springboot kafka多数据源,通过配置动态加载发送者和消费者
前言
最近做项目,需要支持kafka多数据源,实际上我们也可以通过代码固定写死多套kafka集群逻辑,但是如果需要不修改代码扩展呢,因为kafka本身不处理额外逻辑,只是起到削峰,和数据的传递,那么就需要对架构做一定的设计了。
准备test
kafka本身非常容易上手,如果我们需要单元测试,引入jar依赖,JDK使用1.8,当然也可以使用JDK17
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.7.17</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>2.7.17</version><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.9.13</version></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><version>2.9.13</version><scope>test</scope></dependency><!-- https://mvnrepository.com/artifact/org.testcontainers/kafka --><dependency><groupId>org.testcontainers</groupId><artifactId>kafka</artifactId><version>1.20.1</version><scope>test</scope></dependency></dependencies>修改发送者和接收者
@Component
public class KafkaProducer {private static final Logger LOGGER = LoggerFactory.getLogger(KafkaProducer.class);@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void send(String topic, String payload) {LOGGER.info("sending payload='{}' to topic='{}'", payload, topic);kafkaTemplate.send(topic, payload);}
}@Component
public class KafkaConsumer {private static final Logger LOGGER = LoggerFactory.getLogger(KafkaConsumer.class);private String payload;@KafkaListener(topics = "${test.topic}")public void receive(ConsumerRecord<?, ?> consumerRecord) {LOGGER.info("----------------received payload='{}'", consumerRecord.toString());payload = consumerRecord.toString();}public String getPayload() {return payload;}public void setPayload(String payload) {this.payload = payload;}
}然后写main方法,随意写一个即可,配置入戏
spring:kafka:consumer:auto-offset-reset: earliestgroup-id: mytest
test:topic: embedded-test-topic写一个单元测试
@SpringBootTest
@EmbeddedKafka(partitions = 1, brokerProperties = { "listeners=PLAINTEXT://localhost:9092", "port=9092" })
class DemoMainTest {@Autowiredprivate KafkaConsumer consumer;@Autowiredprivate KafkaProducer producer;@Value("${test.topic}")private String topic;@Testvoid embedKafka() throws InterruptedException {String data = "Sending with our own simple KafkaProducer";producer.send(topic, data);Thread.sleep(3000);assertThat(consumer.getPayload(), containsString(data));Thread.sleep(10000);}
}通过
@EmbeddedKafka(partitions = 1, brokerProperties = { "listeners=PLAINTEXT://localhost:9092", "port=9092" })
直接模拟一个kafka,里面有一些注解参数,可以设置broker的 数量端口,zk的端口,topic和partition数量等

实际上是通过embed zk和kafka来mock了一个kafka server
单元测试运行成功
![]()

思路
有了kafka单元测试后,根据springboot map可以接收多套配置的方式不就实现了kafka的多数据源的能力,貌似非常简单;但是如果需要不用修改代码,消费端怎么办,发送者可以手动创建,消费端是注解方式,topic等信息在注解参数中,注解参数值却是常量,代码写死的,那么我们就需要:
- 不让Springboot自动扫描,根据配置手动扫描注册bean
- 字节码生成bean,就可以根据参数
这里没考虑把消费端和发送者的额外处理逻辑写在这里的做法,统一处理kafka,类似kafka网关,因为kafka一般不会仅一套,且不会仅有一个topic,需要分发处理,比如slb,feign等。
kafka消费者的原理
其实kafka发送者和消费者也是类似逻辑,但是spring-kafka通过注解方式实现消费者,如果我们使用原生kafka的kafkaconsumer,那么只需要通过Map接收参数,然后自己实现消费逻辑就行,但是spring-kafka毕竟做了很多公共没必要的逻辑,拉取消费的一系列参数,线程池管理等处理措施。看看Spring-kafka的消费者初始化原理,
BeanPostProcessor的kafka实现
org.springframework.kafka.annotation.KafkaListenerAnnotationBeanPostProcessor
看前置处理

