基于XGBoost的结核分枝杆菌的耐药性预测研究【多种机器学习】
1. 绪论
目录
1. 绪论
1.1研究背景及意义
1.2国内外研究现状
1.2.1国内研究现状
1.2.2国外研究现状
1.3研究目的
2. 相关技术概念
2.1结核分枝杆菌的耐药性机制
2.2机器学习与系统发育法相结合
2.3XGBoost和随机森林算法的优势和应用
3. 模型设计
3.1数据准备与预处理
3.1.1数据收集来源和类型说明
3.1.2数据清洗和预处理的详细步骤
3.2特征选择与工程
3.2.1采用的特征选择方法
3.2.2特征工程具体实施
3.3模型构建
3.3.1 XGBoost模型配置
3.3.2随机森林模型配置
3.3.3使用GridSearchCV进行超参数优化
3.4模型训练
3.4.1训练过程描述
3.4.2交叉验证策略
4. 实验设计与结果
4.1实验设计的逻辑
4.2结果分析
4.2.1XGBoost和随机森林模型的性能对比
4.2.2特征重要性分析
4.2.3XGBOOST结果的可视化展示
5. 讨论
5.1模型结果的解释
5.1.1XGBoost模型
5.2不同模型性能差异的可能原因
5.3实验中遇到的问题及解决方案
6. 结论
6.1研究的主要发现
6.2研究的局限性
6.3未来工作的方向
1.1研究背景及意义
本次研究旨在利用机器学习技术预测结核分枝杆菌对抗生素的耐药性,选择XGBoost(eXtreme Gradient Boosting)作为主要的建模算法。XGBoost是一种基于梯度提升(Gradient Boosting)机制的优化分布式梯度提升库,不仅在算法性能上具有优势,也在处理大规模数据集方面显示出高效性。
1.2国内外研究现状
1.2.1国内研究现状
近年来,中国在结核分枝杆菌耐药性预测和系统发育研究方面取得了显著进展,学者们在多方面开展了深入研究。.....
1.2.2国外研究现状
近年来,国际上关于结核病(Tuberculosis,TB)耐药性预测的研究取得了显著进展。许多研究者结合机器学习技术与系统发育学分析,深入探索结核分枝杆菌(Mycobacterium tuberculosis,MTB)的耐药机制。
.....
1.3研究目的
本研究的主要目
2. 相关技术概念
2.1结核分枝杆菌的耐药性机制
结核分枝准确性、制定个性化治疗方案以及开发新型抗结核药物具有重要意义。
2.2机器学习与系统发育法相结合
2.3XGBoost和随机森林算法的优势和应用
3. 模型设计
3.1数据准备与预处理
3.1.1数据收集来源和类型说明
本研究使用的数据集从国际公共健康数据库中获得,包括多个研究中心提供的结核分枝杆菌耐药性相关的详细临床和基因型数据。这些数据主要包括患者的基本信息、治疗历史以及详细的耐药测试结果。此外,还包括结核分枝杆菌的基因序列变异信息,这些信息是通过高通量测序技术获得,用于识别与耐药性相关的遗传标记。数据以制表符分隔的值(TSV)格式提供,确保了它们可以被广泛的数据处理工具有效读取和处理,方便后续的数据分析工作。
3.1.2数据清洗和预处理的详细步骤
在数据预处理阶段,首先使用Python的pandas库通过read_csv()函数加载TSV格式的数据文件,其中sep='\t'参数用于正确分隔数据列。随后,对数据集进行初步的检查,包括确认数据的完整性,识别并处理数据类型错误,
3.2特征选择与工程
3.2.1采用的特征选择方法
在结核分枝杆菌耐药性预测项目中,特征选择和特征工程是关键的步骤,旨在提高模型的预测精度和解释性。本研究采用了基于XGBoost和随机森林(Random Forest)的特征重要性评估方法来进行特征选择。这种方法利用这两种算法内置的特征重要性指标,选择对模型预测结果影响最大的特征,从而减少模型的复杂度并提高预测的准确性。通过实施SelectFromModel方法,仅保留那些重要性高于设定阈值的特征,这种基于模型的特征选择方法有助于消除不重要的特征,减少过拟合的风险,同时提高模型训练和预测的速度。
3.2.2特征工程具体实施
在特征工程方面,本研究对原始数据集中的特征进行了扩展和优化。首先,针对基因型数据,创建了新的特征,如基因突变组合和基因表达水平差异指标,这些新特征旨在捕捉耐药性形成的复杂生物学机制。此外,从临床数据中提取了患者的治疗响应和历史用药信息,这些信息被转化为数值型特征,用于增强模型对患者治疗效果的预测能力。还引入了交互特征,如药物组合的相互作用,以评估不同药物组合对耐药性的影响。通过这些特征工程步骤,不仅提升了数据集的信息丰富度,也增强了模型的预测能力和生物学解释性,为后续的机器学习模型分析和耐药性研究提供了更为深入的视角。
3.3模型构建
3.3.1 XGBoost模型配置
在本研究中,XGBoost算法用于构建一个预测模型,旨在评估结核分枝杆菌的耐药性。使用XGBoost的优势在于其高效的执行速度和模型的预测准确性,特别适用于处理包含复杂非线性关系的大型数据集。
3.3.2随机森林模型配置
在本研究中,随机森林算法被用于估计特征重要性并优化预测模型。通过使用随机森林分类器训练数据并评估每个特征的重要性,初始模型设置了固定的随机状态(random_state=42),以确保实验结果的可重复性。利用SelectFromModel方法,根据特征重要性的中位数作为阈值,从训练完成
3.3.3使用GridSearchCV进行超参数优化
在本研究中,使用了GridSearchCV来进行XGBoost和随机森林模型的参数调优,旨在找到最佳的模型参数组合以提升预测的准确性。以下是对这两个过程的详细描述:
XGBoost模型的参数调优
3.4模型训练
3.4.1训练过程描述
在本研究中,结核分枝杆菌耐药性预测模型的训练过程是通过详细的步骤和策略执行的,以确保高效和精确的模型性能。首先,通过Pandas库的read_csv()函数从提供的TSV文件中加载数据,确保所有数据按预定格式正确处理。
3.4.2交叉验证策略
在本研究中,为了确保模型的泛化能力和稳定性,交叉验证是一个关键的步骤。采用了10折交叉验证(10-fold cross-validation)的策略,这种方法在机器学习领域被广泛使用以评估模型的性能。
在10折交叉验证中,整个训练数据集被随机分割成10个相等的子集。在这些子集中,每一次迭代中选择一个子集作为测试集,剩余的9个子集合并作为训练集。这个过程会重复10次,每次选择不同的子集作为测试集,从而确保每个数据点都有一次机会被用作测试集。
4. 实验设计与结果
4.1实验设计的逻辑
在本研究中
4.2结果分析
4.2.1XGBoost和随机森林模型的性能对比
遍历每个药物对应的随机森林模型,并使用该模型对测试集进行预测,随后计算并打印出相关的性能评估指标
图4.1可视化代码

