<Project-8.1.1 pdf2tx-mm> Python 调用 ChatGPT API 翻译PDF内容 历程心得
原因
用ZhipuAI,测试用的PDF里,有国名+西部省+穆斯林,翻译结果返回 “系统检测到输入或生成内容可能包含不安全或敏感内容,请您避免输入易产生敏感内容的提 示语,感谢您的配合” 。想过先替换掉省名、民族名等,不发送敏感词去翻译。再试下去看到的结果就没剩几个省,内容也是。中文存在的意思都要考虑,伤心一天。
后来用的MyMemory Translater, 测试时翻译达到上限。用deep_translator调用MyMemory,返回竟然是google服务。改用MyMemory API,没几页就limited。浪费时间。 已知,MyMemory 最大的问题,日文到简体中文会是错意,但翻译成老国语你体会一下:日语你好,老国语是问候。 英语到两国文都没问题。 日语到英语也是原来的意思。难到中文就这样了?
几个小时前,用ChatGPT API试试。
Chatgpt
CSDN里好像谈及它,都是收费的。贫穷的我不想浪费。
1. OpenAI 版本冲突
代码试要有一个过程... 代码总出错, 出错的信息如下:
You tried to access openai.ChatCompletion, but this is no longer supported in openai>=1.0.0 - see the README at https://github.com/openai/openai-python for the API.
You can run openai migrate to automatically upgrade your codebase to use the 1.0.0 interface.
Alternatively, you can pin your installation to the old version, e.g. pip install openai==0.28
A detailed migration guide is available here: https://github.com/openai/openai-python/discussions/742
————————————————版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。原文链接:https://blog.csdn.net/davenian/article/details/142820402CMD里执行:
CMD: dir /s /b openai.py蹦出来3个 openai.py 即三个源。 于是想到 python 虚拟环境 VE,写个流水充数,然后就去做饭。于是有了篇文章:
<OS 有关> Python 虚拟环境 用处-CSDN博客 链接可以打开阅读。
2. OpenAI 库升级 类方法改变了
升级PC的openai库,新库里没有这个类:openai.ChatCompletion.create
报错:
'ChatCompletion' object is not subscriptable
我也是第一次用 API 去调用 chatgpt 模型,受些文启发《【新知】chatGPT 使用笔记(二)——chatGPT API的使用》参考里面的代码,使用的 ChatCompletion 对象... 将近2小时找有关的代码与文章,看官网,如下链接(不全但有线索):
https://stackoverflow.com/questions/77444332/openai-python-package-error-chatcompletion-object-is-not-subscriptable
GitHub - openai/openai-python: The official Python library for the OpenAI API
https://platform.openai.com/docs/quickstart?desktop-os=windows&language-preference=python
Issue with openai.ChatCompletion.create() in Latest OpenAI Python Library - API - OpenAI Developer Forum
直到上下两篇看完,才明白。
https://github.com/openai/openai-python/discussions/884
类改名儿了
新的是
client.chat.completions.create
或
openai.chat.completions.create后者是全局函数来调用 OpenAI 的 API,我选择前者方法 客户端实例。在
OpenAI Developer quickstart 示例:
from openai import OpenAI
client = OpenAI()completion = client.chat.completions.create(model="gpt-4o-mini",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user","content": "Write a haiku about recursion in programming."}]
)print(completion.choices[0].message)示例中,OpenAI 的 API 客户端类,而不只是模块级的调用,这个在代码上更变通些。
3. 没有提供所需的参数
错误信息 “Missing required arguments; Expected either ('messages' and 'model') or ('messages', 'model' and 'stream') arguments to be given”
大概意思是: OpenAI 的 ChatCompletion.create() 方法时,没有提供所需的参数。
其实, 调用 OpenAI 的 ChatGPT 模型来生成对话或文本的核心函数。 这类新旧版本没什么变化。在报错的信息,很误导。我遇到时,问题出在两个方面,一个是 类的名字变了,另一个是:

