使用PyTorch从0实现Fashion-MNIST数据集分类
完整代码:
from d2l import torch as d2l
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
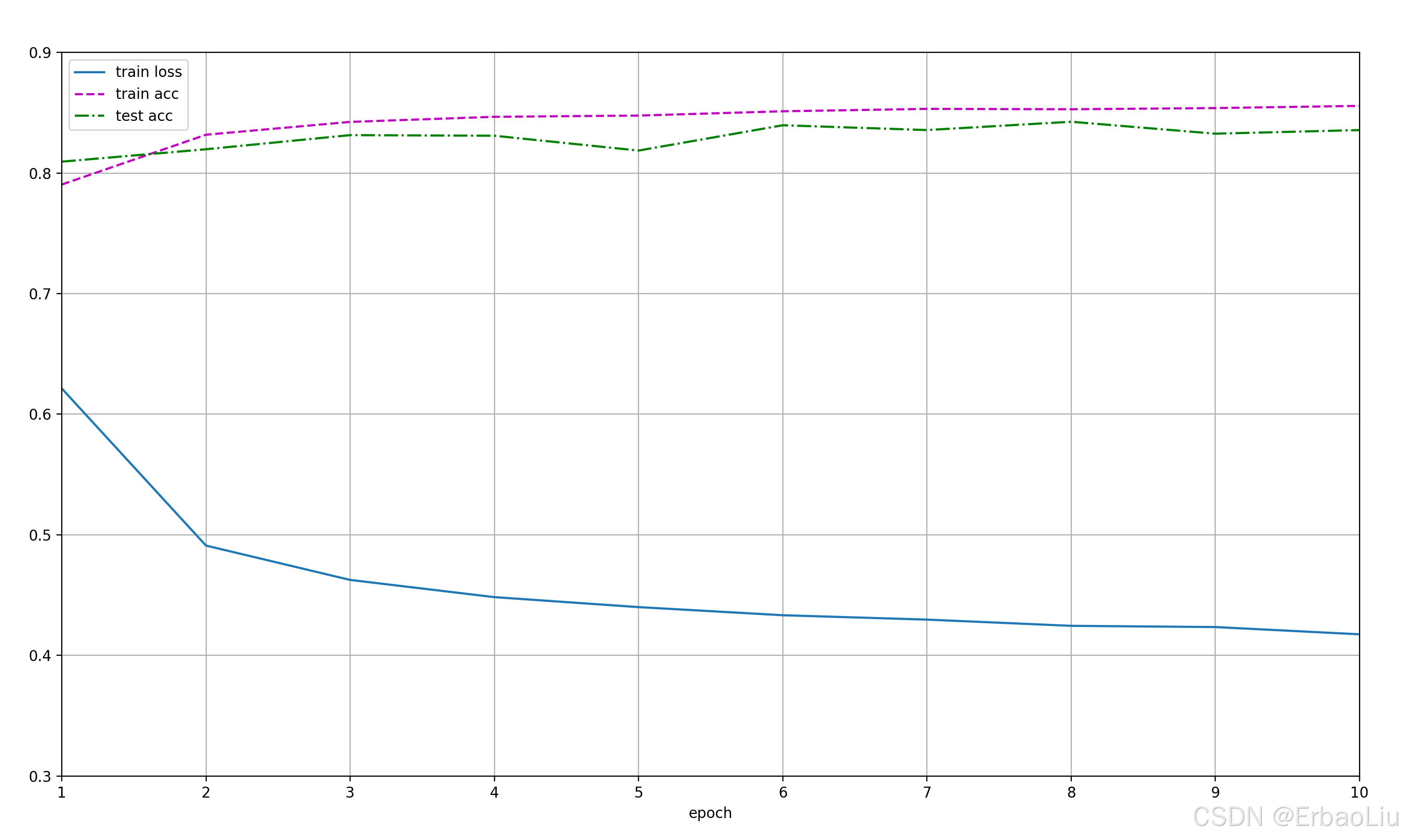
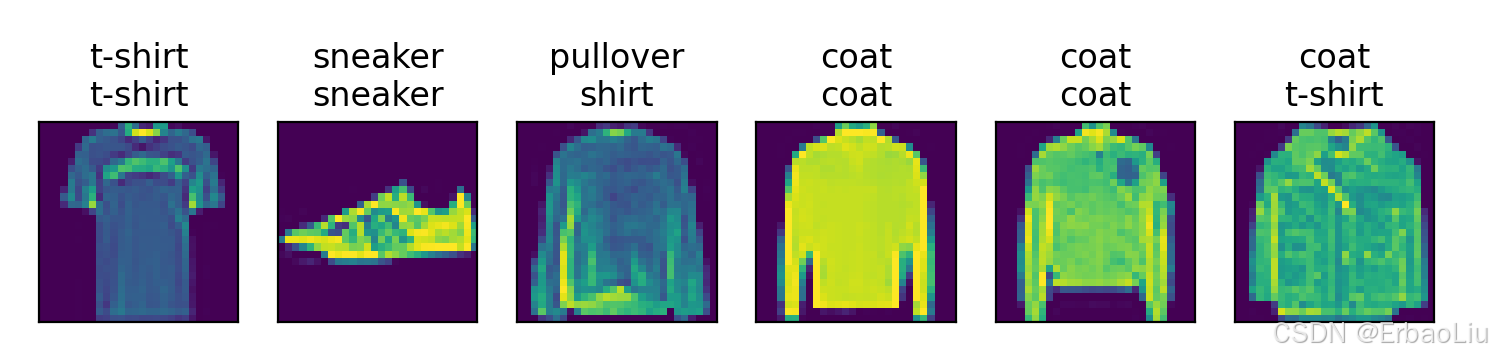
from IPython import displaydef get_fashion_mnist_labels(labels): # @save"""返回Fashion-MNIST数据集的文本标签.遍历labels,取出i,i是一个数字文本,通过int(i)转换成数字,然后作为索引,从text_labels获取类别名称.:param labels: 文本数字标签,labels中的数字是字符串,需要int()函数转换为整型数字.:return: 类别名称.Example:输入labels=['3','5']返回 ['dress','sandal']"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def show_image_gray(mnist_train):figure = plt.figure(figsize=(8, 8))cols, rows = 3, 3for i in range(1, cols * rows + 1):sample_idx = torch.randint(len(mnist_train), size=(1,)).item()img, label = mnist_train[sample_idx]figure.add_subplot(rows, cols, i)plt.title(get_fashion_mnist_labels([label]))plt.axis("off")plt.imshow(img.squeeze(), cmap="gray")# plt.show()def show_images_color(imgs, num_rows, num_cols, titles=None, scale=1.5): # @save"""绘制图像列表.:param imgs: 图像.:param num_rows: 行数.:param num_cols: 列数.:param titles: 标题.:param scale: 缩放比例.:return:"""figsize = (num_cols * scale, num_rows * scale)_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 图片张量ax.imshow(img.numpy())else:# PIL图片ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])# plt.show()def softmax(X):""":param X::return:Example:X=[[0, 1, 2][3, 4, 5]]X_exp= [[e^0, e^1, e^2][e^3, e^4, e^5]]partition=[[e^0+e^1+e^2][e^3+e^4+e^5]]X_exp / partition中对partition进行广播(按列复制)partition=[[e^0+e^1+e^2, e^0+e^1+e^2, e^0+e^1+e^2][e^3+e^4+e^5, e^3+e^4+e^5, e^3+e^4+e^5]]X_exp / partition = [[e^0/(e^0+e^1+e^2), e^1/(e^0+e^1+e^2), e^2/(e^0+e^1+e^2)][e^3/(e^3+e^4+e^5), e^4/(e^3+e^4+e^5), e^5/(e^3+e^4+e^5)]]"""X_exp = torch.exp(X) # 矩阵的每个元素计算指数.partition = X_exp.sum(1, keepdim=True) # 按行求和,保持张量阶数.return X_exp / partition # 这里应用了广播机制 partition按列复制.def accuracy_num(y_hat, y): # @save"""计算预测正确的数量:param y_hat: 预测值.:param y: 标签值.:return: 预测正确的个数.Example:y_hat = [[0.1, 0.2, 0.7][0.4, 0.3, 0.3]]y = [[2][1]]计算每行最大概率对应的索引,例如第一行最大概率为0.7,对应的索引为2,最终得到:y_hat = [[2][0]]然后将类型转换成y的数据类型,将预测值与y标签值判断是否相等,相等为True,否则为False,例如:cmp = [[True][False]]最后统计True的个数,返回1."""if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = (y_hat.type(y.dtype) == y)return float(cmp.type(y.dtype).sum())def net(X):"""神经网络:param X: 小批量输入数据,是一个张量,例如X张量维度[64, 1, 28, 28].