UCI-HAR数据集深度剖析:训练仿真与可视化解读
在本篇文章中,我们将深入探讨如何使用Python对UCI人类活动识别(HAR)数据集进行分割和预处理,以及运用模型网络CNN对数据集进行训练仿真和可视化解读。
一、UCI-HAR数据集分析及介绍
UCI-HAR数据集是一个公开的数据集,旨在通过智能手机传感器数据进行人类活动识别。这个数据集由30名志愿者在进行日常生活活动时携带带有嵌入式惯性传感器的腰部智能手机生成。数据集中的活动包括行走、上楼梯、下楼梯、坐着、站立和躺着等六种基本活动。
UCI-HAR数据集提供了原始的采样数据和经过预处理的数据。原始数据包括加速度计和陀螺仪的三轴数据,而预处理后的数据则包括时域和频域的特征向量。数据集中的每个样本都包含了丰富的特征信息,如加速度和角速度数据,以及从这些数据中提取的561种特征向量。
执行的六项活动如下:
Walking;Walking Upstairs;Walking Downstairs;Sitting;Standing;Laying
二、UCI-HAR数据集分割及处理
1.环境设置
在正式开始实验前,我们需要确保Python环境中安装了以下库:
numpy:用于高效的数值计算。pandas:用于数据分析和处理。os和sys:Python标准库,用于操作系统级别的操作。
2.数据集下载
首先,我们需要下载UCI-HAR数据集,通过设定一个单独的 download_dataset 函数完成,下载数据集并将其保存到指定的目录,这是下载链接:https://archive.ics.uci.edu/static/public/240/human+activity+recognition+using+smartphones.zip
download_dataset(dataset_name='UCI-HAR',file_url='https://archive.ics.uci.edu/static/public/240/human+activity+recognition+using+smartphones.zip', dataset_dir=dataset_dir
)
3.数据预处理
3.1读取数据
预处理的第一步是将文本格式的数据转换为numpy数组,通过自定义的 xload 和 yload 函数完成。
def xload(X_path):# 遍历每个信号类别的文件路径x = []for each in X_path:# 打开文件,读取每一行,分割字符串并转换为浮点数数组with open(each, 'r') as f:x.append(np.array([eachline.replace(' ', ' ').strip().split(' ') for eachline in f], dtype=np.float32))# 转置数组以匹配预期的形状x = np.transpose(x, (1, 2, 0))return x
xload 函数接收一组文本文件路径,逐行读取数据,去除空白字符,分割字符串,并将每个信号的数据转换为浮点数格式。然后,它通过转置操作调整数据的形状以匹配后续处理的需要。
3.2标签处理
yload 函数用于读取标签数据,并将它们转换为从0开始的整数数组。
def yload(Y_path):# 使用pandas读取CSV文件,转换为numpy数组,并重塑为一维数组y = pd.read_csv(Y_path, header=None).to_numpy().reshape(-1)# 将标签转换为从0开始的整数return y - 1
4.数据分割
UCI-HAR数据集已经预先分割为训练集和测试集。在本次的实验中,我们定义了训练集和测试集的文件路径,并使用 xload 和 yload 函数加载数据。
X_train_path = [dataset + '/train/Inertial Signals/' + signal + 'train.txt' for signal in signal_class]
X_test_path = [dataset + '/test/Inertial Signals/' + signal + 'test.txt' for signal in signal_class]
Y_train_path = dataset + '/train/y_train.txt'
Y_test_path = dataset + '/test/y_test.txt'X_train = xload(X_train_path)