我看到的简中都是 使用字典式访问 message 对象中的 content 字段(从 choices 返回的对象中提取生成的文本。),我也是跟着学的,也中招儿了。
现在是:从 message 对象中直接访问 content 属性
questions = completions.choices[0].message.content.strip().split("\n\n")
下面我放上以前的,这下就弄清楚了。
questions = completions.choices[0].message['content'].strip().split("\n\n")
4. 提示词
要Chatgpt做事,就要给它文字上的引导。不再是喂鸡等蛋或是听打鸣。 他是有智慧的,生命对他来说是无穷无尽的时间。有时想想,那它应该叫什么?
作为翻译的调用,就要让他知道,他的职责是翻译,还要让他知道向哪种文字翻译。前者是固定的角色,后者是变量, 这样就很简单,我的实现方法,都不需要判断自源文字,只想让他知道去翻译,翻译成什么文字就行。
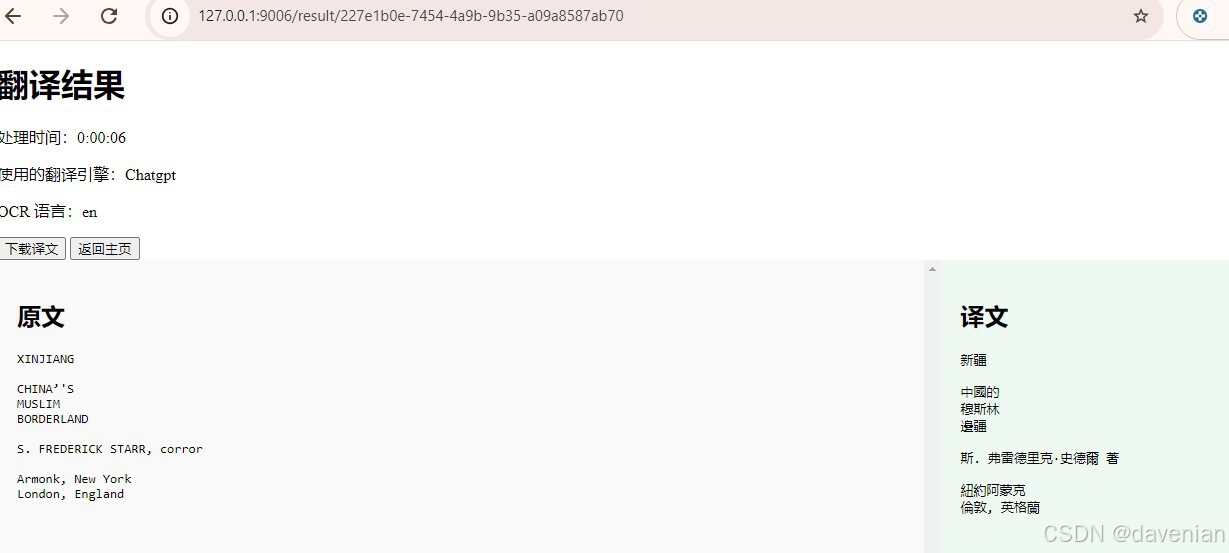
实例是,翻译成老中文。我给的prompt:
chatgpt_prompt = f"translate to {target_language}:\n\n{chunk}"与 AI 对话,主语宾语都可以略,像老朋友一样。 “ to 啥 chinese ”介词短语,修饰动词 translate ,他就明白。 用 AI 做翻译,都不用改代码, 上传页面,加选项就全搞定。
upload.html<label for="enginet">选择翻译引擎:</label><select id="enginet" name="enginet"><option value="google">Google 翻译</option><option value="microsoft">Microsoft 翻译</option><option value="chatgpt">ChatGPT 翻译</option><!-- 如有其他翻译引擎,可在此添加 --></select><label for="target_language">选择目标语言:</label><select id="target_language" name="target_language"><option value="zh-cn">简体中文</option><option value="zh-tw">繁体中文(台湾)</option>看上传页面的代码,后4行,尤其是最后两行。(我有做了一个 字典映射,为了另外两个翻译引擎使用)
'en': 'English','ja': 'Japanese','zh-cn': 'Simplified Chinese ','zh-tw': 'Traditional Chinese',代码
其它几个文件都没有改,在这版里,去掉了 ZhipuAI, 去掉了 MyMemory Translator, 只保留Google Translator, Azure Translator, 还有新加入的 Chatgpt.
app.py
import os
import uuid
import logging
import configparser
from flask import Flask, render_template, request, redirect, url_for, Response
from threading import Thread, Lock
from werkzeug.utils import secure_filename
from pdf2image import convert_from_path
import pytesseract
from deep_translator import GoogleTranslator, MicrosoftTranslator
from concurrent.futures import ThreadPoolExecutor
from collections import defaultdict
import time # 导入 time 模块, 显示处理时间用
from datetime import timedelta #在结果页面显示处理时间,格式为 HH:MM
import nltk
#try:
# nltk.data.find('tokenizers/punkt','tokenizers/punkt_tank')
#except LookupError:
# nltk.download('punkt','punkt_tank', quiet=True)#nltk.download('punkt', quiet=True) # 已经安装,用:python -m nltk.downloader all
# 但运行还会报错! 还需要安装 unstructured 库,Y TMD在介绍里没说 f!
from functools import lru_cache
from pdfminer.high_level import extract_text as pdf_extract_text
from pdfminer.pdfparser import PDFSyntaxError
from langdetect import detect
import jieba
from janome.tokenizer import Tokenizer
import random
from openai import OpenAI# 定义支持的语言映射
language_mapping = {'en': 'english','fr': 'french','de': 'german','es': 'spanish','it': 'italian','ja': 'japanese','ko': 'korean','ru': 'russian','zh-cn': 'chinese','zh-tw': 'chinese','zh': 'chinese','pt': 'portuguese','ar': 'arabic','hi': 'hindi',# 添加其他语言
}# OCR 语言代码映射
ocr_language_mapping = {'en': 'eng','fr': 'fra','de': 'deu','es': 'spa','it': 'ita','ja': 'jpn','ko': 'kor','ru': 'rus','zh-cn': 'chi_sim','zh-tw': 'chi_tra',# 添加更多语言如有需要
}# Microsoft Translator 语言代码映射
microsoft_language_mapping = {'en': 'en','fr': 'fr','de': 'de','es': 'es','it': 'it','ja': 'ja','ko': 'ko','ru': 'ru','zh-cn': 'zh-hans','zh-tw': 'zh-hant','pt': 'pt','ar': 'ar','hi': 'hi',# 添加更多语言如有需要
}# Google Translator 语言代码映射
google_language_mapping = {'en': 'en','fr': 'fr','de': 'de','es': 'es','it': 'it','ja': 'ja','ko': 'ko','ru': 'ru','zh-cn': 'zh-CN', # 修正为 Google 支持的简体中文代码'zh-tw': 'zh-TW', # 修正为 Google 支持的繁体中文代码'zh': 'zh-CN', # 默认简体中文'pt': 'pt','ar': 'ar','hi': 'hi',# 添加更多语言如有需要
}ChatGPT_language_mapping = {'en': 'English','ja': 'Japanese','zh-cn': 'Simplified Chinese ','zh-tw': 'Traditional Chinese',
}# 初始化 Flask 应用
app = Flask(__name__)
app.config['ALLOWED_EXTENSIONS'] = {'pdf'}
app.config['UPLOAD_FOLDER'] = 'uploads'
app.config['MAX_CONTENT_LENGTH'] = 50 * 1024 * 1024 # 50MB# 确保上传文件夹存在
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)# 全局变量
progress = defaultdict(int)
results = {}
progress_lock = Lock()# 设置日志 格式
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')# 读取配置文件
