各类排序详解
前言
本篇博客将为大家介绍各类排序算法,大家知道,在我们生活中,排序其实是一件很重要的事,我们在网上购物,需要根据不同的需求进行排序,异或是我们在高考完报志愿时,需要看看院校的排名,等等这些都离不开排序;今天我们就来看计算机语言中几类常见的排序算法,如果你对本文感兴趣,欢迎留言交流,下面进入正文部分。

Comparison Sorting Visualization
大家可以通过这个网址来查看各种排序的动图,以便于大家理解。
1.直接插入排序
这个顾名思义,就是将数据取出来比较,然后再插入合适的位置以达到有序的效果;这个就类似于我们玩的扑克牌,当我们摸到拍时,我们需要按照扑克牌的规则对其进行有效的排序,这里其实就是运用了插入排序的思想。
上面介绍了什么是插入排序,下面大家来看看具体代码。
void InsertSort(int* a, int n)
{int i = 0;for (i = 0; i < n - 1; i++)//这里循环的结束条件需要注意,我们最后一组是a[n-1]=a[n-2]{int end = i;//假设[0,end]有序,现在将end+1位置的值插入到[0,end],保持有序int tmp = a[end + 1];//这里需要先保存end+1位置的值,否则挪动的时候就会覆盖掉后面的数据while (end >= 0){if (a[end] > tmp){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}
直接插入排序的特性总结:
1. 元素集合越接近有序,直接插入排序算法的时间效率越高
2. 时间复杂度:O(N^2)(最坏情况),O(N)(最好情况)
3. 空间复杂度:O(1),它是一种稳定的排序算法
4. 稳定性:稳定
插入排序比起我们之前学过的冒泡排序效率是要高不少的,在实践中我们会用到插入排序,所以大家需要掌握插入排序的写法。
2. 希尔排序
希尔排序是一种比较复杂的排序方法,但是它的效率是比较高的,可以说它是选择排序的一种优化,所以我们必须先理解好插入排序;
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先进行预排序,然后再进行插入排序。

预排序阶段,我们会先定义一个gap,表示一次跳过的间隔,这里其实大家可以根据插入排序去理解gap,当gap等于1时,其实就变成了插入排序。
这里大家需要明确:
gap越大,大数可以越快跳到前面,小数可以越快跳到后面,但是结果越不接近有序;
gap越小,则反之。所以我们需要让gap成为一个变量。
#include<stdio.h>
void ShellSort(int* a,int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;//这里+1是为了让gap最终等于1//当gap>1时,执行的是预排序//当gap==1时,执行的就是插入排序for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
这里大家注意与插入排序进行对比,代码的逻辑和插入排序是类似的;这里还有一点需要大家注意,就是希尔排序的时间复杂度:O(n^1.3),这个结果大家记忆即可。
3. 选择排序
这个排序属于比较简单的一种排序,基本思想就是找出最大的放后面,找出最小的放前面,然后重复上述过程即可,从这里大家其实就可以感受到这个算法的效率是比较低的,在实践中我们一般是不用它来进行排序的。
void SelectSort(int* a, int n)
{int begin = 0;int end = n - 1;while (begin < end){int mini = begin;int maxi = begin;for (int i = begin + 1; i <= end; i++){if (a[i] > a[maxi]){maxi = i;}if (a[i] < a[mini]){mini = i;}}Swap(&a[begin], &a[mini]);if (maxi == mini){maxi = mini;}Swap(&a[end], &a[maxi]);begin++;end--;}
}
直接选择排序的特性总结:
1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
4.快速排序
说到快速排序,这里有三种方法:hoare、挖坑法,前后指针法;我主要为大家介绍前后指针的方法,因为这个方法相对于其他两个好理解一些。

