java8 Stream流详细API及用法
目录
整理的更全面的API及用法
创建Stream流
中间操作
filter 过滤
map 映射
flatMap 扁平映射
sorted 排序
limit 截断
skip 跳过
distinct 去重
peek 遍历
终端操作
forEach 遍历
forEachOrdered 顺序遍历
min 统计最小值
max 统计最大值
count 统计元素数量
findFirst 查找第一个元素
findAny 找到最后一个元素
noneMatch 检查流中的所有元素是否都不满足给定的条件, 如果所有元素都不满足条件,则返回 true, 如果有任何一个元素满足条件,则返回 false
anyMatch 检查流中的元素是否至少有一个满足给定的条件
allMatch 检查流中的所有元素是否都满足给定的条件
reduce 规约为单个值
summaryStatistics 流中所有的统计信息
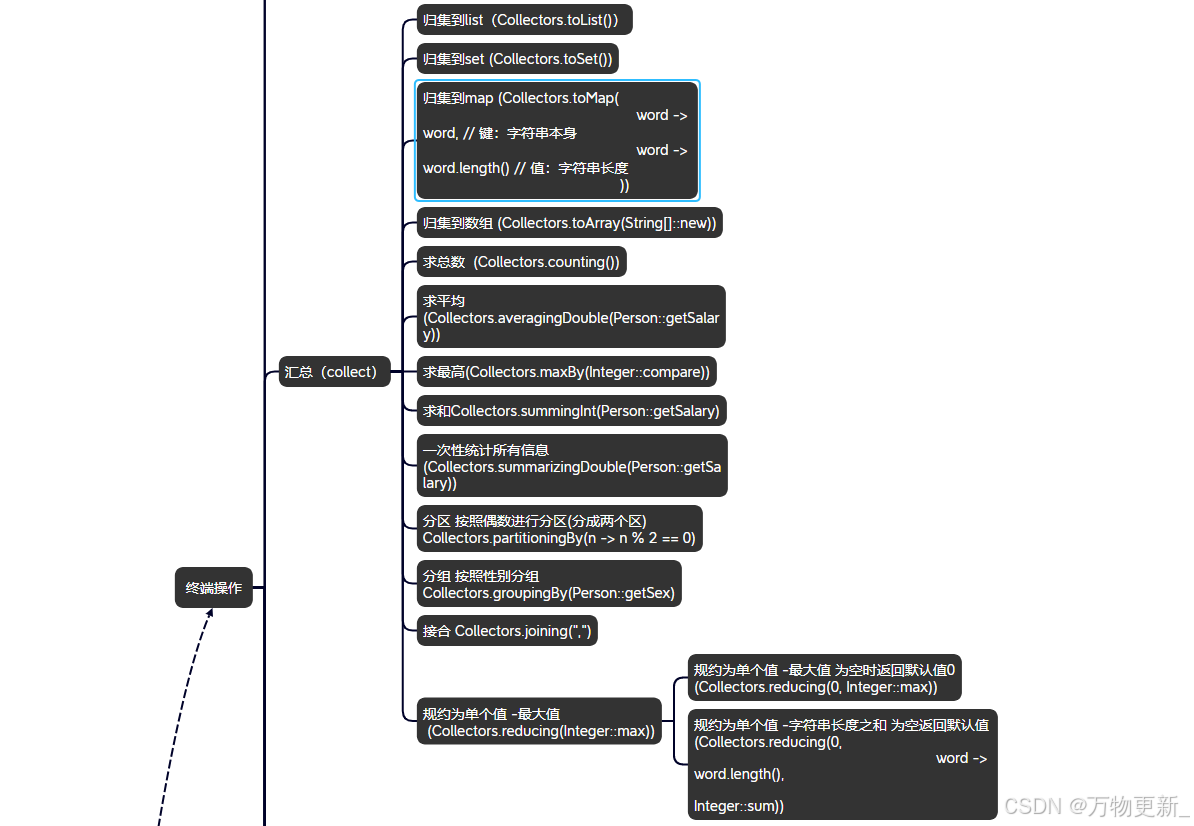
collect 汇总:
归集到set(Collectors.toSet()) 去重确保数据唯一性
归集到map (Collectors.toMap())
归集到数组 (Collectors.toArray())
计算元素的次数 (Collectors.counting())
计算平均值 (Collectors.averagingDouble())
最大值 (Collectors.maxBy())
求和 (Collectors.summingInt())
一次性统计 (Collectors.summarizingDouble())
按条件分成两个区 (Collectors.partitioningBy())
按照条件分组 (Collectors.groupingBy())
接合 (Collectors.joining())
规约 Collectors.reducing()
并行

