SpringBoot教程(二十四) | SpringBoot实现分布式定时任务之Quartz(基础)
SpringBoot教程(二十四) | SpringBoot实现分布式定时任务之Quartz(基础)
- 简介
- 适用场景
- Quartz核心概念
- Quartz 存储方式
- Quartz 版本类型
- 引入相关依赖
- 开始集成
- 方式一:内存方式(MEMORY)存储实现定时任务
- 1. 定义任务类
- 2. 定义任务描述及创建任务触发器
- 3. Quartz的yml配置(按需配置)
- 方式二:数据库(JDBC)方式存储实现定时任务
- 1. 创建相关表
- 2. 引入mysql相关依赖
- 3. 添加yml配置及相关配置类
- 启动查看
- 防止并发执行:上一周期还没执行完,下一周期又开始了
- 遇到的问题及解决
- 问题1:更改 Quartz 的 默认连接池配置
- 问题2:找不到名为 quartzDataSource 的数据源
- 问题3:jdbcUrl is required with driverClassName
- 问题4:url is required with driverClassName
简介
Quartz是一个完全由Java开发的开源任务日程管理系统(或称为作业调度框架),它能够集成于任何Java应用,小到独立的应用,大至电子商务系统。
Quartz提供了丰富的调度功能和灵活的配置选项,帮助开发者实现复杂的任务调度和定时任务功能。
适用场景
Quartz广泛应用于各种企业级应用系统中,如电子商务、金融、物流等领域。
无论是简单的定时任务(如定时发送邮件、定时清理临时文件等),还是复杂的分布式任务(如分布式定时任务调度、任务依赖关系管理等),Quartz都能够胜任。
Quartz核心概念
Job(作业)
Quartz中的任务,是一个需要被调度执行的接口,任务类需要实现该接口,并在execute方法中编写具体的业务逻辑。
JobDetail
JobDetail用来绑定Job,并为Job实例提供许多属性,如名称、组名、Job类名以及JobDataMap等。
JobDetail定义的是任务数据,而真正的执行逻辑是在Job中。
Trigger(触发器)
Trigger是Quartz的触发器,它描述了触发Job执行的时间触发规则。
Trigger最常用的触发器类型:SimpleTrigger和CronTrigger。
Scheduler(调度器)
Scheduler是Quartz的调度器,它负责基于Trigger设定的时间执行Job。Scheduler是一个容器,它装载着任务和触发器。
Quartz 存储方式
Quartz 存储方式有两种:MEMORY 和 JDBC。
- MEMORY(或RAMJobStore):这是Quartz的默认存储方式,它将任务调度的运行信息保存在内存中。这种方式提供了最佳的性能,因为内存中数据访问最快。然而,它的不足之处在于缺乏数据的持久性,当程序中途停止或系统崩溃时,所有运行的信息都会丢失。
- JDBC:这种存储方式允许Quartz通过JDBC将任务调度的运行信息保存到数据库中。使用数据库保存任务调度信息后,即使系统崩溃后重新启动,任务的调度信息也将得到恢复。因此,JDBC存储方式提供了数据的持久性。
Quartz 版本类型
Quartz 版本类型有两种:单机版 和 集群版
-
单机版:这是Quartz的默认版本类型 ,Quartz运行在一个单一的Java虚拟机(JVM)实例中。它通常使用MEMORY存储方式,因为这种方式配置容易且运行速度快。然而,单机版Quartz存在单点故障的风险,如果应用程序所在的服务器出现故障,任务调度将会停止。
-
集群版:集群版Quartz可以在多个JVM实例中运行,实现高可用性和负载均衡。在集群版中,通常使用JDBC存储方式,以便在多个节点之间共享任务调度的数据。这样,即使其中一个节点出现故障,其他节点仍然可以继续工作,从而保证了任务调度的连续性和可靠性。
引入相关依赖
<!--quartz定时任务-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
开始集成
方式一:内存方式(MEMORY)存储实现定时任务
1. 定义任务类
可以通过实现 Job 接口来定义任务,也可以通过继承 QuartzJobBean 这个抽象类来定义任务,其实 QuartzJobBean 本身也实现了 Job 接口,其本质都是实现 Job 接口来定义任务。
我这边定义了两个任务,用于后续来说明一下关于调度器Scheduler绑定的不同方式
Scheduler绑定有两种方式,一种是使用bena的自动配置,一种是Scheduler手动配置。
FirstJob 类
package com.example.springbootfull.quartztest;import lombok.extern.slf4j.Slf4j;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.scheduling.quartz.QuartzJobBean;import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;@Slf4j
public class FirstJob extends QuartzJobBean {@Overrideprotected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {String now = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").format(LocalDateTime.now());log.info("手动-FirstJob, 当前的时间: " + now);}
}SecondJob 类
package com.example.springbootfull.quartztest;import lombok.extern.slf4j.Slf4j;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.scheduling.quartz.QuartzJobBean;import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;@Slf4j
public class SecondJob extends QuartzJobBean {@Overrideprotected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {String now = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").format(LocalDateTime.now());log.info("自动-SecondJob, 当前的时间: " + now);}
}2. 定义任务描述及创建任务触发器
方式一:Scheduler手动配置
这个例子使用的是触发器类型为Cron
package com.example.springbootfull.quartztest.config;import com.example.springbootfull.quartztest.FirstJob;
import org.quartz.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;@Component
public class JobInit implements ApplicationRunner {private static final String ID = "MANUAL";@Autowiredprivate Scheduler scheduler;@Overridepublic void run(ApplicationArguments args) throws Exception {// 配置定时任务的信息,例如配置定时任务的名字,群组之类的JobDetail jobDetail = JobBuilder.newJob(FirstJob.class).withIdentity(ID + " 01")// 设置Job的标识符.storeDurably()// 使JobDetail持久化.build();//触发器类型CronScheduleBuilder scheduleBuilder =CronScheduleBuilder.cronSchedule("0/5 * * * * ? *");// 创建任务触发器Trigger trigger = TriggerBuilder.newTrigger().forJob(jobDetail) //指定 定时任务.withIdentity(ID + " 01Trigger") // 设置Trigger的标识符.withSchedule(scheduleBuilder) //配置触发器类型.startNow() //立即執行一次任務.build();// 手动将触发器与任务绑定到调度器内scheduler.scheduleJob(jobDetail, trigger);}
}方式二:使用bena的自动配置(建议这种)
这个例子使用的是触发器类型为Simple
package com.example.springbootfull.quartztest.config;import com.example.springbootfull.quartztest.SecondJob;
import org.quartz.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class QuartzConfig {private static final String ID = "AUTOMATIC";//配置定时任务的信息,例如配置定时任务的名字,群组之类的@Beanpublic JobDetail jobDetail1() {return JobBuilder.newJob(SecondJob.class).withIdentity(ID + " 01")// 设置Job的标识符.storeDurably()// 使JobDetail持久化.build();}//创建任务触发器@Beanpublic SimpleTrigger trigger1() {// 简单的调度计划的构造器SimpleScheduleBuilder scheduleBuilder = SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(6) // 频率.repeatForever(); // 无限期地重复执行return TriggerBuilder.newTrigger().forJob(jobDetail1())//指定 定时任务.withIdentity(ID + " 01Trigger").withSchedule(scheduleBuilder).build();}
}
运行启动类以后,可以看到如下情况

