强化学习笔记之【DDPG算法】
强化学习笔记之【DDPG算法】
文章目录
- 强化学习笔记之【DDPG算法】
- 前言:
- 原论文伪代码
- DDPG算法
- DDPG 中的四个网络
- 代码核心更新公式
前言:
本文为强化学习笔记第二篇,第一篇讲的是Q-learning和DQN
就是因为DDPG引入了Actor-Critic模型,所以比DQN多了两个网络,网络名字功能变了一下,其它的就是软更新之类的小改动而已
本文初编辑于2024.10.6
CSDN主页:https://blog.csdn.net/rvdgdsva
博客园主页:https://www.cnblogs.com/hassle
博客园本文链接:

原论文伪代码

- 上述代码为DDPG原论文中的伪代码
DDPG算法
需要先看:
Deep Reinforcement Learning (DRL) 算法在 PyTorch 中的实现与应用【DDPG部分】【没有在选择一个新的动作的时候,给policy函数返回的动作值增加一个噪音】【critic网络与下面不同】
深度强化学习笔记——DDPG原理及实现(pytorch)【DDPG伪代码部分】【这个跟上面的一样没有加噪音】【critic网络与上面不同】
【深度强化学习】(4) Actor-Critic 模型解析,附Pytorch完整代码【选看】【Actor-Critic理论部分】
如果需要给policy函数返回的动作值增加一个噪音,实现如下
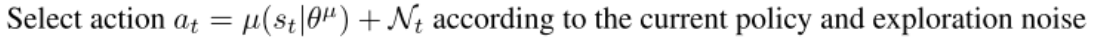
def select_action(self, state, noise_std=0.1):state = torch.FloatTensor(state.reshape(1, -1))action = self.actor(state).cpu().data.numpy().flatten()# 添加噪音,上面两个文档的代码都没有这个步骤noise = np.random.normal(0, noise_std, size=action.shape)action = action + noisereturn actionDDPG 中的四个网络
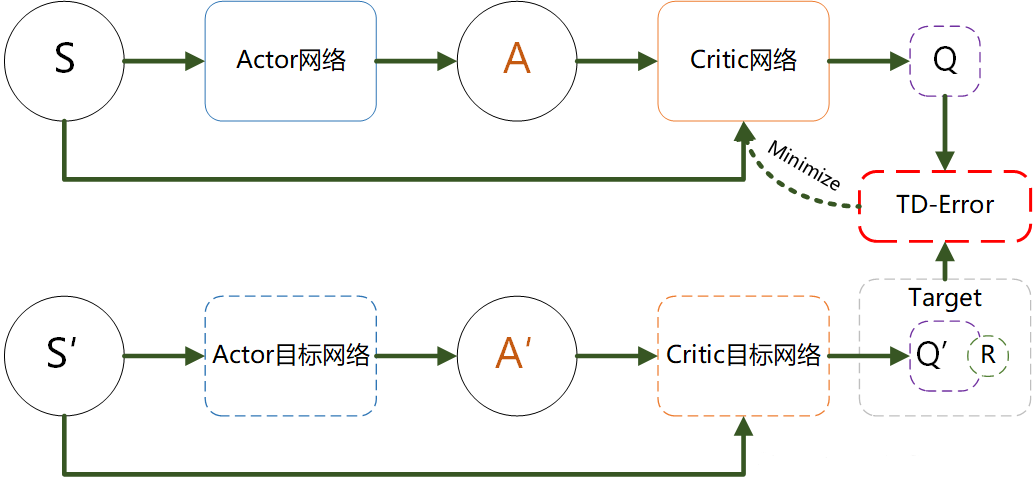
注意!!!这个图只展示了Critic网络的更新,没有展示Actor网络的更新
- Actor 网络(策略网络):
- 作用:决定给定状态 ss 时,应该采取的动作 a=π(s)a=π(s),目标是找到最大化未来回报的策略。
- 更新:基于 Critic 网络提供的 Q 值更新,以最大化 Critic 估计的 Q 值。
- Target Actor 网络(目标策略网络):
- 作用:为 Critic 网络提供更新目标,目的是让目标 Q 值的更新更为稳定。
- 更新:使用软更新,缓慢向 Actor 网络靠近。
- Critic 网络(Q 网络):
- 作用:估计当前状态 ss 和动作 aa 的 Q 值,即 Q(s,a)Q(s,a),为 Actor 提供优化目标。
- 更新:通过最小化与目标 Q 值的均方误差进行更新。
- Target Critic 网络(目标 Q 网络):
- 作用:生成 Q 值更新的目标,使得 Q 值更新更为稳定,减少振荡。
- 更新:使用软更新,缓慢向 Critic 网络靠近。
大白话解释:
1、DDPG实例化为actor,输入state输出action
2、DDPG实例化为actor_target
3、DDPG实例化为critic_target,输入next_state和actor_target(next_state)经DQN计算输出target_Q
