java 洛谷题单【数据结构1-2】二叉树
P4715 【深基16.例1】淘汰赛
解题思路
- 半区分配:将前半部分国家分配到左半区,后半部分国家分配到右半区,分别找到两个半区的最强国家。
- 决赛和亚军确定:最后比较两个半区最强国家的能力值,失败者即为亚军,输出其编号。
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner input = new Scanner(System.in);// 读入nint n = input.nextInt();int numTeams = (int) Math.pow(2, n); // 参赛队伍的数量为 2^n// 读入每个国家的能力值int[] abilities = new int[numTeams + 1]; // 1-based indexingfor (int i = 1; i <= numTeams; i++) {abilities[i] = input.nextInt();}// 找出左半区和右半区的最强者int leftBest = 1; // 初始假设左半区第一个国家是最强的int rightBest = numTeams / 2 + 1; // 初始假设右半区第一个国家是最强的// 找左半区最强的国家for (int i = 2; i <= numTeams / 2; i++) {if (abilities[i] > abilities[leftBest]) {leftBest = i;}}// 找右半区最强的国家for (int i = numTeams / 2 + 2; i <= numTeams; i++) {if (abilities[i] > abilities[rightBest]) {rightBest = i;}}// 决赛:leftBest 和 rightBest 进行比赛,输者即为亚军if (abilities[leftBest] > abilities[rightBest]) {System.out.println(rightBest);} else {System.out.println(leftBest);}}
}
P4913 【深基16.例3】二叉树深度
1. 数据结构设计
- 使用一个数组或列表来表示树结构。每个节点的左右子节点可以用
Node类或结构体来表示,存储其左、右子节点的编号。- 数组的大小为 n+1(节点编号从 1 开始)。
2. 深度计算方法
递归方法:
- 从根节点开始,定义一个递归函数
dfs,计算当前节点的深度。- 当节点为
0时返回深度为0(表示到达叶子节点)。- 递归调用左右子节点,更新最大深度。
迭代方法:
- 使用栈来模拟递归。初始化栈,存储每个节点及其当前深度。
- 弹出栈顶元素,更新最大深度,然后将左右子节点及其深度推入栈中。
3. 输入输出处理
- 读取节点数 n,并在循环中读取每个节点的左右子节点信息。
- 调用深度计算函数,并输出计算得到的最大深度。
4. 边界情况考虑
- 处理节点数为 0 或 1 的情况。
- 确保节点的左右子节点编号有效,避免访问越界。
import java.util.Scanner;
import java.util.Stack;public class Main {static class Node {int left, right; // 左右子节点}static Node[] tree; // 存储树的结构static int n;// 迭代方式计算树的深度static int calculateDepth() {Stack<int[]> stack = new Stack<>();stack.push(new int[]{1, 1}); // {节点编号, 当前深度}int maxDepth = 0;while (!stack.isEmpty()) {int[] current = stack.pop();int id = current[0];int deep = current[1];if (id == 0) continue; // 如果是叶子节点,跳过maxDepth = Math.max(maxDepth, deep); // 更新最大深度stack.push(new int[]{tree[id].left, deep + 1}); // 左子节点stack.push(new int[]{tree[id].right, deep + 1}); // 右子节点}return maxDepth;}public static void main(String[] args) {Scanner input = new Scanner(System.in);n = input.nextInt(); // 读取节点数tree = new Node[n + 1]; // 初始化树的数组// 读取节点的左、右子节点for (int i = 1; i <= n; i++) {tree[i] = new Node(); // 初始化每个节点tree[i].left = input.nextInt();tree[i].right = input.nextInt();}int depth = calculateDepth(); // 计算深度System.out.println(depth); // 输出深度}
}P1827 [USACO3.4] 美国血统 American Heritage
解题思路
理解遍历方式:
- 前序遍历:第一个字符是根节点。
- 中序遍历:根节点将树分为左子树和右子树。
构建树的后序遍历:
- 从前序遍历中找到根节点。
- 在中序遍历中找到根节点的位置,并据此分割左右子树。
- 递归处理左子树和右子树,最后合并后序遍历结果。
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;public class Main {static String inorder, preorder;static Map<Character, Integer> inorderIndexMap = new HashMap<>();public static void main(String[] args) {Scanner input = new Scanner(System.in);inorder = input.nextLine().trim();preorder = input.nextLine().trim();// 构建中序遍历字符的索引for (int i = 0; i < inorder.length(); i++) {inorderIndexMap.put(inorder.charAt(i), i);}// 获取后序遍历String postorder = getPostOrder(0, preorder.length() - 1, 0, inorder.length() - 1);System.out.println(postorder);}private static String getPostOrder(int preStart, int preEnd, int inStart, int inEnd) {if (preStart > preEnd || inStart > inEnd) {return "";}// 前序遍历的根节点char root = preorder.charAt(preStart);// 找到根节点在中序遍历中的索引int rootIndexInInorder = inorderIndexMap.get(root);// 左子树的节点数量int leftSubtreeSize = rootIndexInInorder - inStart;// 递归处理左子树和右子树String leftPostOrder = getPostOrder(preStart + 1, preStart + leftSubtreeSize, inStart, rootIndexInInorder - 1);String rightPostOrder = getPostOrder(preStart + leftSubtreeSize + 1, preEnd, rootIndexInInorder + 1, inEnd);// 后序遍历是左子树 + 右子树 + 根节点return leftPostOrder + rightPostOrder + root;}
}P5076 【深基16.例7】普通二叉树(简化版)
解题思路
数据结构:使用二叉树
操作分析
查询数 xxx 的排名(操作1):
- 使用
TreeSet的headSet(x)方法可以获得所有小于 xxx 的元素集合。- 计算其大小并加1(因为排名从1开始)。
查询排名为 xxx 的数(操作2):
- 将
TreeSet转换为数组或列表,直接通过索引访问。- 注意索引需要减1,因为排名从1开始而数组索引从0开始。
求前驱(操作3):
- 使用
TreeSet的lower(x)方法可以直接获取小于 xxx 的最大值。- 如果不存在前驱,则返回特定的值 −2147483647-2147483647−2147483647。
求后继(操作4):
- 使用
higher(x)方法获取大于 xxx 的最小值。- 如果不存在后继,则返回特定的值 214748364721474836472147483647。
插入数 xxx(操作5):
- 直接调用
add(x)方法将 xxx 插入到集合中。根据题意保证插入前 xxx 不在集合里。
import java.util.*;public class Main {private static TreeSet<Integer> set;public static void main(String[] args) {Scanner input = new Scanner(System.in);int q = input.nextInt();set = new TreeSet<>();StringBuilder output = new StringBuilder();for (int i = 0; i < q; i++) {int op = input.nextInt();int x = input.nextInt();switch (op) {case 1: // 查询排名int rank = getRank(x);output.append(rank).append("\n");break;case 2: // 查询排名为x的数int value = getValueByRank(x);output.append(value).append("\n");break;case 3: // 求前驱int predecessor = getPredecessor(x);output.append(predecessor).append("\n");break;case 4: // 求后继int successor = getSuccessor(x);output.append(successor).append("\n");break;case 5: // 插入数xset.add(x);break;default:break;}}System.out.print(output);}private static int getRank(int x) {// 计算小于x的元素个数return set.headSet(x).size() + 1; // +1因为排名从1开始}private static int getValueByRank(int rank) {// 获取排名为rank的数return (Integer) set.toArray()[rank - 1]; // rank-1因为数组索引从0开始}private static int getPredecessor(int x) {// 获取前驱Integer pred = set.lower(x);return (pred != null) ? pred : -2147483647; // 若不存在前驱返回 -2147483647}private static int getSuccessor(int x) {// 获取后继Integer succ = set.higher(x);return (succ != null) ? succ : 2147483647; // 若不存在后继返回 2147483647}
}
P1364 医院设置
解题思路
树的表示与输入解析:通过输入的描述可以构造二叉树,每个结点包含了人口数和它的左、右子树链接。
距离和的计算:可以通过深度优先搜索(DFS)来计算每个结点作为医院时的总距离和。首先从任意一个结点开始递归计算其所有子结点与它的距离和,再使用动态规划的思想通过子问题解决整体问题。
