腾讯音乐:从 Elasticsearch 到 Apache Doris 内容库升级,统一搜索分析引擎,成本直降 80%
导读: 为满足更严苛数据分析的需求,腾讯音乐借助 Apache Doris 替代了 Elasticsearch 集群,统一了内容库数据平台的内容搜索和分析引擎。并基于 Doris 倒排索引和全文检索的能力,支持了复杂的自定义标签计算,实现秒级查询响应需求。此外,实现写入性能提升 4 倍、使用成本节省达 80% 的显著成效。相关文章:#腾讯音乐案例 、#Elasticsearch 到 Apache Doris 案例、#日志场景案例
作者|腾讯音乐内容信息平台部,张俊、罗雷、李继蓬、代凯
腾讯音乐娱乐拥有丰富的内容曲库,包括录制音乐、现场表演、音频和视频等多种形式。通过技术和数据赋能,腾讯音乐娱乐不断创新产品,为用户提供更优质的体验,提高用户参与度,同时为音乐人和合作伙伴在制作、发行和销售方面提供更大支持。基于公司丰富的音乐内容资产,腾讯音乐将歌曲库、艺人资讯、专辑信息、厂牌信息等大量数据统一存储,形成音乐内容库数据平台,该平台旨在为应用层提供库存盘点、分群画像、指标分析、标签圈选等内容分析服务,高效为业务赋能。
内容库数据平台的数据架构已经从 1.0 版本演进到了 4.0 版本。之前的文章介绍了分析引擎 从 ClickHouse 到 Apache Doris 升级实践。本文将重点分享内容搜索引擎从 Elasticsearch 到 Apache Doris 的替换,如何通过一个系统同时满足内容搜索和数据分析的需求,并满足复杂的自定义标签计算的支持。最终,实现存储成本降低 80%,写入性能提升 4 倍的显著效益。
业务需求
从业务角度来看,腾讯音乐有两个场景需要搜索能力的支持,分别是内容库的百科搜索及内容库的标签圈选。
- 内容库百科搜索: 分析师和运营人员需要快速查找歌手、歌曲名称以及其他文本信息。这种检索能力不仅要求高效的全文搜索,还需支持多种查询条件,以便用户能够迅速获取所需数据,提升工作效率。
- 内容库标签圈选: 分析师和运营人员会根据特定的标签和条件,筛选出符合要求的内容。这要求系统能够在亿级数据量的情况下,提供秒级的查询响应,以便快速定位和分析相关数据,支持业务决策和策略优化。
Elasticsearch + Doris 混合架构
在 2.0 版本之前,Doris 暂未推出倒排索引能力,检索能力相对较弱。而 Elasticsearch 在全文检索方面具备优势,能够基于倒排索引快速匹配特定关键词或短语、可对所有字段建立索引,在查询时支持任意组合的过滤条件等。