config = configparser.ConfigParser()
config_file = 'config.ini'if not os.path.exists(config_file):raise FileNotFoundError(f"配置文件 {config_file} 未找到,请确保其存在并包含必要的配置。")config.read(config_file)try:AZURE_API_KEY = config.get('translator', 'azure_api_key') # Microsoft Azure 需要KEY, 它给了2个,可以循环使用。用一个就行。AZURE_REGION = config.get('translator', 'azure_region') # 还需要 copied: This is the location (or region) of your resource. You may need to use this field when making calls to this API.OPENAI_API_KEY = config.get('translator', 'openai_api_key') # 使用openAI API# 如果有其他 API 密钥,例如 Yandex,可以在此添加# YANDEX_API_KEY = config.get('translator', 'yandex_api_key') 这个是俄国的google,而且是收费的,不想花1分钱给俄罗斯。
except (configparser.NoSectionError, configparser.NoOptionError):raise ValueError("配置文件中缺少必要的配置选项。")# 设置 OpenAI API 密钥
# Initialize the OpenAI clientclient = OpenAI(api_key=OPENAI_API_KEY)# 允许的文件类型检查函数
def allowed_file(filename):return '.' in filename and filename.rsplit('.', 1)[1] in app.config['ALLOWED_EXTENSIONS']# OCR 函数,指定语言
def ocr_image(image, lang='eng'):try:text = pytesseract.image_to_string(image, lang=lang)except Exception as e:logging.error(f"OCR 失败: {e}")text = ''return textdef chinese_sentence_split(text):# 使用 jieba 进行分词并辅助分句sentences = []current_sentence = []for word in jieba.cut(text):current_sentence.append(word)if word in ['。', '!', '?', ';']:sentence = ''.join(current_sentence).strip()if sentence:sentences.append(sentence)current_sentence = []if current_sentence:sentence = ''.join(current_sentence).strip()if sentence:sentences.append(sentence)return sentencesdef japanese_sentence_split(text):# 使用 Janome 进行分词,并按标点符号分割tokenizer = Tokenizer()tokens = tokenizer.tokenize(text, wakati=True)sentences = []current_sentence = []for token in tokens:current_sentence.append(token)if token in ['。', '!', '?']:sentence = ''.join(current_sentence).strip()if sentence:sentences.append(sentence)current_sentence = []if current_sentence:sentence = ''.join(current_sentence).strip()if sentence:sentences.append(sentence)return sentencesdef process_with_chatgpt(prompt, max_tokens=1500):if len(prompt.split()) > 3000: # Or use a more sophisticated tokenizer to count tokenslogging.error("Prompt is too long to process with the given token limit")return "Prompt too long"try: response = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user","content": prompt}],#max_tokens=max_tokens#n=1,#stop=None,#temperature=0.7)return response.choices[0].message.content.strip() #Err response.choices[0].message['content'].strip().split("\n\n")except Exception as e:logging.error(f"ChatGPT 处理失败: {e}")return "ChatGPT 处理失败。"@lru_cache(maxsize=512) #缓存常见的翻译请求,减少重复的 API 调用
def cached_translate(text, enginet, source_lang, target_lang):return translate_text(text, enginet, source_lang, target_lang)# 翻译文本函数,支持分段、并行、进度更新、重试和缓存
def translate_text(text, enginet, progress_callback=None, text_lang='en', target_language='en'):global google_language_mappingglobal microsoft_language_mappingglobal ChatGPT_language_mappinglogging.info(f"翻译引擎参数: {enginet}")# 句子分割nltk_lang = language_mapping.get(text_lang, 'english')if nltk_lang in ['english', 'french', 'german', 'spanish', 'italian', 'russian']:try:sentences = nltk.sent_tokenize(text, language=nltk_lang)except Exception as e:logging.error(f"NLTK 分句失败,使用默认分割方法:{e}")sentences = text.split('\n')elif nltk_lang == 'chinese':sentences = chinese_sentence_split(text)elif nltk_lang == 'japanese':sentences = japanese_sentence_split(text)else:sentences = text.split('\n')# 根据翻译引擎设置最大字符长度if enginet == 'google':max_length = random.randint(4200, 4700)elif enginet == 'chatgpt':max_length = 2000 # OpenAI 对单个请求的 token 数有上限,具体取决于模型else: max_length = 5000# 确保 target_language 已被正确设置if not target_language:logging.error("未能正确设置目标语言,使用默认值 'en'")target_language = 'en'# 初始化翻译器translator = Nonesource_language = Noneif enginet == 'google':target_language = google_language_mapping.get(target_language, 