X_test = xload(X_test_path)
Y_train = yload(Y_train_path)
Y_test = yload(Y_test_path)
5.数据保存
预处理后需要将数据保存起来,供下面的训练仿真与可视化使用。这里,我们使用 save_npy_data 函数将数据保存为 .npy 文件。
if SAVE_PATH: # 如果提供了保存路径save_npy_data(dataset_name='UCI_HAR',root_dir=SAVE_PATH,xtrain=X_train,xtest=X_test,ytrain=Y_train,ytest=Y_test)
6.结果展示
最后,输出=出训练集和测试集的形状,以确认数据加载和预处理是否正确。
print('xtrain shape: %s\nxtest shape: %s\nytrain shape: %s\nytest shape: %s' % (X_train.shape, X_test.shape, Y_train.shape, Y_test.shape))
输出结果:
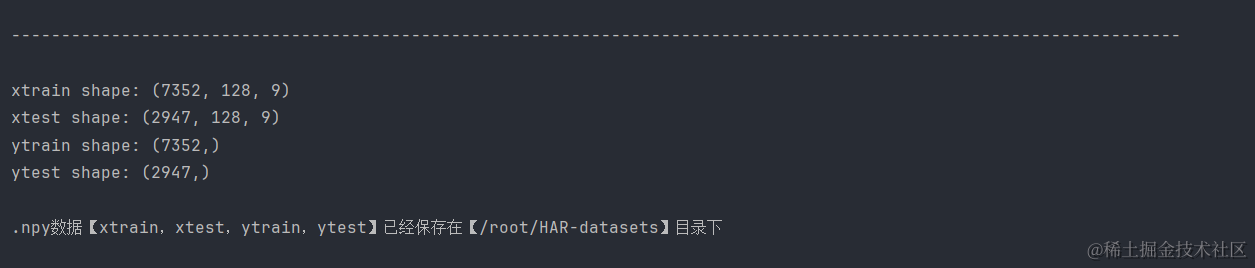
输出结果给出了每个集合的维度信息, X_train.shape 输出 (7352, 128, 9),表示训练集有7352个样本,每个样本有128个时间步长的数据,每个时间步包含9个特征(对应于信号类别)。
通过上述步骤,我们完成了UCI-HAR数据集的下载、预处理、分割和保存。这些步骤为下面的训练仿真与可视化使用任务奠定了基础。预处理后的数据可以直接用于训练模型,而不需要从头开始处理原始数据集。
三、CNN网络训练UCI-HAR数据集
CNN网络我们在之前的文章中已经很详细的介绍了,这里并不做过多的解读。
1.环境设置
确保你的环境中安装了以下Python库:
torch:PyTorch深度学习框架。numpy:用于高效的数值计算。sklearn:用于模型评估。argparse:用于解析命令行参数。
2.参数解析
首先,我们使用 argparse 库来定义和解析命令行参数,这包括数据集、模型、保存路径、批次大小、训练轮数和学习率等。
def parse_args():# ... 省略部分代码 ...args = parser.parse_args()return args
3.主执行流程
在主执行流程中,我们首先定义了数据集和模型的字典,选择想要训练的网络模型。
if __name__ == '__main__':# ... 省略部分代码 ...args = parse_args()# ... 省略部分代码 ...
4.数据集加载与预处理
加载数据集,并将其转换为PyTorch需要的张量格式:
X_train = torch.from_numpy(train_data).float().unsqueeze(1)
X_test = torch.from_numpy(test_data).float().unsqueeze(1)
Y_train = torch.from_numpy(train_label).long()
Y_test = torch.from_numpy(test_label).long()
5.模型构建
构建相应的CNN模型,并将其发送到合适的设备(GPU或CPU)。
net = model_dict[args.model](X_train.shape, category).to(device)
6.训练与评估
接下来,我们定义了优化器、学习率调度器、损失函数,并使用混合精度训练来提高训练效率。
optimizer = torch.optim.AdamW(net.parameters(), lr=LR, weight_decay=0.001)
lr_sch = torch.optim.lr_scheduler.StepLR(optimizer, EP // 3, 0.5)
loss_fn = nn.CrossEntropyLoss()
scaler = GradScaler() # 在训练最开始之前实例化一个GradScaler对象
然后,我们进入训练循环,每个epoch都包括模型训练和评估。