图4-2随机森林性能可视化
从图表中可以观察到各药物模型的性能有显著差异。例如,对于Amikacin,模型展示了较高的准确率和召回率,而对于Capreomycin,虽然准确率较高,但召回率相对较低。
因其与随机森林的性能指标代码几乎相同,不做重复赘述。如下为XGBOOST的性能可视化。

图4.3XGBOOST性能可视化
4.2.2特征重要性分析
热图结果如下图所示。

图4.4amikacin特征关联

图4.5capreomycin特征关联

图4.6ethionamide特征关联

图4.7kanamycin特征关联

图4.8ofloxacin特征关联

图4.9streptomycin特征关联

图4.10学习曲线
绘制结果下图所示。

图4.11amikacin重要特征值

图4.12capreomycin重要特征值

图4.13ethioonamide重要特征值
图表显示了由XGBoost模型提供的Ethionamide药物的特征重要性。如图所示,特征主要基于单核苷酸多态性(SNP)标记,图中展示了对Ethionamide耐药性预测影响最大的特征。条形图通过长度展示了各个特征的重要性,其中最顶部的条形图 (761161, 'T,C', 'snp') 表示在模型中具有最高重要性,强调了该遗传标记在预测药物反应中的关键作用。随着条形图向下递减,其它较低但依然重要的特征依次排列,如 (1473246, 'A,G', 'snp') 和 (1673425, 'C,T', 'snp') 等。