什么都没做,所以,所有逻辑都在后置处理
public Object postProcessAfterInitialization(final Object bean, final String beanName) throws BeansException {if (!this.nonAnnotatedClasses.contains(bean.getClass())) {Class<?> targetClass = AopUtils.getTargetClass(bean);//找到注解,消费注解KafkaListener打在类上,一般不用这种方式Collection<KafkaListener> classLevelListeners = findListenerAnnotations(targetClass);//类上KafkaListener注解的标志final boolean hasClassLevelListeners = classLevelListeners.size() > 0;final List<Method> multiMethods = new ArrayList<>();//找到消费方法,去每个方法上找KafkaListener注解Map<Method, Set<KafkaListener>> annotatedMethods = MethodIntrospector.selectMethods(targetClass,(MethodIntrospector.MetadataLookup<Set<KafkaListener>>) method -> {Set<KafkaListener> listenerMethods = findListenerAnnotations(method);return (!listenerMethods.isEmpty() ? listenerMethods : null);});if (hasClassLevelListeners) {//类上KafkaListener注解的时候,通过另外的注解KafkaHandler的方式,找到消费方法Set<Method> methodsWithHandler = MethodIntrospector.selectMethods(targetClass,(ReflectionUtils.MethodFilter) method ->AnnotationUtils.findAnnotation(method, KafkaHandler.class) != null);multiMethods.addAll(methodsWithHandler);}//实际上大部分类是没有kafka消费注解的,效率并不高,但是因为日志是trace,所以日志一般默认看不见//注解KafkaListener打在方法上的时候if (annotatedMethods.isEmpty() && !hasClassLevelListeners) {this.nonAnnotatedClasses.add(bean.getClass());this.logger.trace(() -> "No @KafkaListener annotations found on bean type: " + bean.getClass());}else {// Non-empty set of methodsfor (Map.Entry<Method, Set<KafkaListener>> entry : annotatedMethods.entrySet()) {Method method = entry.getKey();for (KafkaListener listener : entry.getValue()) {//核心逻辑processKafkaListener(listener, method, bean, beanName);}}this.logger.debug(() -> annotatedMethods.size() + " @KafkaListener methods processed on bean '"+ beanName + "': " + annotatedMethods);}//注解KafkaListener打在类上,实际上处理逻辑跟KafkaListener打在方法上差不多if (hasClassLevelListeners) {processMultiMethodListeners(classLevelListeners, multiMethods, bean, beanName);}}return bean;}如果是注解打在类上,如下