自底向上计算距离和:通过一次DFS计算出以任意一个结点为根时的距离和,然后通过递归遍历整棵树的其他结点,通过子树距离和转移来快速更新。
import java.util.*;class TreeNode {int population; // 当前结点的人口数int left; // 左子结点的索引int right; // 右子结点的索引public TreeNode(int population, int left, int right) {this.population = population;this.left = left;this.right = right;}
}public class Main {static TreeNode[] tree; // 用数组来表示树static int[] subtreePopulation; // 记录以当前结点为根的子树总人口数static int[] subtreeDistanceSum; // 记录以当前结点为根的子树距离和static int n; // 结点数// 计算以当前结点为根的子树人口和以及距离和static void dfs1(int node) {if (node == 0) return;int left = tree[node].left;int right = tree[node].right;dfs1(left); // 递归计算左子树dfs1(right); // 递归计算右子树// 计算以当前结点为根的子树总人口和subtreePopulation[node] = tree[node].population;if (left != 0) subtreePopulation[node] += subtreePopulation[left];if (right != 0) subtreePopulation[node] += subtreePopulation[right];// 计算以当前结点为根的子树距离和if (left != 0) subtreeDistanceSum[node] += subtreeDistanceSum[left] + subtreePopulation[left];if (right != 0) subtreeDistanceSum[node] += subtreeDistanceSum[right] + subtreePopulation[right];}// 递归从根结点开始转移static void dfs2(int node, int parentDistanceSum) {if (node == 0) return;// 当前结点的总距离和 = 父结点的距离和 + 父结点距离和 - 左右子树的影响subtreeDistanceSum[node] = parentDistanceSum;int left = tree[node].left;int right = tree[node].right;if (left != 0) dfs2(left, subtreeDistanceSum[node] - subtreePopulation[left] + (subtreePopulation[1] - subtreePopulation[left]));if (right != 0) dfs2(right, subtreeDistanceSum[node] - subtreePopulation[right] + (subtreePopulation[1] - subtreePopulation[right]));}public static void main(String[] args) {Scanner input = new Scanner(System.in);n = input.nextInt();tree = new TreeNode[n + 1];subtreePopulation = new int[n + 1];subtreeDistanceSum = new int[n + 1];for (int i = 1; i <= n; i++) {int population = input.nextInt();int left = input.nextInt();int right = input.nextInt();tree[i] = new TreeNode(population, left, right);}// 第一次 DFS:计算以 1 为根的子树人口和与距离和dfs1(1);// 第二次 DFS:动态转移,从根结点向其他结点转移dfs2(1, subtreeDistanceSum[1]);// 寻找最小的距离和int minDistanceSum = Integer.MAX_VALUE;for (int i = 1; i <= n; i++) {minDistanceSum = Math.min(minDistanceSum, subtreeDistanceSum[i]);}System.out.println(minDistanceSum);}
}
P1229 遍历问题
解题思路
根节点不参与子树划分:前序遍历的第一个字符和后序遍历的最后一个字符是根节点,根节点不会影响左右子树的划分。代码通过遍历前序和后序字符串中间部分来寻找可能的左右子树划分。
寻找左右子树的模糊性:通过找到前序和后序遍历中成对的匹配字符(前序中某个字符的后续和后序中对应字符的前驱),代码识别出左右子树划分的模糊性。每一对匹配字符可以代表一个子树划分点。
中序遍历组合数的计算:如果有
ans对匹配子树,每一对子树可以有两种排列方式(左右子树顺序不同),所以总的中序遍历组合数是2^ans。
import java.util.Scanner;public class Main {public static void main(String[] args) {Scanner input = new Scanner(System.in);String str1 = input.next();String str2 = input.next();int ans = 0;for (int i = 0; i < str1.length(); i++) {for (int j = 1; j < str2.length(); j++) {if (str1.charAt(i) == str2.charAt(j) && (i + 1 < str1.length() && str1.charAt(i + 1) == str2.charAt(j - 1))) {ans++;}}}System.out.println(1 << ans);}
}P1305 新二叉树
解题思路
二叉树节点类设计 (
Node类)
- 每个节点用一个字符表示,并且每个节点可以有左子树和右子树。
Node类包含三个属性:节点的值val、左子节点left和右子节点right,初始时左右子节点都为null。读取输入
- 首先读取一个整数
n,表示树中节点的数量。题目保证节点数不超过 26,所以可以直接按顺序读取每个节点的信息。- 接下来读取每个节点的关系,依次表示父节点、左子节点、右子节点。空节点使用
'*'表示。- 输入的第一行一定是根节点的定义,后续的行则表示其他节点及其左右子节点。
构建二叉树
- 使用一个哈希表 (
Map<Character, Node>) 来存储每个节点,其中键是节点的字符,值是该节点的Node对象。- 遍历输入的每行信息,根据当前行的第一个字符创建父节点,并根据后两个字符判断是否有左子节点和右子节点,分别连接父节点和其子节点。如果子节点为
'*',表示该节点为空,不做处理。前序遍历
- 使用递归方法进行前序遍历。前序遍历的顺序是:
- 先访问根节点(直接输出根节点的值)。
- 递归访问左子节点。
- 递归访问右子节点。
- 递归函数
preOrder(Node root)对每个节点进行处理,如果当前节点为null,则返回。如果不为null,先打印当前节点的值,再递归处理左子树和右子树。根节点的获取
- 根节点是第一行读取的节点,因此在第一次读取时,将其保存为
rootNode变量。在所有节点构建完成后,直接从哈希表中获取该根节点并进行前序遍历。
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;class Node {char val;Node left;Node right;public Node(char val) {this.val = val;this.left = null;this.right = null;}
}public class Main {static Map<Character, Node> tree = new HashMap<>();// 前序遍历public static void preOrder(Node root) {if (root == null) return;System.out.print(root.val); // 先输出根节点preOrder(root.left); // 递归遍历左子树preOrder(root.right); // 递归遍历右子树}public static void main(String[] args) {Scanner input = new Scanner(System.in);int n = input.nextInt(); // 读取节点数input.nextLine(); // 读取下一行// 根节点的字符char rootNode = ' ';// 读入每个节点和其左右子节点的关系for (int i = 0; i < n; i++) {String line = input.nextLine();char parent = line.charAt(0);char leftChild = line.charAt(1);char rightChild = line.charAt(2);// 记录第一个输入的节点为根节点if (i == 0) {rootNode = parent;}// 如果父节点还不存在,创建一个新的节点tree.putIfAbsent(parent, new Node(parent));// 如果左子节点不是'*',创建并连接if (leftChild != '*') {tree.putIfAbsent(leftChild, new Node(leftChild));tree.get(parent).left = tree.get(leftChild);}// 如果右子节点不是'*',创建并连接if (rightChild != '*') {tree.putIfAbsent(rightChild, new Node(rightChild));tree.get(parent).right = tree.get(rightChild);}}// 根节点就是第一个输入的节点Node root = tree.get(rootNode);// 前序遍历preOrder(root);}
}P1030 [NOIP2001 普及组] 求先序排列
解题思路
后序遍历的特点:
- 后序遍历是“左子树 - 右子树 - 根节点”。
- 因此后序遍历的最后一个节点一定是二叉树的根节点。
中序遍历的特点:
- 中序遍历是“左子树 - 根节点 - 右子树”。
- 因此根据根节点,可以将中序遍历分为两部分,根节点左边是左子树,右边是右子树。
递归构造树:
- 通过后序遍历找到根节点。
- 根据根节点在中序遍历中的位置,将中序遍历划分为左子树和右子树部分。
- 对左子树和右子树分别递归进行相同的操作。
- 最后,按照“根节点 - 左子树 - 右子树”的顺序输出先序遍历结果。
import java.util.Scanner;public class Main {// 递归构造先序遍历public static void findPreOrder(String inOrder, String postOrder) {if (postOrder.isEmpty()) {return;}// 后序遍历的最后一个字符是根节点char root = postOrder.charAt(postOrder.length() - 1);// 输出根节点System.out.print(root);// 在中序遍历中找到根节点的位置int rootIndex = inOrder.indexOf(root);// 划分中序遍历为左子树和右子树String inOrderLeft = inOrder.substring(0, rootIndex);String inOrderRight = inOrder.substring(rootIndex + 1);// 划分后序遍历为左子树和右子树的后序遍历String postOrderLeft = postOrder.substring(0, inOrderLeft.length());String postOrderRight = postOrder.substring(inOrderLeft.length(), postOrder.length() - 1);// 递归处理左子树findPreOrder(inOrderLeft, postOrderLeft);// 递归处理右子树findPreOrder(inOrderRight, postOrderRight);}public static void main(String[] args) {Scanner input = new Scanner(System.in);// 输入中序遍历和后序遍历String inOrder = input.nextLine();String postOrder = input.nextLine();// 求先序遍历并输出findPreOrder(inOrder, postOrder);}
