2013年国赛高教杯数学建模C题古塔的变形解题全过程文档及程序
2013年国赛高教杯数学建模
C题 古塔的变形
由于长时间承受自重、气温、风力等各种作用,偶然还要受地震、飓风的影响,古塔会产生各种变形,诸如倾斜、弯曲、扭曲等。为保护古塔,文物部门需适时对古塔进行观测,了解各种变形量,以制定必要的保护措施。
某古塔已有上千年历史,是我国重点保护文物。管理部门委托测绘公司先后于1986年7月、1996年8月、2009年3月和2011年3月对该塔进行了4次观测。
请你们根据附件1提供的4次观测数据,讨论以下问题:
1. 给出确定古塔各层中心位置的通用方法,并列表给出各次测量的古塔各层中心坐标。
2. 分析该塔倾斜、弯曲、扭曲等变形情况。
3. 分析该塔的变形趋势。
整体求解过程概述(摘要)
本文要求根据测绘公司对古塔的4次测量数据,给出确定古塔各层中心位置的通用方法,并分析古塔的变形情况及其变形趋势。为了计算的精度,我们首先对各变形量进行了合理的数学定义,并对附录的缺失数据进行合理的赋值。
对于问题一,我们通过最小二乘法拟合出观测点所在平面,再建立优化模型,在拟合平面上寻找到各观测点距离的平方和最小的点作为古塔该层的中心点。利用MATLAB编程求解,得到了每次观测古塔各层中心坐标的通用方法及各层的中心点坐标。
对于问题二,我们将古塔的倾斜、弯曲和扭曲等变形情况,分别给予合理的数学描述。对于倾斜变形,我们定义了倾斜角α,即塔尖与底层中心的水平距离与塔高的比值;对于弯曲变形,我们定义了弯曲率K,即用中心点所拟合出的空间曲线的曲率来描述古塔各处弯曲率;对于扭曲变形,我们定义了相对扭曲度θ,利用坐标的旋转变换角度描述古塔的扭曲变形情况。利用空间曲线拟合、坐标变换等方法以及MATLAB程序,分别求出了三个变形刻画量的量化指标。
对于问题三,我们考虑通过古塔的倾斜、弯曲及扭曲程度来分析古塔的变形趋势。由于数据量较少,我们建立灰色预测模型分析这三种变形因素的变化趋势,利用相应的MATLAB程序,得到了倾斜角、弯曲率以及相对扭曲度的预测函数和误差检验,验证了模型的可靠性,并继而分析古塔的变形趋势。
本文巧妙地将各种变形量给予了合理的数学描述及模型,并运用最小二乘法、曲线投影拟合、坐标变换等数学方法实现了求解,并利用灰色预测对未来变形趋势进行了预测,具有较好的实用性和可推广性。
模型假设:
1.由于中国古代建筑物多为对称图形,假设古塔是对称的。
2.假设每次古塔的测量点选取是固定的。
3.假设测量数据都是准确可靠的。
4.假设古塔的变形只由倾斜、弯曲和扭曲变形造成,不考虑其他因素。
问题分析:
问题一要求确定古塔各层中心位置的通用方法。根据建筑变形测量规范,在建筑物变形测量中,为更好地测量出建筑物变形程度的各个指标,我们假设每次测量应选取固定的测量点,且在同一层所选取的测量点在未变形前处于同一个水平面上。而经过对各层观测点三维散点图的绘制发现,各层的八个点近似对称地分布在一个平面上,只是因为年代久远发生变形导致了些许偏差。因此为了更准确地找出各层中心点,我们考虑先利用最小二乘法拟合出各层观测点所在的平面方程,再建立优化模型在该平面上寻找一点使其到各观测点距离的平方和最小,以此确立古塔各层中心坐标。
问题二要求分析古塔的各种变形情况。根据《中华人民共和国行业标准建筑变形测量规范(JGJ8—2007)》知,变形是建筑的地基、基础、上部结构及其场地受各种作用力而产生的形状或位置变化现象。在本问中,我们主要分析古塔三种主要的变形情况:倾斜、弯曲、扭曲。对于倾斜变形,我们定义倾斜角α进行描述 ,其正切值等于塔尖与底层中心的水平距离与塔高的比值,即tanα=d/h ;对于弯曲变形,我们首先通过投影法拟合出古塔各层中心点所在空间曲线的参数方程,再利用空间曲线的曲率来刻画古塔的弯曲度K;对于扭曲变形,考虑到扭曲变形实际为古塔水平面的旋转产生,因此我们采用二维坐标( x, y)旋转的矩阵变换,通过各观测量点前后的坐标确定古塔的旋转角度θ,以此刻画古塔的扭曲度。但是,实际中水平面坐标( x, y)不仅发生了旋转变换,还受到倾斜弯曲变形等所引起的平移变化的影响,因此我们在考虑坐标变换的时候加入了平移量( p,q )使其更加准确合理。
问题三为分析古塔的变形情况。本文中,我们认为建筑物变形由建筑物的倾斜、弯曲、扭曲等因素共同造成。由于附录只给出了四次统计的数据,而我们的目标是分析古塔未来多年的变化趋势,因此我们采用信息不完全、不充分的预测系统——灰色预测对古塔未来的变形趋势进行预测。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
clc,clear
x0=[0.0141,0.0142,0.0146,0.0147];%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
clc
clear
x1=[0.000141404 0.000121639 0.000089860 0.000056555];
x2=[0.000141405 0.000121641 0.000089920 0.000056556 ];
x3=[0.000141406 0.000121642 0.000089977 0.000056556 ];
x4=[0.000141407 0.000121643 0.000090030 0.000056557 ];
x5=[0.000141408 0.000121644 0.000090089 0.000056557 ];
x6=[0.000141408 0.000121645 0.000090149 0.000056558 ];
x7=[0.000141409 0.000121646 0.000090200 0.000056558 ];
x8=[0.000141409 0.000121646 0.000090250 0.000056558 ];