前后指针,顾名思义有两个指针,具体怎么工作呢:刚cur位置的值小于key时,那么prev++,然后将prev位置的值和cur位置的值互换,然后cur指针继续往后走;当cur位置的值大于key时,cur直接往后走;一直到cur越界为止。本质上实现key左边都是比key小的,key右边都是比key大的。
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}int PartSort(int* a, int left, int right)
{int keyi = left;int prev = left;int cur = prev + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[keyi], &a[prev]);return prev;
}
void QuickSort(int* a, int left, int right)
{if (left >= right){return;}int keyi = PartSort(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);
}这里大家看快排的代码,这里运用了递归的思想,在单趟排序中我们得到的就是key的位置,然后在不同的区间进行快排;这里运用递归,很快可以实现快排,但是递归还是存在一定的缺陷,当深度过深时,递归可能会引发栈溢出的问题,所以我们能不能不用递归来实现快排呢?答案当然是可以的。
如果我们想写非递归的快排,那么我们就需要用到栈这个数据结构,本质上是将存在栈帧中的区间放在了栈这个数据结构中,来模拟实现递归的过程;
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
int PartSort2(int* a, int left, int right)
{int keyi = left;int prev = left;int cur = prev + 1;while (cur <= right){if (a[cur] > a[keyi] && ++prev != cur)Swap(&a[prev], &a[cur]);cur++;}Swap(&a[prev], &a[keyi]);return prev;
}
void QuickSortNonR(int* a, int left, int right)
{ST st;STInit(&st);//入两个整数,先入右再入左,形成一个区间STPush(&st, right);STPush(&st, left);while (!STEmpty(&st)){int begin = STTop(&st);//这里出栈就是先出左再出右STPop(&st);int end = STTop(&st);STPop(&st);int keyi = PartSort2(a, begin, end);if (keyi + 1 < end){STPush(&st, end);STPush(&st, keyi+1);}if (begin < keyi - 1){STPush(&st, keyi-1);STPush(&st, begin);}}STDestroy(&st);
}这里大家来看非递归的代码,循环每走一次,就取出栈顶区间,然后还是先入右再入左,如此循环下去,就模拟了递归的过程。
快速排序的特性总结:
1. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(logN)
4. 稳定性:不稳定
5. 堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。
需要注意的是排升序要建大堆,排降序建小堆。
堆排序之所以叫做堆排是因为需要结合堆中的向上调整和向下调整两个算法,具体大家可以看下面代码或者去二叉树那篇文章中查看。
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void AdjustUp(int* a, int child)
{int parent = (child - 1) / 2;while (child >= 0){if (a[child] > a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
void AdjustDown(int* a, int n, int parent)
{//这里先假设左孩子小int child = parent * 2 + 1;while (child < n)//child>=n时,说明已经调整到叶节点了{//找出小的那个孩子if (a[child + 1] > a[child] && child + 1 < n){child++;}if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{int i = 0;for (i = 1; i < n; i++){AdjustUp(a, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}
这里我举的例子是建大堆排升序,升降序可以在向下调整和向上调整中进行切换。
堆排的工作原理在于我们要先根据需要建堆,这里就用到向上调整的算法帮助我们建成大堆或小堆;建好堆后,我们需要将首尾位置的数据进行交换,然后让根部位置的数据向下调整,这里拿建大堆排升序来说,我们第一次交换将最大的数放到了最后,然后第二次将次大的数放到倒数第二个位置,以此类推,到最后我们就可以得到一组升序的数据;排降序是同理。
上面所介绍的是堆排的第一种写法,这种写法是比较容易理解的;但是,我们还有另一种写法,可以在其基础上再提高效率——向下调整建堆。这里大家需要明确一个问题:向下调整算法有一个前提:左右子树必须是一个堆,才能调整。所以我们必须保证左右子树都是堆才可以,然而这样显然不太现实,于是我们就采取一种倒着建堆的方式,我们从倒数第一个非叶子节点开始调,一直到根节点,这样也能实现同样的建堆效果。
这里大家还需要注意一点:无论哪种写法,时间复杂度都为:O(NlogN)。但是实际上还是第二种方法能快一些,它们时间复杂度一样,只是说它们属于同一个量级,但是具体详细地来看,还是第二种快,建议大家堆排就写下面这种。
void AdjustDown(int* a, int n, int parent)
{//这里先假设左孩子小int child = parent * 2 + 1;while (child < n)//child>=n时,说明已经调整到叶节点了{//找出小的那个孩子if (a[child + 1] < a[child] && child + 1 < n){child++;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{int i = 0;for (i = (n-2)/2; i >=0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}堆排序的特性总结:
1. 堆排序使用堆来选数,效率就高了很多。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
堆排序是一种效率很高的排序方法,尤其是在数据比较多的情况下,它的运行效率和快排是一个档次的,所以这个排序是具有实际意义的。
6. 归并排序