}
P3884 [JLOI2009] 二叉树问题
解题思路
1. 邻接表存储树的结构:
- 树的结构通过边描述,每条边连接两个节点。
- 使用邻接表(
head[]和edge[])存储边的信息,以有效管理和访问节点的相邻节点。2. SPFA 算法求最短路径:
SPFA(Shortest Path Faster Algorithm) 是一种基于队列的单源最短路径算法,适合稀疏图(如树结构)中的最短路径计算。
代码通过 SPFA 来计算从某个起点(如节点 1)到所有其他节点的最短路径,得到从根节点到每个节点的距离(也即树的深度)。
SPFA 的过程:
- 初始化所有节点的距离为无穷大,起点的距离为 0。
- 利用队列进行松弛操作,更新每个节点到起点的最短路径。
- 如果某个节点的距离被更新,且该节点不在队列中,则将其加入队列。
3. 计算树的最大深度:
- 通过 SPFA 计算出从根节点(即节点 1)到所有其他节点的最短路径,存储在
dis[]数组中。- 遍历
dis[]数组,找出其中的最大值,即为树的最大深度。4. 计算树的最大宽度:
- 在遍历
dis[]数组的过程中,记录每个不同深度(层次)上节点的数量,存储在box[]数组中。- 找出
box[]数组的最大值,即为树的最大宽度。5. 计算两个指定节点之间的最短路径:
- 在输入两个指定的节点
u和v后,使用 SPFA 从节点u出发,计算到所有其他节点的最短路径。- 通过
dis[v]获得从节点u到节点v的最短距离。
import java.util.*;class Node {int to, next, value;// 构造函数,用于初始化节点信息,包括目的节点、下一个边的索引以及边的权值Node(int to, int next, int value) {this.to = to;this.next = next;this.value = value;}
}public class Main {static final int MAXN = 1000; // 最大节点数static int[] dis = new int[MAXN + 1], vis = new int[MAXN + 1], head = new int[MAXN + 1], box = new int[MAXN + 1];static Node[] edge = new Node[2 * MAXN]; // 用于存储所有边的邻接表static int tot = 0; // 边的计数器public static void main(String[] args) {Scanner input = new Scanner(System.in);int n = input.nextInt(); // 输入节点数量// 读取树的边,并建立邻接表for (int i = 1; i < n; i++) {int u = input.nextInt(), v = input.nextInt(); // 输入每条边的两个节点addedge(u, v, 1); // 从父节点到子节点的边权为 1addedge(v, u, 2); // 从子节点到父节点的边权为 2}int u = input.nextInt(), v = input.nextInt(); // 输入需要查询路径的两个节点SPFA(1); // 从根节点 1 开始,使用 SPFA 算法计算最短路径int ans = 0;// 遍历每个节点,统计距离根节点的最远距离(即最大深度)for (int i = 1; i <= n; i++) {box[dis[i]]++; // 统计每层的节点数量ans = Math.max(ans, dis[i]); // 计算最大深度}System.out.println(ans + 1); // 输出树的最大深度(加上根节点)ans = 0;// 找到层中最多节点的层数(即最大宽度)for (int i = 1; i <= n; i++) {ans = Math.max(ans, box[i]); // 计算最大宽度}System.out.println(ans); // 输出最大宽度// 重新计算从节点 u 到节点 v 的最短路径SPFA(u);System.out.println(dis[v]); // 输出节点 u 到节点 v 的最短距离}// 添加一条边到邻接表static void addedge(int x, int y, int w) {edge[++tot] = new Node(y, head[x], w); // 创建新边head[x] = tot; // 更新当前节点的头部指针}// SPFA 算法用于计算单源最短路径static void SPFA(int s) {Queue<Integer> q = new LinkedList<>(); // 队列用于存储待处理的节点Arrays.fill(dis, Integer.MAX_VALUE); // 初始化所有节点的距离为无穷大Arrays.fill(vis, 0); // 初始化访问标记为 0,表示节点未在队列中dis[s] = 0; // 起点到自身的距离为 0vis[s] = 1; // 将起点标记为已访问q.add(s); // 将起点加入队列// 开始松弛操作,更新节点的最短距离while (!q.isEmpty()) {int x = q.poll(); // 从队列中取出一个节点vis[x] = 0; // 标记该节点不在队列中// 遍历从节点 x 出发的所有边for (int i = head[x]; i != 0; i = edge[i].next) {// 如果通过 x 可以使某个相邻节点的距离更短,则进行更新if (dis[edge[i].to] > dis[x] + edge[i].value) {dis[edge[i].to] = dis[x] + edge[i].value; // 更新相邻节点的最短距离// 如果该相邻节点不在队列中,则将其加入队列if (vis[edge[i].to] == 0) {vis[edge[i].to] = 1; // 标记相邻节点已在队列中q.add(edge[i].to); // 将该节点加入队列}}}}}
}P1185 绘制二叉树
解题思路
输入处理:
- 使用
BufferedReader读取输入,利用StringTokenizer分割输入数据,以获得树的深度k和不可绘制的节点数p。- 通过循环读取每个不可绘制的节点,并将其记录在布尔数组
f中。树形结构绘制:
- 根据树的深度
k,计算节点的总数n和画布的宽度m。- 使用深度优先搜索(DFS)绘制树的节点和边。函数
dfs1中根据当前节点的位置、父节点信息以及深度信息决定如何绘制节点和边。- 如果绘制到达叶子节点(深度为
n),则在相应的位置绘制叶子节点。输出结果:
- 将整个画布以字符的形式输出到控制台,使用
BufferedWriter提高输出效率。- 每行绘制完成后调用
newLine()输出换行。
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.StringTokenizer;public class Main {static int k, n, m, p, x, y; // k: 树的深度,n: 节点数,m: 画布宽度,p: 不可绘制的节点数static char[][] c = new char[800][1600]; // 绘制树的字符数组static boolean[][] f = new boolean[800][1600]; // 记录不可绘制的节点static BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); // 输入流static BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out)); // 输出流static StringTokenizer st; // 用于分割输入字符串// 深度优先搜索,绘制树形结构static void dfs1(int x, int y, int a, int b, int k, int xx, int yy) {// 如果到达树的最底层,绘制叶子节点if (x == n) {c[x][y] = 'o';return;}// 根据当前的 k 值决定绘制点还是边if (k == 1) {c[x][y] = 'o'; // 绘制节点int X = xx + 1, Y = (yy - 1) * 2 + 1; // 左儿子的位置// 如果左儿子不可绘制,则继续绘制if (!f[X][Y]) dfs1(x + 1, y - 1, a + 1, b, 2, X, Y);X = xx + 1;Y = yy * 2; // 右儿子的位置// 如果右儿子不可绘制,则继续绘制if (!f[X][Y]) dfs1(x + 1, y + 1, a + 1, b, 3, X, Y);} else if (k == 2) {c[x][y] = '/'; // 绘制左边的边// 判断接下来绘制点还是边if (a * 2 == b) dfs1(x + 1, y - 1, 1, a, 1, xx, yy);else dfs1(x + 1, y - 1, a + 1, b, 2, xx, yy);} else if (k == 3) {c[x][y] = '\\'; // 绘制右边的边// 判断接下来绘制点还是边if (a * 2 == b) dfs1(x + 1, y + 1, 1, a, 1, xx, yy);else dfs1(x + 1, y + 1, a + 1, b, 3, xx, yy);}}// 计算树的大小和绘制树形结构static void make(int k) {n = 3; // 初始设置为 3 层for (int i = 3; i <= k; i++) n *= 2; // 计算层数m = 6 * (1 << (k - 2)) - 1; // 计算画布的宽度// 初始化画布,填充空格for (int i = 1; i <= n; i++)for (int j = 1; j <= m; j++) c[i][j] = ' ';dfs1(1, m / 2 + 1, 1, n, 1, 1, 1); // 从根节点开始绘制}public static void main(String[] args) throws IOException {// 读取输入的树的深度和不可绘制节点数st = new StringTokenizer(br.readLine());k = Integer.parseInt(st.nextToken());p = Integer.parseInt(st.nextToken());// 读取不可绘制的节点while (p-- > 0) {st = new StringTokenizer(br.readLine());x = Integer.parseInt(st.nextToken());y = Integer.parseInt(st.nextToken());f[x][y] = true; // 标记这个节点为不可绘制}// 特殊情况处理if (k == 1) {n = m = 1;c[1][1] = 'o'; // 仅绘制一个节点} else {make(k); // 计算并绘制树}// 使用 BufferedWriter 输出结果for (int i = 1; i <= n; i++) {for (int j = 1; j <= m; j++) {bw.write(c[i][j]); // 输出画布的每个字符}bw.newLine(); // 换行}bw.flush(); // 刷新输出流,确保所有数据都被写出bw.close(); // 关闭输出流}
}
相关文章:

java 洛谷题单【数据结构1-2】二叉树
P4715 【深基16.例1】淘汰赛 解题思路 半区分配:将前半部分国家分配到左半区,后半部分国家分配到右半区,分别找到两个半区的最强国家。决赛和亚军确定:最后比较两个半区最强国家的能力值,失败者即为亚军,输…...
项目优化内容及实战
文章目录 事前思考Prometheus 普罗米修斯概述架构安装及使用 Grafana可视化数据库读写分离实战1-PrometheusGrafanaspringboot 事前思考 需要了解清楚:需要从哪些角度去分析实现?使用了缓存,就需要把缓存命中率数据进行收集;使用…...

科研绘图系列:R语言蝴蝶图(Butterfly Chart)
文章目录 介绍加载R包数据函数画图系统信息介绍 蝴蝶图(Butterfly Chart),也被称为龙卷风图(Tornado Chart)或双轴图(Dual-Axis Chart),是一种用于展示两组对比数据的图表。这种图表通过在中心轴两侧分别展示两组数据的条形图,形似蝴蝶的翅膀,因此得名。蝴蝶图的特点…...

【FPGA开发】Modelsim如何给信号分组
前面已经发布过了一篇关于 Modelsim 的入门使用教程,针对的基本是只有一个源文件加一个仿真tb文件的情况,而实际的工程应用中,往往是顶层加多个底层的源文件结构,如果不对信号进行一定的分组,就会显得杂乱不堪…...