'en') # 使用正确的目标语言translator = GoogleTranslator(source='auto', target=target_language)logging.info(f"初始化翻译器, google Target_language: {target_language}")elif enginet == 'microsoft':# 使用用户提供的目标语言代码进行翻译source_language = microsoft_language_mapping.get(text_lang, 'en')target_language = microsoft_language_mapping.get(target_language, 'en')logging.info(f"初始化翻译器, Azure Source Language: {source_language}, Target Language: {target_language}")translator = MicrosoftTranslator(source=source_language,target=target_language,api_key=AZURE_API_KEY,region=AZURE_REGION)elif enginet == 'chatgpt':target_language=ChatGPT_language_mapping.get(target_language)logging.info(f"初始化翻译器, ChatGPT 使用模型: gpt-3.5-turbo, Target Language: {target_language}")else:raise ValueError(f"没有选择翻译引擎或引擎不工作:{enginet}")# 将句子组合成不超过最大长度的块chunks = []current_chunk = ''for sentence in sentences:if len(current_chunk) + len(sentence) + 1 <= max_length:current_chunk += sentence + ' 'else:chunks.append(current_chunk.strip())current_chunk = sentence + ' 'if current_chunk:chunks.append(current_chunk.strip())translated_chunks = [''] * len(chunks)total_chunks = len(chunks)completed_chunks = 0# 定义翻译单个块的函数,带有重试机制def translate_chunk(index, chunk):nonlocal completed_chunksmax_retries = 3for attempt in range(max_retries):try:if enginet == 'google':translated_chunk = translator.translate(chunk)elif enginet == 'microsoft':translated_chunk = translator.translate(chunk)elif enginet == 'chatgpt': #为 ChatGPT 构建适当的提示chatgpt_prompt = f"translate to {target_language}:\n\n{chunk}"#logging.info(f"chatgpt_prompt:{chatgpt_prompt}")translated_chunk = process_with_chatgpt(prompt=chatgpt_prompt#max_tokens=1500 #根据需要调整)else:translated_chunk = f"翻译引擎不支持:{enginet}"translated_chunks[index] = translated_chunkbreak # 成功后跳出循环except Exception as e:logging.error(f"翻译块 {index} 失败,尝试次数 {attempt + 1}: {e}")if attempt == max_retries - 1:translated_chunks[index] = chunk # 最后一次重试失败,使用原文#with progress_lock:completed_chunks += 1if progress_callback:progress = int(100 * completed_chunks / total_chunks)progress_callback(progress)# 使用线程池并行翻译with ThreadPoolExecutor(max_workers=5) as executor:for idx, chunk in enumerate(chunks):executor.submit(translate_chunk, idx, chunk)# 重建翻译后的文本translated_text = ' '.join(translated_chunks)return translated_text.strip()# 后台处理函数
# 使用 logging.info 在调试模式中输出所使用的翻译引擎和处理时间
# 在任务开始时,记录开始时间 start_time。
# 在任务结束时,记录结束时间 end_time,计算处理时间 elapsed_time。
# 将 elapsed_time 保存到 results 字典中,以便在结果页面显示
# 加入对pdf file checking. 如果不是Image,跳过OCR. 9oct.24 1230am
def process_file(task_id, filepath, enginet, ocr_language, target_language):global resultsglobal language_mapping # 声明使用全局变量try:start_time = time.time() # 记录开始时间logging.info(f"任务 {task_id}: 开始处理文件 {filepath},使用 OCR 语言 {ocr_language},翻译引擎 {enginet}, 目标语言 {target_language}"), # 输出详细信息with progress_lock:progress[task_id] = 0# 尝试直接提取文本extracted_text = ''try:extracted_text = pdf_extract_text(filepath)if extracted_text.strip():logging.info(f"任务 {task_id}: 成功提取文本,无需 OCR")with progress_lock:progress[task_id] = 50 # 文本提取完成,进度更新为 50%# 在提取文本后,检测语言try:detected_language = detect(extracted_text)logging.info(f"检测到的文本语言:{detected_language}")if detected_language not in language_mapping:logging.warning(f"检测到的语言 '{detected_language}' 不在支持的语言列表中,使用默认语言 'en'")detected_language = 'en'except Exception as e:logging.error(f"语言检测失败,使用默认语言 'en'。错误信息:{e}")detected_language = 'en'else:logging.info(f"任务 {task_id}: 提取到的文本为空,使用 OCR 处理")raise ValueError("Empty text extracted")except Exception as e: # 如果直接提取文本失败,使用 OCR 处理logging.info(f"任务 {task_id}: 无法直接提取文本,将使用 OCR 处理。原因:{e}")# 将 PDF 转换为图像try:images = convert_from_path(filepath)except PDFSyntaxError as e:logging.error(f"PDF 解析错误: {e}")raise ValueError("PDF 解析错误,无法转换为图像。")