论文阅读:Attention is All you Need
Abstract
贡献:
提出了Transformer,完全基于注意力机制,摒弃了循环和卷积网络。
结果:
本模型在质量上优于现有模型,同时具有更高的并行性,并且显著减少了训练时间。
1. Introduction
- long short-term memory(LSTM)——长短期记忆网络
- gated recurrent neural networks——门控循环神经网络
循环模型通常沿着输入和输出序列的符号位置来分解计算。通过将位置与计算时间步骤对齐,它们生成一系列隐藏状态 ht,作为前一个隐藏状态 ht−1 和位置 t 的输入的函数。
Transformer完全摒弃循环网络、完全依赖注意力机制来捕捉输入和输出之间全局依赖关系的模型架构。
显著允许增加并行化。
2. Background
减少序列计算。
- Extended Neural GPU
- ByteNet
- ConvS2S
在这些模型中,关联任意两个输入或输出位置信号所需的操作次数随着位置之间的距离而增加。
Self-attention,是一种通过关联同一序列中不同位置来计算该序列表示的注意力机制。
End-to-end memory networks,基于一种循环注意力机制,而不是与序列对齐的循环网络。
Transformer是第一个完全依赖自注意力来计算输入和输出表示的转换模型,没有使用与序列对齐的RNN或卷积网络。
3. Model Architecture
编码器输入x,输出z;解码器输入z,输出y。
在每一步,模型都是自回归的,在生成下一步时,使用先前生成的符号作为附加输入。
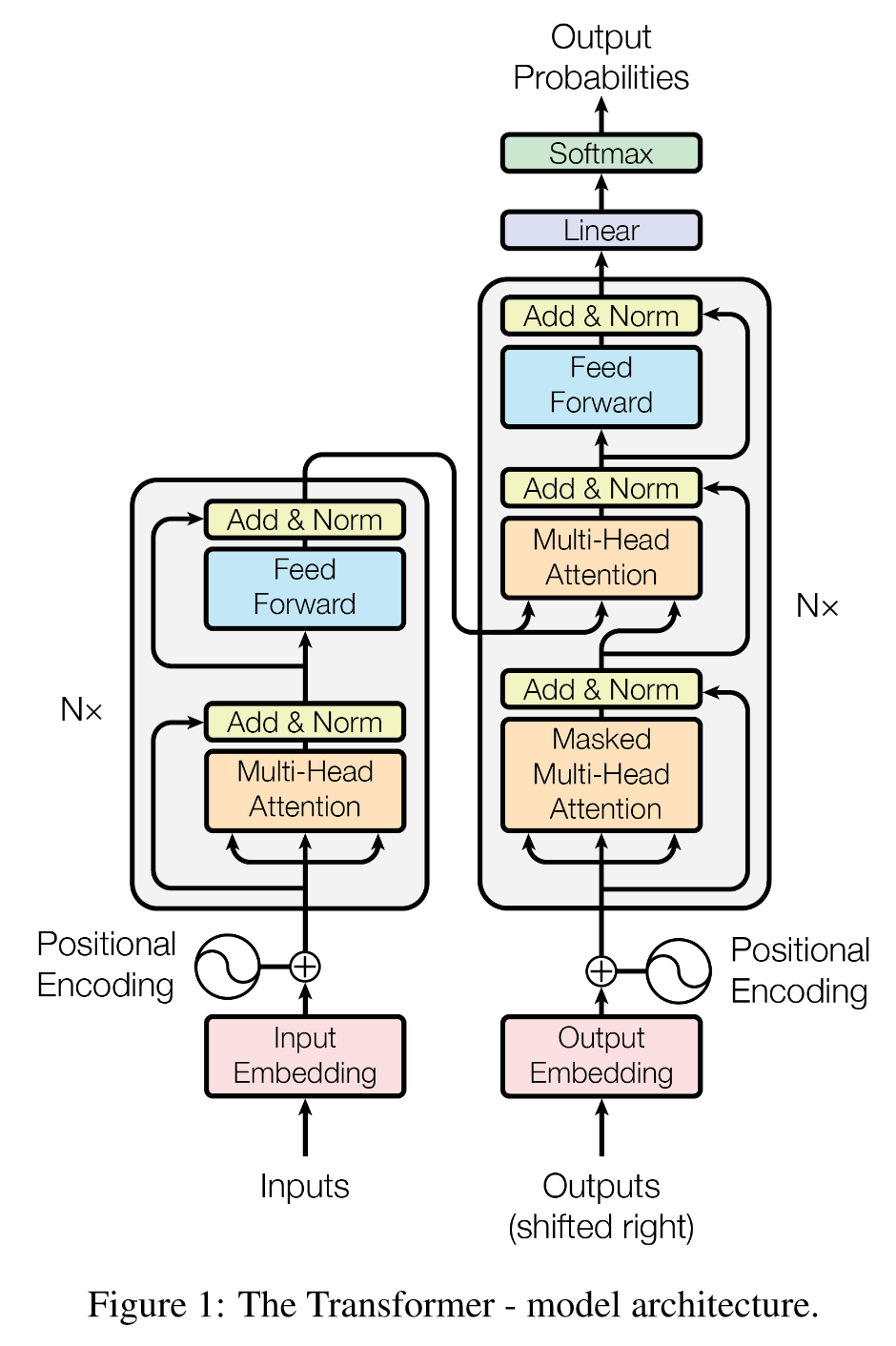
3.1 Encoder and Decoder Stacks
编码器:
N=6,每个两层。
第一层,多头自注意力机制;
第二层,逐位置全连接前馈网络。
残差连接,层归一化,即:LayerNorm(x + Sublayer(x))。
维度 d m o d e l = 512 d_{model} = 512 dmodel=512。
解码器:
N=6,每个三层。
二三层同上。
第一层,掩码多头自注意力机制。
这种掩码机制结合输出嵌入偏移一个位置,确保位置 i 的预测只能依赖于位置 i 之前已知的输出。
3.2 Attention