Apache SeaTunnel 9月份社区发展记录
各位热爱 SeaTunnel 的小伙伴们,9月份社区月报来啦!这里将定期更新SeaTunnel社区每个月的重大进展,欢迎关注! 月度Merge Stars 感谢以下小伙伴上个月为 Apache SeaTunnel 做的精彩贡献(排名不分先后)&…...

系统架构设计师:数据库系统相关考题预测
作为系统架构设计师,在准备数据库系统相关的考试时,可以预期到的一些关键知识点包括但不限于以下几个方面: 数据库类型: 关系型数据库(RDBMS)与非关系型数据库(NoSQL)的区别及其适用场景。数据库管理系统(DBMS)的功能及组成部分。数据模型: 如何设计ER模型(实体-关…...

污水排放口细粒度检测数据集,污-水排放口的类型包括10类目标,10000余张图像,yolo格式目标检测,9GB数据量。
污水排放口细粒度检测数据集,污-水排放口的类型包括10类目标(1 合流下水道,2 雨水,3 工业废水,4 农业排水,5 牲畜养殖,6 水产养殖,7 地表径流,8 废水处理厂&…...

c++(多态)
多态的定义 多态是⼀个继承关系的下的类对象,去调⽤同⼀函数,产⽣了不同的⾏为 ⽐如Student继承了Person。Person对象买票全价,Student对象优惠买票。 多态实现的条件 • 必须指针或者引⽤调⽤虚函数 第⼀必须是基类的指针或引⽤,…...

【网络协议】TCP协议常用机制——延迟应答、捎带应答、面向字节流、异常处理,保姆级详解,建议收藏
💐个人主页:初晴~ 📚相关专栏:计算机网络那些事 前几篇文章,博主带大家梳理了一下TCP协议的几个核心机制,比如保证可靠性的 确认应答、超时重传 机制,和提高传输效率的 滑动窗口及其相关优化机…...

财政部官宣: 国家奖学金,涨了!
财政部副部长郭婷婷10月12日在国新办新闻发布会上介绍,关于高校学生的资助,财政部将会同相关部门从奖优和助困两个方面,分两步来调整完善高校学生的资助政策—— 第一步是在2024年推出以下政策措施: 国家奖学金的奖励名额翻倍。…...

antd table合并复杂单元格、分组合并行、分组合并列、动态渲染列、嵌套表头
项目里遇到个需求,涉及到比较复杂的单元格合并 、嵌套表头、分组合并行、合并列等,并且数据列还是动态的,效果图如下: 可以分组设置【显示列】例如:当前组为【合同约定】,显示列为【合同节点】和【节点金额…...

一键安装与配置Stable Diffusion,轻松实现AI绘画
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。 最新 Stable Di…...

模板和静态文件
模板和静态文件 1、templates模板2、静态文件2.1、static目录2.2、引用静态文件 1、templates模板 "templates"目录用于存放模板文件,通常是用于动态生成页面的文件。 在app01目录下创建templates文件夹,html文件均保存在templates中 在urls.p…...

Android Studio 打包aar丢失远程依赖问题解决
之前打包,使用的com.kezong.fat-aar,embed(‘XXXX’)的方式,可以使三方依赖打包在aar包里,在项目里直接使用 升级了Gradle:7.5后,打包就打包不起来了,一直报错ÿ…...