4、DDPG实例化为critic,输入state和action输出current_Q,输入state和actor(state)【这个参数需要注意,不是action】经负均值计算输出actor_loss
5、current_Q 和target_Q进行critic的参数更新
6、actor_loss进行actor的参数更新
action实际上是batch_action,state实际上是batch_state,而batch_action != actor(batch_state)
因为actor是频繁更新的,而采样是随机采样,不是所有batch_action都能随着actor的更新而同步更新
Critic网络的更新是一发而动全身的,相比于Actor网络的更新要复杂要重要许多
代码核心更新公式
t a r g e t ‾ Q = c r i t i c ‾ t a r g e t ( n e x t ‾ s t a t e , a c t o r ‾ t a r g e t ( n e x t ‾ s t a t e ) ) t a r g e t ‾ Q = r e w a r d + ( 1 − d o n e ) × g a m m a × t a r g e t ‾ Q . d e t a c h ( ) target\underline{~}Q = critic\underline{~}target(next\underline{~}state, actor\underline{~}target(next\underline{~}state)) \\target\underline{~}Q = reward + (1 - done) \times gamma \times target\underline{~}Q.detach() target Q=critic target(next state,actor target(next state))target Q=reward+(1−done)×gamma×target Q.detach()
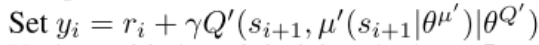
- 上述代码与伪代码对应,意为计算预测Q值
c r i t i c ‾ l o s s = M S E L o s s ( c r i t i c ( s t a t e , a c t i o n ) , t a r g e t ‾ Q ) c r i t i c ‾ o p t i m i z e r . z e r o ‾ g r a d ( ) c r i t i c ‾ l o s s . b a c k w a r d ( ) c r i t i c ‾ o p t i m i z e r . s t e p ( ) critic\underline{~}loss = MSELoss(critic(state, action), target\underline{~}Q) \\critic\underline{~}optimizer.zero\underline{~}grad() \\critic\underline{~}loss.backward() \\critic\underline{~}optimizer.step() critic loss=MSELoss(critic(state,action),target Q)critic optimizer.zero grad()critic loss.backward()critic optimizer.step()