for i in range(EP):net.train()inference_start_time = time.time()for data, label in train_loader:data, label = data.to(device), label.to(device)# 前向过程(model + loss)开启 autocast,混合精度训练with autocast():out = net(data)loss = loss_fn(out, label)optimizer.zero_grad() # 梯度清零scaler.scale(loss).backward() # 梯度放大scaler.step(optimizer) # unscale梯度值scaler.update()lr_sch.step()
7.可视化结果展示
7.1 准确率、精确率、召回率、F1分数、推理时间
在每个epoch结束后,输出准确率、精确率、召回率、F1分数、推理时间。
# 计算评估指标
accuracy = accuracy_score(all_labels, all_preds)
report = classification_report(all_labels, all_preds, output_dict=True, zero_division=1)
precision = report['weighted avg']['precision']
recall = report['weighted avg']['recall']
f1_score = 2 * precision * recall / (precision + recall)
# 计算推理时间
inference_end_time = time.time()
inference_time = inference_end_time - inference_start_time
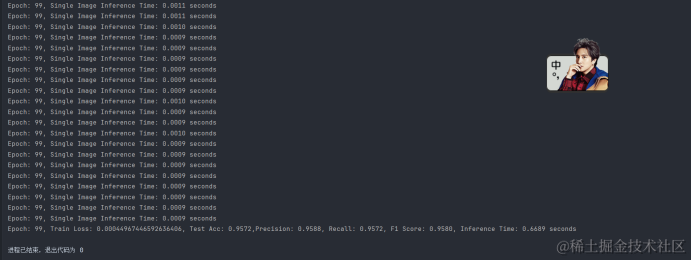
最后得到的准确率、精确率、召回率、F1分数、推理时间分别是:Test Acc:0.9572,Precision: 0.9588,Recall: 0.9572,F1 Score: 0.9580,Inference Time: 0.6689 seconds。
根据上述性能指标,我们可以看出所训练的CNN模型在UCI-HAR数据集上取得了非常优异的性能。准确率、精确率、召回率和F1分数均超过了95%,显示出模型具有很高的分类准确性和鲁棒性。同时,较短的推理时间意味着该模型可以有效地应用于需要快速响应的实际问题中。
接下来,我们将介绍混淆矩阵、雷达图、准确率与损失率的收敛曲线图以及仿真指标的柱状图和折线图的生成方法。
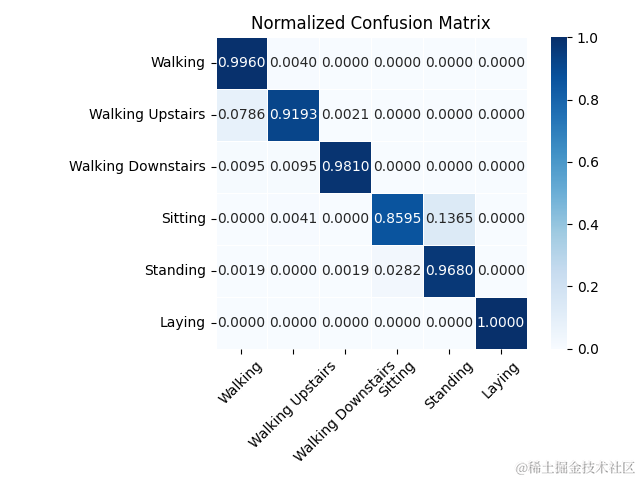
7.2混淆矩阵图
混淆矩阵是一个重要的工具,用于可视化模型在各个类别上的性能。我们首先计算归一化的混淆矩阵,然后使用seaborn的heatmap函数进行绘图。
conf_matrix = confusion_matrix(all_labels, all_preds, normalize='true')
# 自定义类别标签列表
class_labels = ['Walking', 'Walking Upstairs', 'Walking Downstairs', 'Sitting', 'Standing', 'Laying']# 使用 seaborn 的 heatmap 函数绘制归一化的混淆矩阵
ax = sns.heatmap(conf_matrix, annot=True, fmt='.4f', cmap='Blues',xticklabels=class_labels, yticklabels=class_labels,square=True, linewidths=.5)
输出混淆矩阵图:
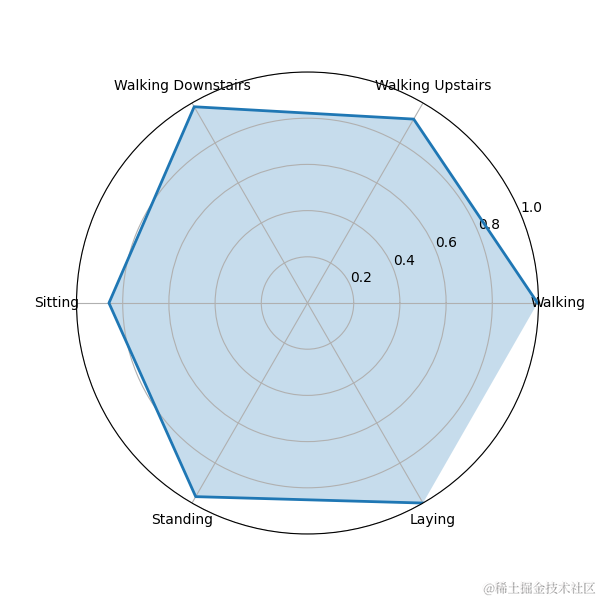
7.3雷达图
雷达图可以展示模型在不同类别上的识别能力。我们使用matplotlib绘制每个行为的雷达图。
# 绘制雷达图
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))# 绘制每个行为的雷达图
ax.plot(angles, beh, linestyle='-', linewidth=2)
ax.fill(angles, beh, alpha=0.25)# 设置雷达图的刻度和标签
ax.set_xticks(angles)
