Spark高级用法-自定义函数
用户可以根据需求自己封装计算的逻辑,对字段数据进行计算
内置函数,是spark提供的对字段操作的方法 ,split(字段) 对字段中的数进行切割,F.sum(字段) 会将该字段下的数据进行求和
实际业务中又能内置函数不满足计算需求,此时就需要自定义行数,完成字段数据的业务处
函数分类
- udf
- 自定义
- 一进一出
- udaf
- 聚合
- 自定义
- 多进一出
- udtf
- 爆炸
- 一进多出
UDF函数
对每一行数据以此进行计算,返回每一行的结果
1)不带装饰器
# UDF函数
from pyspark.sql import SparkSession,functions as F
from pyspark.sql.types import *ss = SparkSession.builder.getOrCreate()# 读取文件数据转为df
df = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',')df.show()# 自定义字符串长度计算函数
# @F.udf(returnType=IntegerType()) # 使用装饰器注册函数,只能在DSL方法中使用,不能在SQL中使用
def len_func(field):"""自定义函数,函数名可以自己指定:param field: 是用来结构处理的字段数据,可以定义多个。根据实际处理的字段数量决定定义多少个接收参数:return: 返回处理后的数据"""if field is None:return 0else:data = len(field)return data# 将自定义的函数注册到spark中使用
# 参数一 指定spark中使用函数的名
# 参数二 指定自定义函数的名
# 参数三 指定函数的返回值类型
# 接收参数 定义和函数名一样的值
len_func = ss.udf.register('len_func',len_func,returnType = IntegerType())# 在spark中使用
df2 = df.select('id','name','gender',len_func('name'))
df2.show()# 使用sql语句
df.createTempView('stu')df3 = ss.sql('select * ,len_FUNC(name) from stu')
df3.show()
2)带有装饰器
# UDF函数
from pyspark.sql import SparkSession,functions as F
from pyspark.sql.types import *ss = SparkSession.builder.getOrCreate()# 读取文件数据转为df
df = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',')df.show()# 自定义字符串长度计算函数
@F.udf(returnType=IntegerType()) # 使用装饰器注册函数,只能在DSL方法中使用,不能在SQL中使用
def len_func(field):"""自定义函数,函数名可以自己指定:param field: 是用来结构处理的字段数据,可以定义多个。根据实际处理的字段数量决定定义多少个接收参数:return: 返回处理后的数据"""if field is None:return 0else:data = len(field)return data# 在spark中使用
df2 = df.select('id','name','gender',len_func('name'))
df2.show()装饰器注册
-
只能在DSL方法中使用,在sql语句中无法使用
UDAF函数
多进一出 主要是聚合
使用pandas中的series实现,可以读取一列数据存储在pandas的seriess中进行数据的聚合
# 读取文件数据转为df
df = ss.read.csv('hdfs://node1:8020/data/students.csv',header=True,sep=',',schema='id int,name string,gender string,age int,cls string')df.show()# 自定义udaf函数
# 装饰器注册
@F.pandas_udf(returnType=IntegerType())
# 自定义udaf函数
# fileds:pd.Series 给数据字段指定一个类型
# -> float 指定返回值类型
# udaf函数注册需要两步,第一步现指定装饰器
def sub(filed:pd.Series) -> int:"""自定义udaf函数,实现累减:param field: 接收的字段列数据 pd.Series声明字段数据的类型,接收一列数据可以使用pandas的series类型:return:"""# field是series,就按照series方式操作n = filed[0] # 取出第一个值作为初始值for i in filed[1::]:n-=ireturn n# regidter方法注册
sub = ss.udf.register('sub',sub)# 使用udaf函数 缺少 PyArrow pandas中series类型交个spark程序无法识别,spark是有scala实现,scala中没有对应的series类型
# 可以使用 PyArrow框架将series转为scale能识别的数据类型
df2 = df.select(sub('age'))
df2.show()
- arrow框架 pyarrow
-
Apache Arrow 是一种内存中的列式数据格式,用于Spark中,以在JVM和Python进程之间有效地传输数据。目前这对使用 Pandas/NumPy 数据的 Python 用户最有益,提升传输速度。
-
在线安装 三台机器安装
-
进入虚拟环境 conda activate base
-
在线安装 pip install pyspark[sql] -i Verifying - USTC Mirrors
-
-
离线安装 三台机器安装
-
pip install pyarrow-10.0.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
-
-

安装pyarrow
conda activate base
pip install pyspark[sql] -i https://pypi.mirrors.ustc.edu.cn/simple/
相关文章:
Spark高级用法-自定义函数
用户可以根据需求自己封装计算的逻辑,对字段数据进行计算 内置函数,是spark提供的对字段操作的方法 ,split(字段) 对字段中的数进行切割,F.sum(字段) 会将该字段下的数据进行求和 实际业务中又能内置函数不满足计算需求࿰…...