注意力函数可以描述为将查询(query)和一组键-值对(key-value pairs)映射到一个输出,其中查询、键、值和输出都是向量。
输出是根据值(value)的 加权和 计算得到的,权重是通过查询(query)与相应键(key)之间的兼容性函数计算得出的。
3.2.1 Scaled Dot-Product Attention——缩放点积注意力
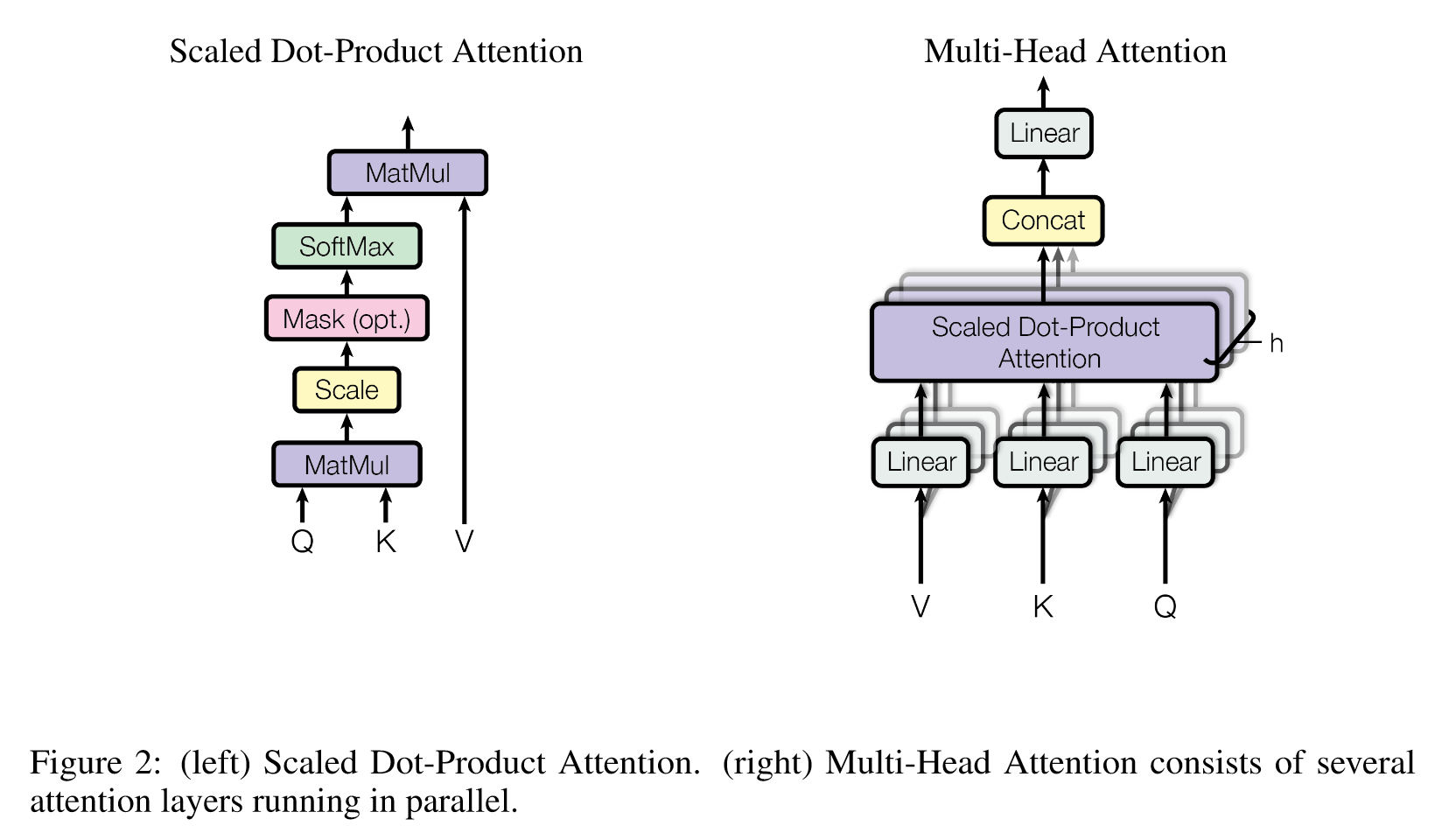
输入由维度为 dk 的查询和键以及维度为 dv 的值组成,计算查询与所有键的点积,将每个点积除以 d k \sqrt{d_k} dk,并应用 softmax 函数以获得值的权重。
在实际应用中,会同时对一组查询计算注意力函数,使用矩阵计算。
输出矩阵:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
- 加性注意力
- 点积注意力
对于较大的 dk 值,如果没有缩放,点积的数值可能会变得很大,从而将 softmax 函数推入梯度极小的区域,所以缩放 d k \sqrt{d_k} dk 。
为什么选择 d k \sqrt{d_k} dk 而不是其他数,这与点积结果的统计性质有关。