但是,Elasticsearch 聚合统计分析性能较差,不支持 JOIN 等复杂查询,且存储空间占用较高。这些正是 Apache Doris 所擅长的领域,能够高效处理复杂的统计分析和查询任务,并通过高压缩率优化存储效率。
因此,腾讯音乐构建基于 Elasticsearch 与 Doris 的混合架构,Elasticsearch 负责内容的全文检索和标签圈选,而 Apache Doris 专注于 OLAP 分析。借助 Doris 的 ES catalog 外表查询机制,能够直接查询 Elasticsearch 中数据,实现对外查询接口的统一。
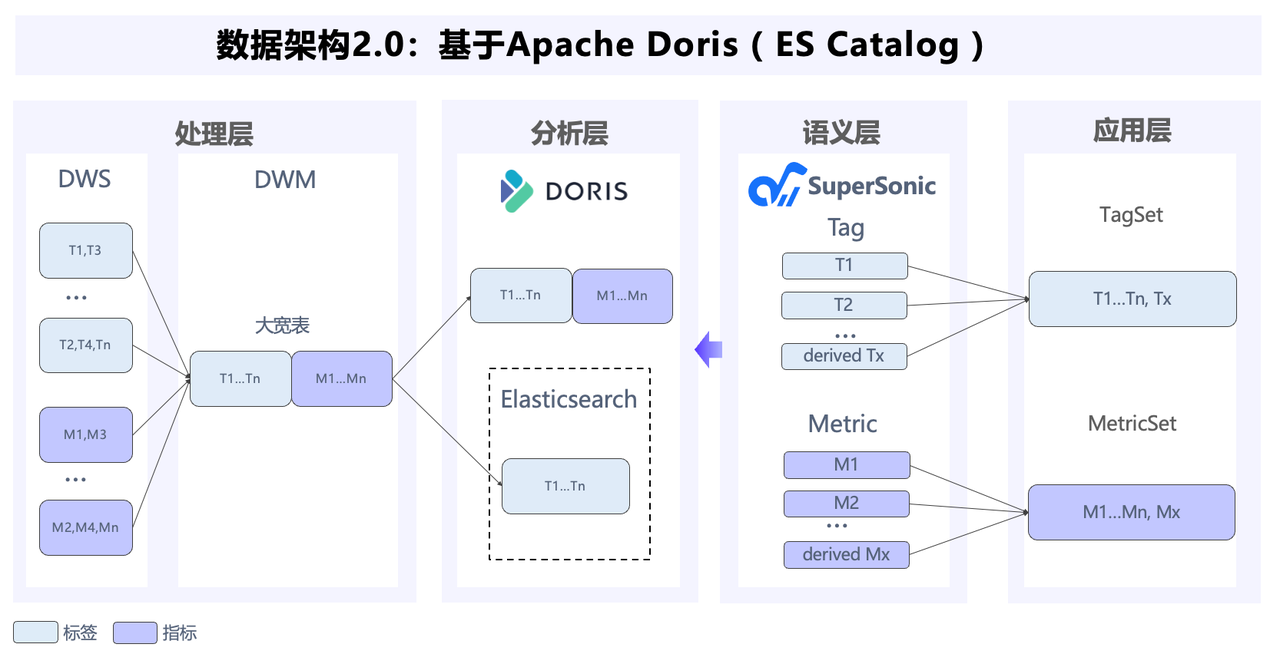
但这套混合架构在应用时,也遇到了一些问题:
- 存储成本较高:Doris 的引入并没有完全解决存储成本高的问题,Elasticsearch 的存储空间占用仍然显著。
- 写入性能受限:随着数据量的增长,Elasticsearch 集群的写入压力不断加大,全量写入耗时超过 10 个小时,接近业务可承受极限。
- 混合架构复杂:Elasticsearch 和 Doris 的混合架构增加了系统和技术栈的维护成本,同时冗余的数据存储也带来了额外费用,两套系统也增加了数据不一致的风险。
基于 Apache Doris 的统一架构方案
因此,腾讯音乐考虑是否可以将搜索引擎统一为 Doris,让其全面负责全文检索、标签圈选以及聚合分析的需求。这样考虑的主要原因是 Apache Doris 自 2.0 版本开始支持倒排索引和全文检索,这使其有能力完全替 Elasticsearch 所负责的部分,获得更好的收益。
- 在全文检索方面,Doris 不仅支持普通的等值和范围(
=, !=, >, >=, <, <=)查询加速,还支持文本字段的全文检索,包括中英文分词、多关键词检索(MATCH_ANY, MATCH_ALL)、短语检索(MATCH_PHRASE, MATCH_PHRASE_PREFIX, MATCH_PHRASE_REGEXP)、短语词距(slop)、多字段检索(MULTI_MATCH),其性能相较于传统数据库支持的 LIKE 模糊匹配有数量级的提升。 - 在倒排索引方面, Doris 倒排索引在数据库内核中实现,语法与 SQL 无缝结合,支持多种条件的任意 AND OR NOT 逻辑组合,满足普通过滤以及全文检索组合的复杂需求。如下方示例,