第一个维度表示批量大小batch_size,第二个维度表示通道数,第三个维度表示图像高度,第四个维度表示图像宽度.:return: 输出.Example:神经网络线性变换:XW+b,例如:batch_size = 2神经网络结构: 输出层(2个神经元): * *输入层(3个神经元):+ + +X= [[0, 1, 2][3, 4, 5]]W = [[1, 2][2, 0][1, 1]]b = [1, 2]XW = [[4, 2][16 11]]XW + b中b首先使用广播机制,按行复制得到b = [[1, 2][1, 2]]最终得到XW + b = [[5, 4][17, 13]]"""# X张量维度[64, 1, 28, 28],W张量维度[784,10],W.shape[0]=784,# reshape表示将X变成两个维度,第二个维度为784,第一个维度自动计算,也就是64*1*28*28/784=64,# 所以reshape后X维度为[64,784],X = X.reshape((-1, W.shape[0]))X = torch.matmul(X, W) + breturn softmax(X)def evaluate_accuracy(net, data_iter): # @save"""计算在指定数据集上模型的精度.:param net: 神经网络对象.:param data_iter: 可迭代数据集.:return: 神经网络模型在数据集上的预测准确率.Example:"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式# 初始化累加器.accumulator = Accumulator(2) # [正确预测数,预测总数]with torch.no_grad(): # 这里不需要计算梯度,关闭梯度计算.for X, y in data_iter: # 变量数据集. X的维度[64,1,28,28], y的维度[64,1]y_hat = net(X) # 数据集输入神经网络,输出预测值y_hat.acc_num = accuracy_num(y_hat, y) # 预测正确的个数.total = y.numel() # 总数.accumulator.add(acc_num, total) # 对每批数据集的正确个数,总数分别进行累加.return accumulator[0] / accumulator[1]class Accumulator: # @save"""累加器:在n个变量上累加"""def __init__(self, n):"""初始化累加器.:param n: 累加器中的数据个数.Exapmle:n = 3, data = [0.0, 0.0, 0.0]"""self.data = [0.0] * n # 变成n个0.0的列表.def add(self, *args):"""累加器对输入数据进行累加操作.:param args::return:Example:如果data=[0.0,0.0],args=[2,64],zip对两个列表的对应位置压缩变成元组列表:[(0.0,2),(0.0,64)],遍历元组列表,每个元组中两个元素求和得到data=[2.0,64.0]."""self.data = [a + float(s) for a, s in zip(self.data, args)]def reset(self):"""重置累加器.:return: 重置后的累加器.Example:data = [1, 4, 5],重置后data = [0.0, 0.0, 0.0]"""self.data = [0.0] * len(self.data)def __getitem__(self, idx):"""根据索引获取累加器对应索引上的值.:param idx: 索引:return: 数据索引上的值.Example:data = [1, 4, 5], idx=1data[idx] = 4."""return self.data[idx]def cross_entropy(y_hat, y):"""计算每个样本的交叉熵损失值函数,存储在一个列表中.后面在计算交叉熵总损失 = 所有样本交叉熵损失值的和.:param y_hat: 预测值,是一个(batch_size,label_num)的二阶张量,第一个维度是批次数,第二个维度是类别数,例如(64,10).:param y: 标签值,是一个(batch_size)的一阶张量.:return: 交叉熵损失值.Example:假设批次数batch_size=2, 类别总数label_num=3.y_hat = [[0.1, 0.3, 0.6][0.3, 0.5, 0.2]]y_hat的每一行表示一个输入样本,输出以后,对应每个类别的概率.y = [[0][2]]y_hat[range(len(y_hat)), y]表示从y_hat中按照行索引和列索引取值.行索引range(len(y_hat)) = [0,1], 列索引 y=[0,2] ,按照行列索引组成(0,0)和(1,2)。从y_hat中取出位置为(0,0)和(1,2)的值,得到prob = [0.1,0.2],最后对prob的每个值取对数的负数,得到[-log0.1, -log0.2],它的每个值表示每个样本的损失值.例如第一个样本的损失值为-log0.1,所有样本的总损失值可以如下计算:-log0.1-log0.2"""prob = y_hat[range(len(y_hat)), y]return - torch.log(prob)def updater(batch_size, lr=0.1):"""更新参数.with torch.no_grad()是一个用于禁用梯度的上下文管理器。