【大数据】数据采集工具sqoop介绍
文章目录
- 什么是sqoop?
- 一、Sqoop的起源与发展
- 二、Sqoop的主要功能
- 三、Sqoop的工作原理
- 四、Sqoop的使用场景
- 五、Sqoop的优势
- 六、Sqoop的安装与配置
- sqoop命令行
- 一、Sqoop简介与架构
- 二、Sqoop特点
- 三、Sqoop常用命令及参数
- 四、使用示例
- 五、注意事项
什么是sqoop?
Sqoop是一款开源的数据采集工具,专门设计用于在Hadoop生态系统和关系型数据库之间高效传输批量数据。以下是对Sqoop的详细介绍:
一、Sqoop的起源与发展
- Sqoop项目始于2009年,最初是作为Hadoop的一个第三方模块存在。
- 为了便于用户快速部署和开发人员快速迭代开发,Sqoop后来独立成为一个Apache项目。
二、Sqoop的主要功能
- 数据迁移:Sqoop可以将关系型数据库(如MySQL、Oracle、PostgreSQL等)中的数据迁移到Hadoop的HDFS、Hive、HBase等数据存储系统中,也可以将HDFS中的数据导出到关系型数据库中。
- 数据采集:Sqoop支持从关系型数据库中采集数据,并导入到Hadoop生态系统中进行进一步的分析和处理。
- 结果导出:经过Hadoop平台对数据进行分析统计后,Sqoop可以将结果数据导出到关系型数据库中进行可视化展示。
三、Sqoop的工作原理
- Sqoop底层基于MapReduce程序模板实现。MapReduce提供了DBInputFormat和DBOutputFormat类,用于实现对数据库数据的导入和导出。
- Sqoop通过解析传递的参数,将这些参数传递给底层的MapReduce模板来运行。所有Sqoop的MapReduce程序只有Map过程,没有Reduce过程,因为数据迁移过程通常不需要聚合操作。
四、Sqoop的使用场景
- 数据仓库:Sqoop适用于数据仓库等批处理场景,特别是与关系型数据库的集成。
- 数据迁移:公司传统的数据都存在关系型数据库中,随着公司业务的发展,希望将历史数据迁移到大数据平台做存档,此时Sqoop是一个很好的选择。
- 数据分析:需要对公司网站的业务数据进行分析统计、构建用户画像等大数据应用时,可以使用Sqoop将业务数据同步到大数据平台中Hive,然后利用分布式计算来进行分析统计。
五、Sqoop的优势
- 支持多种数据库:Sqoop支持与各种关系型数据库的集成,包括MySQL、Oracle、SQL Server等。
- 增量加载:Sqoop支持增量加载策略,可以仅导入发生变化的数据,而不必每次导入整个数据集,这大大提高了数据加载的效率。
- 数据格式转换:Sqoop可以将数据从数据库中提取并将其转换为Hadoop支持的数据格式,如Avro、Parquet等。
- 易于使用:Sqoop提供了易于使用的命令行界面,方便用户进行操作和配置。
六、Sqoop的安装与配置
- 安装Sqoop前需要确保已经安装并配置好Hadoop和Java环境。
- 下载Sqoop的压缩包并解压到指定目录。
- 修改Sqoop的配置文件,包括sqoop-env.sh和sqoop-site.xml等。
- 将Hive的配置文件hive-site.xml放在Sqoop的conf目录中,以便Sqoop可以找到Hive的元数据位置。
- 将关系型数据库的驱动包放在Sqoop的lib目录下。
sqoop命令行
一、Sqoop简介与架构
-
简介:Sqoop(SQL to Hadoop)允许用户将结构化数据从关系型数据库导入到HDFS(Hadoop分布式文件系统)或Hive表中,或者将数据从HDFS导出到关系型数据库中。
-
架构:
- Sqoop Client:提供命令行工具和API,用于与Sqoop Server进行通信,并提交数据导入和导出的任务。
- Sqoop Server:负责接收来自客户端的请求,并协调和管理数据导入和导出的任务。Sqoop Server可以在独立模式下运行,也可以与Hadoop集群中的其他组件(如HDFS、YARN)集成。
- Connector:用于与不同类型的关系型数据库进行交互。Sqoop提供了一些内置的连接器,如MySQL、Oracle、SQL Server等,同时还支持自定义连接器。
- Metastore:用于保存与数据导入和导出相关的元数据信息,如表结构、字段映射、导入导出配置等。Metastore可以使用关系型数据库(如MySQL、PostgreSQL)或HDFS来存储元数据。