本文中的示例的@KafkaListener打在方法上,所以分析
processKafkaListener
其实原理都一样,spring-kafka不会写2份一样逻辑,只是读取处理的参数略有不同
protected synchronized void processKafkaListener(KafkaListener kafkaListener, Method method, Object bean,String beanName) {//检查代理Method methodToUse = checkProxy(method, bean);//终端设计思想,Spring很多地方都这样设计,尤其是swaggerMethodKafkaListenerEndpoint<K, V> endpoint = new MethodKafkaListenerEndpoint<>();endpoint.setMethod(methodToUse);//bean的名称,这里需要定制全局唯一,否则多个listener会冲突String beanRef = kafkaListener.beanRef();this.listenerScope.addListener(beanRef, bean);String[] topics = resolveTopics(kafkaListener);TopicPartitionOffset[] tps = resolveTopicPartitions(kafkaListener);if (!processMainAndRetryListeners(kafkaListener, bean, beanName, methodToUse, endpoint, topics, tps)) {//核心逻辑processListener(endpoint, kafkaListener, bean, beanName, topics, tps);}this.listenerScope.removeListener(beanRef);}继续
processListener
protected void processListener(MethodKafkaListenerEndpoint<?, ?> endpoint, KafkaListener kafkaListener,Object bean, String beanName, String[] topics, TopicPartitionOffset[] tps) {//MethodKafkaListenerEndpoint赋值了,这个很关键processKafkaListenerAnnotation(endpoint, kafkaListener, bean, topics, tps);//容器工厂String containerFactory = resolve(kafkaListener.containerFactory());KafkaListenerContainerFactory<?> listenerContainerFactory = resolveContainerFactory(kafkaListener,containerFactory, beanName);//注册终端,最终生效this.registrar.registerEndpoint(endpoint, listenerContainerFactory);}processKafkaListenerAnnotation
private void processKafkaListenerAnnotation(MethodKafkaListenerEndpoint<?, ?> endpoint,KafkaListener kafkaListener, Object bean, String[] topics, TopicPartitionOffset[] tps) {endpoint.setBean(bean);endpoint.setMessageHandlerMethodFactory(this.messageHandlerMethodFactory);endpoint.setId(getEndpointId(kafkaListener));endpoint.setGroupId(getEndpointGroupId(kafkaListener, endpoint.getId()));endpoint.setTopicPartitions(tps);endpoint.setTopics(topics);endpoint.setTopicPattern(resolvePattern(kafkaListener));endpoint.setClientIdPrefix(resolveExpressionAsString(kafkaListener.clientIdPrefix(), "clientIdPrefix"));endpoint.setListenerInfo(resolveExpressionAsBytes(kafkaListener.info(), "info"));String group = kafkaListener.containerGroup();if (StringUtils.hasText(group)) {Object resolvedGroup = resolveExpression(group);if (resolvedGroup instanceof String) {endpoint.setGroup((String) resolvedGroup);}}String concurrency = kafkaListener.concurrency();if (StringUtils.hasText(concurrency)) {endpoint.setConcurrency(resolveExpressionAsInteger(concurrency, "concurrency"));}String autoStartup = kafkaListener.autoStartup();if (StringUtils.hasText(autoStartup)) {endpoint.setAutoStartup(resolveExpressionAsBoolean(autoStartup, "autoStartup"));}resolveKafkaProperties(endpoint, kafkaListener.properties());endpoint.setSplitIterables(kafkaListener.splitIterables());if (StringUtils.hasText(kafkaListener.batch())) {endpoint.setBatchListener(Boolean.parseBoolean(kafkaListener.batch()));}endpoint.setBeanFactory(this.beanFactory);resolveErrorHandler(endpoint, kafkaListener);resolveContentTypeConverter(endpoint, kafkaListener);resolveFilter(endpoint, kafkaListener);}各种参数注册,尤其是其中的ID和handler是必须的,不注册不行;笔者试着自己设置endpoint,发现其中的各种handler注册。
解决方式
先写一个工具类,用于创建一些关键类的bean,定义了发送者创建,消费者工厂类,消费者的创建由注解扫描实现,引用工具类的消费者容器工厂bean。
