爬虫——爬取小音乐网站
爬虫有几部分功能???
1.发请求,获得网页源码 #1.和2是在一步的 发请求成功了之后就能直接获得网页源码
2.解析我们想要的数据
3.按照需求保存
注意:开始爬虫前,需要给其封装

headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
爬虫分析:
第一步:从列表页抓取详情页面的链接

正则表达式:
<li\sclass="media\sthread\stap\s\s".*?>.*?<div\sclass="subject\sbreak-all">.*?<a\shref="(.*?)">(.*?)</a>
得到如下结果

从以上结果可以看出,此链接不可直接点击,缺少https://www.hifini.com/这一部分
https://www.hifini.com/thread-20945.htm
因此如下处理
for i in result:
# print(i)#元祖下标取值
href = "https://www.hifini.com/"+i[0]
name = i[1]
print(href)
print(name)
print('======================')

第二步:获取歌曲播放资源
找到歌曲url的xpath:
music:\s\[.*?title:\s'(.*?)',.*?url:\s'(.*?)'
代码:
#解析歌曲的播放组员
song_re = "music:\s\[.*?title:\s'(.*?)',.*?url:\s'(.*?)'"
r = re.findall(song_re,song_html_data,re.S)
# print('歌曲信息',r)
for i in r:song_name = i[0]song_link = "https://www.hifini.com/"+i[1]print('歌名:',song_name)print("歌曲播放资源链接",song_link)print('++++++++++++++++')

第三步:再次像歌曲播放资源链接发请求 获得二进制数据,进行保存
1.创建文件夹
#保存歌曲 先创建一个文件夹 导入os模块
#判断文件是否存在
if not os.path.exists('歌曲'):os.makedirs("歌曲")
2.创建文件流,将歌曲保存在文件夹中
with open('歌曲\{}.m4a'.format(song_name),'wb')as f:f.write(data_bytes)
代码:
import requests
import re
import osshouye_url = 'https://www.hifini.com/'
# 1.起始目标
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
response = requests.get(shouye_url, headers=headers)
#1.发请求,获得网页源码
def get_data(url):response = requests.get(url,headers=headers)# print(response.status_code)# print(response.text)if response.status_code == 200:return response.text
#2.解析我们想要的数据
def parse_data(data):#形参站位 模拟的就是爬虫爬取下来的源码z ='<li\sclass="media\sthread\stap\s\s".*?>.*?<div\sclass="subject\sbreak-all">.*?<a\shref="(.*?)">(.*?)</a>'result = re.findall(z,data,re.S)# print(result)# https://www.hifini.com/thread-20945.htmfor i in result:# print(i)#元祖下标取值href = "https://www.hifini.com/"+i[0]name = i[1]print(href)print(name)print('======================')get_song_link(href)#https://www.hifini.com/get_music.php?key=2Ydoqazb8E6jj+Nvl6rZLnuh3Fu1MRARle/srx5zQfZVMkPqsGrSzFHehon89oIENCUU19ru3GEJax60Ew
# 像详情页发请求 获得网页源码
def get_song_link(link):#link模拟的是详情页的urlsong_html_data = get_data(link)# print("详情页的网页源码",song_html_data)#解析歌曲的播放组员song_re = "music:\s\[.*?title:\s'(.*?)',.*?url:\s'(.*?)'"r = re.findall(song_re,song_html_data,re.S)# print('歌曲信息',r)for i in r:song_name = i[0]song_link = "https://www.hifini.com/"+i[1]print('歌名:',song_name)print("歌曲播放资源链接",song_link)print('++++++++++++++++')#再次像歌曲播放资源链接发请求 获得二进制数据data_bytes = requests.get(song_link,headers=headers).content# print(data_bytes)#保存歌曲 先创建一个文件夹 导入os模块#判断文件是否存在if not os.path.exists('歌曲'):os.makedirs("歌曲")with open('歌曲\{}.m4a'.format(song_name),'wb')as f:f.write(data_bytes)
#对应的功能写在不同的函数里面 如果需要互用功能 互相调用即可
if __name__ == '__main__':h = get_data(shouye_url)parse_data(h)结果:


相关文章:
爬虫——爬取小音乐网站
爬虫有几部分功能??? 1.发请求,获得网页源码 #1.和2是在一步的 发请求成功了之后就能直接获得网页源码 2.解析我们想要的数据 3.按照需求保存 注意:开始爬虫前,需要给其封装 headers {User-…...

