基于 Qwen2.5-0.5B 微调训练 Ner 命名实体识别任务
一、Qwen2.5 & 数据集
Qwen2.5 是 Qwen 大型语言模型的最新系列,参数范围从 0.5B 到 72B 不等。
对比 Qwen2 最新的 Qwen2.5 进行了以下改进:
- 知识明显增加,并且大大提高了编码和数学能力。
- 在指令跟随、生成长文本(超过
8K个标记)、理解结构化数据(例如表格)以及生成结构化输出(尤其是JSON)方面有了显著改进。对系统提示的多样性更具弹性,增强了聊天机器人的角色扮演实现和条件设置。 - 长上下文支持多达
128K个令牌,并且可以生成多达8K个令牌。 - 多语言支持超过
29种语言,包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。
Qwen2.5 ModelScope 地址:
https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
本文基于 Qwen2.5-0.5B 强化微调训练 Ner 命名实体识别任务,数据集采用 CLUENER(中文语言理解测评基准)2020数据集:
进入下面链接下载数据集:
https://www.cluebenchmarks.com/introduce.html

数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
数据实例如下:
{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": {"name": {"叶老桂": [[9, 11]]}, "company": {"浙商银行": [[0, 3]]}}}
{"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {"game": {"CSOL": [[4, 7]]}}}
{"text": "那不勒斯vs锡耶纳以及桑普vs热那亚之上呢?", "label": {"organization": {"那不勒斯": [[0, 3]], "锡耶纳": [[6, 8]], "桑普": [[11, 12]], "热那亚": [[15, 17]]}}}
{"text": "加勒比海盗3:世界尽头》的去年同期成绩死死甩在身后,后者则即将赶超《变形金刚》,", "label": {"movie": {"加勒比海盗3:世界尽头》": [[0, 11]], "《变形金刚》": [[33, 38]]}}}
{"text": "布鲁京斯研究所桑顿中国中心研究部主任李成说,东亚的和平与安全,是美国的“核心利益”之一。", "label": {"address": {"美国": [[32, 33]]}, "organization": {"布鲁京斯研究所桑顿中国中心": [[0, 12]]}, "name": {"李成": [[18, 19]]}, "position": {"研究部主任": [[13, 17]]}}}
{"text": "目前主赞助商暂时空缺,他们的球衣上印的是“unicef”(联合国儿童基金会),是公益性质的广告;", "label": {"organization": {"unicef": [[21, 26]], "联合国儿童基金会": [[29, 36]]}}}
{"text": "此数据换算成亚洲盘罗马客场可让平半低水。", "label": {"organization": {"罗马": [[9, 10]]}}}
{"text": "你们是最棒的!#英雄联盟d学sanchez创作的原声王", "label": {"game": {"英雄联盟": [[8, 11]]}}}
{"text": "除了吴湖帆时现精彩,吴待秋、吴子深、冯超然已然归入二三流了,", "label": {"name": {"吴湖帆": [[2, 4]], "吴待秋": [[10, 12]], "吴子深": [[14, 16]], "冯超然": [[18, 20]]}}}
{"text": "在豪门被多线作战拖累时,正是他们悄悄追赶上来的大好时机。重新找回全队的凝聚力是拉科赢球的资本。", "label": {"organization": {"拉科": [[39, 40]]}}}
其中 train.json 有 10748 条数据,dev.json 中有 1343 条数据,可作为验证集使用。
本次我们实验暂时不需要模型输出位置,这里对数据集格式做下转换:
import jsondef trans(file_path, save_path):with open(save_path, "a", encoding="utf-8") as w:with open(file_path, "r", encoding="utf-8") as r:for line in r:line = json.loads(line)text = line['text']label = line['label']trans_label = {}for key, items in label.items():items = items.keys()trans_label[key] = list(items)trans = {"text": text,"label": trans_label}line = json.dumps(trans, ensure_ascii=False)w.write(line + "\n")w.flush()if __name__ == '__main__':trans("ner_data_origin/train.json", "ner_data/train.json")trans("ner_data_origin/dev.json", "ner_data/val.json")转换后的数据格式示例:
{"text": "彭小军认为,国内银行现在走的是台湾的发卡模式,先通过跑马圈地再在圈的地里面选择客户,", "label": {"address": ["台湾"], "name": ["彭小军"]}}
{"text": "温格的球队终于又踢了一场经典的比赛,2比1战胜曼联之后枪手仍然留在了夺冠集团之内,", "label": {"organization": ["曼联"], "name": ["温格"]}}
{"text": "突袭黑暗雅典娜》中Riddick发现之前抓住他的赏金猎人Johns,", "label": {"game": ["突袭黑暗雅典娜》"], "name": ["Riddick", "Johns"]}}
{"text": "郑阿姨就赶到文汇路排队拿钱,希望能将缴纳的一万余元学费拿回来,顺便找校方或者教委要个说法。", "label": {"address": ["文汇路"]}}
{"text": "我想站在雪山脚下你会被那巍峨的雪山所震撼,但你一定要在自己身体条件允许的情况下坚持走到牛奶海、", "label": {"scene": ["牛奶海", "雪山"]}}
{"text": "吴三桂演义》小说的想像,说是为牛金星所毒杀。……在小说中加插一些历史背景,", "label": {"book": ["吴三桂演义》"], "name": ["牛金星"]}}
{"text": "看来各支一二流的国家队也开始走出欧洲杯后低迷,从本期对阵情况看,似乎冷门度也不太高,你认为呢?", "label": {"organization": ["欧洲杯"]}}
{"text": "就天涯网推出彩票服务频道是否是业内人士所谓的打政策“擦边球”,记者近日对此事求证彩票监管部门。", "label": {"organization": ["彩票监管部门"], "company": ["天涯网"], "position": ["记者"]}}