图4.14kanamycin重要特征值
在图表中,条形图的长度代表各特征的相对重要性,其中最顶部的条形 (1217157, 'A,C', 'snp') 显示为最关键的特征,其重要性远超过其他特征,强调了它在模型中的显著作用。随着条形逐渐变短,其他较少但依然具有一定重要性的特征依次展示,如 (204489, 'T,C', 'snp') 和 (69338, 'G,T', 'snp')。

图4.15ofloxcain重要特征值

图4.16streptomycin重要特征值
4.2.3XGBOOST结果的可视化展示
在本研究中,为了更好地理解和解释XGBoost模型的决策过程,采用可视化技术对不同药物的

图4.17XGBoost可视化(amikacin)

图4.18XGBoost可视化(capreomycin)

图4.19XGBoost可视化(ethionamide)
在第三棵决策树的可视化中,显示了异烟肼(Ethionamide)耐药性预测模型的决策逻辑。模型首先通过f2154特征进行分裂,将样本分为两个主要分支。左侧分支的样本特征值小于阈值,并继续通过f548和f827等特征进行分裂,最终到达叶节点,给出相应的耐药性预测值。右侧分支的样本特征值大于等于阈值,接着根据f113、f804和f1037等特征分裂,给出相应的的预测结果。

图4.20XGBoost可视化(kanamycin)

图4.21XGBoost可视化(streptomycin)
这张决策树图描绘了链霉素(Streptomycin)耐药性预测模型的决策路径。模型首先利用特征f971的阈值判别来划分样本,然后通过进一步的特征分裂来精细化耐药性预测。左侧的主分支处理f971小于特定阈值的样本,然后依次考察f310和f411的特征值,每一步的决策都紧密关联着特定的叶节点预测结果。右侧的分支处理f971大于或等于阈值的样本,继而通过f810和f450的分裂,以及随后的细节特征分裂,来确定具体的耐药性结果。

图4.22AUC图(amikacin)
曲线图显示了XGBoost模型预测阿米卡星(Amikacin)耐药性的分类性能。横轴代表假阳性率(False Positive Rate),纵轴代表真阳性率(True Positive Rate)。红色的ROC曲线表示模型对阿米卡星的预测效果,蓝色虚线作为基准线,表示随机猜测的分类效果。曲线下面积(AUC)为0.96,接近1,表明模型对阿米卡星耐药性的预测具有极高的准确性。较高的AUC值表明模型在区分耐药和非耐药样本方面表现出色,具有很好的分类性能。

图4.23AUC值(capreomycin)
曲线图展示了XGBoost模型预测卡那霉素(Capreomycin)耐药性的分类性能。图中的横轴代表假阳性率(False Positive Rate),纵轴代表真阳性率(True Positive Rate)。红色的ROC曲线显示了模型对卡那霉素的预测效果,而蓝色虚线作为基准线,代表随机猜测的分类效果。曲线下面积(AUC)为0.93,表明该模型对卡那霉素的耐药性预测具有很高的准确性。

图4.24AUC值(ethionamide)
曲线图展示了XGBoost模型预测乙硫异烟胺(Ethionamide)耐药性的分类性能。横轴代表假阳性率(False Positive Rate),纵轴代表真阳性率(True Positive Rate)。红色的ROC曲线显示了模型对乙硫异烟胺的预测效果,而蓝色虚线作为基准线,代表随机猜测的分类效果。曲线下面积(AUC)为0.85,表明该模型对乙硫异烟胺的耐药性预测具有较高的准确性。

图4.25AUC值(kanamycin)
ROC曲线:Kanamycin的模型ROC曲线(图9)显示AUC为0.96,表现非常出色。
特征重要性:特征重要性图(图10)表明,'A,G','T,C','C,A'等特征对Kanamycin预测最重要

