大模型训练环境搭建
硬件资源说明
本教程基于GPU 3090的服务器
| 资源类型 | 型号 | 核心指标 |
| CPU | Intel(R) Xeon(R) Bronze 3204 CPU @ 1.90GHz | 12核 |
| 内存 | / | 125Gi |
| GPU | NVIDIA GeForce RTX 3090 | 24G显存 |
注意:接下来的部分命令需要使用科学上网,需要事先配置好。
安装docker
参考docker的官方文档:Install | Docker Docs
这里简单列举一下常见系统的安装命令
对于ubuntu系统:
sudo apt install docker.io
sudo systemctl enable docker对于centos系统:
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo systemctl start docker
sudo systemctl enable docker这里默认安装的docker版本为24.0.7,docker版本的差异不会影响整个测试的流程,不过还是建议使用和本教程相同的版本
安装NVIDIA Container Toolkit
安装该工具主要是为了docker可以挂载Nvidia GPU设备。
参考:Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.16.2 documentation
安装方式有很多,这里仅列举比较常用的ubuntu和centos安装方式:
在线安装
对于ubuntu系统
sudo apt install curl -y
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit对于Centos系统
sudo yum install curl -y
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
sudo yum install -y nvidia-container-toolkit离线安装
参考开源项目:libnvidia-container/stable/ubuntu18.04/amd64 at gh-pages · NVIDIA/libnvidia-container · GitHub
对于Ubuntu系统
下载以下安装包:
# 分别打开如下链接
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/libnvidia-container1_1.9.0-1_amd64.deb
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/libnvidia-container-tools_1.9.0-1_amd64.deb
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/nvidia-container-toolkit_1.9.0-1_amd64.deb
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/ubuntu18.04/amd64/nvidia-docker2_2.10.0-1_all.deb点击下载