{"text": "市场仍存在对网络销售形式的需求,网络购彩前景如何?为此此我们采访业内专家程阳先生。", "label": {"name": ["程阳"], "position": ["专家"]}}
{"text": "组委会对中国区预选赛进行了抽签分组,并且对本次抽签进行了全程直播。", "label": {"government": ["组委会"]}}
整体数据集 train.json 的 Token 分布如下所示:
import json
from transformers import AutoTokenizer
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']def get_token_distribution(file_path, tokenizer):input_num_tokens, outout_num_tokens = [], []with open(file_path, "r", encoding="utf-8") as r:for line in r:line = json.loads(line)text = line['text']label = line['label']label = json.dumps(label, ensure_ascii=False)input_num_tokens.append(len(tokenizer(text).input_ids))outout_num_tokens.append(len(tokenizer(label).input_ids))return min(input_num_tokens), max(input_num_tokens), np.mean(input_num_tokens),\min(outout_num_tokens), max(outout_num_tokens), np.mean(outout_num_tokens)def main():model_path = "model/Qwen2.5-0.5B-Instruct"train_data_path = "ner_data/train.json"tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)i_min, i_max, i_avg, o_min, o_max, o_avg = get_token_distribution(train_data_path, tokenizer)print(i_min, i_max, i_avg, o_min, o_max, o_avg)plt.figure(figsize=(8, 6))bars = plt.bar(["input_min_token","input_max_token","input_avg_token","ouput_min_token","ouput_max_token","ouput_avg_token",], [i_min, i_max, i_avg, o_min, o_max, o_avg])plt.title('训练集Token分布情况')plt.ylabel('数量')for bar in bars:yval = bar.get_height()plt.text(bar.get_x() + bar.get_width() / 2, yval, int(yval), va='bottom')plt.show()if __name__ == '__main__':main()
其中输入Token 最大是 50,输出 Token 最大是 69 。
二、微调训练
解析数据,构建 Dataset 数据集:
ner_dataset.py
# -*- coding: utf-8 -*-
from torch.utils.data import Dataset
import torch
import json
import numpy as npclass NerDataset(Dataset):def __init__(self, data_path, tokenizer, max_source_length, max_target_length) -> None:super().__init__()self.tokenizer = tokenizerself.max_source_length = max_source_lengthself.max_target_length = max_target_lengthself.max_seq_length = self.max_source_length + self.max_target_lengthself.data = []if data_path:with open(data_path, "r", encoding='utf-8') as f:for line in f:if not line or line == "":continuejson_line = json.loads(line)text = json_line["text"]label = json_line["label"]label = json.dumps(label, ensure_ascii=False)self.data.append({"text": text,"label": label})print("data load , size:", len(self.data))def preprocess(self, text, label):messages = [{"role": "system","content": "你的任务是做Ner任务提取, 根据用户输入提取出完整的实体信息, 并以JSON格式输出。"},{"role": "user", "content": text}]prompt = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)instruction = self.tokenizer(prompt, add_special_tokens=False, max_length=self.max_source_length,padding="max_length", pad_to_max_length=True, truncation=True)response = self.tokenizer(label, add_special_tokens=False, max_length=self.max_target_length,padding="max_length", pad_to_max_length=True, truncation=True)input_ids = instruction["input_ids"] + response["input_ids"] + [self.tokenizer.pad_token_id]attention_mask = (instruction["attention_mask"] + response["attention_mask"] + [1])labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [self.tokenizer.pad_token_id]return input_ids, attention_mask, labelsdef __getitem__(self, index):item_data = self.data[index]input_ids, attention_mask, labels = self.preprocess(**item_data)return {"input_ids": torch.LongTensor(np.array(input_ids)),"attention_mask": torch.LongTensor(np.array(attention_mask)),"labels": torch.LongTensor(np.array(labels))}def __len__(self):return len(self.data)微调训练,这里采用全参数微调:
# -*- coding: utf-8 -*-
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from transformers import AutoModelForCausalLM, AutoTokenizer
from ner_dataset import NerDataset
from tqdm import tqdm
import time, sysdef train_model(model, train_loader, val_loader, optimizer,device, num_epochs, model_output_dir, writer):batch_step = 0for epoch in range(num_epochs):time1 = time.time()model.train()for index, data in enumerate(tqdm(train_loader, file=sys.stdout, desc="Train Epoch: " + str(epoch))):input_ids = data['input_ids'].to(device, dtype=torch.long)attention_mask = data['attention_mask'].to(device, dtype=torch.long)labels = data['labels'].to(device, dtype=torch.long)optimizer.zero_grad()outputs = model(input_ids=input_ids,attention_mask=attention_mask,labels=labels,)loss = outputs.lossloss.backward()optimizer.step()writer.add_scalar('Loss/train', loss, batch_step)batch_step += 1# 100轮打印一次 lossif index % 100 == 0 or index == len(train_loader) - 1:time2 = time.time()tqdm.write(f"{index}, epoch: {epoch} -loss: {str(loss)} ; each step's time spent: {(str(float(time2 - time1) / float(index + 0.0001)))}")# 验证model.eval()val_loss = validate_model(model, device, val_loader)writer.add_scalar('Loss/val', val_loss, epoch)print(f"val loss: {val_loss} , epoch: {epoch}")print("Save Model To ", model_output_dir)model.save_pretrained(model_output_dir)def validate_model(model, device, val_loader):running_loss = 0.0with torch.no_grad():for _, data in enumerate(tqdm(val_loader, file=sys.stdout, desc="Validation Data")):input_ids = data['input_ids'].to(device, dtype=torch.long)attention_mask = data['attention_mask'].to(device, dtype=torch.long)labels = data['labels'].to(device, dtype=torch.long)outputs = model(input_ids=input_ids,attention_mask=attention_mask,labels=labels,)loss = outputs.lossrunning_loss += loss.item()return running_loss / len(val_loader)def main():# 基础模型位置model_name = "model/Qwen2.5-0.5B-Instruct"# 训练集train_json_path = "ner_data/train.json"# 验证集val_json_path = "ner_data/val.json"max_source_length = 50max_target_length = 140epochs = 30batch_size = 15lr = 1e-4model_output_dir = "output_ner"logs_dir = "logs"# 设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 加载分词器和模型tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)print("Start Load Train Data...")train_params = {"batch_size": batch_size,"shuffle": True,"num_workers": 4,}training_set = NerDataset(train_json_path, tokenizer, max_source_length, max_target_length)training_loader = DataLoader(training_set, **train_params)print("Start Load Validation Data...")val_params = {"batch_size": batch_size,"shuffle": False,"num_workers": 4,}val_set = NerDataset(val_json_path, tokenizer, max_source_length, max_target_length)val_loader = DataLoader(val_set, **val_params)# 日志记录writer = SummaryWriter(logs_dir)# 优化器optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)model = model.to(device)# 开始训练print("Start Training...")train_model(model=model,train_loader=training_loader,val_loader=val_loader,optimizer=optimizer,device=device,num_epochs=epochs,model_output_dir=model_output_dir,writer=writer)writer.close()if __name__ == '__main__':main()训练过程:

