肺腺癌预后新指标:全切片图像中三级淋巴结构密度的自动化量化|文献精析·24-10-09
小罗碎碎念
本期这篇文章,我去年分享过一次。当时发表在知乎上,没有标记参考文献,配图的清晰度也不够,并且分析的还不透彻,所以趁着国庆假期重新分析一下。
这篇文章的标题为《Computerized tertiary lymphoid structures density on H&E-images is a prognostic biomarker in resectable lung adenocarcinoma》,作者包括Yumeng Wang, Huan Lin, Ningning Yao等。

一作&通讯
| 作者类型 | 作者姓名 | 单位名称 | 单位地址 |
|---|---|---|---|
| 第一作者 | Yumeng Wang | 桂林电子科技大学计算机科学与信息安全学院 | 桂林 541004, 中国 |
| 通讯作者 | Xipeng Pan | 桂林电子科技大学计算机科学与信息安全学院 | 桂林 541004, 中国 |
| 通讯作者 | Cheng Lu | 广东省人民医院放射科/南方医科大学 | 广州 510080, 中国 |
| 通讯作者 | Jun Liu | 中南大学湘雅二医院放射科 | 长沙 410011, 中国 |
| 通讯作者 | Zhenbing Liu | 桂林电子科技大学计算机科学与信息安全学院 | 桂林 541004, 中国 |
| 通讯作者 | Zaiyi Liu | 广东省人民医院放射科/南方医科大学 | 广州 510080, 中国 |
文献速览
研究背景和目的:
- 肺腺癌(LUAD)是非小细胞肺癌最常见的亚型,具有高发病率和死亡率。
- 组织中的三级淋巴结构(TLS)数量增加与肺腺癌患者的有利预后相关。
- 手动评估TLS是经验依赖和耗时的过程,限制了其临床应用。
研究内容和发现:
- 开发了一种自动化计算工作流程,用于量化常规苏木精-伊红(H&E)染色的全切片图像(WSIs)中肿瘤区域的TLS密度。
- 在三个独立数据集中的802名可切除LUAD患者中进一步探索了计算机化的TLS密度与无病生存期(DFS)之间的关联。
- 建立了结合临床病理变量和TLS密度的Cox比例风险回归模型,以评估其预后能力。
- 计算机化的TLS密度是可切除LUAD患者的独立预后生物标志物。
- 将TLS密度与临床病理变量整合,可以通过改善预后分层来支持个体化的临床决策。
研究方法:
- 收集了1196名可切除LUAD患者的数据,最终802名患者符合纳入和排除标准。
- 使用最大选择排名统计方法确定TLS密度的截止值。
- 通过Kaplan-Meier曲线展示了TLS密度低组与TLS密度高组在DFS方面的显著差异。
- 通过多变量逐步Cox回归分析确定了TLS密度是DFS的独立预后因素。
结论:
- TLS密度的量化是一个可靠、可重复、具有普遍性的独立预后生物标志物。
- 将TLS密度与临床病理变量整合,可以改善患者分层,指导个体化临床决策。
一、引言
肺腺癌(LUAD)是肺癌最常见的亚型,具有较高的发病率和死亡率1。
对LUAD患者进行精确分层有助于个性化临床决策。肿瘤-淋巴结-转移(TNM)分期系统2在LUAD患者的风险分层和管理中起着关键作用,但由于肿瘤异质性,相同TNM分期的LUAD患者预后可能存在显著差异1,3。
近期研究发现,三级淋巴结构(TLSs)4–6在抗肿瘤免疫反应中发挥重要作用7,8。TLSs数量的增加与多种癌症类型,包括黑色素瘤9、肺癌10和胃肠癌11等较好的预后相关。因此,TLSs有望成为LUAD的补充预后生物标志物。
以往大多数研究通过多重免疫组化(mIHC)或免疫荧光(mIF)方法12–14对TLS相关指标进行定量分析。然而,mIHC和mIF并非常规检查,成本较高,限制了其临床应用。相比之下,苏木精-伊红(H&E)染色是组织病理学中最广泛使用的染色技术。
H&E染色的组织病理学切片成本低廉,易于获取。图1展示了肿瘤内TLSs在H&E染色切片上的代表性图像。因此,在H&E染色切片中评估TLSs可能更容易推广至临床实践。
图1展示了肿瘤区域内三级淋巴结构(TLS)的实例图像。
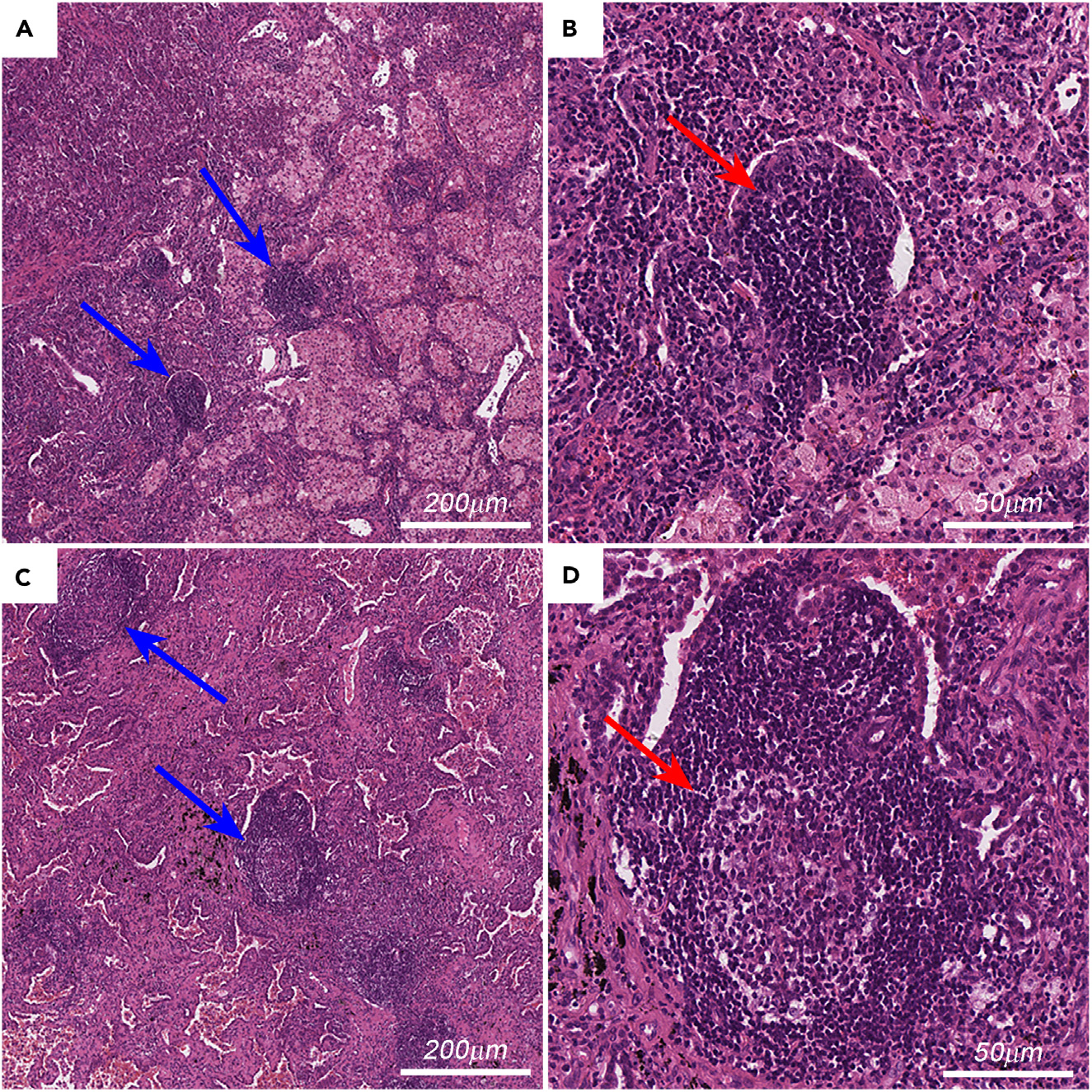
具体分析如下:
-
图A 展示了不成熟的TLS,呈现为密集的圆形或椭圆形的淋巴细胞团(蓝色箭头,100倍放大;刻度条,200微米)。这表明在肿瘤区域中,不成熟的TLS由紧密堆积的淋巴细胞构成。
-
图B 为图A中左下角一个不成熟TLS的更高放大倍数的图像(红色箭头,400倍放大,与图A中的左下角不成熟TLS对应;刻度条,50微米)。在更高放大倍数下,可以更清晰地观察到TLS的细节,如细胞的形态和排列。
-
图C 展示了成熟的TLS,具有生发中心(蓝色箭头,100倍放大;刻度条,200微米)。成熟的TLS通常包含一个或多个生发中心,这是B淋巴细胞增殖和分化的区域。
-
图D 为图C中一个成熟TLS的更高放大倍数的图像,生发中心显示为淡色区域(红色箭头,400倍放大,与图C中的中心成熟TLS对应;刻度条,50微米)。在更高放大倍数下,可以观察到生发中心的细微结构,这些结构在肿瘤免疫反应中起着关键作用。
总的来说,这些图像展示了肿瘤区域内TLS的不同成熟阶段,从不成熟的淋巴细胞团到包含生发中心的成熟结构,反映了肿瘤微环境中复杂的免疫状态。
已开发出几种方法15,16基于常规H&E染色的全切片图像(WSIs)对TLSs进行定量。然而,这些识别TLSs的方法仍由病理学家手动评估,耗时且依赖经验,重复性较差17。
随着计算机技术的快速发展18,有望开发出一种自动化、标准化的工作流程,用于高效、准确地评估LUAD常规H&E染色WSIs中的TLSs。
在本研究中,作者开发了一种自动化工作流程,用于量化H&E染色WSIs肿瘤区域中TLSs的密度,并使用三个独立的可切除LUAD患者数据集评估了TLS密度的预后价值。
