尚硅谷rabbitmq 2024 流式队列2024指定偏移量 第55节答疑
rabbitmq的stream:
4、对比
autoTrackingstrategy方式:始终监听Stream中的新消息(狗狗看家,忠于职守)指定偏移量方式:针对指定偏移量的消息消费之后就停止(狗狗叼飞盘,回来就完)
这两种分别怎么写?java
在 RabbitMQ 中,Stream 是一种新的消息传递机制,允许高吞吐量和低延迟的消息传递。你提到的两种消费方式分别是自动跟踪策略(Auto Tracking Strategy)和指定偏移量(Offset)的消费方式。下面我们将分别演示这两种方式的 Java 实现。
### 1. 自动跟踪策略(Auto Tracking Strategy)
这种方式下,消费者会一直监听 Stream 中的新消息,并不断处理这些消息。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.OffsetSpecification;
import com.rabbitmq.stream.ConsumerBuilder;
public class AutoTrackingConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.offset(OffsetSpecification.first()) // 从第一个消息开始
.messageHandler((context, message) -> {
String body = new String(message.getBodyAsBinary());
System.out.println("Received message: " + body);
})
.build();
// 消费者会一直运行,监听新的消息
System.out.println("Consumer is listening for new messages...");
}
}
```
### 2. 指定偏移量(Offset)的消费方式
这种方式下,消费者会从指定的偏移量开始消费消息,并在消费完这些消息后停止。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.OffsetSpecification;
import com.rabbitmq.stream.ConsumerBuilder;
public class OffsetConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
long offset = 10; // 指定偏移量
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.offset(OffsetSpecification.offset(offset)) // 从指定偏移量开始
.messageHandler((context, message
============
为什么没写.autoTrackingStrategy()?
你提到的 `.autoTrackingStrategy()` 是 RabbitMQ Stream API 中的一个重要方法,它用于指定消费者的自动跟踪策略。让我们详细解释一下如何在代码中使用这个方法。
### 自动跟踪策略(Auto Tracking Strategy)
自动跟踪策略允许消费者始终监听 Stream 中的新消息,并自动跟踪消息的偏移量。这种方式下,消费者会持续消费新消息,而不会停止。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.OffsetSpecification;
import com.rabbitmq.stream.ConsumerBuilder;
public class AutoTrackingConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.offset(OffsetSpecification.first()) // 从第一个消息开始
.autoTrackingStrategy() // 启用自动跟踪策略
.messageHandler((context, message) -> {
String body = new String(message.getBodyAsBinary());
System.out.println("Received message: " + body);
})
.build();
// 消费者会一直运行,监听新的消息
System.out.println("Consumer is listening for new messages...");
}
}
```
### 指定偏移量(Offset)的消费方式
这种方式下,消费者会从指定的偏移量开始消费消息,并在消费完这些消息后停止。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.OffsetSpecification;
import com.rabbitmq.stream.ConsumerBuilder;
public class OffsetConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
long offset = 10; // 指定偏移量
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.offset(OffsetSpecification.offset(offset)) // 从指定偏移量开始
.messageHandler((context, message) -> {
============
.offset(OffsetSpecification.first()) // 从第一个消息开始
.autoTrackingStrategy() /
-----这里指定了 .autoTrackingStrategy() /就不用指定.offset(OffsetSpecification.first())了吧?
确实,如果你使用 `.autoTrackingStrategy()`,那么你不需要再指定 `.offset(OffsetSpecification.first())`,因为自动跟踪策略会自动从最新的消息开始消费并持续监听新的消息。让我们分别看看两种方式的完整代码示例。
### 自动跟踪策略(Auto Tracking Strategy)
这种方式下,消费者会自动从最新的消息开始消费,并持续监听新的消息。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.ConsumerBuilder;
public class AutoTrackingConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.autoTrackingStrategy() // 启用自动跟踪策略
.messageHandler((context, message) -> {
String body = new String(message.getBodyAsBinary());
System.out.println("Received message: " + body);
})
.build();
// 消费者会一直运行,监听新的消息
System.out.println("Consumer is listening for new messages...");
}
}
```
### 指定偏移量(Offset)的消费方式
这种方式下,消费者会从指定的偏移量开始消费消息,并在消费完这些消息后停止。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.OffsetSpecification;
import com.rabbitmq.stream.ConsumerBuilder;
public class OffsetConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
long offset = 10; // 指定偏移量
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.offset(OffsetSpecification.offset(offset)) // 从指定偏移量开始
.messageHandler((context, message) -> {
String body = new String(message.getBodyAsBinary());
System.out.println("Received message: " + body);
============
那里之前为什么要写: .offset(OffsetSpecification.first()) // 从第一个消息开始
.autoTrackingStrategy() /
?
