DBT hook 实战教程
本文将介绍dbt中在模型和seed级别使用post-hook的几个具体示例。dbt中的Post-hooks是一个强大而简单的特性,它在构建模型之后(如果是pre-hook,甚至在此之前)执行SQL语句。这些语句实际上(几乎)可以是任何东西,从将表复制到另一个数据库/模式,或限制记录的数量,或重新格式化seed。我们将讨论的示例是指DuckDB,但是也可以适用于其他数据库。
认识 dbt hook
将原始数据转换为可供下游消费者使用的模型,直接使用SQL非常实用,但dbt默认不支持,仅支持SELECT 语句。如果遇到下列场景,我们可能需要SQL实现:
- 管理计算层的大小或容量
- 应用屏蔽策略或访问策略
- 管理数据库参数
dbt hook可以实现这些特殊任务。与dbt项目中的许多资源不同,钩子可以使用简单的SELECT语句之外的SQL命令,这打开了充满可能性的新世界。dbt hook 主要分为:
- On-run-start/end: 用于在执行某些dbt命令之前/之后运行SQL查询
在下列命令的开始或结束处运行SQL语句(或SQL语句列表): dbt build, dbt compile, dbt docs generate, dbt run, dbt seed, dbt snapshot, dbt test`. on-run-start和on-run-end hook也可以宏。语法如下:
-- dbt_project.yml
on-run-start: sql-statement | [sql-statement]
on-run-end: sql-statement | [sql-statement]
- Pre-/post-hooks: 用于在执行某些dbt节点之前/之后运行SQL查询
在model, seed, snapshot 被构建之前/后运行SQL语句(或SQL语句列表), Pre-/post-hooks子也可以调用宏。dbt旨在通过开箱即用的功能提供SQL模版代码 (DDL、DML和DCL),从而快速而简洁地配置模型转换业务。当需要执行dbt尚未提供的特性时,我们可以使用dbt的编译上下文编写所需的SQL,并将其传递到Pre-/post-hooks,以便在model, seed 或 snapshot之前或之后运行。语法如下:
-- dbt_project.ymlmodels:<resource-path>:+pre-hook: SQL-statement | [SQL-statement]+post-hook: SQL-statement | [SQL-statement]
也可以在模型中配置:
-- models/<model_name>.sql{{ config(pre_hook="SQL-statement" | ["SQL-statement"],post_hook="SQL-statement" | ["SQL-statement"],
) }}select ...
对于seed 和 snapshot 语法类似。
dbt模型使用post-hook
想象有业务需求如是:我们dbt项目中模型需存储在特定schema中,其访问权限是不公开的。这意味着组织中的任何人都无法从该模式中读取数据。这样做的原因可能与包含个人敏感数据有关,或者仅仅是数据治理规范,团队希望控制创建表的访问和使用权限。
我们可以使用post-hook实现对数据的访问,同时不影响安全管理规范。在本例中,这些数据需要被其他团队使用,我们将表的内容复制到另一个公共模式/表中:
{{config(materialized='table',post_hook=["CREATE OR REPLACE TABLE {{ env_var('DBT_DATABASE') }}.public_schema.mart_orders AS SELECT * FROM {{this}};"]
)
}}SELECT *
FROM {{ ref('ref_orders') }}
当这个模型运行时,用于构建模型的SQL首先运行,紧接着post-hook语句被执行。在这个示例中,我们使用:
- {{this}}函数,它引用了在此文件中构建的模型,特别是它在数据库中的表示
- env_var函数获取存储在profiles文件中的数据库变量。从技术上讲,如果您已经为本地使用设置了DEV环境,则不需要添加它,因为dbt将自动指向它。然而,这似乎是一个很好的做法,声明它,也使读者清楚。
请注意,建议这里使用{{this}},特别是如果在两个独立的环境,一个用于本地开发,一个用于生产。如前所述,如果在本地运行该模型,dbt将把FROM {{this}}和CREATE TABLE语句转换为在配置文件中声明的本地开发数据库。然而,很可能实际不需要在开发数据库中使用公开表,而只需要在生产中使用。在这种情况下,可以简单地在post-hook中进行显式设置,只需从生产环境中获取数据并将其构建到生产环境中。代码示例如下:
{{config(materialized='table',post_hook=["CREATE OR REPLACE TABLE prod_database.public_schema.mart_orders AS SELECT * FROM prod_database.team_private_schema.mart_orders;"]