3.2.2 Multi-Head Attention
h=8,dk=dv=dmodel/h=64
将查询、键和值分别线性投影为 dk、dk 和 dv 维度的 h 次不同的线性投影。
在这些投影后的查询、键和值上并行执行注意力函数,得到 dv 维度的输出值。
输出拼接起来,并再次投影,得到最终的输出值。
多头注意力允许模型在不同的位置上同时关注来自不同表示子空间的信息。
多头注意力公式:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , … , h e a d h ) W O MultiHead(Q, K, V) = Concat(head_1, \dots, head_h) W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
第 i 个头的注意力为:
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i = Attention(Q W^Q_i, K W^K_i, V W^V_i) headi=Attention(QWiQ,KWiK,VWiV)
投影矩阵分别为:
W i Q ∈ R d m o d e l × d k , W i K ∈ R d m o d e l × d k , W i V ∈ R d m o d e l × d v , W O ∈ R h d v × d m o d e l . W^Q_i \in \mathbb{R}^{d_{model} \times d_k}, \quad W^K_i \in \mathbb{R}^{d_{model} \times d_k}, \quad W^V_i \in \mathbb{R}^{d_{model} \times d_v}, \quad W^O \in \mathbb{R}^{h d_v \times d_{model}}. WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,WO∈Rhdv×dmodel.
3.2.3 Applications of Attention in our Model
编码器-解码器注意力层:
查询来自前一层的解码器,键和值来自编码器的输出。
编码器自注意力层:
键、值和查询全部来自同一个地方,它们都来自编码器中前一层的输出。
解码器自注意力层:
允许解码器中的每个位置关注解码器中该位置及之前的所有位置。
需要阻止解码器中的左向信息流动。
3.3 Position-wise Feed-Forward Networks——按位置的前馈网络
编码器和解码器中的每一层还包含一个全连接的前馈网络。
该网络由两次线性变换构成,中间使用 ReLU 激活函数:
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
线性变换在不同位置之间是相同的,但它们在不同层次之间使用不同的参数。
另一种描述方式是将其看作两个卷积,卷积核大小为1。输入和输出的维度为 dmodel=512,而内部层的维度为 dff=2048。
3.4 Embeddings and Softmax——嵌入和Softmax
使用学习到的嵌入(embeddings)来将输入标记(tokens)和输出标记转换为dmodel维的向量。
使用常规的线性变换和 Softmax 函数将解码器的输出转换为预测的下一个标记的概率。
在两个嵌入层和 Softmax 之前的线性变换中共享相同的权重矩阵。
在嵌入层中,将这些权重乘以 d m o d e l \sqrt{d_{model}} dmodel 。
3.5 Positional Encoding——位置编码
在编码器和解码器堆栈的底部将“位置编码”添加到输入嵌入中。
位置编码的维度与嵌入相同,均为 dmodel,这样两者可以相加。
位置编码使用不同频率的正弦和余弦函数:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d m o d e l ) PE(pos, 2i) = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{model}}}}\right) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d m o d e l ) PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{model}}}}\right) PE(pos,2i+1)=cos(10000dmodel2ipos)
pos 是位置,i 是维度。
位置编码的每个维度都对应于一个正弦波。
对于任何固定的偏移量 k,位置 P E p o s + k PE_{pos+k} PEpos+k 可以表示为位置 P E p o s PE_{pos} PEpos 的线性函数。
4. Why Self-Attention
自注意力层与
将一个可变长度的符号表示序列(x1, …, xn)映射到另一个等长度的序列(z1, …, zn)的循环层和卷积层
进行比较。
- 总计算复杂度
- 并行化的计算量
- 长距离依赖的路径长度
学习长距离依赖,一个关键因素是前向和后向信号在网络中必须穿过的路径长度。输入和输出序列中任意位置组合之间的这些路径越短,学习长距离依赖就越容易。
比较了由不同类型层组成的网络中任意两个输入和输出位置之间的最大路径长度。