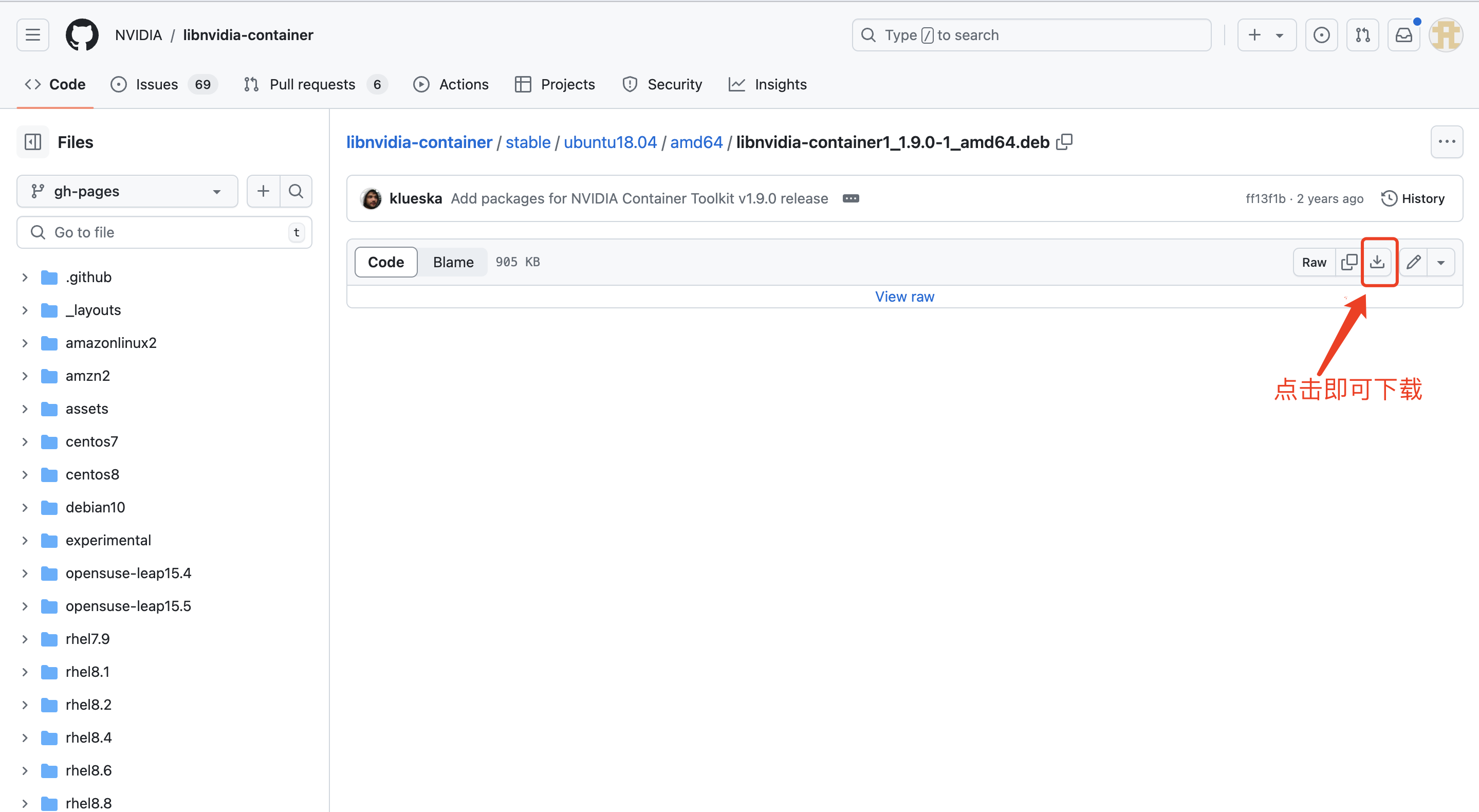
下载好的安装包执行如下命令即可安装:
dpkg -i libnvidia-container1_1.9.0-1_amd64.deb
dpkg -i libnvidia-container-tools_1.9.0-1_amd64.deb
dpkg -i nvidia-container-toolkit_1.9.0-1_amd64.deb
dpkg -i nvidia-docker2_2.10.0-1_all.deb安装完成后需要重启docker以生效
systemctl restart docker对于Centos系统
参考ubuntu的方式寻找适合自己系统的rpm包进行安装
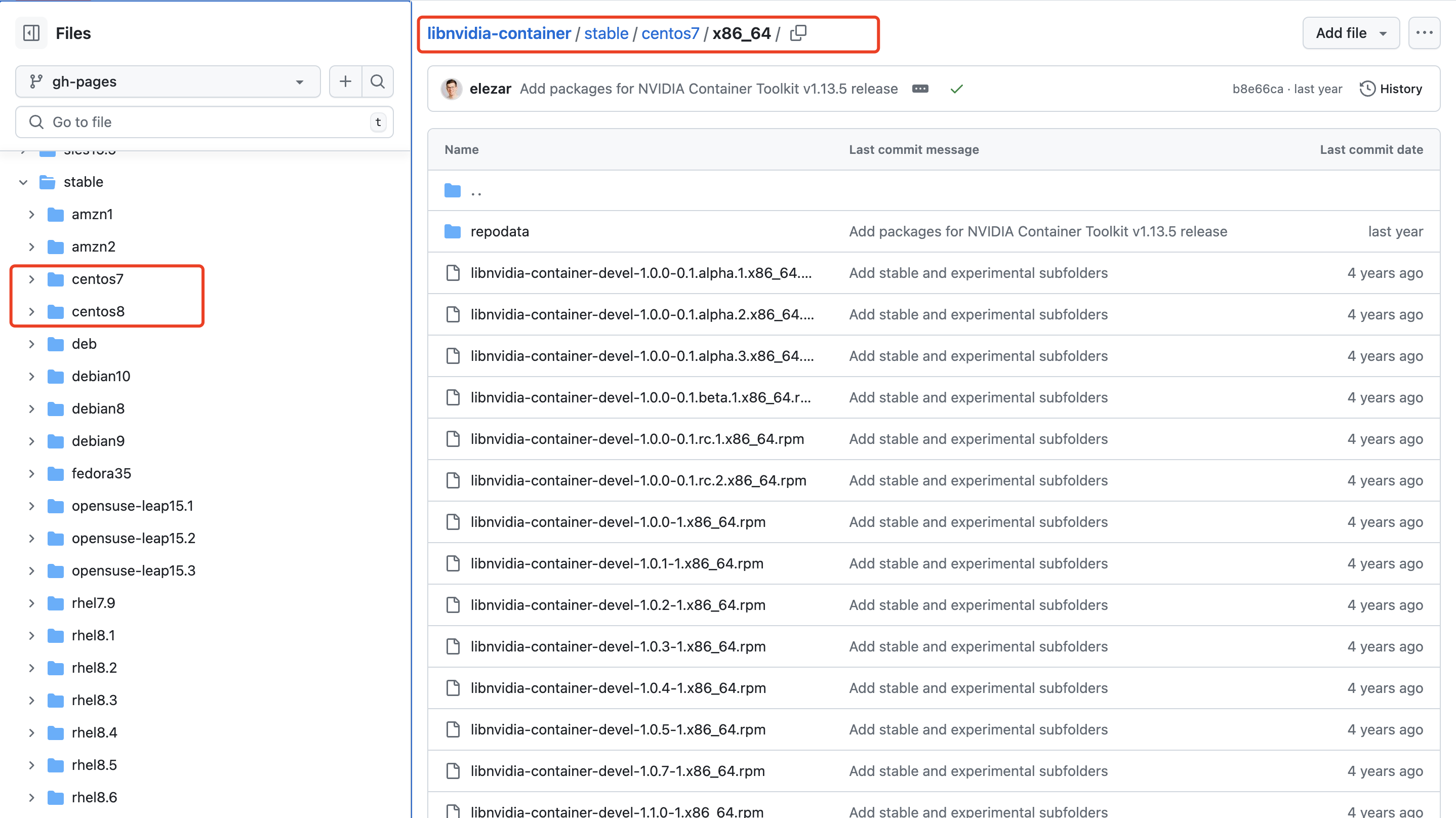
这里假设是Centos7,则在如下页面寻找libnvidia-container/stable/centos7/x86_64 at gh-pages · NVIDIA/libnvidia-container · GitHub
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/libnvidia-container-devel-1.9.0-1.x86_64.rpm
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/libnvidia-container-tools-1.9.0-1.x86_64.rpm
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/nvidia-container-toolkit-1.9.0-1.x86_64.rpm
https://github.com/NVIDIA/libnvidia-container/blob/gh-pages/stable/centos7/x86_64/nvidia-docker2-2.10.0-1.noarch.rpm下载好后安装命令为
rpm -ivh libnvidia-container-devel-1.9.0-1.x86_64.rpm
rpm -ivh libnvidia-container-tools-1.9.0-1.x86_64.rpm
rpm -ivh nvidia-container-toolkit-1.9.0-1.x86_64.rpm
rpm -ivh nvidia-docker2-2.10.0-1.noarch.rpm安装完成后需要重启docker以生效
systemctl restart docker镜像制作
下载镜像
这里在Nvidia NGC上下载一个比较干净的镜像,模型开发需要的pip包我们自己来装「比如xtuner」。
镜像仓库:dockerhub
对于NVIDIA的GPU,很多基础的镜像名字(编译安装好各类软件包的环境)可以在NGC上找到,网址为:Data Science, Machine Learning, AI, HPC Containers | NVIDIA NGC
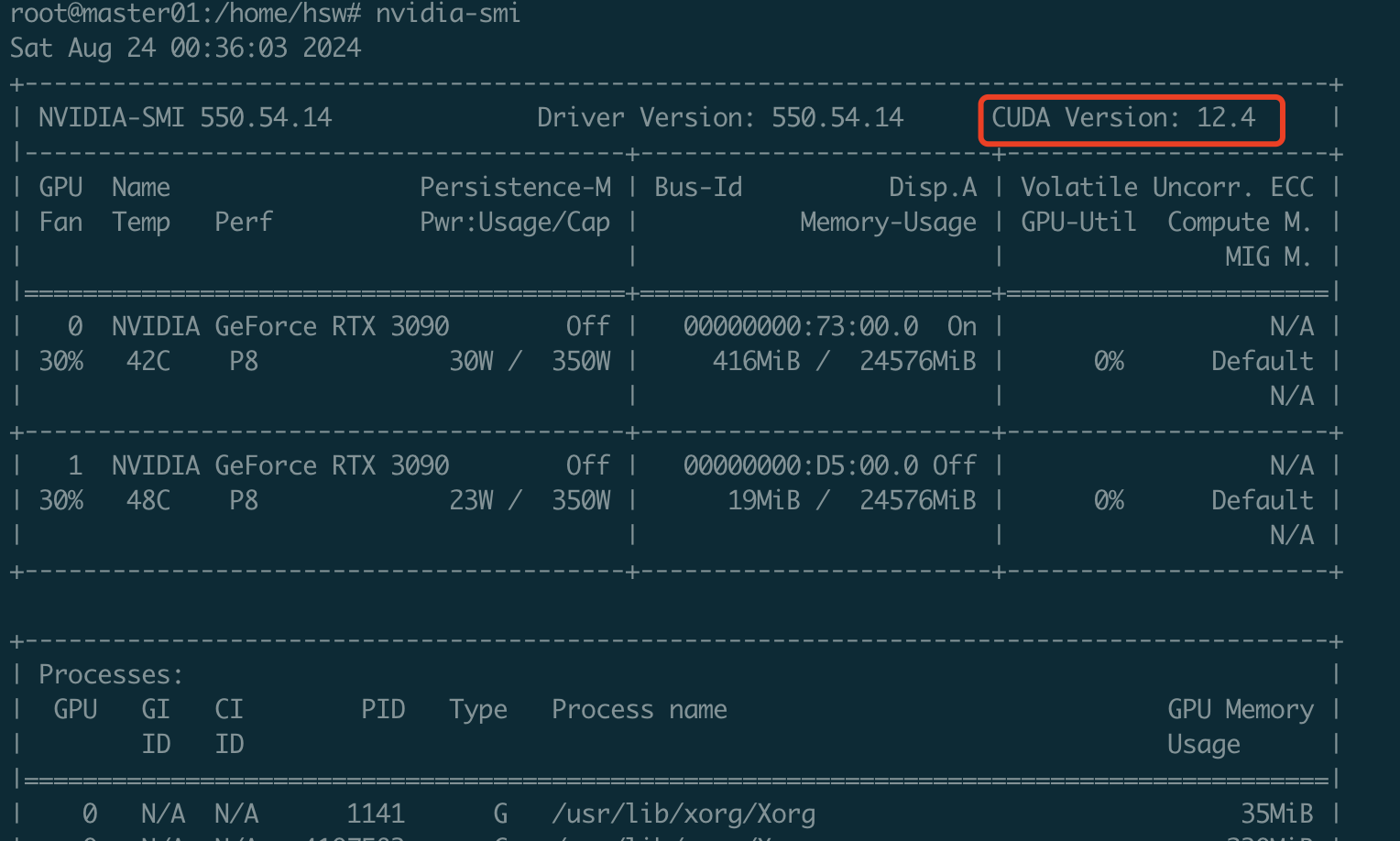