Stream流的基础知识参考资料
万字详解 Stream 流式编程,写代码也可以很优雅_大模型输出怎么流式输出 stream设为true 没生效-CSDN博客
整理的更全面的API及用法
创建Stream流
1.从集合创建:通过调用集合的 stream() 方法来创建一个 Stream 对象
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream();2.从数组创建:java 8 引入了 Arrays 类的 stream() 方法,我们可以使用它来创建一个 Stream 对象
String[] names = {"Alice", "Bob", "Carol"};
Stream<String> stream = Arrays.stream(names); 3.通过 Stream.of() 创建:我们可以使用 Stream.of() 方法直接将一组元素转换为 Stream 对象
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);4.通过 Stream.builder() 创建:如果我们不确定要添加多少个元素到 Stream 中,可以使用 Stream.builder() 创建一个 Stream.Builder 对象,并使用其 add() 方法来逐个添加元素,最后调用 build() 方法生成 Stream 对象
tream.Builder<String> builder = Stream.builder();
builder.add("Apple");
builder.add("Banana");
builder.add("Cherry");
Stream<String> stream = builder.build();5.从 I/O 资源创建:Java 8 引入了一些新的 I/O 类(如 BufferedReader、Files 等),它们提供了很多方法来读取文件、网络流等数据。这些方法通常返回一个 Stream 对象,可以直接使用
Path path = Paths.get("C:\\Users\\oak\\Desktop\\data.txt");try (Stream<String> stream = Files.lines(path,StandardCharsets.UTF_8)) {stream.forEach(System.out::println);// 使用 stream 处理数据} catch (IOException e) {e.printStackTrace();}try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("C:\\\\Users\\\\oak\\\\Desktop\\\\data.txt"), StandardCharsets.UTF_8))) {Stream<String> lines = br.lines(); // 返回一个Stream<String>lines.forEach(System.out::println); // 处理每一行} catch (IOException e) {e.printStackTrace();}6.通过生成器创建:除了从现有的数据源创建 Stream,我们还可以使用生成器来生成元素。Java 8 中提供了 Stream.generate() 方法和 Stream.iterate() 方法来创建无限 Stream
Stream<Integer> stream = Stream.generate(() -> 0); // 创建一个无限流,每个元素都是 0Stream<Integer> stream = Stream.iterate(0, n -> n + 1); // 创建一个无限流,从 0 开始递增// 生成无限长度的任务流Stream<Instant> tasks = Stream.generate(Instant::now).filter(instant -> instant.getEpochSecond() % 5 == 0);// 模拟每 5 秒一次的任务tasks.limit(5).forEach(task -> {System.out.println("Executing task at: " + task);try {Thread.sleep(Duration.ofSeconds(1).toMillis());} catch (InterruptedException e) {Thread.currentThread().interrupt();}});long startTime = System.currentTimeMillis();Stream<Integer> stream = Stream.iterate(0, n -> n + 1);stream.filter(n -> n % 2 == 0).limit(50000).forEach(System.out::println);long endTime = System.currentTimeMillis();long executionTime = endTime - startTime;//159System.out.println("---------------------1结束--------------------"+executionTime );long startTime1 = System.currentTimeMillis();for (int i = 0; i < 100000; i++) {if(i % 2 == 0){System.out.println(i);}}long endTime1 = System.currentTimeMillis();long executionTime1 = startTime1 - endTime1;//92System.out.println("---------------------2结束--------------------"+executionTime1 );long startTime2 = System.currentTimeMillis();Stream<Integer> stream2 = Stream.iterate(0, n -> n + 1);stream2.filter(n -> n % 2 == 0).limit(50000).parallel().forEach(System.out::println);long endTime2 = System.currentTimeMillis();long executionTime2 = endTime2 - startTime2;//72 (无序)System.out.println("---------------------3结束--------------------"+executionTime2 );9.创建原始数据流, 适用于需要高效处理大量数值的情况:
IntStream intStream = IntStream.range(0, 10);
LongStream longStream = LongStream.rangeClosed(1, 5);
DoubleStream doubleStream = DoubleStream.iterate(0.0, d -> d + 0.5).limit(10);中间操作
filter 过滤
List<String> strings = Arrays.asList("apple", "banana", "cherry", "date", "elderberry", "fig");// 过滤长度大于 5 的字符串
List<String> filteredStrings = strings.stream().filter(s -> s.length() > 5).collect(Collectors.toList());map 映射
List<String> names = Arrays.asList("alice", "bob", "charlie");// 使用 map 方法将每个字符串转换为大写
List<String> uppercaseNames = names.stream().map(String::toUpperCase).collect(Collectors.toList()); flatMap 扁平映射
