示页面是一个涉及多个步骤和技术的任务。下面我将为你提供一个基本的框架,包括爬虫代码(使用Python和Scrapy框架)和前端HTML页面(伏羲.html)。 爬虫代码 (使用Scrapy) 首先,你需要安装Scrapy库:bash pip install scrapy 然后,创建一个新…...

简历制作面试篇
一.面试技巧分析 模板: 推荐使用简洁一点的模板,不要太花哨,能够让HR和面试官清楚,快速知道信息就可以,太花哨容易分散别人的注意力。 格式: 一般选用PDF,不要用WORD。 照片: 技术岗一般不用贴照片,推进写上自己的联系方式或者微信。 专业技能: 描述专业技能…...
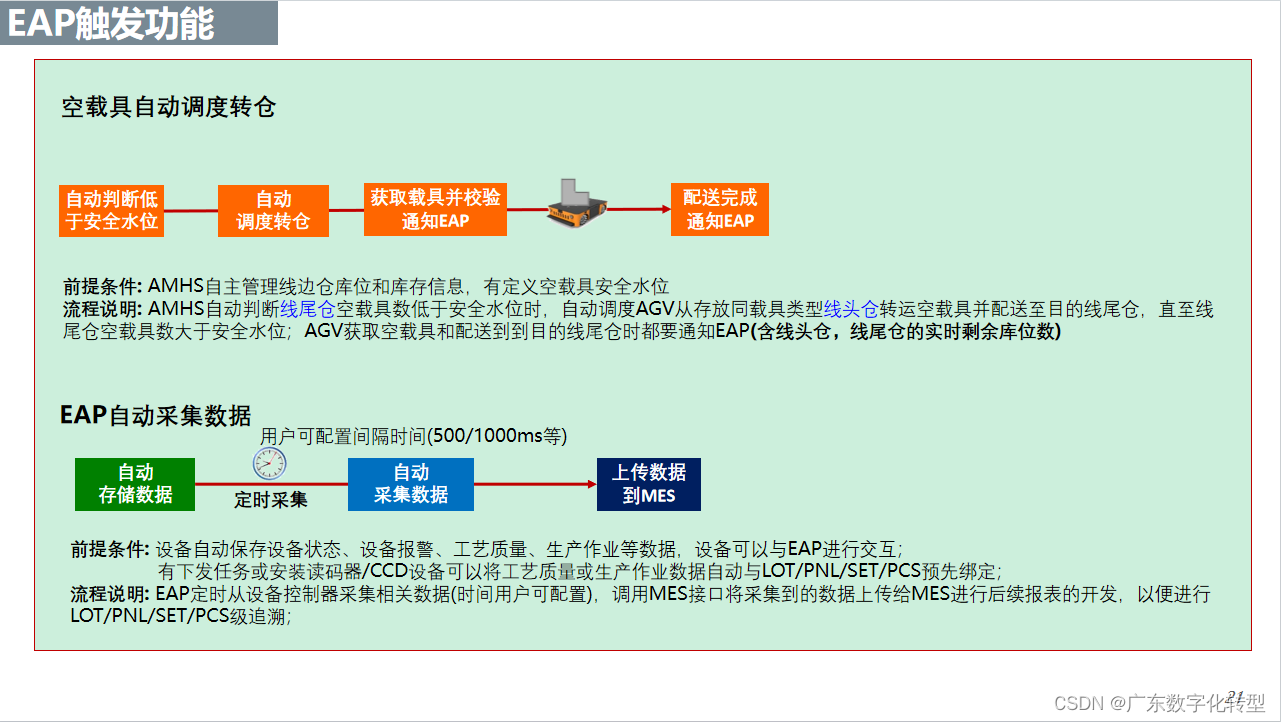
智能制造--EAP设备自动化程序
EAP是设备自动化程序(Equipment Automation Program)的缩写,他是一种用于控制制造设备进行自动化生产的系统。EAP系统与MES系统整合,校验产品信息,自动做账,同时收集产品生产过程中的制程数据和设备参数数据…...
LabVIEW混合控制器质量检测
随着工业自动化水平的提高,对控制器的精度、稳定性、可靠性要求也在不断上升。特别是在工程机械、自动化生产、风力发电等领域,传统的质量检测方法已无法满足现代工业的高要求。因此,开发一套自动化、精确、可扩展的混合控制器质量检测平台成…...

新技术浪潮下的等保测评:云计算、物联网与大数据的挑战与机遇
随着信息技术的飞速发展,云计算、物联网(IoT)和大数据等新兴技术正以前所未有的速度改变着我们的生活和工作方式。这些技术的广泛应用不仅为信息系统带来了前所未有的性能提升,同时也对等保测评(信息安全等级保护测评&…...