3. Quartz的yml配置(按需配置)
yml配置可以更为精细化的,调整 存储配置 及 线程池配置
spring:# Quartz 的配置,对应 QuartzProperties 配置类quartz:job-store-type: memory # Job 存储器类型。默认为 memory 表示内存,可选 jdbc 使用数据库。auto-startup: true # Quartz 是否自动启动startup-delay: 0 # 延迟 N 秒启动wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 trueoverwrite-existing-jobs: false # 是否覆盖已有 Job 的配置properties: # 添加 Quartz Scheduler 附加属性org:quartz:threadPool:threadCount: 25 # 线程池大小。默认为 10 。threadPriority: 5 # 线程优先级class: org.quartz.simpl.SimpleThreadPool # 线程池类型
# jdbc: # 这里暂时不说明,使用 JDBC 的 JobStore 的时候,才需要配置
方式二:数据库(JDBC)方式存储实现定时任务
1. 创建相关表
首先确定maven拉取了 spring-boot-starter-quartz 的依赖,再接着到私仓下面找到
"你的私仓地址\org\quartz-scheduler\quartz\2.3.2"把这个下面的quartz-2.3.2.jar 给解压
然后到这个文件的 “quartz-2.3.2\org\quartz\impl\jdbcjobstore” 下面就可以可以看到