// 创建一个嵌套列表
List<List<Integer>> nestedList = Arrays.asList(Arrays.asList(1, 2),Arrays.asList(3, 4),Arrays.asList(5, 6)
);// 使用 flatMap 方法将嵌套列表扁平化
List<Integer> flatList = nestedList.stream().flatMap(subList -> subList.stream()).collect(Collectors.toList());sorted 排序
//正序
List<Person> sortedPeople = people.stream().sorted(Comparator.comparing(Person::getAge)).collect(Collectors.toList());//倒序
List<Person> sortedPeople = people.stream().sorted(Comparator.comparing(Person::getAge).reversed()).collect(Collectors.toList());limit 截断
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 limit 方法获取前三个元素
List<Integer> limitedNumbers = numbers.stream().limit(3).collect(Collectors.toList());skip 跳过
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 skip 方法跳过前两个元素
List<Integer> skippedNumbers = numbers.stream().skip(2).collect(Collectors.toList());distinct 去重
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 4, 4, 5, 6, 6, 7, 8, 8, 9, 10, 10);// 使用 distinct 方法去除重复的元素
List<Integer> distinctNumbers = numbers.stream().distinct().collect(Collectors.toList());peek 遍历
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 peek 方法打印每个元素
List<Integer> processedNumbers = numbers.stream().peek(System.out::println).collect(Collectors.toList());终端操作
forEach 遍历
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 forEach 方法打印每个元素
numbers.stream().forEach(System.out::println);forEachOrdered 顺序遍历
List<Integer> numbers = Arrays.asList(10,1, 2, 3, 4, 5, 6, 7, 8, 9 );// 使用 forEachOrdered 方法打印每个元素
numbers.stream().forEachOrdered(System.out::println);min 统计最小值
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "elderberry", "fig");// 使用 min 方法找到最短的字符串
Optional<String> shortestWord = words.stream().min(Comparator.comparingInt(String::length));// 输出结果
shortestWord.ifPresent(System.out::println); // 如果存在则打印max 统计最大值
List<Integer> numbers = Arrays.asList(10, 20, 30, 40, 50, 60, 70, 80, 90, 100);// 使用 max 方法找到最大值
Optional<Integer> maxValue = numbers.stream().max(Integer::compare);// 输出结果
maxValue.ifPresent(System.out::println); // 如果存在则打印count 统计元素数量
List<Integer> numbers = Arrays.asList(10, 20, 30, 40, 50, 60, 70, 80, 90, 100);// 使用 count 方法计算元素数量
long count = numbers.stream().count();// 输出结果
System.out.println(count);//10findFirst 查找第一个元素
List<Integer> numbers = Arrays.asList(20, 100, 30, 40, 50, 60, 70, 80, 90, 100);// 使用 findFirst 方法查找第一个元素
Optional<Integer> firstNumber = numbers.stream().findFirst();// 输出结果
firstNumber.ifPresent(System.out::println); // 如果存在则打印 //20findAny 找到最后一个元素
List<String> words = Arrays.asList("apple", "banana", "elderberry", "cherry", "date", "fig");// 使用 findAny 方法随机选择长度大于等于 5 的一个字符串
Optional<String> anyLongWord = words.stream().parallel().filter(s -> s.length() >= 5).findAny();// 输出结果
anyLongWord.ifPresent(System.out::println); // 如果存在则打印 //cherry noneMatch 检查流中的所有元素是否都不满足给定的条件, 如果所有元素都不满足条件,则返回 true, 如果有任何一个元素满足条件,则返回 false
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 noneMatch 方法检查是否有元素小于 0
boolean result = numbers.stream().noneMatch(n -> n < 0);// 输出结果
System.out.println(result); // 应该输出 trueanyMatch 检查流中的元素是否至少有一个满足给定的条件
List<Integer> numbers = Arrays.asList(1, -2, 3, 4, 5);// 使用 anyMatch 方法检查是否有元素小于 0
boolean result = numbers.stream().anyMatch(n -> n < 0);// 输出结果
System.out.println(result); // 应该输出 trueallMatch 检查流中的所有元素是否都满足给定的条件
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 allMatch 方法检查所有元素是否都大于 0
boolean result = numbers.stream().allMatch(n -> n > 0);// 输出结果
System.out.println(result); // 应该输出 truereduce 规约为单个值
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 reduce 方法求和