你说得对,如果你使用 `.autoTrackingStrategy()`,就不需要再指定 `.offset(OffsetSpecification.first())`。这是一个错误的示例。使用 `.autoTrackingStrategy()` 时,消费者会自动从最新的消息开始消费,并持续监听新的消息。
让我们修正并简化这两种方式的示例代码:
### 自动跟踪策略(Auto Tracking Strategy)
这种方式下,消费者会自动从最新的消息开始消费,并持续监听新的消息。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.ConsumerBuilder;
public class AutoTrackingConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.autoTrackingStrategy() // 启用自动跟踪策略
.messageHandler((context, message) -> {
String body = new String(message.getBodyAsBinary());
System.out.println("Received message: " + body);
})
.build();
// 消费者会一直运行,监听新的消息
System.out.println("Consumer is listening for new messages...");
}
}
```
### 指定偏移量(Offset)的消费方式
这种方式下,消费者会从指定的偏移量开始消费消息,并在消费完这些消息后停止。
#### 示例代码
```java
import com.rabbitmq.stream.Consumer;
import com.rabbitmq.stream.Environment;
import com.rabbitmq.stream.Message;
import com.rabbitmq.stream.OffsetSpecification;
import com.rabbitmq.stream.ConsumerBuilder;
public class OffsetConsumer {
public static void main(String[] args) {
Environment environment = Environment.builder().host("localhost").build();
String streamName = "test_stream";
long offset = 10; // 指定偏移量
// 创建消费者
Consumer consumer = environment.consumerBuilder()
.stream(streamName)
.offset(OffsetSpecification.offset(offset)) // 从指定偏移量开始
.messageHandler((context, message) -> {
String body = new String(message.getBodyAs
相关文章:

尚硅谷rabbitmq 2024 流式队列2024指定偏移量 第55节答疑
rabbitmq的stream: 4、对比 autoTrackingstrategy方式:始终监听Stream中的新消息(狗狗看家,忠于职守)指定偏移量方式:针对指定偏移量的消息消费之后就停止(狗狗叼飞盘,回来就完) 这两种分别怎么写?java 在 RabbitMQ 中,…...

NSSCTF-WEB-pklovecloud
目录 前言 正文 思路 尝试 结尾 前言 许久未见,甚是想念. 今天来解一道有意思的序列化题 正文 思路 <?php include flag.php; class pkshow {function echo_name(){return "Pk very safe^.^";} }class acp {protected $cinder;public $neutron;public $…...
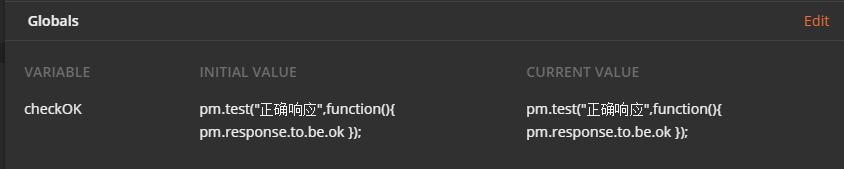
深入Postman- 自动化篇
前言 在前两篇博文《Postman使用 - 基础篇》《玩转Postman:进阶篇》中,我们介绍了 Postman 作为一款专业接口测试工具在接口测试中的主要用法以及它强大的变量、脚本功能,给测试工作人员完成接口的手工测试带来了极大的便利。其实在自动化测试上,Postman 也能进行良好的支…...