下载什么版本镜像来匹配自己的cuda版本呢?可以通过执行nvidia-smi来查看,我这台服务器是cuda 12.4,如下图所示,那我们最好也是下载cuda12.x对应的docker镜像(不需要严格对齐版本)。
找到对应的镜像名字:
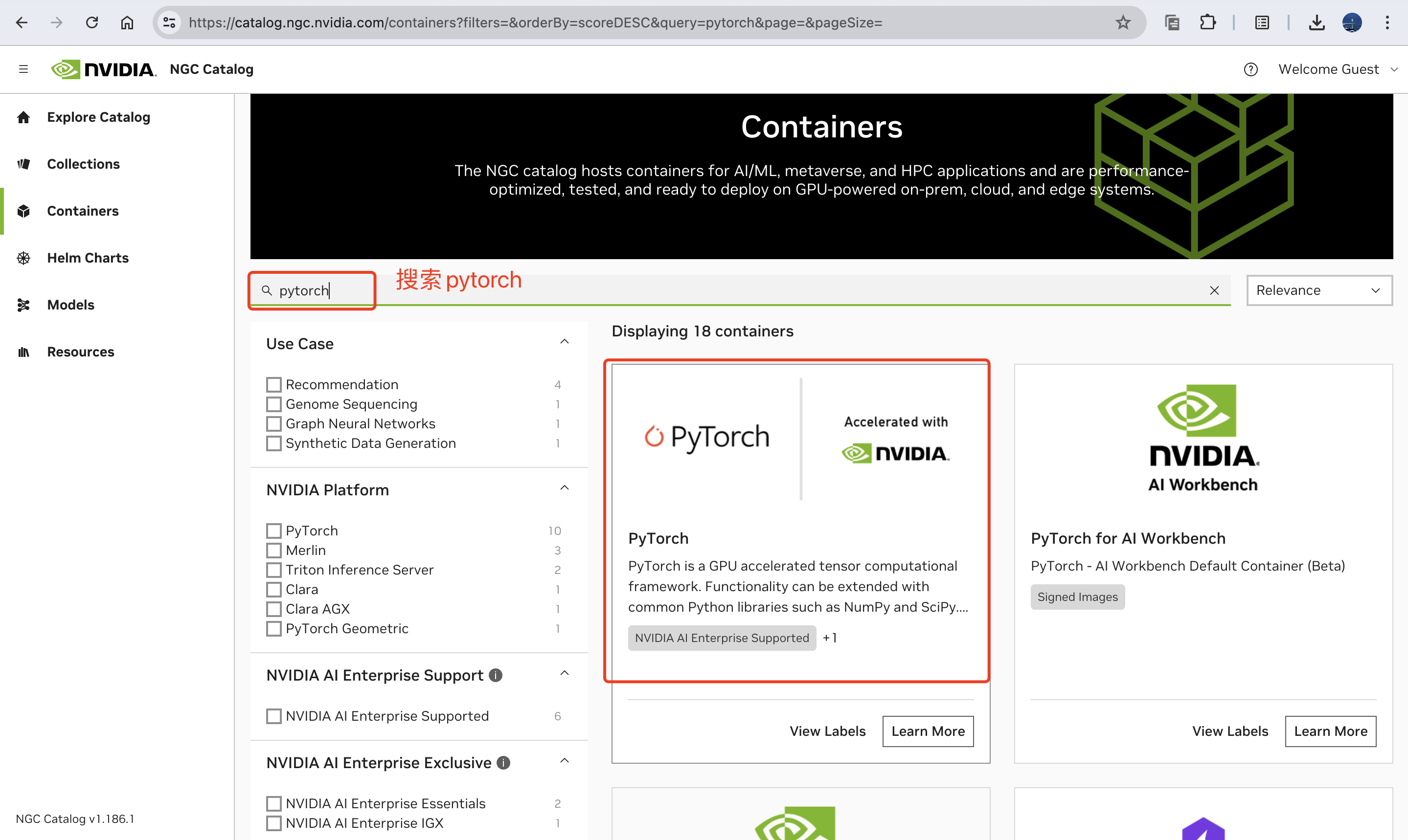
这里选择的cuda版本和机器安装的cuda版本一致,都是12.x;此外选择一个自己常用的操作系统版本,比如这里我选择的是ubuntu22.04,值得一提的是,这里的系统版本和自己机器上的系统版本没有必然联系,机器上只要可以运行docker即可。
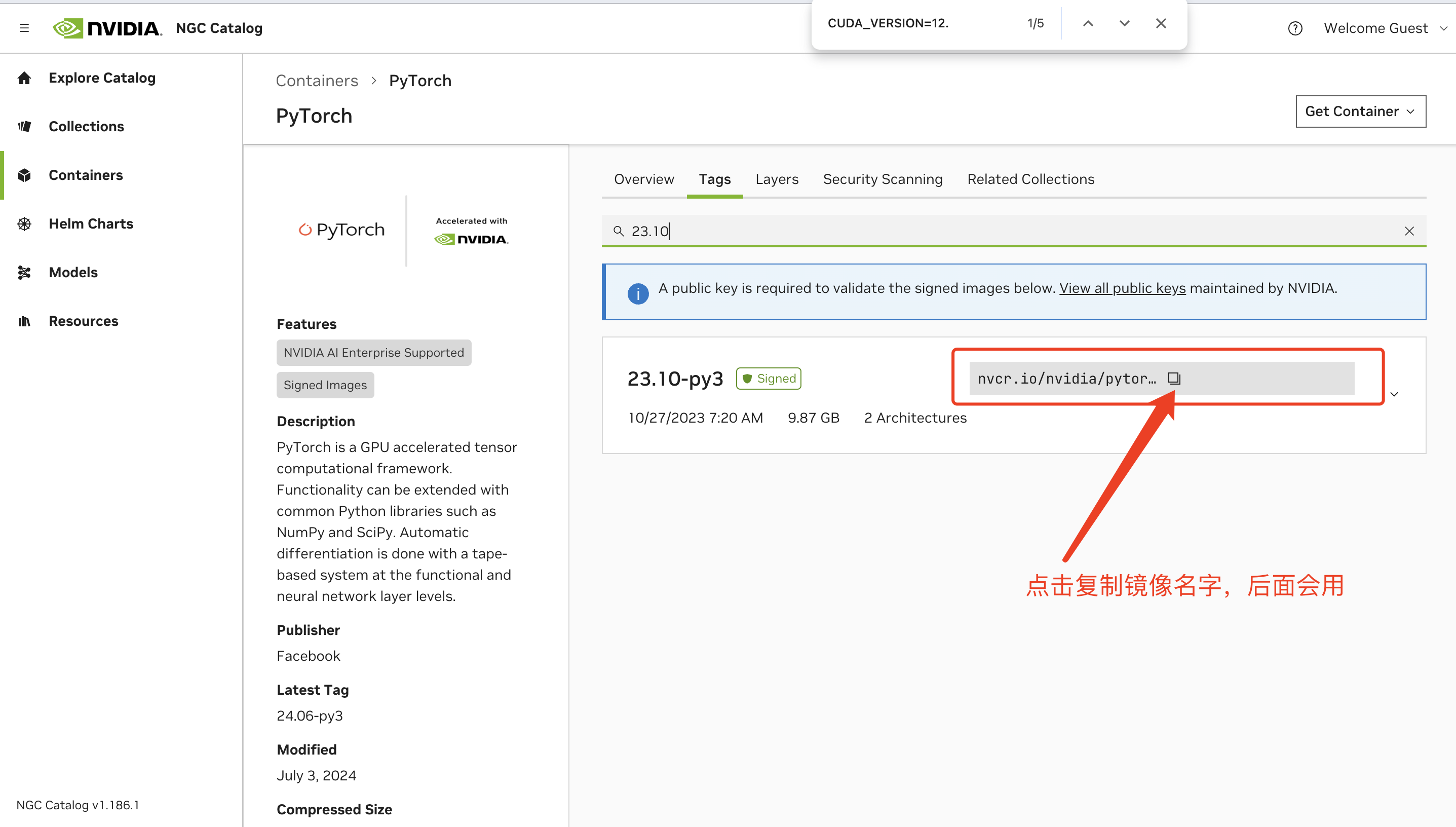
执行下载镜像的命令,这个过程的耗时和各自的网络速度有关:
# 刚刚复制的镜像名字放在docker pull后面即可
docker pull nvcr.io/nvidia/pytorch:23.10-py3
如果镜像无法下载,需要配置科学上网。
启动镜像
启动镜像时有一些参数如下。执行如下命令后,就已经启动了镜像并进入了容器内部,接下来执行的所有命令都是在容器内部进行的。
# --gpus=all 表示将机器上的所有GPU挂载到容器内
# -v /data2/:/datasets表示将本地的/data2 目录挂载到容器的/datasets目录
docker run -it --gpus=all -v /data2/:/datasets nvcr.io/nvidia/pytorch:23.10-py3 bash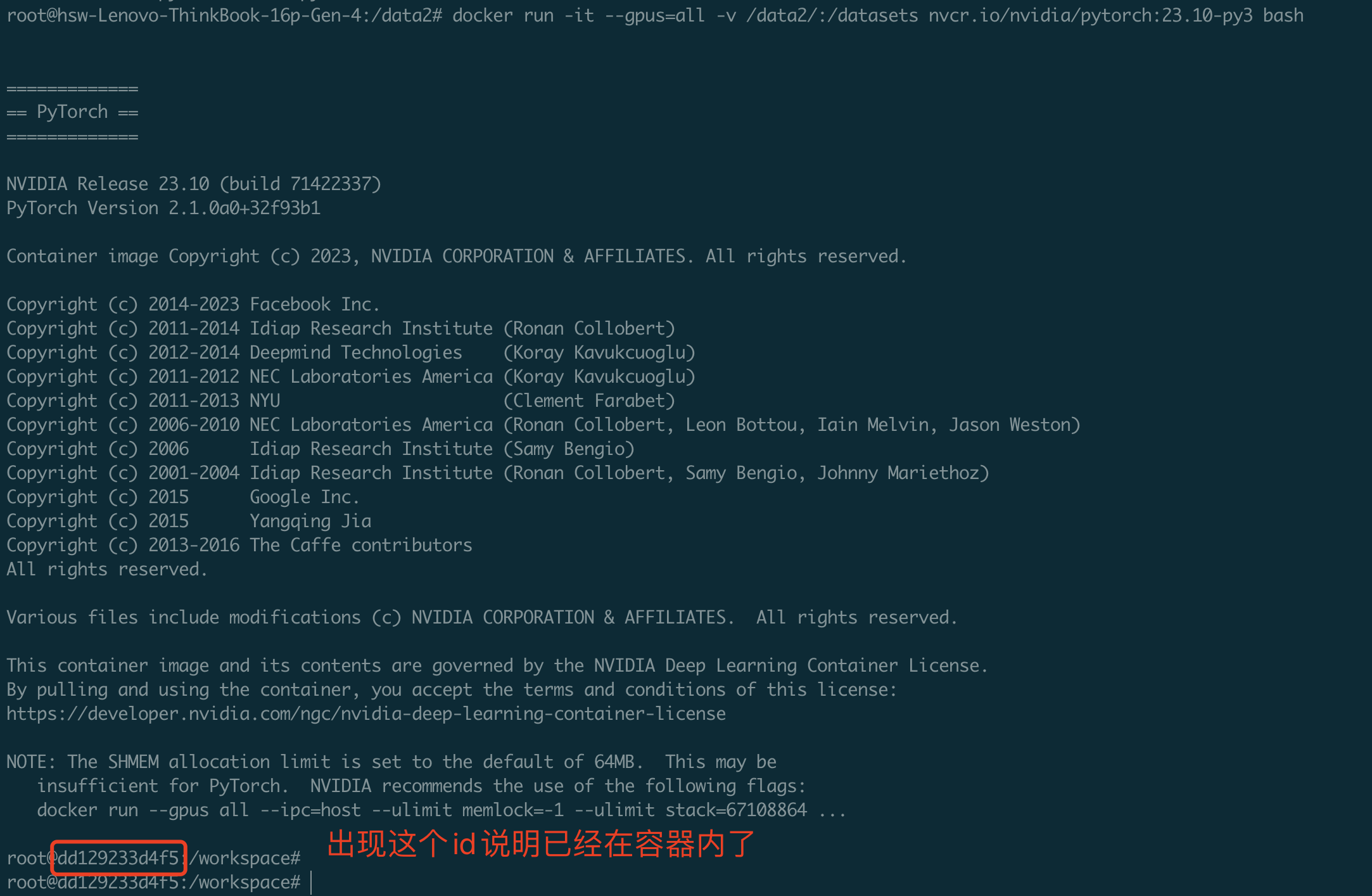
开始安装环境
现在在容器内,开始执行环境安装命令:
apt-get update
apt-get install libaio-dev -y
pip install xtuner[all]==0.1.18 -i https://mirrors.ustc.edu.cn/pypi/web/simple
pip3 install "fschat[model_worker,webui]" -i https://mirrors.ustc.edu.cn/pypi/web/simple
pip3 install jupyterlab -i https://mirrors.ustc.edu.cn/pypi/web/simple
pip install opencv-python==4.8.0.74 -i https://mirrors.ustc.edu.cn/pypi/web/simple
pip uninstall transformer_engine flash-attn
pip install datasets==2.18.0 安装过程如下「这个过程大约持续10~20分钟,主要看机器的网速」:
保存镜像
将制作好镜像进行保存,上面的容器内部截图中显示了一个id,使用这个容器id即可保存安装好的环境。
#xtuner-fastchat-cuda122:23.10-py3表示给镜像取一个新的名字「命名形式为xxx:yyy」
docker commit dd129233d4f5 xtuner-fastchat-cuda122:23.10-py3Tips:比较高级的用法是使用Dockerfile进行镜像制作,参考:Docker Dockerfile | 菜鸟教程
运行微调测试
启动环境