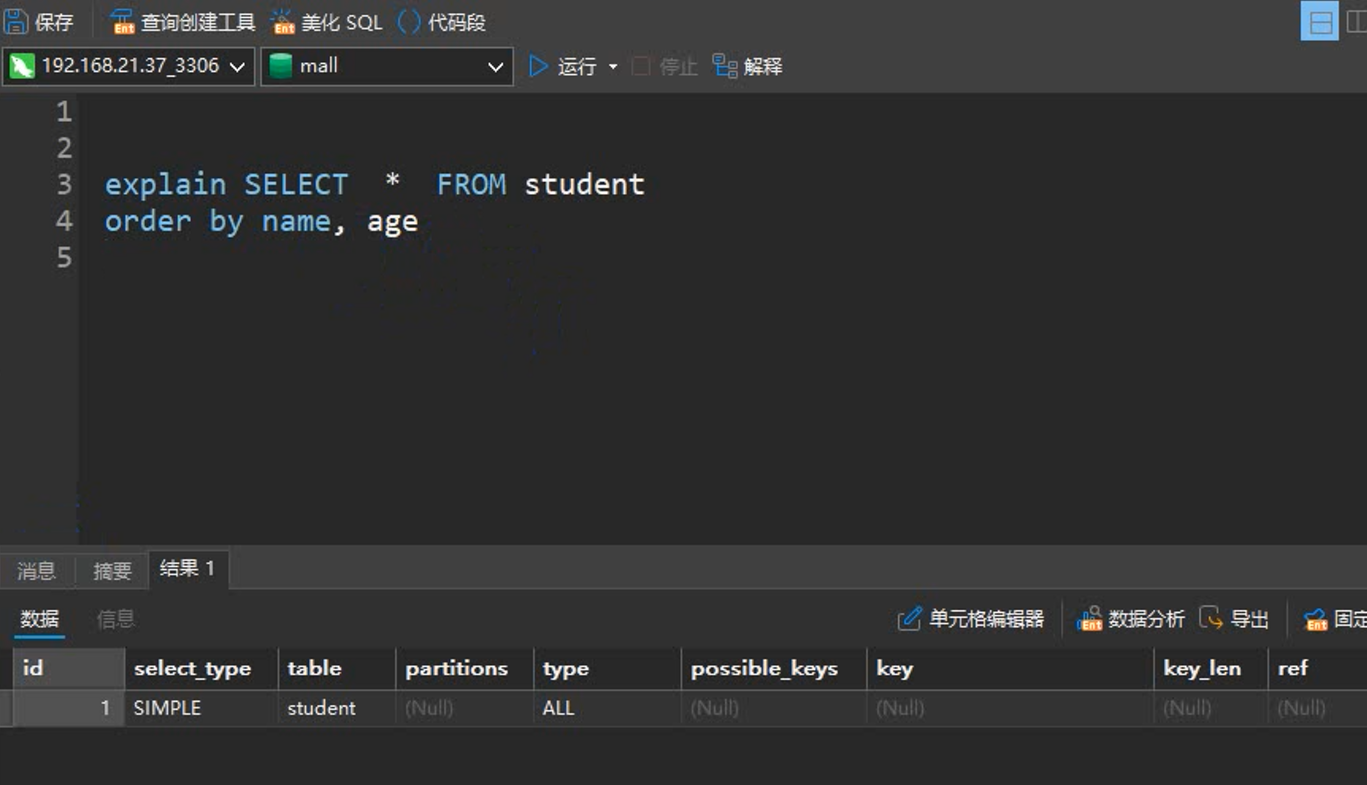
『Mysql进阶』Mysql explain详解(五)
目录 Explain 介绍 Explain分析示例 explain中的列 1. id 列 2. select_type 列 3. table 列 4. partitions 列 5. type 列 6. possible_keys 列 7. key 列 8. key_len 列 9. ref 列 10. rows 列 11. filtered 列 12. Extra 列 Explain 介绍 EXPLAIN 语句提供有…...

【工具】音视频翻译工具基于Whisper+ChatGPT
OpenAI推出的开源语音识别工具Whisper,以其卓越的语音识别能力,在音频和视频文件处理领域大放异彩。与此同时,ChatGPT也在翻译领域崭露头角,其强大的翻译能力备受赞誉。因此,一些字幕制作团队敏锐地捕捉到了这两者的结…...

