DataFrame增删改数据
目录
准备数据
DataFrame添加列
直接添加列数据
使用insert添加列数据
DataFrame删除行列
准备数据
删除行
删除列
DataFrame数据去重
准备数据
import pandas as pd
df = pd.read_csv("../data/b_LJdata.csv")
df
DataFrame添加列
直接添加列数据
1)获取前5条数据并复制一份
# 获取前5条数据并复制一份
copy_df = df.head().copy()
copy_df 2) 添加列名为 城市 的一列, 值都为 北京
2) 添加列名为 城市 的一列, 值都为 北京
# 添加一列 城市,值为北京
copy_df['城市']='北京'
copy_df
3)添加列名为 区县 的一列, 值分别是 '朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'
# 添加列名为 区县 的一列, 值分别是 '朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'
copy_df['区县']=['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区']
copy_df
4) 添加列名为 新价格 的一列, 值比原价格列的值多1000元
# 添加列名为 新价格 的一列, 值比原价格列的值多1000元
copy_df['新价格'] = copy_df['价格'] +1000
copy_df
使用insert添加列数据
DataFrame的 insert 方法用于在特定位置插入新的列
以下是 df.insert(loc=, column=, value=)的详细解释:
-
1 参数说明
-
loc:
-
这是一个整数,表示要插入新列的位置索引。索引从 0 开始,所以 loc=0 表示在最左边插入新列,loc=1 表示在第二列的位置插入新列,依此类推。
-
-
column:
-
这是一个字符串,表示新列的名称。
-
-
value:
-
可以是一个标量值、列表、数组或其他可迭代对象,它将成为新列的值。如果是标量值,该值将被广播到新列的所有行。如果是可迭代对象,其长度必须与数据框的行数相等。
-
-
使用insert方法会直接修改原始的DataFrame对象。如果需要保留原始数据框的副本,可以先对其进行复制。
确保value参数的值与数据框的行数相匹配,否则会引发错误。
如果多次调用insert方法插入多个新列,每次插入都会移动后续的列,可能会影响性能。在某些情况下,可以考虑一次性构建包含所有列的数据框,而不是逐个插入列。
1) 获取前5条数据并复制一份
# 1 获取前5条数据并复制一份
copy_df = df.head().copy()
copy_df
2) 在区域列后添加列名为 城市 的一列, 值都为北京
# 2 在 区域 列后添加列名为 城市 的一列, 值都为北京
# 2.1 获取指定列的索引 df.columns.get_loc(列名)
area = copy_df.columns.get_loc('区域')
print(area)# 添加新列
copy_df.insert(loc=area+1,column='城市',value='北京')
print(copy_df)
3)在城市列后添加列名为 区县 的一列, 值分别是 '朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'
#%%
# 3 在城市列后添加列名为 区县 的一列, 值分别是 '朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'
# 3.1 获取指定列的索引 df.columns.get_loc(列名)
city = copy_df.columns.get_loc('城市')
print(city)# 添加新列
copy_df.insert(loc=city+1,column='区县',value=['朝阳区', '朝阳区', '西城区', '昌平区', '朝阳区'])
print(copy_df)
4) 在价格列后添加列名为 新价格 的一列, 值比原价格列的值多1000元
# 4 在价格列后添加列名为 新价格 的一列, 值比原价格列的值多1000元
# 4.1 获取指定列的索引 df.columns.get_loc(列名)
price = df.columns.get_loc('价格')
print(price)# 添加新列
copy_df.insert(loc=price+1,column='新价格',value=copy_df['价格']+1000)
print(copy_df)
DataFrame删除行列
在pandas中,df.drop(labels=, axis=, inplace=)方法用于删除DataFrame中的行或列。
-
labels:-
可以是一个标签(例如列名或行索引)或一个标签列表,表示要删除的行或列。
-
如果是单个标签,将删除对应的一行或一列。如果是列表,则删除多个行或列。
-
-
axis:-
决定是删除行还是列。默认值为 0,表示按行删除。如果设置为 1,则表示按列删除。
-
例如,
axis=0可以用来删除特定的行,而axis=1可以用来删除特定的列。
-
-
inplace:-
这是一个布尔值参数。如果为
True,则直接在原始DataFrame上进行修改,不会返回新的DataFrame。如果为False(默认值),则会返回一个新的DataFrame,原始的DataFrame保持不变。
-
准备数据
import pandas as pd
df = pd.read_csv('../data/b_LJdata.csv')
df
删除行
1)删除一行数据 原df上并没有删除(完整版)
# 删除行:不在原有基础删除,删除一行
copy_df = df.head().copy()
print("===================删除=============================")
new_df = copy_df.drop(labels=[1],axis=0,inplace= False)
print(new_df)
print("====================删除后======================")
print(copy_df)
2) 删除一行数据 原df上并没有删除(简化版)
# 删除行:不在原有基础删除,删除一行
copy_df = df.head().copy()
print("===================删除=============================")
new_df = copy_df.drop(labels=[1])
print(new_df)
print("====================删除后======================")
print(copy_df)
3) 删除多行数据 原df上并没有删除
# 删除多行
copy_df = df.head().copy()
print("===================删除=============================")
new_df = copy_df.drop(labels=[1,2,4],axis=0,inplace= False)
print(new_df)
print("====================删除后======================")
print(copy_df)
4) 删除一行数据 原df上删除
# 在原基础上删除一行
copy_df = df.head().copy()
print("====================删除前======================")
print(copy_df)
print("===================删除=============================")
new_df = copy_df.drop(labels=[1],axis=0,inplace= True)
print(new_df)
print("====================删除后======================")
print(copy_df)
5) 删除多行数据 原df上删除
# 在原基础上删除多行
copy_df = df.head().copy()
print("====================删除前======================")
print(copy_df)
print("===================删除=============================")
new_df = copy_df.drop(labels=[1,1,3],axis=0,inplace= True)
print(new_df)
print("====================删除后======================")
print(copy_df)
删除列
1) 删除一列数据 原df上并没有删除(完整版)
# 不在原基础上,删除一列
copy_df = df.head().copy()
print("==================删除=====================")
new_df = copy_df.drop(labels=['地址'],axis=1,inplace= False)