# 用新的镜像启动容器
# 参数--shm-size 32G表示容器运行环境添加了32G的共享内存
# 参数-p 8888:8888表示将容器内部的8888端口和主机上的8888端口进行映射
docker run -it --shm-size 32G --gpus=all --network=host -v /mnt/nfs_share/data2/:/code/ -v /mnt/nfs_share/data2/:/dataset xtuner-fastchat-cuda122:23.10-py3 bash# 进入容器后执行如下命令开启jupyter-lab
cd /code
jupyter-lab --allow-root --ip='*' --NotebookApp.token='' --NotebookApp.password='' &在自己的浏览器中新建一个页面,输入http://127.0.0.1:8888/lab即可进入jupyterlab界面
运行测试
我们还是以微调qwen0.5B作为例子,展示下代码无缝迁移:
step1: 模型下载
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download Qwen/Qwen1.5-0.5B-Chat --resume-download --local-dir-use-symlinks False --local-dir /dataset/Qwen1.5-0.5B-Chat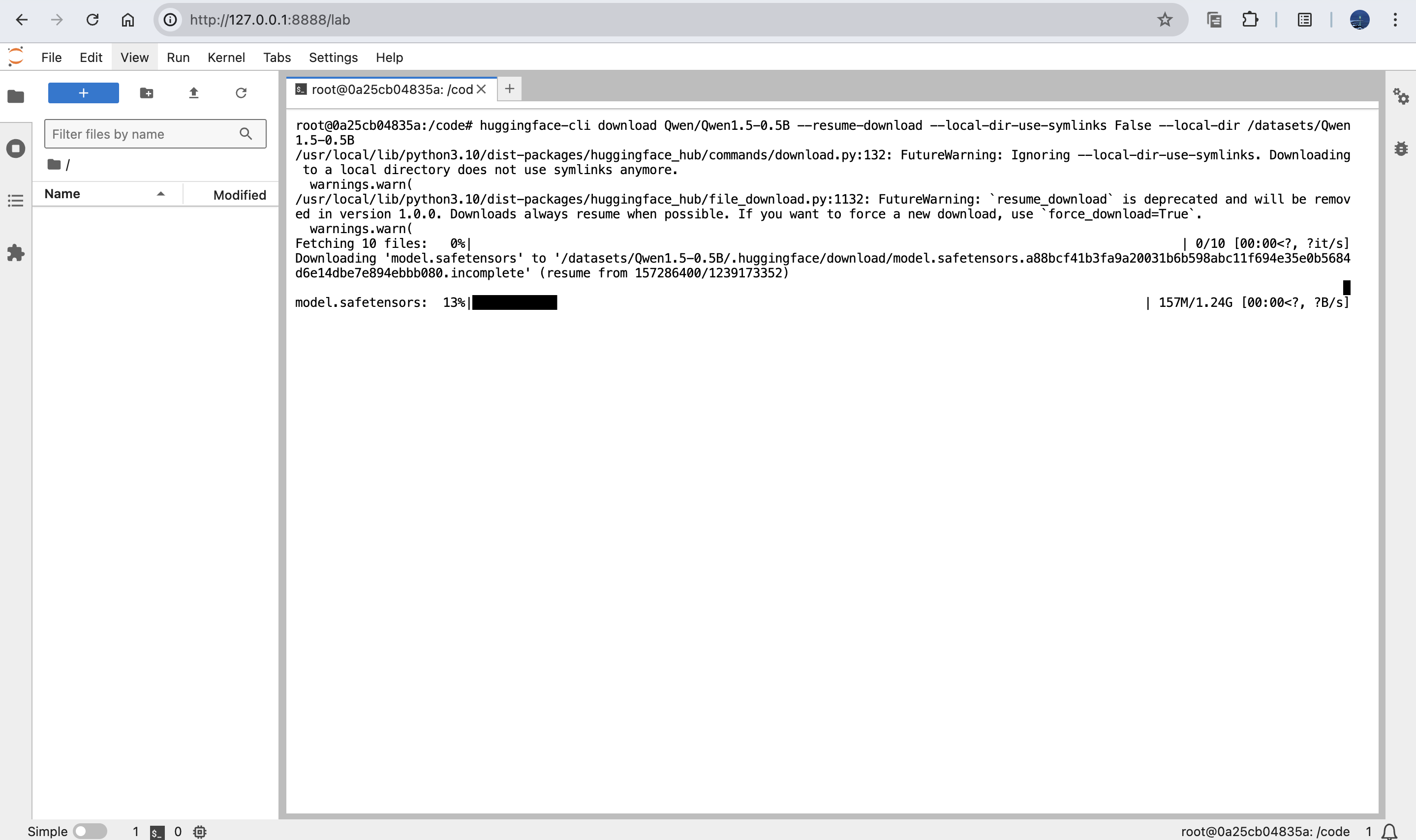
数据下载
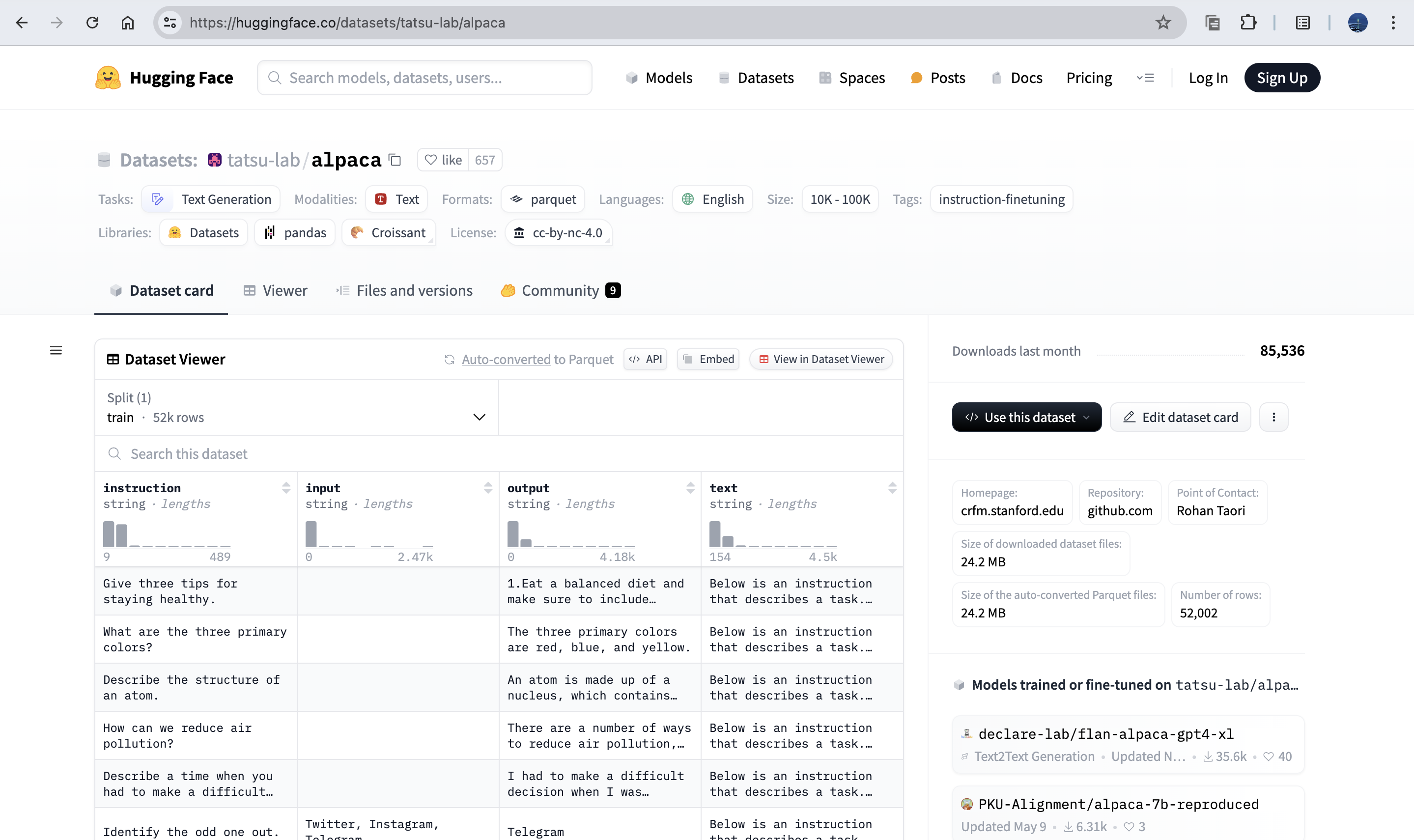
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download tatsu-lab/alpaca --repo-type dataset --revision main --local-dir-use-symlinks False --local-dir /dataset/datasets/tatsu-lab___alpaca/data/算法文件(qwen1_5_0_5b_chat_full_alpaca_e3.py)
# Copyright (c) OpenMMLab. All rights reserved.
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizerfrom xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook,VarlenAttnArgsToMessageHubHook)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/dataset/Qwen1.5-0.5B-Chat/'
use_varlen_attn = False# Data
alpaca_en_path = '/dataset/datasets/tatsu-lab___alpaca/data/'
prompt_template = PROMPT_TEMPLATE.qwen_chat
max_length = 2048
pack_to_max_length = False# parallel
