专题十_穷举vs暴搜vs深搜vs回溯vs剪枝_二叉树的深度优先搜索_算法专题详细总结
目录
搜索 vs 深度优先遍历 vs 深度优先搜索 vs 宽度优先遍历 vs 宽度优先搜索 vs 暴搜
1.深度优先遍历 vs 深度优先搜索(dfs)
2.宽度优先遍历 vs 宽度优先搜索(bfs)
2.关系图暴力枚举一遍所有的情况
3.拓展搜索问题全排列
决策树
1. 计算布尔⼆叉树的值(medium)
解析:
1.函数头
2.函数体
3.函数出口
总结:
2. 求根节点到叶节点数字之和(medium)
解析:编辑
总结:
3. ⼆叉树剪枝(medium)
总结:
4. 验证⼆叉搜索树(medium)
解析:
策略一:中序遍历,判断这个二叉树是否有序
策略二:剪枝
总结:
5. ⼆叉搜索树中第 k ⼩的元素(medium)
解析:
总结:
6. ⼆叉树的所有路径(easy)
解析:
总结:
穷举vs暴搜vs深搜vs回溯vs剪枝
什么是回溯算法
7. 全排列(medium)
解析:
1)暴力枚举:
2)递归优化:
2.设计代码:
全局变量
dfs函数
细节问题
总结:
8. ⼦集(medium)
解析:
解法一:
1.决策树
2.设计代码
全局变量
dfs
解法二:
1.画决策树
2.设计代码
总结:
搜索 vs 深度优先遍历 vs 深度优先搜索 vs 宽度优先遍历 vs 宽度优先搜索 vs 暴搜
1.深度优先遍历 vs 深度优先搜索(dfs)

2.宽度优先遍历 vs 宽度优先搜索(bfs)

那么遍历只是形式,目的是搜索
2.关系图
暴力枚举一遍所有的情况
搜索(暴搜) dfs
3.拓展搜索问题
全排列
决策树

废话不多说,直接进入例题:
1. 计算布尔⼆叉树的值(medium)

解析:
递归函数的调用:
主要就是分三步,当主问题与子问题相同的时候:
1.函数头
2.函数体
3.函数出口

/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:bool a[2]={false,true};bool evaluateTree(TreeNode* root) {if(root->left==nullptr||root->right==nullptr) return a[root->val];bool left=evaluateTree(root->left);bool right=evaluateTree(root->right);return root->val==2?left|right:left&right;}
};总结:
只要能分析出当前问题的相同子函数,就可以得出函数体里面的内容,通过所有相同的子函数的内容进行一步步操作就能完成当前函数的任务。
2. 求根节点到叶节点数字之和(medium)
题意还是比较好理解的,就是对从根节点开始一直到叶子节点,计算每个节点当前值不断*10最后所有叶子节点的和

解析:

这种题目计算每个叶子节点的方法一眼就是dfs,先递归到叶子节点,然后就开始相加。
以下是同一种dfs的两种思想:
1.定义全局变量ret,然后每次递归到叶子节点的时候就开始进行相加,那么我就是用一个字符串s来保存每一层的临时变量,这样可以达到回溯的效果,起始不要字符串保存,只有用presum来存储临时变量也是ok的,都能存的下最终的和,然后每次到叶子节点ret就进行相加,知道加完所有叶子节点的值就完成,返回ret
唯一需要注意的就是,在传入dfs的时候就要立刻加上当前节点的值,这样就不会漏掉当前节点的某一位,因为只要到叶子节点就要开始返回上一层了,为了防止叶子节点的值给漏掉。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int ret=0;int sumNumbers(TreeNode* root) {string s;dfs(root,s);return ret;}void dfs(TreeNode* root,string s){s+=to_string(root->val);if(root->left==nullptr&&root->right==nullptr){ret+=stoi(s);return;}if(root->left) dfs(root->left,s);if(root->right) dfs(root->right,s);}
};2.就是用presum来记录临时变量,不需要字符串到整形,整形到字符串的各种转换,因为最后的结果int也能存下。
看到上面的图,就能看出,如果我存临时变量presum,那么dfs返回的就是当前节点下所有叶子节点的和,那么整个二叉树就都变成了一个子问题,就是要求头节点下所有叶子节点的和。
函数头:int dfs(root,presum);
出口:就是当到达叶子节点的时候,那么就返回当前叶子节点的presum
函数体:用ret来记录当前节点下所有左右子树中,叶子节点的和,在当前节点左子树不为空下,传入dfs(root->left,presum);在当前节点右子树不为空下,传入dfs(root->right,presum);来求出当前节点下的左右子树的所有叶子节点的和
最后返回ret
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int sumNumbers(TreeNode* root) {return dfs(root,0);}int dfs(TreeNode* root,int presum){presum=presum*10+root->val;if(root->left==nullptr&&root->right==nullptr) return presum;int ret=0;//记录当前节点下,所有叶子节点的值if(root->left) ret+=dfs(root->left,presum);if(root->right) ret+=dfs(root->right,presum);return ret; //返回给上一层}
};总结:
像这种带有回溯类的问题,只需要考虑清楚带上的临时变量不会再中途被改变,并且再返回上一层稳定即可。
3. ⼆叉树剪枝(medium)