我这边选择的是“tables_mysql_innodb.sql”脚本
内容如下,执行以后会出现11张表
#
# In your Quartz properties file, you'll need to set
# org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#
#
# By: Ron Cordell - roncordell
# I didn't see this anywhere, so I thought I'd post it here. This is the script from Quartz to create the tables in a MySQL database, modified to use INNODB instead of MYISAM.DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;CREATE TABLE QRTZ_JOB_DETAILS(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(190) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_SIMPLE_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_CRON_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_SIMPROP_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(190) NOT NULL,TRIGGER_GROUP VARCHAR(190) NOT NULL,STR_PROP_1 VARCHAR(512) NULL,STR_PROP_2 VARCHAR(512) NULL,STR_PROP_3 VARCHAR(512) NULL,INT_PROP_1 INT NULL,INT_PROP_2 INT NULL,LONG_PROP_1 BIGINT NULL,LONG_PROP_2 BIGINT NULL,DEC_PROP_1 NUMERIC(13,4) NULL,DEC_PROP_2 NUMERIC(13,4) NULL,BOOL_PROP_1 VARCHAR(1) NULL,BOOL_PROP_2 VARCHAR(1) NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_BLOB_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
INDEX (SCHED_NAME,TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_CALENDARS (
SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(190) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME))
ENGINE=InnoDB;CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;CREATE TABLE QRTZ_FIRED_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(190) NULL,
JOB_GROUP VARCHAR(190) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID))
ENGINE=InnoDB;CREATE TABLE QRTZ_SCHEDULER_STATE (
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME))
ENGINE=InnoDB;CREATE TABLE QRTZ_LOCKS (
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME))
ENGINE=InnoDB;CREATE INDEX IDX_QRTZ_J_REQ_RECOVERY ON QRTZ_JOB_DETAILS(SCHED_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_J_GRP ON QRTZ_JOB_DETAILS(SCHED_NAME,JOB_GROUP);CREATE INDEX IDX_QRTZ_T_J ON QRTZ_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_JG ON QRTZ_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_C ON QRTZ_TRIGGERS(SCHED_NAME,CALENDAR_NAME);
CREATE INDEX IDX_QRTZ_T_G ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_T_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_G_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NEXT_FIRE_TIME ON QRTZ_TRIGGERS(SCHED_NAME,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE_GRP ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);CREATE INDEX IDX_QRTZ_FT_TRIG_INST_NAME ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME);
CREATE INDEX IDX_QRTZ_FT_INST_JOB_REQ_RCVRY ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_FT_J_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_JG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_T_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_FT_TG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);commit;
表的说明
| 表名称 | 说明 |
|---|---|
| qrtz_blob_triggers | blog类型存储triggers |
| qrtz_calendars | 以blog类型存储Calendar信息 |
| qrtz_cron_triggers | 存储cron trigger信息 |
| qrtz_fired_triggers | 存储已触发的trigger相关信息 |
| qrtz_job_details | 存储每一个已配置的job details |
| qrtz_locks | 存储悲观锁的信息 |
| qrtz_paused_trigger_grps | 存储已暂停的trigger组信息 |
| qrtz_scheduler_state | 存储Scheduler状态信息 |
| qrtz_simple_triggers | 存储simple trigger信息 |
| qrtz_simprop_triggers | 存储其他几种trigger信息 |
| qrtz_triggers | 存储已配置的trigger信息 |
所有的表中都含有一个SCHED_NAME字段,对应我们配置的scheduler-name,相同 Scheduler-name的节点,形成一个 Quartz 集群。
2. 引入mysql相关依赖
<!-- MySQL连接 -->
<dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId>
</dependency>
<!--mybatis-plus 这个版本需要指定了,因为场景启动器里面没有 -->
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.7</version>
</dependency>
3. 添加yml配置及相关配置类
spring:datasource:quartz:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/quartz?serverTimezone=GMT%2B8username: rootpassword: rootquartz:job-store-type: jdbc # 使用数据库存储scheduler-name: hyhScheduler # 相同 Scheduler 名字的节点,形成一个 Quartz 集群wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 truejdbc:initialize-schema: never # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,表示我们手动创建表结构。properties:org:quartz:# JobStore 相关配置jobStore:# 使用的数据源 (和配置类DataSourceConfiguration的 @Bean(name = "quartzDataSource") 存在直接关系)dataSource: quartzDataSource #class: org.quartz.impl.jdbcjobstore.JobStoreTX # JobStore 实现类driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegatetablePrefix: QRTZ_ # Quartz 表前缀isClustered: true # 是集群模式clusterCheckinInterval: 1000useProperties: false# 线程池相关配置threadPool:threadCount: 25 # 线程池大小。默认为 10 。threadPriority: 5 # 线程优先级class: org.quartz.simpl.SimpleThreadPool # 线程池类型新建DataSourceConfiguration 配置类
该类为数据源配置类
目前只是配置了quartz 数据源,暂不支持多数据源
如需多数据源配置,请往下看
package com.example.springbootfull.quartztest.config;import com.zaxxer.hikari.HikariDataSource;
import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties;
import org.springframework.boot.autoconfigure.quartz.QuartzDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.util.StringUtils;import javax.sql.DataSource;/*** 该类为数据源配置类* 目前只是配置了quartz 数据源,暂不支持多数据源* 如需多数据源配置,请自行补充*/
@Configuration
public class DataSourceConfiguration {private static HikariDataSource createHikariDataSource(DataSourceProperties properties) {// 创建 HikariDataSource 对象HikariDataSource dataSource = properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();// 设置线程池名if (StringUtils.hasText(properties.getName())) {dataSource.setPoolName(properties.getName());}return dataSource;}/*** 创建 quartz 数据源的配置对象*/@Primary@Bean(name = "quartzDataSourceProperties")@ConfigurationProperties(prefix = "spring.datasource.quartz")// 读取 spring.datasource.quartz 配置到 DataSourceProperties 对象public DataSourceProperties quartzDataSourceProperties() {return new DataSourceProperties();}/*** 创建 quartz 数据源*/@Bean(name = "quartzDataSource")//@ConfigurationProperties(prefix = "spring.datasource.quartz.hikari")@QuartzDataSourcepublic DataSource quartzDataSource() {// 获得 DataSourceProperties 对象DataSourceProperties properties = this.quartzDataSourceProperties();// 创建 HikariDataSource 对象return createHikariDataSource(properties);}}启动查看
启动启动类后,发现数据库表里面有数据了