x9=[0.000141409 0.000121647 0.000090301 0.000056559 ];
x10=[0.000141409 0.000121647 0.000090352 0.000056559 ];
x11=[0.000141408 0.000121648 0.000090417 0.000056559 ];
x12=[0.000141408 0.000121648 0.000090486 0.000056560 ];
x13=[0.000141408 0.000121648 0.000090555 0.000056560 ];
x14=[0.000141407 0.000121648 0.000090599 0.000056560 ];x0=x1(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a1(1,:)=x0;
a1(2,:)=x0_hat;
a1(3,:)=epsilon;
a1(4,:)=delta;x0=x2(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a2(1,:)=x0;
a2(2,:)=x0_hat;
a2(3,:)=epsilon;
a2(4,:)=delta;x0=x3(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a3(1,:)=x0;
a3(2,:)=x0_hat;
a3(3,:)=epsilon;
a3(4,:)=delta;x0=x4(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a4(1,:)=x0;
a4(2,:)=x0_hat;
a4(3,:)=epsilon;
a4(4,:)=delta;x0=x5(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a5(1,:)=x0;
a5(2,:)=x0_hat;
a5(3,:)=epsilon;
a5(4,:)=delta;x0=x6(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a6(1,:)=x0;
a6(2,:)=x0_hat;
a6(3,:)=epsilon;
a6(4,:)=delta;x0=x7(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a7(1,:)=x0;
a7(2,:)=x0_hat;
a7(3,:)=epsilon;
a7(4,:)=delta;x0=x8(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a8(1,:)=x0;
a8(2,:)=x0_hat;
a8(3,:)=epsilon;
a8(4,:)=delta;x0=x9(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a9(1,:)=x0;
a9(2,:)=x0_hat;
a9(3,:)=epsilon;
a9(4,:)=delta;x0=x10(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a10(1,:)=x0;
a10(2,:)=x0_hat;
a10(3,:)=epsilon;
a10(4,:)=delta;x0=x11(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a11(1,:)=x0;
a11(2,:)=x0_hat;
a11(3,:)=epsilon;
a11(4,:)=delta;x0=x12(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a12(1,:)=x0;
a12(2,:)=x0_hat;
a12(3,:)=epsilon;
a12(4,:)=delta;x0=x13(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a13(1,:)=x0;
a13(2,:)=x0_hat;
a13(3,:)=epsilon;
a13(4,:)=delta;x0=x14(1,:);%原始数据序列
n=length(x0);
a_x0=diff(x0)';%求1次累减序列,即1阶向前差分
B=[-x0(2:end)',ones(n-1,1)];
u=B\a_x0%最小二乘拟合参数
x=dsolve('D2x+a*Dx=b','x(0)=c1,Dx(0)=c2');%求二阶微分方程的符号解
x=subs(x,{'a','b','c1','c2'},{u(1),u(2),x0(1),x0(1)});
yuce=subs(x,'t',0:n-1)%求已知数据点1次累加序列的预测值
x=vpa(x,6)
x0_hat=[yuce(1),diff(yuce)]%求已知数据点的预测值
epsilon=x0-x0_hat%求残差
delta=abs(epsilon./x0)%求相对误差
a14(1,:)=x0;
a14(2,:)=x0_hat;
a14(3,:)=epsilon;
a14(4,:)=delta;
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2013年国赛高教杯数学建模C题古塔的变形解题全过程文档及程序
2013年国赛高教杯数学建模 C题 古塔的变形 由于长时间承受自重、气温、风力等各种作用,偶然还要受地震、飓风的影响,古塔会产生各种变形,诸如倾斜、弯曲、扭曲等。为保护古塔,文物部门需适时对古塔进行观测,了解各种变…...