解析:

因为计算机不可能知道当前节点下左右子树的所有节点是否全为0,所以就要完全遍历到叶子节点在开始判断,判断叶子节点是否为0 如果是就直接置为空,并且返回空,否则就返回当前节点,不改变。
经过上面的思考,发现要先解决完所有的左子树和右子树,然后在考虑当前的节点是否为0,且左右子树是否为空,所以就完全是一个后序遍历。
1.函数头:再前面的分析里面要返回当前节点的情况,是否为空,否则就返回当前节点。说明函数头是带有返回值的。
Node* dfs(root);
2.函数体:
由于是后序遍历,先访问所有左子树,再访问右子树。然后进行判断当前节点
root->left=dfs(root->left);
root->right=dfs(root->right);
判断:如果当前节点的左右子树都为空,并且当前节点值为0,就说明这个节点也可以被删掉
if(root->left==nullptr&&root->right==nullptr&&root->val==0) root=nullptr;
return root;//将当前节点的值,返回给上一层
3.递归出口:当前节点为空的时候就返回空
if(root==nullptr) return nulltpr;
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:TreeNode* pruneTree(TreeNode* root) {if(root==nullptr) return nullptr;root->left=pruneTree(root->left);root->right=pruneTree(root->right);if(root->left==nullptr&&root->right==nullptr&&root->val==0) root=nullptr; return root;//返回给上一层}
};总结:
写的代码很简单,但是要想清楚每一步还是很不容易,多注意细节问题,多思考,一个题目要反复思考才能被吸收。
4. 验证⼆叉搜索树(medium)
题意很简单,只要证明该树是不是二叉搜索树

解析:
策略一:中序遍历,判断这个二叉树是否有序
用prev来记录二叉树的中序的根节点,就是当前节点左子树的最右边的一个节点
要保证该二叉树是平衡二叉树,就要一直保证prev < root->val 那么就能满足条件,一旦打破了就返回false
那么:
1.函数头:bool dfs(root)
2.函数体:
弄弄左子树:bool left=dfs(root->left);
中序判断:bool ret = false;
if(prev<root->val) ret=true;
prev = root->val;弄弄右子树:bool right=dfs(root->right);
3.出口条件:
当节点访问到空的时候,证明没有问题,返回true
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:long prev=LONG_MIN;bool isValidBST(TreeNode* root) {if(root==nullptr) return true;bool left=isValidBST(root->left);bool ret=false;if(root->val>prev) ret=true;prev=root->val;bool right=isValidBST(root->right);return left&&right&&ret;}
};策略二:剪枝
上面策略一是访问了所有的节点,但是如果只要满足有一个节点不满足平衡二叉树的条件,不满足升序,那么就要返回false,不在往后遍历。
那么只需要再判断左子树的时候证明他是false 或者 再判断当前值不满足升序的时候都返回false就能完成剪枝操作,不在往后执行
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:long prev=LONG_MIN;bool isValidBST(TreeNode* root) {if(root==nullptr) return true;bool left=isValidBST(root->left);if(left==false) return false;bool ret=false;if(root->val>prev) ret=true;prev=root->val;if(ret==false) return false;bool right=isValidBST(root->right);return left&&right&&ret;}
};总结:
回溯、剪枝真的没有那么神秘,再递归里面百分之99都要用到回溯,剪枝只是再我们能完成条件之后再考虑优化,我们可以尝试以下剪枝。
5. ⼆叉搜索树中第 k ⼩的元素(medium)