5G NR SSB简介
文章目录 SSB介绍SSB波束扫描 SSB介绍 5G NR 引入了SSB 这个概念,同步信号和PBCH块(Synchronization Signal and PBCH block, 简称SSB) 它由主同步信号(Primary Synchronization Signals, 简称PSS)、辅同步信号(Secondary Synchronization Signals, 简称SSS)、PBCH…...

java将mysql表结构写入到word表格中
文章目录 需要的依赖 需要的依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.9</version> </dependency> <!--07版本的,行数不受限制--> <dependency>&l…...

SpringBoot教程(安装篇) | Docker Desktop的安装(Windows下的Docker环境)
SpringBoot教程(安装篇) | Docker Desktop的安装(Windows下的Docker环境) 前言如何安装Docker Desktop资源下载安装启动(重点)1. 检查 bcdedit的hypervisorlaunchtype是否为Auto2. 检查CPU是否开启虚拟化3.…...

day2网络编程项目的框架
基于终端的 UDP云聊天系统 开发环境 Linux 系统GCCUDPmakefilesqlite3 功能描述 通过 UDP 网络使服务器与客户端进行通信吗,从而实现云聊天。 Sqlite数据库 用户在加入聊天室前,需要先进行用户登录或注册操作,并将注册的用户信息…...

C++和OpenGL实现3D游戏编程【连载13】——多重纹理混合详解
🔥C++和OpenGL实现3D游戏编程【目录】 1、本节要实现的内容 前面说过纹理贴图能够大幅提升游戏画面质量,但纹理贴图是没有叠加的。在一些游戏场景中,要求将非常不同的多个纹理(如泥泞的褐色地面、绿草植密布的地面、碎石遍布的地面)叠加(混合)起来显示,实现纹理间能够…...

探索云计算中的 Serverless 架构:未来的计算范式?
目录 引言 一、Serverless架构概览 二、Serverless 架构的优势 三、Serverless架构的挑战 四、Serverless架构的未来展望 五、结论 引言 在当今快速发展的 IT 行业中,云计算无疑占据了举足轻重的地位。随着技术的不断演进,云计算的一个新兴分支——…...
爬虫及数据可视化——运用Hadoop和MongoDB数据进行分析
作品详情 运用Hadoop和MongoDB对得分能力数据进行分析; 运用python进行机器学习的模型调理,利用Pytorch框架对爬取的评论进行情感分析预测; 利用python和MySQL对网站的数据进行爬取、数据清洗及可视化。...
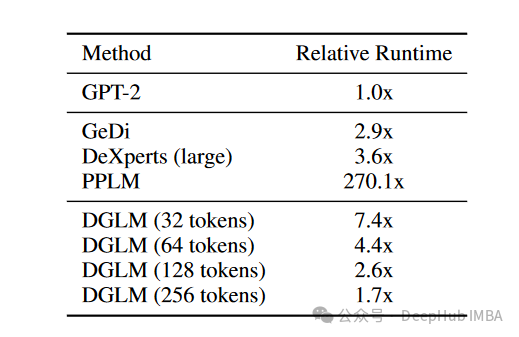
扩散引导语言建模(DGLM):一种可控且高效的AI对齐方法
随着大型语言模型(LLMs)的迅速普及,如何有效地引导它们生成安全、适合特定应用和目标受众的内容成为一个关键挑战。例如,我们可能希望语言模型在与幼儿园孩子互动时使用不同的语言,或在撰写喜剧小品、提供法律支持或总结新闻文章时采用不同的风格。 目前,最成功的LLM范式是训练…...
)
LeetCode hot100---数组及矩阵专题(C++语言)
1、最大子数组和 (1)题目描述以及输入输出 (1)题目描述: 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 (2)输入输出描述: 输入&#…...
LabVIEW提高开发效率技巧----快速实现原型和测试
在LabVIEW开发中,DAQ助手(DAQ Assistant)和Express VI为快速构建原型和测试功能提供了极大的便利,特别适合于简单系统的开发和早期验证阶段。 DAQ助手:是一种可视化配置工具,通过图形界面轻松设置和管理数据…...