大家可以直接来看这张图,展现了归并排序的核心思想,我们要采用分治法,保证两边区间都有序后进行归并;
void _MergeSort(int* a, int* tmp, int begin, int end)
{if (begin == end)return;int mid = (begin + end) / 2;//递归使左右区间都有序_MergeSort(a, tmp, begin, mid);_MergeSort(a, tmp, mid+1, end);//进行归并int begin1 = begin, end1 = mid;int begin2 = mid+1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, tmp, 0, n - 1);free(tmp);tmp = NULL;
}上面就是归并排序的代码,其实大家可以结合二叉树中的后序遍历来进行理解,这要提醒一下大家,在我们分割区间的时候,要按照上面的方式进行分割,不能分割成[begin,mid-1]和[mid,end],这样会导致程序陷入死循环。
上面我们学习快排的时候,介绍了两种方法,一种是运用递归,一种是运用非递归;那么在这里亦有异曲同工之妙,归并排序也是可以用非递归来实现的。
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");exit(1);}//gap为每组归并数据的个数int gap = 1;int i = 0;while (gap < n){for (i = 0; i < n; i += 2 * gap){//进行归并int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;if (begin2 >= n){break;}if (end2 >= n){end2 = n - 1;}int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));}gap *= 2;}free(tmp);tmp = NULL;
}这里大家来看一下非递归的归并排序,核心思想就是一组一组归并,这里大家要注意我们需要归并一段拷贝一段,区别于上面递归版的归并。
归并排序的特性总结:
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定
这里大家可以发现,归并排序也是一种效率很高的排序方法,它的效率和堆排快排是一个档次的,所以具有一定实践意义。
7. 冒泡排序
关于冒泡排序,这里就不赘述了,再前面C语言的文章介绍循环的文章中有,大家有需要的可以自行去我的主页查看。为什么里不详细介绍冒泡呢?原因有二:
其一,冒泡排序比较简单,属于交换排序的一种,如果是初学者可以学习一下冒泡排序,感受一下循环的嵌套。
其二,冒泡排序确实是上不了台面,因为它太慢了,和其他几个不是一个量级的,所以没啥实际意义,只有一定的教学意义。
8. 计数排序
void CountSort(int* a, int n)
{int min = a[0];int max = a[0];int i = 0;for (i = 0; i < n; i++){if (a[i] < min){min = a[i];}if (a[i] > max){max = a[i];}}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int));if (count == NULL){perror("calloc fail");exit(1);}//统计次数for (i = 0; i < n; i++){count[a[i] - min]++;}//排序int j = 0;for (i = 0; i < range; i++){while (count[i]--){a[j++] = i + min;}}free(count);count = NULL;
}这里需要为大家强调几点,计数排序只适用于整数,适合范围集中的数据;但是计数排序在特定情况下的效率是很高的,甚至比堆排还要快,所以具有实践意义,我们可以在日常中使用它来进行排序。
9. 各类排序算法分析
这里主要就是来总结一下各类排序的时间复杂度、空间复杂度、稳定性等因素;首先大家需要明确一下稳定性的一个概念:相同的值相对位置不变。满足这个要求才可以算得上稳定。

10.总结
本篇博客为大家介绍了各种排序算法,其中有一些算法的实践意义不大,有些是可以在实践中进行运用的,大家需要理解每一种排序的思路,并且掌握对应的代码,了解每种排序的特点;排序这块儿内容还是比较重要的,后面我们在面试中,排序是一个常考的点,所以大家需要重点掌握,最后,希望本篇博客可以为大家带来帮助,感谢阅读!
相关文章:
各类排序详解
前言 本篇博客将为大家介绍各类排序算法,大家知道,在我们生活中,排序其实是一件很重要的事,我们在网上购物,需要根据不同的需求进行排序,异或是我们在高考完报志愿时,需要看看院校的排名&#…...

【c语言——指针详解(4)】
文章目录 一、回调函数是什么?二、qsort的使⽤1、使⽤qsort函数排序整型数据2、使⽤qsort排序结构数据 三、qsort函数的模拟实现 作者主页 一、回调函数是什么? 回调函数就是⼀个通过函数指针调⽤的函数。 如果你把函数的指针(地址…...