react-JSX
JSX理念 jsx在编译的时候会被babel编译为react.createELement方法 在使用jsx的文件中,需要引入react。import React from "react" jsx会被编译为React.createElement,所有jsx的运行结果都是react element React Component 在react中,常使用…...

深度对比:IPguard与Ping32在企业网络管理中的应用
随着网络安全形势日益严峻,企业在选择网络管理工具时需慎之又慎。IPguard与Ping32是目前市场上两款颇具代表性的产品,它们在功能、性能以及应用场景上各有优势。本文将对这两款产品进行深度对比,以帮助企业找到最合适的解决方案。 IPguard以其…...
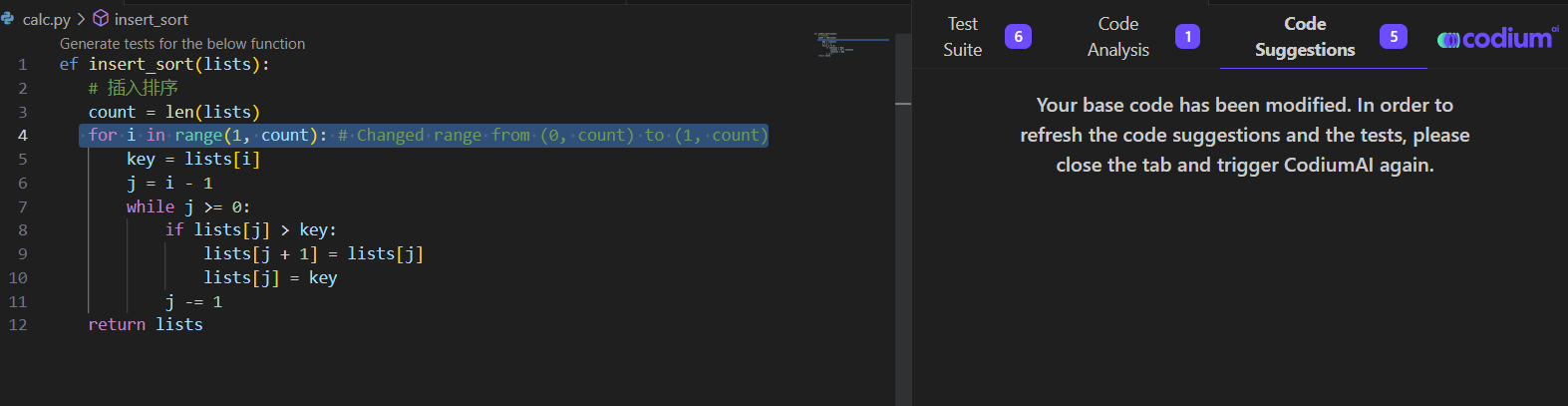
AI测试之 TestGPT
如今最火热的技术莫非OpenAI的ChatGPT莫属,AI技术也在很多方面得到广泛应用。今天我们要介绍的TestGPT就是一个软件测试领域中当红的应用。 TestGPT是什么? TestGPT是一家总部位于以色列特拉维夫的初创公司 CodiumAI Ltd.,发布的一款用于测…...

JavaEE-进程与线程
1.进程 1.1什么是进程 每个应⽤程序运⾏于现代操作系统之上时,操作系统会提供⼀种抽象,好像系统上只有这个程序在运 ⾏,所有的硬件资源都被这个程序在使⽤。这种假象是通过抽象了⼀个进程的概念来完成的,进程可 以说是计算机科学…...
-equals与hashcode方法)
JAVA软开-面试经典问题(6)-equals与hashcode方法
1.equals方法 1.Object类中的equals方法比较的是两个对象的地址(底层原理是 比较的,即比较的是对象的地址) return (this obj);2.基本数据类型的包装类和String类都重写了equals方法。 基本数据类型:比较的是数值的是否相等 …...

计算机网络(以Linux讲解)
计算机网络 网络协议初识协议分层OSI七层模型TCP/IP五层模型--初识 网络中的地址管理IP地址MAC地址 网络传输基本流程网络编程套接字预备知识网络字节序socket编程UDP socketTCP socket地址转换函数Jsoncpp 进程间关系与守护进程进程组会话控制终端作业控制守护进程 网络命令TC…...