训练结束后,可以查看下 tensorboard 中你的 loss 曲线:
tensorboard --logdir=logs --bind_all
在 浏览器访问 http:ip:6006/

三、模型测试
# -*- coding: utf-8 -*-
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchdef main():model_path = "model/Qwen2.5-0.5B-Instruct"train_model_path = "output_ner"tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(train_model_path, trust_remote_code=True)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model.to(device)test_case = ["三星WCG2011北京赛区魔兽争霸3最终名次","新华网孟买3月10日电(记者聂云)印度国防部10日说,印度政府当天批准","证券时报记者肖渔"]for case in test_case:messages = [{"role": "system","content": "你的任务是做Ner任务提取, 根据用户输入提取出完整的实体信息, 并以JSON格式输出。"},{"role": "user", "content": case}]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=140,top_k=1)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print("----------------------------------")print(f"input: {case}\nresult: {response}")if __name__ == '__main__':main()
相关文章:
基于 Qwen2.5-0.5B 微调训练 Ner 命名实体识别任务
一、Qwen2.5 & 数据集 Qwen2.5 是 Qwen 大型语言模型的最新系列,参数范围从 0.5B 到 72B 不等。 对比 Qwen2 最新的 Qwen2.5 进行了以下改进: 知识明显增加,并且大大提高了编码和数学能力。在指令跟随、生成长文本(超过 8K…...

16【Protues51单片机仿真】智能洗衣机倒计时系统
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 用直流电机转动模拟洗衣机。要求 有弱洗、普通洗、强洗三种模式,可通过按键选择。可以设置洗衣时长,通关按键选择15、30、45、60、90分钟。时间到蜂鸣器报警提示。LCD 显示…...
爱心曲线公式大全
local r a*((math.sin(angle) * math.sqrt(math.abs(math.cos(angle)))) / (math.sin(angle) 1.4142) - 2 * math.sin(angle) 2) local x r * math.cos(angle) -- 计算对应的x值 local z r * math.sin(angle) 1.5*a - --曲线公式绘画 local function generateParabola()…...

新书速览|你好,C++
《你好,C》 本书内容 《你好,C》主要介绍C开发环境的搭建、基础语法知识、面向对象编程思想以及标准模板库的应用,特别针对初学者在学习C过程中可能遇到的难点提供了解决方案。全书共分13章,以一个工资程序的不断优化和完善为线索…...

ufw:Linux网络防火墙
一、命令简介 ufw(Uncomplicated Firewall)是一个为 Linux 系统提供简单易用的命令行界面的防火墙管理工具。它是基于 iptables 的,但提供了更简洁的语法和更直观的操作方式,使得配置防火墙变得更加简单,特别适…...

[C++]使用纯opencv部署yolov11-cls图像分类onnx模型
【算法介绍】 在C中使用纯OpenCV部署YOLOv11-cls图像分类ONNX模型是一项具有挑战性的任务,因为YOLOv11通常是用PyTorch等深度学习框架实现的,而OpenCV本身并不直接支持加载和运行PyTorch模型。然而,可以通过一些间接的方法来实现这一目标&am…...

如何使用Immersity AI将图片转换成3D效果视频
随着技术的进步,图片处理变得越来越强大和直观。借助Immersity AI这样的工具,我们现在可以轻松地将平面图片转换成3D效果视频。以下是如何使用Immersity AI进行这一转换的详细步骤。 第一步:访问Immersity AI网站 首先,打开你的…...