C# (.net6)实现Redis发布和订阅简单案例
概念: 在 .NET 6 中使用 Redis 的/订发布阅模式。发布/订阅(Pub/Sub)是 Redis 支持的一种消息传递模式,其中一个或多个发布者向一个或多个订阅者发送消息,Redis 客户端可以订阅任意数量的频道。 多个客户端可以订阅一个相同的频道…...

【golang】gorm 使用map实现in 条件查询用法
当 where 字典的值为数组时 gorm 会自动转换为条件 IN 查询 where : map[string]interface{}{} where["id"] [1,2,3] where["name"] "zhangsan"type userList struct {Id int "gorm:id"Name string "gorm:name" } Table.…...

理论篇| 移动端爬虫
移动应用的快速发展和广泛普及带来了海量的数据,这些数据对于市场分析、用户行为洞察和业务优化具有重要价值。然而,由于移动应用的特殊性和防护措施,传统的爬虫技术在采集移动应用数据方面面临许多挑战。因此,App爬虫采集与逆向在爬虫领域的重要性不可低估 然而,App采集…...

systemd实现seatunnel自动化启停
在 systemd 中,您可以通过配置服务单元文件来设置服务在失败或退出后自动重启。这对于确保关键服务在意外退出时能够自动恢复运行非常有用。下面是实现 systemd 自动重启服务的步骤: 通用操作 1. 创建或编辑服务单元文件 假设服务单元文件位于 /etc/systemd/system/my-ser…...

MySQL-08.DDL-表结构操作-创建-案例
一.MySQL创建表的方式 1.首先根据需求文档定义出原型字段,即从需求文档中可以直接设计出来的字段 2.再在原型字段的基础上加上一些基础字段,构成整个表结构的设计 我们采用基于图形化界面的方式来创建表结构 二.案例 原型字段 各字段设计如下&…...

完成Sentinel-Dashboard控制台数据的持久化-同步到Nacos
本次案例采用的是Sentinel1.8.8版本 一、Sentinel源码环境搭建 1、下载Sentinel源码工程 git clone https://github.com/alibaba/Sentinel.git 2、导入到idea 这里可以先运行DashboardApplication.java试一下是否运行成功,若成功,源码环境搭建完毕&a…...

RocketMq详解:三、RocketMq通用生产和消费方法改造
文章目录 1.背景2.通用方法改造2.1添加maven依赖2.2 RocketMq基础配置2.3 配置类2.5 消息传输的对象和结果2.4 消息生产者2.5 消息消费者2.6 功能测试 1.背景 在第二章:《RocketMq详解:二、SpringBoot集成RocketMq》中我们已经实现了消费基本生产和消费…...
基于SpringBoot+Vue+Uniapp的仓库点单小程序的详细设计和实现
2. 详细视频演示 文章底部名片,联系我获取更详细的演示视频 3. 论文参考 4. 项目运行截图 代码运行效果图 代码运行效果图 代码运行效果图 代码运行效果图代码运行效果图 代码运行效果图 5. 技术框架 5.1 后端采用SpringBoot框架 Spring Boot 是一个用于快速开发…...

R语言从多波段tif数据中逐个提取单波段数据
在遥感和地理信息系统(GIS)领域,将多个波段存储在一个文件中可以更有效地进行数据压缩和管理,减少了存储空间的需求。 在R语言中,处理多波段栅格数据通常涉及以下步骤: 读取数据:使用raster包中…...

华为海思:大小海思的双轮驱动战略分析
华为海思,作为华为旗下的半导体设计部门,近年来在芯片设计领域取得了显著成就,成为了中国乃至全球芯片设计的重要力量。实际上,华为海思并非单一实体,而是由两个主要分支构成:大海思和小海思。这两个分支虽然同属华为海思,但在定位、产品布局以及市场策略上有所不同,共…...

LeetCode | 704.二分查找
标准的二分查找,直接上模板! class Solution(object):def search(self, nums, target):""":type nums: List[int]:type target: int:rtype: int"""l 0r len(nums) - 1while l < r:mid (l r 1) / 2if nums[mid] …...