sequence_parallel_size = 1# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 3
optim_type = AdamW
lr = 2e-5
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03# Save
save_steps = 500
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = ['请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai'
]#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side='right')model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True))#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path=alpaca_en_path),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=alpaca_map_fn,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn)sampler = SequenceParallelSampler \if sequence_parallel_size > 1 else DefaultSamplertrain_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=alpaca_en,sampler=dict(type=sampler, shuffle=True),collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn))#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale='dynamic',dtype='float16')# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [dict(type=LinearLR,start_factor=1e-5,by_epoch=True,begin=0,end=warmup_ratio * max_epochs,convert_to_iter_based=True),dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,begin=warmup_ratio * max_epochs,end=max_epochs,convert_to_iter_based=True)
]# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),# dict(# type=EvaluateChatHook,# tokenizer=tokenizer,# every_n_iters=evaluation_freq,# evaluation_inputs=evaluation_inputs,# system=SYSTEM,# prompt_template=prompt_template)
]if use_varlen_attn:custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 10 iterations.logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=1),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per `save_steps`.checkpoint=dict(type=CheckpointHook,by_epoch=False,interval=save_steps,max_keep_ckpts=save_total_limit),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend='nccl'),
)# set visualizer
visualizer = None# set log level
log_level = 'INFO'# load from which checkpoint
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)# set log processor
log_processor = dict(by_epoch=False)
算法上传到自己本地启动的notebook中:
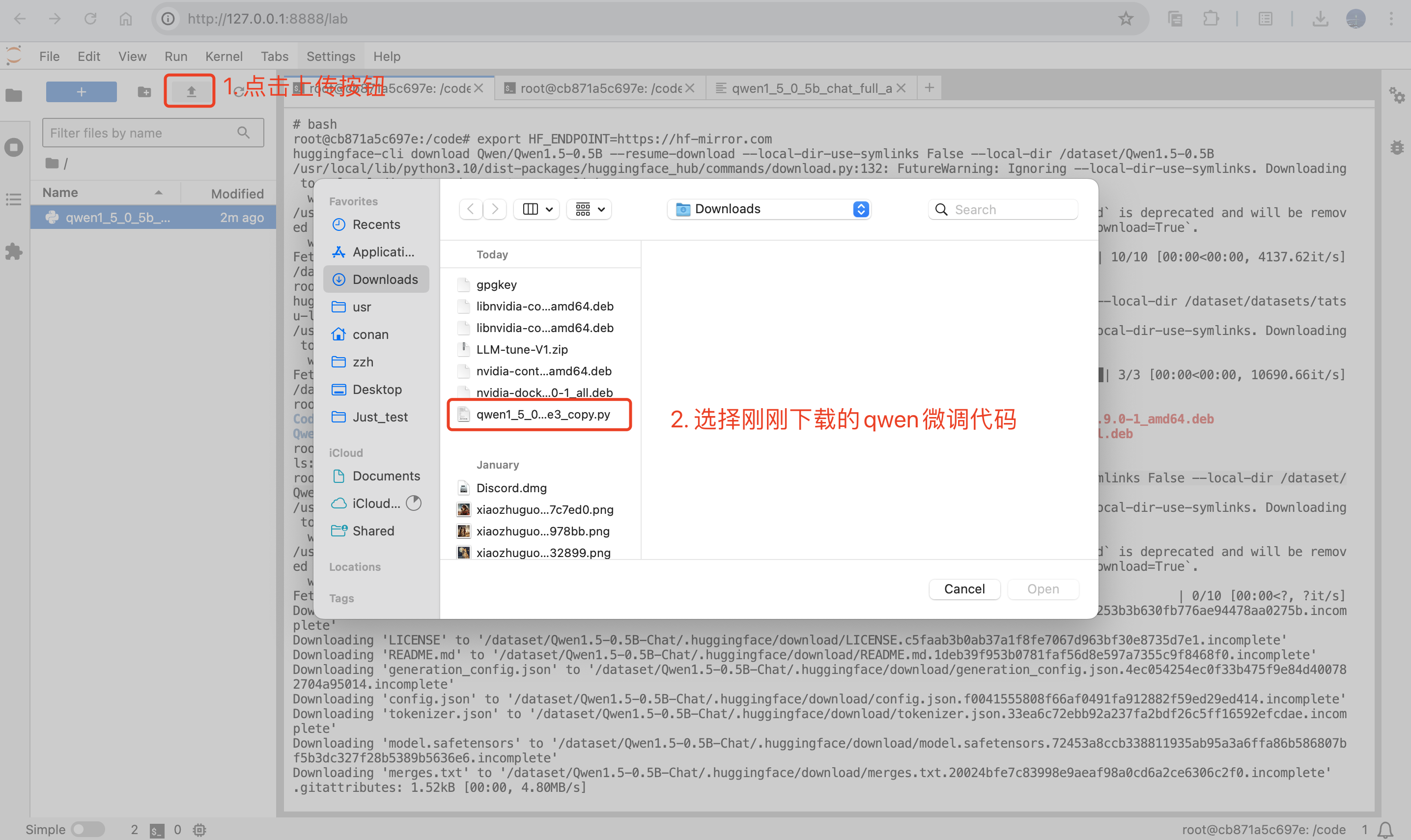
开始微调
mkdir -p /userhome/xtuner-workdir
NPROC_PER_NODE=1 xtuner train qwen1_5_0_5b_chat_full_alpaca_e3_copy.py --work-dir /userhome/xtuner-workdir --deepspeed deepspeed_zero3_offload如果显存不够可以考虑使用lora或者qlora
3090的显存24G,全量参数微调不够用,需要开启lora训练
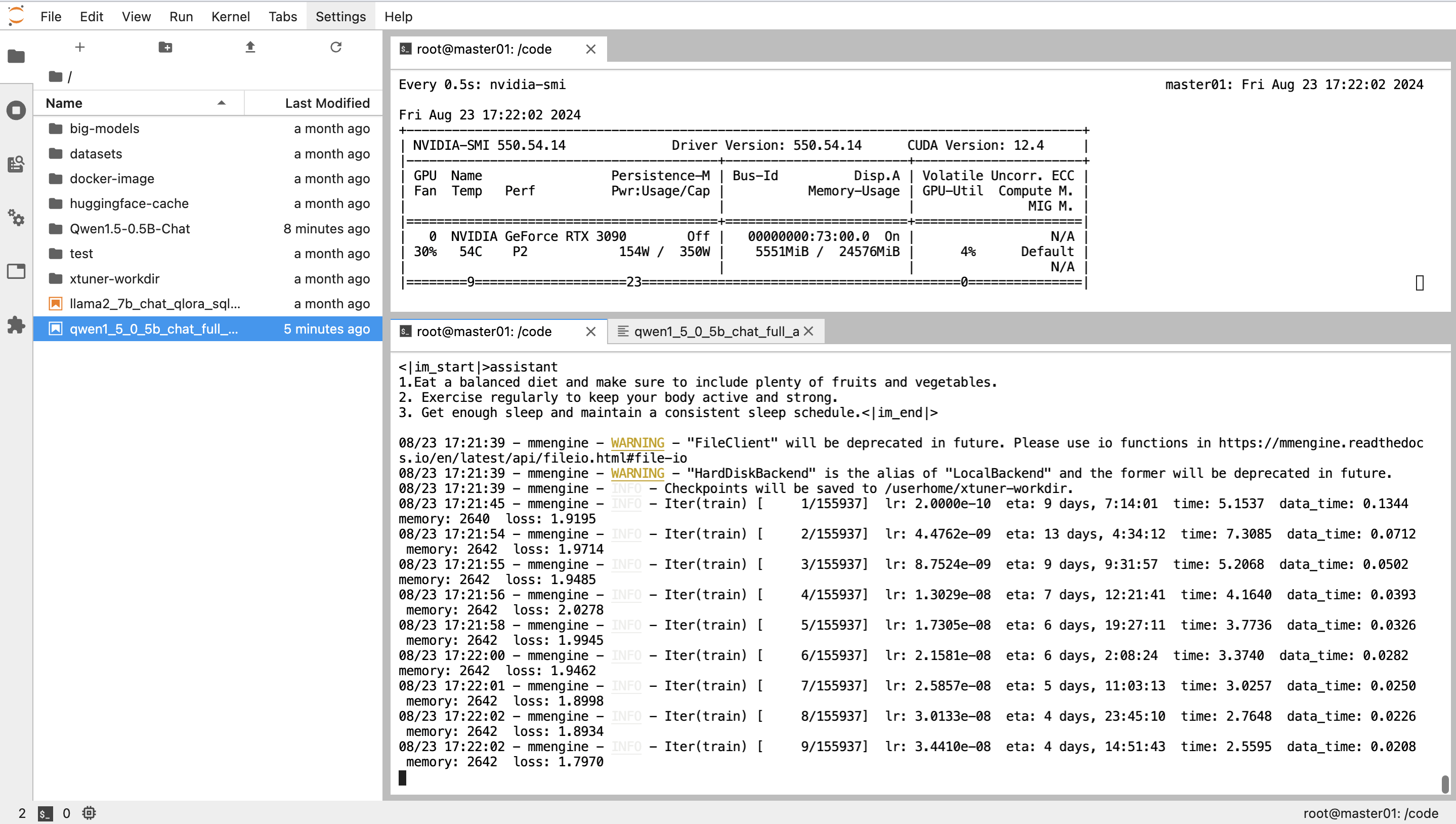
运行模型部署
打开4个终端,分别按顺序执行如下命令
多机多卡训练教程以及视频 mp4 下载链接:点击这里下载
python -m fastchat.serve.controller --host 0.0.0.0
python -m fastchat.serve.model_worker --model-path /dataset/Qwen1.5-0.5B-Chat/ --host 0.0.0.0 --num-gpus 1 --max-gpu-memory 20GiB
python -m fastchat.serve.openai_api_server --host 0.0.0.0
curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen1.5-0.5B-Chat","prompt": "Once upon a time","max_tokens": 41,"temperature": 0.5}'
调用结果返回正常:

相关文章:
大模型训练环境搭建
硬件资源说明 本教程基于GPU 3090的服务器 资源类型 型号 核心指标 CPU Intel(R) Xeon(R) Bronze 3204 CPU 1.90GHz 12核 内存 / 125Gi GPU NVIDIA GeForce RTX 3090 24G显存 注意:接下来的部分命令需要使用科学上网,需要事先配置好。 安…...

使用Java调用GeoTools实现全球国家矢量数据入库实战
目录 前言 一、相关数据介绍 1、无空间参考的数据 2、有空间参考的数据 3、空间信息表物理模型 二、全球国家空间数据入库 1、后台实体类图 2、后台实体对象关键代码 三、时空数据入库实践 1、读取无空间参考数据 2、入库成果及注意事项 四、总结 前言 在当今世界&…...

计算机毕业设计 基于Python的广东旅游数据分析系统的设计与实现 Python+Django+Vue Python爬虫 附源码 讲解 文档
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

Springboo通过http请求下载文件到服务器
这个方法将直接处理从URL下载数据并将其保存到文件的整个过程。下面是一个这样的方法示例: import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.HttpURLConnection…...

使用CSS实现酷炫加载
使用CSS实现酷炫加载 效果展示 整体页面布局 <div class"container"></div>使用JavaScript添加loading加载动画的元素 document.addEventListener("DOMContentLoaded", () > {let container document.querySelector(".container&q…...
【STM32-HAL库】AHT10温湿度传感器使用(STM32F407ZGT6配置i2c)(附带工程下载连接)
一、温湿度传感器: 温湿度传感器是一种能够检测环境中的温度和湿度,并将其转化为电信号输出的装置。它在智能家居、工业自动化、气象监测、农业等领域有着广泛的应用。 原理: 温湿度传感器通常基于不同的物理原理,以下是一些常见…...