WHERE筛选条件由 5 部分组成,包括全文检索title MATCH '爱' OR description MATCH_PHRASE '热爱',日期范围过滤dt BETWEEN '2024-09-10 00:00:00' AND '2024-09-10 23:59:59',数值范围过滤rating > 4,字符串等值过滤country = '中国',这些条件通过统一的 SQL 语法无缝组合起来,筛选完之后又按照 actor 进行分组统计,最后对分组统计的 cnt 排序取最高的 100 个结果。
SELECT actor, count() as cnt
FROM table1
WHERE dt BETWEEN '2024-09-10 00:00:00' AND '2024-09-10 23:59:59'AND (title MATCH '爱' OR description MATCH_PHRASE '热爱')AND rating > 4AND country = '中国'
GROUP BY actor
ORDER BY cnt DESC LIMIT 100;
因此,腾讯音乐将 Doris 升级至 2.0 版,将架构从原先的 Elasticsearch 和 Doris 转变为统一的 Doris 解决方案:
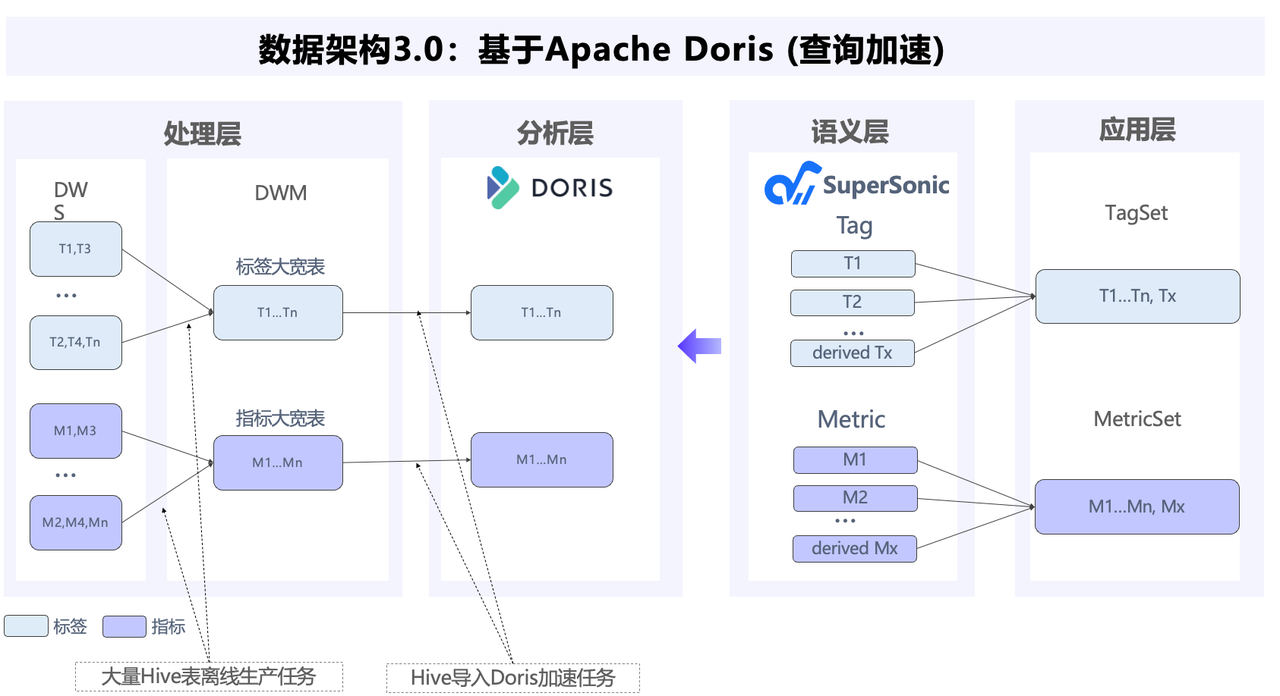
基于 Doris 的统一架构上线后,所带来的收益也非常可观:
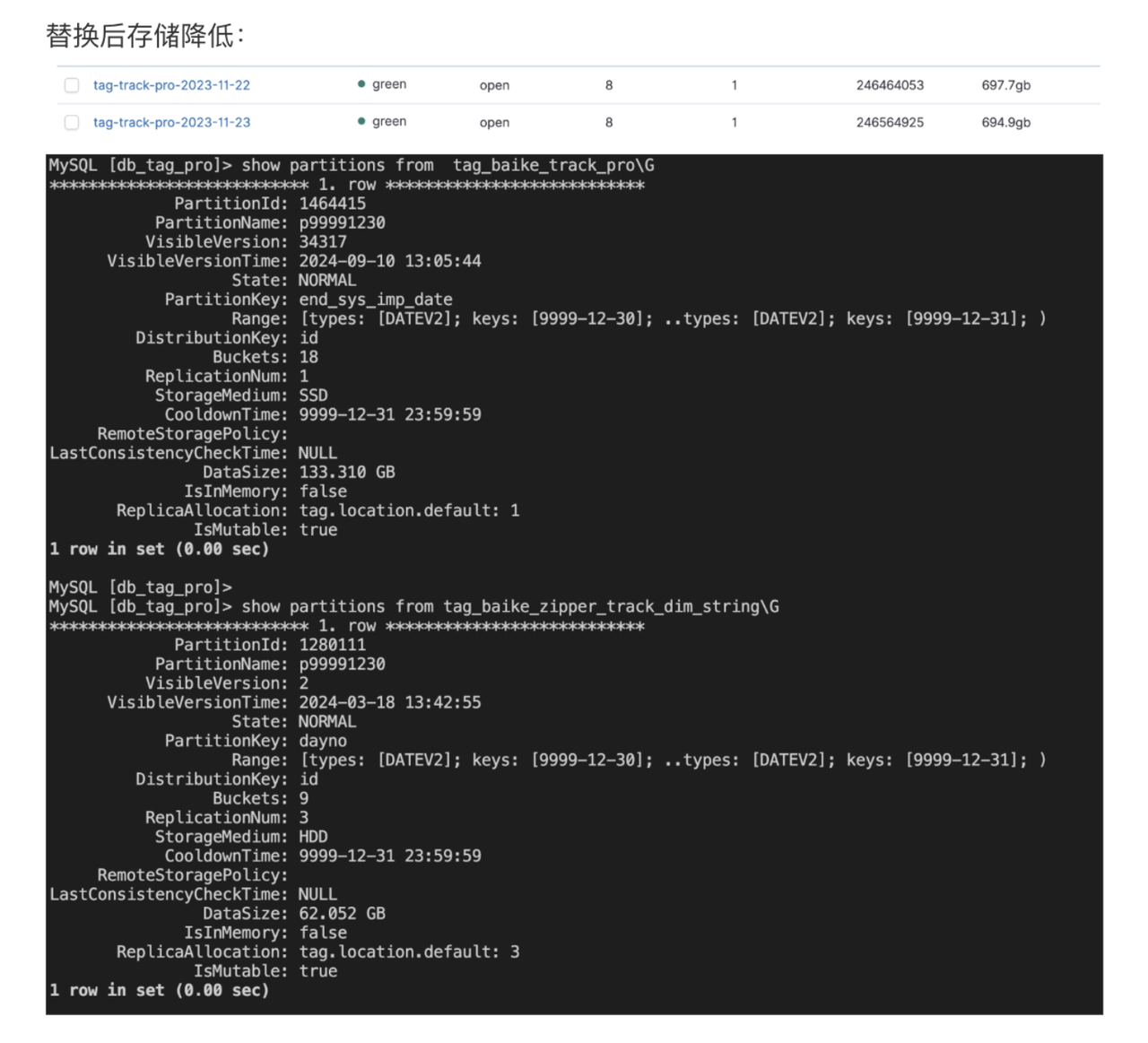
- 成本显著降低:Doris 替代了 Elasticsearch 集群,同时承载了搜索和分析两类负载,使用成本节省达 80%。比如,某个表单日全量数据在 Elasticsearch 中需要 697.7 GB 存储空间,而在 Doris 中仅需 195.4 GB ,存储空间减少了 72%。
-
写入和查询性能提升:全量数据导入时间从 10 小时以上缩短至 3 小时以内, **写入性能是 Elasticsearch 的 4 倍。**此外,Doris 可以支持复杂的自定义标签计算,使不可能变为可能,显著改善了用户体验。
-
统一系统架构:架构统一到 Doris 后,内部只需维护一套技术栈,极大降低了维护成本,同时也很好避免了两套系统之间的数据一致性问题,确保了数据质量的可靠性。
在架构统一的过程中,涉及到一些关键设计,接下来将相关方案及经验分享给读者。
01 Doris 倒排索引的使用
在存储结构上采用了维度表与事实表的方案:
- 维度表:使用 Merge-on-Write Unique 模型,用于百科搜索和标签圈选,通过部分列更新进行维度更新。
- 事实表:使用 Aggregate 模型,用于存储每日的指标数据。由于数据量较大且每天的数据独立,每天需新建一个分区。