web 0基础第一节 文本标签
这是一个html文件的基本结构 在vs code 中使用英文的 ! 可快捷设置这样的结构 <!-- --> 是在html写注释的结构 <!DOCTYPE html> <!--标识当前文档类型为html--> <html> …...

Zookeeper快速入门:部署服务、基本概念与操作
文章目录 一、部署服务1.下载与安装2.查看并修改配置文件3.启动 二、基本概念与操作1.节点类型特性总结使用场景示例查看节点查看节点数据 2.文件系统层次结构3.watcher 一、部署服务 1.下载与安装 下载: 一定要下载编译后的文件,后缀为bin.tar.gz w…...

【Sqlite】sqlite内部函数sqlite3_value_text特性
目录 ⚛️1 结论 ☪️2 说明 ☪️3 传入数值转成科学计数法 ♋3.1 只有整数部分 ♏3.2 只有小数部分 ♐3.3 整数小数 ⚛️1 结论 整数(sqlite视为int64)位数 > 20位,sqlite3_value_text 采用科学计数法。否则正常表示。 浮点数(sqlite视为double)的整数部…...

树莓派应用--AI项目实战篇来啦-4.OpenCV读取、写入和显示视频
1. 介绍 视频是由一张一张图片组成的,所以读取视频就相当于读取很多张图片,然后将其连起来cv2.VideoCapture可以捕获摄像头,但是针对树莓派的CSI摄像头调用方式采用了之前介绍的Picamera2 库,所以在调用的时候是有区别的ÿ…...

智能电子后视镜,汽车驾驶更安全,会是一种趋势
相比于传统的后视镜,智能电子后视镜的确有很多的优点。在下雨天和夜晚场景,电子后视镜可以说是表现优秀。 我之前一直以为我们国内是有规定不能使用电子后视镜。没想到,偶然刷到享界S9的视频,这电子后视镜,妥妥的给安排…...

IEC104规约的秘密之九----链路层和应用层
104规约从TCP往上,分成链路层和应用层。 如图,APCI就是链路层,ASDU的就是应用层 我们看到报文都是68打头的,因为应用层报文也要交给链路层发送,链路层增加了开头的6个字节再进行发送。 完全用于链路层的报文每帧都只有…...

最新Prompt预设词指令教程大全ChatGPT、AI智能体(300+预设词应用)
使用指南 直接复制在AI工具助手中使用(提问前) 可以前往已经添加好Prompt预设的AI系统测试使用(可自定义添加使用) SparkAi系统现已支持自定义添加官方GPTs(对专业领域更加专业,支持多模态文档࿰…...