深入理解网络通信: 长连接、短连接与WebSocket
在现代网络应用开发中,选择合适的通信方式对于应用的性能、效率和用户体验至关重要。本文将深入探讨三种常见的网络通信方式:长连接、短连接和WebSocket,分析它们的特点、区别以及适用场景。 1. 短连接 © ivwdcwso (ID: u012172506) 1.1 定义 短连接是指客户端和服务器…...

Linux·环境变量与进程地址空间
1. 命令行参数 各位可能见过main函数也是有参数的,只是我们平时写的代码都比较简单,用不到main函数的参数,下面我们看一下main函数的参数是什么又是怎么用的 我们看这样一段代码 其编译运行后的效果是这样的 我们将main函数后面的那两个参数叫…...

MYSQL 乐观锁
乐观锁是一种用于处理并发控制的策略,特别适用于读多写少的场景。在 MySQL 数据库中,乐观锁通常通过版本号或时间戳来实现。下面将详细介绍乐观锁的概念、实现方式以及在 MySQL 中的应用。 1. 乐观锁的概念 乐观锁的基本思想是:在对数据进行…...
全局过滤器和跨域)
SpringCloud入门(十二)全局过滤器和跨域
一、全局过滤器 全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。 区别在于GatewayFilter通过配置定义,处理逻辑是固定的,如果我们希望拦截请求,做自己的业务逻辑则没办法实现。而GlobalFilt…...

51单片机系列-按键检测原理
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 独立按键是检测低电平的。 下面我们来看一张对应的电路原理图: 在这张图当中,P1,P2,P3内部都上拉了电阻,但是P0没有&am…...

基于元神操作系统实现NTFS文件操作(五)
1. 背景 本文主要介绍$Root元文件的解析。先介绍元文件的构成及各个部分的结构,然后结合上一篇博文中读取到的元文件内容,对测试磁盘中目标分区的根目录进行展示。 2. $Root元文件解析 (1)$Root元文件的结构 $Root元文件由两部…...
AutoCAD学习
AutoCAD学习 最基本操作 命令用途说明空格键确认键也可以是重复刚才的命令回车键也是确认键鼠标右键也可以选择确认LINE、L直线命令绘制直线DLI线性尺寸标注DIMLINEAR鼠标滚轮滚动放大缩小视图界面鼠标中键按住移动视图DAL对齐线性标注DIMALIGNED F8 正交模式ORTHOMODE Tab 切换…...

go的一些知识点
一.package 1.新建项目 新建一个itying文件夹,在里面使用命令 就能生成一个go项目。生成一个go.mod 2.调用别的包的代码 按照下面的目录层级生成代码 //clac.go package calcfunc Add(x, y int) int {return x y } func Sub(x, y int) int {return x - y }…...

前端 vue3 对接科大讯飞的语音在线合成API
主要的功能就是将文本转为语音,可以播放。 看了看官方提供的demo,嗯....没看懂。最后还是去网上找的。 网上提供的案例,很多都是有局限性的,我找的那个他只能读取第一段数据,剩下的不读取。 科大讯飞的接口…...

缺省参数
一、概念 在声明或定义函数时为函数的参数指定一个默认值,调用时,如果对应参数没有传参,则使用其默认值,否则使用指定的实参 void TestFunc(int a 0) {cout<<a<<endl; }int main() {TestFunc(); // 没有传参&am…...
Stable Diffusion绘画 | 来训练属于自己的模型:炼丹启动
经过前面几轮辛苦的准备工作之后,现在开始进入终篇的炼丹环节。 在「上传素材」页面,点击「开始训练」: 可以在「查看进度-进度」中,查看模型训练的整体进度: 求助!!!操作「开始训练…...

08_OpenCV文字图片绘制
import cv2 import numpy as npimg cv2.imread(image0.jpg,1) font cv2.FONT_HERSHEY_SIMPLEXcv2.rectangle(img,(500,400),(200,100),(0,255,0),20) # 1 dst 2 文字内容 3 坐标 4 5 字体大小 6 color 7 粗细 8 line type cv2.putText(img,flower,(200,50),font,1,(0,0,250)…...

【笔记】选择题笔记+数据结构笔记
文章目录 2014 41方法一先序遍历方法二 连通分量是极大连通子图 一个连通图的生成树是一个极小连通子图 无向图的邻接表中,第i个顶点的度为第i个链表中的结点数 邻接表和邻接矩阵对不同的操作各有优势。 最短路径算法: 单源最短路径 已知图G(V,E),我们…...
浅谈汽车智能座舱如何实现多通道音频
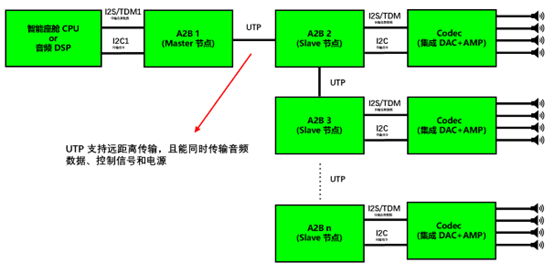
一、引言 随着汽车智能座舱的功能迭代发展,传统的 4 通道、6 通道、8 通道等音响系统难以在满足驾驶场景的需求,未来对于智能座舱音频质量和通道数会越来越高。接下来本文将浅析目前智能座舱如何实现音频功放,以及如何实现多路音频功放方案。…...

ncmdumpGUI:解锁网易云音乐NCM格式的3步可视化解决方案
ncmdumpGUI:解锁网易云音乐NCM格式的3步可视化解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾在网易云音乐下载了心爱的歌曲&…...

Python初学者项目练习23--计算圆的面积
一、练习题目 定义一个函数,这个函数用于计算并返回给定半径的圆的面积(要求结果保留两位小数) 二、代码 1.初始版本 代码如下: def area(r):"""作用:用于计算并返回给定半径的圆的面积(要求…...
)
全学科适用AI写作辅助软件排名(2026 精选)
基于功能完整性、学术适配性、用户满意度和操作便捷性,以下是当前主流AI论文写作工具的权威测评结果,按综合使用价值从高到低排序,并详细说明各工具的核心优势与适用领域。🏆 第一梯队:全流程学术解决方案(…...

从装饰器原理到实战:手把手教你用TypeScript为NestJS方法实现一个‘网络代理’
从装饰器原理到实战:手把手教你用TypeScript为NestJS方法实现一个‘网络代理’ 在Node.js生态中,装饰器(Decorator)作为一种元编程工具,正逐渐从实验性特性转变为现代框架的核心支柱。NestJS正是这一趋势的典型代表—…...

高校生最适用的AI论文网站是哪款?
国内高校学生在论文写作中越来越依赖AI工具,目前主流方案以本土化全流程工具为核心,结合通用大模型与专业辅助工具,覆盖选题构思、框架搭建、初稿撰写、内容降重、查重检测以及格式排版等关键环节,以下将深入解析并对比当前最适配…...

多模型选型与成本对比在Taotoken模型广场轻松完成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型选型与成本对比在Taotoken模型广场轻松完成 对于开发者而言,选择合适的模型并控制调用成本是接入大模型服务时的…...

UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知
UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知在全域空间高精度感知产业高速迭代进程中,室内外人员与目标定位技术逐步分化为两大主流发展路径,其一为深耕多年、依托硬件组网实现测距定位的传统UWB厘米级…...

Hertz.dev实时音频对话实战:构建智能语音助手的最佳实践指南
Hertz.dev实时音频对话实战:构建智能语音助手的最佳实践指南 【免费下载链接】hertz-dev first base model for full-duplex conversational audio 项目地址: https://gitcode.com/gh_mirrors/he/hertz-dev Hertz.dev是一个开创性的全双工会话音频基础模型&a…...

论文的重复率是什么?
论文重复率,说直白一点,就是你的论文内容和数据库里已有内容的文字相似比例。但这里有个很多人会误解的点:重复率 ≠ 抄袭率。查重系统本质上是在做“文本比对”,不是在判断你的主观意图。比如你自己写了一句:“随着数…...
3分钟终极指南:用trackerslist让你的BT下载速度提升5倍
3分钟终极指南:用trackerslist让你的BT下载速度提升5倍 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 还在为BT下载速度慢而烦恼吗?trackerslist项…...