total_pages = len(images)total_steps = total_pagesextracted_text = ''for i, image in enumerate(images):text = ocr_image(image, lang=ocr_language_mapping.get(ocr_language,'eng'))extracted_text += text + '\n'with progress_lock:progress[task_id] = int(100 * (i + 1) / total_steps * 0.5) # OCR 占 50% 进度with progress_lock:progress[task_id] = 50 # OCR 完成,进度更新为 50%# 在 OCR 提取后,检测语言try:detected_language = detect(extracted_text)logging.info(f"检测到的文本语言:{detected_language}")if detected_language not in language_mapping:logging.warning(f"检测到的语言 '{detected_language}' 不在支持的语言列表中,使用默认语言 'en'")detected_language = 'en'except Exception as e:logging.error(f"语言检测失败,使用默认语言 'en'。错误信息:{e}")detected_language = 'en'# 翻译文本,传递 progress_callbackdef progress_callback(p):with progress_lock:progress[task_id] = 50 + int(p * 0.5) # 翻译占 50% 进度# 将检测到的语言传递给 translate_text 函数,并确保 enginet 是小写translated_text = translate_text(extracted_text, enginet.lower(), progress_callback, detected_language, target_language)# 使用 ChatGPT 对翻译后的文本进行处理#chatgpt_prompt = f"请为以下翻译后的文本生成一个精简摘要:\n\n{translated_text}"#chatgpt_summary = process_with_chatgpt(chatgpt_prompt)with progress_lock:progress[task_id] = 100# 计算处理时间end_time = time.time()elapsed_time = end_time - start_time # 处理所用的时间,单位为秒# 将处理时间保存到结果中result = {'original': extracted_text,'translated': translated_text,#'chatgpt_summary': chatgpt_summary,'elapsed_time': elapsed_time, # 添加处理时间'enginet': enginet, # 添加翻译引擎'ocr_language': ocr_language, # 添加 OCR 语言'target_language': target_language}results[task_id] = result# 删除上传的文件os.remove(filepath)logging.info(f"任务 {task_id}: 处理完成,耗时 {elapsed_time:.2f} 秒") # 输出处理时间except Exception as e:logging.error(f"An unexpected error occurred 处理失败: {e}")with progress_lock:progress[task_id] = -1finally:# 确保上传的文件被删除,即使出现异常if os.path.exists(filepath):os.remove(filepath)logging.info(f"任务 {task_id}: 文件已删除")# 文件上传路由
@app.route('/', methods=['GET', 'POST'])
def upload_file():if request.method == 'POST':# 检查请求中是否有文件if 'file' not in request.files:return '请求中没有文件部分', 400file = request.files['file']if file.filename == '':return '未选择文件', 400if file and allowed_file(file.filename):# 安全地保存文件filename = secure_filename(f"{uuid.uuid4().hex}_{file.filename}")filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)file.save(filepath)# 获取选择的翻译引擎和 OCR 语言,设置默认值enginet = request.form.get('enginet', 'google')ocr_language = request.form.get('ocr_language', 'en')target_language = request.form.get('target_language')# 创建唯一的任务 IDtask_id = str(uuid.uuid4())progress[task_id] = 0# 启动后台处理线程thread = Thread(target=process_file, args=(task_id, filepath, enginet, ocr_language, target_language))thread.start()# 重定向到进度页面return redirect(url_for('processing', task_id=task_id))else:return '文件类型不被允许', 400return render_template('upload.html')# 处理页面路由
@app.route('/processing/<task_id>')
def processing(task_id):return render_template('processing.html', task_id=task_id)# 进度更新路由
@app.route('/progress/<task_id>')
def progress_status(task_id):def generate():while True:with progress_lock:status = progress.get(task_id, 0)yield f"data: {status}\n\n"if status >= 100 or status == -1:breakreturn Response(generate(), mimetype='text/event-stream')# 结果页面路由
@app.route('/result/<task_id>')
def result(task_id):result_data = results.get(task_id)if not result_data:return '结果未找到', 404# 获取处理时间elapsed_time = result_data.get('elapsed_time', 0)# 将处理时间格式化为 HH:MM:SSelapsed_time_str = str(timedelta(seconds=int(elapsed_time)))return render_template('result.html', original=result_data['original'], translated=result_data['translated'], #chatgpt_summary=result_data['chatgpt_summary'],elapsed_time=elapsed_time_str,enginet=result_data['enginet'],ocr_language=result_data['ocr_language'])if __name__ == '__main__':app.run(host='0.0.0.0', port=9006, debug=True)其它
我已经写了好几个Dockerfile req.txt 照着参考就也应该会的。 拼到一起,扔到 docker 里。我就不放上了。
知识是有价的,但分享是乐趣。 这些最基本的知识,也要去收费,设置门槛浏览,你们吃相很难看。
相关文章:
<Project-8.1.1 pdf2tx-mm> Python 调用 ChatGPT API 翻译PDF内容 历程心得
原因 用ZhipuAI,测试用的PDF里,有国名西部省穆斯林,翻译结果返回 “系统检测到输入或生成内容可能包含不安全或敏感内容,请您避免输入易产生敏感内容的提 示语,感谢您的配合” 。想过先替换掉省名、民族名等ÿ…...