ax.set_xticklabels(['Walking', 'Walking Upstairs', 'Walking Downstairs', 'Sitting', 'Standing', 'Laying'])
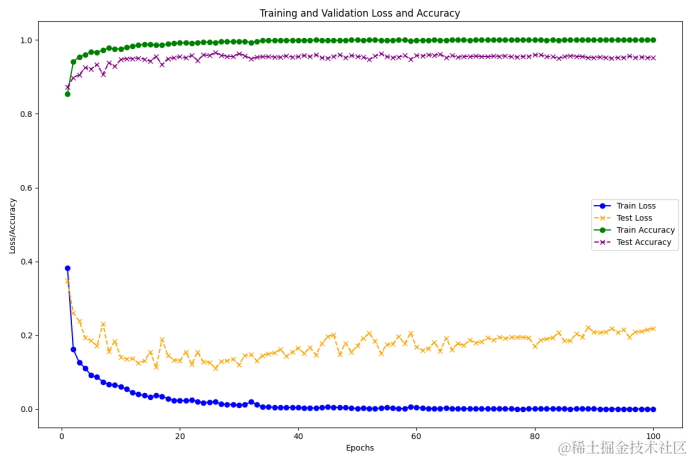
7.4准确率和损失率的收敛曲线图
通过绘制训练损失和测试损失,以及训练准确率和测试准确率的收敛曲线图,我们可以观察模型在训练过程中的稳定性和泛化能力。
# 绘制训练损失和测试损失
plt.plot(range(1, EP + 1), train_losses, label='Train Loss', color='blue', marker='o')
plt.plot(range(1, EP + 1), test_losses, label='Test Loss', color='orange', linestyle='--', marker='x')# 绘制训练准确率和测试准确率
plt.plot(range(1, EP + 1), train_accuracies, label='Train Accuracy', color='green', marker='o')
plt.plot(range(1, EP + 1), test_accuracies, label='Test Accuracy', color='purple', linestyle='--', marker='x')
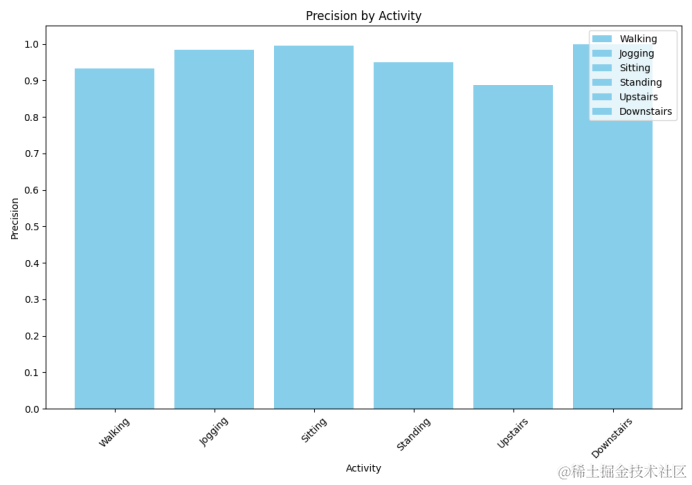
7.5仿真指标柱状图
柱状图可以展示模型在不同类别上的精确率,有助于识别模型在哪些类别上表现更好或更差。
# 自定义类别标签列表
class_labels = ['Walking', 'Jogging', 'Sitting', 'Standing', 'Upstairs', 'Downstairs']# 计算每个类别的精确率
precisions = {}
for label in unique_labels:# 为当前类别创建一个二进制的标签数组y_true = np.where(all_labels == label, 1, 0)y_pred = np.where(all_preds == label, 1, 0)# 计算当前类别的精确率# 设置 average 参数为 'binary',因为我们现在是针对每个类别单独计算precision = precision_score(y_true, y_pred, average='binary')precisions[label] = precision
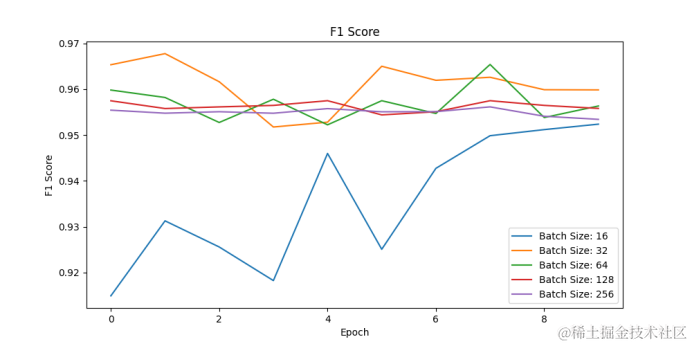
7.6仿真指标折线图
通过改变批处理大小并进行多次实验,我们可以评估批处理大小对模型性能的影响。
# 进行多次实验,每次使用不同的批处理大小
batch_sizes = [16, 32, 64, 128, 256]
f1_scores_per_batch = {BS: [] for BS in batch_sizes}
for BS in batch_sizes:f1_scores_per_batch[BS] = train_and_evaluate(BS, 10, LR)# 绘制不同批处理大小下的加权F1分数
plt.figure(figsize=(10, 5))
for BS, f1_scores in f1_scores_per_batch.items():plt.plot(f1_scores, label=f'Batch Size: {BS}')
在这一部分,我们展示了如何对CNN网络训练的UCI-HAR数据集进行性能评估和可视化。通过混淆矩阵、雷达图、收敛曲线图以及柱状图和折线图,我们可以全面了解模型的性能,并识别模型在不同类别上的表现。这些可视化工具对于模型的调试和优化至关重要。
注意:具体的代码实现和模型细节可以联系作者获取,以便进一步的研究和应用。本文首发于稀土掘金,未经允许禁止转发和二次创作,侵权必究。
相关文章:
UCI-HAR数据集深度剖析:训练仿真与可视化解读
在本篇文章中,我们将深入探讨如何使用Python对UCI人类活动识别(HAR)数据集进行分割和预处理,以及运用模型网络CNN对数据集进行训练仿真和可视化解读。 一、UCI-HAR数据集分析及介绍 UCI-HAR数据集是一个公开的数据集,…...