作者假设TLS密度是疾病无进展生存(DFS)的独立预后因素,并将TLS密度与临床病理学变量结合,将提高可切除LUAD患者的预后分层。
二、结果
2-1:患者
本研究共收集了1196例可切除LUAD患者,最终802例患者符合纳入和排除标准(附加文件:图S1)。
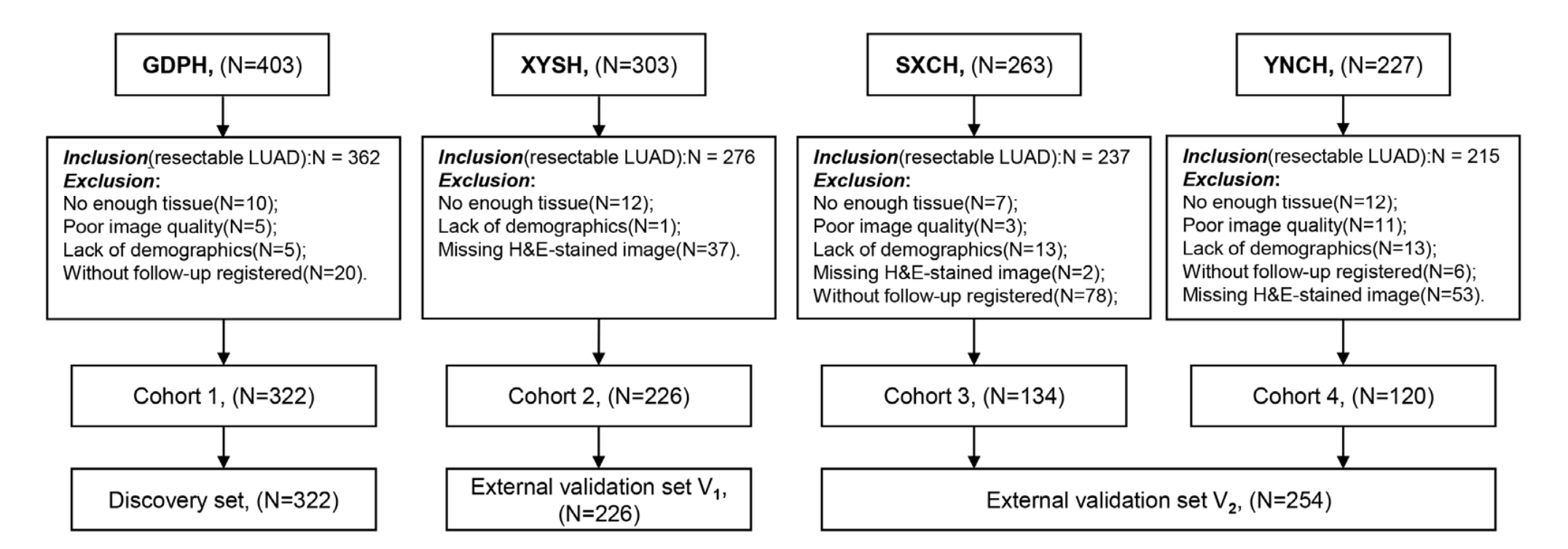
其中,来自广东省人民医院(GDPH)的322例患者组成发现集,来自中南大学湘雅二医院的226例患者组成外部验证集V1,来自山西省肿瘤医院的134例患者和来自云南省肿瘤医院的120例患者组成外部验证集V2。
发现集的中位随访时间为85.3(83.1–89.8)个月,外部验证集V1为60.2(58.5–62.7)个月,外部验证集V2为37.1(35.5–48.3)个月。三个数据集的基线临床病理学变量见表1。
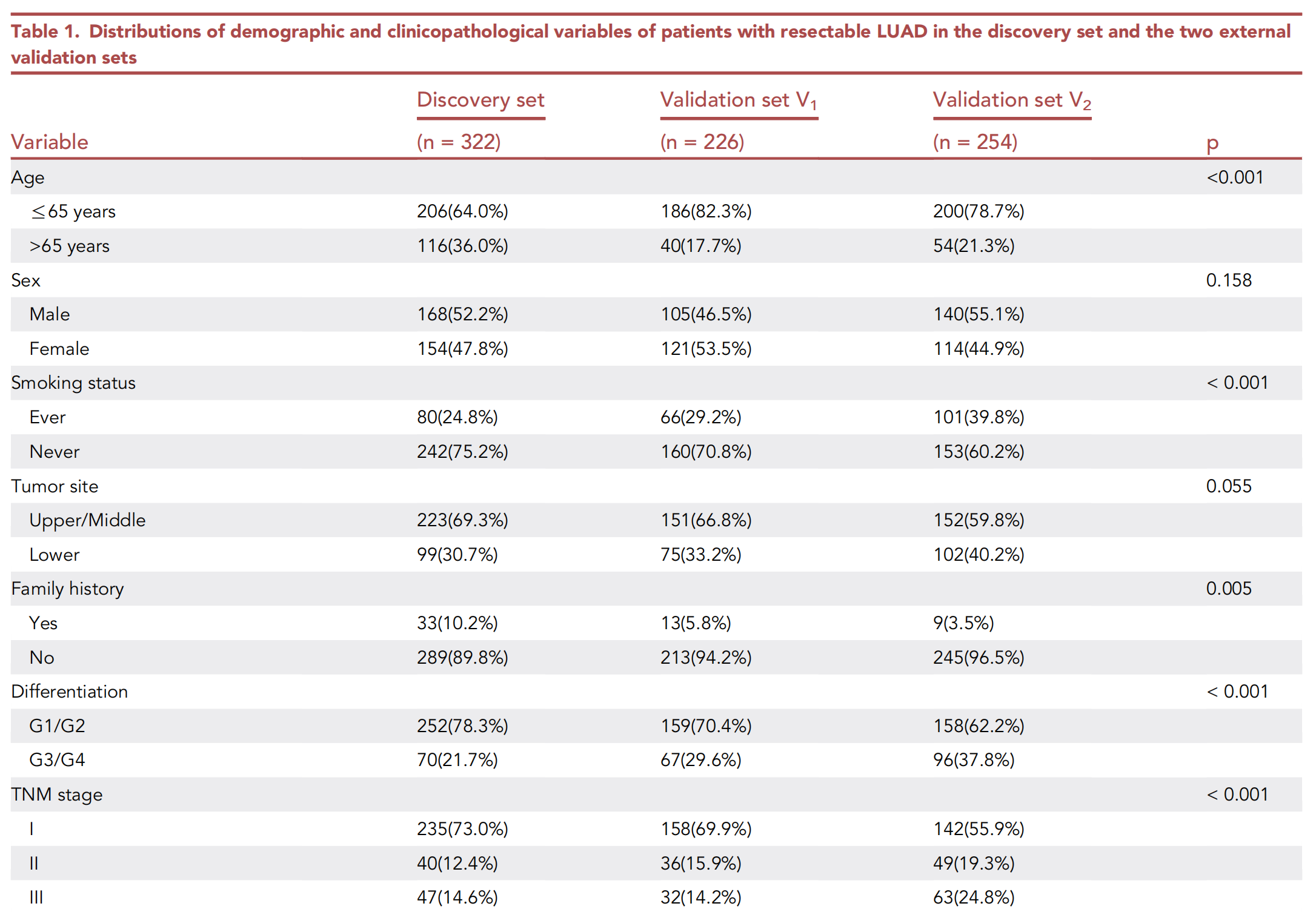
除性别(p = 0.158)和肿瘤部位(p = 0.055)外,三个数据集在所有纳入的临床病理学变量上均存在显著差异。
2-2:分割结果与一致性分析
Bland-Altman图显示,基于H&E染色WSIs的自动TLS计数与病理学家手动TLS计数之间的一致性良好(组内相关系数[ICC] = 0.894,95%CI:0.821–0.938,p < 0.001;图2A),基于IHC染色WSIs的一致性同样良好(ICC = 0.903,95%CI:0.836–0.944,p < 0.001;图2B)。
图2展示了Bland-Altman分析图,用于评估基于手动计数和自动计数的三级淋巴结构(TLS)数量之间的一致性。这种分析常用于评估两种测量方法的一致性或可比性。
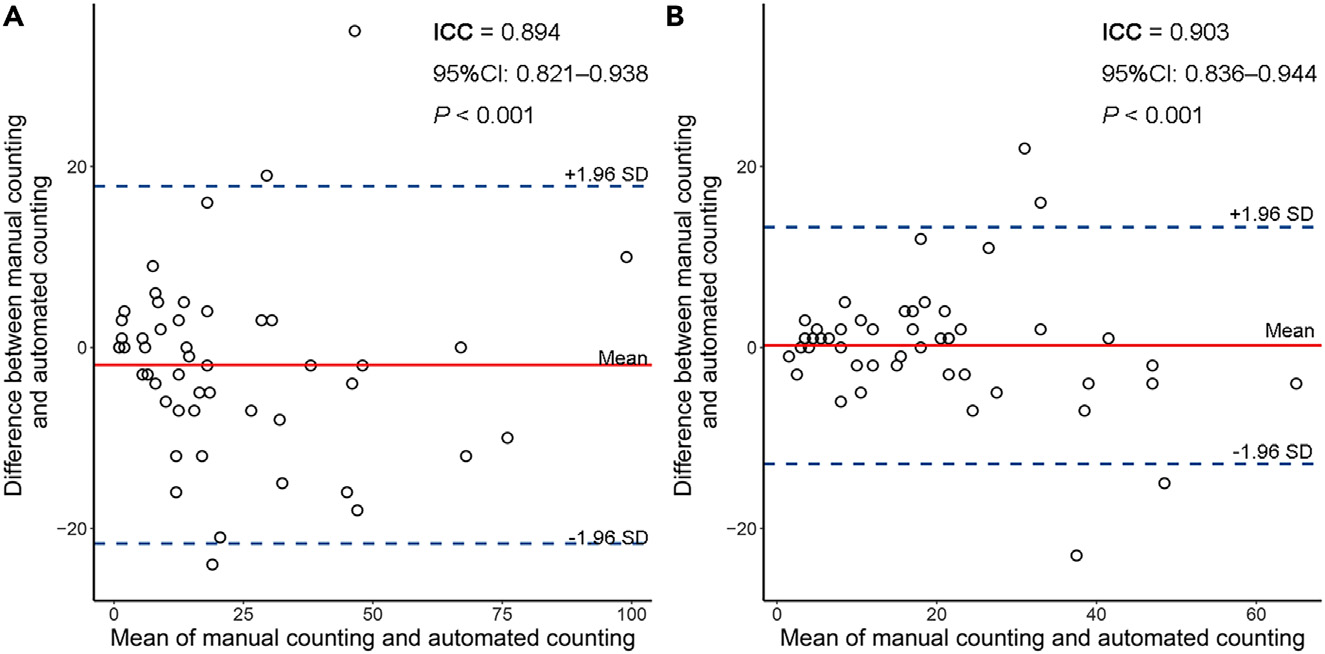
以下是对图2的详细分析:
图2(A) - 基于H&E染色的全切片图像(WSIs)
- 红色实线:表示手动计数和自动计数TLS数量之间差异的平均值(均值差)。如果这条线接近零,说明两种方法的平均差异较小,一致性较好。
- 蓝色虚线:表示95%的一致性限制(95% LoA),即上下界。这些界限表示了两种计数方法之间差异的可接受范围。如果大多数数据点落在这个范围内,这表明两种方法在统计上是一致的。
- ICC(内类相关系数):提供了一个统计量来衡量两种方法之间的一致性。ICC值接近1表示非常高的一致性。
图2(B) - 基于IHC染色的全切片图像(WSIs)
- 与图2(A)类似,这里也展示了基于免疫组化(IHC)染色WSIs的TLS手动计数与自动计数之间的Bland-Altman分析。
- 红色实线和蓝色虚线的意义与图2(A)相同,分别表示差异的均值和95% LoA。
- ICC同样用来衡量两种方法间的一致性。
分析结论
- 如果红色实线接近零,并且大多数数据点落在蓝色虚线表示的95% LoA内,这表明手动和自动TLS计数方法具有很好的一致性。
- ICC值越接近1,表示两种方法之间的一致性越好。通常,ICC值大于0.75被认为是良好的一致性,大于0.9则表示非常高的一致性。
这种分析对于验证自动化图像分析工具的准确性和可靠性至关重要,特别是在病理学诊断和生物标志物量化中。通过这种对比,研究人员可以对自动化计数方法进行校准和验证,以确保其在临床和研究中的有效应用。
附加文件:图S2展示了H&E染色WSIs上手动TLS标注和自动TLS分割的示例图像。在TLS识别中观察到良好的定性一致性。
2-3:TLS密度的预后价值
通过最大选择等级统计方法在发现集中确定TLS密度的截止值为0.489 TLSs/mm²。
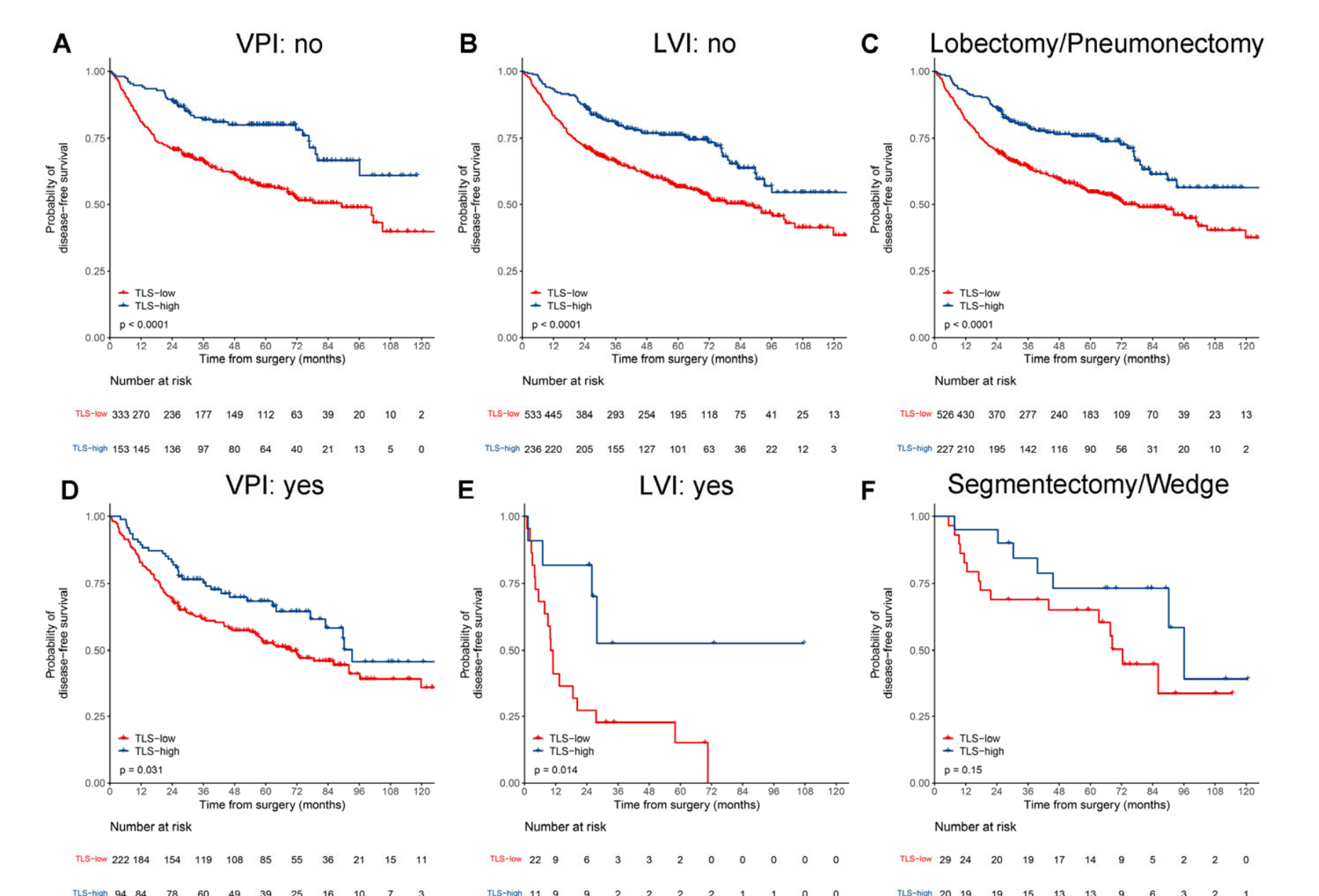
Kaplan-Meier曲线显示,在发现集(HR 0.66,95%CI 0.44–0.98,p = 0.037;图3A)和两个外部验证集(V1:0.60,0.39–0.93,p = 0.022;V2:0.29,0.16–0.55,p < 0.0001;图3B和3C)中,TLS低组与TLS高组相比DFS显著较差。
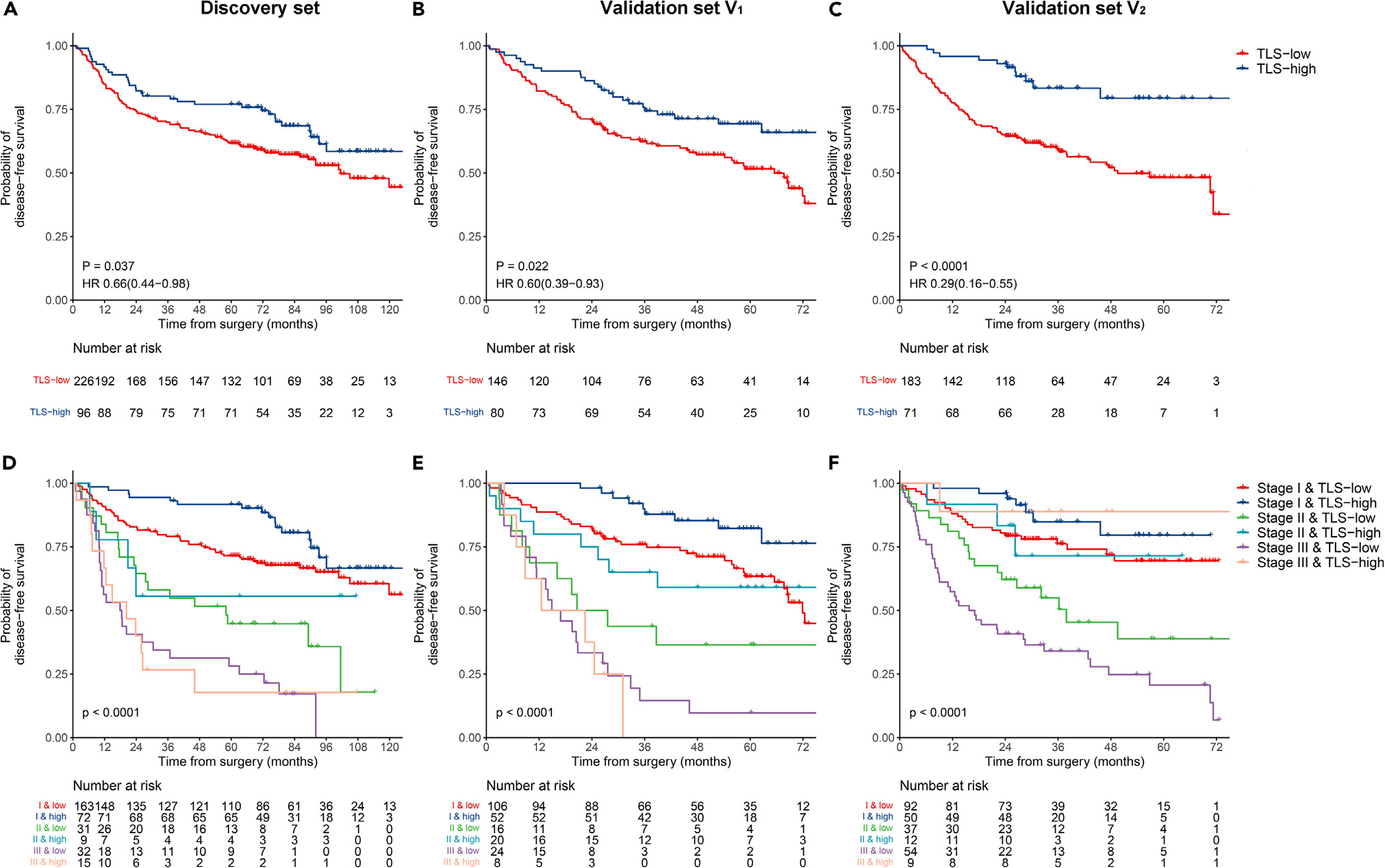
结合TLS密度和TNM分期后,三个数据集中可切除LUAD患者的风险分层变得更加精细(p < 0.0001;图3D–3F)。
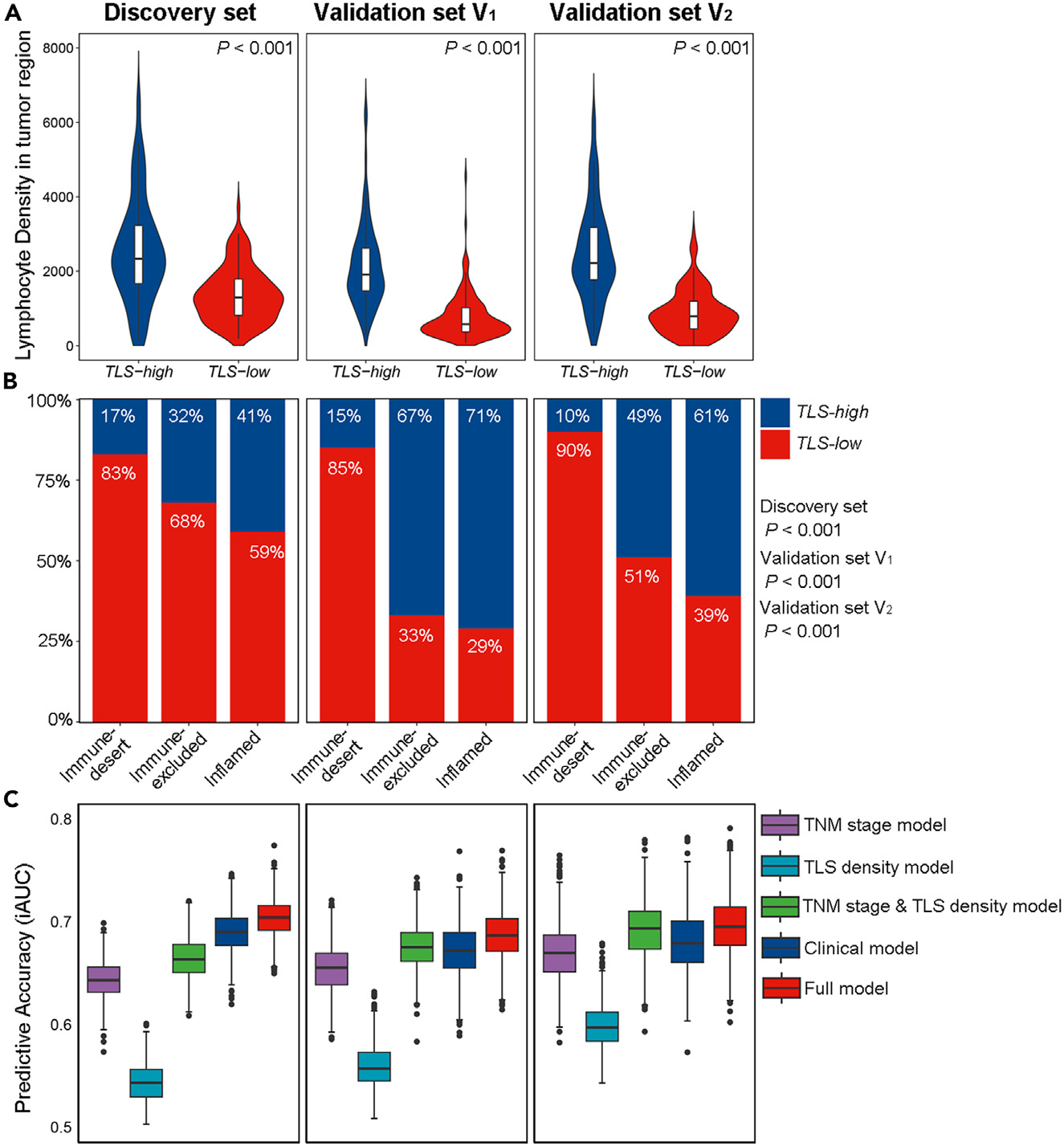
在图4A中,小提琴图显示,TLS高组肿瘤区域内的淋巴细胞密度显著高于TLS低组(p < 0.001)。此外,作者还观察到,在三个数据集中,低TLS密度与免疫荒漠表型显著相关(p < 0.001;图4B)。
图4展示了TLS密度与淋巴细胞密度、免疫表型的相关性以及预测模型的性能。
以下是对图4的详细分析:
图4(A) - TLS密度与淋巴细胞密度的关系
- 比较:比较了TLS高密度组和TLS低密度组在肿瘤区域内淋巴细胞密度的差异。
- 结果:TLS高密度组的淋巴细胞密度显著高于TLS低密度组(p < 0.001),使用Wilcoxon秩和检验进行分析。
- 意义:这表明TLS密度较高的区域有更多的淋巴细胞浸润,可能与更强的抗肿瘤免疫反应相关。
图4(B) - TLS密度与免疫表型的关系
- 分布:展示了三个数据集中TLS密度在不同免疫表型(immune phenotypes)的分布情况。
- 结果:TLS密度较低与免疫荒漠(immune-desert)表型相关联(p < 0.001),使用Cochran-Armitage趋势检验进行分析。
- 意义:免疫荒漠表型的肿瘤通常具有较差的免疫细胞浸润和较低的TLS密度,这可能与不良的预后相关。
图4© - 预测模型的性能
- iAUC:展示了每个模型经过1000次自助法(bootstrap)后的集成曲线下面积(integrated area under the curve)。
- 模型:
- 临床模型(Clinical model):包括吸烟状况、分化程度、TNM分期和淋巴血管侵犯(LVI)。
- 完整模型(Full model):在临床模型的基础上增加了TLS密度。
- 结果:以箱线图形式展示了三个数据集中每个模型的iAUC值。
- 意义:iAUC值越接近1,模型的预测性能越好。通过比较临床模型和完整模型的iAUC值,可以评估TLS密度作为预后生物标志物对模型预测性能的贡献。
分析结论:
- TLS密度与淋巴细胞密度:TLS密度高的肿瘤区域有更多的淋巴细胞浸润,这可能与肿瘤的免疫活性有关。
- TLS密度与免疫表型:TLS密度低的肿瘤更可能是免疫荒漠表型,这可能与较差的预后相关。
- 预测模型性能:完整模型(包含TLS密度)相比于仅包含临床特征的模型,可能具有更好的预测性能,这表明TLS密度是一个有潜力的预后生物标志物。
这些发现强调了TLS密度在评估肿瘤免疫微环境中的重要性,并可能有助于改善临床预后模型的预测准确性。
基于单变量分析的结果,性别、吸烟状况、TNM分期、分化等级、内脏胸膜侵犯(VPI)、淋巴血管侵犯(LVI)、辅助化疗、免疫表型和TLS密度被用作后续多变量分析的候选因素。
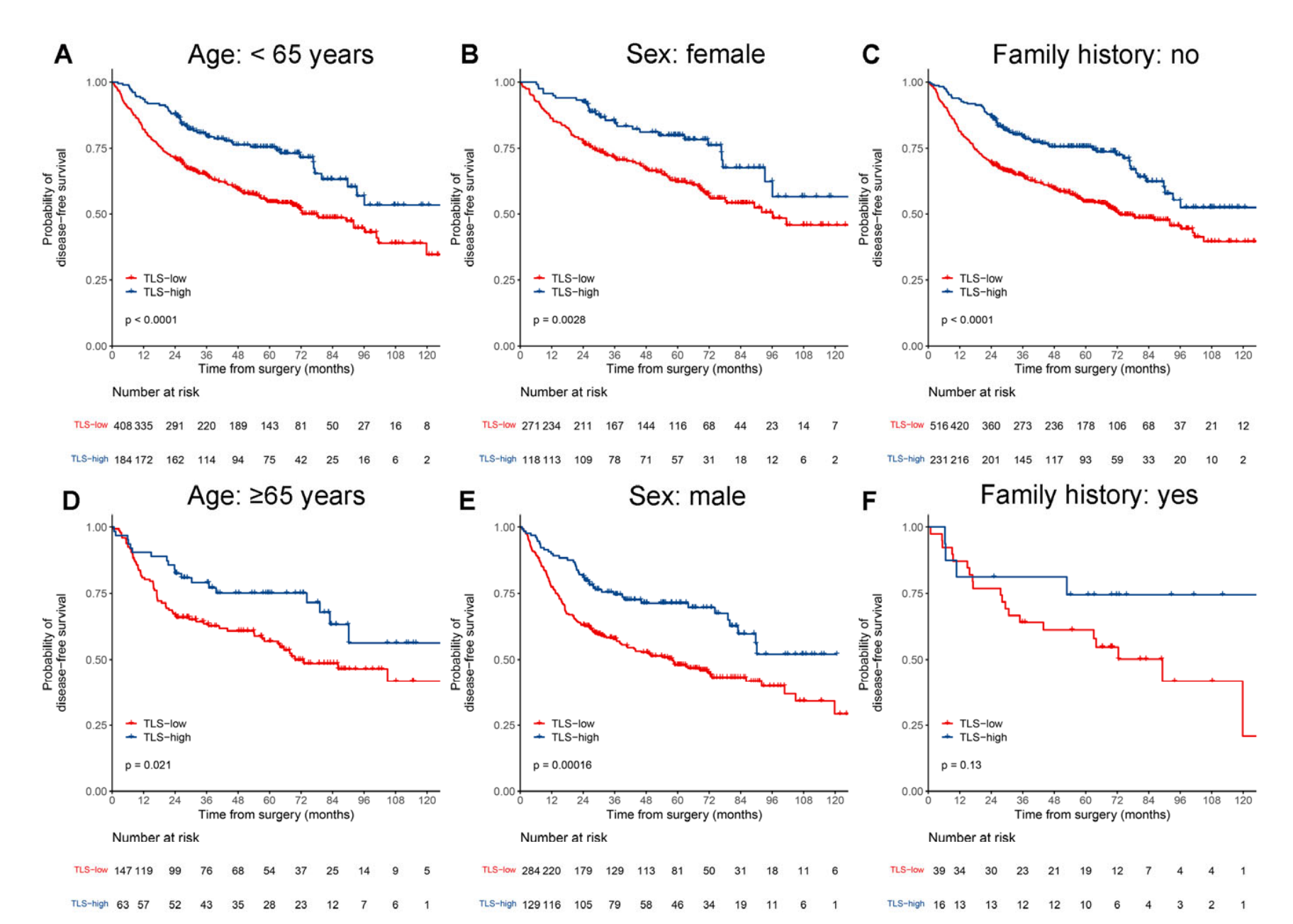
在多变量逐步Cox回归分析中,TLS密度在发现集(HR 0.61,95%CI 0.41–0.92,p = 0.017)和两个外部验证集(V1:0.60,0.37–0.95,p = 0.031;V2:0.32,0.17–0.60,p < 0.001;表2)中被证明是DFS的独立预后因素。
此外,在无逐步回归的多变量分析中,对单变量分析中p值小于0.05的因素进行调整后(表2)。
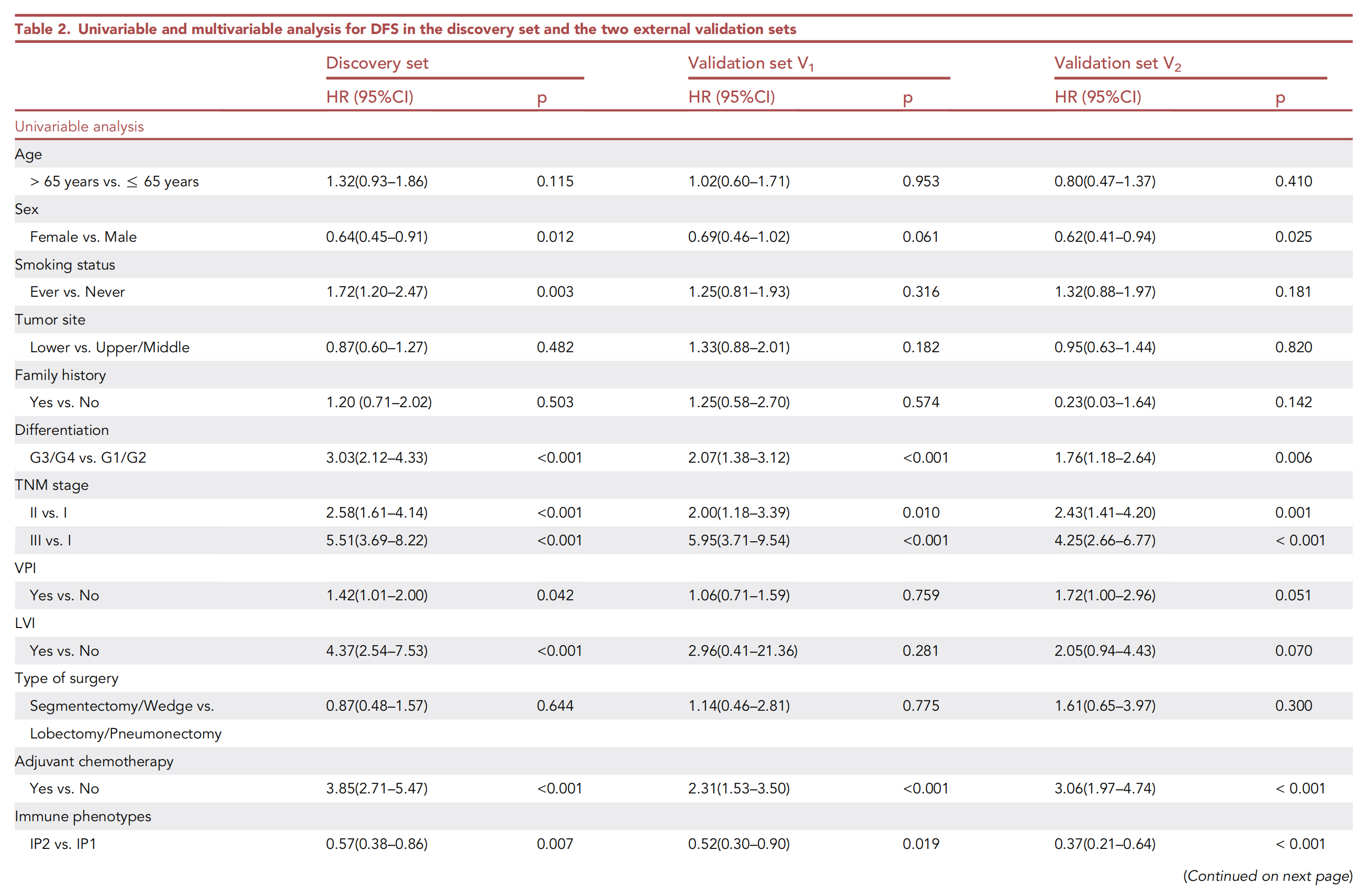
三个数据集中TLS密度的p值仍然低于0.05,进一步表明TLS密度是DFS的独立预后因素(附加文件:表S2)。
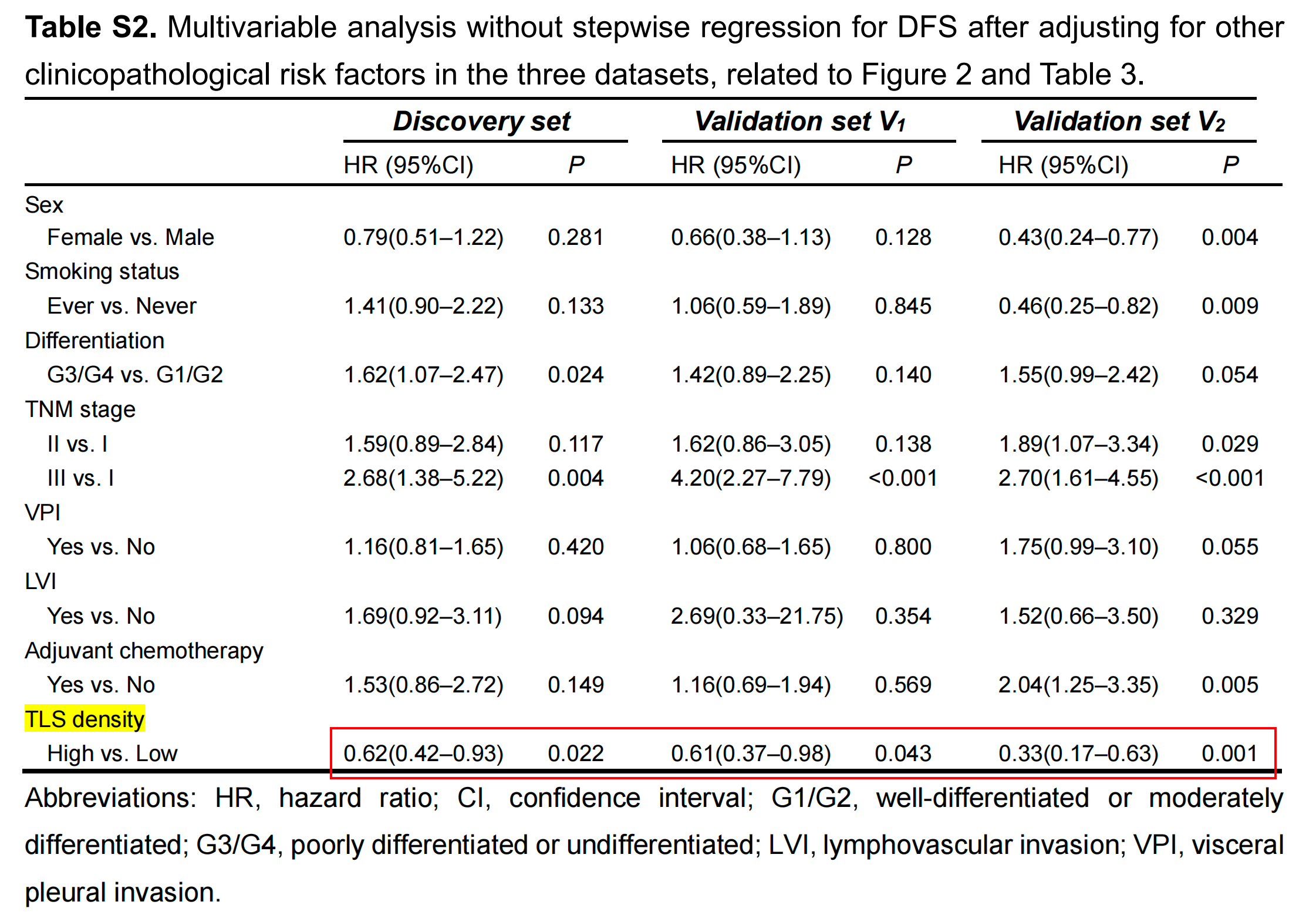
在亚组分析中,为了提高发现能力,将三个数据集中的所有患者合并。对于早期(I–II期)或TNM I期LUAD患者,TLS高组的DFS显著优于TLS低组(p < 0.001;附加文件:图S3A和S3B)。
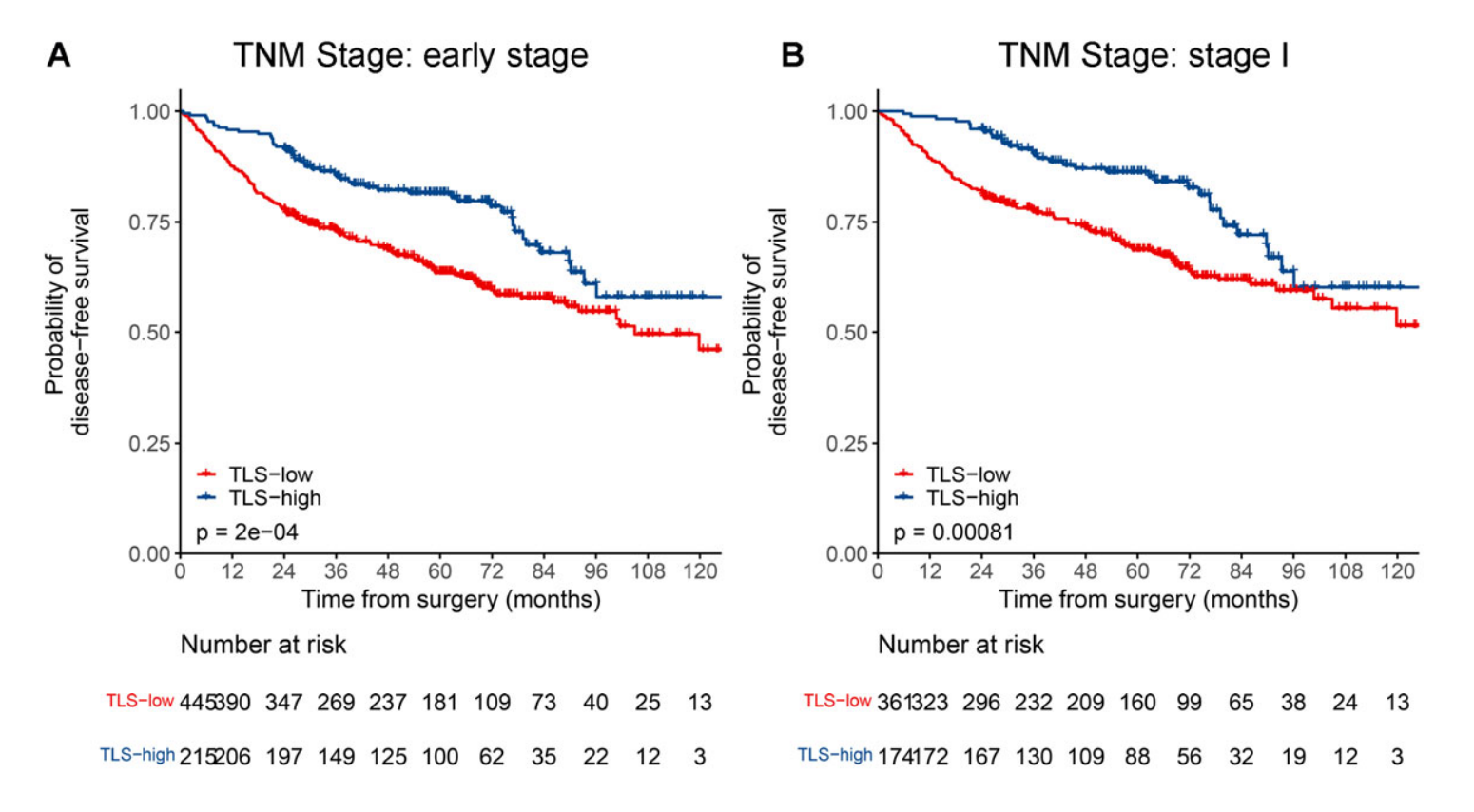
对于TNM I期和II期LUAD患者,TLS低组预后较差的趋势仍然存在(附加文件:图S3C和S3D),尽管没有发现统计学上的显著差异。
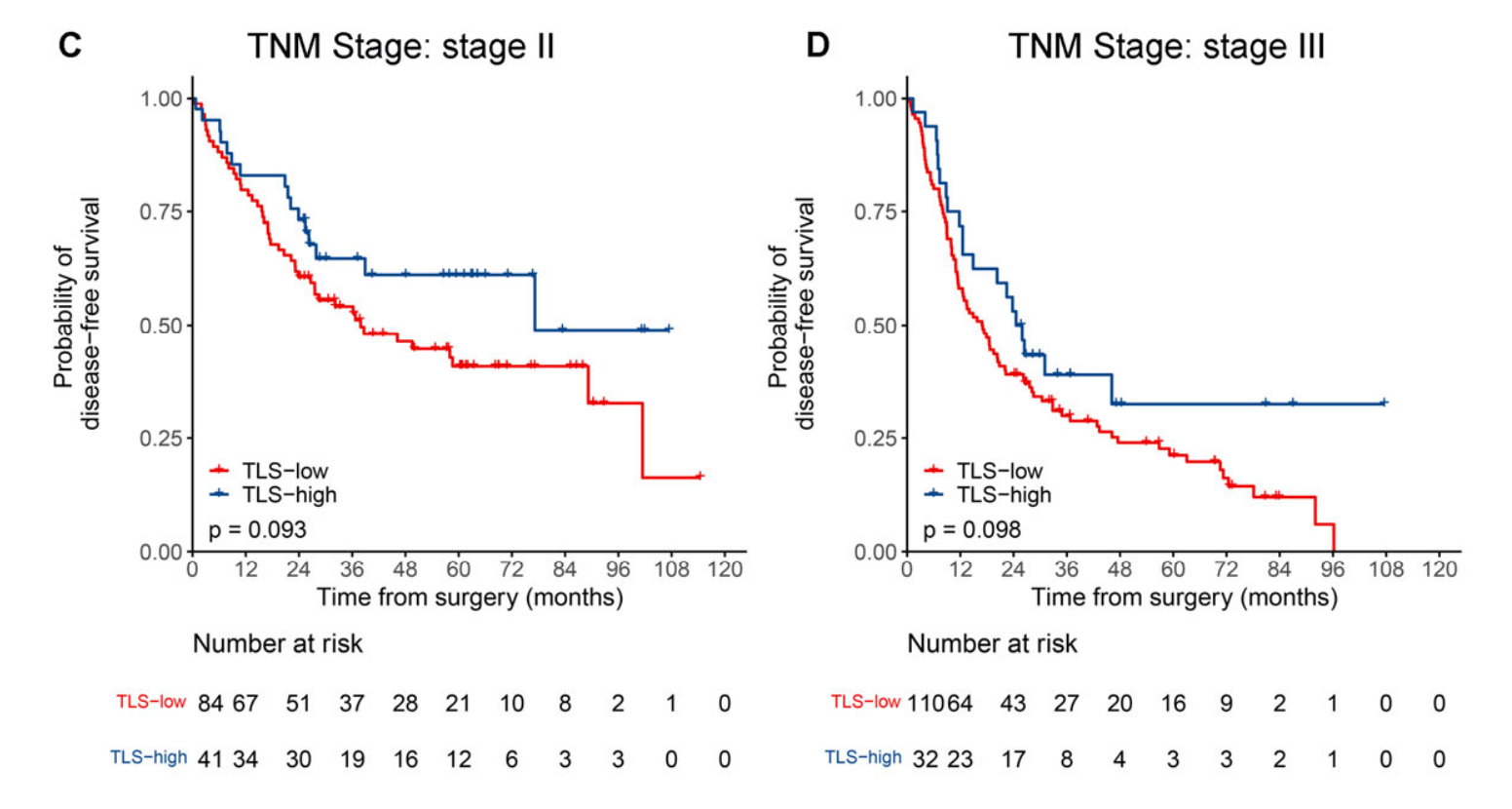
此外,在大多数按临床病理学变量(包括年龄、性别、吸烟状况、肿瘤部位、分化等级、VPI、LVI和辅助化疗)分层的亚组中也观察到了类似的趋势(附加文件:图S4和S5),除了按家族史、手术类型、表皮生长因子受体(EGFR)和间变性淋巴瘤激酶(ALK)分层的亚组。
2-4:预测模型的开发与验证
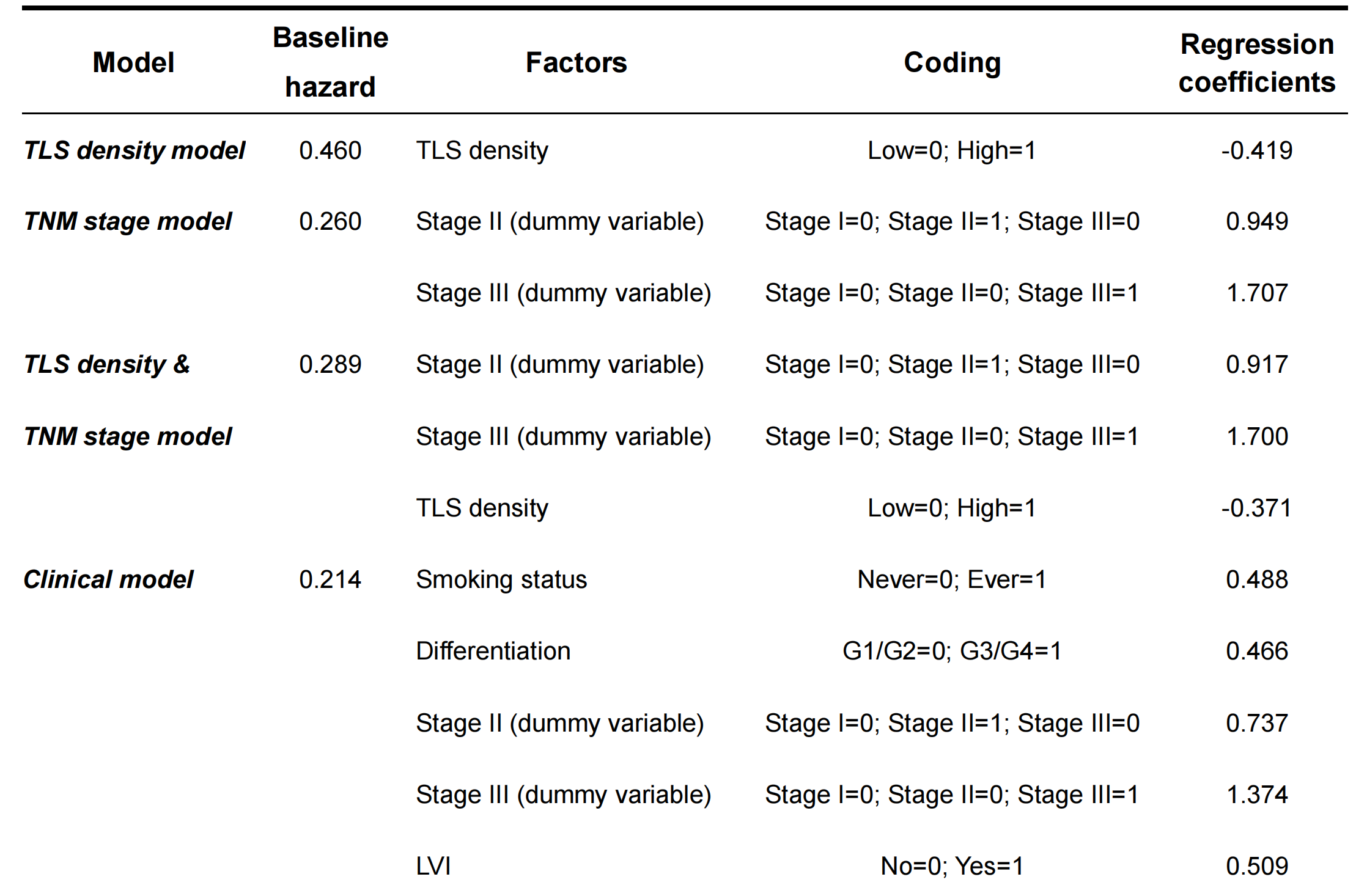
基于发现集中逐步选择方法确定的独立预后因素(即吸烟状况、分化等级、TNM分期、LVI和TLS密度;表2),建立了一个预测DFS的Cox模型(全模型)。
此外,为了进行性能比较,建立了另外四个参考模型,包括TNM分期模型、TLS密度模型、TNM分期和TLS密度模型以及临床模型(吸烟状况和分化等级和TNM分期和LVI)。每个预测模型的编码、回归系数和估计的5年基线危险度总结在附加文件:表S1中。
在三个数据集(表3)中评估了五个模型的性能。
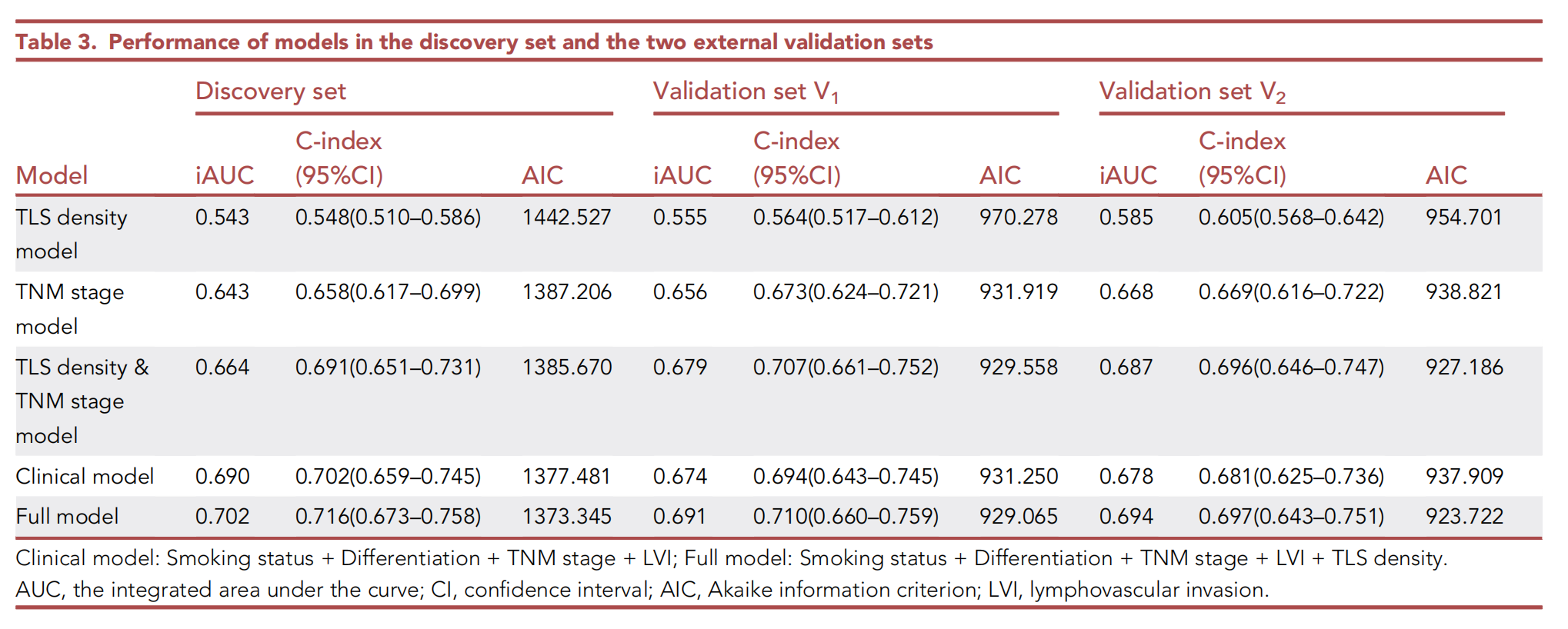
全模型在发现集中比临床模型具有更好的判别和校准能力(一致性指数[C指数] 0.716 vs. 0.702,综合曲线下面积[iAUC] 0.702 vs. 0.690,赤池信息准则[AIC] 1373.345 vs. 1377.481,似然比检验[LRT] p = 0.013;图4C)以及两个外部验证集(V1:C指数 0.710 vs. 0.694,iAUC 0.691 vs. 0.674,AIC 929.065 vs. 931.250;V2:C指数 0.697 vs. 0.681,iAUC 0.694 vs. 0.678,AIC 923.722 vs. 937.909)。
同样,TNM分期和TLS密度模型在三个数据集中与TNM分期模型相比也实现了更好的性能。
此外,5年时的时间依赖性受试者操作特征(ROC)曲线和不同时间点的时间依赖性曲线下面积(AUC)曲线显示在附加文件:图S6中。
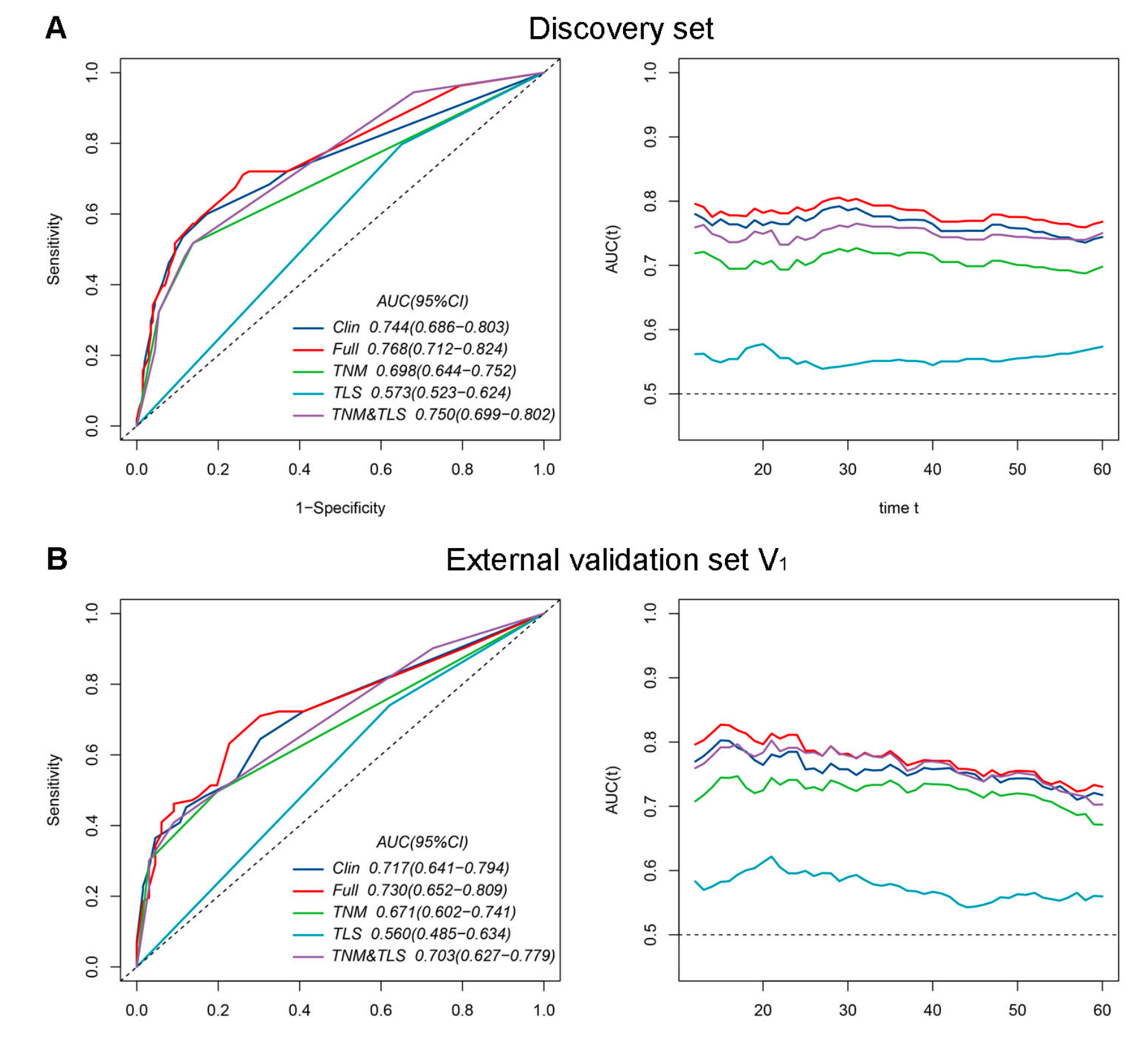
在三个数据集的大多数时间点上,全模型与临床模型相比展现出了更好的预测性能。
三、讨论
对于可切除的肺腺癌(LUAD)患者,准确的预后预测可以指导临床决策并改善风险分层。三级淋巴结构(TLSs)已被证实具有重要的预后价值。
然而,现有针对可切除LUAD中TLSs评估的方法缺乏客观、高效和准确的TLSs量化工作流程。因此,在本项多中心研究中,作者开发了一个自动化工作流程,基于常规H&E染色的Whole Slide Images(WSIs)访问肿瘤区域中TLSs的密度,并在三个独立的可切除LUAD患者数据集中评估了TLS密度对预测无病生存(DFS)的预后价值。
作者发现,TLS密度是可切除LUAD患者的独立预后因素,并且将TLS密度与临床病理学变量结合可以改善可切除LUAD的预后分层。
TLSs在有效的抗肿瘤免疫中发挥关键作用。
现有证据表明,TLSs的存在和密度较高与更好的预后相关。TLSs的预后价值已在几种实体肿瘤类型中得到评估。
例如,Horeweg等人的研究发现,子宫内膜癌患者中肿瘤内TLSs具有超越临床病理学和分子变量的强烈有利预后影响。Silina等人在人类肺鳞状细胞癌的肿瘤周围和肿瘤内区域分析了TLS的形成,并确定TLS密度是未经治疗患者的独立预后标志物。