参考 Doris 倒排索引的使用文档,根据 Elasticsearch Mapping 设计了对应的 Doris 的表结构和索引。其中,Elasticsearch 的 Keyword 类型对应 Doris 的 Varchar/String 类型及不分词的倒排索引(USING INVERTED),ES 的 Text 类型对应 Doris 的 Varchar/String 类型及分词倒排索引(USING INVERTED PROPERTIES("parser" = "english/chinese/unicode"))。
CREATE TABLE `tag_baike_zipper_track_dim_string` (`dayno` date NOT NULL COMMENT '日期',`id` int(11) NOT NULL COMMENT 'id',`a4` varchar(65000) NULL COMMENT 'song_name',`a43` varchar(65000) NULL COMMENT 'zyqk_singer_id',INDEX idx_a4 (`a4`) USING INVERTED PROPERTIES("parser" = "unicode", "support_phrase" = "true") COMMENT '',INDEX idx_a43 (`a43`) USING INVERTED PROPERTIES("parser" = "english") COMMENT ''
) ENGINE=OLAP
UNIQUE KEY(`dayno`, `id`)
COMMENT 'OLAP'
PARTITION BY RANGE(`dayno`)
(PARTITION p99991230 VALUES [('9999-12-30'), ('9999-12-31')))
DISTRIBUTED BY HASH(`id`) BUCKETS auto
PROPERTIES (
...
);
使用 Doris 倒排索引的前后对比:
使用前:以下方复杂查询为例,在使用 Doris 倒排索引之前,该查询运行较慢、响应级别为分钟级。
-- like (查询复杂性能低):
SELECT * FROM db_tag_pro.tag_track_pro_3 WHERE
dayno='2024-08-01' AND ( concat('#',a4,'#') like '%#若月亮还没来#%'
or concat('#',a43,'#') like '%#1000#%') -- explode (执行性能差,经常 ERROR 1105 (HY000)):