- 上述代码与伪代码对应,意为使用均方误差损失函数更新Critic
a c t o r ‾ l o s s = − c r i t i c ( s t a t e , a c t o r ( s t a t e ) ) . m e a n ( ) a c t o r ‾ o p t i m i z e r . z e r o ‾ g r a d ( ) a c t o r ‾ l o s s . b a c k w a r d ( ) a c t o r ‾ o p t i m i z e r . s t e p ( ) actor\underline{~}loss = -critic(state,actor(state)).mean() \\actor\underline{~}optimizer.zero\underline{~}grad() \\ actor\underline{~}loss.backward() \\ actor\underline{~}optimizer.step() actor loss=−critic(state,actor(state)).mean()actor optimizer.zero grad()actor loss.backward()actor optimizer.step()
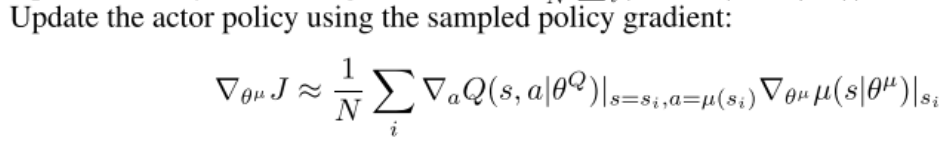
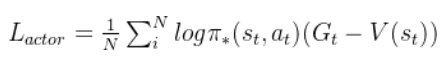
- 上述代码与伪代码对应,意为使用确定性策略梯度更新Actor
c r i t i c ‾ t a r g e t . p a r a m e t e r s ( ) . d a t a = ( t a u × c r i t i c . p a r a m e t e r s ( ) . d a t a + ( 1 − t a u ) × c r i t i c ‾ t a r g e t . p a r a m e t e r s ( ) . d a t a ) a c t o r ‾ t a r g e t . p a r a m e t e r s ( ) . d a t a = ( t a u × a c t o r . p a r a m e t e r s ( ) . d a t a + ( 1 − t a u ) × a c t o r ‾ t a r g e t . p a r a m e t e r s ( ) . d a t a ) critic\underline{~}target.parameters().data=(tau \times critic.parameters().data + (1 - tau) \times critic\underline{~}target.parameters().data) \\ actor\underline{~}target.parameters().data=(tau \times actor.parameters().data + (1 - tau) \times actor\underline{~}target.parameters().data) critic target.parameters().data=(tau×critic.parameters().data+(1−tau)×critic target.parameters().data)actor target.parameters().data=(tau×actor.parameters().data+(1−tau)×actor target.parameters().data)
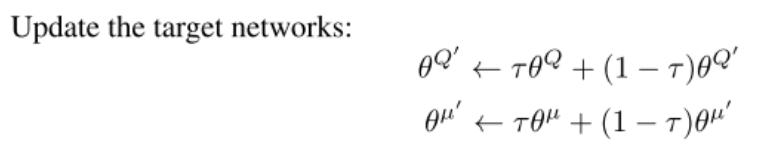
- 上述代码与伪代码对应,意为使用策略梯度更新目标网络
Actor和Critic的角色:
- Actor:负责选择动作。它根据当前的状态输出一个确定性动作。
- Critic:评估Actor的动作。它通过计算状态-动作值函数(Q值)来评估给定状态和动作的价值。
更新逻辑:
- Critic的更新:
- 使用经验回放缓冲区(Experience Replay)从中采样一批经验(状态、动作、奖励、下一个状态)。
- 计算目标Q值:使用目标网络(critic_target)来估计下一个状态的Q值(target_Q),并结合当前的奖励。
- 使用均方误差损失函数(MSELoss)来更新Critic的参数,使得预测的Q值(target_Q)与当前Q值(current_Q)尽量接近。
- Actor的更新:
- 根据当前的状态(state)从Critic得到Q值的梯度(即对Q值相对于动作的偏导数)。
- 使用确定性策略梯度(DPG)的方法来更新Actor的参数,目标是最大化Critic评估的Q值。
个人理解:
DQN算法是将q_network中的参数每n轮一次复制到target_network里面
DDPG使用系数 τ \tau τ来更新参数,将学习到的参数更加soft地拷贝给目标网络
DDPG采用了actor-critic网络,所以比DQN多了两个网络
相关文章:
强化学习笔记之【DDPG算法】
强化学习笔记之【DDPG算法】 文章目录 强化学习笔记之【DDPG算法】前言:原论文伪代码DDPG算法DDPG 中的四个网络代码核心更新公式 前言: 本文为强化学习笔记第二篇,第一篇讲的是Q-learning和DQN 就是因为DDPG引入了Actor-Critic模型&#x…...