图4.26AUC值(streptomycin)
ROC曲线:Streptomycin的模型ROC曲线显示出较高的预测性能,AUC为0.92。
特征重要性:特征重要性图(图12)显示,'G,A','A,C','T,C'等特征是对Streptomycin预测贡献最大的变量。
5. 讨论
5.1模型结果的解释
在本研究中,我们最终选择了XGBoost(eXtreme Gradient Boosting)算法来预测结核分枝杆菌的耐药性。为了验证XGBoost模型的有效性,我们使用随机森林模型作为对比实验,并从以下几个方面对模型结果进行解释和比较。
5.1.1XGBoost模型
通过提升决策树的方式,对结核分枝杆菌的多药耐药(MDR)和广泛耐药(XDR)进行预测。在模型训练和评估阶段,XGBoost模型在准确性、精确率、召回率和F1得分方面均表现出较高的预测性能。
5.2不同模型性能差异的可能原因
不同模型性能差异的可能原因在于它们对数据的处理方式、模型结构、超参数优化和对噪声数据的容忍度等方面存在差异。XGBoost模型通过迭代提升决策树的方式,能够更好地处理数据中的噪声和缺失值
5.3实验中遇到的问题及解决方案
问题1:数据预处理问题 在数据预处理阶段,我们发现结核分枝杆菌耐药性数据集中存在一些缺失值和异常值,特别是基因突变位点的部分数据缺失。缺失和异常数据会导致模型训练效果下降。
..........
6. 结论
6.1研究的主要发现
在本研究中,利用XGBoost模型对结核分枝杆菌耐药性进行了深入的预测和分析,并与随机森林模型进行了对比实验。结果表明,XGBoost模型在结核分枝杆菌耐药性预测中表现出高效性和准确性。在准确率、精确率、召回率和F1得分方面均优于随机森林模型。通过正则化项抑制模型的过拟合,并利用早停策略进一步优化模型性能,最终取得了较高的预测准确性。
6.2研究的局限性
尽管本研究利用XGBoost模型对结核分枝杆菌耐药性进行了有效预测,并识别出了一些关键的耐药基因,但仍存在一些局限性值得注意。首先,本研究使用的数据集规模相对有限,样本数不足以充分代表结核分枝杆菌的多样性。数据集中耐药菌株的数量相对较少,可能导致模型在预测稀有耐药性表型时存在偏差。因此,研究结果在实际应用中可能受到数据规模的影响。
6.3未来工作的方向
在本研究中,虽然利用XGBoost模型成功对结核分枝杆菌的耐药性进行了预测并识别出了关键的耐药基因,但仍有许多方面值得进一步探索与改进。未来的工作方向应包括以下几个方面:
每文一语
数字孪生与实践
相关文章:
基于XGBoost的结核分枝杆菌的耐药性预测研究【多种机器学习】
1. 绪论 目录 1. 绪论 1.1研究背景及意义 1.2国内外研究现状 1.2.1国内研究现状 1.2.2国外研究现状 1.3研究目的 2. 相关技术概念 2.1结核分枝杆菌的耐药性机制 2.2机器学习与系统发育法相结合 2.3XGBoost和随机森林算法的优势和应用 3. 模型设计 3.1数据准备与预…...

【C++差分数组】3229. 使数组等于目标数组所需的最少操作次数|2066
本文涉及知识点 C差分数组 LeetCode3229. 使数组等于目标数组所需的最少操作次数 给你两个长度相同的正整数数组 nums 和 target。 在一次操作中,你可以选择 nums 的任何子数组,并将该子数组内的每个元素的值增加或减少 1。 返回使 nums 数组变为 tar…...

浅谈PyTorch中的DP和DDP
目录 1. 引言2. PyTorch 数据并行(Data Parallel, DP)2.1 DP 的优缺点2.2 DP 实现代码示例 3. PyTorch 分布式数据并行(Distributed Data Parallel, DDP)3.1 DDP 的优缺点3.2 分布式基本概念3.3 DDP 的应用流程3.5 DDP 实现代码示…...

在Windows上利用谷歌浏览器进行视频会议和协作
随着远程工作和在线教育的普及,使用谷歌浏览器在Windows上进行视频会议和协作变得越来越常见。本文将为您提供一个详细的教程,教您如何在Windows上利用谷歌浏览器进行视频会议和协作,同时解决一些常见的问题。(本文由https://goog…...