解析:
设置两个全局变量,ret,count,那么当count==k的时候,说明dfs再中序遍历里面已经遇到了k次中序遍历的值,得到了第k小的值
1.函数头:
void dfs(root);
2.函数体:
中序遍历,遍历到第k次时找到第k小的值:
dfs(root->left);
++count; if(count==k) ret=root->val;
dfs(root->right);
3.出口条件:
知道root==nullptr || ret != -1 就return;只要ret被改变就可以进行剪枝
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int ret=-1;int _k;int count=0;int kthSmallest(TreeNode* root, int k) {_k=k;dfs(root);return ret;}void dfs(TreeNode* root){if(root==nullptr||ret!=-1) return;dfs(root->left);if(++count==_k) ret=root->val;dfs(root->right);}
};总结:
这题真的很简单,通过上面的练习,就只需要一次中序遍历就可以得到第k小的值。
6. ⼆叉树的所有路径(easy)

解析:
虽然这题很简单,但只是有这个简单题来突破其他的难题,我们需要考虑到很多细节问题:
回溯 -> 恢复现场 的因果关系,是因为有了回溯才出现的恢复现场,不能本末倒置了。
只要有递归,那么就绝对伴随之回溯,只要有深度优先遍历,就会存在恢复现场。
为了回溯恢复现场的时候,那么就要考虑我们的参数就不能设置为全局变量,只需要把他设置为dfs的参数,那么就不需要对全局变量进行修改或删除。再每一层的临时变量都是存储当前位置的参数,不会被后面递归影响。
再考虑路径值的时候,就只需要考虑前序遍历然后添加到字符串内即可。
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:vector<string> ret;vector<string> binaryTreePaths(TreeNode* root) {string s;dfs(root,s);return ret;}void dfs(TreeNode* root,string s){if(root==nullptr) return;s+=to_string(root->val);if(root->left==nullptr&&root->right==nullptr) ret.push_back(s);else s+="->";dfs(root->left,s);dfs(root->right,s);}
};总结:
这里对于回溯和恢复现场真的有很强的表现,强烈建议深刻理解以下恢复现场时,把参数当作临时变量真的很方便,就不需要自己再进行操作。
穷举vs暴搜vs深搜vs回溯vs剪枝
什么是回溯算法
回溯算法是⼀种经典的递归算法,通常⽤于解决组合问题、排列问题和搜索问题等。回溯算法的基本思想:从⼀个初始状态开始,按照⼀定的规则向前搜索,当搜索到某个状态⽆法前进时,回退到前⼀个状态,再按照其他的规则搜索。回溯算法在搜索过程中维护⼀个状态树,通过遍历状态树来实现对所有可能解的搜索。回溯算法的核⼼思想:“试错”,即在搜索过程中不断地做出选择,如果选择正确,则继续向前搜索;否则,回退到上⼀个状态,重新做出选择。回溯算法通常⽤于解决具有多个解,且每个解都需要搜索才能找到的问题。
void backtrack(vector<int>& path, vector<int>& choice, ...) {// 满⾜结束条件if (/* 满⾜结束条件 */) {// 将路径添加到结果集中res.push_back(path);return;}// 遍历所有选择for (int i = 0; i < choices.size(); i++) {// 做出选择path.push_back(choices[i]);// 做出当前选择后继续搜索backtrack(path, choices);// 撤销选择path.pop_back();}
}其中, path 表⽰当前已经做出的选择, choices 表⽰当前可以做的选择。在回溯算法中,我们需要做出选择,然后递归地调⽤回溯函数。如果满⾜结束条件,则将当前路径添加到结果集中;否则,我们需要撤销选择,回到上⼀个状态,然后继续搜索其他的选择。回溯算法的时间复杂度通常较⾼,因为它需要遍历所有可能的解。但是,回溯算法的空间复杂度较低,因为它只需要维护⼀个状态树。在实际应⽤中,回溯算法通常需要通过剪枝等⽅法进⾏优化,以减少搜索的次数,从⽽提⾼算法的效率。
7. 全排列(medium)

