【AI论文精读14】RAG论文综述2(微软亚研院 2409)P6(完)-隐含推理查询L4
AI知识点总结:【AI知识点】
AI论文精读、项目、思考:【AI修炼之路】
P1,P2,P3,P4,P5
六、隐藏推理查询(L4)
ps:P2有四种查询(L1,L2,L3,L4)的举例对比
6.1 概述
隐含推理查询(Hidden rationale queries)是所有查询中最具挑战性的一类问题。与可解释推理查询(interpretable rationale queries)不同,后者提供了明确的推理指导来响应查询,而隐含推理查询涉及的是特定领域的推理方法,这些方法通常没有明确说明,且数量众多,难以在典型的上下文窗口内穷尽。这类推理通常包含大量难以在单一上下文中全面探讨的隐性知识,并且往往缺乏清晰的指引,代表了一种隐含在数据中的领域专长。这样的数据可能包括但不限于:
-
领域内数据(In-domain Data):隐含推理查询可能利用来自同一领域的数据,如历史问答记录或人工生成的数据。这类领域内数据本身包含了解决当前查询所需的推理技能或方法。例如,在Python编程难题的背景下,解决历史问题的方案通常包含经典算法和问题解决策略,这些方案可以帮助解决当前问题。
-
初步知识(Preliminary Knowledge):另一种形式的隐含推理是广泛分布的知识库,这些知识库在不同场景中的应用各有不同。这种初步知识可能构成一个完整的公理系统,比如所有的本地法律法规,它们是法律判决的基础。它也可能包括简化推理过程的已证明的中间结论,如数学证明中的推论。在使用外部数据解决现实问题时,这种先验知识还可能源于人类经验和经验总结的复杂积累。
因此,处理隐含推理查询需要复杂的分析技术,以解码并利用分散的数据源中隐含的智慧。这为RAG系统在有效解释和应用这些复杂且隐含的信息带来了巨大的挑战。
示例:
- 经济状况将如何影响公司的未来发展?(给定一系列财务报告,需要经济和财务推理)。
- 如何用数字5、5、5和1凑出24点?(给定一系列24点游戏示例及对应答案)。
- 阿富汗是否允许父母将其国籍授予在国外出生的子女?(给定GLOBALCIT国籍法律数据集【136】)。
6.2 挑战与解决方案
在构建数据增强的LLM应用时,隐含推理查询(Hidden rationale queries)面临着诸多挑战,主要困难表现在以下几个方面:
1. 逻辑检索(Logical retrieval):
对于涉及隐含推理的问题,外部数据的有用性不仅依赖于实体级别的或语义上的相似性,更关键的是逻辑上的一致性或主题的对齐。传统的检索方法通常难以捕捉到查询的真正目标,或者无法识别在逻辑上相关的文本段落。因此,需要开发更复杂的检索算法,这些算法不仅能解析和识别潜在的逻辑结构,还能突破单纯依赖文本表面相似性的局限。
- 例如,传统的语义检索可能会返回包含相同关键词的片段,但未必能找到逻辑相关的内容。假如一个查询涉及法律案例分析,系统不仅需要检索包含相同法律条款的文档,还需要找到逻辑上类似的判例或相关的法律解释。
2. 数据不足(Data insufficiency):
从根本上说,外部数据可能并不直接包含解决当前查询的所有必要信息。相关信息通常散布在不同的知识领域中,或者通过示例间接体现。这种间接呈现要求LLM具备强大的数据解释和综合能力,能够从分散的或间接相关的数据源中推导出连贯的答案。这表明LLM不仅需要具备基础的检索能力,还必须能够在不同数据片段之间建立关联,提供合理的推理。
- 例如,在预测公司未来发展的经济分析场景中,可能无法通过单一的财务报告直接回答问题,而需要LLM结合多个报告中的经济趋势、市场动态和行业信息,进行合理的综合推断。
这些挑战表明,处理隐含推理查询需要LLM具备更复杂的数据整合和推理能力。这不仅包括基础的信息检索,还涉及更高级的逻辑推理和数据解释能力,以便有效应对复杂问题中的隐含逻辑和知识结构。
6.3 离线学习(Offline Learning)