安全运营 -- GPO审计
0x00 背景 审计GPO,目的是审计哪些GPO权限分配不合理,包括但不限于审计预期以外的用户具有对GPO的写权限。 0x01 开启审核 在一台windows服务器上 开始 -- 运行 -- 输入 server manager 依次点击Manage -- Add Roles and Features Wizard 角色和功能…...
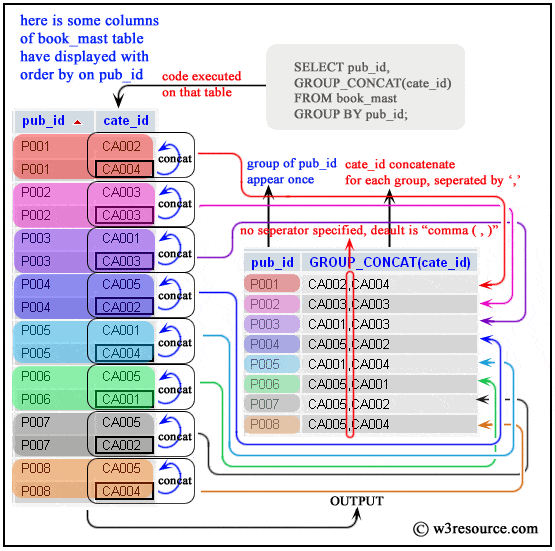
thinkphp6入门(25)-- 分组查询 GROUP_CONCAT
假设表名为 user_courses,字段为 user_id 和 course_name,存储每个用户选修的课程,想查询每个学生选修的所有课程 SQL 原生查询 SELECT user_id, GROUP_CONCAT(course_name) as courses FROM user_courses GROUP BY user_id; ThinkPHP 代码…...

小米 MIX FOLD工程固件 更换字库修复分区 资源预览与刷写说明
小米 MIX FOLD机型代号 :cetus 该手机搭载骁龙888旗舰处理器 。对于一些因为字库问题损坏导致的故障,更换字库后要先刷写对应的工程底层修复固件。绑定cpu后在写入miui量产固件。 通过博文了解 1💝💝💝-----此机型工程固件的资源刷写注意事项 2💝💝💝-----此…...

Flutter全局统一自定义导航栏返回按钮
Flutter全局统一自定义导航栏返回按钮 在Flutter开发中,导航栏(AppBar)是用户界面的重要组成部分,它不仅提供了页面标题,还可能包含返回按钮、导航按钮等。默认情况下,每个Scaffold的AppBar都会包含一个返…...
微信图片的超能力:5大隐秘功能揭秘,让你成为信息处理大师
在数字化时代,微信已成为我们日常生活中不可或缺的通讯工具。 它不仅仅是聊天的平台,更是一个功能强大的信息处理工具。 今天,我们将揭秘微信中图片背后的五大隐秘功能,让你在使用微信时更加得心应手,成为信息处理的…...

python实现RC4加解密算法
RC4算法 一、算法介绍1.1 背景1.2 密钥调度算法(KSA)1.3 伪随机生成算法(PRGA) 二、代码实现三、演示效果 一、算法介绍 1.1 背景 RC4算法是由Ron Rivest在1987年为RSA数据安全公司设计的一种流密码算法,其安全性主要依赖于其密钥流的随机性和不可预测性。该算法因…...

BLE MESH学习2——自定义MESH网络架构思考
BLE MESH学习2——自定义MESH网络架构思考 基于对WCH CH582这款单片机的了解,其可以实现mesh配网、朋友节点、低功耗节点和中继节点的角色,基本功能无问题。在此基础上,考虑满足IoT需求的MESH架构设计,作为后续设计的“白皮书”。…...

路由器的工作机制
在一个家庭或者一个公司中 路由器的作用主要有两个(①路由–决定了数据包从来源到目的地的路径 通过映射表决定 ②转送–通过路由器知道了映射表 就可以将数据包从路由器的输入端转移给合适的输出端) 我们可以画一张图来分析一下: 我们好好来解析一下这张图&#x…...