近期研究确定了TLSs在肝癌患者中的预后价值,考虑了不同解剖亚区域(肿瘤内和肿瘤周围区域)和不同免疫类别的TLSs。然而,大多数先前的研究使用手动和定性的方法评估TLSs。
基于手动评估的方法量化TLSs非常耗时且容易受到观察者间变异性的影响。
在本研究中,作者综合参考了当前研究,并量化了肿瘤区域中的TLS密度。与上述研究不同,作者的研究开发了一个自动化管道,以标准化的方式评估TLS密度。
在肿瘤分割阶段,采用了迁移学习的方法,使用公开可用的带注释的数据集预训练分割模型。预训练模型使用少量带注释的LUAD组织病理学图像进行微调。
在组织分割和分类阶段,作者采用基于斑块级分类标签的弱监督方法,对组织病理学图像进行语义分割。此外,本研究中基于H&E染色WSIs的手动TLS计数(ICC = 0.894;p < 0.001)或基于IHC染色WSI的手动TLS计数(ICC = 0.903,p < 0.001)与自动化TLS计数之间存在良好的一致性,如图2和附加文件:图S2所示。
因此,与基于手动评估的方法相比,自动化工作流程不仅可以减轻病理学家的注释工作量,还可以提高可重复性和可靠性。
在大多数针对肺癌的研究中,TLSs是基于多重免疫组化(mIHC)或多重免疫荧光(mIF)图像进行评估的,这些方法在临床设置中并不常规使用。
在作者的研究中,设计了一个基于LUAD常规H&E染色WSIs的工作流程来评估TLSs,这可能更容易促进临床应用。在肺癌的背景下,目前只有有限的研究在开发TLSs检测和分析的自动化方法方面取得了进展。
Barmpoutis等人提出了一种自动识别和量化TLS的方法,并通过椭圆模型对淋巴细胞进行分割。这个管道在临床应用中显示出巨大潜力,但研究并未分析其用于风险分层的价值。
Kushnarev等人进行的初步研究设计了一个数字成像分析平台,用于识别LUAD的H&E染色WSIs上的TLSs,并在独立队列中通过患者分层进行了总体生存分析。
相比之下,作者在来自中国不同地区的三个独立数据集中验证了自动化工作流程中量化的TLS密度在预后能力上的价值。
作者发现,在三个数据集中,TLS密度是一个独立的预后因素,尽管这些数据集在基线特征上存在统计学上的显著差异(表1)。
此外,量化的TLS密度与DFS的相关性在大多数按年龄、性别、吸烟状况、肿瘤部位、分化程度和TNM分期分层的亚组中得到了进一步验证(附加文件:图S3和S4)。
将TLS密度纳入TNM分期模型和临床模型后,含有TLS密度的模型在三个数据集中的判别和校准能力比不含TLS密度的模型更好(表3和图4C)。
这些结果表明,量化的TLS密度是预测可切除LUAD患者DFS的稳健生物标志物,有望在临床上得到更广泛的应用。
根据肿瘤浸润淋巴细胞的空间分布,肿瘤微环境可以被分类为三种免疫表型,包括炎症型、免疫排斥型和免疫荒漠型。
在本研究中,作者发现炎症免疫表型的患者倾向于有更好的预后,而免疫荒漠表型的患者倾向于有更差的预后(表2;附加文件;图S7)。
近期研究显示,不同的免疫表型可能对应于不同的抗肿瘤免疫反应。其中,炎症表型通常伴随着强烈的炎症反应,"炎症"肿瘤表现出更密集的免疫细胞浸润。肿瘤区域内TLSs的形成可能促进免疫反应的产生。
因此,TLSs的存在或增加在LUAD的炎症表型中更为常见,而在免疫排斥和免疫荒漠表型中TLSs的存在可能相对较少。这一关联与作者的发现一致(p < 0.001;图4B)。
此外,计算机化的TLS密度在多变量分析中被识别为DFS的独立预后因素(表2)。相反,免疫表型并未独立与可切除LUAD的DFS相关,这可能表明量化的TLS密度具有提供更强预测力的潜在可能。
综上所述,作者开发了一个自动化计算工作流程,用于量化常规H&E染色WSIs肿瘤区域中的TLSs,并分析了TLS密度与可切除LUAD患者DFS之间的关系。
本研究表明,量化的TLS密度是一个具有良好可靠性、可重复性和普遍适用性的独立预后生物标志物,并且将TLS密度与临床病理学变量结合可以改善患者分层,从而指导个性化的临床决策。
四、研究的局限性
本研究亦存在若干局限性。首先,作为一项回顾性研究,其固有局限性在于无法进行随机化设计。未来作者将进一步在更大的前瞻性队列中验证TLS密度的预后价值。
其次,本研究是基于组织分割结果间接量化TLSs,由于TLSs形态学的变异,TLSs计数存在一定程度的偏差。尽管如此,自动化TLSs计数与手动TLSs计数方法之间的一致性良好。
同时,作者目前正在开发一个完全自动化的工作流程,以直接在H&E染色的WSIs上识别TLSs,从而进一步提高TLSs计数的准确性。
此外,作者还将根据TLSs的成熟程度将其分类为淋巴聚集物、初级滤泡和具有生发中心的次级滤泡,并评估它们在可切除LUAD患者预后影响上的差异。
五、实验模型与研究对象细节
5-1:患者
本研究是一项回顾性研究,纳入了中国不同地区四家机构(广东省人民医院GDPH、中南大学湘雅二医院XYSH、山西省肿瘤医院SXCH和云南省肿瘤医院YNCH)的可切除肺腺癌(LUAD)患者。
研究时间跨度为GDPH(2007年11月至2014年12月)、XYSH(2013年8月至2017年12月)、SXCH(2014年7月至2020年11月)和YNCH(2012年9月至2014年7月)。
疾病无进展生存期(DFS),定义为从手术到复发或死亡的时间间隔,被确定为感兴趣的研究终点。
作者从医疗信息系统收集了基线和临床病理学变量,包括手术时的年龄、性别、吸烟状况、家族史、肿瘤部位、分化等级、TNM分期、VPI、LVI、手术类型、EGFR、ALK和辅助化疗。
排除了临床病理学变量缺失、接受新辅助治疗、剩余残留肿瘤(R1/R2切除)以及有其他恶性肿瘤病史的病例。
5-2:组织切片数字化