SELECT * FROM (SELECT tab1.*,a4_single,a43_single FROM ( SELECT * FROM db_tag_pro.tag_track_pro_3WHERE dayno='2024-08-01') tab1 lateral view explode_split(a4, '#') tmp1 as a4_singlelateral view explode_split(a43, '#') tmp2 as a43_single) tab2 where a4_single='若月亮还没来' or a43_single='1000'
使用后:使用 Doris 倒排索引之后,查询过程显著简化,运行速度极大提升,响应时间从分钟级缩短至秒级别。
- 对中文采用
unicode分词,数值采用english分词创建倒排索引。 - 设置
store_row_column,启用行存,优化select*查询所有列。
-- 先通过match从维度表搜索查询到id
SELECT id FROM db_tag_pro.tag_baike_zipper_track_dim_string WHERE
( a4 MATCH_PHRASE '若月亮还没来' OR a43 MATCH_ALL '1000' ) AND dayno ='2024-08-01'-- 再通过id主键查询事实表得到明细数据
SELECT * FROM db_tag_pro.tag_baike_track_pro WHERE id IN ( 563559286 )
不仅如此,原来在 Elasticsearch 中由于语句过长而无法查询的复杂自定义标签,在 Doris 内能够更好的支持,Doris 能够处理更长的 SQL 语句。并且在同一个引擎内,可以通过物化视图和 BITMAP 类型轻松对查询后的中间结果进一步优化,避免了不同引擎之间的跨网络同步。
02 业务间资源隔离
为了确保业务侧使用体验和成本可控,我们采用了 Doris 的资源隔离机制进行业务间的资源管理。
- 第一层:物理隔离(Resource Group) 将集群划分为两个资源组:Core 和 Common,以服务不同重要场景的需求。Core 组专注于内容搜索和标签圈选的核心需求,而 Common 组则处理其他普通需求。通过在节点层面实施物理隔离,可确保核心业务不受其他业务的影响。
- 第二层:逻辑隔离(Workload Group) 在每个物理隔离内部,通过 Workload Group 对每个 Resource Group 进行逻辑资源的细分。例如,在普通集群中建立多个 Workload Group,并为用户指定默认的 Workload group,以防止单个用户占满整个集群的资源。