TCP三握四挥
TCP三握(简述) 一开始,客户端和服务端都处于closed状态,服务端主动监听某个端口,处于listen状态 一握要进行C-S的第一个SYN发送,客户端会随机初始化序列号(client_isn)并将其置于TCP首部的序列号字段中,并且将SYN标志…...

java项目之大型商场应急预案管理系统(源码+文档)
项目简介 大型商场应急预案管理系统实现了以下功能: 大型商场应急预案管理系统的主要使用者管理员功能有个人中心,员工管理,预案信息管理,预案类型管理,事件类型管理,预案类型统计管理,事件类…...

【C++】--内存管理
👾个人主页: 起名字真南 👻个人专栏:【数据结构初阶】 【C语言】 【C】 目录 1 C/C内存分布2 C语言中动态内存管理方式 :3 C内存管理方式3.1 new/delete操作内置类型3.2 new和delete操作自定义类型 4 operator new与operator delete4.1 opera…...

【设计模式系列】模板方法模式
一、什么是模板方法模式 模板方法模式(Template Method Pattern)是一种行为型设计模式,它在父类中定义一个算法的框架,允许子类在不改变算法结构的情况下重写算法的某些特定步骤。这种模式非常适合于那些存在共同行为的类&#x…...
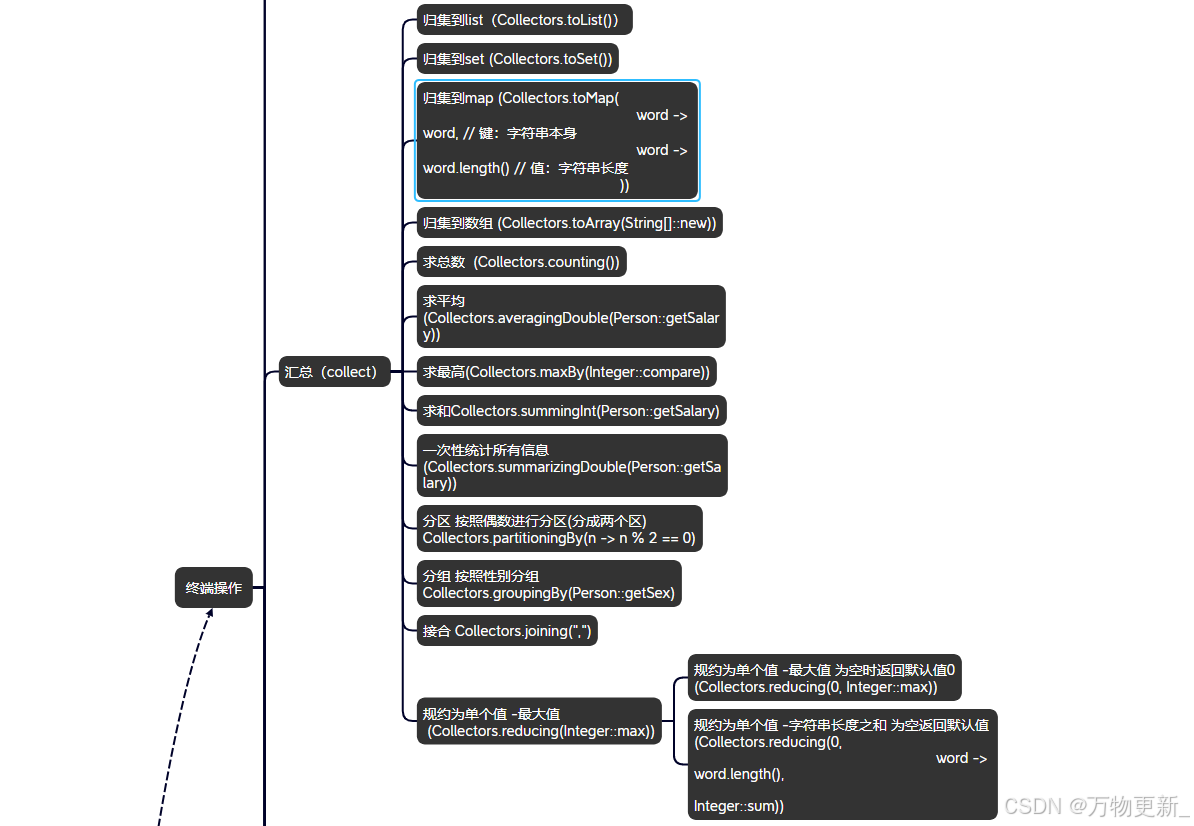
java8 Stream流详细API及用法
目录 整理的更全面的API及用法 创建Stream流 中间操作 filter 过滤 map 映射 flatMap 扁平映射 sorted 排序 limit 截断 skip 跳过 distinct 去重 peek 遍历 终端操作 forEach 遍历 forEachOrdered 顺序遍历 min 统计最小值 max 统计最大值 count 统计元素数量 f…...