)
}}SELECT *
FROM {{ ref('ref_orders') }}
现在,让我们给post-hook逻辑增加两个业务用例,基于以下现实场景:
- 我们要公开的表包含一些个人隐私数据,如customer_email或customer_phone_number
- 公共模式仅用于“展示”模型的内容,而实际的访问是在其他地方(例如按需)提供的,并且直接访问存储在私有schema中的表。
对于第一个用例,我们仅需排除不想暴露的字段以返回其部分内容:
{{config(materialized='table',post_hook=["CREATE OR REPLACE TABLE prod_database.public_schema.mart_orders AS SELECT * EXCLUDE (customer_email, customer_phone_number), split(customer_email,'@')[2] AS customer_email FROM prod_database.team_private_schema.mart_orders;"]
)
}}SELECT *
FROM {{ ref('ref_orders') }}
对于第二个用例,我们只是限制表中返回的记录数量。并添加一列,其中包含友好的提醒信息,以便与团队联系以访问表格:
{{config(materialized='table',post_hook=["CREATE OR REPLACE TABLE prod_database.public_schema.mart_orders AS SELECT 'request access to the table at team_data@company.com' AS readme, * EXCLUDE (customer_email, customer_phone_number), split(customer_email,'@')[2] AS customer_email FROM prod_database.team_private_schema.mart_orders
LIMIT 5;"]
)
}}SELECT *
FROM {{ ref('ref_orders') }}
dbt seed使用post-hook
Dbt seed可以直接加载CSV文件到数据仓库中,通常拥有处理不经常更改的静态数据。有时这些csv是由多个业务团体提供的,格式上可能缺乏标准化。让我们看一个简单的例子,理解post-hook是如何派上用场的。
我们有一个seed文件,包含新旧产品的名称映射,在中间层模型连接引用。我们希望确保列中的值都转换为小写,因为这是编码格式约定,要做的是在seed的.yml配置文件中添加post-hook和相关的SQL语句:
version: 2seeds:- name: seed_product_namesconfig:post-hook: "CREATE OR REPLACE TABLE prod_database.team_private_schema.seed_product_names AS SELECT LOWER(old_product_name) AS old_product_name, LOWER(new_product_name) as new_product_name FROM prod_database.team_private_schema.seed_product_names;"description: >This seed contains all product names (old and new versions)columns:- name: old_product_namedescription: The old product name used in previous platformtype: string- name: new_product_namedescription: The new product name used in current platformtype: string
dbt seed命令运行后,执行post-hook中的SQL,将dbt seed刚刚构建的模型替换为遵循约定的重新格式化版本。
很明显,我们可以在添加至seed之前直接格式化CSV文件:然而添加格式规则在SQL不仅能给你更多的质量控制能力,也会提高文档描述,因为格式化内容在SQL和描述中已清晰地说明。
或许有人认为这种重新格式化SQL操作,可以通过构建从seed获取数据的staging模型表来实现。虽然这显然是可行的,但它违背了将这些“规范”映射CSV文件存储和记录为dbt seed的约定。
同样与dbt模型一样,post-hook可以用于各种数据操作常见(例如,在seed中连接字符串创建新列,截取或替换字符串等),这些都可以通过SQL语句实现。
总结
本文通过提供在模型和种子级别上使用post-hook的具体示例,展示了dbt中post-hook的多种应用场景。这些示例演示了post-hook如何用于复制表、限制返回记录和重新格式化数据。总之,通过使用post-hooks,用户可以更好地控制数据质量并提升模型文档。期待您的真诚反馈,更多内容请阅读数据分析工程专栏。
相关文章:

DBT hook 实战教程
本文将介绍dbt中在模型和seed级别使用post-hook的几个具体示例。dbt中的Post-hooks是一个强大而简单的特性,它在构建模型之后(如果是pre-hook,甚至在此之前)执行SQL语句。这些语句实际上(几乎)可以是任何东西,从将表复制到另一个数据库/模式&…...

SpringBoot整合JPA详解
SpringBoot版本是2.0以上(2.6.13) JDK是1.8 一、依赖 <dependencies><!-- jdbc --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jdbc</artifactId></dependency><!--…...

【微服务】springboot 实现动态修改接口返回值
目录 一、前言 二、动态修改接口返回结果实现方案总结 2.1 使用反射动态修改返回结果参数 2.1.1 认识反射 2.1.2 反射的作用 2.1.3 反射相关的类 2.1.4 反射实现接口参数动态修改实现思路 2.2 使用ControllerAdvice 注解动态修改返回结果参数 2.2.1 注解…...

【前端开发入门】html快速入门
目录 引言一、html基础模板内容二、html文档流三、html 标签1.块级元素2.行内元素3.功能性元素4.标签嵌套 四、html编码习惯五、总结 引言 本系列教程旨在帮助一些零基础的玩家快速上手前端开发。基于我自学的经验会删减部分使用频率不高的内容,并不代表这部分内容不…...

python配置环境变量
方法一:首先卸载重新安装,在安装时勾选增加环境变量 方法二:我的电脑-属性-高级系统配置 手动添加环境变量,路径为python的安装路径 检查:查看环境变量是否安装成功 安装第三方lib winr,输入cmd pip ins…...

从0到1:培训机构排课小程序开发笔记一
业务调研 随着人们生活水平的提高,健康意识和学习需求日益增强,私教、健身和培训机构的市场需求迅速增长。高效的排课系统不仅可以提升机构的管理效率,还能提高学员的满意度。解决传统的排课方式存在的时间冲突、信息不对称、人工操作繁琐等…...

方法重载(Overload)
前言 在前面的学习中,我们学到了重写(Override),这里我们主要进行重载(Overload)的介绍,同时对重写和重载的区别进行分析。 1. 重载(Overload) #方法重载 在同一个类中定义多个同名但参数不同的方法。我们称方法与方法之间构成方法重载 在Java中&…...

[论文笔记]SGPT: GPT Sentence Embeddings for Semantic Search
引言 解码器Transformer的规模不断壮大,轻松达到千亿级参数。同时由于该规模,基于提示或微调在各种NLP任务上达到SOTA结果。但目前为止解码器Transformer还无法应用在语义搜索或语句嵌入上。 为了简单,下文中以翻译的口吻记录,比…...

基于微信小程序的旅游拼团系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

富格林:警悟可信经验安全投资
富格林指出,黄金具有不错的投资价值,一直以来备受投资者的喜爱,近年来大家也纷纷加入现货黄金市场为己增值财富。但是要为投资安全护航的前提,是需要投资者使用合适可信的方法以及掌握相对应的投资技巧。下面富格林将总结以下可信…...

【Linux】使Ubuntu自适应窗口大小并与主机共享文件
LInux虚拟机版本ubuntu-20.04.6,VM版本VMware Workstation 17 Pro VMware Tools™ 是一组服务和模块,是VMware公司在其虚拟化平台中提供的一套工具集,旨在提高虚拟机的性能和稳定性。它们支持 VMware 产品中的多种功能特性,有助于…...

C++ 语言特性18 - static_assert 介绍
一:概述 在 C 中,static_assert 是一种用于在编译时进行断言的机制,确保某些编译时条件成立。如果条件不成立,则编译器会生成错误,阻止代码的编译。static_assert 在 C11 中引入,目的是帮助程序员在编译时捕…...

centos 7.9系统redis6.2.6哨兵模式部署
由于系统需要处理大量的数据并发请求,所以借助于Redis的高性能,可以有效提升整个系统的处理效率。这里采用redis6.2版本源码编译部署哨兵模式,提高整个系统的可用性,避免单点故障。 1. Redis基本环境安装 centos7安装redis 6.2.6 采用源码编译方式安装。 服务器主机名:…...