DockerCompose 启动 open-match
背景介绍 open-match是Google和unity联合开源的支持实时多人匹配的框架,已有多家游戏厂商在生产环境使用,官网 https://open-match.dev/site/ 。原本我们使用的是UOS上提供的匹配能力,但是UOS目前不支持自建的Dedicated servers 集群&#x…...

Chainlit集成Dashscope实现语音交互网页对话AI应用
前言 本篇文章讲解和实战,如何使用Chainlit集成Dashscope实现语音交互网页对话AI应用。实现方案是对接阿里云提供的语音识别SenseVoice大模型接口和语音合成CosyVoice大模型接口使用。针对SenseVoice大模型和CosyVoice大模型,阿里巴巴在github提供的有开…...

Canal 扩展篇(阿里开源用于数据同步备份,监控表和表字段(日志))
1.Canal介绍 Canal把自己伪装成从数据库,获取mysql主数据库的日志(binlog)信息,所以要想使用canal就得先开启数据库日志 https://github.com/alibaba/canal Canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量…...
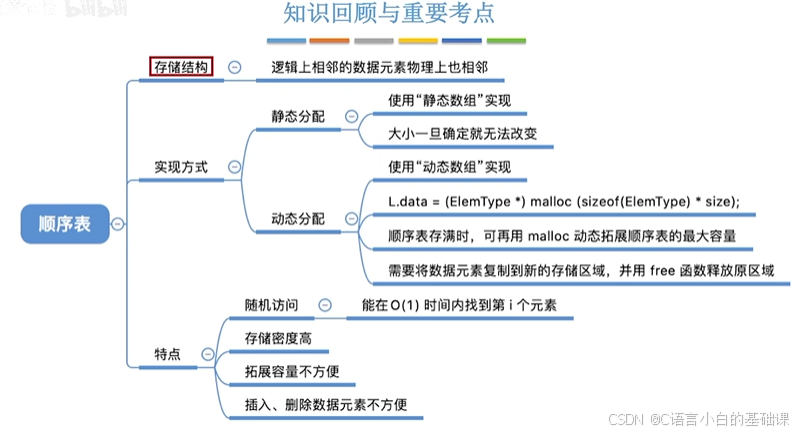
顺序表的定义
一.顺序表的定义 顺序表--用顺序存储的方式实现线性表 顺序存储。把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关 系由存储单元的邻接关系来体现。 二.顺序表的实现--静态分配 #include<stdio.h> #define MaxSize 10 //定义最大长度 …...

青少年编程能力等级测评CPA C++一级试卷(1)
青少年编程能力等级测评CPA C一级试卷(1) 一、单项选择题(共20题,每题3.5分,共70分) CP1_1_1.在C中,下列变量名正确的是( )。 A.$123 B&#…...

R语言中的plumber介绍
R语言中的plumber介绍 基本用法常用 API 方法1. GET 方法2. POST 方法3. 带路径参数的 GET 方法 使用 R 对数据进行操作处理 JSON 输入和输出运行 API 的其他选项其他功能 plumber 是个强大的 R 包,用于将 R 代码转换为 Web API,通过使用 plumber&#x…...

uniapp 设置 tabbar 的 midButton 按钮
效果展示: 中间的国际化没生效(忽略就行) 示例代码: 然后在 App.vue 中进行监听: <script>export default {onLaunch(e) {// #ifdef APPuni.onTabBarMidButtonTap(()>{console.log("中间按钮点击回调…...

php 生成随机数
记录:随机数抽奖 要求:每次生成3个 1 - 10 之间可重复(或不可重复)的随机数,10次为一轮,每轮要求数字5出现6次、数字4出现3次、…。 提炼需求: 1,可设置最小数、最大数、每次抽奖生成随机数的个数、是否允许重复 2,可设置每轮指定数字的出现次数 3,可设置每轮的抽奖…...
MySQL 8.4修改初始化后的默认密码
MySQL 8.4修改初始化后的默认密码 (1)初始化mysql: mysqld --initialize --console (2)之后,mysql会生成一个默认复杂的密码,如果打算修改这个密码,可以先用旧密码登录: mysql -u…...