在计算复杂度方面,当序列长度n小于表示维度d时,自注意力层比循环层更快。
为了提高涉及非常长序列的任务的计算性能,自注意力可以限制为仅考虑输入序列中以相应输出位置为中心的、大小为r的邻域。这将使最大路径长度增加到O(n/r)。
具有核宽度k < n的单个卷积层不会连接所有输入和输出位置对。在连续核的情况下,这需要堆叠O(n/k)个卷积层;在膨胀卷积的情况下,则需要O(logk(n))个卷积层。
不仅单个注意力头明显学会了执行不同的任务,而且许多注意力头似乎表现出与句子句法和语义结构相关的行为。
可分离卷积大大降低了复杂度,降至O(k · n · d + n · d^2)。
5. Training
5.1 Training Data and Batching
- WMT 2014英德数据集
- 每个训练批次包含一组句子对,其中包含大约25,000个源标记和25,000个目标标记。
5.2 Hardware and Schedule
- 8个NVIDIA P100 GPU
- 基础模型训练了100,000个步骤,12小时
- 大型模型训练了300,000个步骤,3.5天
5.3 Optimizer
- Adam优化器
- β 1 = 0.9 \beta_1 = 0.9 β1=0.9、 β 2 = 0.98 \beta_2 = 0.98 β2=0.98 和 ϵ = 1 0 − 9 \epsilon = 10^{-9} ϵ=10−9
学习率公式:
l r a t e = d model − 0.5 ⋅ min ( step_num − 0.5 , step_num ⋅ warmup_steps − 1.5 ) lrate = d_{\text{model}}^{-0.5} \cdot \min(\text{step\_num}^{-0.5}, \text{step\_num} \cdot \text{warmup\_steps}^{-1.5}) lrate=dmodel−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)