禁用梯度计算对于推理是很有用的,当我们确定不会调用Tensor.backward()时,它将减少计算的内存消耗。因为在此模式下,即使输入为 requires_grad=True,每次计算的结果也将具有requires_grad=False。总的来说, with torch.no_grad() 可以理解为,在管理器外产生的与原参数有关联的参数requires_grad属性都默认为True,而在该管理器内新产生的参数的requires_grad属性都将置为False。:param batch_size: 批次大小:param lr: 学习率,是一个超参数,默认值为0.1.Example:假设损失函数loss(W,b)=2w_1^2+3w_2^3+b,对W的梯度向量为(4w_1,9w_2),假设W的初始值为 W = [0.1,0.3],lr = 0.1,batch_size = 2,第一次更新:W = W - (lr / batch_size) * gradW = [0.1,0.3]-(0.1 / 2) * [0.4, 2.7] = [0.1,0.3] - [0.02, 0.135] = [0.08, 0.865]b同理."""with torch.no_grad():for param in [W, b]:param -= lr * param.grad / batch_sizeparam.grad.zero_() # 梯度清零.def train_one_epoch(net, train_iter, loss, updater): # @save"""一轮训练.:param net: 神经网路模型.:param train_iter: 训练数据集.:param loss: 损失函数.:param updater: 更新器.:return:"""# 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数accumulator = Accumulator(3) # [0.0, 0.0, 0.0],第一个表示总损失值,第二个表示预测准确个数,第三个表示样本总数.for X, y in train_iter: # 遍历数据集.y_hat = net(X) # 正向传播,计算最终输出.loss_value = loss(y_hat, y) # 计算损失.if isinstance(updater, torch.optim.Optimizer):# 使用PyTorch内置的优化器和损失函数updater.zero_grad()loss_value.mean().backward()updater.step()else:# 使用定制的优化器和损失函数loss_value.sum().backward() # loss_value.sum() 计算总损失,然后反向传播,计算梯度.updater(X.shape[0]) # 更新参数.# 对每批数据集的损失值、预测准确个数、样本数进行累加.accumulator.add(float(loss_value.sum()), accuracy_num(y_hat, y), y.numel())# 返回训练损失和训练精度return accumulator[0] / accumulator[2], accumulator[1] / accumulator[2]class Animator: # @save"""在动画中绘制数据"""def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []# d2l.use_svg_display()self.fig, self.axes = plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使用lambda函数捕获参数self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)display.clear_output(wait=True)def train(net, train_iter, test_iter, loss, num_epochs, updater): # @save"""训练神经网络模型.:param net: 神经网络.:param train_iter: 训练数据集.:param test_iter: 测试数据集.:param loss: 损失.:param num_epochs: 训练轮次.:param updater: 参数更新器.:return:"""animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])train_metrics = 0.0, 0test_acc = 0for epoch in range(num_epochs): # 遍历轮次.train_metrics = train_one_epoch(net, train_iter, loss, updater) # 训练一轮,并返回平均损失和准确率.test_acc = evaluate_accuracy(net, test_iter) # 使用训练的模型测量在测试集上的准确度.animator.add(epoch + 1, train_metrics + (test_acc,))plt.show()train_loss, train_acc = train_metrics# 断言:如果不满足断言,程序中断.assert train_loss < 0.5, train_loss # 