为了解决隐含推理查询(Hidden rationale queries),一种常见的方法是通过离线方式从数据集中识别和提取规则和指导方针,然后检索相关项目。在推理生成方面,一些研究,如 STaR【137】和 LXS【138】,使用了LLM进行推理生成。STaR采用一种迭代的小样本到大样本的方法,逐步扩展数据集进行生成,而LXS引入了双角色的解释提取过程,其中一个学习者模型生成解释,另一个评论者模型对其进行验证和评估。
GL【139】通过上下文学习(in-context learning)识别错误,并将这些错误概括为未来任务的指导方针。LEAP【140】通过生成错误、低层次的原则和高层次的原则,将这些原则整合到提示中以进行最终推理。RICP【141】使用训练数据中的错误生成高级推理和具体的见解,然后利用层次聚类对错误模式进行分组,生成任务级和问题级的原则,并将其组合并检索以获得问题级别的洞见。Buffer-of-Thought【142】使用一个问题提炼器在许多推理任务中提炼出一个元缓冲区。
一些集成方法,例如 MedPrompt【143】,结合了GPT-4生成的链式思维进行训练示例,并通过自验证与KNN检索上下文学习相结合。Agent Hospital【144】通过反思生成推理,并在生成的数据上利用记录检索和经验检索。
尽管这些概念有许多不同的名称——如指导方针、原则、经验和思维模板——其核心思想是提取通用且有用的推理,以增强推理查询。这些推理可能来自自生成的链式思维(如MedPrompt和Buffer-of-Thought),来自训练集中的错误(如GL、RICP、Agent Hospital),或故意生成的错误(如LEAP)。此外,一些原则适用于所有任务(如Agent Hospital、RICP),而另一些则是为特定问题动态检索的(如MedPrompt、Buffer-of-Thought)。这些研究表明,从案例中学习,积累经验作为推理依据,有助于在各种推理任务中提高表现。
6.4 上下文学习(In Context Learning,ICL)
使用示例进行上下文学习(In Context Learning, ICL) 是发现隐含推理(hidden rationales)的常用方法。经过预训练的大型语言模型(LLM)展现出强大的上下文学习能力,通过基于相似性的示例检索可以增强这些模型的少样本学习(few-shot learning) 能力【145, 146】。然而,提示中包含不相关的信息可能会分散LLM的注意力,导致错误的回答【147, 148】。OpenICL 是由 Wu 等人开发的框架,该框架探讨了不同的传统检索示例和推理方法对ICL效果的影响【149】。
此外,基于LLM对上下文示例反馈,训练较小模型,可以更有针对性地选择最佳示例,改进特定任务上下文的构建【150, 5, 151】。为了应对基于语义相似性的示例检索可能无法涵盖实际测试中所需的广泛关联这一问题,Su等人提出了一种无监督、基于图的选择注释方法,称为vote-k,该方法构建了一个更具多样性和代表性的少样本学习示例数据库【152】。Zhang等人提出了Auto-CoT方法,将示例聚类为各种代表性类型,通过多样化地采样问题并生成推理链,构建更好支持学习过程的示例【153】。
然而,想要通过少样本学习让LLM掌握其训练领域之外的推理能力仍是一个重大挑战。 Wang等人通过采样多种推理路径,并对这些路径进行边缘化处理,选择最一致的答案,增强了LLM选择正确推理链的概率【154】。Agarwal等人引入了两种可扩展的生成可用示例的方法,即强化ICL和无监督ICL,旨在替代人类生成的示例,从而扩展了可用示例库【155】。DIN-SQL【156】试图将任务分解为更简单的子任务,并将这些子问题的解决方案作为提示提供给LLM,显著提升了LLM将文本生成SQL的性能。同样,DUP【157】确定了LLM在使用链式思维(chain of thought)解决复杂数学问题时面临的三个主要问题:语义误解、计算错误和步骤缺失,其中语义误解是限制因素之一。鼓励LLM深入理解问题并提取解决问题的核心信息可以显著增强其解决数学问题的能力。