对应于在前 w a r m u p _ s t e p s warmup\_steps warmup_steps 个训练步骤中线性增加学习率,此后按步数的平方根倒数比例减少学习率。
设置 w a r m u p _ s t e p s = 4000 warmup\_steps = 4000 warmup_steps=4000 。
5.4 Regularization
三种正则化方法:
残差 Dropout:
每个子层的输出加入残差并进行归一化之前应用 dropout。
编码器和解码器堆栈中的嵌入和位置编码的和上应用 dropout。
dropout 率为 P d r o p = 0.1 P_{drop} = 0.1 Pdrop=0.1
标签平滑:
值为 ϵ l s = 0.1 \epsilon_{ls} = 0.1 ϵls=0.1。
影响困惑度,因为模型会学得不那么确定,但能提高准确度和 BLEU 分数。
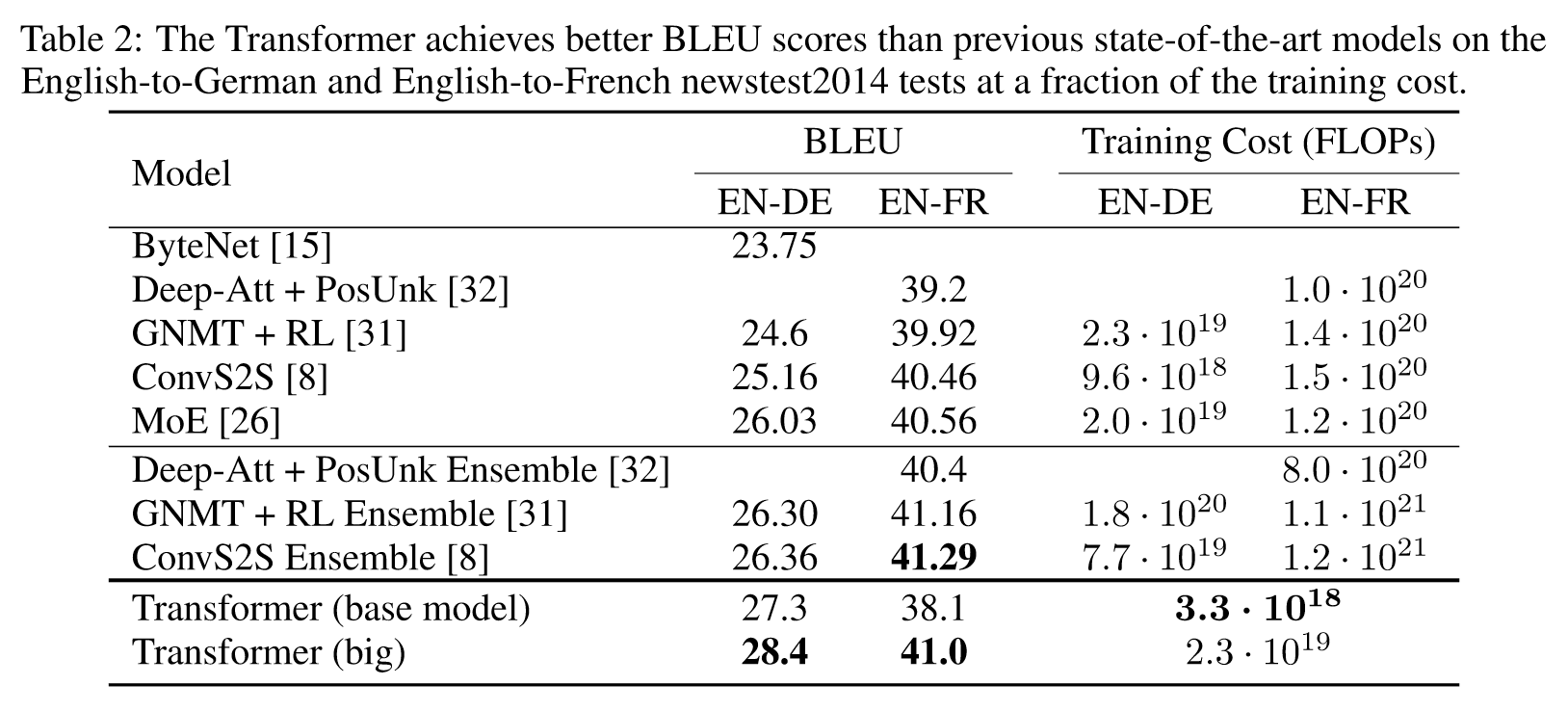
6. Results
6.1 Machine Translation
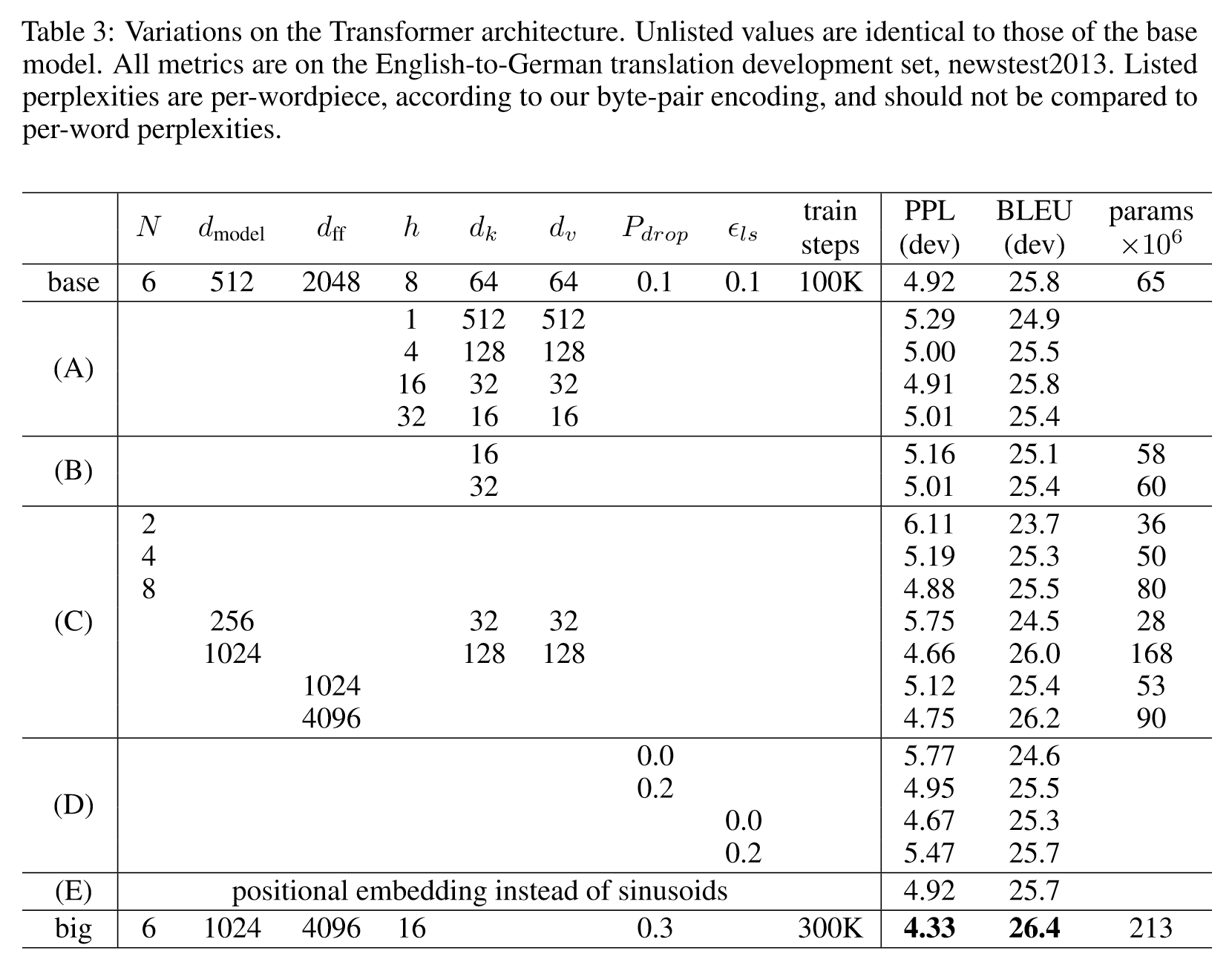
6.2 Model Variations
7. Conclusion
Transformer,这是第一个完全基于注意力机制的序列转换模型,它用多头自注意力替代了在编码器-解码器架构中最常用的循环层。
计划将 Transformer 扩展到涉及文本以外的输入和输出模式的问题中,并研究局部、受限的注意力机制,以便高效处理如图像、音频和视频等大型输入和输出。减少生成过程的顺序性也是研究目标之一。
相关文章:
论文阅读:Attention is All you Need
Abstract 贡献: 提出了Transformer,完全基于注意力机制,摒弃了循环和卷积网络。 结果: 本模型在质量上优于现有模型,同时具有更高的并行性,并且显著减少了训练时间。 1. Introduction long short-term …...