Redis——持久化
文章目录 Redis持久化Redis的两种持久化的策略定期备份:RDB触发机制rdb的触发时机:手动执行save&bgsave保存测试不手动执行bgsave测试bgsave操作流程测试通过配置,自动生成rdb快照RDB的优缺点 实时备份:AOFAOF是否会影响到red…...

川字结构布局/国字结构布局
1.串字结构布局 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title><style&g…...

三自由度机械臂运动学建模与求解:从DH参数到算法验证
1. 三自由度机械臂运动学基础 刚接触机械臂控制时,我最头疼的就是运动学建模这部分。三自由度机械臂虽然结构简单,但要把它的运动规律用数学语言描述清楚,需要建立完整的理论框架。运动学主要研究机械臂末端执行器的位置、速度和加速度与各关…...

3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案
3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 还在为Linux系统中寻找文件而烦恼吗ÿ…...

如何让QtScrcpy投屏画质提升300%?3个隐藏参数解锁超清体验
如何让QtScrcpy投屏画质提升300%?3个隐藏参数解锁超清体验 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScr…...

ARM GIC中断控制器分组机制与安全配置详解
1. GIC中断控制器基础架构解析在ARM架构的嵌入式系统中,通用中断控制器(Generic Interrupt Controller,GIC)扮演着系统中断管理的核心角色。作为连接外设中断与CPU之间的桥梁,GIC的设计直接影响着系统的实时性、安全性…...

Midscene.js跨平台AI自动化测试:从视觉驱动到企业级部署的完整指南
Midscene.js跨平台AI自动化测试:从视觉驱动到企业级部署的完整指南 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene Midscene.js作为一款基于视觉语言…...

Sekai Stickers:如何用这款开源工具快速创建个性化Discord表情包
Sekai Stickers:如何用这款开源工具快速创建个性化Discord表情包 【免费下载链接】sekai-stickers Project Sekai sticker maker 项目地址: https://gitcode.com/gh_mirrors/se/sekai-stickers 在Discord社区交流中,表情包已经成为表达情感、活跃…...
)
告别密集计算:用SpConv稀疏卷积加速3D点云处理(附PyTorch代码示例)
告别密集计算:用SpConv稀疏卷积加速3D点云处理实战指南 在自动驾驶和机器人感知领域,LiDAR点云数据的处理一直是计算密集型任务的代表。传统3D卷积神经网络在处理这类数据时,往往需要消耗大量显存和计算资源,而实际上点云数据的有…...

使用Python快速接入Taotoken聚合大模型API的简明教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Python快速接入Taotoken聚合大模型API的简明教程 本文面向希望快速集成大模型能力的Python开发者,介绍如何通过官方…...

STM32驱动MAX31855测温模块:从SPI时序到代码实现的保姆级避坑指南
STM32驱动MAX31855测温模块:从SPI时序到代码实现的保姆级避坑指南 在嵌入式开发领域,精确的温度测量往往是项目成败的关键。MAX31855作为一款集成冷端补偿的热电偶数字转换器,凭借其2℃的高精度和-200℃至700℃的宽测温范围,成为工…...

VSCode调试STM32实战:解决Cortex-Debug插件配置JLink/OpenOCD时最常见的5个报错
VSCode调试STM32实战:破解Cortex-Debug插件五大经典报错 当你在深夜赶工STM32项目,按下F5期待调试器顺利启动时,终端却弹出鲜红的错误信息——这种挫败感每个嵌入式开发者都深有体会。本文不重复那些基础配置教程,而是直击VSCode…...