作者从原发性肿瘤的H&E染色诊断切片中获取了数字化全切片图像(WSIs)。H&E染色的诊断切片在GDPH和YNCH使用Leica Aperio-AT2扫描仪(美国,0.252μm/像素)、在XYSH使用Leica Aperio-GT450扫描仪(美国,0.264μm/像素)、在SXCH使用Hamamatsu扫描仪(日本,0.220μm/像素)以40倍放大率进行扫描。
此外,作者还收集了GDPH中与本研究常规H&E染色切片相邻的CD3染色的可用切片。这些免疫组化(IHC)染色的切片通过Leica Aperio-AT2扫描仪(美国,0.252μm/像素)以40倍放大率进行数字化。
图像质量由一名经验丰富的病理学家(B.B.L.)在不了解患者临床信息的情况下进行审查,并排除了模糊、含有伪影、染色不良或肿瘤组织不足的WSIs。
六、方法细节
6-1:组织和细胞分割与分类
本研究概述如下所示。肿瘤区域的半自动分割采用与作者先前研究相同的策略。31
为了减少注释工作量,作者使用迁移学习训练了一个ResNet5029模型进行肿瘤区域分割。作者从Camelyon1630数据集中提取了数百万个小型的正负图像块来预训练模型。
作者使用来自GDPH的67个注释的LUAD WSIs对预训练模型进行了微调。微调模型被用于来自四家医院的 所有WSIs的肿瘤区域分割。肿瘤区域的分割掩模由一名病理学家(B.B.L.)肉眼检查,并手动校正了不完美的掩模(见下图)。
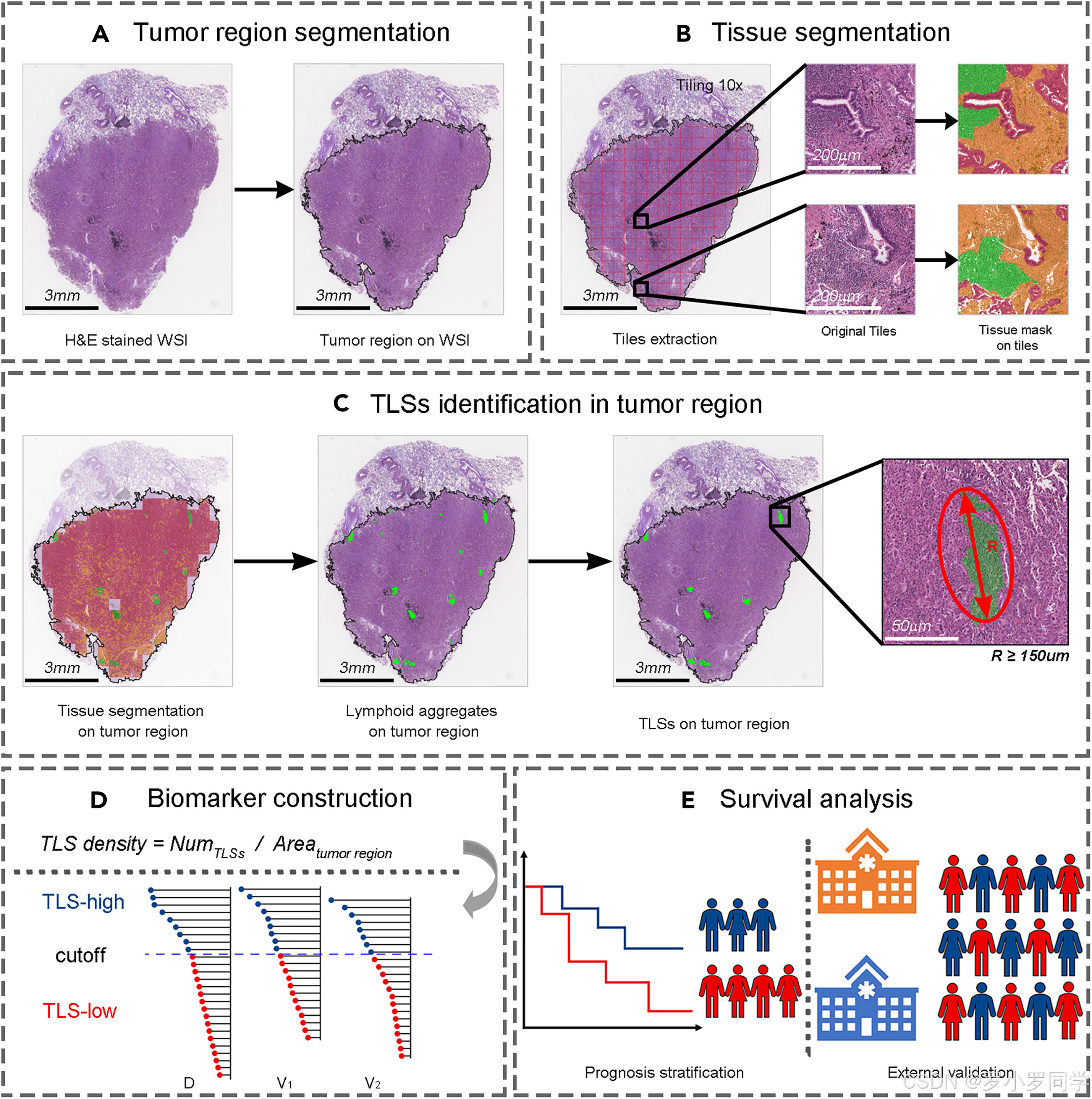
基于肿瘤区域分割的结果,作者采用了基于块级分类标签的弱监督语义分割方法28来执行肿瘤区域内的组织分割,最终减少了注释的工作量。该方法在10×放大倍数下将肿瘤区域分类为肿瘤上皮、肿瘤间质和淋巴细胞聚集。
此外,作者部署了Hover-Net27在40×放大倍数下对肿瘤区域内的细胞进行分割和分类。
这些细胞被归类为肿瘤细胞、间质细胞、淋巴细胞和其他细胞。作者识别了淋巴细胞所在的组织区域,并获得了癌上皮、间质和整个肿瘤区域内的淋巴细胞密度。23,32
然后,作者使用淋巴细胞密度数据量化了三种免疫表型(即炎症型、免疫排斥型和免疫荒漠型)。24
6-2:TLS密度量化
TLS密度的量化采用以下程序(见组织和细胞分割与分类中的图)。
首先,作者计算了每个WSI的肿瘤区域面积。基于预先分割的组织分割掩模,作者排除了直径小于150μm的淋巴聚集物13,并获得了TLSs的最终分割掩模。
最后,作者定义TLS密度为肿瘤区域内的TLS数量与整个肿瘤面积的比例,如下所示:
T L S 密度 = 肿瘤区域内的 T L S 数量 肿瘤区域面积 TLS密度 = \frac{肿瘤区域内的TLS数量}{肿瘤区域面积} TLS密度=肿瘤区域面积肿瘤区域内的TLS数量
为了对患者进行分层,作者使用最大选择等级统计方法33在发现集中确定截止值。TLS密度低于截止值的患者属于TLS低组,而TLS密度大于或等于截止值的患者属于TLS高组(见组织和细胞分割与分类中的图)。
为了分析手动计数与TLS自动计数之间的一致性,作者从所有可用的组织病理学图像中随机选择了50个H&E染色的WSIs和50个IHC染色的WSIs。
一名经验丰富的病理学家(B.B.L.),在不知道自动TLS分割结果的情况下,手动识别了这些选定WSIs上的TLSs,并确定了每个WSI肿瘤区域内的TLS计数。
本研究中的手动计数使用Aperio ImageScope(版本12.3.2)进行。使用ICC和Bland-Altman图来评估基于H&E染色的WSIs或基于IHC染色的WSIs的手动TLS计数与作者的量化方法的自动TLS计数之间的协议。
6-3:量化与统计分析
分类数据以计数(百分比)报告。三个数据集之间的差异通过Pearson卡方检验进行比较。中位随访时间通过逆Kaplan–Meier方法估计。使用对数秩检验来估计TLS低组和TLS高组之间DFS的差异。通过Wilcoxon秩和检验比较TLS高组和TLS低组肿瘤区域内淋巴细胞密度的分布。使用Cochran-Armitage趋势检验来分析TLS密度与免疫表型之间的关联。
使用Wald检验在单变量Cox回归分析中评估TLS密度和其他临床变量的预后能力。在单变量分析中达到统计学显著性(P值小于0.05)的变量被保留为后续多变量分析的候选变量。
基于AIC的多变量逐步Cox回归分析用于确定DFS的最优预测模型。预测模型的区分能力通过Harrell的C指数34和iAUC(1000次引导重采样的AUC)来衡量。模型的校准通过AIC来评估。
在5年DFS的预测准确性通过时间依赖的ROC和AUC曲线来衡量。使用LRT来确定模型间差异是否显著。此外,为了进一步证明TLS密度是一个独立的预后因素,还使用了不包括逐步回归的多变量分析来分析单变量分析中达到P<0.05的所有变量。
所有统计分析使用R[36]软件(版本4.1.2,www.R-project.org)进行,使用的包包括survival, survminer, lmtest, risksetROC和vioplot。P<0.05(双尾)被认为具有统计学意义。
相关文章:
肺腺癌预后新指标:全切片图像中三级淋巴结构密度的自动化量化|文献精析·24-10-09
小罗碎碎念 本期这篇文章,我去年分享过一次。当时发表在知乎上,没有标记参考文献,配图的清晰度也不够,并且分析的还不透彻,所以趁着国庆假期重新分析一下。 这篇文章的标题为《Computerized tertiary lymphoid structu…...
基于jmeter+perfmon的稳定性测试记录
1. 引子 最近承接了项目中一些性能测试的任务,因此决定记录一下,将测试的过程和一些心得收录下来。 说起来性能测试算是软件测试行业内,有些特殊的部分。这部分的测试活动,与传统的测试任务差别是比较大的,也比较依赖…...
前沿论文 M5Product 组会 PPT
对比学习(Contrast learning):对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。假设一个试图理解世界的新生婴儿。在家里,假设有两只猫和…...