断言总损失需要小于0.5.assert 1 >= train_acc > 0.7, train_acc # 断案训练集的准确率需要在(0.7,1]之间.assert 1 >= test_acc > 0.7, test_acc # 断案训练集的准确率需要在(0.7,1]之间.def predict(net, test_iter, n=6): # @save"""预测标签(定义见第3章)"""for X, y in test_iter:breaktrues = get_fashion_mnist_labels(y)preds = get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true + '\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])plt.show()if __name__ == '__main__':torch.manual_seed(42)trans = transforms.ToTensor()# 将数据集下载到data目录mnist_train = datasets.FashionMNIST(root="data",train=True,download=True,transform=trans)mnist_test = datasets.FashionMNIST(root="data",train=False,download=True,transform=trans)train_size, test_size = len(mnist_train), len(mnist_test)print('train_size=', train_size, 'test_size=', test_size)# mnist_train[0] 表示第一行训练数据,包含图像和标签,是两者组成的一个二元组.# mnist_train[0][0]表示第一个图像,是一个三阶张量,第一阶表示通道数,第二阶表示图像高度,第三阶表示图像宽度,(1,28,28)。# mnist_train[0][1]表示第一个图像的标签.print('mnist_train.shape=', mnist_train[0][0].shape)print('mnist_train.label=', mnist_train[0][1])# 可视化图像.show_image_gray(mnist_train)batch_size = 64dataloader_workers = 4# 如果代码不写在main中,num_workers只能设置为0,否则报错。与Windows系统有关。# https://blog.csdn.net/weixin_45953673/article/details/132417457train_iter = DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=dataloader_workers)test_iter = DataLoader(mnist_test, batch_size=batch_size, shuffle=True, num_workers=dataloader_workers)# iter()将DataLoader返回转换成一个可迭代对象,类似可迭代对象list.# next()对可迭代对象进行迭代,类似遍历list.train_features, train_labels = next(iter(train_iter))# 四阶张量,torch.Size([64, 1, 28, 28]).print('train_features.shape=', train_features.shape)show_images_color(imgs=train_features.reshape(batch_size, 28, 28),num_rows=2, num_cols=9,titles=get_fashion_mnist_labels(train_labels))# 初始化权重.num_inputs = 784num_outputs = 10W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)b = torch.zeros(num_outputs, requires_grad=True)accuracy = evaluate_accuracy(net, test_iter)print('accuracy=', accuracy)num_epochs = 10train(net, train_iter, test_iter, cross_entropy, num_epochs, updater)predict(net, test_iter)程序输出结果:
train_size= 60000 test_size= 10000
mnist_train.shape= torch.Size([1, 28, 28])
mnist_train.label= 9
train_features.shape= torch.Size([64, 1, 28, 28])
accuracy= 0.0484
Figure(350x250)
Figure(350x250)
Figure(350x250)
Figure(350x250)
Figure(350x250)
Figure(350x250)
Figure(350x250)
Figure(350x250)
Figure(350x250)
Figure(350x250)