上下文学习正越来越多地应用于数学、法律、医学和金融等领域【158, 159, 160】,在数据增强型LLM应用程序的发展中发挥着至关重要的作用。这种方法不仅扩展了LLM的功能,还增强了它们在各个领域的实际应用价值。
6.5 微调
尽管大型语言模型(LLMs)在上下文学习能力上非常强大,但在面对复杂、冗长的逻辑链时,准确识别推理过程或找到最佳示例依然是一个巨大的挑战。此外,为LLMs提供大量的外部先验知识也可能对其推理能力带来困难。在这种背景下,微调(fine-tuning) 成为一种有效的方法。微调不仅能利用LLMs在预训练期间获得的广泛基础知识,还能帮助它们快速掌握新的领域推理。通过这种方法,LLMs能够更好地适应和处理高级且专门化的任务。
1. 指令微调
指令微调(Instruction tuning) 是一种常见的为LLMs注入新能力的方法,通常通过配对的(指令、输出)数据进行有监督的微调。构建指令数据集的方法主要有三种:
- 从现有数据集中获取 [161, 162],
- 手工创建,通过手工编写的指令生成 [163, 164, 165],
- 使用强大的LLMs生成合成数据 [166, 154]。
此外,许多研究[167, 168, 169]还探索了如何优化指令数据集中的数据分布,以提高微调的效果。然而,在构建数据增强的LLM应用时,微调依然是一个相对昂贵的操作,涉及大量时间和计算资源。
2. 降低微调成本
为了降低微调大型模型的成本,近年来出现了一些新的尝试。例如:
- Adapter Tuning(适配器微调):在LLMs中集成小型适配器模型,在微调期间冻结LLM的参数,仅优化适配器的权重 [170, 171, 172, 173]。
- Prefix Tuning 和 Prompt Tuning:在输入前添加一组可训练向量,并在训练过程中优化这些向量,以提高LLM的性能 [174, 175, 176, 177, 178]。
- Low-Rank Adaptation(低秩适应):通过对每个密集层施加低秩约束,近似更新矩阵,从而减少适应下游任务所需的可训练参数 [179, 180, 181, 182, 183]。
3. 专门领域的微调应用
近年来,许多研究通过有监督的微调来提升LLMs在特定领域的能力,包括数学推理、金融、法律和医疗等。例如:
- ChatTimeLlama [187] 引入了一个可解释的时间推理指令微调数据集,并在LLaMA [188]上进行微调,显著提升了模型在复杂时间推理、未来事件预测以及可解释性方面的能力。
- LISA [189] 通过一小部分包含推理的段落数据样本微调多模态LLM LLaVA,显著提升了推理分割的能力。
- MAmmoTH [190] 精心构建了一个结合了“思维链(Chain of Thought)”和“程序思维(Program of Thought)”的数学示例数据集,覆盖了不同的数学领域,从而提升了LLM解决数学问题的能力。
- ReFT [191] 提出了一个从多个标注推理路径中学习的方法,它为给定的数学问题自动生成多条推理轨迹,并利用正确答案生成奖励信号。
- ChatDoctor [192] 利用一个包含10万个患者与医生对话的庞大数据集(来自广泛使用的在线医疗咨询平台)对LLaMA进行微调,显著增强了模型理解患者需求并提供有效建议的能力。
- FinGPT [193] 开发了一个基于金融数据微调的开源LLM,通过自动数据整理和轻量化的低秩适应技术来实现。
- DISC-LawLLM [194] 为中国司法领域创建了一个有监督的微调数据集,微调LLMs以便在不同法律场景下更有效地为用户提供服务,并增强其法律推理能力。
通过这些微调方法,LLMs不仅能够在通用任务中表现出色,还能够在复杂、专门的领域中展现出更强的适应性和推理能力。
