『Mysql进阶』Mysql explain详解(五)
目录
Explain 介绍
Explain分析示例
explain中的列
1. id 列
2. select_type 列
3. table 列
4. partitions 列
5. type 列
6. possible_keys 列
7. key 列
8. key_len 列
9. ref 列
10. rows 列
11. filtered 列
12. Extra 列
Explain 介绍
EXPLAIN 语句提供有关 MySQL 如何执行语句的信息,使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈 。
我们根据 MySQL 的慢查询去记录一些执行时间比较久的SQL语句, 然后使用explain命令来查看这些SQL语句的执行计划, 根据执行计划内容,判断该SQL语句有没有使用上索引, 有没有做全表扫描等, 进而排查出SQL执行慢的原因。
官网介绍
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
Explain分析示例
-
CREATE TABLE `actor` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(45) NOT NULL,`create_time` datetime DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `uk_name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `actor` (`id`, `name`, `create_time`) VALUES (1,'a',NOW()), (2,'b',NOW()), (3,'c',NOW());CREATE TABLE `film` (`id` int(11) NOT NULL AUTO_INCREMENT,`actor_id` int(11) NOT NULL,`name` varchar(10) DEFAULT NULL,`create_time` datetime DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_actorid` (`actor_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `film` (`id`, `actor_id`, `name`, `create_time`) VALUES (1,1,'一路向东',NOW());
explain中的列
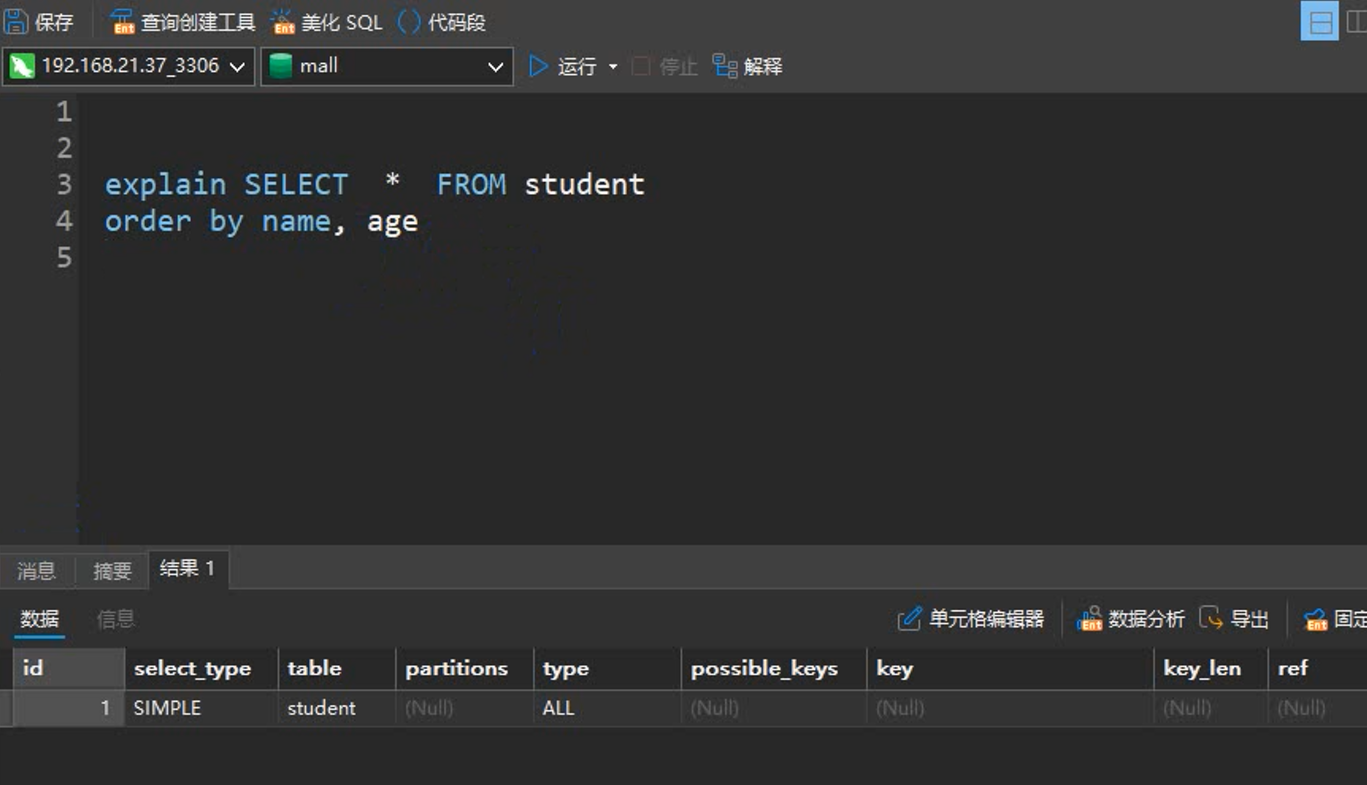
explain select * from actor;
1. id 列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。id列越大执行优先级越高,id相同则从上往下执行。
- id 相同,按table列由上至下顺序执行
- id 不同,如果是子查询,id的序号会递增,id的值越大优先级越高,越先被执行。
- id 想通不同同时存在,id如果相同,可以认为是一组,(本组内)从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行。
- 当使用union时,id会出现NULL值,同时table列会出现<unionM,N>的值,其表示id的值为M和N的行的联合。
2. select_type 列
表示对应行是简单还是复杂的查询。
-
simple:简单查询。查询不包含子查询和union