Chromium 搜索引擎功能浅析c++
地址栏输入:chrome://settings/searchEngines 可以看到 有百度等数据源,那么如何调整其顺序呢,此数据又存储在哪里呢? 1、浏览器初始化搜索引擎数据来源在 components\search_engines\prepopulated_engines.json // Copyright …...

DDoS攻击快速增长,如何在抗ddos防护中获得主动?
当下DDoS攻击规模不断突破上限。前段时间,中国首款3A《黑神话:悟空》也在一夜之内遭受到28万次攻击DDoS攻击,严重影响到全球玩家的游戏体验。Gcore发布的数据也显示了 DDoS攻击令人担忧的趋势,尤其是峰值攻击已增加到了令人震惊的…...

MongoDB 死锁 锁定问题
要查看 MongoDB 是否出现“锁死” (也就是所谓的 锁定问题,通常指长时间的锁定导致数据库操作无法正常进行),可以通过以下几种方法来检测数据库的锁定状态和锁定相关信息。 1. 使用 db.currentOp() 检查活动操作 MongoDB 提供了 db.currentOp() 命令来查…...
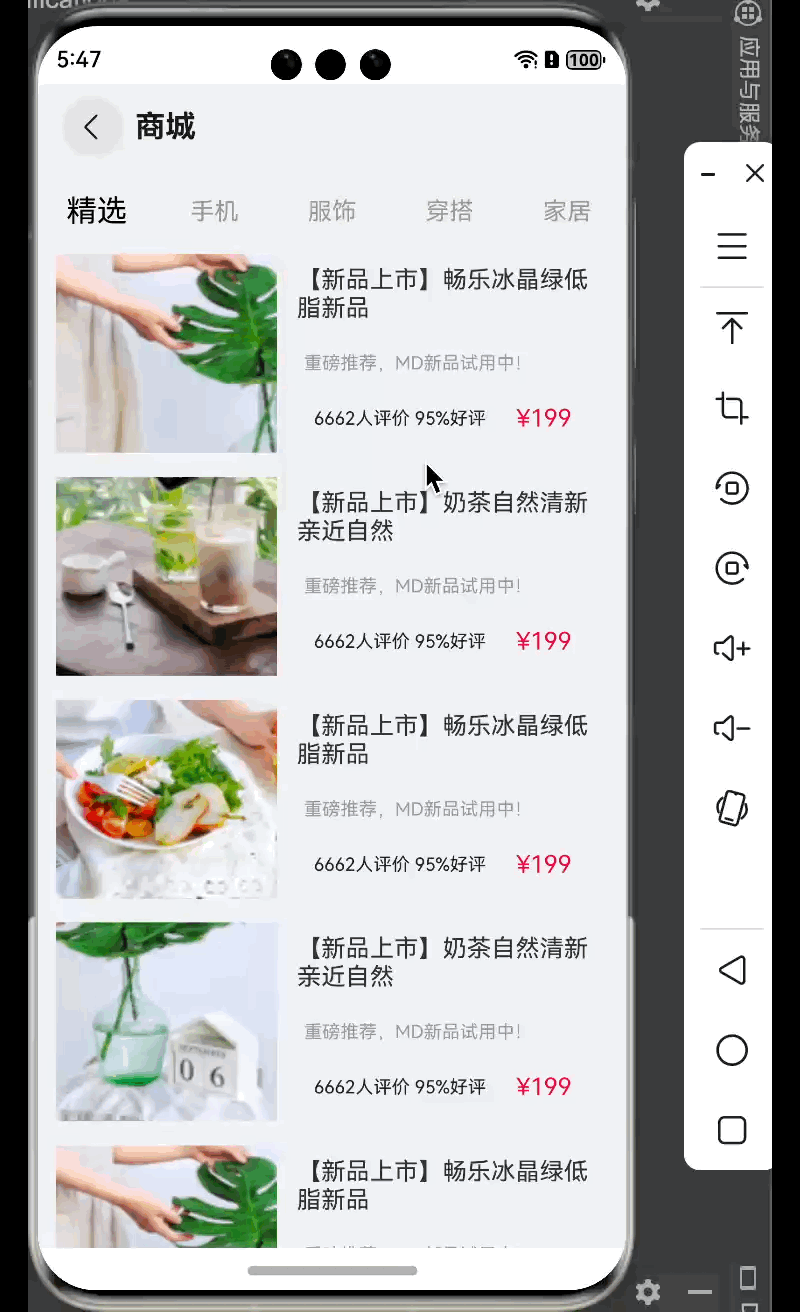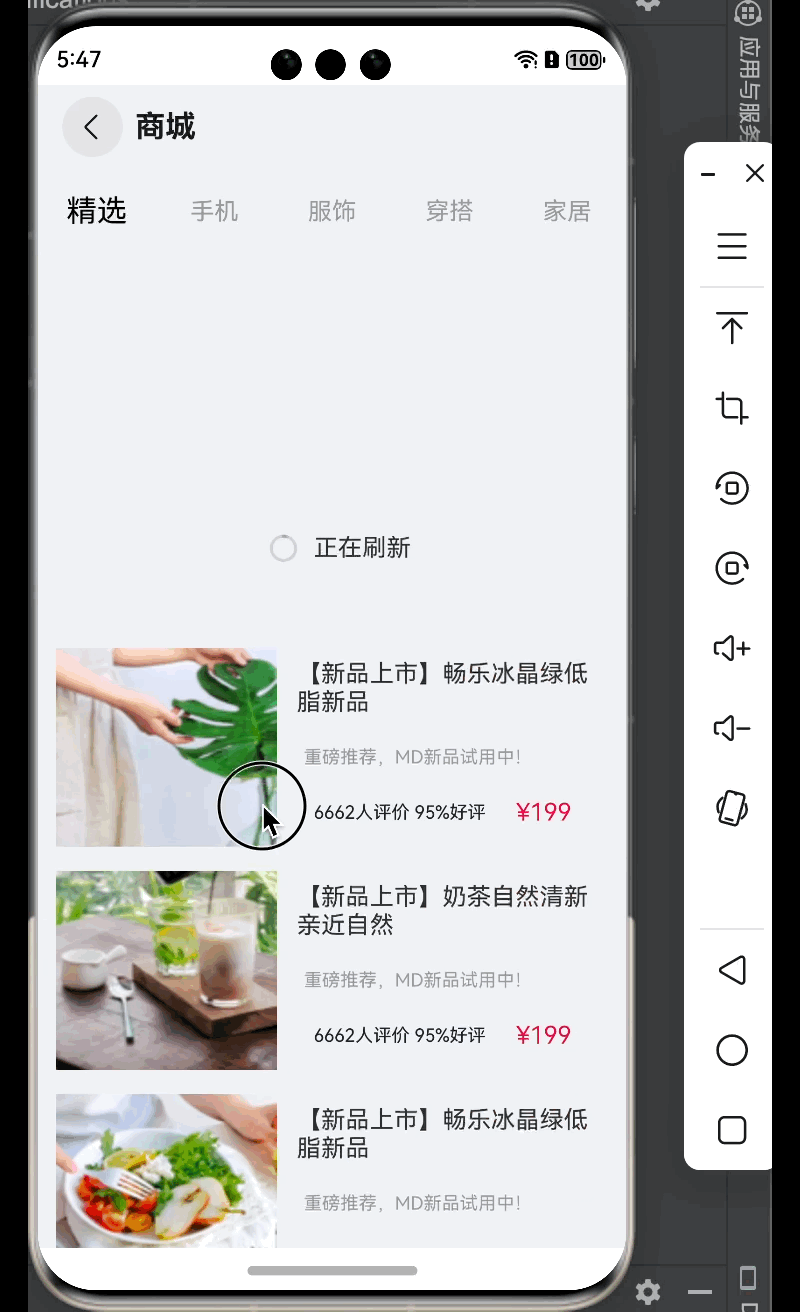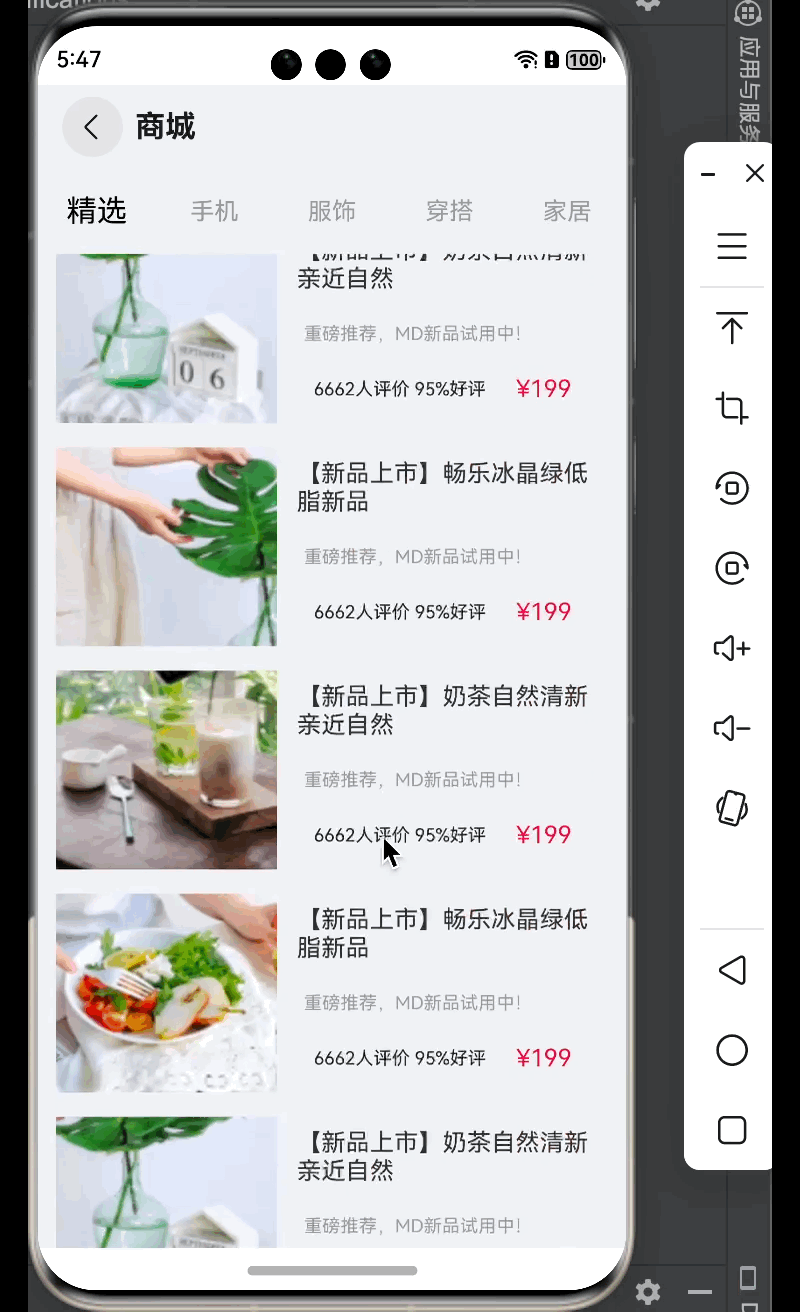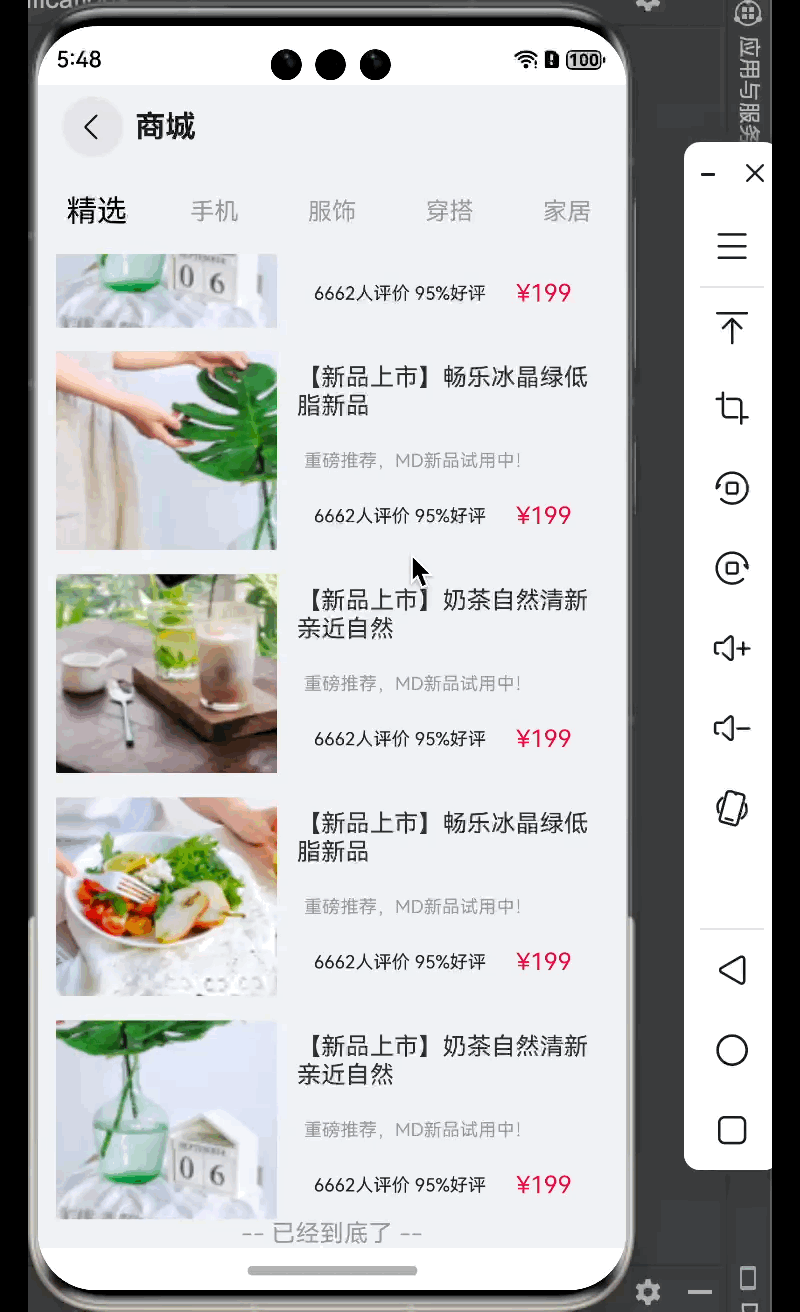
鸿蒙--商品列表
这里主要利用的是 List 组件 相关概念 Scroll:可滚动的容器组件,当子组件的布局尺寸超过父组件的视口时,内容可以滚动。List:列表包...