七、结论
在本文中,我们将数据增强的LLM(Large Language Model)应用根据查询的主要焦点划分为四个不同的类别,每个类别面临独特的挑战,因此需要量身定制的解决方案,如图5所示。
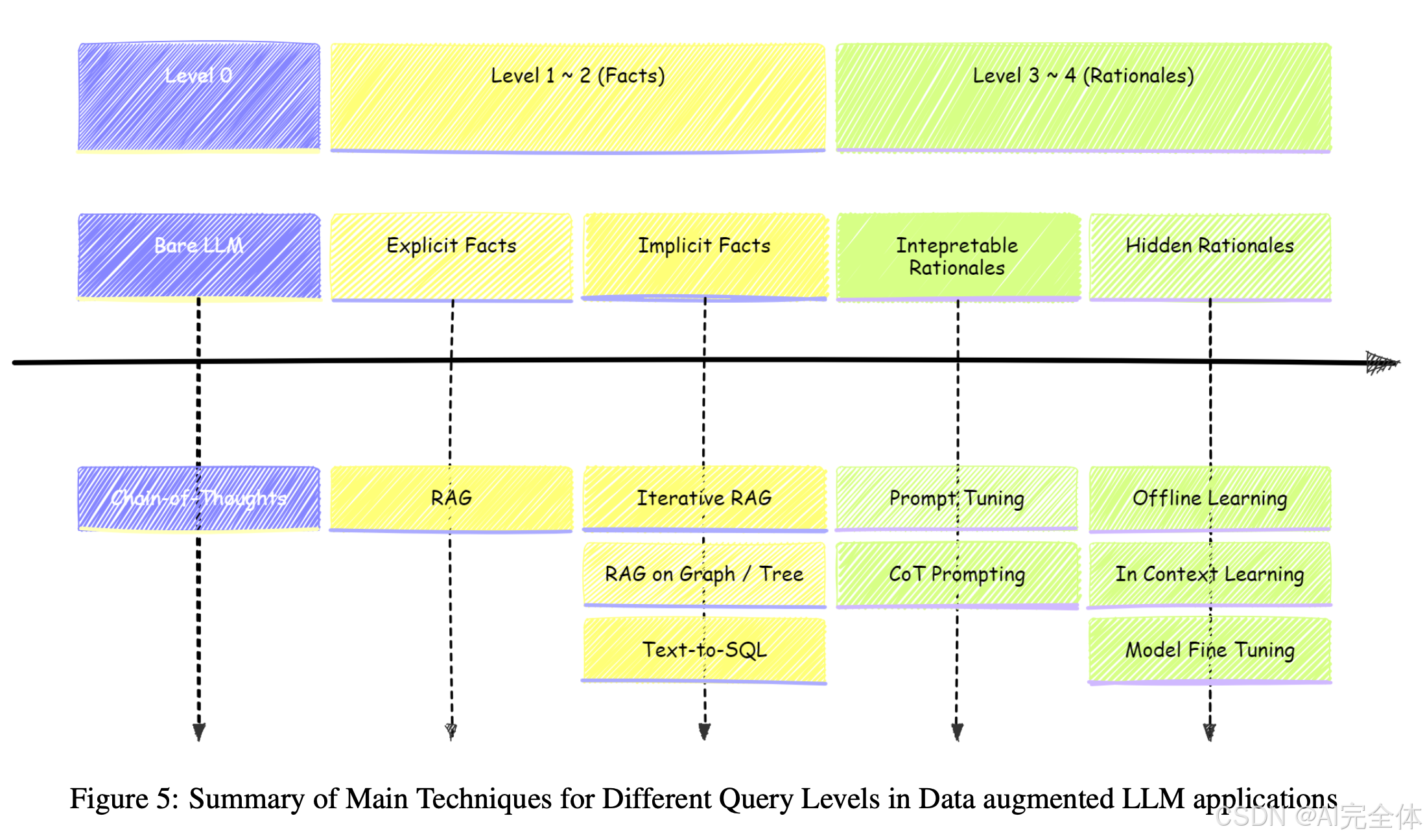
- 静态常识性查询:对于涉及静态常识性问题的查询,通过思维链(Chain of Thought, CoT) 的方法部署通用LLM是有效的。
- 明确事实查询:对于明确的事实性问题,主要的挑战是精确定位数据库中的事实位置,因此基础的RAG(Retrieval-Augmented Generation) 方法成为首选。
- 隐含事实查询:当查询涉及需要汇总多个相关事实的隐含事实时,迭代RAG以及基于图或树结构的RAG实现是理想选择,因为这些方法能够同时检索单个事实并连接多个数据点。
- 大量数据链接查询:当需要大量数据关联时,文本到SQL(Text-to-SQL) 技术是不可或缺的,它利用数据库工具来促进外部数据的搜索。
- 可解释推理查询:提示调优(Prompt Tuning) 和CoT提示的进展,对于提高LLMs对外部指令的遵从性至关重要。
- 隐藏推理查询:最具挑战性的是隐藏推理查询,它要求从大量数据集中自主学习综合解决问题的方法。在此情况下,离线学习(offline learning)、上下文学习(In-Context Learning, ICL) 和微调(fine-tuning) 成为关键方法。
在开发针对性的LLM应用程序之前,作为领域专家,我们必须深入理解预期的任务,确定相关查询的复杂程度,并选择相应的技术方法来解决问题。这些方法主要通过三种机制将知识注入LLMs,如图6所示:
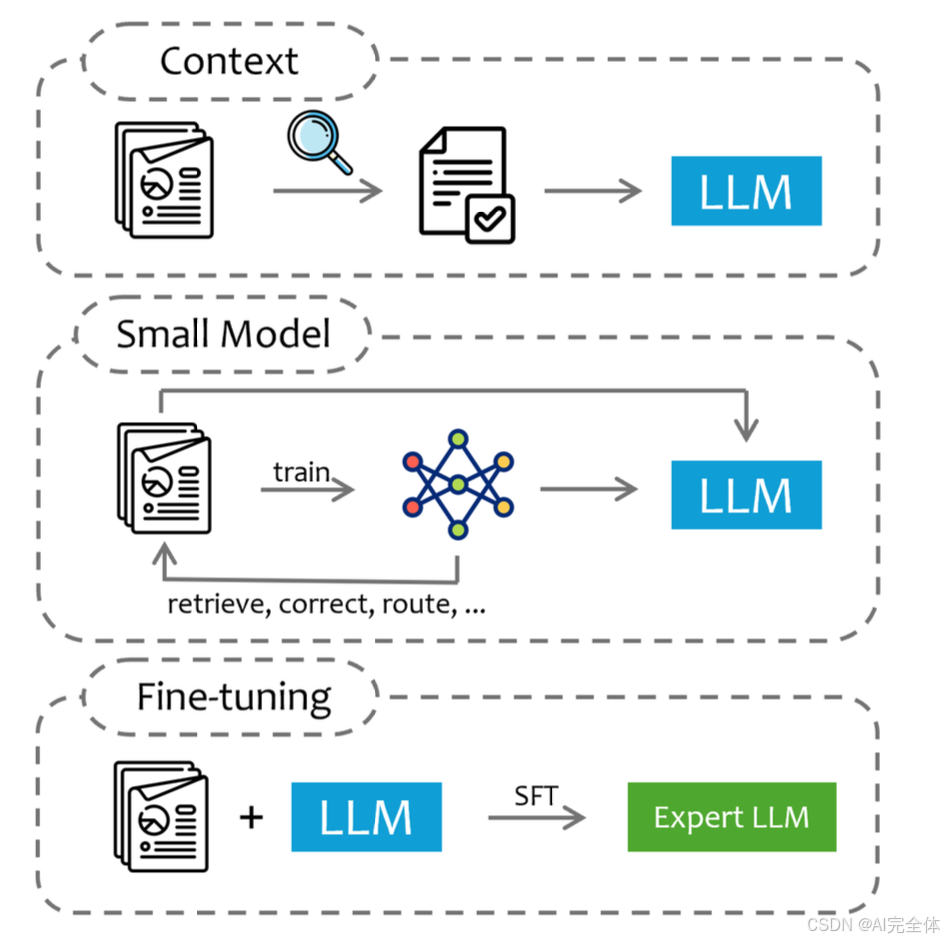
- 根据查询从领域数据中提取部分内容作为LLM的上下文输入;
- 使用特定领域数据训练一个较小的模型,然后引导该模型整合外部信息并输入LLM;
- 直接使用外部领域知识对通用大型语言模型进行微调,使其成为领域专家模型。
这些策略在数据量、训练时间和计算资源需求上各不相同,依次递增。
-
上下文:通过上下文进行的知识注入具有更好的可解释性和稳定性,但由于上下文窗口的有限性和信息可能在中途丢失,存在局限性 【40】。这种方法适用于可以简洁地解释在较短文本中的场景。然而,它对模型的检索能力和知识提取能力提出了挑战。
-
小模型:小模型方法的优点在于减少训练时间和能够吸收大量数据,但其效果依赖于模型本身的能力,这可能会限制LLM在处理更复杂任务时的性能。此外,随着数据量的增加,这种方法的训练成本也会上升。
-
微调 :微调则能够利用大型模型的容量并结合大量特定领域数据,但其效果强烈依赖于所使用数据的设计。如果使用域外事实数据进行微调,可能会导致LLM生成更多的错误输出,同时也有可能导致之前已知的领域知识丢失,并且在微调过程中忽略未曾遇到的任务 【110, 195】。
因此,选择适当的数据注入策略需要对数据源有深入的了解,并基于此做出明智的决策。
此外,在实际应用中,数据增强的LLM应用通常涉及多种类型的查询,要求开发者设计一个集成多种方法的路由管道,以有效应对这些复杂的挑战。
完结撒花🎉😊
相关文章:
【AI论文精读14】RAG论文综述2(微软亚研院 2409)P6(完)-隐含推理查询L4
AI知识点总结:【AI知识点】 AI论文精读、项目、思考:【AI修炼之路】 P1,P2,P3,P4,P5 六、隐藏推理查询(L4) ps:P2有四种查询(L1,L2,L3…...
FFmpeg的简单使用【Windows】--- 视频倒叙播放
实现功能 点击【选择文件】按钮可以选择视频,当点击【开始处理】按钮之后,会先将视频上传到服务器,然后开始进行视频倒叙播放的处理,当视频处理完毕之后会将输出的文件路径返回,同时在页面中将处理好的视频展示出来。…...