防止并发执行:上一周期还没执行完,下一周期又开始了
使用 @DisallowConcurrentExecution 注解:这可以确保同一时间只有一个该任务的实例在执行,从而避免并发执行带来的问题。
但是,这可能会导致任务执行的延迟,因为新实例必须等待前一个实例完成。
举例:
@Slf4j
@DisallowConcurrentExecution
public class SecondJob extends QuartzJobBean {@Overrideprotected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {JobDetail jobDetail = jobExecutionContext.getJobDetail();log.info("------任务名:" + jobDetail.getKey().getName() + ",组名:" +jobDetail.getKey().getGroup() + "------我是要执行的定时任务工作内容!");}
}遇到的问题及解决
问题1:更改 Quartz 的 默认连接池配置
Quartz 2.0 以前 需要使用的 DBCP 作为数据库连接池
Quartz 2.0 以后 C3P0(包含2.0)需要使用 C3P0 作为数据库连接池
这个时候我们就需要更改这个连接池,改用 HikariCP 或者 Druid
方式一:关键属性 provider :
#指定的数据源名称
spring.quartz.properties.org.quartz.jobStore.dataSource=quartz_jobs
#指定数据库连接池
spring.quartz.properties.org.quartz.dataSource.quartz_jobs.provider=hikaricp
方式二:初始化为 HikariDataSource 的数据源
private static HikariDataSource createHikariDataSource(DataSourceProperties properties) {// 创建 HikariDataSource 对象HikariDataSource dataSource = properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();// 设置线程池名if (StringUtils.hasText(properties.getName())) {dataSource.setPoolName(properties.getName());}return dataSource;}
问题2:找不到名为 quartzDataSource 的数据源
当你的spring版本为spring 2.6.x 版本的 集成Quartz时,如果启动时报错如下
Failed to obtain DB connection from data source ‘quartzDataSource’: java.sql.SQLException: There is no DataSource named ‘quartzDataSource’
解决方法一:去掉配置的org.quartz.jobStore.class属性即可解决该问题。
解决方法二:把 org.quartz.impl.jdbcjobstore.JobStoreTX 改成 org.springframework.scheduling.quartz.LocalDataSourceJobStore
问题3:jdbcUrl is required with driverClassName
使用了HikariCP连接池时,spring.datasource.jdbc-url 才是有效属性
问题4:url is required with driverClassName
没有使用HikariCP连接池时,spring.datasource.url 才是有效属性
参考文章如下:
【1】SpringBoot整合任务调度框架Quartz及持久化配置
【2】玩转 Spring Boot 集成篇(定时任务框架Quartz)
【3】springboot升级2.6.x,Quartz2.3.2找不到数据源
【4】springboot升级到2.7.17后,quartz集群模式配置修改
【5】Quartz配置Springboot自带连接池Hikaricp
【6】定时任务Quartz总结
相关文章:
SpringBoot教程(二十四) | SpringBoot实现分布式定时任务之Quartz(基础)
SpringBoot教程(二十四) | SpringBoot实现分布式定时任务之Quartz(基础) 简介适用场景Quartz核心概念Quartz 存储方式Quartz 版本类型引入相关依赖开始集成方式一:内存方式(MEMORY)存储实现定时任务1. 定义任务类2. 定…...