上述资源隔离机制显著提升了系统的稳定性,告警频率从每天 20 多次降低到每月个位数。这不仅保障了业务的可靠性,还减轻了团队运维管理压力,使他们能够将更多时间投入到系统优化中。
业务无感迁移方案
腾讯音乐自研的 SuperSonic 项目内置了 Headless BI 功能,其核心理念是将数据建模、管理和消费进行解耦。通过这种架构,业务分析师只需在 Headless BI 平台上定义指标和标签,而无需关心底层数据源的具体实现。
在业务迁移过程中,业务团队通过 SuperSonic Headless BI 进行。利用转换工具将 DSL 转换为 Elasticsearch SQL 查询,只需切换已定义指标和标签所对应的数据源即可。由于 Headless BI 屏蔽了底层不同数据存储和分析引擎的差异,业务方能够实现无感知的迁移。
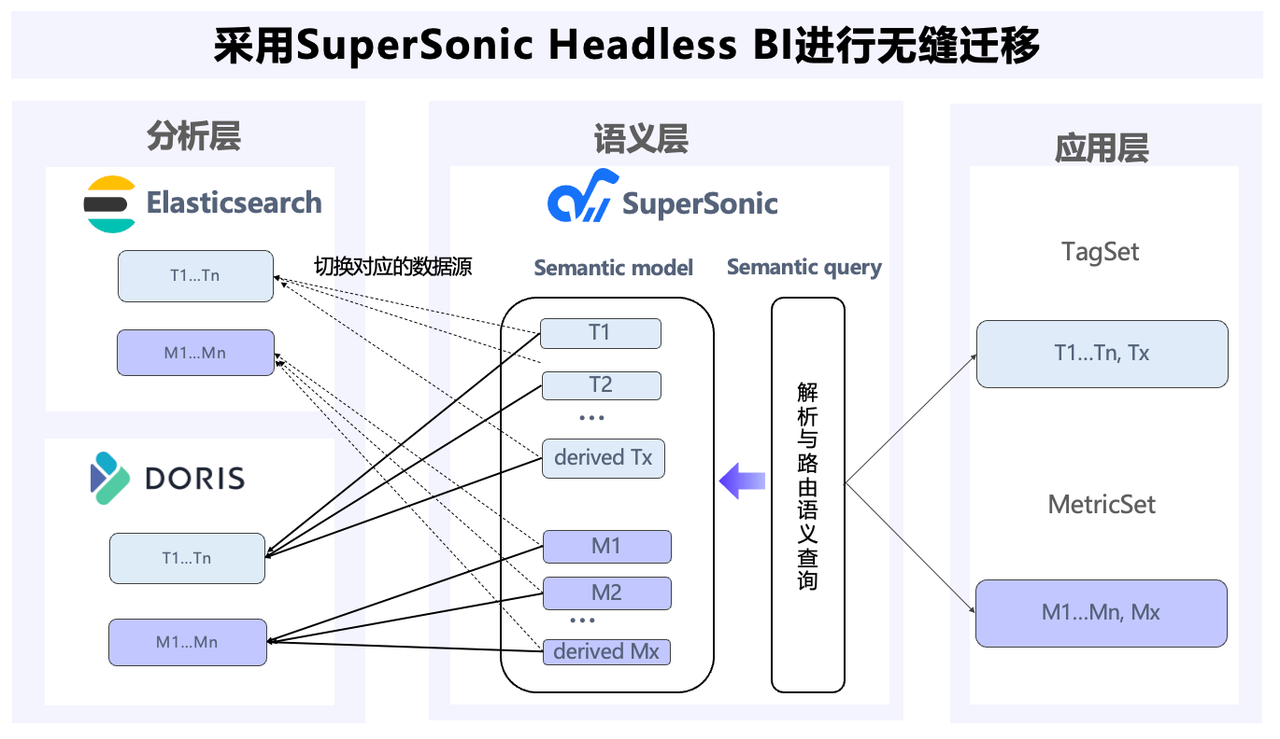
Headless BI 架构不仅实现了数据源的无缝迁移,还大大简化了数据管理和查询的复杂性。SuperSonic 将 Chat BI 与 Headless BI 融合,使用户能够实现统一的数据治理,并通过自然语言进行数据分析。经过腾讯音乐的自主研发和实际应用,SuperSonic 平台现已开源,欢迎感兴趣的同仁使用与共同建设。(项目地址)
结束语
借助 Doris 替代 Elasticsearch 集群,腾讯音乐统一了搜索和分析引擎。基于倒排索引和全文检索的能力,支持复杂的自定义标签计算,满足秒级响应需求。此外,写入性能提升了 4 倍,存储空间减少了 72%,使用成本节省达 80%。
未来,腾讯音乐将与 Apache Doris 深度合作,探索更多特性在场景应用中的可能性,包括引入 3.0 版本的存算分离,以进一步降低成本。
相关文章:#腾讯音乐案例 、#Elasticsearch 到 Apache Doris 案例、#日志场景案例
相关文章:
腾讯音乐:从 Elasticsearch 到 Apache Doris 内容库升级,统一搜索分析引擎,成本直降 80%
导读: 为满足更严苛数据分析的需求,腾讯音乐借助 Apache Doris 替代了 Elasticsearch 集群,统一了内容库数据平台的内容搜索和分析引擎。并基于 Doris 倒排索引和全文检索的能力,支持了复杂的自定义标签计算,实现秒级查…...