学成在线——关于nacos配置优先级的坑
出错: 本地要起两个微服务,一个是content-api,另一个是gateway网关服务。 发现通过网关服务请求content微服务时,怎么请求都请求不到。 配置如下: content-api-dev.yaml的配置: server:servlet:context-p…...

Nginx在Windows Server下的启动脚本
Nginx在Windows Server下的快捷运行脚本 使用时记得修改NGINX_DIR路径 ECHO OFF CHCP 65001 SET NGINX_DIRD:\software\Nginx\ color 0a TITLE Nginx Management GOTO MENU :MENU CLS ECHO. ECHO. * * * * Nginx Management * * * * * * * * * * * ECHO. * * EC…...

【国科大】C++程序设计秋季——五子棋
【国科大】C程序设计秋季 —— 五子棋程序 下载地址:https://mbd.pub/o/bread/Zp2Ukptx...

Docker 环境下多节点服务器监控实战:从 Prometheus 到 Grafana 的完整部署指南
Docker 环境下多节点服务器监控实战:从 Prometheus 到 Grafana 的完整部署指南 文章目录 Docker 环境下多节点服务器监控实战:从 Prometheus 到 Grafana 的完整部署指南一 多节点部署1 节点一2 节点二3 节点三 二 监控节点部署三 配置 prometheus.yml四 …...

【动手学深度学习】6.3 填充与步幅(个人向笔记)
卷积的输出形状取决于输入形状和卷积核的形状在应用连续的卷积后,我们最终得到的输出大小远小于输入大小,这是由于卷积核的宽度和高度通常大于1导致的比如,一个 240 240 240240 240240像素的图像,经过10层 5 5 55 55的卷积后&am…...

【宝可梦】游戏
pokemmo https://pokemmo.com/zh/ 写在最后:若本文章对您有帮助,请点个赞啦 ٩(๑•̀ω•́๑)۶...

docker启动的rabbitmq如何启动其SSL功能
docker run --hostname my-rabbit --name my-rabbit -p 5671:5671 -p 15671:15671 -p 15672:15672 -e RABBITMQ_DEFAULT_USERabc -e RABBITMQ_DEFAULT_PASSabc -d rabbitmq:4.0-management 使用docker的复制命令将ca.crt、server.crt和server.key文件复制到容器的/etc/server_s…...

易基因: cfMeDIP-seq揭示cfDNA甲基化高效区分原发性和转移性前列腺|Nat Commun
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 前列腺癌(Prostate cancer,PCa)是男性中第二常见的恶性肿瘤,也是全球癌症相关死亡的第三大原因。虽然大多数原发性前列腺癌可以治愈&#…...

CMake 教程跟做与翻译 4
目录 添加一个option! 添加一个option! option,正如其意,就是选项的意思。我们这里需要演示一下option的做法。 option对于大型的工程必然是非常常见的:一些模块会被要求编译,另一些客户不准备需要这些模块。option就是将这种需…...
MySQL面试题分享
慢日志(了解) 慢日志开启的变量:slow_query_logON; 如果值为 OFF ,那就是没有开启慢日志 耗时: long_query_time,默认是10秒 redis 和 mysql 慢日志的区别 redis 慢日志默认是没有开启的 mysql 慢日志默认是开启的…...

vue路由缓存问题
什么是路由缓存问题 解决方案: 让组件实例不再复用,强制销毁重建监听路由变化,变化之后执行数据更新操作 方法一 给 routerv-view 添加key属性,强制不添加缓存,破坏缓存,所以这个方法性能会比较差 <Ro…...

RabbitMQ中如何解决消息堆积问题,如何保证消息有序性
RabbitMQ中如何解决消息堆积问题 如何保证消息有序性 只需要让一个消息队列只对应一个消费者即可...

python爬虫案例——selenium爬取淘宝商品信息,实现翻页抓取(14)
文章目录 1、任务目标2、网页分析3、代码编写3.1 代码分析3.2 完整代码1、任务目标 目标网站:淘宝(https://www.taobao.com/) 任务要求:通过selenium实现自动化抓取 淘宝美食 板块下的所有商品信息,并实现翻页抓取,最后以csv格式将数据保存至本地;如: 2、网页分析 首先…...