5分钟了解docker的Swarm机制
Swarm框架概述 1.1 Swarm的基本概念 在容器化技术的浪潮中,Docker无疑是最为耀眼的明星之一。而作为Docker生态系统中的重要组成部分,Swarm框架则扮演着至关重要的角色。Swarm,顾名思义,就是“群”的意思,它是一个开…...

python实现ppt转pdf
要实现将PPT文件转换为PDF文件,可以使用Python中的python-pptx库来读取PPT文件,并使用reportlab库来生成PDF。又或者,你也可以使用其他库如pypdf和pypptx等进行处理。 以下是一个使用unoconv工具以及Python的示例,可以将PPT转换为…...

VS2017 编译 SQLite3 动态库
首先官方下载源码: Tags sqlite/sqlite (github.com) 1.安装 VS2017 community edition 2.打开VS2017命令行工具 3.安装TCL 开发库,推荐 TCL 9.0 先下载源码: Tcl/Tk 9.0 使用vs2017编译tcl&...

Linux运维_Apache更改默认网站目录
1.首先创建目录 并且在目录下新建测试文件 index.html mkdir -p /home/test/ap_web 直接wget 百度官网 wget www.baidu.com 2.编辑配置文件 /etc/apache2/sites-available/000-default.conf(找到 DocumentRoot)更改为刚刚创建的目录 接着在添加 最终文件: 3.给文件 添加属…...