Integer sum = numbers.stream().reduce(0, Integer::sum);// 输出结果
System.out.println(sum); // 应该输出 15// 使用 reduce 方法查找最大值
Integer max = numbers.stream().reduce(Integer.MIN_VALUE, Integer::max);// 使用 reduce 方法查找最小值
Integer min = numbers.stream().reduce(Integer.MAX_VALUE, Integer::min);// 输出结果
System.out.println(max); // 应该输出 5
System.out.println(min); // 应该输出 1// 使用 reduce 方法计算乘积
Integer product = numbers.stream().reduce(1, (a, b) -> a * b);// 输出结果
System.out.println(product); // 应该输出 120List<String> words = Arrays.asList("Hello", "World", "Java", "Stream");// 使用 reduce 方法拼接字符串
String concatenatedString = words.stream().reduce("", (a, b) -> a + b);// 输出结果
System.out.println(concatenatedString); // 应该输出 HelloWorldJavaStreamsummaryStatistics 流中所有的统计信息
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 获取整数流的统计信息
ntSummaryStatistics stats = numbers.stream().mapToInt(Integer::intValue).summaryStatistics();// 输出结果
System.out.println("Count: " + stats.getCount()); // 应该输出 10
System.out.println("Min: " + stats.getMin()); // 应该输出 1
System.out.println("Max: " + stats.getMax()); // 应该输出 10
System.out.println("Average: " + stats.getAverage()); // 应该输出 5.5
System.out.println("Sum: " + stats.getSum()); // 应该输出 55List<Long> numbers = Arrays.asList(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L);// 获取长整型流的统计信息
LongSummaryStatistics stats = numbers.stream().mapToLong(Long::longValue).summaryStatistics();// 输出结果
System.out.println("Count: " + stats.getCount()); // 应该输出 10
System.out.println("Min: " + stats.getMin()); // 应该输出 1
System.out.println("Max: " + stats.getMax()); // 应该输出 10
System.out.println("Average: " + stats.getAverage()); // 应该输出 5.5
System.out.println("Sum: " + stats.getSum()); // 应该输出 55List<Double> numbers = Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0);// 获取浮点数流的统计信息
DoubleSummaryStatistics stats = numbers.stream().mapToDouble(Double::doubleValue).summaryStatistics();// 输出结果
System.out.println("Count: " + stats.getCount()); // 应该输出 10
System.out.println("Min: " + stats.getMin()); // 应该输出 1.0
System.out.println("Max: " + stats.getMax()); // 应该输出 10.0
System.out.println("Average: " + stats.getAverage()); // 应该输出 5.5
System.out.println("Sum: " + stats.getSum()); // 应该输出 55.0collect 汇总:
归集到list(Collectors.toList())
String[] wordsArray = {"Hello", "World", "Java", "Stream"};// 使用 toList 方法将数组转换为列表
List<String> wordsList = Arrays.stream(wordsArray).collect(Collectors.toList());// 输出结果
System.out.println(wordsList); // 应该输出 [Hello, World, Java, Stream]归集到set(Collectors.toSet()) 去重确保数据唯一性
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 3, 2);// 使用 toSet 方法将列表转换为 Set
Set<Integer> numberSet = numbers.stream().collect(Collectors.toSet());// 输出结果
System.out.println(numberSet); // 应该输出 [1, 2, 3, 4, 5](顺序可能不同)归集到map (Collectors.toMap())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date");// 使用 toMap 方法将每个字符串作为键,其索引作为值
Map<String, Integer> wordIndexMap = words.stream().collect(Collectors.toMap(word -> word, // key mapperword -> words.indexOf(word) // value mapper));// 输出结果
System.out.println(wordIndexMap); // 应该输出 {apple=0, banana=1, cherry=2, date=3}归集到数组 (Collectors.toArray())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 toArray 方法将列表转换为数组
Integer[] numberArray = numbers.stream().toArray(Integer[]::new);// 输出结果
System.out.println(Arrays.toString(numberArray)); // 应该输出 [1, 2, 3, 4, 5]计算元素的次数 (Collectors.counting())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date");// 使用 counting 方法计算字符 'a' 出现的次数
long count = words.stream().flatMapToInt(String::chars).filter(c -> c == 'a').collect(Collectors.counting());// 输出结果