navicat~导出数据库密码
当我们mysql密码忘记了,而在navicat里有记录,我们应该如何导出这个密码呢? 第一步:文件菜单,导出链接,导出连接获取到 connections.ncx 文件 这里需要勾选 导出密码!!! 不然导出的文…...
【Java】 —— 数据结构与集合源码:Vector、LinkedList在JDK8中的源码剖析
目录 7.2.4 Vector部分源码分析 7.3 链表LinkedList 7.3.1 链表与动态数组的区别 7.3.2 LinkedList源码分析 启示与开发建议 7.2.4 Vector部分源码分析 jdk1.8.0_271中: //属性 protected Object[] elementData; protected int elementCount;//构造器 public …...
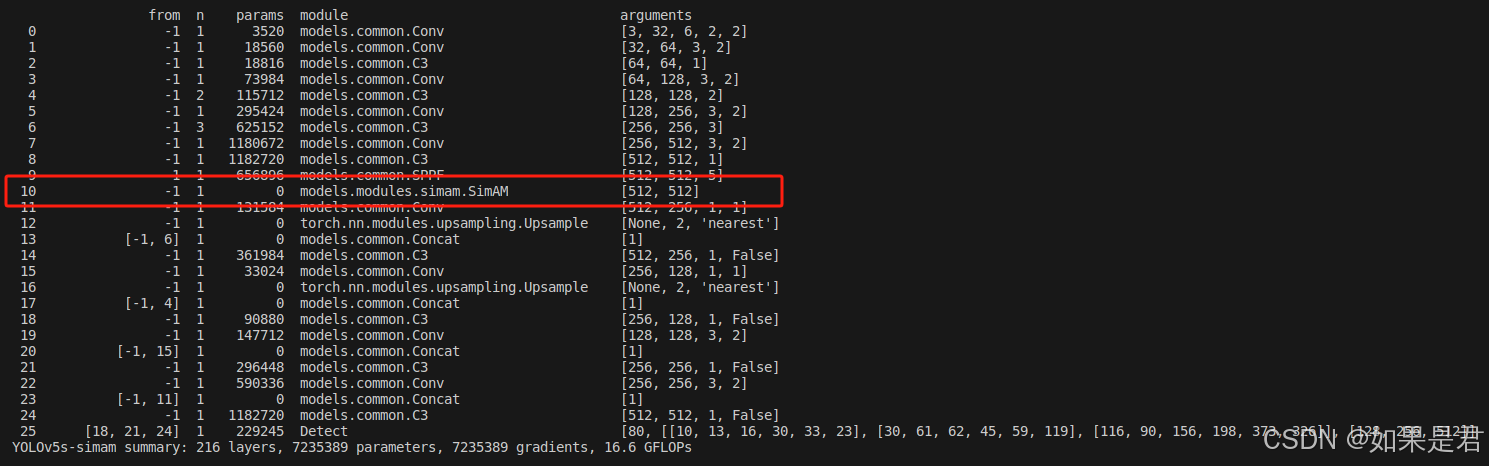
YOLOv5改进——添加SimAM注意力机制
目录 一、SimAM注意力机制核心代码 二、修改common.py 三、修改yolo.py 三、建立yaml文件 四、验证 一、SimAM注意力机制核心代码 在models文件夹下新建modules文件夹,在modules文件夹下新建一个py文件。这里为simam.py。复制以下代码到文件里面。 import…...