-
primary:复杂查询中最外层的 select
-
subquery:包含在 select 中的子查询(不在 from 子句中)

-
derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)

- union:在 union 中的第二个和随后的 select

- union result: 从union表获取结果的select, UNION的结果集
- dependent union: UNION UNIONUNION中的第二个或以后的SELECT的SELECT的SELECT语句,取决于外部查询
-
dependent subquery: 子查询中的第一个SELECT,依赖于外部查询,表示这个subquery的查询要受到外部表查询的影响

3. table 列
这一列表示 explain 的一行正在访问哪个表。
它也可以是以下值之一:
<union:行引用M,N>ID值为M和N的行的并集。<derived:该行引用N>ID值为N的行的派生表结果。派生表可以由例如FROM子句中的子查询产生。- <subquery
N>:该行引用ID值为N的行的具体化子查询的结果。
4. partitions 列
使用的哪些分区(对于非分区表值为null)。
5. type 列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:
system > const > eq_ref > ref >fulltext >ref_or_null >unique_subquery>index_subquery> range > index_merge>index > ALL
一般来说,得保证查询达到range级别,最好达到ref
explain select min(id) from actor
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表.
-
system: 表中只有一行数据或者是空表。等于系统表,这是const类型的特列,平时不会出现,可以忽略不计 .
-
const : 使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type 是const。其他数据库也叫做唯一索引扫描。
explain select * from actor where id=1;
- eq_ref: primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能是在const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。在连接表,被驱动表会出现.
explain select * from actor a JOIN film b on a.id=b.actor_id
- ref : 相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
explain select * from film where actor_id=1
- fulltext : 全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时, mysql不管代价,优先选择使用全文索引 .
- ref_or_null : 与ref方法类似,只是增加了null值的比较。实际用的不多。
- unique_subquery: 用于where中的in形式子查询,子查询返回不重复值唯一值
- index_subquery: 用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复 值,可以使用索引将子查询去重。
- range : 范围扫描通常出现在 in(), between ,> ,= 等操作中。使用一个索引来检索给定范围的行。
explain select * from actor where id >=1 and id <=3;
- index_merge: 表示查询使用了两个以上的索引,最后取交集或者并集,常见 and , or 的条件使 用了不同的索引.
- index : 扫描全索引就能拿到结果,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。(全叶子索引扫描,扫描的是二级索引)
explain select actor_id from film;
-
ALL:即全表扫描,扫描你的聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。
explain select * from film;
6. possible_keys 列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
7. key 列
查询真正使用到的索引
8. key_len 列
显示MySQL决定使用的索引size
key_len 计算规则:
- 索引字段,非NOT NULL,加1个字节。