System.out.println(count); // 应该输出 4 ("apple" 中有 1 个 'a',"banana" 中有 3 个 'a')计算平均值 (Collectors.averagingDouble())
List<Double> numbers = Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0);// 使用 averagingDouble 方法计算平均值
double average = numbers.stream().mapToDouble(Double::doubleValue) // 将 Double 转换为 double 值.average() // 计算平均值.orElse(Double.NaN); // 如果流为空,则返回 NaN// 输出结果
System.out.println(average); // 应该输出 3.0最大值 (Collectors.maxBy())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 maxBy 方法找出最大值
Optional<Integer> maxNumber = numbers.stream().collect(Collectors.maxBy(Integer::compare));// 输出结果
maxNumber.ifPresent(System.out::println); // 应该输出 5求和 (Collectors.summingInt())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 summingInt 方法计算总和
int totalSum = numbers.stream().collect(Collectors.summingInt(Integer::intValue));// 输出结果
System.out.println(totalSum); // 应该输出 15一次性统计 (Collectors.summarizingDouble())
List<Double> numbers = Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0);// 使用 summarizingDouble 方法生成统计摘要
DoubleSummaryStatistics stats = numbers.stream().collect(Collectors.summarizingDouble(Double::doubleValue));// 输出统计信息
System.out.println("Count: " + stats.getCount()); // 应该输出 5
System.out.println("Sum: " + stats.getSum()); // 应该输出 15.0
System.out.println("Min: " + stats.getMin()); // 应该输出 1.0
System.out.println("Max: " + stats.getMax()); // 应该输出 5.0
System.out.println("Average: " + stats.getAverage()); // 应该输出 3.0按条件分成两个区 (Collectors.partitioningBy())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);// 使用 partitioningBy 方法按奇偶性划分整数列表
Map<Boolean, List<Integer>> partitionedNumbers = numbers.stream().collect(Collectors.partitioningBy(n -> n % 2 == 0));// 输出结果
System.out.println("Even numbers: " + partitionedNumbers.get(true)); // 应该输出 [2, 4, 6]
System.out.println("Odd numbers: " + partitionedNumbers.get(false)); // 应该输出 [1, 3, 5]按照条件分组 (Collectors.groupingBy())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "fig", "grape");// 使用 groupingBy 方法按字符串长度分组
Map<Integer, List<String>> groupedByLength = words.stream().collect(Collectors.groupingBy(String::length));// 输出结果
System.out.println(groupedByLength);
// 应该输出:
// {5=[apple, grape], 6=[banana, cherry], 4=[date, fig]}List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 groupingBy 方法按数字的范围分组
Map<String, List<Integer>> groupedByRange = numbers.stream().collect(Collectors.groupingBy(n -> {if (n <= 5) return "1-5";else return "6-10";}));// 输出结果
System.out.println(groupedByRange);
// 应该输出:
// {1-5=[1, 2, 3, 4, 5], 6-10=[6, 7, 8, 9, 10]}接合 (Collectors.joining())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date");// 使用 joining 方法连接字符串列表,以逗号作为分隔符,并添加方括号作为前缀和后缀
String joinedString = words.stream().collect(Collectors.joining(", ", "[", "]"));// 输出结果
System.out.println(joinedString); // 应该输出 "[apple, banana, cherry, date]"规约 Collectors.reducing()
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 reducing 方法计算乘积
Optional<Integer> product = numbers.stream().collect(Collectors.reducing(1, (a, b) -> a * b));// 输出结果
System.out.println(product.orElse(null)); // 应该输出 120并行
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 创建并行流
numbers.parallelStream().forEach(System.out::println);List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 创建顺序流并转换为并行流
numbers.stream().parallel().forEach(System.out::println);// 使用并行流构造器创建 IntStream
IntStream.rangeParallel(0, 10).forEach(System.out::println);相关文章:
java8 Stream流详细API及用法
目录 整理的更全面的API及用法 创建Stream流 中间操作 filter 过滤 map 映射 flatMap 扁平映射 sorted 排序 limit 截断 skip 跳过 distinct 去重 peek 遍历 终端操作 forEach 遍历 forEachOrdered 顺序遍历 min 统计最小值 max 统计最大值 count 统计元素数量 f…...