相关文章:
使用PyTorch从0实现Fashion-MNIST数据集分类
完整代码: from d2l import torch as d2l import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import matplotlib.pyplot as plt from IPython import displaydef get_fashion_mnist_la…...

Java数组的值拷贝和地址拷贝
在Java中,数组的值拷贝和地址拷贝是两种不同的操作。 值拷贝是指将一个数组的值复制到另一个新的数组中。这意味着新数组和原数组独立存在,修改其中一个数组不会影响另一个数组。Java中的数组是对象,所以通过值拷贝操作实际上是复制了数组对…...
 以及 日历)
类与对象 中(剩余部分) 以及 日历
运算符重载 • 当运算符被⽤于类类型的对象时,C语⾔允许我们通过运算符重载的形式指定新的含义。C规定类类型对象使⽤运算符时,必须转换成调⽤对应运算符重载,若没有对应的运算符重载,则会编译报错。 • 运算符重载是具有特名字的…...
iOS 14 自定义画中画悬浮窗 Custom AVPictureInPictureController 实现方案
iOS 14,基于 AVPictureInPictureController,实现自定义画中画,涵盖所有功能与难点。 市面上的各种悬浮钟和提词器的原理都是基于此。 Demo源码在文末。 使用 iOS 画中画的要求: 真机,不能使用模拟器;iO…...