二、Sqoop特点
- 简化数据传输过程。
- 高效处理大数据量,支持并行导入和导出操作。
- 灵活的数据格式支持,包括文本文件、Avro、Parquet等。
- 丰富的连接器支持,可以直接与多种关系型数据库进行交互。
- 支持数据压缩和加密功能,保护数据的安全性。
- 与Hadoop生态系统紧密集成,可以充分利用Hadoop的分布式计算和存储能力。
三、Sqoop常用命令及参数
以下是Sqoop的一些常用命令及其参数:
-
import:将关系型数据库中的数据导入到Hadoop集群中。
- 常用参数:
--connect:指定数据库连接URL。--username:指定数据库用户名。--password:指定数据库密码。--table:指定要导入的数据库表名。--columns:指定要导入的列。--target-dir:指定导入数据的目标目录。--where:指定导入数据的条件。--split-by:指定用于拆分数据的列。--incremental:指定增量导入的模式(如append)。--check-column:指定用于检查增量数据的列。--last-value:指定上次导入的值,用于增量导入。
- 常用参数:
-
export:将Hadoop集群中的数据导出到关系型数据库中。
- 常用参数:
--connect:指定数据库连接URL。--username:指定数据库用户名。--password:指定数据库密码。--table:指定要导出的数据库表名。--export-dir:指定导出数据的源目录。--input-fields-terminated-by:指定输入字段的分隔符。--input-lines-terminated-by:指定输入行的分隔符。--columns:指定要导出的列。
- 常用参数:
-
eval:执行SQL查询语句并返回结果。
- 常用参数:
--connect:指定数据库连接URL。--username:指定数据库用户名。--password:指定数据库密码。--query:指定要执行的SQL查询语句。
- 常用参数:
-
list-databases:列出数据库中的所有数据库名称。
-
list-tables:列出指定数据库中的所有表名。
-
create-hive-table:生成与关系数据库表结构对应的Hive表结构。
-
codegen:将关系型数据库中的表映射为一个Java类。
-
import-all-tables:将关系型数据库中的所有表导入到HDFS中。
-
job:用于创建、列出、执行和删除Sqoop作业。
- 常用参数:
--create:创建一个新的Sqoop作业。--list:列出所有Sqoop作业。--exec:执行指定的Sqoop作业。--delete:删除指定的Sqoop作业。
- 常用参数:
四、使用示例
以下是一些Sqoop命令的使用示例:
- 全量导入数据到Hive中:
sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--hive-import \
--hive-table hive_staff
- 增量导入数据到HDFS中:
sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--target-dir /user/hive/warehouse/staff_hdfs \
--check-column id \
--incremental append \
--last-value 3
- 导出数据到关系型数据库中:
sqoop export \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--export-dir /user/company \
--input-fields-terminated-by "\t"
- 执行SQL查询并返回结果:
sqoop eval \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--query "SELECT * FROM staff"
- 创建Sqoop作业:
sqoop job \
--create myjob \
--import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--hive-import \
--hive-table hive_staff
- 执行Sqoop作业:
sqoop job \
--exec myjob
五、注意事项
- 在使用Sqoop时,需要确保Hadoop和关系型数据库已经正确配置并运行。
- 根据实际需求选择合适的数据格式和连接器。
- 在执行增量导入时,需要指定正确的检查列和上次导入的值。
- Sqoop作业可以方便地管理和执行数据导入和导出任务,建议在实际使用中充分利用。
以上是Sqoop命令行使用的详解,包括Sqoop的简介、架构、特点、常用命令及参数、使用示例和注意事项。通过掌握这些知识,可以更好地利用Sqoop在Hadoop和关系型数据库之间进行数据传输和处理。
相关文章:
【大数据】数据采集工具sqoop介绍
文章目录 什么是sqoop?一、Sqoop的起源与发展二、Sqoop的主要功能三、Sqoop的工作原理四、Sqoop的使用场景五、Sqoop的优势六、Sqoop的安装与配置 sqoop命令行一、Sqoop简介与架构二、Sqoop特点三、Sqoop常用命令及参数四、使用示例五、注意事项 什么是sqoop? Sqoop是一款开…...
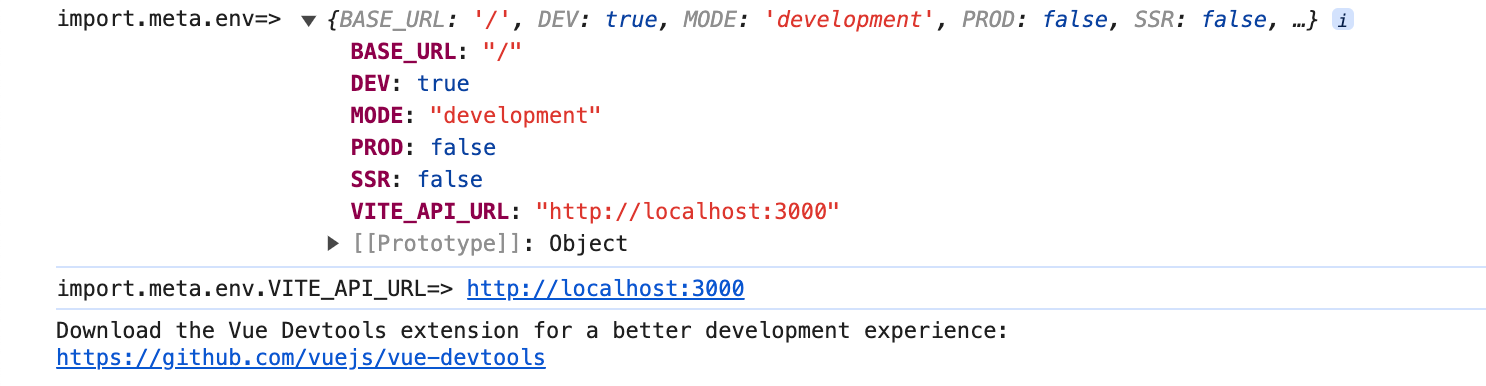
vite学习教程02、vite+vue2配置环境变量
文章目录 前言1、安装依赖2、配置环境变量3、应用环境变量4、运行和构建项目资料获取 前言 博主介绍:✌目前全网粉丝3W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。 涵盖技术内容࿱…...