编程基础:详解 C++ 中的 `std::sort` 函数
编程基础:详解 C 中的 std::sort 函数 在C编程中,排序是非常常见的操作,而std::sort是C标准库中用于排序的一个高效函数。它提供了灵活的排序功能,可以使用默认排序规则或自定义的比较函数。本文将深入探讨std::sort的用法、参数要…...

51单片机的宠物自动投喂系统【proteus仿真+程序+报告+原理图+演示视频】
1、主要功能 该系统由AT89C51/STC89C52单片机LCD1602显示模块温湿度传感器DS1302时钟模块蓝牙步进电机按键、蜂鸣器等模块构成。适用于猫猫/狗狗宠物自动喂食器等相似项目。 可实现基本功能: 1、LCD1602实时显示北京时间和温湿度 2、温湿度传感器DHT11采集环境温湿度 3、时…...

MongoDB快速实战与基本原理
目录 链接:https://note.youdao.com/ynoteshare/index.html?id=5e038498891617c552667b853742fdc1&type=note&_time=1727935558812 Mongo数据库的特点: mongo数据库和关系型数据库的区别: 编辑 关系型数据库和文档型数据库的主要概念对比: 下载和启动(具体…...

编程技巧:优化
第一种:构造回文串---构造法 题目描述 [NOIP2016 普及组] 回文日期 - 洛谷 那么这道题我们总结一些题目要求: 1.输入两个字符串,为起始和终止日期 2.年份不会出现前导0 3.如果是回文日期,答案1 4.如果月份是2,要…...

pycharm中使用anaconda创建多环境,无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称
问题描述 用的IDE是: 使用anaconda创建了一个Python 3.9的环境 结果使用pip命令的时候,报错 无法将“pip”项识别为 cmdlet、函数、脚本文件或可运行程序的名称 解决方案 为了不再增加系统变量,我们直接将变量添加在当前项目中你的Ter…...
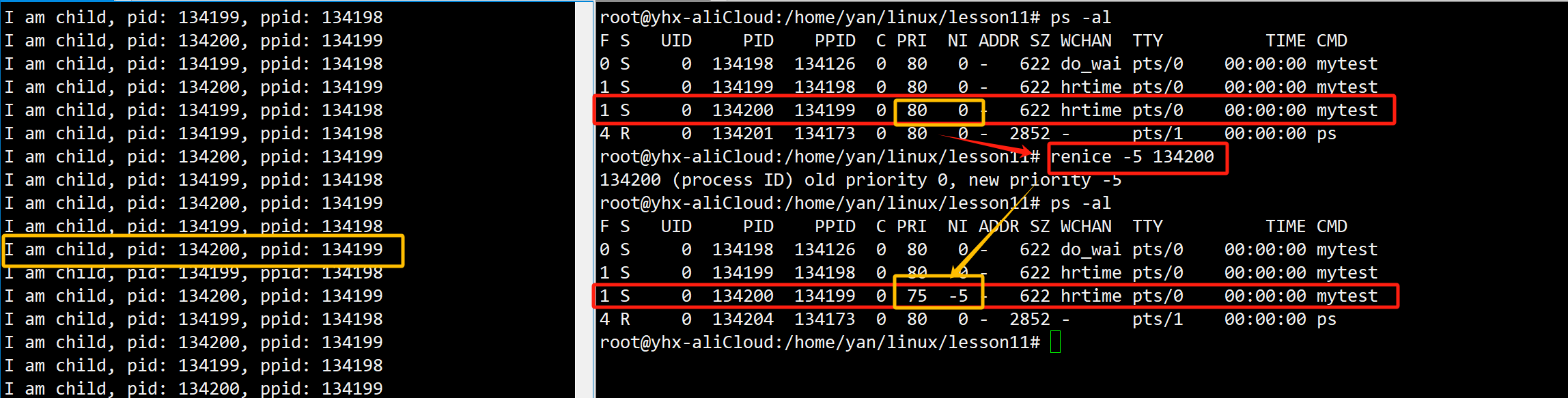
【Linux】进程周边之优先级
目录 一、优先级 1.为什么要有进程优先级? 2.什么是进程优先级? 3.优先级的初始设定 3.1 PRI 和 NI 3.2如何修改优先级?(sudo/root) 3.2.1 概念: 3.2.2 如何查看进程的优先级? 3.3.3 或…...