【Fargo】5:根据网络带宽动态调整发送速率
根据网络带宽动态调整发送速率 原理:这个简单实现的原理是 改变包的发送速率就可以改变发送码率了。例如1秒发1000个1KB 的包,带宽8Mbps,如果带宽是4Mbps,那么1秒发500个就够了。D:\XTRANS\thunderbolt\ayame\zhb-bifrost\player-only\worker\src\fargo\zhb_uv_udp_sender.…...

入门C语言:从原码、反码、补码到位运算
入门C语言:从原码、反码、补码到位运算 C语言作为一门底层编程语言,离不开对计算机硬件的深入理解。掌握整数的二进制表示法和位运算是深入学习C语言的基础。对于大一新生来说,理解原码、反码、补码与位运算这几个概念,将帮助你更…...

Taotoken Token Plan套餐为高频用户带来的长期成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan套餐为高频用户带来的长期成本优势感知 对于高频使用大模型API的开发者或团队而言,项目开发中的模…...

Warcraft Helper完整指南:3步解决魔兽争霸3在Win10/Win11的兼容性问题
Warcraft Helper完整指南:3步解决魔兽争霸3在Win10/Win11的兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在W…...

ElevenLabs动画配音语音交付危机预警,紧急修复唇动不同步、语速断层、多语言混读错位的6大实时响应方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs动画配音语音交付危机的本质溯源 当动画制作团队依赖 ElevenLabs API 实时生成角色语音时,突然出现的 429 Too Many Requests 响应、TTS 音频静音片段、以及语音情感断层现象&…...

3分钟极速激活:KMS智能激活工具让你的Windows和Office永久免费使用
3分钟极速激活:KMS智能激活工具让你的Windows和Office永久免费使用 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文…...
)
别再乱放模型文件了!手把手教你用Simulink Project管理MBD项目(附目录结构最佳实践)
从混乱到秩序:Simulink Project工程化管理实战指南 在模型驱动开发(MBD)的世界里,一个整洁有序的项目结构就像建筑师的蓝图——它不仅是工作的基础,更是团队协作和长期维护的保障。许多工程师在初次接触Simulink时&…...

如何在macOS上免费解锁百度网盘SVIP下载限速?终极解决方案
如何在macOS上免费解锁百度网盘SVIP下载限速?终极解决方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS BaiduNetdiskPlugin-macOS是一款…...

别再写一堆CASE WHEN了!PostgreSQL里COALESCE和NULLIF这两个函数,帮你把SQL写得又短又稳
告别冗长SQL:用PostgreSQL的COALESCE和NULLIF重构条件逻辑 在数据处理的世界里,SQL就像是我们与数据库对话的语言。但你是否经常遇到这样的情况:为了处理各种空值和边界条件,你的SQL查询变成了一个由无数CASE WHEN语句组成的庞然大…...

B站视频解析API架构解析:PHP实现的高效视频流获取方案
B站视频解析API架构解析:PHP实现的高效视频流获取方案 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 在视频内容生态蓬勃发展的今天,开发者经常面临一个技术挑战:…...

Dify工作流实战指南:零代码构建企业级应用系统的终极方案
Dify工作流实战指南:零代码构建企业级应用系统的终极方案 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Di…...

Visual C++运行库终极指南:如何3分钟解决Windows软件启动失败问题
Visual C运行库终极指南:如何3分钟解决Windows软件启动失败问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的场景…...