牛客SQL练习详解 06:综合练习
牛客SQL练习详解 06:综合练习 SQL34 统计复旦用户8月练题情况SQL35 浙大不同难度题目的正确率SQL39 21年8月份练题总数 叮嘟!这里是小啊呜的学习课程资料整理。好记性不如烂笔头,今天也是努力进步的一天。一起加油进阶吧! SQL34 统…...

k8s apiserver高可用方案
目前官方推荐有 2 种方式部署k8s apiserver 高可用 keepalived and haproxy 部署有2种方式,一种是systemd管理的,另一种是pod形式,使用那种可以根据实际情况选择 服务部署 systemd方式 可以通过包管理工具安装,正常启动之后&…...

服务器数据恢复—硬盘坏扇区导致Linux系统服务器数据丢失的数据恢复案例
服务器数据恢复环境: 一台linux操作系统网站服务器,该服务器上部署了几十个网站,使用一块SATA硬盘。 服务器故障&原因: 服务器在工作过程中突然宕机。管理员尝试重新启动服务器失败,于是将服务器上的硬盘拆下检测…...

【多线程】多线程(12):多线程环境下使用哈希表
【多线程环境下使用哈希表(重点掌握)】 可以使用类:“ConcurrentHashMap” ★ConcurrentHashMap对比HashMap和Hashtable的优化点 1.优化了锁的粒度【最核心】 //Hashtable的加锁,就是直接给put,get等方法加上synch…...