【现代控制理论】第2-5章课后题刷题笔记
文章目录 第二章:线性控制系统的状态空间描述第三章:控制系统状态空间描述的特性3.1 计算状态转移矩阵(矩阵指数函数)3.2 计算系统的时间响应(状态方程的解)3.3 判断系统的能控性和能观性,以及能…...
Proteus仿真STM32单片机使用定时器控制LED)
(四)Proteus仿真STM32单片机使用定时器控制LED
(四)Protues仿真STM32单片机使用定时器控制LED – ARMFUN 定时器在单片机中具有重要的作用,它可以提供精确的时间控制和事件触发功能。相比之下,使用延时函数(delay function)来实现时间控制存在以下一些坏…...

Python快速编程小案例——打印蚂蚁森林植树证书
提示:(个人学习),案例来自工业和信息化“十三五”人才培养规划教材,《Python快速编程入门》第2版,黑马程序员◎编著 蚂蚁森林是支付宝客户端发起“碳账户”的一款公益活动:用户通过步行地铁出行、在线消费等…...

Cherno游戏引擎笔记(61~72)
---------------一些维护和更改------------- 》》》》 Made Win-GenProjects.bat work from every directory 代码更改: echo off->pushd ..\->pushd %~dp0\..\call vendor\bin\premake\premake5.exe vs2019popdPAUSE 为什么要做这样的更改? …...