k8s 的网络通信
目录 1 k8s通信整体架构 2 flannel 网络插件 2.1 flannel 插件组成 2.2 flannel 插件的通信过程 2.3 flannel 支持的后端模式 3 calico 网络插件 3.1 calico 简介 3.2 calico 网络架构 3.3 部署 calico 1 k8s通信整体架构 k8s通过CNI接口接入其他插件来实现网络通讯。目前比较…...

【编程基础知识】掌握Spring MVC:从入门到精通
摘要: 本文将深入探讨Spring MVC框架的核心概念、组件和工作流程。读者将学习如何将Spring MVC应用于现代Web应用程序开发中,并通过实际代码示例和流程图,理解其强大的功能和灵活性。文章最后,我们将通过一个Excel表格总结全文内容…...
多线程下,@Transactional失效解决
一、问题复现 批量插入时,使用多线程对插入数据实现分批插入,在service层使用Transactional注解,对应方法中线程池中开辟的子线程抛出异常时,没有回滚事务。 二、原因分析 事务管理范围不正确:Transactional注解仅对…...

PyCharm 项目解释器切换指南:如何在项目中更换 Python Interpreter
PyCharm 项目解释器切换指南:如何在项目中更换 Python Interpreter 文章目录 PyCharm 项目解释器切换指南:如何在项目中更换 Python Interpreter一 Settings 设置二 Project 选项三 Conda Environment四 更换 Environment 本文详细介绍了在 macOS 系统中…...