public class KafkaConfigUtil {private DefaultKafkaProducerFactory<String, String> initProducerFactory(KafkaProperties kafkaProperties) {return new DefaultKafkaProducerFactory<>(kafkaProperties.buildProducerProperties());}public KafkaTemplate<String, String> initKafkaTemplate(KafkaProperties kafkaProperties) {return new KafkaTemplate<>(initProducerFactory(kafkaProperties));}private ConsumerFactory<? super Integer, ? super String> initConsumerFactory(KafkaProperties kafkaProperties) {return new DefaultKafkaConsumerFactory<>(kafkaProperties.buildConsumerProperties());}public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>>initKafkaListenerContainerFactory(KafkaProperties kafkaProperties) {ConcurrentKafkaListenerContainerFactory<Integer, String> factory =new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(initConsumerFactory(kafkaProperties));return factory;}
}
1、通过Map接收多数据源
定义一个配置接收器,仿造zuul的模式
@ConfigurationProperties(prefix = "spring.kafka")
public class KafkaMultiProperties {private Map<String, KafkaProperties> routes;public Map<String, KafkaProperties> getRoutes() {return routes;}public void setRoutes(Map<String, KafkaProperties> routes) {this.routes = routes;}
}每一个route其实就说一套kafka,再写一个Configuration,注入配置文件
@Configuration
@EnableConfigurationProperties(KafkaMultiProperties.class)
public class KafkaConfiguration {}这样就可以注入配置了,从此可以根据配置的不同初始化不同的kafka集群逻辑。 这样就可以把自定义的Properties注入Springboot的placeholder中。
2、通过自定义扫描支持消费者
如果消费者或者发送者逻辑需要写在当前kafka网关应用,那么只能通过自定义扫描方式支持配置不同,所有配置的生成者和消费者必须代码实现逻辑,通过配置加载方式,自定义扫描注入bean即可。以消费者为例,生产者不涉及注解发送方式相对简单。
public class KafkaConfigInit {private KafkaMultiProperties kafkaMultiProperties;private ConfigurableApplicationContext applicationContext;public KafkaConfigInit(KafkaMultiProperties kafkaMultiProperties,ConfigurableApplicationContext applicationContext) {this.kafkaMultiProperties = kafkaMultiProperties;this.applicationContext = applicationContext;}@PostConstructpublic void initConfig() {if (kafkaMultiProperties == null || kafkaMultiProperties.getRoutes() == null) return;kafkaMultiProperties.getRoutes().forEach((k, v) -> {//register producer by configConfigurableListableBeanFactory beanFactory = applicationContext.getBeanFactory();beanFactory.registerSingleton(k + "_producer", KafkaConfigUtil.initKafkaTemplate(v));//register consumer container factoryKafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory = KafkaConfigUtil.initKafkaListenerContainerFactory(v);beanFactory.registerSingleton(k + "_consumerFactory", kafkaListenerContainerFactory);});}
}写了一个初始化的bean,用于通过配置加载bean。但是有2个问题:
- 消费者是注解方式扫描,bean需要根据配置加载,不能写在代码里面
- 这里仅仅是注册bean,并不会被beanpostprocessor处理
关于第1点
因为需要按照配置加载,不能代码写bean的加载逻辑,只能自己扫描按照配置加载,那么需要自定义扫描注解和扫描包名(减少扫描范围,提高效率)
关于第2点
需要手动执行beanpostprocessor的逻辑即可
show me the code
完善刚刚写的部分代码:
写一个注解
@Target({ ElementType.TYPE, ElementType.ANNOTATION_TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface KafkaConfigConsumer {String beanId() default "";
}通过beanId区分,配置文件的key+"_consumer"可以作为唯一标识,定义一种标准
可以使用Spring的
PathMatchingResourcePatternResolver
自己解析resources信息,来拿到写的自定义注解的类,然后生成对象,注入Spring
public class KafkaConfigInit {private KafkaMultiProperties kafkaMultiProperties;private ConfigurableApplicationContext applicationContext;private KafkaListenerAnnotationBeanPostProcessor<?,?> kafkaListenerAnnotationBeanPostProcessor;private static final Map<String, Object> consumerMap = new ConcurrentHashMap<>();public KafkaConfigInit(KafkaMultiProperties kafkaMultiProperties, ConfigurableApplicationContext applicationContext, KafkaListenerAnnotationBeanPostProcessor<?, ?