JDK1.1主要特性
JDK 1.1,也被称为Java Development Kit 1.1,是Java编程语言的第一个更新版本,由Sun Microsystems公司在1997年发布。JDK 1.1在JDK 1.0的基础上进行了许多重要的改进和扩展,进一步巩固了Java作为一种强大、安全的编程语言和平台的地…...

软件测试工作中-商城类项目所遇bug点
商城的 bug 1、跨设备同步问题 当用户在不同设备上使用同一个账户时,购物车数据无法正确同步这可能是由于购物车数据存储和同步机制不完善,导致购物车内容在设备之间无法实时更新。怎么解决:开发把同步机制代码修改了一下,就不会出现这个 bug 了。 2、数…...

Java多线程面试题
1.进程和线程的区别 程序由指令和数据组成,但这些指令要运行,数据要读写,就必须将指令加载至 CPU中,数据加载至内存。在指令运行过程中还需要用到磁盘、网络等设备。进程就是用来加载指令、管理内存、管理 IO 的。 当一个程序被运…...

安徽大学《2022年+2023年831自动控制原理真题》 (完整版)
本文内容,全部选自自动化考研联盟的:《安徽大学831自控考研资料》的真题篇。后续会持续更新更多学校,更多年份的真题,记得关注哦~ 目录 2022年真题 2023年真题 Part1:2022年2023年完整版真题 2022年真题 2023年真题…...
Vulnhub靶场案例渗透[6]- DC6
文章目录 1. 靶场搭建2. 信息收集2.1 确定靶机ip2.2 主机信息收集2.3 主机目录扫描2.4 网站用户名和密码爆破 3. 反弹shell4. 提权 1. 靶场搭建 靶场源地址 检验下载文件的检验码,对比没问题使用vmware打开 # windwos 命令 Get-FileHash <filePath> -Algori…...

FreeSWITCH 分机网关路由
不废话了,直接贴代码: --[[作用:分机网关呼叫第一个参数: 分机号码第二个参数: 被叫号码第三个参数: 主叫号码使用例子:<extension name"usergw"><condition><action applicatio…...