print(new_df)
print("===============删除后==================")
print(copy_df)
2) 删除多列数据 原df上并没有删除
# 不在原基础上,删除多列
copy_df = df.head().copy()
print("==================删除=====================")
new_df = copy_df.drop(labels=['地址','价格'],axis=1,inplace= False)
print(new_df)
print("===============删除后==================")
print(copy_df)
3) 删除一列数据 原df上删除
# 在原有基础上,删除一行
copy_df = df.head().copy()
print("==================删除=====================")
new_df = copy_df.drop(labels=['地址'],axis=1,inplace= True)
print(new_df)
print("===============删除后==================")
print(copy_df)
4) 删除多列数据 原df上删除
# 在原基础上,删除多列
copy_df = df.head().copy()
print("==================删除=====================")
new_df = copy_df.drop(labels=['地址','价格'],axis=1,inplace= True)
print(new_df)
print("===============删除后==================")
print(copy_df)
DataFrame数据去重
在pandas中,DataFrame.drop_duplicates(subset=, keep=, inplace=)方法用于删除数据框中的重复行。
-
subset:-
可以是一个列标签或列标签列表,表示根据这些列来判断重复行。
-
如果指定了
subset,则只考虑这些列中的值来确定重复行。例如,如果subset=['col1', 'col2'],那么只有当col1和col2列的值完全相同时,才会被认为是重复行。 -
如果不指定
subset,则会考虑所有列来判断重复行。
-
-
keep:-
决定保留哪些重复行。可以取以下三个值之一:
-
'first'(默认值):保留第一次出现的重复行。 -
'last':保留最后一次出现的重复行。 -
False:删除所有重复行。
-
-
-
inplace:-
这是一个布尔值参数。如果为
True,则直接在原始DataFrame上进行修改,不会返回新的DataFrame。如果为False(默认值),则会返回一个新的DataFrame,原始的DataFrame保持不变。
-
1) 对 '户型', '朝向' 去重, 保留第一条, 不影响原始数据
# 1 对 '户型', '朝向' 去重, 保留第一条, 不影响原始数据
# 1.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates(subset=['户型', '朝向' ],keep='first',inplace=False)
print(new_df)
print("=================去重后===========================")
print(copy_df)
2) 对 '户型', '朝向' 去重, 保留最后一条, 不影响原始数据
# 2 对 '户型', '朝向' 去重, 保留最后一条, 不影响原始数据
# 1.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates(subset=['户型', '朝向' ],keep='last',inplace=False)
print(new_df)
print("=================去重后===========================")
print(copy_df)
3) 对 '户型', '朝向' 去重, 删除所有重复数据, 不影响原始数据
# 3 对 '户型', '朝向' 去重, 删除所有重复数据, 不影响原始数据
# 3.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates(subset=['户型', '朝向' ],keep=False,inplace=False)
print(new_df)
print("=================去重后===========================")
print(copy_df)
4) 对 '户型', '朝向' 去重, 保留第一条, 影响原始数据
# 4 对 '户型', '朝向' 去重, 保留第一条, 影响原始数据
# 4.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates(subset=['户型', '朝向' ],keep='first',inplace=True)
print(new_df)
print("=================去重后===========================")
print(copy_df)
5) 对 '户型', '朝向' 去重, 保留最后一条, 影响原始数据
# 5 对 '户型', '朝向' 去重, 保留最后一条, 影响原始数据
# 5.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates(subset=['户型', '朝向' ],keep='last',inplace=True)
print(new_df)
print("=================去重后===========================")
print(copy_df)
6) 对 '户型', '朝向' 去重, 删除所有重复数据, 影响原始数据
# 6 对 '户型', '朝向' 去重, 删除所有重复数据, 影响原始数据
# 6.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates(subset=['户型', '朝向' ],keep=False,inplace=True)
print(new_df)
print("=================去重后===========================")
print(copy_df)
7) 简化版1 对 '户型', '朝向' 去重
# 7 简化版1 对 '户型', '朝向' 去重
# 7.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates(subset=['户型', '朝向' ])
print(new_df)
print("=================去重后===========================")
print(copy_df)
8) 简化版2 对 所有列 去重
# 8 简化版2 对 所有列 去重
# 8.1 准备测试数据
copy_df = df.head().copy()
print("===============去重========================")
new_df = copy_df.drop_duplicates()
print(new_df)
print("=================去重后===========================")
print(copy_df)
相关文章:
DataFrame增删改数据
目录 准备数据 DataFrame添加列 直接添加列数据 使用insert添加列数据 DataFrame删除行列 准备数据 删除行 删除列 DataFrame数据去重 准备数据 import pandas as pd df pd.read_csv("../data/b_LJdata.csv") df DataFrame添加列 直接添加列数据 1&…...
一站式解决App下载量统计,Xinstall引领新潮流
在移动应用市场中,App下载量是衡量应用受欢迎程度和市场表现的重要指标。然而,对于许多开发者而言,如何精准统计App下载量却是一个不小的挑战。幸运的是,如今有了一款专业的App全渠道统计服务商——Xinstall,它能够帮助…...
)
ijkMediaPlayer+ TextureView 等比全屏播放视频(避免拉伸)
TextureView默认以fitxy的方式加载surface数据,如果需要等比全屏播放视频,避免拉伸,可以采用Matrix对TextureView进行变换 废话不多说,直接上代码 public class BaseIjkPlayer implements TextureView.SurfaceTextureListener{/…...
:数据处理)
【RS】GEE(Python):数据处理
在前面的章节中,我们已经学习了如何加载影像数据。现在,让我们进一步探讨如何在 Google Earth Engine (GEE) 中进行数据处理。数据处理通常包括图像预处理、裁剪、过滤、重采样等操作。 栅格影像的处理 栅格影像处理包括了裁剪、波段选择、重采样、合成…...