【Linux 】文件描述符fd、重定向、缓冲区(超详解)
目录 编辑 系统接口进行文件访问 open 接口介绍 文件描述符fd 重定向 缓冲区 1、缓冲区是什么? 2、为什么要有缓冲区? 3、怎么办? 我们先来复习一下,c语言对文件的操作: C默认会打开三个输入输出流…...

Unity WebGL使用nginx作反向代理处理跨域,一些跨域的错误处理(添加了反向代理的配置依旧不能跨域)
反向代理与跨域描述 什么是跨域? 跨域(Cross-Origin Resource Sharing, CORS)是指在浏览器中,当一个网页的脚本试图从一个域名(协议、域名、端口)请求另一个域名的资源时,浏览器会阻止这种请求…...

视频转文字免费的软件有哪些?6款工具一键把视频转成文字!又快又方便!
视频转文字免费的软件有哪些?在视频制作剪辑过程中,我们经常进行视频语音识别成字幕,帮助我们更好地呈现视频内容的观看和宣传,市场上有许多免费的视频转文字软件,可以快速导入视频,进行视频内音频的文字转…...

解决DHCP服务异常导致设备无法获取IP地址的方法
DHCP在网络环境中会自动为网络中的设备分配IP地址和其他关键网络参数,可以简化网络配置过程。但是,如果DHCP服务出现异常时,设备可能无法正常获取IP地址,会影响到网络通信。 本文讲述一些办法可以有效解决DHCP服务异常导致设备无法…...

Python机器学习模型的部署与维护:版本管理、监控与更新策略
🚀 Python机器学习模型的部署与维护:版本管理、监控与更新策略 目录 💼 模型版本管理 使用DVC进行数据和模型的版本控制,确保可复现性 🔍 监控与评估 部署后的模型性能监控,使用Prometheus和Grafana进行实…...

免费送源码:Java+ssm+JSP+Ajax+MySQL SSM汽车租赁管理系统 计算机毕业设计原创定制
摘 要 信息化社会内需要与之针对性的信息获取途径,但是途径的扩展基本上为人们所努力的方向,由于站在的角度存在偏差,人们经常能够获得不同类型信息,这也是技术最为难以攻克的课题。针对汽车租赁信息管理等问题,对其进…...

Vivado viterbi decoder license
Viterbi Decoder 打卡以上链接 添加后next后, 会发送lic文件到邮件,vivado导入lic即可...

【FastAdmin】PHP的Trait机制:代码复用的新选择
PHP的Trait机制:代码复用的新选择 大家好,我是田辛老师。最近收到很多同学的私信,询问关于PHP中Trait机制的相关问题。今天,我们就来详细探讨一下这个强大的代码复用工具,以及它在ThinkPHP 5(简称Tp5&…...

小红书制作视频如何去原视频音乐,视频如何去原声保留背景音乐?
在视频编辑、音乐制作或个人娱乐中,有时我们希望去掉视频中的原声(如对话、解说等),仅保留背景音乐。这种处理能让观众更加聚焦于视频的氛围或节奏,同时也为创作者提供了更多创意空间。选择恰当的背景音乐,…...

netty之Netty使用Protobuf传输数据
前言 在netty数据传输过程中可以有很多选择,比如;字符串、json、xml、java对象,但为了保证传输的数据具备;良好的通用性、方便的操作性和传输的高性能,我们可以选择protobuf作为我们的数据传输格式。目前protobuf可以支…...

【力扣 | SQL题 | 每日四题】力扣2082, 2084, 2072, 2112, 180
四题都比较简单,可以直接秒。 1. 力扣2082:富有客户的数量 1.1 题目: 表: Store ------------------- | Column Name | Type | ------------------- | bill_id | int | | customer_id | int | | amount | int | -------------…...

快速了解Java中的15把锁!
目录 了解 总览 乐观锁 悲观锁 互斥锁和同步锁 公平锁 非公平锁 自旋锁 可重入锁(递归锁) ReadWriteLock读写锁 共享锁 独占锁 偏向锁 轻量级锁 重量级锁 锁优化 在 Java 中,锁是一种用于实现多线程之间同步和互斥的机制。 了…...

TypeScript 封装 Axios 1.7.7
随着Axios版本的不同,类型也在改变,以后怎么写类型? yarn add axios1. 封装Axios 将Axios封装成一个类,同时重新封装request方法 重新封装request有几个好处: 所有的请求将从我们定义的requet请求中发送ÿ…...

【数据结构】【链表代码】移除链表元素
移除链表元素 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/struct ListNode* removeElements(struct ListNode* head, int val) { // 创建一个虚拟头节点,以处理头节点可能被删除的情况 struct…...

作文-杭州游记
杭州的学习与游历 在这个风景如画的城市——杭州,学习信息学的日子如同西湖的水,清澈而又深邃。在这里,课堂与自然的交融、技术与文化的碰撞,构成了一幅独特的画卷。 学习之旅 信息学的课程不仅仅是对代码和算法的解析࿰…...

降压芯片TPS54821
降压芯片TPS54821 介绍 价格低廉,只需1.5元。是一个同步整流降压BUCK电路。MOS管内置。输入电压为4.5V至17V,输出电压为0.6V到15V,输出电流最大到8A。是QFN封装,焊接时有些许困难。得益于QFN封装,其引线电感非常的小…...

YOLO v1详解解读
🚀 在此之前主要介绍了YOLO v5源码的安装和使用(YOLO v5安装教程),接下来将探索YOLO的实现原理,作为一个金典的单阶段目标检测算法,应该深度的理解它的构建思想;所以本系列文章将从LOVO v1出发到…...