解析:
1)暴力枚举:
两层三层循环还可以枚举,如果要排列100层的数,那简直不可能,只能借助递归来思考。
2)递归优化:
1.画出决策树:越详细越好

2.设计代码:
全局变量
int [][] ret
int [] path
bool [] check 实现剪枝
dfs函数
就需要关系某一个节点在干什么事情
细节问题
回溯:
1.干掉path最后一个元素
2.修改check数组
剪枝
递归出口:遇到叶子节点就直接添加结果
class Solution {
public:vector<vector<int>> ret;vector<int> path;bool check[7];vector<vector<int>> permute(vector<int>& nums) {dfs(nums);return ret;}void dfs(vector<int>& nums){if(path.size()==nums.size()){ret.push_back(path);return;}for(int i=0;i<nums.size();i++){if(check[i]==false){path.push_back(nums[i]);check[i]=true;dfs(nums);path.pop_back();check[i]=false;}}}
};总结:
最重要的就是画出决策树,越细致越好,然后通过决策树来观察代码该如何书写。
8. ⼦集(medium)

解析:
解法一:
1.决策树

2.设计代码
全局变量
vector<vector<int>> ret; //来记录整体传入的子集
vector<int> path; //设置全局变量,来保证传参,然后进行手动删除
dfs
细节问题:剪枝,回溯,递归出口
传入nums后,要考虑当前位置是否选择,分为选择和不选择两种
如果选择,那么就是ret.push_back(path+nums[i])
不选择就是ret.push_back(path)
但是这里要注意的就是不选择要在选择前面,这样方便后面选择后的手动删除。再就是dfs传入后就是传入到下一层,i+1,表示的就是下一层的层数,此时回溯到这一层i也不会被改变。
递归出口:就是在i的层数在nums.size()的时候就进行最后的添加,然后进行返回。
、
class Solution {
public:vector<vector<int>> ret;vector<int> path;int check[10];vector<vector<int>> subsets(vector<int>& nums) {dfs(nums,0);return ret;}void dfs(vector<int>& nums,int i){if(nums.size()==i){ret.push_back(path);return;}//不选dfs(nums,i+1);path.push_back(nums[i]);//选dfs(nums,i+1);path.pop_back();}
};解法二:
1.画决策树

2.设计代码
全局变量
vector<vector<int>> ret; //来记录整体传入的子集
vector<int> path; //设置全局变量,来保证传参,然后进行手动删除
dfs
细节问题:回溯 剪枝 递归出口
只用关心每层进去后当前nums下标值的后面的值,前面的值不用考虑
例如:在1中选2,1中选3不选2,就是在for循环内进行的,当进入下一层选2,回来这个数组就会删掉2,i++,再次进入下一层选3.
class Solution {
public:vector<vector<int>> ret;vector<int> path;vector<vector<int>> subsets(vector<int>& nums) {dfs(nums,0);return ret;}void dfs(vector<int>& nums,int k){ret.push_back(path);for(int i=k;i<nums.size();i++){path.push_back(nums[i]);dfs(nums,i+1);path.pop_back();}}
};总结:
我觉得最关键的就是画出决策图然后再进行思考递归出口或者函数体里面的内容,像这一题就是跟上一题决策树完全不同,思考的方向就完全不同。
总结一下吧~这章对我的进步真的很大,希望对你也是!!!
相关文章:
专题十_穷举vs暴搜vs深搜vs回溯vs剪枝_二叉树的深度优先搜索_算法专题详细总结
目录 搜索 vs 深度优先遍历 vs 深度优先搜索 vs 宽度优先遍历 vs 宽度优先搜索 vs 暴搜 1.深度优先遍历 vs 深度优先搜索(dfs) 2.宽度优先遍历 vs 宽度优先搜索(bfs) 2.关系图暴力枚举一遍所有的情况 3.拓展搜索问题全排列 决策树 1. 计算布尔⼆叉树的值(medi…...

基于springboot vue3 在线考试系统设计与实现 源码数据库 文档
博主介绍:专注于Java(springboot ssm springcloud等开发框架) vue .net php phython node.js uniapp小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作☆☆☆ 精彩专栏推荐订阅☆☆☆☆…...