数据交换的金钟罩:合理利用安全数据交换系统,确保信息安全
政府单位为了保护网络不受外部威胁和内部误操作的影响,通常会进行网络隔离,隔离成内网和外网。安全数据交换系统是专门设计用于在不同的网络环境(如内部不同网络,内部网络和外部网络)之间安全传输数据的解决方案。 使用…...
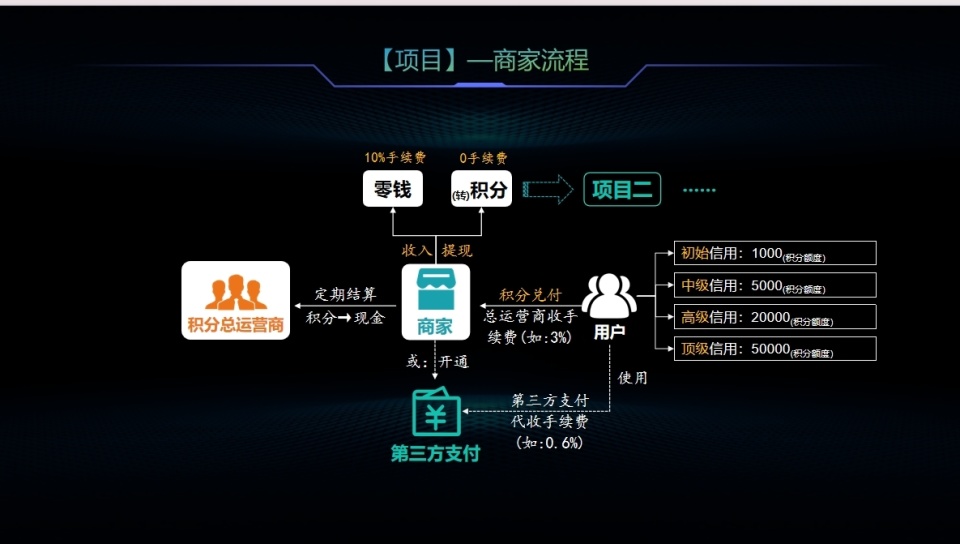
区块链积分系统:重塑支付安全与商业创新的未来
在当今社会,数字化浪潮席卷全球,支付安全与风险管理议题日益凸显。随着交易频次与规模的不断扩大,传统支付体系正面临前所未有的效率、合规性和安全挑战。 区块链技术,凭借其去中心化、高透明度以及数据不可篡改的特性,…...
Django学习笔记十三:优秀案例学习
Django CMS 是一个基于 Django 框架的开源内容管理系统,它允许开发者轻松地创建和管理网站内容。Django CMS 提供了一个易于使用的界面来实现动态网站的快速开发,并且具有丰富的内容管理功能和多种插件扩展。以下是 Django CMS 的一些核心特性和如何开始…...
SSH 公钥认证:从gitlab clone项目repo到本地
这篇文章的分割线以下文字内容由 ChatGPT 生成(我稍微做了一些文字上的调整和截图的补充),我review并实践后觉得内容没有什么问题,由此和大家分享。 假如你想通过 git clone git10.12.5.19:your_project.git 命令将 git 服务器上…...
linux 搭建sentinel
1.下载 linux执行下面的命令下载包 wget https://github.com/alibaba/Sentinel/releases/download/1.8.6/sentinel-dashboard-1.8.6.jar2.启动 nohup java -Dserver.port9090 -Dcsp.sentinel.dashboard.serverlocalhost:9090 -Dproject.namesentinel-dashboard -jar sentin…...
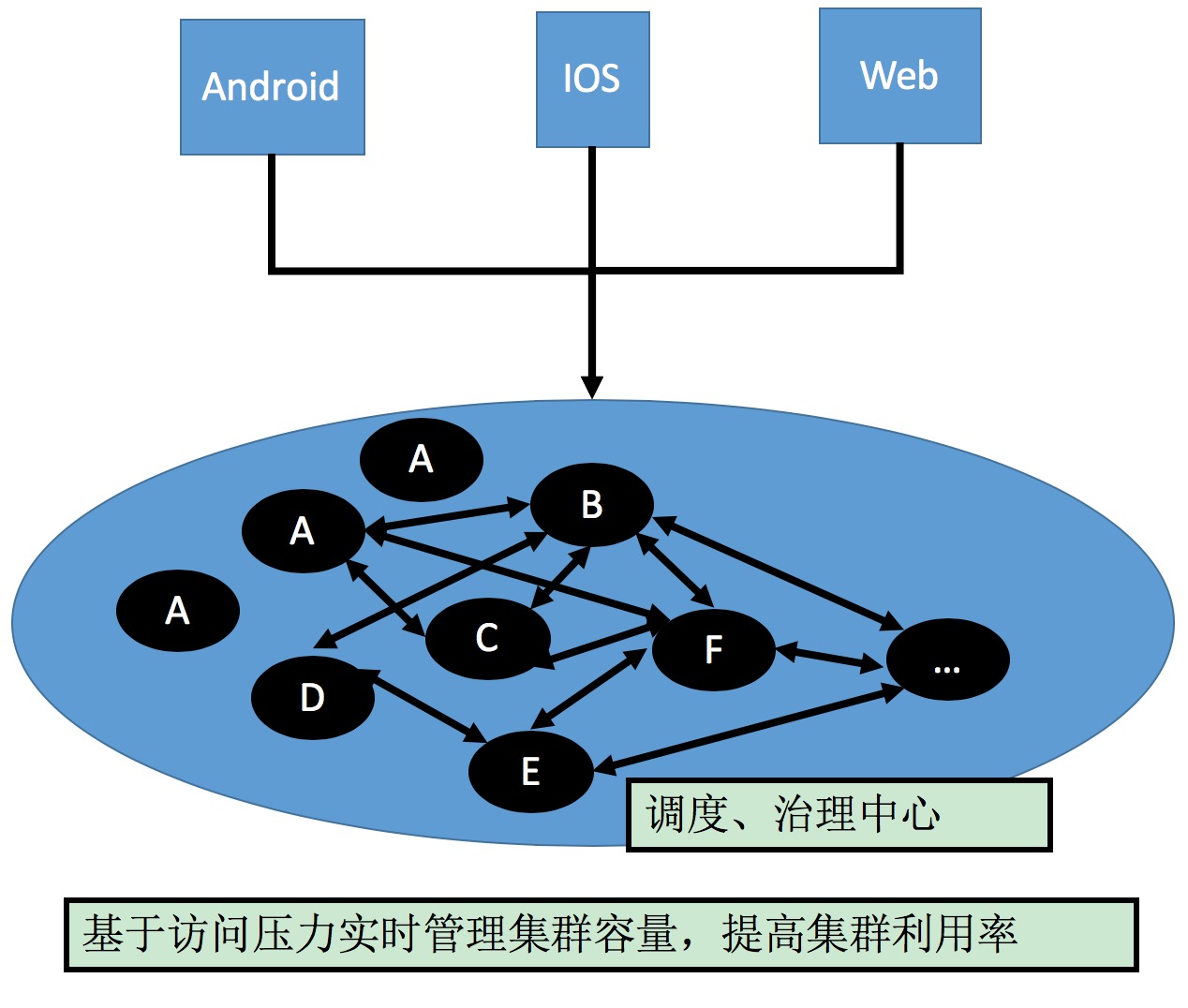
微服务发展历程
服务架构演进 服务架构演进过程:抽取各个模块独立维护,独立部署的过程。 初创公司2 ~ 3个研发人员,ALL IN ONE 的框架开发效率最高。随着队伍的壮大,产品,用户,商品成立独立小组,拆出相应的模块…...