轻量服务器和云服务器ecs哪个好用一些?
轻量服务器和云服务器ecs哪个好用一些?轻量服务器与云服务器ECS在多方面存在显著差异,对于需要高性能计算和大规模数据处理的用户来说,ECS可能是更好的选择;而对于预算有限且需求较为简单的用户来说,轻量服务器可能更为…...
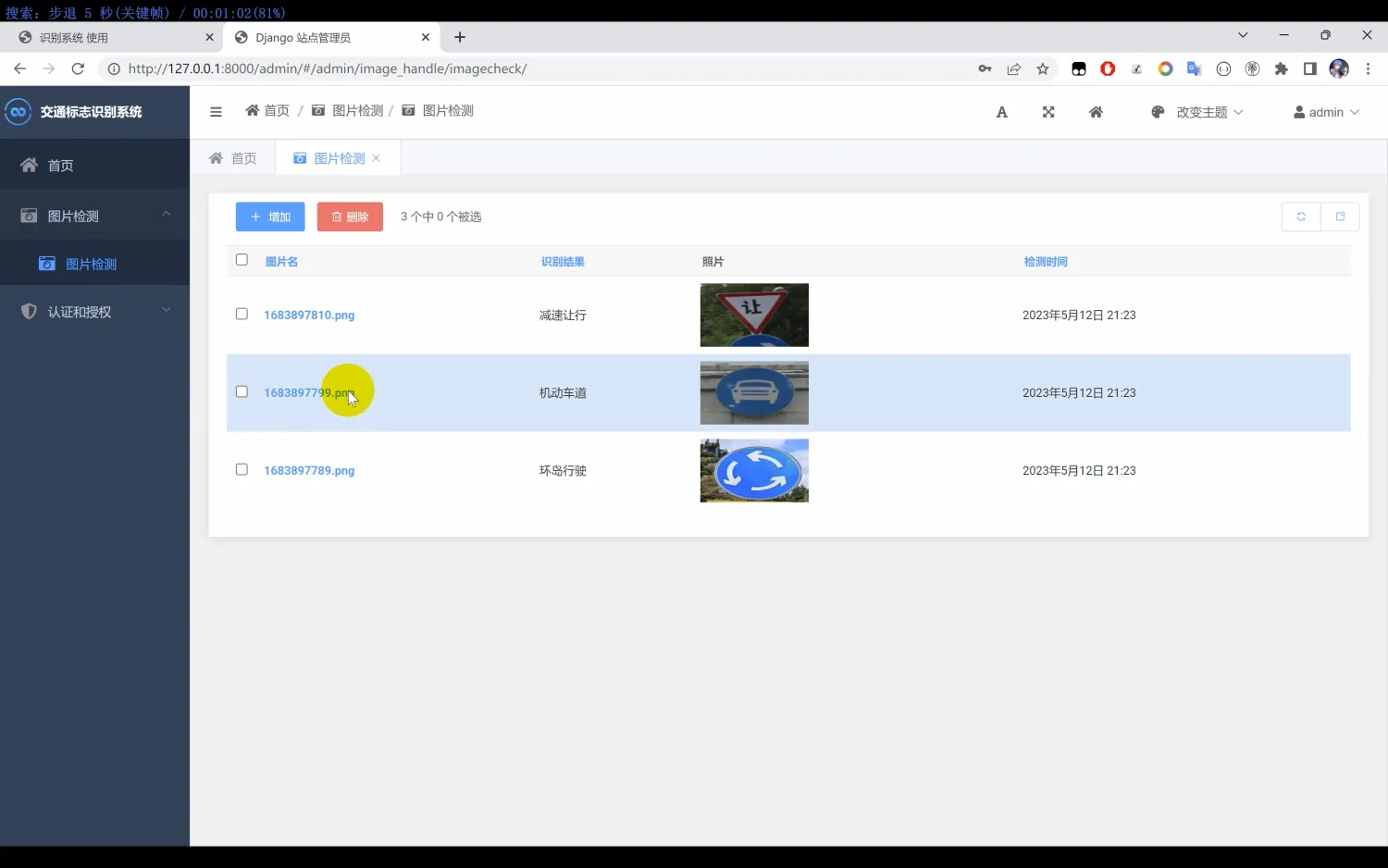
【交通标志识别系统】Python+卷积神经网络算法+人工智能+深度学习+机器学习+算法模型
一、介绍 交通标志识别系统。本系统使用Python作为主要编程语言,在交通标志图像识别功能实现中,基于TensorFlow搭建卷积神经网络算法模型,通过对收集到的58种常见的交通标志图像作为数据集,进行迭代训练最后得到一个识别精度较高…...