CubeMX的FreeRTOS学习
一、FreeRTOS的介绍 什么是FreeRTOS? Free即免费的,RTOS的全称是Real Time Operating system,中文就是实时操作系统。 注意:RTOS不是指某一个确定的系统,而是指一类的操作系统。比如:us/OS,FreeRTOS&…...

C语言初始:数据类型和变量
、 一.数据类型介绍 人有黄人白人黑人,那么数据呢? 我们大家可以看出谁是黄种人,谁是白种人,谁是黑种人,这是因为他们是类似的。 数据也是有类型的,就譬如整数类型,字符类型,浮点…...

Linux shellcheck工具
安装工具 通过linux yum源下载,可能因为yum源的问题找不到软件包,或者下载的软件包版本太旧。 ShellCheck的源代码托管在GitHub上(推荐下载方式): GitHub - koalaman/shellcheck: ShellCheck, a static analysis tool for shell scripts 对下…...

FLINK SQL时间属性
Flink三种时间属性简介 在Flink SQL中,时间属性是一个核心概念,它主要用于处理与时间相关的数据流。Flink支持三种时间属性:事件时间(event time)、处理时间(processing time)和摄入时间&#…...

android——Groovy gralde 脚本迁移到DSL
1、implementation的转换 implementation com.github.CymChad:BaseRecyclerViewAdapterHelper:*** 转换为 implementation ("com.github.CymChad:BaseRecyclerViewAdapterHelper:***") 2、plugin的转换 apply plugin: kotlin-android-extensions 转换为&#x…...

工程项目管理中的最常见概念!蓝燕云总结!
01 怎么理解工程项目管理? 建设工程项目管理指的是专业性的管理,并非行政事务管理。建设工程项目管理是对工程项目全生命周期的管理,确保项目能够按计划的进度、成本和质量完成。 建设工程项目不同阶段管理的主要内容不同,通常…...

PostgreSQL AUTO INCREMENT
PostgreSQL AUTO INCREMENT 在数据库管理系统中,自动递增(AUTO INCREMENT)是一种常见特性,用于在插入新记录时自动生成唯一的标识符。PostgreSQL,作为一个功能强大的开源关系数据库管理系统,也提供了类似的…...

24-10-13-读书笔记(二十五)-《一只特立独行的猪》([中] 王小波)用一生来学习艺术
文章目录 《一只特立独行的猪》([中] 王小波)目录阅读笔记记录总结 《一只特立独行的猪》([中] 王小波) 十月第五篇,放慢脚步,秋季快要过去了,要步入冬季了,心中也是有些跌宕起伏&am…...

Java—继承性与多态性
目录 一、this关键字 1. 理解this 2. this练习 二、继承性 2.1 继承性的理解 2.1.1 多层继承 2.2 继承性的使用练习 2.2.1 练习1 2.2.2 练习2 2.3 方法的重写 2.4 super关键字 2.4.1 子类对象实例化 三、多态性 3.1 多态性的理解 3.2 向下转型与多态练习 四、Ob…...

打通华为认证实验考试“痛点”:备考指南全解析
华为认证体系中的实验考试环节,尤其是针对高端的HCIE认证,是评估考生实践技能的关键部分。这一环节的核心目标是检验考生对华为设备和解决方案的操作熟练度、技术实施技能以及面对现实工作挑战时的问题解决能力。通过在真实环境中进行的实践操作…...

【软考】子系统划分
目录 1. 子系统划分的原则1.1 子系统要具有相对独立性1.2 子系统之间数据的依赖性尽量小1.3 子系统划分的结果应使数据几余较小1.4 子系统的设置应考虑今后管理发展的需要1.5 子系统的划分应便于系统分阶段实现1.6 子系统的划分应考虑到各类资源的充分利用 2. 子系统结构设计3.…...

【Python】selenium获取鼠标在网页上的位置,并定位到网页位置模拟点击的方法
在使用Selenium写自动化爬虫时,遇到验证码是常事了。我在写爬取测试的时候,遇到了点击型的验证码,例如下图这种: 这种看似很简单,但是它居然卡爬虫?用简单的点触验证码的方法来做也没法实现 平常的点触的方…...

【C++ 真题】B2078 含 k 个 3 的数
含 k 个 3 的数 题目描述 输入两个正整数 m m m 和 k k k,其中 1 < m ≤ 1 0 15 1 \lt m \leq 10^{15} 1<m≤1015, 1 < k ≤ 15 1 \lt k \leq 15 1<k≤15 ,判断 m m m 是否恰好含有 k k k 个 3 3 3,如果满足条…...

蓝桥杯省赛真题——冶炼金属
问题描述 小蓝有一个神奇的炉子用于将普通金属 O 冶炼成为一种特殊金属 X。这个炉子有一个称作转换率的属性 V,V 是一个正整数,这意味着消耗 V 个普通金属 O 恰好可以冶炼出一个特殊金属 X,当普通金属 O 的数目不足 V 时,无法继续…...