大论文记录
基础知识回顾 1.强化学习(Agent、Environment) 在 RL 中,代理通过不断与环境交互、以试错的方式进行学习,在不确定性下做出顺序决策,并在探索(新领域)和开发(使用从经验中学到的知识ÿ…...

蘑菇分类检测数据集 21类蘑菇 8800张 带标注 voc yolo
蘑菇分类检测数据集 21类蘑菇 8800张 带标注 v 蘑菇分类检测数据集 21类蘑菇 8800张 带标注 voc yolo 蘑菇分类检测数据集介绍 数据集名称 蘑菇分类检测数据集 (Mushroom Classification and Detection Dataset) 数据集概述 该数据集专为训练和评估基于YOLO系列目标检测模型…...

dockerhub 镜像拉取超时的解决方法
在几个月前,因为一些原因,导致 dockerhub 官网上面的镜像拉取超时,目前可以通过修改仓库地址,通过 daocloud 拉取 public-image-mirror 方式一 源仓库替换仓库cr.l5d.iol5d.m.daocloud.iodocker.elastic.coelastic.m.daocloud.io…...

私家车开车回家过节会发生什么事情
自驾旅行或者是自驾车回家过节路程太远。长途奔袭的私家车损耗很大。新能源汽车开始涉足电力系统和燃电混动的能源供应过渡方式。汽车在路途中出现零件故障。计划的出发日程天气原因。台风是否会提醒和注意。汽车的油站供应链和电力充电桩的漫长充电过程。高速公路的收费站和不…...

正则表达式的使用示例--Everything文件检索批量重命名工具
一、引言 Everything是一款非常实用的文件搜索工具,它可以帮助您快速定位并查找计算机中的文件和文件夹。Everything搜索文件资料之神速,有使用过的朋友们都深有体会,相对于Windows自带的搜索功能,使用Everything,可以…...

centos环境安装JDK详细教程
centos环境安装JDK详细教程 一、前期准备二、JDK安装2.1 rpm方式安装JDK2.2 zip方式安装JDK2.3 yum方式安装JDK 本文主要说明CentOS下JDK的安装过程。JDK的安装有三种方式,用户可根据实际情况选择: 一、前期准备 查看服务器操作系统型号,执…...

Spring Cloud全解析:服务调用之OpenFeign集成OkHttp
文章目录 OpenFeign集成OkHttp添加依赖配置连接池yml配置 OpenFeign集成OkHttp OpenFeign本质是HTTP来进行服务调用的,也就是需要集成一个Http客户端。 使用的是Client接口来进行请求的 public interface Client {// request是封装的请求方式、参数、返回值类型/…...

前端算法合集-1(含面试题)
(这是我面试一家中厂公司的二面算法题) 数组去重并按出现次数排序 题目描述: 给定一个包含重复元素的数组,请你编写一个函数对数组进行去重,并按元素出现的次数从高到低排序。如果次数相同,则按元素值从小到大排序。 let arr [2, 11,10, 1…...

影刀---如何进行自动化操作
本文不是广告,没有人给我宣传费,只是单纯的觉得这个软件很好用 感谢大家的多多支持哦 本文 1.基本概念与操作(非标准下拉框和上传下载)非标准对话框的操作上传对话框、下载的对话框、提示的对话框 2.综合案例3.找不到元素怎么办&a…...

手机上还有免费编辑pdf文本的软件?!
说的就是这款软件:pdfgear 适合哪些朋友:平板电脑、手机轻度办公用户。 这款软件算是为数不多良心软件了。 支持常见的pdf批注:高亮、删除线、下划线等。 主要还有一个很好的功能就是文字编辑功能:不需要切换word就能直接对pdf进行…...