Linux高级编程_29_信号
文章目录 进程间通讯 - 信号信号完整的信号周期信号的编号信号的产生发送信号1 kill 函数(他杀)作用:语法:示例: 2 raise函数(自杀)作用:示例: 3 abort函数(自杀)作用:语法:示例: 4 …...

Unity PC端软键盘唤醒实战:Windows osk.exe兼容性攻坚
1. 这不是“调个API”就能解决的事:PC端软键盘唤醒的现实困境Unity项目上线前一周,测试同事在Windows台式机上点开登录框,手指悬在键盘上方三秒——没反应。他下意识摸了摸键盘,又点了一次输入框,还是没弹出任何软键盘…...

办公效率翻倍!OpenClaw AI 数字员工实操教程
适配系统:Windows 10 64位(新手专享版) 产品亮点: 零门槛安装:无需命令行操作,免去复杂环境配置即开即用:解压即安装,内置完整运行环境可视化操作:全程图形界面&#x…...

通过Taotoken用量看板清晰掌握各模型调用成本与消耗趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰掌握各模型调用成本与消耗趋势 在将大模型能力集成到实际项目时,除了关注功能实现࿰…...

MapStruct实战:手把手教你处理SpringBoot API中的字段名不一致问题
MapStruct实战:SpringBoot API字段名不一致的优雅解决方案 在SpringBoot开发中,前后端数据交互时经常遇到字段命名规范不一致的问题。数据库使用user_name,前端却要求userName;或者需要隐藏敏感字段如password,转换成*…...

Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节
Python操控AB PLC避坑指南:pylogix读写数组、字符串和UDT的实战细节 当工业自动化遇上Python,pylogix库成为了连接AB PLC与Python世界的桥梁。但在处理数组、字符串和用户自定义数据类型(UDT)时,即便是经验丰富的开发…...

AI 变频调速水泵智能功率 MOSFET 完整选型方案
2026年,AI技术在智能水务及工业泵控系统深度渗透(如预测性维护、能效优化、智能流量调节),变频器对功率 MOSFET 提出更高要求:高效节能、高可靠性、快速响应。微碧半导体(VBsemi)基于先进的 Tre…...

蓝桥杯嵌入式第十届真题复盘:从CubeMX配置到EEPROM读写,我是如何一步步踩坑又爬出来的
蓝桥杯嵌入式第十届真题实战复盘:从CubeMX配置到EEPROM读写的深度解析 去年参加蓝桥杯嵌入式比赛的经历,至今回想起来仍让我心有余悸。第十届真题中的LED模块和EEPROM读写部分,堪称"嵌入式开发者的噩梦"。记得当时在实验室熬到凌晨…...
)
别再死记硬背了!用‘榨汁机’和‘张三的饭量’搞定高数函数定义域(附3类题型解法)
用生活化思维破解高数函数定义域:从榨汁机到张三的饭量 第一次翻开高等数学教材时,那些密密麻麻的函数符号让我头晕目眩。直到有一天,我在厨房榨果汁时突然顿悟——原来函数就像一台榨汁机,而定义域不过是张三在不同状态下的饭量。…...

【从零学Vibe Coding】第一章:Vibe Coding 到底是什么?
第一章:Vibe Coding 到底是什么? 先说结论 Vibe Coding 不是"不写代码",而是"先用自然语言描述意图,再让 AI 生成代码,人类负责判断、修正和推进结果"。 这个词在 2025 年突然出圈,不…...
)
Logisim新手避坑指南:手把手搞定头歌平台偶校验解码电路(附完整data.circ文件配置)
Logisim新手避坑指南:手把手搞定头歌平台偶校验解码电路 第一次打开Logisim时,那个简陋的界面和密密麻麻的逻辑门可能会让你望而生畏。更不用说还要在头歌平台上完成偶校验解码电路的评测——光是看到"找不到GB2312ROM.circ"的报错就足以让大多…...