计算机网络基本架构知识点
1. 网络体系结构模型: - OSI 七层模型: - 物理层:是网络通信的基础层,负责在物理介质上传输比特流。该层定义了物理连接的标准,如电缆的类型、接口的形状、插头的规格等,以及信号的传输方式,包括…...
GES DISC 的 ATMOS L2 潜在温度网格上的痕量气体,固定场格式 V3 (ATMOSL2TF)
ATMOS L2 Trace Gases on Potential Temperature Grid, Fixed Field Format V3 (ATMOSL2TF) at GES DISC 简介 GES DISC 的 ATMOS L2 潜在温度网格上的痕量气体,固定场格式 V3 (ATMOSL2TF) 这是版本3的气溶胶痕量分子光谱(ATMOS)第二级产品…...

MLCC贴片电容不同材质区别:【及电容工作原理】
贴片电容的材质常规有:NPO(COG),X7R,X5R,Y5V 等,主要区别是它们的填充介质不同。在相同的体积下由于填充介质不同所组成的电容器的容量就不同,随之带来的电容器的介质损耗、容量稳定…...

Word粘贴时出现“文件未找到:MathPage.WLL”的解决方案
解决方案 一、首先确定自己电脑的位数(这里默认大家的电脑都是64位)二、右击MathType桌面图标,点击“打开文件所在位置”,然后分别找到MathPage.WLL三、把这个文件复制到该目录下:C:\Program Files\Microsoft Office\r…...

前端开发笔记--html 黑马程序员1
文章目录 前端开发工具--VsCode前端开发基础语法VsCode优秀插件Chinese --中文插件Auto Rename Tag --自动重命名插件open in browserOpen in Default BrowserOpen in Other Browser Live Server -- 实时预览 前端开发工具–VsCode 轻量级与快速启动 快速加载:VSCo…...
:华星光电)
ARM/Linux嵌入式面经(四四):华星光电
文章目录 1、自我介绍2、介绍一下你最得意的一个项目3、这个项目里面都用到了什么模块,什么型号,有什么作用4、移植操作系统的过程中,流程是什么,需要注意什么移植操作系统的流程需要注意的事项面试官可能的追问及回答5、你用的传感器挺多的,怎么保证传感器传输的稳定性,…...

帮助,有奖提问
<?php $u $_GET[“user”]; //变量获取 $v $_GET[“variable”]; //$v看flag,绕过正则 $flag‘flag{}; if(isset($u)&&(file_get_contents($u,‘r’)“im admin”)){//猜测data://协议 //检查u指向 echo “hello admin!<br>”; if(preg_…...

Java编辑工具IDEA
哪个编程工具让你的工作效率翻倍? 在日益繁忙的工作环境中,选择合适的编程工具已成为提升开发者工作效率的关键。不同的工具能够帮助我们简化代码编写、自动化任务、提升调试速度,甚至让团队协作更加顺畅。那么,哪款编程工具让你…...

闲谈Promise
预备知识 回调函数:当一个函数作为参数传入另一个函数中,并且它不会立刻执行,当满足一定条件之后,才会执行,这种函数称为回调函数。比如:定时器。异步任务:与之对应的概念是同步任务࿰…...

【C++堆(优先队列)】1882. 使用服务器处理任务|1979
本文涉及知识点 C堆(优先队列) LeetCode1882. 使用服务器处理任务 给你两个 下标从 0 开始 的整数数组 servers 和 tasks ,长度分别为 n 和 m 。servers[i] 是第 i 台服务器的 权重 ,而 tasks[j] 是处理…...