微信小程序技术框架选型
“近期在对团队的微信小程序进行技术框架选型,故对目前主流的微信小程序技术框架进行了一些分析和比较,包括各框架的维护团队、社区链接、GitHub star数、优缺点对比等方面,为团队提供技术框架选型参考” 一、引言 随着移动互联网的快速发展…...

SQL学习3
24.10.3学习目录 一.c语言操作数据库 一.c语言操作数据库 (1)打开、关闭数据库函数 //打开数据库 int sqlite3_open(char *db_name,sqlite3 **db);db_name:数据库文件名,若文件名中有ASCLL码中以外的字符,其必须为UT…...

Linux:进程控制(一)
目录 一、写时拷贝 1.创建子进程 2.写时拷贝 二、进程终止 1.函数返回值 2.错误码 3.异常退出 4.exit 5._exit 一、写时拷贝 父子进程,代码共享,不作写入操作时,数据也是共享的,当任意一方试图写入,便通过写时拷…...

Intel Lunar Lake核显架构解析:Xe2-LPG如何重塑轻薄本图形性能
1. 项目概述:一次架构驱动的核显革命最近,Intel Lunar Lake(月亮湖)移动处理器的核显性能数据开始陆续曝光,行业内讨论的热度很高。作为一个长期关注移动平台图形性能的从业者,我第一时间梳理了目前能获取到…...

Squirrel-RIFE实战指南:7步掌握AI视频补帧核心技术
Squirrel-RIFE实战指南:7步掌握AI视频补帧核心技术 【免费下载链接】Squirrel-RIFE 效果更好的补帧软件,显存占用更小,是DAIN速度的10-25倍,包含抽帧处理,去除动漫卡顿感 项目地址: https://gitcode.com/gh_mirrors/…...

通过Taotoken用量看板与账单追溯精细化管理团队AI支出
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板与账单追溯精细化管理团队AI支出 对于团队管理者而言,将大模型能力集成到业务中后,一…...

懒人必备!OpenClaw 汉化版一键配置上手教程
一、Windows 11 安装 OpenClaw 必看说明 OpenClaw(国内用户昵称"小龙虾")是一款广受欢迎的开源本地AI助手,GitHub星标数已超28万。它集成了多项实用功能:电脑自动操控、智能文件管理、浏览器自动化以及办公流程自动化等…...
)
RT-Thread Studio实战:搞定DS18B20温度读取的时序坑(附逻辑分析仪调试实录)
RT-Thread Studio实战:DS18B20温度读取的时序调试与逻辑分析仪应用 嵌入式开发中,单总线器件因其简洁的硬件连接而广受欢迎,但恰恰是这种"简单"往往隐藏着最棘手的调试难题。当你在RT-Thread环境下使用DS18B20温度传感器࿰…...

Perplexity开发者文档结构逆向工程:通过17个真实HTTP响应头+OpenAPI Schema反推隐藏端点与beta功能开关
更多请点击: https://intelliparadigm.com 第一章:Perplexity开发者文档查询 Perplexity 提供了一套面向 AI 应用开发者的 RESTful API 文档体系,其开发者中心(developer.perplexity.ai)支持结构化检索、版本过滤与实…...

Taotoken用量看板如何帮助团队清晰管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队清晰管理API成本 作为团队的技术负责人,在引入大模型能力支持多个业务项目时,…...

Freewall跨浏览器兼容性:解决IE8+布局问题的完整方案
Freewall跨浏览器兼容性:解决IE8布局问题的完整方案 【免费下载链接】freewall kombai/freewall: Freewall 是一个灵活、响应式的网格布局引擎,可用于创建具有自适应布局功能的网页或应用组件,尤其适合于图片墙、瀑布流布局等场景。 项目地…...

Quectel移远展锐平台5G模组RX500U/RG200U工作模式深度解析:从网卡到路由的实战选择
1. 5G模组工作模式基础认知 第一次接触Quectel移远展锐平台5G模组时,最让我困惑的就是网卡模式和路由模式的区别。记得去年做智能快递柜项目时,就因为没搞清这两种模式的特点,导致现场调试时手忙脚乱。后来在工业网关项目上反复折腾RX500U模组…...
)
特斯拉Model 3车主必看:用华为随行WiFi+流量卡,低成本搞定车载WiFi(附Type-C供电方案)
特斯拉Model 3车主必看:低成本车载WiFi实战指南 特斯拉Model 3的车载娱乐系统依赖网络连接,但官方高级娱乐服务的月费让不少车主犹豫。更糟的是,部分地区的4G信号覆盖不佳,导致在线音乐、实时路况等功能形同虚设。本文将分享一套经…...