VMware Fusion 13.6.1 发布下载,修复 4 个已知问题
VMware Fusion 13.6.1 发布下载,修复 4 个已知问题 VMware Fusion 13.6.1 for Mac - 领先的免费桌面虚拟化软件 适用于基于 Intel 处理器和搭载 Apple 芯片的 Mac 的桌面虚拟化软件 请访问原文链接:https://sysin.org/blog/vmware-fusion-13/ 查看最新…...

P9751 [CSP-J 2023] 旅游巴士
P 9751 P9751 P9751 部分分思路 题目要求时间必须是 k k k 的非负整数倍,所以想到了升维。这样就变成了一道分层图最短路的题目。用 BFS 算法可以拿到 A i 0 A_i0 Ai0 的 35 35 35 分。 满分思路 其实部分分的思路已经很接近正解了,想要拿到满…...

【Linux】man手册安装使用
目录 man(manual,手册) 手册安装: 章节区分: 指令参数: 使用场景: 手册内容列表: 手册查看快捷键: 实例: 仍致谢:Linux常用命令大全(手册) – 真正好用的Linux命令在线查询网站 提供的命令查询 在开头先提醒一下:在 man 手册中退出的方法很简单…...
)
mysql学习教程,从入门到精通,SQL处理重复数据(39)
1、SQL处理重复数据 使用GROUP BY和HAVING子句删除重复数据(以SQL Server为例)”的背景和原理的详细解释: 1.1、背景 在数据库管理中,数据重复是一个常见的问题。重复数据可能由于多种原因产生,如数据录入错误、数据…...

mapbox解决wmts请求乱码问题
贴个群号 WebGIS学习交流群461555818,欢迎大家 事故现场 如图所示,wmts请求全是乱码,看起来像是将一个完整的请求拆成一个一个的字母了,而且控制台打印map.getStyle() 查看该source发现不出异常 解决办法 此类问题就是由于更…...

《C++职场中设计模式的学习与应用:开启高效编程之旅》
在 C职场中,设计模式是提升代码质量、增强程序可维护性和可扩展性的强大武器。掌握并正确应用设计模式,不仅能让你在工作中更加得心应手,还能为你的职业发展增添有力的砝码。那么,如何在 C职场中学习和应用设计模式呢?…...

Maya动画--基础约束
005-基础约束02_哔哩哔哩_bilibili 父子约束 移动圆环,球体会跟着移动,并回到初始的相对位置 不同物体间没有层级关系 明确子物体与父物体间的关系 衣服上的纽扣 法线约束 切线约束 碰到中心时会改变方向...
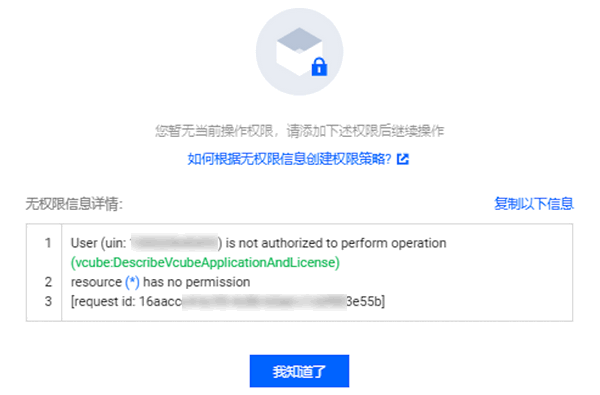
腾讯云License 相关
腾讯云视立方 License 是必须购买的吗? 若您下载的腾讯云视立方功能模块中,包含直播推流(主播开播和主播观众连麦/主播跨房 PK)、短视频(视频录制编辑/视频上传发布)、终端极速高清和腾讯特效功能模块&…...

开放式耳机什么品牌最好?十大超好用开放式耳机排名!
由于长时间使用传统入耳式耳机可能会对耳道健康带来潜在的负面影响,越来越多的用户倾向于选择开放式耳机,这种设计不侵入耳道。它有助于降低耳内湿度、减少细菌滋生,以及缓解耳道因封闭而过热的不适。但是大部分人还是不知道怎么选择开放式耳…...