> kafkaListenerAnnotationBeanPostProcessor) {this.kafkaMultiProperties = kafkaMultiProperties;this.applicationContext = applicationContext;this.kafkaListenerAnnotationBeanPostProcessor = kafkaListenerAnnotationBeanPostProcessor;}@PostConstructpublic void initConfig() throws IOException {scanConsumer();if (kafkaMultiProperties == null || kafkaMultiProperties.getRoutes() == null) return;kafkaMultiProperties.getRoutes().forEach((k, v) -> {//register producer by configConfigurableListableBeanFactory beanFactory = applicationContext.getBeanFactory();beanFactory.registerSingleton(k + "_producer", KafkaConfigUtil.initKafkaTemplate(v));//register consumer container factoryKafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory = KafkaConfigUtil.initKafkaListenerContainerFactory(v);beanFactory.registerSingleton(k + "_containerFactory", kafkaListenerContainerFactory);beanFactory.registerSingleton(k+"_consumer", consumerMap.get(k+"_consumer"));kafkaListenerAnnotationBeanPostProcessor.postProcessAfterInitialization(consumerMap.get(k+"_consumer"), k+"_consumer");});}private void scanConsumer() throws IOException {SimpleMetadataReaderFactory register = new SimpleMetadataReaderFactory();PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();Resource[] resources = resolver.getResources(ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + "com/feng/kafka/demo/init/*");Arrays.stream(resources).forEach((resource)->{try {MetadataReader metadataReader = register.getMetadataReader(resource);if (metadataReader.getAnnotationMetadata().hasAnnotatedMethods("org.springframework.kafka.annotation.KafkaListener")){String className = metadataReader.getClassMetadata().getClassName();Class<?> clazz = Class.forName(className);KafkaConfigConsumer kafkaConfigConsumer = clazz.getDeclaredAnnotation(KafkaConfigConsumer.class);Object obj = clazz.newInstance();consumerMap.put(kafkaConfigConsumer.beanId(), obj);}} catch (IOException | ClassNotFoundException | InstantiationException | IllegalAccessException e) {throw new RuntimeException(e);}});}}同时,需要手动执行
kafkaListenerAnnotationBeanPostProcessor
的逻辑,上面有源码分析,而且因为要支持多数据源,所以需要修改消费者的注解参数
//@KafkaListener(topics = "${test.topic}")
//@Component
@KafkaConfigConsumer(beanId = "xxx_consumer")
public class KafkaConsumer {private static final Logger LOGGER = LoggerFactory.getLogger(KafkaConsumer.class);private String payload;// @KafkaHandler@KafkaListener(topics = "${test.topic}", beanRef = "xxx_listener", containerFactory = "xxx_containerFactory")public void receive(ConsumerRecord<?, ?> consumerRecord) {LOGGER.info("----------------received payload='{}'", consumerRecord.toString());payload = consumerRecord.toString();}// other getterspublic String getPayload() {return payload;}public void setPayload(String payload) {this.payload = payload;}
}增加beanRef属性外加我们自己写的注解,然后通过@Configuration注入
@Configuration
@EnableConfigurationProperties(KafkaMultiProperties.class)
public class KafkaConfiguration {@Beanpublic KafkaConfigInit initKafka(KafkaMultiProperties kafkaMultiProperties,ConfigurableApplicationContext applicationContext,KafkaListenerAnnotationBeanPostProcessor<?, ?> kafkaListenerAnnotationBeanPostProcessor){return new KafkaConfigInit(kafkaMultiProperties, applicationContext, kafkaListenerAnnotationBeanPostProcessor);}
}然后修改配置文件和单元测试类
spring:kafka:routes:xxx:producer:batchSize: 1consumer:auto-offset-reset: earliestgroup-id: xxx然后修改单元测试代码
@SpringBootTest
@EmbeddedKafka(partitions = 1, brokerProperties = { "listeners=PLAINTEXT://localhost:9092", "port=9092" })
class DemoMainTest {@Lazy@Autowiredprivate KafkaConsumer consumer;@Autowiredprivate ApplicationContext applicationContext;@Value("${test.topic}")private String topic;@Testvoid embedKafka() throws InterruptedException {String data = "Sending with our own simple KafkaProducer";applicationContext.getBean("xxx_producer", KafkaTemplate.class).send(topic, data);Thread.sleep(3000);assertThat(consumer.getPayload(), containsString(data));Thread.sleep(10000);}
}执行单元测试成功