FWA(固定无线接入),CPE(客户终端设备)简介
文章目录 FWA(Fixed Wireless Access),固定无线接入CPE(Customer Premise Equipment),用户驻地设备 FWA(Fixed Wireless Access),固定无线接入 固定无线接入(…...

使用IDEA启动项目build时,解决Java编译时内存溢出问题:OutOfMemoryError深入解析
文章目录 简介问题描述解决方案常见解决方案示例代码示例1:增加JVM堆内存代码示例2:检查并修复内存泄漏代码示例3:分批编译代码示例4:使用编译器参数减少内存使用代码示例5:升级编译器和库 结论进一步的资源 简介 在J…...

Kafka如何实现高可用
Kafka实现高可用性主要依赖于其副本机制和Leader选举。以下是Kafka实现高可用的关键点: 多副本机制:Kafka中的每个分区(Partition)都有多个副本(Replica),这些副本分布在不同的Broker上。其中一…...

高级java每日一道面试题-2024年10月1日-服务器篇[Redis篇]-Redis数据结构压缩列表和跳跃表的区别?
如果有遗漏,评论区告诉我进行补充 面试官: Redis数据结构压缩列表和跳跃表的区别? 我回答: 关于Redis数据结构的理解是一个重要的考察点,特别是压缩列表(ziplist)和跳跃表(skiplist)这两种数据结构&…...
功能)
使用 ElLoading 组件来实现加载(loading)功能
在 Element Plus 中,你可以使用 ElLoading 组件来实现加载(loading)功能。ElLoading 通常用于在数据加载或某些异步操作进行时,向用户展示一个覆盖整个页面的加载提示。 以下是如何在你的 Vite Vue 3 JavaScript 项目中使用 El…...

Win10 IDEA连接虚拟机中的Hadoop(HDFS)
获取虚拟机的ip 虚拟机终端输入 ip a关闭虚拟机防火墙 sudo ufw disable修改Hadoop的core-site.xml文件 将localhost修改为虚拟机局域网IP # 位置可能不一样,和Hadoop安装位置有关 cd /usr/local/hadoop/etc/hadoop vim core-site.xmlIDEA 连接 创建Maven项目…...

tp8自带的文件缓存如何配置
TP8自带的缓存是文件缓存。 ThinkPHP6默认的缓存驱动是文件缓存,它将缓存数据存储在应用的runtime目录下的cache目录中。文件缓存适用于单机环境下的应用,对于数据量较小且读写频率较低的应用场景,是一种简单有效的缓存方案。 ThinkPHP8…...

【环境搭建】MAC M1安装ElasticSearch
STEP1 官网下载ES Download Elasticsearch | Elastic,下载mac m1对应版本的es STEP2 进入bin文件夹,执行./elasticSearch 浏览器输入 127.0.0.1:9200 STEP 3 下载对应Kibana版本,Download Kibana Free | Get Started Now | Elastic 出现报错…...
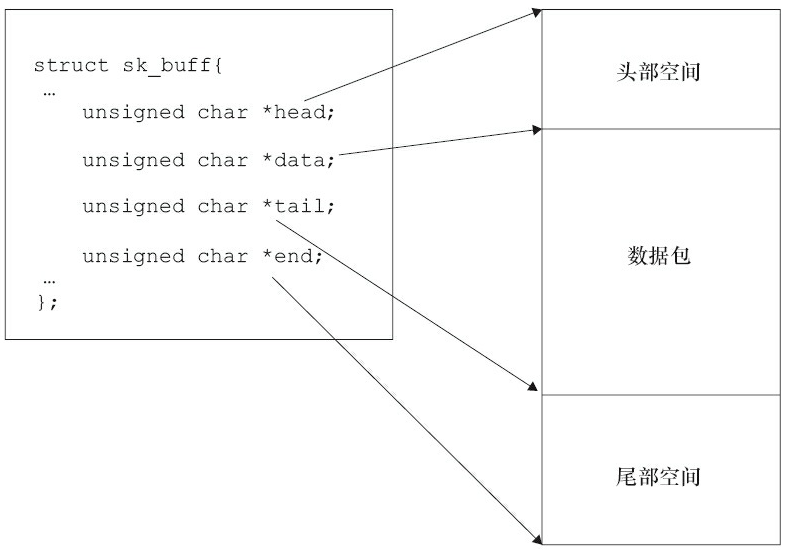
[linux 驱动]网络设备驱动详解
目录 1 描述 2 结构体 2.1 net_device 2.2 sk_buff 2.3 net_device_ops 2.4 ethtool_ops 3 相关函数 3.1 网络协议接口层 3.1.1 dev_queue_xmit 3.1.2 netif_rx 3.1.3 alloc_skb 3.1.4 kfree_skb 3.1.5 skb_put 3.1.6 skb_push 3.1.7 skb_reserve 3.2 网络设备驱…...