Redis——持久化
文章目录 Redis持久化Redis的两种持久化的策略定期备份:RDB触发机制rdb的触发时机:手动执行save&bgsave保存测试不手动执行bgsave测试bgsave操作流程测试通过配置,自动生成rdb快照RDB的优缺点 实时备份:AOFAOF是否会影响到red…...

川字结构布局/国字结构布局
1.串字结构布局 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title><style&g…...

2013年国赛高教杯数学建模C题古塔的变形解题全过程文档及程序
2013年国赛高教杯数学建模 C题 古塔的变形 由于长时间承受自重、气温、风力等各种作用,偶然还要受地震、飓风的影响,古塔会产生各种变形,诸如倾斜、弯曲、扭曲等。为保护古塔,文物部门需适时对古塔进行观测,了解各种变…...

web 0基础第一节 文本标签
这是一个html文件的基本结构 在vs code 中使用英文的 ! 可快捷设置这样的结构 <!-- --> 是在html写注释的结构 <!DOCTYPE html> <!--标识当前文档类型为html--> <html> …...

Zookeeper快速入门:部署服务、基本概念与操作
文章目录 一、部署服务1.下载与安装2.查看并修改配置文件3.启动 二、基本概念与操作1.节点类型特性总结使用场景示例查看节点查看节点数据 2.文件系统层次结构3.watcher 一、部署服务 1.下载与安装 下载: 一定要下载编译后的文件,后缀为bin.tar.gz w…...

【Sqlite】sqlite内部函数sqlite3_value_text特性
目录 ⚛️1 结论 ☪️2 说明 ☪️3 传入数值转成科学计数法 ♋3.1 只有整数部分 ♏3.2 只有小数部分 ♐3.3 整数小数 ⚛️1 结论 整数(sqlite视为int64)位数 > 20位,sqlite3_value_text 采用科学计数法。否则正常表示。 浮点数(sqlite视为double)的整数部…...