STM32F407寄存器操作(DMA+SPI)
1.前言 前面看B站中有些小伙伴吐槽F4的SPIDMA没有硬件可控的CS引脚,那么今天我就来攻破这个问题 我这边暂时没有SPI的从机芯片,并且接收的过程与发送的过程类似,所以这里我就以发送的过程为例了。 2.理论 手册上给出了如下的描述 我们关注…...

Oracle 的 OCP 与 MySQL 的 OCP 的区别
事务开始与提交(以 Java 代码中的事务操作为例) Oracle(在 Java 中使用 JDBC 进行事务操作) import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement;public cla…...

数据治理、数据清洗定义、区别以及数据清洗常用方法
一、数据治理定义 数据治理是一种组织数据管理的方法,涉及数据的收集、存储、处理、分析和共享等方面,旨在最大程度地利用数据资产并降低数据相关的风险。 数据治理确保数据的质量、安全性、合规性和可用性,以支持组织的决策和运营活动。…...

web基础-攻防世界
get-post 一、WP (题目本质:get与post传参方法) 用 GET 给后端传参的方法是:在?后跟变量名字,不同的变量之间用&隔开。例如,在 url 后添加/?a1 即可发送 get 请求。 利用 hackbar 进行…...

Java基础-String Class(字符串类)
String Java String 类概览 String 类是 Java 中最常用的类之一,用于处理字符串。以下是 String 类的主要特性和操作: 特性/操作描述不可变性String 对象一旦创建就不能被修改创建方式使用双引号 “” 或 String 构造函数字符串池Java 维护字符串常量池…...

《Linux服务与安全管理》| 服务进程与网络配置
《Linux服务与安全管理》| 服务进程与网络配置 目录 《Linux服务与安全管理》| 服务进程与网络配置 (1) 写出查看NetworkManager服务状态的命令。 (2) 写出查看NetworkManager服务自启动状态的命令。 (3࿰…...

No.15 笔记 | CSRF 跨站请求伪造
目录 一、基础知识 (一)cookie 和 session、同源策略 (二)CSRF 原理 二、CSRF 类型 (一)GET 类型 (二)POST 类型 三、CSRF 实例讲解 (一)真实案例 &am…...

解决linux中pip速度过慢问题
在 Linux 系统下,如果你发现使用 pip 下载 Python 库时速度非常慢,可以考虑以下几种方法来加速下载: 使用 pip 的 -i 选项: 如果你只想临时使用其他镜像,可以在安装时加上 -i 选项: pip install package_n…...

FlinkSQL中 的 双流JOIN
在 Flink SQL 中,流与流的 JOIN 是一种复杂的操作,因为它涉及到实时数据的无界处理。理解 Flink SQL 流与流 JOIN 的底层原理和实现需要从多个角度来分析,包括 状态管理、事件时间处理、窗口机制 以及 内部数据流处理模型 等。下面将从这些角…...

Mysql(五) --- 数据库设计
文章目录 前言1.范式1.1.第一范式1.1.1 定义1.1.2.例子 1.2.第二范式1.2.1 定义1.2.2 例子1.2.3.不满足第二范式可能会出现的问题 1.3.第三范式1.3.1 定义2.3.2 示例 2. 设计过程3. 实体-关系图3.1 E-R图的基本组成3.2 关系的类型3.2.1 一对一关系(1:1)3.2.2 ⼀对多关系(1:N)3.…...

po框架的了解和应用
https://www.cnblogs.com/xiaolehong/p/18458470 笔记 任务:1、通过po框架输入测试报告 2、编写自动化测试框架 3、总结测试讲解稿 自动化测试框架概念: 自动化测试框架是一个集成体系,这个体系中包含测试功能的函数、测试数据源、测试对以及重要的模块。 作用:用于解决或…...

Linux云计算 |【第四阶段】RDBMS2-DAY5
主要内容: PXC概述、部署PXC(自动故障恢复测试)、存储引擎、读锁/写锁、表锁/行锁、常用的存储引擎介绍 一、PXC概述 PXC(Percona XtraDB Cluster,简称PXC集群),是基于Galera的MySQL高可用集群…...