基于Zynq SDIO WiFi移植二(支持2.4/5G)
1 SDIO设备识别 经过编译,将移植好的uboot、kernel、rootFS、ramdisk等烧录到Flash中,上电启动,在log中,可看到sdio设备 [ 1.747059] mmc1: queuing unknown CIS tuple 0x01 (3 bytes) [ 1.761842] mmc1: queuing unknown…...

Spring Boot敏感数据动态配置:深入实践与安全性提升
在构建Spring Boot应用的过程中,敏感数据的处理与保护是至关重要的。传统上,这些敏感数据(如数据库密码、API密钥、加密密钥等)可能被硬编码在配置文件中,这不仅增加了泄露的风险,也限制了配置的灵活性和可…...

软考数据库部分 ---- (概念数据库模型,三级模式,两级映像,事物管理)
文章目录 一、概念数据库模型二、结构数据库模型三、三级模式四、两级映像五、关系模式基本术语六、关系模式七、关系的数学定义八、数据定义语言九、SQL访问控制十、视图十一、索引十二、关系模式十三、范式十四、数据库设计十五、事物管理(ACID)十六、…...

AI 概念大杂烩
目录 介绍 数据挖掘 / 机器学习 / 深度学习 一、数据挖掘(Data Mining) 1. 定义 2. 目标 3. 常用算法 二、机器学习(Machine Learning) 1. 定义 2. 目标 3. 常用算法 三、深度学习(Deep Learning࿰…...

Composer和PHP有什么关系
Composer是PHP的一个依赖管理工具,以下是对Composer及其与PHP关系的详细解释: Composer简介 核心功能:Composer的核心思想是“依赖管理”,它能够自动下载和安装项目所依赖的库、框架或插件等。这些依赖项可以是PHP本身的库文件&…...

【PGCCC】在 Postgres 上构建图像搜索引擎
我最近看到的最有趣的电子商务功能之一是能够搜索与我手机上的图片相似的产品。例如,我可以拍一双鞋或其他产品的照片,然后搜索产品目录以查找类似商品。使用这样的功能可以是一个相当简单的项目,只要有合适的工具。如果我们可以将问题定义为…...

性能测试之性能问题分析
开始性能测试前需要了解的内容: 1、项目具体需求。 2、指标:响应时间在多少以内,并发数多少,tps多少,总tps多少,稳定性交易总量多少,事务成功率,交易波动范围,稳定运行…...

猫抓Cat-Catch:浏览器媒体资源捕获终极指南
猫抓Cat-Catch:浏览器媒体资源捕获终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾遇到过想下载网页视频却找不到下载…...

5分钟掌握猫抓扩展:浏览器视频下载终极指南
5分钟掌握猫抓扩展:浏览器视频下载终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到精彩的在线视频却无法下载保…...

ARM SMMU-700内存管理单元原理与优化实践
1. MMU-700 SMMU架构概述与典型应用场景内存管理单元(MMU)是现代计算机系统中不可或缺的核心组件,负责处理虚拟地址到物理地址的转换。在ARM架构中,系统级内存管理单元(SMMU)扮演着更为关键的角色ÿ…...

大模型推理全链路拆解
从 token 调度到采样输出,追踪每一步张量维度的变化,搞懂 LLM 推理到底在算什么 01 为什么需要 Continuous Batching 批处理能提升 GPU 利用率——复用权重来均摊显存访问开销。但生成式任务的输出序列长度不可预测且差异巨大,传统"齐…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

三维重建实时映射技术在智慧水利中的核心应用
三维重建实时映射技术在智慧水利中的核心应用在国家大力推进数字孪生水利建设、实现水安全精准保障的背景下,智慧水利已从传统监测、调度向全域感知、智能预判、协同处置、一屏统管升级。智慧水利的核心目标,是实现对江河湖库、灌区、泵站、堤坝、闸站等…...

量子控制中的动态校正门与SCQC几何方法
1. 量子控制中的噪声挑战与动态校正门在超导量子处理器上实现高保真度的量子门操作,最大的障碍来自环境噪声。这些噪声主要分为两类:失谐噪声(δz)和幅度噪声(ϵ)。失谐噪声源于量子比特频率的漂移…...