InstructGPT的四阶段:预训练、有监督微调、奖励建模、强化学习涉及到的公式解读
1. 预训练

1. 语言建模目标函数(公式1):
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_1(\mathcal{U}) = \sum_{i} \log P(u_i \mid u_{i-k}, \dots, u_{i-1}; \Theta) L1(U)=i∑logP(ui∣ui−k,…,ui−1;Θ)
- 解释:
- U = { u 1 , u 2 , … , u n } \mathcal{U} = \{u_1, u_2, \dots, u_n\} U={u1,u2,…,un}是输入的未标注语料(token序列)。
- k k k是上下文窗口的大小,即预测当前词 u i u_i ui时,使用前 k k k个词( u i − k , … , u i − 1 u_{i-k}, \dots, u_{i-1} ui−k,…,ui−1)作为上下文。
- P ( u i ∣ u i − k , … , u i − 1 ; Θ ) P(u_i \mid u_{i-k}, \dots, u_{i-1}; \Theta) P(ui∣ui−k,…,ui−1;Θ) 是模型根据前 k k k个词预测 u i u_i ui的条件概率,其中参数 Θ \Theta Θ是通过训练得到的神经网络参数。
- 通过最大化对数似然,模型被训练以最小化预测和真实词之间的差距,这个过程通常通过随机梯度下降(SGD)进行。
2. Transformer解码器结构(公式2):
公式2描述了模型的架构,采用了多层的Transformer解码器。Transformer通过自注意力机制来捕捉上下文依赖关系,并对输入序列进行编码。
初始嵌入层:
h 0 = U W e + W p h_0 = U W_e + W_p h0=UWe+Wp
- 解释:
- U = ( u − k , … , u − 1 ) U = (u_{-k}, \dots, u_{-1}) U=(u−k,…,u−1) 是上下文窗口中输入序列的词向量。
- W e W_e We是词嵌入矩阵,用于将输入的token转换为词向量。
- W p W_p Wp是位置嵌入矩阵,提供每个token的位置编码,用于捕捉词序信息。
Transformer块:
h l = transformer_block ( h l − 1 ) ∀ i ∈ [ 1 , n ] h_l = \text{transformer\_block}(h_{l-1}) \quad \forall i \in [1, n] hl=transformer_block(hl−1)∀i∈[1,n]
- 解释:
- h l h_l hl表示第 l l l层的Transformer输出。
- 每一层 h l h_l hl是通过前一层 h l − 1 h_{l-1} hl−1经过Transformer块(自注意力和前馈网络)的处理得到的。
- 共有 n n n层,每一层都通过类似的操作进行。
输出层:
P ( u ) = softmax ( h n W e T ) P(u) = \text{softmax}(h_n W_e^T) P(u)=softmax(hnWeT)
- 解释:
- h n h_n hn是最后一层的输出,经过词嵌入矩阵的转置 W e T W_e^T WeT变换后,再通过Softmax函数计算每个词的概率分布。
- 这个概率分布用于预测输出的目标词 u u u,Softmax确保输出的各个词的概率和为1。
总结:
- 该模型采用无监督的方式进行预训练,利用大规模未标注语料数据,通过最大化词序列的条件概率来训练语言模型。
- 预训练的模型架构基于Transformer解码器,通过多层自注意力机制和位置编码来有效捕捉上下文信息,并使用Softmax输出目标词的概率分布。
2. 有监督微调

1. 微调任务的目标函数(公式3):
P ( y ∣ x 1 , … , x m ) = softmax ( h l m W y ) P(y \mid x^1, \dots, x^m) = \text{softmax}(h_l^m W_y) P(y∣x1,…,xm)=softmax(hlmWy)
- 解释:
- x 1 , … , x m x^1, \dots, x^m x1,…,xm 是输入的token序列。
- h l m h_l^m hlm表示输入序列经过预训练模型(如Transformer)的最后一层输出的激活值(即特征表示)。
- W y W_y Wy是用于预测目标标签 y y y的线性层的参数矩阵。
- Softmax 函数将线性层的输出转换为每个类的概率分布,用于分类任务中的标签预测。
2. 最大化目标函数(公式4):