- 定长字段:tinyint占1个字节、smallint占2个字节、int占4个字节、bitint占8个字节、date占3个字节、timestamp占4个字节,datetime占8个字节,char(n)占n个字符。
- 变长字段:varchar(n)占n个字符+2个字节。
- 不同的字符集,一个字符占用的字节数不同:
- latin1编码,每个字符占用一个字节
- gbk编码,每个字符占用两个字节
- utf8编码,每个字符占用三个字节
- utf8mb4编码,每个字符占用四个字节
例子
字段:phone varchar(20) DEFAULT NULL COMMENT ‘手机号’
条件:where phone=‘xxx’
通过explain查看key_len
utf8mb4编码下,key_len=83,即20*4+2+1
utf8编码下,key_len=63,即20*3+2+1
9. ref 列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id)
10. rows 列
显示此查询一共扫描了多少行,这个是一个估计值,不是精确的值。
11. filtered 列
表示此查询条件所过滤的数据的百分比
12. Extra 列
这一列展示的是额外信息。常见的重要值如下:
-
Using where:使用 where 语句来处理结果,表示MySQL将对InnoDB提取的结果在SQL Layer层进行过滤,过滤条件字段无索引;
explain select * from film where name='一路向东';
-
Using index:使用覆盖索引-----不会回表
覆盖索引定义:mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说是用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值
explain select actor_id from film where actor_id=1;
- Using index condition: 用不了索引, 但用了索引下推优化,使之可以使用到索引.
explain select * from film where actor_id>=1;
- Using temporary: mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。(先扫描出来放在临时表,然后再去重)
explain select DISTINCT name from film;
-
Using filesort:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一般也是要考虑使用索引来优化的。
explain select * from film ORDER BY name;
- Using join buffer (Block Nested Loop):在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫join buffer的内存块来加快查询速度 .
相关文章:
『Mysql进阶』Mysql explain详解(五)
目录 Explain 介绍 Explain分析示例 explain中的列 1. id 列 2. select_type 列 3. table 列 4. partitions 列 5. type 列 6. possible_keys 列 7. key 列 8. key_len 列 9. ref 列 10. rows 列 11. filtered 列 12. Extra 列 Explain 介绍 EXPLAIN 语句提供有…...

【工具】音视频翻译工具基于Whisper+ChatGPT
OpenAI推出的开源语音识别工具Whisper,以其卓越的语音识别能力,在音频和视频文件处理领域大放异彩。与此同时,ChatGPT也在翻译领域崭露头角,其强大的翻译能力备受赞誉。因此,一些字幕制作团队敏锐地捕捉到了这两者的结…...

学成在线——关于nacos配置优先级的坑
出错: 本地要起两个微服务,一个是content-api,另一个是gateway网关服务。 发现通过网关服务请求content微服务时,怎么请求都请求不到。 配置如下: content-api-dev.yaml的配置: server:servlet:context-p…...

Nginx在Windows Server下的启动脚本
Nginx在Windows Server下的快捷运行脚本 使用时记得修改NGINX_DIR路径 ECHO OFF CHCP 65001 SET NGINX_DIRD:\software\Nginx\ color 0a TITLE Nginx Management GOTO MENU :MENU CLS ECHO. ECHO. * * * * Nginx Management * * * * * * * * * * * ECHO. * * EC…...

【国科大】C++程序设计秋季——五子棋
【国科大】C程序设计秋季 —— 五子棋程序 下载地址:https://mbd.pub/o/bread/Zp2Ukptx...