树莓派应用--AI项目实战篇来啦-4.OpenCV读取、写入和显示视频
1. 介绍 视频是由一张一张图片组成的,所以读取视频就相当于读取很多张图片,然后将其连起来cv2.VideoCapture可以捕获摄像头,但是针对树莓派的CSI摄像头调用方式采用了之前介绍的Picamera2 库,所以在调用的时候是有区别的ÿ…...

智能电子后视镜,汽车驾驶更安全,会是一种趋势
相比于传统的后视镜,智能电子后视镜的确有很多的优点。在下雨天和夜晚场景,电子后视镜可以说是表现优秀。 我之前一直以为我们国内是有规定不能使用电子后视镜。没想到,偶然刷到享界S9的视频,这电子后视镜,妥妥的给安排…...

IEC104规约的秘密之九----链路层和应用层
104规约从TCP往上,分成链路层和应用层。 如图,APCI就是链路层,ASDU的就是应用层 我们看到报文都是68打头的,因为应用层报文也要交给链路层发送,链路层增加了开头的6个字节再进行发送。 完全用于链路层的报文每帧都只有…...

最新Prompt预设词指令教程大全ChatGPT、AI智能体(300+预设词应用)
使用指南 直接复制在AI工具助手中使用(提问前) 可以前往已经添加好Prompt预设的AI系统测试使用(可自定义添加使用) SparkAi系统现已支持自定义添加官方GPTs(对专业领域更加专业,支持多模态文档࿰…...

DockerCompose 启动 open-match
背景介绍 open-match是Google和unity联合开源的支持实时多人匹配的框架,已有多家游戏厂商在生产环境使用,官网 https://open-match.dev/site/ 。原本我们使用的是UOS上提供的匹配能力,但是UOS目前不支持自建的Dedicated servers 集群&#x…...

Chainlit集成Dashscope实现语音交互网页对话AI应用
前言 本篇文章讲解和实战,如何使用Chainlit集成Dashscope实现语音交互网页对话AI应用。实现方案是对接阿里云提供的语音识别SenseVoice大模型接口和语音合成CosyVoice大模型接口使用。针对SenseVoice大模型和CosyVoice大模型,阿里巴巴在github提供的有开…...

Canal 扩展篇(阿里开源用于数据同步备份,监控表和表字段(日志))
1.Canal介绍 Canal把自己伪装成从数据库,获取mysql主数据库的日志(binlog)信息,所以要想使用canal就得先开启数据库日志 https://github.com/alibaba/canal Canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量…...
顺序表的定义
一.顺序表的定义 顺序表--用顺序存储的方式实现线性表 顺序存储。把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关 系由存储单元的邻接关系来体现。 二.顺序表的实现--静态分配 #include<stdio.h> #define MaxSize 10 //定义最大长度 …...

青少年编程能力等级测评CPA C++一级试卷(1)
青少年编程能力等级测评CPA C一级试卷(1) 一、单项选择题(共20题,每题3.5分,共70分) CP1_1_1.在C中,下列变量名正确的是( )。 A.$123 B&#…...

R语言中的plumber介绍
R语言中的plumber介绍 基本用法常用 API 方法1. GET 方法2. POST 方法3. 带路径参数的 GET 方法 使用 R 对数据进行操作处理 JSON 输入和输出运行 API 的其他选项其他功能 plumber 是个强大的 R 包,用于将 R 代码转换为 Web API,通过使用 plumber&#x…...

uniapp 设置 tabbar 的 midButton 按钮
效果展示: 中间的国际化没生效(忽略就行) 示例代码: 然后在 App.vue 中进行监听: <script>export default {onLaunch(e) {// #ifdef APPuni.onTabBarMidButtonTap(()>{console.log("中间按钮点击回调…...