数据正确发送消费,断言正常
3、通过字节码生成支持消费者
上面的方式觉得还是不方便,一般而言处理消息和消费消息是异步的,即使是同步也不会在消费线程直接处理,一般是发送到其他地方接口处理,所以为啥还要写消费者代码呢,默认一个不就好了,但是注解参数确是常量,那么字节码生成一个唯一的类即可。
如果生成者和消费者处理逻辑不用网关应用处理,那么仅仅是无脑转发,类似zuul,可以通过字节码生成方式实现统一逻辑,主要是消费者,毕竟有注解,生产者不存在注解可以直接new出来注入bean。
以javassist为例,简单些,当然asm也可以
show me the code
其实就说把扫描的消费者类,变成固定某个类消费
//@KafkaListener(topics = "${test.topic}")
//@Component
//@KafkaConfigConsumer(beanId = "xxx_consumer")
public class KafkaConsumer {private static final Logger LOGGER = LoggerFactory.getLogger(KafkaConsumer.class);private String payload;// @KafkaHandler
// @KafkaListener(topics = "${test.topic}", beanRef = "xxx_listener", containerFactory = "xxx_containerFactory")public void receive(ConsumerRecord<?, ?> consumerRecord) {LOGGER.info("----------------received payload='{}'", consumerRecord.toString());payload = consumerRecord.toString();}去掉注解,因为注解需要我们动态加上去,下一步修改bean创建流程
@PostConstructpublic void initConfig() throws IOException {
// scanConsumer();if (kafkaMultiProperties == null || kafkaMultiProperties.getRoutes() == null) return;kafkaMultiProperties.getRoutes().forEach((k, v) -> {//register producer by configConfigurableListableBeanFactory beanFactory = applicationContext.getBeanFactory();beanFactory.registerSingleton(k + "_producer", KafkaConfigUtil.initKafkaTemplate(v));//register consumer container factoryKafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory = KafkaConfigUtil.initKafkaListenerContainerFactory(v);beanFactory.registerSingleton(k + "_containerFactory", kafkaListenerContainerFactory);// beanFactory.registerSingleton(k + "_consumer", consumerMap.get(k + "_consumer"));Object obj = initConsumerBean(k);beanFactory.registerSingleton(k + "_consumer", obj);kafkaListenerAnnotationBeanPostProcessor.postProcessAfterInitialization(obj, k + "_consumer");});}private Object initConsumerBean(String key) {try {ClassPool pool = ClassPool.getDefault();CtClass ct = pool.getCtClass("com.feng.kafka.demo.init.KafkaConsumer");//修改类名,避免重复ct.setName("com.feng.kafka.demo.init.KafkaConsumer"+key);//获取类中的方法CtMethod ctMethod = ct.getDeclaredMethod("receive");MethodInfo methodInfo = ctMethod.getMethodInfo();ConstPool cp = methodInfo.getConstPool();//获取注解属性AnnotationsAttribute attribute = new AnnotationsAttribute(cp, AnnotationsAttribute.visibleTag);Annotation annotation = new Annotation("org.springframework.kafka.annotation.KafkaListener", cp);ArrayMemberValue arrayMemberValue = new ArrayMemberValue(cp);arrayMemberValue.setValue(new MemberValue[]{new StringMemberValue("embedded-test-topic", cp)});annotation.addMemberValue("topics", arrayMemberValue);annotation.addMemberValue("beanRef", new StringMemberValue(key+"_listener", cp));annotation.addMemberValue("containerFactory", new StringMemberValue(key+"_containerFactory", cp));attribute.addAnnotation(annotation);methodInfo.addAttribute(attribute);byte[] bytes = ct.toBytecode();Class<?> clazz = ReflectUtils.defineClass("com.feng.kafka.demo.init.KafkaConsumer" + key, bytes, Thread.currentThread().getContextClassLoader());return clazz.newInstance();} catch (Exception e) {throw new RuntimeException(e);}}通过字节码生成和动态加载class方式,生成唯一的对象,实现通过配置方式支持多数据源,不需要写一句消费代码。
单元测试