从0开始深度学习(9)——softmax回归的逐步实现
文章使用Fashion-MNIST数据集,做一次分类识别任务 Fashion-MNIST中包含的10个类别,分别为: t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙&…...

Cannot inspect org.apache.hadoop.hive.serde2.io.HiveDecimalWritable 问题分析处理
报错; org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.UnsupportedOperationException: Cannot inspect org.apache.hadoop.hive.serde2.io.HiveDecimalWritable 该问题常见于parquet格式hive表查询时,一般原因为hive表对应数据文件元数据对应格式与…...

Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览
Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPh…...

NVDC充电架构深度解析:智能电源管理如何提升笔记本性能与电池寿命
1. 项目概述:NVDC充电器,一个被低估的“能量管家”如果你是一位经常需要带着笔记本电脑移动办公的资深用户,或者是一位对设备续航和充电效率有极致追求的硬件爱好者,那么“NVDC”这个词,很可能已经或即将进入你的视野。…...

对比直接购买与通过Taotoken聚合使用大模型API的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买与通过Taotoken聚合使用大模型API的体验差异 在开发和集成大模型能力的过程中,开发者或团队通常面临两种主…...

OpenStack 12大组件说明-blog
OpenStack 12大组件说明 OpenStack 是开源Iaas云计算平台,由12大核心组件构成,各组件独立部署、协同工作,覆盖计算、存储、网络、认证等全场景,以下是各组件核心说明(精简版)。 1. Nova(计算服务…...

ncmdumpGUI:专业音频解密工具实现网易云音乐跨平台播放自由
ncmdumpGUI:专业音频解密工具实现网易云音乐跨平台播放自由 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,平台间的格…...

从IGS文件命名变迁,看GNSS数据处理流程的演进与自动化机遇
从IGS文件命名变迁透视GNSS数据处理的智能化演进 在卫星导航定位领域,IGS(国际GNSS服务组织)产品文件命名规则的每一次调整都像一面镜子,映射出整个行业的技术演进方向。2022年底从V1.0到V2.0命名规范的升级,绝非简单的…...

STM32F103C8T6驱动BMP280气压模块:从I2C地址纠错到数据转换的完整避坑指南
STM32F103C8T6驱动BMP280气压模块:从I2C地址纠错到数据转换的完整避坑指南 在嵌入式开发中,气压传感器BMP280因其高精度和低成本成为许多项目的首选。然而,当这个看似简单的模块遇上STM32F103C8T6这颗经典的MCU时,不少开发者却踩进…...
)
JDK 17 + Hadoop 3.3.5 + Spark 3.3.2 集群搭建保姆级避坑指南(CentOS 8.5 + VMware)
JDK 17 Hadoop 3.3.5 Spark 3.3.2 集群搭建实战避坑手册 当你第一次尝试在本地环境搭建大数据集群时,是否曾被各种兼容性问题、配置错误和莫名其妙的报错折磨得焦头烂额?本文将带你完整走一遍从零开始搭建基于JDK 17、Hadoop 3.3.5和Spark 3.3.2的集群…...

食品制造 | 品控AI自动化方案主流厂商横评:2026企业级智能体选型与落地实测
2026年,全球食品制造业正处于从“数字化转型”向“智能化深耕”跨越的关键节点。随着国家市场监管总局“互联网AI监管”战略的全面深化,食品安全已不再仅仅依赖于周期性的线下抽检,而是转向了基于AI技术的全时段、全链路实时监控。 从校园食堂…...

银河麒麟系统下Qt5.9.9编译fcitx-qt5的版本适配与源码修改实战
1. 银河麒麟系统下Qt中文输入问题的根源 在银河麒麟系统上开发Qt应用程序时,中文输入法无法正常切换是个常见痛点。这个问题本质上源于Qt输入法插件与Qt版本之间的兼容性断裂。我曾在多个项目中遇到这种情况:明明系统自带输入法可以正常工作,…...