c++继承(下)
c继承(下) (1)继承与友元(2)继承与静态成员(3)多继承及其菱形继承问题3.1 继承模型3.2 虚继承3.3 多继承中指针偏移问题 (4)继承和组合(9…...

数据结构 ——— 单链表oj题:反转链表
目录 题目要求 手搓一个简易链表 代码实现 题目要求 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表 手搓一个简易链表 代码演示: struct ListNode* n1 (struct ListNode*)malloc(sizeof(struct ListNode)); assert(n1);…...

前端项目npm install报错解决的解决办法
报错问题一: [rootspug-api spug_web]# npm install npm WARN deprecated xterm4.19.0: This package is now deprecated. Move to xterm/xterm instead. npm WARN deprecated workbox-google-analytics4.3.1: It is not compatible with newer versions of GA starting with v…...

vue双向绑定/小程序双向绑定区别
Vue双向绑定与小程序双向绑定在实现方式、语法差异以及功能特性上均存在显著区别。以下是对这两者的详细比较: 一、实现方式 Vue双向绑定 Vue的双向绑定主要通过其响应式数据系统实现。Vue使用Object.defineProperty()方法(或在Vue 3中使用Proxy对象&am…...

华为OD机试真题---字符串变换最小字符串
题目描述: 给定一个字符串s,最多只能进行一次变换,返回变换后能得到的最小字符串(按照字典序进行比较)。 变换规则: 交换字符串中任意两个不同位置的字符。 输入描述: 一串小写字母组成的字符串s 输出描述: 按照要求进行变换得到的最小字符串 补…...

JAVA基础面试题汇总(持续更新)
1、精确运算场景使用浮点型运算问题 精确运算场景(如金融领域计算应计利息)计算数字,使用浮点型,由于精度丢失问题,会导致计算后的结果和预期不一致,使用Bigdecimal类型解决此问题,示例代码如下…...

设计模式-创建型-常用:单例模式、工厂模式、建造者模式
单例模式 概念 一个类只允许创建一个对象(或实例),那这个类就是单例类,这种设计模式就叫做单例模式。对于一些类,创建和销毁比较复杂,如果每次使用都创建一个对象会很耗费性能,因此可以把它设…...

【数据结构】【链表代码】随机链表的复制
/*** Definition for a Node.* struct Node {* int val;* struct Node *next;* struct Node *random;* };*/typedef struct Node Node; struct Node* copyRandomList(struct Node* head) {if(headNULL)return NULL;//1.拷贝结点,连接到原结点的后面Node…...

Linux 系统五种帮助命令的使用
Linux 系统五种帮助命令的使用 本文将介绍 Linux 系统中常用的帮助命令,包括 man、–help、whatis、apropos 和 info 命令。这些命令对于新手和有经验的用户来说,都是查找命令信息、理解命令功能的有力工具。 文章目录 Linux 系统五种帮助命令的使用一…...

Vueron引领未来出行:2026年ADAS激光雷达解决方案上市路线图深度剖析
Vueron ADAS激光雷达解决方案路线图分析:2026年上市展望 Vueron近期发布的ADAS激光雷达解决方案路线图,标志着该公司在自动驾驶技术领域迈出了重要一步。该路线图以2026年上市为目标,彰显了Vueron对未来市场趋势的精准把握和对技术创新的坚定…...

Java | Leetcode java题解之第458题可怜的小猪
题目: 题解: class Solution {public int poorPigs(int buckets, int minutesToDie, int minutesToTest) {if (buckets 1) {return 0;}int[][] combinations new int[buckets 1][buckets 1];combinations[0][0] 1;int iterations minutesToTest /…...

怎么不改变视频大小的情况下,修改视频的时长
视频文件太大怎么变小?不影响画质的四种方法 怎么不改变视频大小的情况下,修改视频的时长 截取结尾的时间你可以使用 ffmpeg 来裁剪视频的结尾部分。假设你想去掉视频最后的3秒钟,可以先使用 ffmpeg 获取视频的总时长,然后通过指定一个新的…...

数据结构:AVL树
前言 学习了普通二叉树,发现普通二叉树作用不大,于是我们学习了搜索二叉树,给二叉树新增了搜索、排序、去重等特性, 但是,在极端情况下搜索二叉树会退化成单边树,搜索的时间复杂度达到了O(N),这…...