非线性磁链观测器推导
<div id"content_views" class"htmledit_views"><p id"main-toc"><strong>目录</strong></p> 电机方程 电压方程 磁链方程 定义状态变量和输出变量 非线性观测器方程 电角度的计算--锁相环 锁相环调参 电机…...

什么时机用mysql,什么时机用redis,什么时机用本地内存
mysql 的 buffer pool 也是存在内存中,redis 的数据也是存在内存中,为什么不直接存在 mysql 里? 1、数据结构和访问方式 Redis 是一个内存数据库,专门为高效的读写性能而设计。它支持多种数据结构(如字符串、列表、哈…...

Redis八股
缓存 缓存穿透 当查询一个不存在的数据,mysql查询不到数据,无法写入缓存,导致每次都请求数据库 解决方法 缓存空数据,当查询结果未空,将结果进行缓存。 简单但是会消耗内存,而且会出现不一致情况。布隆…...

vue3--通用 popover 气泡卡片组件实现
背景 在日常开发中,我们一般都是利用一些诸如:element-ui、element-plus、ant-design等组件库去做我们的页面或者系统 这些对于一些后台管理系统来说是最好的选择,因为后台管理系统其实都是大同小异的,包括功能、布局结构等 但是对于前台项目,比如官网、门户网站这些 …...