Docker 环境下多节点服务器监控实战:从 Prometheus 到 Grafana 的完整部署指南
Docker 环境下多节点服务器监控实战:从 Prometheus 到 Grafana 的完整部署指南 文章目录 Docker 环境下多节点服务器监控实战:从 Prometheus 到 Grafana 的完整部署指南一 多节点部署1 节点一2 节点二3 节点三 二 监控节点部署三 配置 prometheus.yml四 …...

【动手学深度学习】6.3 填充与步幅(个人向笔记)
卷积的输出形状取决于输入形状和卷积核的形状在应用连续的卷积后,我们最终得到的输出大小远小于输入大小,这是由于卷积核的宽度和高度通常大于1导致的比如,一个 240 240 240240 240240像素的图像,经过10层 5 5 55 55的卷积后&am…...

【宝可梦】游戏
pokemmo https://pokemmo.com/zh/ 写在最后:若本文章对您有帮助,请点个赞啦 ٩(๑•̀ω•́๑)۶...

docker启动的rabbitmq如何启动其SSL功能
docker run --hostname my-rabbit --name my-rabbit -p 5671:5671 -p 15671:15671 -p 15672:15672 -e RABBITMQ_DEFAULT_USERabc -e RABBITMQ_DEFAULT_PASSabc -d rabbitmq:4.0-management 使用docker的复制命令将ca.crt、server.crt和server.key文件复制到容器的/etc/server_s…...

易基因: cfMeDIP-seq揭示cfDNA甲基化高效区分原发性和转移性前列腺|Nat Commun
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 前列腺癌(Prostate cancer,PCa)是男性中第二常见的恶性肿瘤,也是全球癌症相关死亡的第三大原因。虽然大多数原发性前列腺癌可以治愈&#…...

CMake 教程跟做与翻译 4
目录 添加一个option! 添加一个option! option,正如其意,就是选项的意思。我们这里需要演示一下option的做法。 option对于大型的工程必然是非常常见的:一些模块会被要求编译,另一些客户不准备需要这些模块。option就是将这种需…...
MySQL面试题分享
慢日志(了解) 慢日志开启的变量:slow_query_logON; 如果值为 OFF ,那就是没有开启慢日志 耗时: long_query_time,默认是10秒 redis 和 mysql 慢日志的区别 redis 慢日志默认是没有开启的 mysql 慢日志默认是开启的…...

vue路由缓存问题
什么是路由缓存问题 解决方案: 让组件实例不再复用,强制销毁重建监听路由变化,变化之后执行数据更新操作 方法一 给 routerv-view 添加key属性,强制不添加缓存,破坏缓存,所以这个方法性能会比较差 <Ro…...

RabbitMQ中如何解决消息堆积问题,如何保证消息有序性
RabbitMQ中如何解决消息堆积问题 如何保证消息有序性 只需要让一个消息队列只对应一个消费者即可...

python爬虫案例——selenium爬取淘宝商品信息,实现翻页抓取(14)
文章目录 1、任务目标2、网页分析3、代码编写3.1 代码分析3.2 完整代码1、任务目标 目标网站:淘宝(https://www.taobao.com/) 任务要求:通过selenium实现自动化抓取 淘宝美食 板块下的所有商品信息,并实现翻页抓取,最后以csv格式将数据保存至本地;如: 2、网页分析 首先…...

在VSCode中使用Excalidraw
概述 Excalidraw是一款非常不错的示意图绘制软件,没想到在VSCode中有其扩展,可以在VScode中直接使用。 安装扩展 使用 需要创建.excalidraw.svg、.excalidraw或.excalidraw.png等名称的文件。 搭配手写版使用 自由画笔工具可以配合手写板,…...
25中国投资中投笔试测评秋招校招SHL笔试题型分享
✅中投公司不必过多介绍,和建总都位于金融央企第一档,但是招人更少,竞争更为激烈,看公示录用名单都是清北的金融硕士,投资岗难度更大。 ✅中投公司的笔试往年都是shl系统,但考察范围非常广,包含…...