提示词优化、GPTs逆向工程、大语言模型原理、大语言模型优化、开源模型本地私有化部署、从零构建大语言模型、智能体构建以及大语言模型的发展趋势
深入理解和掌握大语言模型的前言技术,涵盖了提示词优化、GPTs逆向工程、大语言模型原理、大语言模型优化、开源模型本地私有化部署、从零构建大语言模型、智能体构建以及大语言模型的发展趋势。通过系统化的学习,不仅掌握理论知识,还能在实际…...
)
nn.Conv2d(二)
**前置知识: 1、nn.Conv2d和torch.nn.functional.conv2d的对比: nn.Conv2d(能自主学习,更新调整卷积核) 模块:可以看作是一个“卷积层”,用在神经网络里。定义一次,用多次…...

获取鸿蒙设备Udid遇到的问题
参考官方文档:注册调试设备-调试应用(HarmonyOS)-AppGallery Connect帮助中心 - 华为HarmonyOS开发者 (huawei.com) 坑一:The sdk hdc.exe version is too low, please upgrade to the latest version. 升级dev工具和sdk配置为api…...

【华为HCIP实战课程十】OSPF网络DR和BDR实战讲解,网络工程师
一、DR与BDR的基础介绍 点到点同步LSA成本小 多点接入网络同步LSA成本大,需要DR/BDR 由于MA网络中,任意两台路由器都需要传递路由信息,网络中有n台路由器,则需要建立n*(n-1)/2个邻接关系。任何一台路由器的路由变化都会导致多次传递,浪费了带宽资源,DR和BDR应运而生!…...

视频怎么去除杂音保留人声?让人声更动听!视频噪音处理攻略
在视频制作过程中,音质是至关重要的一环。然而,很多时候我们录制的视频会伴随着各种不想要的杂音,比如风声、交通噪音或是其他环境音,这些杂音严重影响了观众的观看体验。那么,如何在保留人声的同时,有效地…...

洗衣店数字化转型:Spring Boot订单管理
3系统分析 3.1可行性分析 通过对本洗衣店订单管理系统实行的目的初步调查和分析,提出可行性方案并对其一一进行论证。我们在这里主要从技术可行性、经济可行性、操作可行性等方面进行分析。 3.1.1技术可行性 本洗衣店订单管理系统采用JAVA作为开发语言,S…...

Koa学习
Koa 安装与配置 1. 初始化项目 在终端中执行以下命令: # 创建项目文件夹 mkdir koa cd koa# 初始化并安装依赖 npm init -y npm install koa npm install nodemon --save-dev2. 修改 package.json 在 package.json 文件中进行如下修改: {"type…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

Applite:告别命令行!macOS软件管理的图形化终极解决方案
Applite:告别命令行!macOS软件管理的图形化终极解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Homebrew复杂的命令行操作而头疼吗&…...

如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南
如何快速提升游戏帧率:OpenSpeedy游戏加速优化终极指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏卡顿和掉帧?OpenSpeedy是一款…...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...

平衡车PID积分饱和问题
你发现了PID最致命的坑! 你说的完全正确:积分(Ki)是累加的,会无限叠加,直接让PWM爆掉、车猛冲、失控! 这就是积分饱和 —— 99%初学者死在这里。 我现在彻底讲透积分为什么炸、怎么修复、平衡车…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

如何选蜂蜜品牌?2026年5月推荐靠谱蜂蜜品牌避坑指南
一、引言买蜂蜜怕踩坑?市面上的蜂蜜产品琳琅满目,但勾兑蜜、浓缩蜜、添加糖浆的“科技蜜”层出不穷,消费者往往花了高价却买不到真正的纯正好蜜。对于注重健康饮食、追求天然原生态食品的消费者而言,如何从海量品牌中筛选出真正无…...

82.人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案
人工智能实战:大模型多环境治理怎么做?从开发、测试、预发到生产的 Prompt、模型、知识库隔离方案 一、问题场景:测试环境改了 Prompt,结果生产回答变了 很多大模型项目早期只有一个环境: 一套 Prompt 一个知识库 一个模型地址 一个配置表开发、测试、运营都在同一套配置…...

构建高质量Awesome教程库:从Claude Code实战到开发者知识体系搭建
1. 项目概述:一个为Claude Code打造的开发者知识库 最近在GitHub上看到一个挺有意思的项目,叫“awesome-claudcode-tutorial”。光看名字,你可能会有点懵——“Claude Code”是什么?这其实是一个由开发者社区推动的、围绕特定AI编…...