QT QString学习笔记
1.操作字符串 1.提供双元运算符 “” QString str1"cccc"; str1 str1 "ddddd"; qDebug()<<str1; qDebug()<<qPrintable(str1); 2.提供操作符 append() QString str1 "Good"; QString str2 "bye"; str1.append(str2); …...

4.stm32 GPIO输入
按键简介 按键:常见的输入设备,按下导通,松手断开 按键抖动:由于按键内部使用的是机械式弹簧片来进行通断的,所以在按下和松手的瞬间会伴随有一连串的抖动 传感器模块简介 传感器模块:传感器元件&#…...

GPT系列
GPT(Generative Pre-Training): 训练过程分两步:无监督预训练有监督微调 模型结构是decoder-only的12层transformer 1、预训练过程,窗口为k,根据前k-1个token预测第k个token,训练样本包括700…...

Chromium 前端window对象c++实现定义
前端中window.document window.alert()等一些列方法和对象在c对应定义如下: 1、window对象接口定义文件window.idl third_party\blink\renderer\core\frame\window.idl // https://html.spec.whatwg.org/C/#the-window-object// FIXME: explain all uses of [Cros…...

【力扣算法题】每天一道,健康生活
2024年10月8日 参考github网站:代码随想录 1.二分查找 leetcode 视频 class Solution { public:int search(vector<int>& nums, int target) {int left 0;int right nums.size()-1;while(left<right){int middle (leftright)/2;if(nums[middle] …...

Android Camera系列(四):TextureView+OpenGL ES+Camera
别人贪婪时我恐惧,别人恐惧时我贪婪 Android Camera系列(一):SurfaceViewCamera Android Camera系列(二):TextureViewCamera Android Camera系列(三):GLSur…...

03 django管理系统 - 部门管理 - 部门列表
部门管理 首先我们需要在models里定义Dept类 # 创建部门表 class Dept(models.Model):name models.CharField(max_length100)head models.CharField(max_length100)phone models.CharField(max_length15)email models.EmailField()address models.CharField(max_length2…...