系统守护者:使用PyCharm与Python实现关键硬件状态的实时监控
目录 前言 系统准备 软件下载与安装 安装相关库 程序准备 主体程序 更改后的程序: 编写.NET程序 前言 在现代生活中,电脑作为核心工具,其性能和稳定性的维护至关重要。为确保电脑高效运行,我们不仅需关注软件优化…...
【工作流引擎集成】springboot+Vue+activiti+mysql带工作流集成系统,直接用于业务开发,流程设计,工作流审批,会签
前言 activiti工作流引擎项目,企业erp、oa、hr、crm等企事业办公系统轻松落地,一套完整并且实际运用在多套项目中的案例,满足日常业务流程审批需求。 一、项目形式 springbootvueactiviti集成了activiti在线编辑器,流行的前后端…...

SumatraPDF一打开就无响应怎么办?
结论:当前安装版不论32位还是64位都会出现问题。使用portable免安装版未发现相关问题。——sumatrapdf可以用于pdf, epub, mobi 等格式文件的浏览。 点击看相关问题和讨论...

棋牌灯控计时计费系统软件免费试用版怎么下载 佳易王计时收银管理系统操作教程
一、前言 【试用版软件下载,可以点击本文章最下方官网卡片】 棋牌灯控计时计费系统软件免费试用版怎么下载 佳易王计时收银管理系统操作教程 棋牌计时计费软件的应用也提升了顾客的服务体验,顾客可以清晰的看到自己的消费时间和费用。增加了消费的透明…...

Excel下拉菜单制作及选项修改
Excel下拉菜单 1、下拉菜单制作2、下拉菜单修改 下拉框(选项菜单)是十分常见的功能。Excel支持下拉框制作,通过预设选项进行菜单选择,可以避免手动输入错误和重复工作,提升数据输入的准确性和效率 1、下拉菜单制作 步…...
登陆问题)
树莓派 mysql (兼容mariadb)登陆问题
树莓派 mysql (兼容mariadb)登陆问题 树莓派 MySQL 登陆问题 1 使用默认账号登陆 在首次登陆的情况下,系统默认为root用户授权 sudo su root  2. 使用root用户登…...

如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南
如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否厌倦了每次启动Minecraft都要手动配…...

NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程
NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gitcode.c…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

大语言模型与多模态生成融合:架构、工具与实践指南
1. 项目概述:当大语言模型遇见多模态生成最近两年,AI领域最激动人心的进展,莫过于大语言模型(LLMs)和多模态生成模型的“双向奔赴”。前者以ChatGPT、GPT-4为代表,展现了惊人的语言理解、推理和生成能力&am…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

Claude API钩子框架设计:非侵入式中间件与生命周期管理实践
1. 项目概述与核心价值最近在折腾一些AI应用开发,发现一个挺有意思的现象:很多开发者想给Claude API的调用过程加点“料”,比如在请求发出前或收到响应后,自动执行一些自定义逻辑。可能是为了日志记录、数据清洗、请求重试&#x…...

MedAgentBench:大模型临床决策能力评估基准详解与应用
1. 项目概述:当大模型成为医疗决策的“实习生” 最近在医疗AI的圈子里,一个名为“MedAgentBench”的开源项目引起了不小的讨论。这个由斯坦福机器学习组(Stanford ML Group)发布的项目,其核心目标非常明确:…...

手把手教你用SystemVerilog Interface搭建一个可复用的DMA寄存器验证环境
基于SystemVerilog Interface构建模块化DMA验证环境的工程实践 在数字IC验证领域,DMA(直接内存访问)控制器作为关键IP核,其寄存器验证环境的搭建效率直接影响项目进度。传统验证方法中信号连接冗长、时序控制分散的问题ÿ…...

深入解析Ayiks project-genesis-framework:模块化架构元框架的设计与实践
1. 项目概述与核心价值最近在梳理一些老项目的技术债,发现很多早期为了快速上线而写的代码,现在维护起来简直是一场灾难。业务逻辑和底层框架耦合得死死的,想换个数据库或者加个缓存层,都得把整个项目翻个底朝天。这种时候&#x…...

Ubuntu中ping命令安装与网络诊断全攻略
1. 项目概述:一个看似简单却暗藏玄机的问题“如何在Ubuntu中安装ping”,这个标题乍一看,可能会让很多老手会心一笑,甚至觉得有些“小白”。但恰恰是这个看似基础到不能再基础的问题,却是我在多年运维和开发工作中&…...