【Mac苹果电脑安装】DBeaverEE for Mac 数据库管理工具软件教程【保姆级教程】
Mac分享吧 文章目录 DBeaverEE 数据库管理工具 软件安装完成,打开效果图片Mac电脑 DBeaverEE 数据库管理工具 软件安装——v24.21️⃣:下载软件2️⃣:安装JDK,根据下图操作步骤提示完成安装3️⃣:安装DBeaverEE&#…...

数据仓库中的维度建模:深入理解与案例分析
数据仓库中的维度建模:深入理解与案例分析 维度建模是数据仓库设计中最常用的一种方法,旨在简化数据访问、提高查询效率,特别适用于需要对数据进行多维分析的场景。本文将深入探讨维度建模的核心概念、设计步骤以及如何将其应用于实际案例中…...

前端打印功能(vue +springboot)
后端 后端依赖生成pdf的方法pdf转图片使用(用的打印模版是带参数的 ,参数是aaa)总结 前端页面 效果 后端 依赖 依赖 一个是用模版生成对应的pdf,一个是用来将pdf转成图片需要的 <!--打印的--><dependency><groupId>net.sf.jasperreports</groupId>&l…...
中间件有哪些分类?
中间件的分类 中间件是位于操作系统和应用程序之间的软件,它提供了一系列服务来简化分布式系统中的应用程序开发和集成。中间件可以根据其功能和用途被分为不同的类别。以下是中间件的一些主要分类: 1. 通信处理(消息)中间件&am…...

开始新征程__10.13
好久没有更新 csdn 了,身边的人都说 csdn 水,但是在我看来,它在我大一这一年里对我的帮助很大,最近上账号看看,看见了网友评论,哈哈,决定以后还是继续更新,分享自己的学习心得。...

OpenClaw 小龙虾智能体联动 DeepSeek 大模型部署实操攻略
前置准备 获取小龙虾open claw一键安装包(www.totom.top)并安装电脑端已成功安装并正常启动OpenClaw,右上角 Gateway 状态显示在线设备网络通畅,可正常访问 DeepSeek 开放平台拥有可接收验证码的手机号 / 微信,用于平…...

FMCW雷达干扰抑制:分数傅里叶变换的工程实践
1. FMCW雷达干扰问题与分数傅里叶变换的机遇在79GHz频段工作的车载FMCW雷达,其线性调频连续波(LFM)信号极易受到同频段其他雷达设备的干扰。这种干扰会导致雷达检测性能显著下降——实测数据显示,强干扰环境下目标检测的虚警率可能…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...

解密Jsxer:如何高效反编译Adobe JSXBIN二进制脚本
解密Jsxer:如何高效反编译Adobe JSXBIN二进制脚本 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer Jsxer是一个快速准确的JSXBIN反编译器,专门用于将Adobe ExtendScript的二进…...
)
别再满世界找Kettle了!手把手教你定位最新官方下载源(附版本选择建议)
开源工具下载困境突围指南:以Kettle为例构建高效溯源方法论 在开源工具的使用过程中,最令人头疼的莫过于某天突然发现熟悉的下载链接失效,官网改版后找不到下载入口,或是搜索引擎返回的结果全是过时的教程。这种情况不仅发生在Ke…...

峰值电流模式控制中传播延迟的功率影响与补偿方案
1. 项目概述:直面峰值电流模式控制的“功率之殇”做电源设计,尤其是反激式开关电源,有一个场景大家肯定都遇到过,而且非常头疼:你的电源在最低输入电压(比如85VAC)下,各项指标都调得…...
SVPWM算法MATLAB仿真进阶:从模型搭建到代码生成)
stm32 FOC从学习开发(七)SVPWM算法MATLAB仿真进阶:从模型搭建到代码生成
1. SVPWM算法仿真与代码生成全流程 搞电机控制的朋友都知道,SVPWM(空间矢量脉宽调制)是FOC(磁场定向控制)的核心算法之一。前几期我们聊过Clark变换、Park变换,也讲过SVPWM的基本原理,今天咱们就…...

英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作
英雄联盟终极自动化工具:LeagueAkari 免费完整指南,告别繁琐操作 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否…...

【Midjourney钯金印相风格终极指南】:20年影像工艺专家亲授——从化学印相原理到AI提示词精准转译的7步闭环工作流
更多请点击: https://intelliparadigm.com 第一章:钯金印相工艺的百年历史溯源与数字复兴语境 钯金印相(Platinum/Palladium Printing)诞生于19世纪末,是摄影史上最具质感与耐久性的手工印相工艺之一。其以铂族金属盐…...

Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程
Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/…...