Bluetooth Channel Sounding中关于CS Step及Phase Based Ranging相应Mode介绍
目录 BLE CS中Step定义 BLE CS中交互的数据包/波形格式 BLE CS中Step的不同Mode BLE CS中Step的执行过程 Mode0介绍 Mode0 步骤的作用 Mode0步骤的执行过程 Mode0步骤的执行时间 Mode0步骤的时间精度要求 Mode2介绍 Mode2步骤的作用和执行过程 Mode2步骤的执行时间 B…...

简易STL实现 | Queue 的实现
封装: std::queue 在底层容器的基础上 提供了封装。默认情况下,std::queue 使用 std::deque 作为其底层容器,但也可以配置为使用 std::list 或 其他符合要求的容器 时间复杂度: 入队和出队操作 通常是 常数时间复杂度(…...

【hot100-java】LRU 缓存
链表篇 灵神题解 class LRUCache {private static class Node{int key,value;Node prev,next;Node (int k,int v){keyk;valuev;}}private final int capacity;//哨兵节点private final Node dummynew Node(0,0);private final Map<Integer,Node> keyToNode new HashMap&l…...

Centos7安装ZLMediaKit
一 获取代码 git clone https://gitee.com/xia-chu/ZLMediaKit cd ZLMediaKit git submodule update --init git submodule update --init 命令用于初始化和更新 Git 仓库中的子模块(submodules)。这个命令在 Git 仓库中包含对其他 Git 仓库作为依赖时…...

面试问我LLM中的RAG,咱就是说秒过!!!
前言 本篇文章涉及了 RAG 流程中的数据拆分、向量化、查询重写、查询路由等等,在做 RAG 的小伙伴一定知道这些技巧的重要性。推荐仔细阅读,建议收藏,多读几遍,好好实践。 本文是对检索增强生成(Retrieval Augmented …...

python程序操作pdf
python代码进行多个图片合并为pdf: #python代码进行多个图片合并为pdf: from PIL import Image from fpdf import FPDF import osdef images_to_pdf(image_paths, output_pdf, quality85):"""将多个图片合并为一个PDF文件,并…...

【Python报错】ImportError: DLL load failed while importing _network: 找不到指定的模块。
【Python报错】ImportError: DLL load failed while importing _network: 找不到指定的模块。 问题描述报错原因解决方案参考 问题描述 此段Python代码(在Conda环境下运行)昨天还能运行,但在我手痒更新conda(我有罪)之…...

外包干了5天,技术明显退步
我是一名本科生,自2019年起,我便在南京某软件公司担任功能测试的工作。这份工作虽然稳定,但日复一日的重复性工作让我逐渐陷入了舒适区,失去了前进的动力。两年的时光匆匆流逝,我却在原地踏步,技术没有丝毫…...
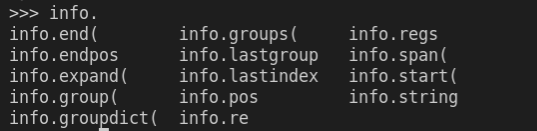
正则表达式 | Python、Julia 和 Shell 语法详解
正则表达式在网页爬虫、脚本编写等众多任务中都有重要的应用。为了系统梳理其语法,以及 Python、Julia 和 Shell 中与正则表达式相关的工具,本篇将进行详细介绍。 相关学习资源:编程胶囊。 基础语法 通用语法 在大多数支持正则表达式的语…...
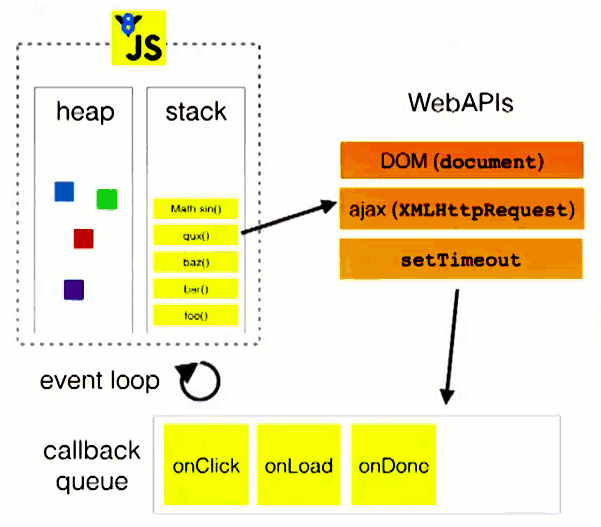
JavaScript全面指南(一)
🌈个人主页:前端青山 🔥系列专栏:JavaScript篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来JavaScript篇专栏内容:JavaScript全面指南(一) 1、介绍一下JS的内置类型有哪些? 基本数据类型…...