Delft3D建模、水动力模拟方法及地表水环境影响评价:岸线绘制与导入、非结构化计算网格生成、水下地形数据处理等前处理操作;水动力与污染物对流扩散模拟的参数设置、边界条件设定及模型率定验证
查看原文>>>https://mp.weixin.qq.com/s/_CiPDK_oXaAGxVfu2qk6ew 前言 本文以地表水数值模拟软件Delft3D 4.03.00操作为主要内容,强调地表水水动力建模、基础资料的获取、边界条件设定、模型率定和验证、数据分析和处理等关键环节。通过对案例模型的实操…...

谷歌AI掌门竟是死敌大股东!“DeepMind黑手党”四年卷走140亿美元
谷歌AI掌门竟是死敌大股东,“DeepMind黑手党”四年卷走140亿美元!就在刚刚,全球科技圈爆出惊人消息——谷歌AI最高掌门人、DeepMind创始人、诺贝尔奖得主Demis Hassabis,被挖出是其最大死敌、超级独角兽Anthropic的早期隐秘金主&a…...

1987年5月10日晚上23-24点出生性格、运势和命运
出生在下午13-15点这一时段,从心理发展角度来看,最大的性格红利是“社交直觉”。这类人往往在很小的时候就展现出一种能力:能快速识别他人的情绪,并自然地调整自己的行为以促进和谐。这并非玄学,而是因为下午出生婴儿的…...

软件架构分析方法SAAM、ATAM与CBAM
一、SAAM(软件架构分析方法) 1. 核心思路 基于场景,评估架构对可修改性(以及可移植性、可扩充性)的支持程度。 关键是区分 直接场景(现有架构直接支持)和 间接场景(需要修改架构)。 通过分析间接场景的数量与修改代价,定位高风险、高耦合的模块。 2. 典型案例:内…...

CentOS Stream 9初体验:除了名字加了Stream,桌面和内核到底有哪些升级?
CentOS Stream 9深度评测:技术选型者的上游发行版实战指南 当红帽宣布CentOS Linux转向Stream模式时,整个开源社区掀起了一场关于"稳定性与前瞻性如何平衡"的持久讨论。作为RHEL上游的滚动预览版,CentOS Stream 9的定位已从传统的&…...

影刀RPA 企业级专题篇:自动化中台架构与多业务流程治理实践
影刀RPA 企业级专题篇:自动化中台架构与多业务流程治理实践 作者:林焱 很多团队最开始做自动化。 目标都很简单。 让流程跑起来。 减少重复操作。 前期。 几个流程。 几台机器。 一个维护人员。 系统看起来非常轻。 但随着业务扩大。 问题会…...

硬件工程选型解析:钡特电源VB60-24S12LD与金升阳URB2412LD-60WR3同属工业高可靠
在工业硬件研发、设备调试与批量量产工作中,大功率工业DC-DC模块的工况适配性、结构规范性与运行稳定性,是硬件研发工程师重点核查的核心指标,直接决定工控设备、电力终端、智能装备的长期运行可靠性。在60W级国产直流电源模块品类中…...

scikit-learn自定义Pipeline:从接口契约到业务落地的完整实践
1. 项目概述:为什么需要自己动手定制 scikit-learn 的模型与流水线在真实的数据科学项目里,你几乎不可能靠from sklearn.ensemble import RandomForestClassifier一行代码就搞定所有事。我带过十几个工业级建模项目,从电商价格预测到医疗设备…...

白帽工程师的四大核心工具链:从资产测绘到修复验证
1. 这不是“黑客速成班”,而是真实白帽工程师的日常工具箱很多人看到“挖漏洞”三个字,第一反应是黑进系统、炫技式提权、深夜敲代码改数据库——这其实是影视作品和自媒体标题党联手塑造的幻觉。真实的网络安全一线工作中,90%以上的漏洞发现…...