L1 Sklearn 衍生概念辨析 - 回归/分类/聚类/降维
背景 前文中我们提到: Scikit-Learn 库的算法主要有四类:分类、回归、聚类、降维: 回归:线性回归、决策树回归、SVM回归、KNN 回归;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees。…...

【畅捷通-注册安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

TCP IP网络编程
文章目录 TCP IP网络编程一、基础知识(TCP)1)Linux1. socket()2.bind()2.1前提2.2字节序与网络字节序2.3 字节序转换2.4 字符串信息转化成网络字节序的整数型2.5 INADDR_ANY 3.listen()4.accept()5.connect()6.案例小结6.1服务器端6.2 客户端…...

libssh2编译部署详解
libssh2编译部署详解 一、准备工作二、编译libssh2方法一:使用Autotools构建方法二:使用CMake构建三、验证安装四、使用libssh2五、结论libssh2是一个用于实现SSH2协议的开源库,它支持建立安全的远程连接、传输文件等操作。本文将详细介绍如何在Linux系统下编译和部署libssh…...

IPv4数据报的首部格式 -计算机网络
IPv4数据报的首部格式 Day22. IPv4数据报的首部格式 -计算机网络_4字节的整数倍-CSDN博客 IP数据报首部是4字节的整数倍 🌿版本: 占4比特,表示IP协议的版本通信双方使用的IP协议必须一致,目前广泛使用的IP协议版本号上4…...

小米电机与STM32——CAN通信
背景介绍:为了利用小米电机,搭建机械臂的关节,需要学习小米电机的使用方法。计划采用STM32驱动小米电机,实现指定运动,为此需要了解他们之间的通信方式,指令写入方法等。花了很多时间学习,但网络…...

2.2.ReactOS系统KSERVICE_TABLE_DESCRIPTOR结构体的声明
2.2.ReactOS系统KSERVICE_TABLE_DESCRIPTOR结构体的声明 2.2.ReactOS系统KSERVICE_TABLE_DESCRIPTOR结构体的声明 文章目录 2.2.ReactOS系统KSERVICE_TABLE_DESCRIPTOR结构体的声明KSERVICE_TABLE_DESCRIPTOR系统调用表结构体的声明 KSERVICE_TABLE_DESCRIPTOR系统调用表结构体…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

Thorium浏览器深度解析:5个核心优势与进阶配置实战
Thorium浏览器深度解析:5个核心优势与进阶配置实战 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of the RE…...

开源银行API模拟器Bankr Buddy:金融科技开发的本地化测试解决方案
1. 项目概述:一个为开发者准备的银行API模拟器如果你正在开发一个需要与银行账户数据打交道的应用,无论是个人财务管理工具、预算分析软件,还是企业级的财务聚合服务,你肯定遇到过同一个难题:如何在不触碰真实用户敏感…...

从零构建团队技能仓库:结构化知识管理与VuePress实践
1. 项目概述:一个技能仓库的诞生与价值 最近在整理团队内部的技术资产时,我一直在思考一个问题:如何让那些散落在个人笔记、项目代码片段、会议纪要里的“隐性知识”和“最佳实践”沉淀下来,变成团队可复用、可传承的“显性资产”…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...

GitClaw:基于Go的轻量级Git钩子服务器与集中式权限管理方案
1. 项目概述与核心价值如果你是一名开发者,尤其是经常在团队协作中处理Git仓库的工程师,那么你一定对“权限管理”这四个字又爱又恨。爱的是它能保障代码安全,恨的是它配置起来繁琐,尤其是在处理跨项目、跨团队的复杂权限矩阵时。…...

三维重建实时映射技术在智慧水利中的核心应用
三维重建实时映射技术在智慧水利中的核心应用在国家大力推进数字孪生水利建设、实现水安全精准保障的背景下,智慧水利已从传统监测、调度向全域感知、智能预判、协同处置、一屏统管升级。智慧水利的核心目标,是实现对江河湖库、灌区、泵站、堤坝、闸站等…...

模拟电路布局优化:多智能体强化学习实践
1. 模拟电路布局优化的挑战与机遇在集成电路设计领域,模拟电路布局一直是个令人头疼的问题。作为一名从业十余年的模拟电路设计师,我深刻体会到传统布局方法在面对现代工艺挑战时的局限性。每次手工调整晶体管位置时,那种"差之毫厘&…...