docker-compose与docker
“docker-compose” 是一个用于定义和运行多容器 Docker 应用程序的工具。它使用一个名为 docker-compose.yml 的配置文件来描述应用程序的服务、网络和卷,然后通过简单的命令就可以管理整个应用。 以下是一些常用的 docker-compose 命令及其用法: 启动…...

DDPM浅析
在机器学习和人工智能领域,生成模型一直是一个备受关注的研究方向。近年来,一种新型的生成模型——扩散概率模型(Diffusion Probabilistic Models,简称DDPM)引起了广泛的关注。本文将探讨DDPM的原理、优势以及应用。 …...

DAMOYOLO-S快速上手:移动端浏览器访问Web服务与触屏操作适配说明
DAMOYOLO-S快速上手:移动端浏览器访问Web服务与触屏操作适配说明 1. 开篇:一个能“看懂”世界的AI助手 想象一下,你正用手机拍一张街景照片,屏幕上立刻就能标出“汽车”、“行人”、“交通灯”,甚至“手提包”。这不…...

【Coze】从零开始:AI Agent开发平台的入门指南
1. Coze平台初体验:零基础也能玩转AI开发 第一次接触Coze时,我完全被它的易用性震惊了。作为一个没有任何编程背景的市场专员,我居然在半小时内就做出了能自动回复客户咨询的AI助手。这个由字节跳动开发的AI Agent开发平台,真正实…...
AgentCPM-Report研报系统实操:Pixel Epic贤者响应延迟优化教程
AgentCPM-Report研报系统实操:Pixel Epic贤者响应延迟优化教程 1. 认识Pixel Epic智识终端 Pixel Epic是一款基于AgentCPM-Report大模型构建的创新研究报告辅助系统。与传统AI工具不同,它将枯燥的科研过程转化为一场像素风格的RPG冒险。在这个系统中&a…...

小白也能学会:MogFace透明蒙版可视化,人脸检测不再难
小白也能学会:MogFace透明蒙版可视化,人脸检测不再难 1. 为什么需要透明蒙版可视化? 想象一下这样的场景:你拍了一张全家福,想用AI工具检测照片中有多少人。传统的检测工具会在每个人脸上画一个绿色的方框࿰…...

30 分钟搞定答辩 PPT!Paperxie AI 生成器:拯救论文人的「熬夜克星」
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AIPPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 一、答辩 PPT 惨案现场:你是不是也在为这四件事崩溃? 论文查重通过的那一刻,你以为终于能…...

res-downloader:智能资源捕获工具的技术实现与高效工作流指南
res-downloader:智能资源捕获工具的技术实现与高效工作流指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 资源…...

【仅限JDK 25 Early Access用户】:隐藏API `LinkerOptions` 强制启用向量化调用的2行代码,实测吞吐提升2.8倍
第一章:Java 25 外部函数接口优化案例Java 25 正式将外部函数与内存 API(Foreign Function & Memory API)从预览特性转为正式特性,显著提升了 JVM 与本地代码交互的安全性、性能与开发体验。相比早期 JNI 方案,FFM…...

一键搭建AI对话系统:通义千问1.5-1.8B-Chat-GPTQ-Int4镜像使用指南
一键搭建AI对话系统:通义千问1.5-1.8B-Chat-GPTQ-Int4镜像使用指南 想快速拥有一个属于自己的AI对话助手吗?今天要介绍的这个方法,可能比你想象中简单得多。不用折腾复杂的模型下载,不用配置繁琐的运行环境,更不用写一…...
)
保姆级教程:在OBBDetection项目中为DOTA数据集定制检测结果可视化(mmdetection 2.2)
深度定制OBBDetection检测结果可视化:DOTA数据集高级实践指南 在旋转目标检测领域,DOTA数据集因其复杂的航拍场景和多角度目标特性,对结果可视化提出了独特挑战。本文将带您从零构建一套完整的可视化解决方案,涵盖从基础配置到高级…...

抖音音乐高效解决方案:douyin-downloader批量下载与智能管理指南
抖音音乐高效解决方案:douyin-downloader批量下载与智能管理指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fall…...