去掉了断言,因为类是动态变化的了。
总结
实际上spring-kafka已经非常完善了,spring-kafka插件的支持也很完善,不需要关注kafka的消费过程,只需要配置即可,但是也为灵活性埋下了隐患,当然一般而言我们基本上用不到多kafka的情况,也不会做一个kafka网关应用,不过当业务需要的时候,可以设计一套kafka网关应用,分发kafka的消息,起到一个流量网关的能力,解耦业务的应用,实现架构的松耦合。
相关文章:
springboot kafka多数据源,通过配置动态加载发送者和消费者
前言 最近做项目,需要支持kafka多数据源,实际上我们也可以通过代码固定写死多套kafka集群逻辑,但是如果需要不修改代码扩展呢,因为kafka本身不处理额外逻辑,只是起到削峰,和数据的传递,那么就需…...

【华为】基于华为交换机的VLAN配置与不同VLAN间通信实现
划分VLAN(虚拟局域网)主要作用: 一、提高网络安全性 广播域隔离访问控制增强 二、优化网络性能 减少网络拥塞提高网络可管理性 sysytem-view #进入系统视图配置参数 vlan batch 10 20 #批量创建vlan LSW3: int g0/0/1 port…...

力扣题11~20
题11(中等): 思路: 这种题目第一眼就是双循环,但是肯定不行滴,o(n^2)这种肯定超时,很难接受。 所以要另辟蹊径,我们先用俩指针(标志位)在最左端和最右端&am…...
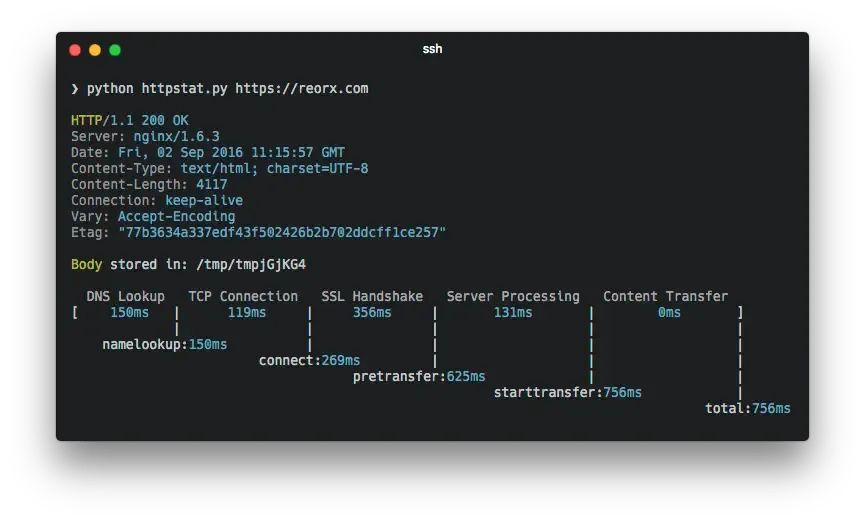
更美观的HTTP性能监测工具:httpstat
reorx/httpstat是一个旨在提供更美观和详细HTTP请求统计信息的cURL命令行工具,它能够帮助开发者和运维人员深入理解HTTP请求的性能和状态。 1. 基本概述 项目地址:https://github.com/reorx/httpstat语言:该工具主要是以Python编写ÿ…...

在2024 VDC,听一曲“蓝心智能”的江河协奏
作为科技从业者,我们每年参加的终端产品发布会和开发者大会,少则几十场。说每一场都别有新意,那自然是不可能的,但每次去vivo的活动现场,总能给我耳目一新的感觉。 雨果说过,音乐可以表达难以用语言描述&am…...
算法来优化掩模设计)
Python编写的数字光刻仿真程序,使用了Hopkins光刻模型和粒子群优化(PSO)算法来优化掩模设计
Python编写的数字光刻仿真程序,使用了Hopkins光刻模型和粒子群优化(PSO)算法来优化掩模设计,以减少光刻过程中的图形偏差。 4. 定义了几个函数来模拟光波通过光刻系统的变化: - `transfer_function`:计算光波的相位变化。 - `light_source_function`:描述光源在各…...
)
【AD那些事 11】绘制PCB板时“隔离” 的那些事(笔记摘抄)
在设计新板子时发现需要考虑隔离!!!!!!!!!!!于是我在网上找了很多资料,摘抄了一些,整理了一下,作为笔记&#…...

sublime配置(竞赛向)
我也想要有jiangly一样的sublime 先决条件 首先,到官网上下载最新的sublime4,然后在mingw官网上下载最新的mingw64 mingw64官网:左边菜单栏点击dowloads,然后选择MinGW-W64-builds(可能会有点慢)——然后有时候会变成选LLVM-minGW,接着选择…...

双向数据库迁移工具:轻松实现 MySQL 与 SQLite 数据互导
项目概述与作用 该项目的核心是实现 MySQL 和 SQLite 两种数据库之间的数据迁移工具。它能够轻松地将 MySQL 数据库中的数据导出为 SQLite 数据库文件,反过来也可以将 SQLite 数据库中的数据上传到 MySQL 数据库中。这个双向迁移工具非常适用于: 数据库备…...

oracle查询表空间信息
方式一,通过SQLPLUS查看,适用于无PLSQL等工具 sqlplus / as sysdba set line 200 set lines 200 col tablespace_name for a20 col SUM_SPACE(M) for a15 col USED_SPACE(M) for a15 col USED_RATE(%) for a15 col FREE_SPACE(M) for a15 SELEC…...