【C#生态园】完整解读C#网络通信库:从基础到实战应用
探索C#网络通信库:功能、用途和最佳实践 前言 随着互联网的快速发展,网络通信在现代软件开发中扮演着至关重要的角色。C#作为一种流行的编程语言,拥有多个优秀的网络通信库,为开发人员提供了丰富的选择。本文将深入探讨几种常用…...

js面试题---事件委托是什么
事件委托是JavaScript中的一种事件处理模式,通过将事件处理程序绑定到父元素,而不是直接绑定到每个子元素,从而优化事件管理和提高性能。 1 工作原理 事件冒泡:当一个事件在某个元素上发生时,它会从该元素向上冒泡到…...

谷歌浏览器 文件下载提示网络错误
情况描述: 谷歌版本:129.0.6668.90 (正式版本) (64 位) (cohort: Control)其他浏览器,比如火狐没有问题,但是谷歌会下载失败,故推断为谷歌浏览器导致的问题小文件比如1、2M会成功,大…...

【记录】PPT|PPT 箭头相交怎么跨过
众所周知,在PPT中实现“跨线”效果并非直接可行,这一功能仅存在于Visio中。然而,通过一些巧妙的方法,我们可以在PPT中模拟出类似的效果。怎么在PPT中画交叉但不重叠的线-百度经验中介绍了一种方法,而本文将介绍一种改进…...

Linux中如何修改root密码
在 Linux 中,修改 root 用户密码可以通过以下步骤进行。你需要具有超级用户权限才能执行这些操作。 方法一:使用 passwd 命令修改 root 密码 使用具有超级用户权限的账户登录 如果你已经以 root 身份登录,或者你当前账户具备超级用户权限&am…...

中间件:SpringBoot集成Redis
一、Redis简介 Redis是一个开源的、基于内存的数据结构存储系统,它可以用作数据库、缓存和消息中间件。Redis支持多种类型的数据结构,如字符串(strings)、哈希(hashes)、列表(lists)…...

数据中心建设方案,大数据平台建设,大数据信息安全管理(各类资料原件)
第一章 解决方案 1.1 建设需求 1.2 建设思路 1.3 总体方案 信息安全系统整体部署架构图 1.3.1 IP准入控制系统 1.3.2 防泄密技术的选择 1.3.3 主机账号生命周期管理系统 1.3.4 数据库账号生命周期管理系统 1.3.5 双因素认证系统 1.3.6 数据库审计系统 1.3.7 数据脱敏…...

TDD(测试驱动开发)是否已死?
Rails 大神、创始人 David Heinemeier Hansson 曾发文抨击TDD。 TDD is dead. Long live testing. (DHH) 此后, Kent Beck、Martin Fowler、David Hansson 三人就这个观点还举行了系列对话(辩论) Is TDD Dead? 笔者作为一个多年在软件测试领域摸索的人&…...