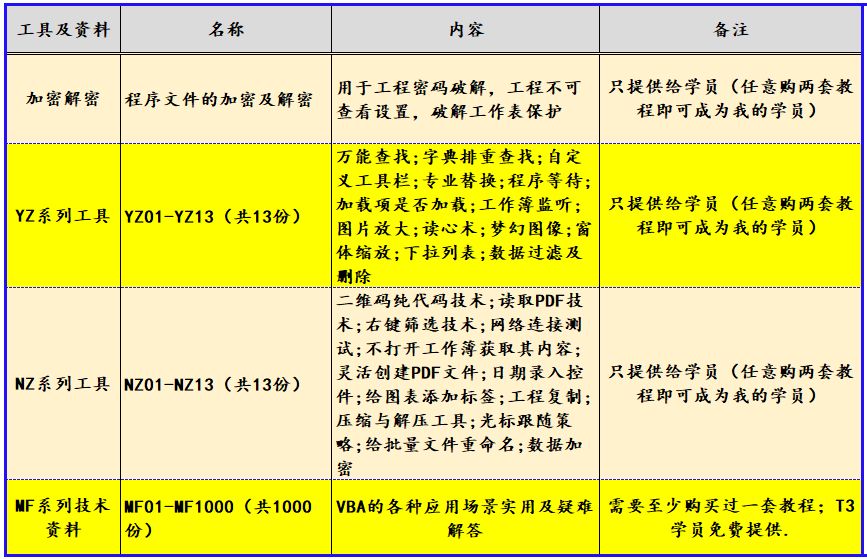
VBA高级应用30例应用3Excel中的ListObject对象:选择表的一部分
《VBA高级应用30例》(版权10178985),是我推出的第十套教程,教程是专门针对高级学员在学习VBA过程中提高路途上的案例展开,这套教程案例与理论结合,紧贴“实战”,并做“战术总结”,以…...

STM32CubeMX外设配置实战——以F103C8T6的CAN与DMA为例
1. STM32CubeMX与F103C8T6开发基础 STM32CubeMX是ST官方推出的图形化配置工具,它能极大简化STM32系列MCU的外设初始化流程。对于刚接触STM32开发的工程师来说,这个工具就像"乐高积木说明书"——通过可视化操作就能完成80%的底层配置工作。我最…...

Touchpoint:命令行工具集中管理工作上下文,提升开发效率
1. 项目概述:一个被低估的开发者效率工具如果你和我一样,日常开发工作需要在多个代码仓库、项目管理工具(如Jira、Linear)、文档平台(如Confluence、Notion)和沟通软件(如Slack)之间…...

3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA
3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 还在为…...

δ - mem:提升大型语言模型内存效率,得分最高可达 1.31 倍!
快速通道可了解 arXiv 成为独立非营利组织的情况,也能直达康奈尔大学官网。同时,还能通过链接进行捐赠,支持 arXiv 的发展。搜索与导航提供了多种搜索途径,可在所有字段(标题、作者、摘要等)进行搜索。还有…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

多智能体的协作成本:沟通开销、上下文膨胀与优化手段
多智能体的协作成本:沟通开销、上下文膨胀与优化手段 1. 标题 (Title) 多智能体系统的协作困境:解析沟通开销与上下文膨胀 从理论到实践:优化多智能体协作成本的完整指南 协作的代价:多智能体系统中的沟通、上下文与优化策略 打破协作壁垒:如何有效降低多智能体系统的运行…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...

AI原生产品管理:多智能体协作如何重塑产品开发工作流
1. 项目概述:当AI成为你的产品经理最近在GitHub上看到一个挺有意思的项目,叫NathanJCW/ai-native-pm-cortex。光看名字,你大概能猜到它想做什么——“AI原生的产品经理大脑”。这可不是一个简单的聊天机器人插件,它试图构建一个完…...

Kubernetes原生自动化部署工具Keel:实现容器镜像自动更新的最后一公里
1. 项目概述:什么是Keel,以及它解决了什么问题如果你和我一样,在团队里负责过一段时间的应用部署和更新,那你一定对“发布日”的紧张感深有体会。开发那边代码一提交,这边就得开始手动拉取镜像、更新Kubernetes的Deplo…...

工作流编排核心原理与实践:从概念到MiniFlow系统实现
1. 项目概述:从代码仓库到工作流编排的实践最近在梳理团队内部的一些自动化流程,发现很多脚本和任务散落在各个角落,执行依赖混乱,出了问题排查起来像大海捞针。正好看到GitHub上有个叫dnh33/workflow-orchestration的项目&#x…...