L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , … , x m ) L_2(C) = \sum_{(x, y)} \log P(y \mid x^1, \dots, x^m) L2(C)=(x,y)∑logP(y∣x1,…,xm)
- 解释:
- 这是监督学习的目标函数,模型通过最大化预测标签 y y y 的对数概率来微调模型参数。
- C C C是标注数据集,包含输入序列 x x x和相应的标签 y y y。
- 目标是最大化所有样本的对数似然,确保模型在监督任务中的准确性。
3. 辅助目标函数(公式5):
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_3(C) = L_2(C) + \lambda \ast L_1(C) L3(C)=L2(C)+λ∗L1(C)
- 解释:
- 为了提高监督学习的效果,模型还结合了语言建模的辅助目标,即无监督的语言建模损失( L 1 L_1 L1 )和监督任务的损失( L 2 L_2 L2)相结合。
- λ \lambda λ 是用于平衡两个目标的权重参数。
- 这样做的好处是:可以通过语言模型的任务帮助监督任务更好地泛化,同时加快收敛速度。这种辅助目标在之前的研究中已证明可以有效提高性能。
总结:
- 监督微调阶段,模型利用预训练好的参数,结合带标签的数据来优化预测性能。
- 通过最大化预测标签 y y y的对数概率,模型适应特定任务。
- 引入语言建模作为辅助任务,有助于提升模型的泛化能力和训练效率。
3. 奖励建模

这个段落介绍了 奖励模型(Reward Modeling, RM) 在 InstructGPT 模型中的训练方式,具体描述了模型如何从 监督微调模型(SFT) 继续优化以输出奖励分数(reward score),并通过 比较(comparison)来训练这个奖励模型。
核心内容解释:
-
奖励模型的基础
- 奖励模型的训练是基于监督微调模型(SFT)进一步改进的。为了输出奖励,SFT 模型的最后一层(unembedding layer)被移除,留下的是可以根据给定的提示(prompt)和回应(response)输出一个标量的奖励值。
- 为了节省计算资源,他们使用了一个 6B 参数的奖励模型(RM),因为较大规模的 175B 参数奖励模型虽然理论上可能更准确,但实际训练时表现不稳定,且不适合作为 RL 的值函数。
-
Stiennon et al. (2020) 的方法:
- 数据集:奖励模型通过比较训练,数据集包含两个模型生成的输出(response),并根据这些生成的结果做出比较。
- 损失函数:训练中使用了 交叉熵损失(cross-entropy loss),这些比较的标签是人类标注员根据两者的优劣给出的。交叉熵损失衡量了两个结果中哪一个应该被人类标注员优先选择,实际优化的是两者奖励分数的对数几率(log odds)。
-
加速比较收集过程:
- 在标注过程中,给标注员展示了 K = 4 到 9 个不同的生成回应,标注员需要对这些生成的结果进行排名。这会生成 ( K 2 ) \binom{K}{2} (2K)对比较,即每个标注任务中有 K 个回应时,将产生 K 中选取 2 个的组合数的比较对数。比如 K = 9 K = 9 K=9 时,会生成 ( 9 2 ) = 36 \binom{9}{2} = 36 (29)=36 对比较。
- 为了避免过度拟合,研究者决定不将所有比较对一起训练(因为不同的比较对之间存在强相关性),而是仅从每个提示中抽取一对比较结果作为一个训练样本。这种方式更加 计算高效,因为对于每个完成的任务只需要一次前向传播(forward pass),而不是处理所有 ( K 2 ) \binom{K}{2} (2K) 的比较对。
-
奖励模型的损失函数:
奖励模型的损失函数定义如下:
loss ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] \text{loss}(\theta) = -\frac{1}{\binom{K}{2}} \mathbb{E}_{(x, y_w, y_l) \sim D} \left[ \log \left( \sigma \left( r_\theta(x, y_w) - r_\theta(x, y_l) \right) \right) \right] loss(θ)=−(2K)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 sigmoid 函数,用于将差值映射到 [0, 1] 区间,用来表示某一结果被标注员认为更优的概率。