【ShuQiHere】 重新定义搜索:本体搜索引擎的时代
🌐 【ShuQiHere】 什么是本体搜索引擎?🤖 本体搜索引擎(Ontological Search Engine, OSE) 是一种基于语义理解和本体结构的智能搜索工具。与传统的关键词搜索不同,本体搜索引擎能够理解搜索背后的深层语义…...

Ruby脚本:自动化网页图像下载的实践案例
随着互联网的快速发展,网页上的内容变得越来越丰富,尤其是图像资源。对于需要大量图像资源的设计师、内容创作者或数据分析师来说,手动下载这些图片不仅耗时耗力,而且效率低下。因此,自动化网页图像下载成为了一个迫切…...

ArcGIS中分区统计栅格值前需要进行投影吗(在投影坐标系下进行吗),为什么?
最近,我接到了一个分区统计栅格数值前需要进行投影,或者说是必须需要在投影坐标系下进行吗的咨询。 答案是不需要刻意去变。 但是他又说他把地理坐标系下分区统计结果与投影坐标系下的分区统计结果分别做了一遍,并进行了对比,两个…...

怎么将视频原声提出来?视频原声提取,让创作更自由
在数字媒体时代,视频已成为我们日常生活和工作中不可或缺的一部分。有时,我们可能想要提取视频中的音频部分,无论是为了制作音频素材、学习语言,还是为了其他创意用途。那么,怎么将视频原声提出来呢?本文将…...

在IDEA里用XDebug调试PHP,断点....
做程序开发,调试必不可少,这里最近用到了PHP,顺便写个关于PHP的调试安装使用: 1、首先是PHP先安装xdebug扩展(还有zend的),这个我的工具是IDEA,所以安装方法也相对简单,如果你是用VSCode等应该也是一样,如下图,找到这个PHP->DEBUG 2、直接点上面的Install XDebug 就可以帮你…...

如何设置 GitLab 密码过期时间?
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 60天专业…...

IDEA 2018.2.3 下 Maven 依赖包消失?别慌,可能是版本兼容性在作祟
IDEA 2018.2.3 下 Maven 依赖包消失的深度排查指南 当你打开一个尘封已久的老项目,准备继续维护或迁移时,突然发现IDEA的External Libraries里空空如也,只剩下孤零零的JDK包,整个项目文件一片飘红——这种场景对许多维护历史代码库…...

Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生
Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你心爱的Netgear路由器因为固件升级失败、意外断电或其他原因变成一块"砖头&q…...

终极CoreCycler教程:简单三步完成CPU稳定性测试与优化
终极CoreCycler教程:简单三步完成CPU稳定性测试与优化 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.com/…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验
WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经面对游戏修改工具…...

高效视频帧提取终极指南:为深度学习构建专业数据集
高效视频帧提取终极指南:为深度学习构建专业数据集 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

NCM格式转换实战指南:ncmdumpGUI全面解析
NCM格式转换实战指南:ncmdumpGUI全面解析 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的NCM格式音乐无法在其他设备播…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...