SQL 自学:表别名的运用与对被联结表使用聚集函数
一、表别名的概念与作用 (一)表别名的定义 表别名是为表指定的临时名称,在 SQL 查询中使用别名可以简化表名,提高代码的可读性和可维护性。当表名较长或在复杂的查询中多次引用表时,使用表别名可以避免重复输入冗长的…...

jmeter学习(2)变量
1)用户定义的变量 路径:添加-》配置元件-》用户定义的变量 用户定义的变量是全局变量,可以跨线程组被调用,但在启动运行时获取一次值,在运行过程中不再动态获取值。 注意的是,如果在某个线程组定义了全…...

【C#生态园】C#文件压缩库全面比较:选择最适合你的库
从核心功能到API概览:深度解析六大C#文件压缩库 前言 在软件开发过程中,文件的压缩和解压缩是一个常见的需求。针对C#开发者而言,选择合适的文件压缩库可以极大地简化开发工作。本文将介绍几个常用的C#文件压缩库,包括其核心功能…...

【测试】接口测试与接口自动化
壹、接口测试基础 一、接口测试概念 I、基础概念 是测试系统组件间接口的一种测试。 主要用于检测外部系统与系统间、内部子系统间的交互点;测试重点检查数据的交换、传递和控制管理过程,以及系统间的相互逻辑依赖关系。 内部接口调用相当于函数调用&am…...