【动态规划-最长公共子序列(LCS)】【hard】【科大讯飞笔试最后一题】力扣115. 不同的子序列
给你两个字符串 s 和 t ,统计并返回在 s 的 子序列 中 t 出现的个数,结果需要对 10^9 7 取模。 示例 1: 输入:s “rabbbit”, t “rabbit” 输出:3 解释: 如下所示, 有 3 种可以从 s 中得到 “rabbit”…...

深入理解 JavaScript 中的 void`运算符和 yield*表达式
深入理解 JavaScript 中的 void 运算符和 yield* 表达式 在 JavaScript 中,void 运算符和 yield* 表达式是两个功能独特但常被忽视的运算符。本文将详细介绍它们的用法和应用场景,帮助您更好地理解和运用这两个运算符。 目录 void 运算符概述void 运算…...

不止VSIN!Cadence PSpice仿真库SOURCE.OLB里还有哪些宝藏信号源?实战对比与选型指南
不止VSIN!Cadence PSpice仿真库SOURCE.OLB里还有哪些宝藏信号源?实战对比与选型指南 在电路仿真设计中,信号源的选择往往决定了仿真结果的准确性与实用性。许多工程师对PSpice中的VSIN元件较为熟悉,却忽略了SOURCE.OLB库中其他丰富…...

Python技能安装器设计:从虚拟环境到CLI的自动化部署实践
1. 项目概述:一个技能安装器的诞生在开源社区里,我们经常遇到一些“小而美”的工具或脚本,它们能解决特定场景下的痛点,但往往缺乏一个统一的、便捷的安装和管理入口。用户需要手动克隆仓库、检查依赖、配置环境变量,甚…...

终极指南:如何用Snipe-IT免费开源系统解决企业IT资产追踪难题
终极指南:如何用Snipe-IT免费开源系统解决企业IT资产追踪难题 【免费下载链接】snipe-it A free open source IT asset/license management system 项目地址: https://gitcode.com/GitHub_Trending/sn/snipe-it 想象一下,你的公司有500台笔记本电…...

瑞萨RL78/G16开发板与EZ-CUBE3仿真器连接调试全攻略
1. 项目概述与核心价值 最近在折腾瑞萨的RL78系列MCU,手头正好有一块RL78/G16的快速原型开发板和一个EZ-CUBE3仿真器。对于刚接触瑞萨生态的朋友来说,如何把这套硬件正确地连接起来,并成功跑通第一个LED闪烁程序,往往是入门路上的…...

5分钟掌握全平台炫酷抽奖:Magpie-LuckyDraw开源项目深度解析
5分钟掌握全平台炫酷抽奖:Magpie-LuckyDraw开源项目深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https://gitcode.com/gh_mirrors/ma…...

OpenWrt防火墙深度解析:从区域模型到多网络隔离实战
1. 项目概述:从“看门人”到“交通警察”如果你玩过OpenWrt,或者任何软路由系统,那你一定对“防火墙”这个词不陌生。在大多数人的第一印象里,它就是个“看门人”——决定哪些数据包能进,哪些不能进。这个理解没错&…...

SoC与SoM:硬件开发的效率革命与双刃剑效应
1. 项目概述:当“系统”成为商品从业十几年,从画第一块51单片机的板子,到参与设计复杂的通信基站,我亲眼见证了硬件开发模式的剧变。如果说早些年我们还在为如何把CPU、内存、Flash、各种接口控制器塞进一块PCB而绞尽脑汁…...

三分钟搞定全网音乐歌词:双平台智能歌词下载工具完全指南
三分钟搞定全网音乐歌词:双平台智能歌词下载工具完全指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到心爱歌曲的歌词而烦恼吗?无…...

DuClaw智能体:使用手册
学习并使用技能DuClaw 在创建时已为您预置部分常用技能,可根据任务需求自动匹配调用。查看已有技能1.进入对话界面,单击“技能平台”按钮,并在弹窗中单击“查看我的技能”。2.DuClaw会回复您当前已安装的技能以及相应的技能信息。安装并使用技…...

Threadline MCP:基于消息协议的线程管理与任务编排框架解析
1. 项目概述:从“Threadline MCP”看现代应用架构的线程管理革新最近在GitHub上看到一个挺有意思的项目,叫“vidursharma202-del/threadline-mcp”。光看这个名字,可能有点摸不着头脑,但拆解一下,“threadline”直译是…...