什么是 HTTP 请求中的 options 请求?
在 Chrome 开发者工具中的 Network 面板看到的 HTTP 方法 OPTIONS,其实是 HTTP 协议的一部分,用于客户端和服务器之间进行“预检”或“协商”。OPTIONS 请求的作用是让客户端能够获取关于服务器支持的 HTTP 方法和其他跨域资源共享 (CORS) 相关的信息&am…...

[图形学]smallpt代码详解(1)
一、简介 本文介绍了著名的99行代码实现全局光照的光线跟踪代码smallpt。 包括对smallpt的功能介绍、编译运行介绍,和对代码的详细解释。希望能够帮助读者更进一步的理解光线跟踪。 二、smallpt介绍 1.smallpt是什么 smallpt(small Path Tracing) 是一个全局光照…...

Vite多环境配置与打包:
环境变量必须以VITE开头 1.VITE_BASE_API: 在开发环境中设置为 /dev-api,这是一个本地 mock 地址,通常用于模拟后端接口。 2.VITE_ENABLE_ERUDA: 设置为 "true",表示启用调试工具,通常是为了…...

git维护【.gitignore文件】
在工程下添加 .gitignore 文件【git忽略文件】 *.class .idea *.iml *.jar /*/target/...
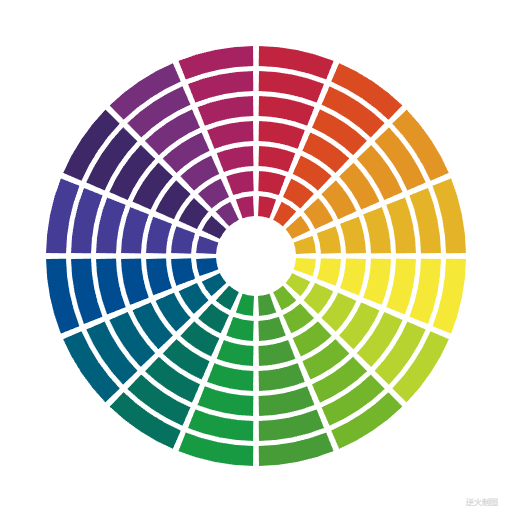
【Canvas与色彩】十六等分多彩隔断圆环
【成图】 【代码】 <!DOCTYPE html> <html lang"utf-8"> <meta http-equiv"Content-Type" content"text/html; charsetutf-8"/> <head><title>隔断圆环Draft5十六等分多彩</title><style type"text…...

什么是pip? -- Python 包管理工具
前言 不同的编程语言通常都有自己的包管理工具,这些工具旨在简化项目的依赖管理、构建过程和开发效率,同时促进代码的复用和共享。每个包管理工具都有其独特的特点和优势,开发者可以根据自己的编程语言和项目需求选择合适的包管理工具。 pip是…...

FastAPI框架使用枚举来型来限定参数、FastApi框架隐藏没多大意义的Schemes模型部分内容以及常见的WSGI服务器Gunicorn、uWSGI了解
一、FastAPI框架使用枚举来型来限定参数 FastAPI框架验证时,有时需要通过枚举的方式来限定参数只能为某几个值中的一个,这时就可以使用FastAPI框架的枚举类型Enum了。publish:December 23, 2020 -Wednesday 代码如下: #引入Enum模块 from fa…...

OceanBase—02(入门篇——对于单副本单节点,由1个observer扩容为3个observer集群)——之前的记录,当初有的问题未解决,目前新版未尝试
OceanBase—02(入门篇——对于单副本单节点,由1个observer扩容为3个observer集群)——之前的记录,有的问题未解决,新版未尝试 1、前言—安装单副本单节点集群1.1 docker安装OB 2、查看现有集群情况2.1 进入容器&#x…...

前沿论文创新点集合
系列文章目录 文章目录 系列文章目录一、《LAMM: Label Alignment for Multi-Modal Prompt Learning》二、《MaPLe: Multi-modal Prompt Learning》三、《Learning to Prompt for Vision-Language Models》CoOp四、《MobileCLIP: Fast Image-Text Models through Multi-Modal R…...
)
刷题记录(好题)
Problem - D - Codeforces 思路: 滑动窗口思想,一个数组记录起始点(记录出现过的次数),另一个数组记录截至点(记录出现过的次数),从0开始遍历,设定一个长度为d的滑动窗口…...