使用Python编写你的第一个算法交易程序
背景 Background 最近想学习一下量化金融,总算在盈透投资者教育(IBKRCampus)板块找到一篇比较好的算法交易入门教程。我在记录实践过程后,翻译成中文写成此csdn博客,分享给大家。 如果你的英语好可以直接看原文…...

点进HTML初步了解
写在前边 ##关于插件 ①简体中文 ②open-in-browser:自动在浏览器生成html页面; ③Auto Rename Tag:自动匹配标签; ④Live server:实现页面的实时刷新; ##关于快捷键: Ctrl / 用来注释…...

幸运的沈抖,进击的百度智能云
文|白 鸽 编|王一粟 AI对百度智能云的意义,可能远大于任何一家云计算厂商。 2022年5月,分管百度移动生态事业群组(MEG)的集团执行副总裁沈抖,转而担任百度智能云事业群组(ACG&…...

android广播实现PIN码设置
摘要:本文通过广播的方式调用系统设置PIN码的流程实现类似锁机的功能,可供开发人员在联网状态下后台推送消息进行锁机/解锁。有需要的同学可以参考PIN码的流程改为密码等其他形式。 1 定义一个广播接收器 广播action:android.intent.action…...

Mac 需要杀毒软件?
大部分 mac用户普遍认为 Apple mac 不受病毒和恶意软件的影响。这导致许多 Mac 用户误以为无需为 Mac 安装防病毒软件,但事实并非如此。 在这篇文章中,将深入探讨 Mac 安全性的细节,探索针对 Apple 设备的恶意软件类型,并为您…...

Java | Leetcode Java题解之第472题连接词
题目: 题解: class Solution {Trie trie new Trie();public List<String> findAllConcatenatedWordsInADict(String[] words) {List<String> ans new ArrayList<String>();Arrays.sort(words, (a, b) -> a.length() - b.length(…...

CUDA Graphs学习与实验
CUDA Graphs学习与实验 一.参考链接二.测试方案三.测试代码 CUDA图(CUDA Graphs)为CUDA引入了一种全新的工作提交模型。它允许将一系列操作(如内核启动)以图的形式表示,并通过依赖关系将这些操作连接起来。这种图的定义…...

【自注意力与Transformer架构在自然语言处理中的演变与应用】
背景介绍 在自然语言处理(NLP)领域,序列到序列(seq2seq)模型和Transformer架构的出现,极大地推动了机器翻译、文本生成和其他语言任务的进展。传统的seq2seq模型通常依赖于循环神经网络(RNN&…...

LabVIEW交直流接触器动态检测系统
LabVIEW软件与霍尔传感器技术结合的交直流接触器动态检测系统通过实时数据采集和处理技术,有效地测量并分析交直流接触器在吸合及吸持阶段的电流和电压变化,以及相应的功率消耗,从而优化电力和配电系统的性能和可靠性。 项目背景 交直流接触…...

Unity3D中基于四叉树的范围检测算法详解
在游戏开发中,碰撞检测和范围检测是常见的需求,尤其是在处理大量物体时,传统的暴力检测法(即每个物体与其他所有物体进行碰撞检测)会消耗大量的计算资源,导致性能下降。为了优化这一过程,四叉树…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...

Windows鼠标指针主题定制:从.cur/.ani文件到个性化交互体验
1. 项目概述:一个为Windows终端注入灵魂的鼠标指针主题如果你和我一样,每天有超过8小时的时间是与Windows操作系统相伴的,那么你对那个千篇一律的白色箭头鼠标指针,恐怕早已感到审美疲劳。它就像一个沉默的、功能性的背景板&#…...

用C++和RealSense D435i搞个3D手势识别?从像素坐标到相机坐标的保姆级避坑指南
3D手势识别实战:用RealSense D435i实现像素到相机坐标的高精度转换 当你的手指在空气中划出一道弧线,计算机能否精准捕捉这个三维动作?这正是3D手势识别技术试图解决的问题。作为人机交互领域的前沿方向,3D手势识别正在VR游戏、医…...

ViewTurbo:基于响应式依赖追踪的前端渲染优化方案
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 ViewTurbo。这名字听起来就带点“涡轮增压”的劲儿,事实上,它也确实是一个旨在为视图渲染“加速”的工具。简单来说,ViewTurbo 的核心目标,是解决在复杂前端…...