Android设置边框圆角
在Android开发中,圆角设计十分常见,那么实现边框圆角有几种形式呢? 文章目录 设置圆角边框样式使用ClipToOutline进行裁切最后 设置圆角边框样式 常见的方式是在drawable文件夹下设置一个xml文件的边框样式,比如 <shape andro…...

SpringBoot项目打成jar包,在其他项目中引用
1、首先新建一个SpringBoot工程 记得要将Gradle换成Maven 2、新建一个要引用的方法 3、打包的时候要注意: ① 不能使用springboot项目自带的打包插件进行打包,下面是自带的: ②要换成传统项目的maven打包,如下图: 依…...

【音频可视化】通过canvas绘制音频波形图
前言 这两天写项目刚好遇到Ai对话相关的需求,需要录音功能,绘制录制波形图,写了一个函数用canvas实现可视化,保留分享一下,有需要的直接粘贴即可,使用时传入一个1024长的,0-255大小的Uint8Arra…...

解决github每次pull push输入密码问题
# 解决git pull/push每次都需要输入密码问题 git bash进入你的项目目录,输入: git config --global credential.helper store然后你会在你本地生成一个文本,上边记录你的账号和密码。配置项写入到 "C:\Users\用户名\ .gitconfig" …...
IO 流 - 标准输入输出流、InputStreamReader 和 OutputStreamWriter)
Java重修笔记 第六十四天 坦克大战(十四)IO 流 - 标准输入输出流、InputStreamReader 和 OutputStreamWriter
标准输入输出流 1. System.in 标准输入流 本质上是一个InputString,对应键盘,表示从键盘输入。 定义:public final static InputStream in null; 所以 Scanner scanner new Scanner(System.in); 会从键盘中获取数据 2. System.out 标准输…...

prctl的函数和pthread_self函数
1.prctl的函数原型如下: #include<sys/prctl.h> prctl(PR_SET_NAME, “process_name”);第一个参数是操作类型,指定PR_SET_NAME(对应数字15),即设置进程名; 第二个参数是进程名字符串,…...

Vim 命令行模式下的常用命令
Vim 命令行模式下的常用命令 文件操作: :w :保存当前文件。:w filename :将当前内容另存为指定的 filename 。:q :退出 Vim,如果文件有修改但未保存,会提示错误。:q! :强制退出 Vim,…...
】力扣2826. 将三个组排序)
【动态规划-最长递增子序列(LIS)】力扣2826. 将三个组排序
给你一个整数数组 nums 。nums 的每个元素是 1,2 或 3。在每次操作中,你可以删除 nums 中的一个元素。返回使 nums 成为 非递减 顺序所需操作数的 最小值。 示例 1: 输入:nums [2,1,3,2,1] 输出:3 解释: …...

Elastic Stack--16--ES三种分页策略
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 方式一:from size实现原理使用方式优缺点 方式二:scroll实现原理使用方式优缺点 方式三:search_after实现原理使用方式优缺点 三…...

[LeetCode] 315. 计算右侧小于当前元素的个数
题目描述: 给你一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。 题目链接: . - 力扣(LeetCode) 题目主要思路&a…...

RK3562核心板选型与开发实战:从硬件拆解到软件适配
1. 项目概述:为什么是PET_RK3562_CORE? 在嵌入式开发领域,尤其是智能硬件和物联网设备的设计中,核心板的选择往往是决定项目成败、成本控制和技术路线的关键一步。最近几年,基于ARM架构的国产化芯片方案异军突起&#…...

为你的Hermes Agent项目配置Taotoken作为自定义模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent项目配置Taotoken作为自定义模型提供商 应用场景类,假设你正在使用Hermes Agent框架并希望接入更多…...

软件测试从思维到实战:测试设计黄金法则与黑盒/灰盒/白盒全解析
📌为什么你的测试用例找不到Bug?你是否遇到过这样的场景:辛辛苦苦写了几十个测试用例,执行完发现一切正常,信心满满地发布上线。结果用户一用,马上就发现了严重问题。问题出在哪里?不是你的执行…...

ThinkPHP8.x全面升级:现代化PHP开发新标杆
好的,我们来梳理一下 ThinkPHP 8.x 版本(通常指 8.0 及后续小版本)的主要特性和改进方向。相较于之前的版本(如 5.x),8.x 版本在架构、性能、规范性和安全性上都有显著提升:核心方向与重大变更&…...

2025年网盘直链下载神器:LinkSwift完全使用指南与深度解析
2025年网盘直链下载神器:LinkSwift完全使用指南与深度解析 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

从MapReduce到Spark:深入理解reduceByKey的‘预聚合’是如何继承并超越Hadoop的Combiner的
从MapReduce到Spark:深入理解reduceByKey的‘预聚合’如何继承并超越Hadoop的Combiner 在分布式计算的演进历程中,数据处理模式的优化往往体现在对既有范式的精炼与重构。当开发者从Hadoop生态转向Spark时,reduceByKey操作符的设计哲学尤其值…...

扩散模型在机器人控制中的多模态优化应用
1. 扩散模型在近似模型预测控制中的创新应用在机器人控制领域,模型预测控制(MPC)因其优秀的约束处理能力和优化性能而广受青睐。然而,传统MPC需要在线求解优化问题,计算成本高昂,难以满足高速实时控制的需求…...

FFXIV TexTools深度解析:游戏模组制作框架的技术架构与实战应用
FFXIV TexTools深度解析:游戏模组制作框架的技术架构与实战应用 【免费下载链接】FFXIV_TexTools_UI 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_TexTools_UI FFXIV TexTools是一款专为《最终幻想14》设计的专业级模组制作与安装框架,为…...

CentOS 8.5最小化安装实战:为什么我只选Minimal Install,以及后续必装的10个软件包
CentOS 8.5最小化安装实战:为什么我只选Minimal Install,以及后续必装的10个软件包 当你面对CentOS 8.5安装界面中那个看似简单的"Software Selection"选项时,是否曾犹豫过该选择哪个?作为一个经历过无数次系统安装的老…...
)
告别点灯:用STM32+FPGA+FSMC做个数据吞吐测试仪(附Quartus与标准库工程)
STM32与FPGA联袂打造:高性能数据吞吐测试仪实战指南 在嵌入式系统开发中,总线通信性能往往是决定整体系统响应速度的关键瓶颈。对于硬件爱好者、电子工程师和学生群体而言,如何直观测量和优化总线传输效率,是一个既具挑战性又充满…...