特种设备作业叉车司机试题附答案
1.发生事故要本着"( )不放过"的原则,查明原因、分清责任、严肃处理。 A.三 B.四 C.五 答案:B 2.柴油发动机在压缩行程终了时气体的温度和压力都比汽油机( )。 A.低 B.高 C.相同 答案:B 3.柴油发动机的压缩比比汽…...

【Nginx系列】Nginx启动失败
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

2024/10/12 计组大题专训
2018: 2019: 2020: 2021:...

2024年腾讯外包面试题(微创公司)
笔试: 1、判断异步执行顺序 console.log(1);setTimeout(()>{Promise.resolve().then(()>{console.log(2);})console.log(3);},0);new Promise ((resolve)>{for(let i0; i<1000;i ){if(i1000){resolve();}}console.log(4);}).then(()>{console.log(5…...

nginx运行时报:No rule to make target ‘build‘, needed by ‘deault‘.Stop
项目场景: 部署前端项目,将打好的前端包,放到服务器上,运行nginx执行,结果nginx运行报错。 问题描述 nginx运行报以下错误: No rule to make target ‘build‘, needed by ‘deault‘.Stop原因分析&…...

dvwa:暴力破解、命令注入、csrf全难度详解
暴力破解 easy模式 hydra -L /usr/share/wordlists/SecLists-master/Usernames/top-usernames-shortlist.txt -P /usr/share/wordlists/SecLists-master/Passwords/500-worst-passwords.txt 192.168.72.1 http-get-form "/dvwa/vulnerabilities/brute/:username^USER^&…...

Java-学生管理系统[初阶]
这次我们来尝试使用Java实现一下"学生管理系统",顾名思义,就是实现一个能用来管理学生各种数据的系统。在后续学习中我们将对"学生管理系统"进行两种实现: 📚 学生管理系统[初阶](不带模拟登录系统) &#…...

微信小程序 详情图片预览功能实现详解
详情图片预览功能实现详解 在开发微信小程序时,我们经常需要实现点击商品图片进行全屏预览的功能。这不仅提升了用户体验,还允许用户进行保存图片、发送给朋友等操作。本文将详细介绍如何实现这一功能。 思路分析 当用户在商品详情页点击图片时&#…...

LeetCode 48 Rotate Image 解题思路和python代码
题目: You are given an n x n 2D matrix representing an image, rotate the image by 90 degrees (clockwise). You have to rotate the image in-place, which means you have to modify the input 2D matrix directly. DO NOT allocate another 2D matrix and …...