php 生成随机数
记录:随机数抽奖 要求:每次生成3个 1 - 10 之间可重复(或不可重复)的随机数,10次为一轮,每轮要求数字5出现6次、数字4出现3次、…。 提炼需求: 1,可设置最小数、最大数、每次抽奖生成随机数的个数、是否允许重复 2,可设置每轮指定数字的出现次数 3,可设置每轮的抽奖…...
MySQL 8.4修改初始化后的默认密码
MySQL 8.4修改初始化后的默认密码 (1)初始化mysql: mysqld --initialize --console (2)之后,mysql会生成一个默认复杂的密码,如果打算修改这个密码,可以先用旧密码登录: mysql -u…...
预处理小工具)
告别手动处理!用MATLAB App Designer打造你的专属数据(图片/表格)预处理小工具
告别手动处理!用MATLAB App Designer打造你的专属数据预处理小工具 在数据分析与科研工作中,我们常常陷入重复性劳动的泥潭:每次收到新数据集都要用不同软件打开图片查看尺寸、用Excel检查表格结构、用统计工具计算基础指标。这种碎片化操作不…...

8255 Boot流程深度解析与Bring Up实战避坑指南
1. 8255芯片启动流程全景解析 第一次拿到8255芯片开发板时,最让我困惑的就是这个"安全岛"架构的启动流程。和传统芯片不同,8255的启动更像是一场精心编排的交响乐,SAIL(安全岛)、APPS(应用处理器…...

百度网盘秒传链接终极指南:免费在线转存、生成与转换全攻略
百度网盘秒传链接终极指南:免费在线转存、生成与转换全攻略 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 还在为百度网盘文件分享的繁…...
)
别再只用EC11调音量了!用STM32做个旋转编码器计数器(OLED显示,附防抖代码)
解锁EC11旋转编码器的计数潜能:STM32实战指南与防抖优化 旋转编码器在电子项目中常被简化为音量调节工具,但其真正的价值远不止于此。EC11作为一款经济高效的旋转编码器,能够提供精确的数字脉冲信号,非常适合需要精准位置控制或速…...

大疆C板实战:基于BMI088与Mahony算法的实时姿态解算实现
1. 从零开始搭建姿态解算系统 第一次接触大疆C板的时候,我被它精致的做工和丰富的接口惊艳到了。这块开发板简直就是为机器人开发者量身定做的,特别是内置的BMI088惯性测量单元(IMU),让我们不用再为传感器选型和电路设计发愁。不过说实话&…...

5步掌握Beyond Compare 5逆向工程:RSA加密破解与密钥生成实战
5步掌握Beyond Compare 5逆向工程:RSA加密破解与密钥生成实战 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 软件授权逆向工程是信息安全领域的重要研究方向,通过分析Be…...

Windows驱动管理专业解决方案:Driver Store Explorer完全指南
Windows驱动管理专业解决方案:Driver Store Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Driver Store Explorer(简称Rapr)是一款…...

开源实时监控告警引擎OpenAlerts:从原理到生产部署实战
1. 项目概述:一个开源的实时监控与告警引擎在运维、开发和业务监控的日常工作中,我们常常面临一个核心痛点:如何从海量的日志、指标和事件数据中,快速、准确地识别出异常,并及时通知到正确的人。市面上的商业监控方案功…...

基于视觉大模型的GUI自动化:从原理到实践
1. 项目概述:当GUI自动化遇见视觉大模型 最近在折腾自动化测试和RPA(机器人流程自动化)的时候,我遇到了一个老生常谈但又极其棘手的问题:如何稳定、高效地识别和操作那些没有标准控件标识的图形界面元素?传…...

正交设计实战指南:从理论到最优方案验证
1. 正交设计入门:从概念到实战价值 第一次接触正交设计是在五年前的一个电机工艺优化项目上。当时面对12个关键参数、每个参数4-5个水平的选择困境,如果做全面实验需要3125组数据,而项目周期只允许做50组实验。正是正交设计让我们用36组实验…...