- r θ ( x , y ) r_\theta(x, y) rθ(x,y) 是奖励模型对于给定提示 x x x和生成的回应 y y y所输出的奖励分数。
- y w y_w yw和 y l y_l yl分别是优胜和劣胜的生成结果。
- D D D是人类标注员比较的结果数据集。
- 1 ( K 2 ) \frac{1}{\binom{K}{2}} (2K)1 是对所有比较的标准化处理。
解释:
- 损失函数的目标是最大化优胜结果 y w y_w yw 比劣胜结果 y l y_l yl更受偏好的概率(通过两者奖励分数差异的 sigmoid 值来实现)。这个函数通过最小化损失来优化奖励模型,使得奖励模型能够更准确地给出与人类标注员偏好一致的分数。
- 防止过拟合的解释(脚注 5):
- 如果每一个比较对都被视为一个单独的数据点,那么每个生成的回应可能在训练中会得到 K − 1 K-1 K−1 次更新,从而导致模型过拟合。而研究人员发现,模型过度训练甚至只需一个 epoch 就会过拟合。为了解决这个问题,他们只对每个提示下的一对回应进行一次前向传播训练,从而避免过拟合。
总结:
- 奖励模型的训练基于人类反馈,通过比较两个模型生成的回应来进行优化。该训练过程使用了 交叉熵损失函数,优化目标是让奖励模型尽可能地预测出哪个回应更符合人类标注员的偏好。
- 通过只选取部分比较对进行训练(而不是所有组合对),减少了计算开销,并有效避免了模型过拟合。
4. 强化学习(PPO)

1. 强化学习(Reinforcement Learning, RL)
在这部分,模型使用了强化学习(RL)进行微调,采用了 PPO(Proximal Policy Optimization) 算法来优化策略。PPO 是一种策略梯度算法,常用于强化学习任务中,通过限制策略更新的步长来提高训练的稳定性。
2. 环境设置
强化学习的环境被设置为一个 多臂老虎机问题(bandit environment),该环境会随机给定提示(prompt),模型需要生成相应的回应。生成的回应会通过奖励模型(reward model)来打分并结束当前回合。
为了防止模型过度优化奖励模型,训练过程中在每个 token 的输出时,加入了 KL 惩罚项,这项惩罚的来源是监督微调模型(SFT, Supervised Fine-Tuned Model)。
3. PPO-ptx 模型
为了提高模型的泛化能力,研究者还尝试将 预训练梯度(pretraining gradients) 与 PPO 的梯度混合,构建了所谓的 PPO-ptx 模型。这种方法可以解决在某些公共 NLP 数据集上性能回退的问题。
他们使用了以下的 目标函数(Objective Function):
objective ( ϕ ) = E ( x , y ) ∼ D π ϕ R L [ r θ ( x , y ) − β log ( π ϕ R L ( y ∣ x ) π S F T ( y ∣ x ) ) ] + γ E x ∼ D pretrain [ log ( π ϕ R L ( x ) ) ] \text{objective}(\phi) = \mathbb{E}_{(x,y) \sim D_{\pi^{RL}_{\phi}}} \left[ r_\theta(x, y) - \beta \log \left( \frac{\pi^{RL}_{\phi}(y \mid x)}{\pi^{SFT}(y \mid x)} \right) \right] + \gamma \mathbb{E}_{x \sim D_{\text{pretrain}}} \left[ \log(\pi^{RL}_{\phi}(x)) \right] objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πSFT(y∣x)πϕRL(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))]
4. 公式解读
第一部分:PPO 的核心目标
E ( x , y ) ∼ D π ϕ R L [ r θ ( x , y ) − β log ( π ϕ R L ( y ∣ x ) π S F T ( y ∣ x ) ) ] \mathbb{E}_{(x,y) \sim D_{\pi^{RL}_{\phi}}} \left[ r_\theta(x, y) - \beta \log \left( \frac{\pi^{RL}_{\phi}(y \mid x)}{\pi^{SFT}(y \mid x)} \right) \right] E(x,y)∼DπϕRL[rθ(x,y)−βlog(πSFT(y∣x)πϕRL(y∣x))]