Debezium系列之:实时从TDengine数据库采集数据到Kafka Topic
Debezium系列之:实时从TDengine数据库采集数据到Kafka Topic 一、认识TDengine二、TDengine Kafka Connector三、什么是 Kafka Connect?四、前置条件五、安装 TDengine Connector 插件六、启动 Kafka七、验证 kafka Connect 是否启动成功八、TDengine Source Connector 的使用…...
顺序表)
数据结构(一)顺序表
顺序表的概念及结构 线性表 线性表是具有相同特征的数据结构的集合 物理结构 不一定连续 逻辑结构 连续 顺序表 顺序表是线性表的一种,顺序表的底层是数组 物理结构 连续 逻辑结构 连续 顺序表分类 静态顺序表 struct SeqList {int a…...
)
如何在 Jupyter Notebook 执行和学习 SQL 语句(中)
1. 基础SQL操作 创建数据库和表,插入数据: import sqlite3# 创建SQLite数据库并连接 conn sqlite3.connect(example.db) cursor conn.cursor()# 创建用户表 cursor.execute(CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY AUTOINCREMENT…...

AutosarMCAL开发——基于EB Wdg驱动
目录 一、Wdg原理以及作用1.看门狗类型2.看门狗功能特点3.看门狗工作模式4.看门狗超时响应5.看门狗寄存器 二、WDG模块EB配置(TC3X系列MCU)1.WDG通用配置:2.WDG设置:3.时钟资源分配4.配置STM IRQ中断5.配置触发执行动作࿱…...

Linux(1. 基本操作_命令)
目录 关于超级用户root: root用户可以做什么? 避免灾难: 格式约定: 浏览硬盘: 命令行补全和通配符: 命令行补全: 通配符: 常用基本命令: 查看目录和文件ÿ…...

难点:Linux 死机定位(进程虚拟地址空间耗尽)
死机定位(进程虚拟地址空间耗尽) 一、死机现象 内存富裕,但内存申请失败。 死机时打印: 怀疑是: 1、内存碎片原因导致。 2、进程虚拟地址空间耗尽导致。 3、进程资源限制导致。 二、内存碎片分析 1、理论知识:如何分析内存碎片化情况 使用 /proc/buddyinfo: /proc/…...

小米路由器刷机istoreOS,愉快上网
istoreOS与openwrt openwrt是一个开源的路由器系统,市场上所有小米路由器的内部系统都是基于openwrt进行二次开发形成的,做了硬件适配和功能上的阉割,不太好用。 istoreos是小宝团队基于openwrt制作的一个发行版,更适合中国宝宝体质。页面简约华丽,完全兼容开源openwrt的…...
)
微信小程序 - 01 - 一些补充和注意点(补充ing...)
目录 一、节流二、在一个发请求的函数中,只有发生下拉动作,才执行关闭下拉代码 最近在学微信小程序,把学习过程中的一些补充和注意点总结一下,内容会比较简单,因为只涉及基础知识,供个人参考 一、节流 情…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

如何免费高效优化电脑性能:UXTU终极调优指南
如何免费高效优化电脑性能:UXTU终极调优指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility Universal x86 Tuning…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

Go语言实现Hermes引擎:高性能JavaScript字节码虚拟机解析与实践
1. 项目概述:一个Go语言实现的Hermes引擎最近在折腾一些需要高性能模板渲染的后端服务,偶然间在GitHub上发现了LAI-755/hermes-go这个项目。简单来说,这是一个用纯Go语言实现的Hermes引擎。如果你对前端生态熟悉,可能听说过Hermes…...

CI/CD安全最佳实践:保护软件交付流程
CI/CD安全最佳实践:保护软件交付流程 一、CI/CD安全最佳实践概述 1.1 CI/CD安全最佳实践的定义 CI/CD安全最佳实践是指在持续集成和持续部署流程中实施的安全策略和措施。它涵盖代码提交、构建、测试、部署等各个阶段的安全防护。 1.2 CI/CD安全最佳实践的价值 安全…...