【LeetCode热题100】分治-快排
本篇博客记录分治快排的4道题目:颜色分类、排序数组、数组中的第K个最大元素、数组中最小的N个元素(库存管理)。 class Solution { public:void sortColors(vector<int>& nums) {int n nums.size();int left -1,right n;for(int…...

Docker 教程四 (Docker 镜像加速)
Docker 镜像加速 国内从 DockerHub 拉取镜像有时会遇到困难,此时可以配置镜像加速器。 目前国内 Docker 镜像源出现了一些问题,基本不能用了,后期能用我再更新下。* Docker 官方和国内很多云服务商都提供了国内加速器服务,例如…...

各类排序详解
前言 本篇博客将为大家介绍各类排序算法,大家知道,在我们生活中,排序其实是一件很重要的事,我们在网上购物,需要根据不同的需求进行排序,异或是我们在高考完报志愿时,需要看看院校的排名&#…...

ORTC与AI融合:从实时传输到智能通信的架构演进与实践
1. 项目概述:当实时通信遇上人工智能最近几年,我身边不少做音视频通信和做AI算法的朋友,聊天时总绕不开一个话题:ORTC(Object Real-Time Communication)和AI,这两者到底能擦出什么样的火花&…...

在多模型AI应用开发中利用Taotoken实现成本与性能的平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型AI应用开发中利用Taotoken实现成本与性能的平衡 开发一个复杂的AI应用,往往意味着需要调用多个模型来完成不同…...

G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制
G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

CherryUSB嵌入式USB协议栈终极指南:从入门到精通
CherryUSB嵌入式USB协议栈终极指南:从入门到精通 【免费下载链接】CherryUSB CherryUSB is a tiny and beautiful, high performance and portable USB host and device stack for embedded system with USB IP 项目地址: https://gitcode.com/gh_mirrors/ch/Cher…...

从公式到代码:傅里叶级数系数的完整推导与实现
1. 从三角函数到傅里叶级数:数学基础回顾 第一次接触傅里叶级数时,我被那一堆积分符号和三角函数搞得头晕眼花。后来才发现,理解它的关键其实藏在高中数学课本里——那些看似简单的三角函数公式,正是打开傅里叶变换大门的钥匙。 让…...

终极指南:使用Tinke轻松探索和修改NDS游戏资源
终极指南:使用Tinke轻松探索和修改NDS游戏资源 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经好奇任天堂DS游戏内部是如何组织的?想要提取游戏中的精美图片、动…...

Python实战:从时序数据到ARIMA预测的完整建模指南
1. 时间序列分析与ARIMA模型入门 时间序列分析就像是一位经验丰富的老中医把脉——通过观察数据随时间变化的"脉搏",我们能诊断出背后的规律并预测未来走势。ARIMA模型正是其中最经典的"听诊器"之一,我在处理销售预测、库存管理等项…...
)
【故障诊断】DSCNN-HA-TL:融合Swin窗口注意力和全局注意力机制的变工况轴承故障诊断(迁移学习/小样本)
在工业旋转机械中,滚动轴承是最关键、也最容易发生故障的部件之一。然而,变工况、故障样本稀缺、跨域泛化能力差三大难题,长期制约着故障诊断模型的落地效果。 近期,来自河北工程大学、天津大学等机构的研究团队提出了一种全新的…...

Termux零门槛部署Kali:从命令行到可视化桌面的完整实践
1. 为什么要在手机上部署Kali Linux? 几年前我第一次听说能在手机上运行Kali Linux时,第一反应是"这玩意儿能用吗?"。但当我真正尝试后才发现,这种便携式的渗透测试环境简直太香了!想象一下,在地…...

LLM资源库:大语言模型开发者的高效导航与实战指南
1. 项目概述:一个汇聚LLM资源的“藏宝图”在人工智能,特别是大语言模型(LLM)领域,技术迭代的速度快得让人眼花缭乱。每天都有新的模型发布、新的工具开源、新的论文发表。对于开发者、研究者甚至是刚入门的学习者来说&…...