【大数据入门 | Hive】函数{单行函数,集合函数,炸裂函数,窗口函数}
1. 函数简介: Hive会将常用的逻辑封装成函数给用户进行使用,类似于Java中的函数。 好处:避免用户反复写逻辑,可以直接拿来使用。 重点:用户需要知道函数叫什么,能做什么。 Hive提供了大量的内置函数&am…...

python sqlite3 工具函数
起因, 目的: sqlite3 最常用的函数。 比如,某人给了一个 database.db 文件。 但是你登录的时候,不知道账号密码。 此文件就是,查看这个数据库的详细内容。 有哪些表某个表的全部内容。添加数据 代码, 见注释 impor…...

顺丰Android面试题集锦及参考答案
TCP 三次握手和四次挥手是什么,挥手过程中主动方的状态是什么? TCP 三次握手是建立连接的过程: 第一次握手:客户端向服务器发送一个 SYN 报文,该报文包含客户端的初始序列号(seq=x)。此时客户端进入 SYN_SENT 状态。第二次握手:服务器收到客户端的 SYN 报文后,向客户端…...

uniapp中检测应用更新的两种方式-升级中心之uni-upgrade-center-app
uniapp一个很是用的功能,就是在我们发布新版本的app后,需要提示用户进行app更新,并告知用户我们新版的app更新信息,以使得用户能及时使用上我们新开发的功能,提升用户的实用度和粘性。注意:这个功能只能在app端使用 效…...

Python爬虫通过 Cookie 和会话管理来维持其在网站上的会话状态
Python 爬虫虽然是一个热门且非常实用的技术领域,但在实际开发中,确实存在一些困难的地方。以下是 Python 爬虫开发中常见的难点和挑战: 1. 处理反爬虫机制 许多网站为防止爬虫的恶意访问,采取了各种反爬虫措施。常见的反爬虫技…...

使用STM32单片机实现无人机控制系统
无人机控制系统是无人机的大脑,负责处理无人机的姿态控制、导航和通信等功能。本文将详细介绍如何使用STM32单片机实现无人机控制系统,包括硬件设计、软件设计、系统调试与测试等内容。 一、系统概述 无人机控制系统通常包括飞行控制器、传感器、执行器…...

【包教包会】2D图片实现3D透视效果(支持3.x、支持原生、可合批)
将去年写的SpriteFlipper从2.x升级到3.x。 如果需要2.x版本或需要了解算法思路,请移步:https://blog.csdn.net/weixin_42714632/article/details/136745051 优化功能:可同时绕X轴和Y轴旋转,两者效果会叠加。 完美适配Web、原生…...

解决nginx+tomcat宕机完美解决方案
问题描述:公司项目太老了,还是tomcat项目,部署两台tomcat,做了nginx负载。最近发现每到上午10,下午3点,tomcat就宕机了,死活找不到原因,客户影响超期差,实在让人头疼。 解决思路&am…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案
ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲…...
)
用51单片机和HC-SR04超声波模块DIY一个倒车雷达(附完整代码和立创EDA原理图)
51单片机与HC-SR04超声波模块实战:打造高精度倒车雷达系统 在汽车电子和智能硬件领域,倒车雷达作为基础安全装置,其DIY实现不仅能帮助理解超声波测距原理,更是掌握嵌入式系统开发的绝佳实践。本文将手把手教你使用经典的STC89C52单…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

零基础实操:小龙虾 AI OpenClaw 接入 Kimi 详细步骤
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常运行OpenClaw客户端,顶部 Gateway 状态保持在线设备网络通畅,可正常访问 Kimi 开放平台拥有可正常登录的 Kimi 月之暗面 Moonshot 账号账号提…...

Nixtla时间序列预测库实战:从统计模型到深度学习的一站式解决方案
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理销售预测、服务器负载监控或者任何与时间相关的数据预测问题,并且厌倦了在复杂的模型库和繁琐的预处理步骤之间反复横跳,那么 Nixtla 这个开源项目很可能就是你一直在找的“瑞士军刀”。…...

飞书自动化工具feishu-atuo:Python积木式开发与实战指南
1. 项目概述:飞书自动化,从零到一的效率革命 如果你和我一样,每天的工作流里都离不开飞书,那你肯定也经历过这些时刻:手动把日报、周报从文档复制到表格里归档;在多个群里重复发送同样的通知;为…...