前端开发笔记--css 黑马程序员1
文章目录 1. css 语法规范2.css的书写风格3.基础选择器选择器的分类标签选择器类选择器类选择器的特殊使用--多类名 id 选择器 字体属性常见字体字体大小字体粗细字体倾斜字体的复合简写字体属性总结 文本属性文本颜色文本对齐装饰文本文本缩进文本间距文本属性总结 css的引入方…...

ORACLE 19C创建多个不同字符集PDB
现在需要在一个测试环境创建1个为AL32UTF8的PDB,2个ZHS16GBK的PDB 这种情况下,必须先创建的CDB为AL32UTF8,下面是具体步骤: 1.AL32UTF8的pdb在建实例的时候一起创建完成 2.创建第一个ZHS16GBK的PDB cdr,通过pdbseed来克隆: SQL> create pluggable database cdr admin us…...

基于协同过滤的景区旅游可视化与景区推荐系统(自动爬虫,地点可换)
文章目录 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主项目介绍过程展示项目移植每文一语 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主 项目介绍 本项目是一个综合性的旅游景区数据管理与分析推荐系统,集成了用…...

Java——线程的中断
线程的中断1、取消/关闭的场景2、取消/关闭的机制3、线程对中断的反应3.1、Runnable3.2、Waiting/Timed_Waiting3.3、Blocked3.4、New/Terminate4、如何正确地取消/关闭线程1、取消/关闭的场景 我们知道,通过线程的start方法启动一个线程后,线程开始执行…...

极简黑魔法:用 gh gist 搭建我们的私有配置分发 CDN
在多端协作的时代,我们经常需要在 PC、手机和路由器之间同步一些私密的订阅配置(如应用服务配置文件,凭据等)。 如果使用公共 Gist 会有隐私泄露风险;维护一个私有 Git 仓库又需要处理复杂的 API Token 鉴权࿰…...

3个思维转变:用Obsidian Homepage打造你的第二大脑控制中心
3个思维转变:用Obsidian Homepage打造你的第二大脑控制中心 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 你是否曾…...

Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析
Android跨平台文件同步技术实现:WebDAV桥接工具架构深度解析 【免费下载链接】webdav-provider An Android app that can expose WebDAV storage to other apps through Androids Storage Access Framework (SAF) 项目地址: https://gitcode.com/gh_mirrors/we/we…...

Live Server深度解析:如何用实时重载技术提升前端开发效率300%
Live Server深度解析:如何用实时重载技术提升前端开发效率300% 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-se…...

HBuilderX网站打包APP
下载HBuilderX安装包官网地址:https://www.dcloud.io/ 选择HBuilderX极客开发工具 点击DOWNLOAD 点击历史版本,这里为什么不下载最新的版本,是因为我一开始下载的最新版本,打包一直提示cannot find module babel-core 将HBuilder…...

ElevenLabs藏文语音生成上线仅72小时:开发者必须立即掌握的5个API调用避坑要点
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs藏文语音生成上线背景与技术意义 藏语作为中国官方认可的少数民族语言之一,拥有超过600万母语使用者,主要分布在西藏、青海、四川、甘肃和云南等地区。长期以来&…...

深入解析 magic-cli:基于模板的自动化代码生成工具设计与实践
1. 项目概述:一个能“变魔术”的命令行工具最近在折腾一些自动化脚本和项目脚手架时,发现了一个挺有意思的开源项目,叫magic-cli。乍一看这个名字,你可能会觉得有点玄乎,命令行工具还能玩出什么“魔法”来?…...
)
告别单调列表!用Unity Dropdown组件打造游戏中的动态交互式菜单(附事件处理完整代码)
告别单调列表!用Unity Dropdown组件打造游戏中的动态交互式菜单(附事件处理完整代码) 在独立游戏开发中,UI交互的细腻程度往往决定了玩家的沉浸感。想象一下:当玩家在角色创建界面选择职业时,下拉菜单不仅显…...

音频处理中的头部空间标准化:原理、工具与工程实践
1. 项目概述:一个为音频处理而生的“头部空间”工具如果你经常处理音频,尤其是人声干音,那你一定对“头部空间”这个概念不陌生。简单来说,它指的是人声录音中,人声峰值电平与数字满刻度(0 dBFS)…...