余承东直播论道智能驾驶:激光雷达不可或缺,华为ADS 3.0引领安全创新
华为余承东:激光雷达,智能驾驶安全性的关键 9月29日,华为消费者业务集团CEO余承东在一场引人注目的直播中,与知名主持人马东就智能驾驶技术的最新进展进行了深入交流。在这场直播中,余承东针对激光雷达在智能驾驶中的必要性问题,发表了明确且深刻的观点,引发了业界和公众…...

51WORLD携手浙江科技大学,打造智慧校园新标杆
当前,国家教育数字化战略行动扎实推进,高等教育数字化转型步伐加快。 紧抓数字教育发展战略机遇,浙江科技大学联合51WORLD、正方软件股份有限公司(简称:正方软件),共同研发打造浙科大孪生数智校…...

SAP SD学习笔记09 - 受注传票中的不完全Log 和 Business Partner(取引先机能)
好久没写SD了,今天继续写。 上一章讲了SD的如下知识 - SD的售前的流程(引合和見積(询价和报价)) - 数据流的概念,主要就是后传票可以参照前传票,以实现数据的流动,减少输入 - Co…...
数据计算、发布)
【ROS2】里程计(odometry)数据计算、发布
1、里程计消息 1.1 Odometry消息 消息描述:nav_msgs::msg::Odometry 是ROS2中用发布里程计信息的消息,包括:线速度、角速度、位置和朝向 消息路径:/opt/ros/humble/share/nav_msgs/msg/Odometry.msg 消息内容: # 包含父ID std_msgs/Header header# 子ID,即姿势所在的坐…...

晶晨T972嵌入式主板开发指南:从硬件选型到量产部署
1. 项目概述:一颗“芯”引发的性价比革命 最近在嵌入式开发圈和智能硬件圈里,一个消息传得挺火:亮钻推出了一款基于晶晨T972平台的高性价比主板。对于很多正在寻找稳定、高性能且成本可控的解决方案的开发者、产品经理和创客来说,…...

从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库
从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.com…...

MATLAB图像处理实战:用形态学开闭运算5分钟搞定椒盐噪声去除
MATLAB图像处理实战:5分钟用形态学开闭运算高效去除椒盐噪声 在数字图像处理领域,椒盐噪声是最常见的干扰类型之一——那些随机分布在图像上的黑白噪点,就像撒在照片上的胡椒和盐粒。对于工程师和科研人员来说,如何快速有效地去除…...
)
手机拍电脑屏幕总有水波纹?一文搞懂Sensor Flicker与Banding现象(附避坑指南)
手机拍屏幕水波纹全解析:从频闪原理到实战避坑指南 你是否遇到过这样的尴尬时刻——用手机拍摄电脑屏幕上的重要内容,结果照片或视频里布满诡异的水波纹和条纹?这种令人抓狂的现象并非手机质量问题,而是Sensor Flicker与Banding这…...

SolidWorks二次开发踩坑记:Python调用SaveAs函数时,那些让人头疼的Errors和Warnings详解
SolidWorks二次开发实战:Python调用SaveAs函数时的错误码解析与解决方案 当你在深夜加班调试SolidWorks二次开发脚本时,SaveAs函数突然返回False,错误码像摩尔斯电码一样难以解读——这种经历恐怕每个工业软件开发者都深有体会。本文将深入剖…...

终极Markdown浏览器扩展:如何打造完美的文档阅读体验
终极Markdown浏览器扩展:如何打造完美的文档阅读体验 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展,专为开发…...

如何免费快速解锁电脑隐藏性能:UXTU硬件调优终极指南
如何免费快速解锁电脑隐藏性能:UXTU硬件调优终极指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 还在为电脑性…...

NCM解密终极指南:3步释放网易云音乐到任何播放器
NCM解密终极指南:3步释放网易云音乐到任何播放器 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在特定应用中播放?当你想要将音乐迁移到其他设…...

如何通过DLSS版本管理工具提升30%游戏性能:实战指南
如何通过DLSS版本管理工具提升30%游戏性能:实战指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款开源游戏性能优化工具,专门用于管理DLSS、FSR和XeSS动态库版本。你是否曾…...

终极指南:如何在Mac上免费快速导出微信聊天记录
终极指南:如何在Mac上免费快速导出微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑?或需要查找…...