在VSCode中使用Excalidraw
概述 Excalidraw是一款非常不错的示意图绘制软件,没想到在VSCode中有其扩展,可以在VScode中直接使用。 安装扩展 使用 需要创建.excalidraw.svg、.excalidraw或.excalidraw.png等名称的文件。 搭配手写版使用 自由画笔工具可以配合手写板,…...
25中国投资中投笔试测评秋招校招SHL笔试题型分享
✅中投公司不必过多介绍,和建总都位于金融央企第一档,但是招人更少,竞争更为激烈,看公示录用名单都是清北的金融硕士,投资岗难度更大。 ✅中投公司的笔试往年都是shl系统,但考察范围非常广,包含…...

【LeetCode热题100】分治-快排
本篇博客记录分治快排的4道题目:颜色分类、排序数组、数组中的第K个最大元素、数组中最小的N个元素(库存管理)。 class Solution { public:void sortColors(vector<int>& nums) {int n nums.size();int left -1,right n;for(int…...

Docker 教程四 (Docker 镜像加速)
Docker 镜像加速 国内从 DockerHub 拉取镜像有时会遇到困难,此时可以配置镜像加速器。 目前国内 Docker 镜像源出现了一些问题,基本不能用了,后期能用我再更新下。* Docker 官方和国内很多云服务商都提供了国内加速器服务,例如…...

实战指南:如何高效部署VoiceFixer语音修复系统,从噪声消除到低分辨率增强全解析
实战指南:如何高效部署VoiceFixer语音修复系统,从噪声消除到低分辨率增强全解析 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer VoiceFixer是一款基于深度学习的通用语音修复工…...

STC8H高级PWM实战:用呼吸灯搞懂定时器配置,附完整代码和寄存器详解
STC8H高级PWM实战:从寄存器到呼吸灯的完整设计指南 在嵌入式开发领域,PWM(脉冲宽度调制)技术就像一位无声的魔术师,通过精确控制脉冲的宽度,它能让我们手中的LED灯实现从完全熄灭到最亮之间的任意亮度变化…...

Windows 10系统瘦身实战:用Win10BloatRemover打造高效纯净系统
Windows 10系统瘦身实战:用Win10BloatRemover打造高效纯净系统 【免费下载链接】Win10BloatRemover Configurable CLI tool to easily and aggressively debloat and tweak Windows 10 by removing preinstalled UWP apps, services and more. Originally based on …...

RK3568网关实战:如何用1TOPS NPU在智慧农业里做实时虫情监测?
RK3568网关实战:如何用1TOPS NPU在智慧农业里做实时虫情监测? 在智慧农业的浪潮中,虫害监测一直是困扰农户的核心问题。传统依赖人工巡查的方式不仅效率低下,还容易错过最佳防治时机。而基于RK3568边缘计算网关的实时虫情监测方案…...

如何在5分钟内用Python获取同花顺问财金融数据?
如何在5分钟内用Python获取同花顺问财金融数据? 【免费下载链接】pywencai 获取同花顺问财数据 项目地址: https://gitcode.com/gh_mirrors/py/pywencai 你是否曾经为了获取金融数据而花费大量时间编写爬虫,却总是面临反爬机制和接口变动的困扰&a…...

GitHub个人访问令牌实战:告别密码认证,安全推送代码与创建PR
1. 项目概述与核心痛点如果你刚开始接触开源贡献,或者最近在尝试向GitHub推送代码时,大概率会遇到一个令人困惑的拦路虎:在终端执行git push命令后,系统提示你输入用户名和密码。你很自然地输入了登录GitHub网站用的账号密码&…...

金蝶云星空日常使用功能
1、必录和锁定和隐藏 2、取多少位字符 FMaterialId <> null AND ( FMaterialId.FNumber[0:3] in (321) or FMaterialId.FNumber[0:1] in (P)) 3、设定指定值...

涿州靠谱软体沙发家具城,为你打造舒适家居的理想之选!
在涿州,选择一家靠谱的软体沙发家具城至关重要,它不仅关系到家居的舒适度,还影响着生活品质。今天就为大家推荐涿州市雅木轩家具店(简称:旭日家具),并将它与其他大厂进行对比,让你更…...

SubDomainizer与其他工具集成:打造完整的网络安全评估工作流
SubDomainizer与其他工具集成:打造完整的网络安全评估工作流 【免费下载链接】SubDomainizer A tool to find subdomains and interesting things hidden inside, external Javascript files of page, folder, and Github. 项目地址: https://gitcode.com/gh_mirr…...

Go语言策略模式:算法替换
Go语言策略模式:算法替换 1. 策略接口 type SortStrategy interface {Sort(data []int) []int }type BubbleSort struct{}func (s *BubbleSort) Sort(data []int) []int {// 冒泡排序实现return data }type QuickSort struct{}func (s *QuickSort) Sort(data []int)…...