Studying-多线程学习Part3 - condition_variable与其使用场景、C++11实现跨平台线程池
来源:多线程学习 目录 condition_variable与其使用场景 生产者与消费者模型 C11实现跨平台线程池 condition_variable与其使用场景 生产者与消费者模型 生产者-消费者模式是一种经典的多线程设计模式,用于解决多个线程之间的数据共享和协作问题。…...
开发自定义starter
环境:Spring Cloud Gateway 需求:防止用户绕过网关直接访问服务器,用户只需引入依赖即可。 1、创建项目 首先创建一个spring boot项目 2、配置pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xm…...

Vue2电商平台(五)、加入购物车,购物车页面
文章目录 一、加入购物车1. 添加到购物车的接口2. 点击按钮的回调函数3. 请求成功后进行路由跳转(1)、创建路由并配置路由规则(2)、路由跳转并传参(本地存储) 二、购物车页面的业务1. uuid生成用户id2. 获取购物车数据3. 计算打勾商品总价4. 全选与商品打勾(1)、商品全部打勾&a…...

众数信科 AI智能体政务服务解决方案——寻知智能笔录系统
政务服务解决方案 寻知智能笔录方案 融合民警口供录入与笔录生成需求 2分钟内生成笔录并提醒错漏 助办案人员二次询问 提升笔录质量和效率 寻知智能笔录系统 众数信科AI智能体 产品亮点 分析、理解行业知识和校验规则 AI实时提醒用户文书需注意部分 全文校验格式、内容…...
Redis篇(面试题 - 连环16炮)(持续更新迭代)
目录 目录 目录 (第一炮)一、Redis?常用数据结构? 1. 项目里面到了Redis,为什么选用Redis? 2. Redis 是什么? 3. Redis和关系型数据库的本质区别有哪些? 4. Redis 的线程模型…...

fastapi · FastAPI framework, high performance, easy to learn, fast to code, ready for production
fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 本文整理自 GitHub,经重新整理编辑。 FastAPI framework, high performance, easy to learn, fast to code, ready for production Documentation: https://fas…...

ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署
更多请点击: https://kaifayun.com 第一章:ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署 环境准备与API密钥获取 首先注册ElevenLabs账号并进入 Profile → API Keys页面,生成…...

智能驾驶系统场景下的自动化仿真测试评价技术【附仿真】
✨ 长期致力于智能驾驶系统、有效性评价、测试用例生成、测试场景优化、自动化仿真测试平台研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于复杂度…...

ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南
ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南 ChatGPT-Web-Midjourney-Proxy 是一款集成 ChatGPT、Midjourney 和 GPTs 功能的一站式 UI 工具,为用户提供便捷的 AI 交互体验。在日常使用中,数据安全与灾难恢复至关…...

如何构建高性能 Azure 应用:azcore 的 7 大优化技巧
如何构建高性能 Azure 应用:azcore 的 7 大优化技巧 【免费下载链接】azure-sdk-for-go This repository is for active development of the Azure SDK for Go. For consumers of the SDK we recommend visiting our public developer docs at: 项目地址: https:/…...

CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算
CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算 【免费下载链接】ops-sparse 本项目是CANN提供的高性能稀疏矩阵计算的算子库,专注于优化稀疏矩阵的计算效率。 项目地址: https://gitcode.com/cann/ops-sparse 在高性能计算领域…...
)
今日算法(构造二叉搜索树)
题目描述给你一个整数数组 nums,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树(BST)。平衡二叉搜索树:左右两个子树的高度差的绝对值不超过 1每个节点的左右子树都是平衡二叉树二叉搜索树的中序遍历结…...

BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3分钟学会从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/g…...

终极QRazyBox指南:免费在线修复损坏二维码的完整教程
终极QRazyBox指南:免费在线修复损坏二维码的完整教程 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否遇到过重要二维码因为打印模糊、水渍污损或物理磨损而无法扫描的困扰&a…...

端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践
端到端关键词识别技术范式:WeKWS在边缘计算场景下的架构创新与实践 【免费下载链接】wekws Production First and Production Ready End-to-End Keyword Spotting Toolkit 项目地址: https://gitcode.com/gh_mirrors/we/wekws 在物联网设备普及的今天&#x…...