- E ( x , y ) ∼ D π ϕ R L \mathbb{E}_{(x,y) \sim D_{\pi^{RL}_{\phi}}} E(x,y)∼DπϕRL表示在 RL 策略 π ϕ R L \pi^{RL}_{\phi} πϕRL 生成的分布 D π ϕ R L D_{\pi^{RL}_{\phi}} DπϕRL上的期望。
- r θ ( x , y ) r_\theta(x, y) rθ(x,y) 是奖励模型 r θ r_\theta rθ对生成的响应 y y y的奖励。
- β log ( π ϕ R L ( y ∣ x ) π S F T ( y ∣ x ) ) \beta \log \left( \frac{\pi^{RL}_{\phi}(y \mid x)}{\pi^{SFT}(y \mid x)} \right) βlog(πSFT(y∣x)πϕRL(y∣x))是 KL 散度惩罚项,惩罚 RL 策略 π ϕ R L \pi^{RL}_{\phi} πϕRL偏离 SFT 模型 π S F T \pi^{SFT} πSFT的程度,其中 β \beta β控制 KL 惩罚的权重。
解释:
这部分的目标是最大化模型的奖励,同时通过 KL 惩罚防止策略 π ϕ R L \pi^{RL}_{\phi} πϕRL与监督微调模型 π S F T \pi^{SFT} πSFT偏离过远。惩罚项确保模型在强化学习时不走偏,保持与原本训练目标的相似性。
第二部分:预训练损失
γ E x ∼ D pretrain [ log ( π ϕ R L ( x ) ) ] \gamma \mathbb{E}_{x \sim D_{\text{pretrain}}} \left[ \log(\pi^{RL}_{\phi}(x)) \right] γEx∼Dpretrain[log(πϕRL(x))]
- E x ∼ D pretrain \mathbb{E}_{x \sim D_{\text{pretrain}}} Ex∼Dpretrain 表示在预训练数据分布 D pretrain D_{\text{pretrain}} Dpretrain上的期望。
- log ( π ϕ R L ( x ) ) \log(\pi^{RL}_{\phi}(x)) log(πϕRL(x)) 是 RL 策略 π ϕ R L \pi^{RL}_{\phi} πϕRL生成的结果的对数概率。
- γ \gamma γ是预训练损失项的权重,控制预训练数据与强化学习的结合程度。
解释:
这一部分引入了预训练的损失,使得模型能够保持在大规模预训练数据上的表现,防止模型在强化学习过程中完全依赖于奖励模型而失去通用能力。通过设置 γ \gamma γ,我们可以平衡预训练损失和强化学习损失的影响。
5. 策略和符号说明
- π ϕ R L \pi^{RL}_{\phi} πϕRL 是在强化学习中学习到的策略,参数为 ϕ \phi ϕ。
- π S F T \pi^{SFT} πSFT 是通过监督学习微调得到的策略,它代表了模型在强化学习之前的性能。
- β \beta β是 KL 惩罚的权重系数,控制 RL 策略和 SFT 策略的偏离程度。
- γ \gamma γ 是预训练损失的权重系数,控制预训练梯度在 PPO 优化中的作用。
总结:
在这篇文章中,InstructGPT 使用了强化学习中的 PPO(Proximal Policy Optimization) 进行策略优化,同时通过引入 KL 散度惩罚项 来确保 RL 策略与 SFT 策略不过度偏离。此外,预训练损失 通过一个额外的项加入到了目标函数中,以解决在某些 NLP 任务上的性能回退问题。
相关文章:
InstructGPT的四阶段:预训练、有监督微调、奖励建模、强化学习涉及到的公式解读
1. 预训练 1. 语言建模目标函数(公式1): L 1 ( U ) ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_1(\mathcal{U}) \sum_{i} \log P(u_i \mid u_{i-k}, \dots, u_{i-1}; \Theta) L1(U)i∑logP(ui∣ui−k,…,ui−1;Θ…...

没有HTTPS 证书时,像这样实现多路复用
在没有 HTTPS 证书的情况下,HTTP/2 通常不能直接通过 HTTP 协议使用。虽然 HTTP/2 协议的规范是可以支持纯 HTTP 连接(即通过 http:// 协议),但大多数主流浏览器(如 Chrome、Firefox)都 强制要求 HTTP/2 必须在 HTTPS 上运行。这是出于安全和隐私的考虑。 因此,如果你没…...

2.1.ReactOS系统NtReadFile函数的实现。
ReactOS系统NtReadFile函数的实现。 ReactOS系统NtReadFile函数的实现。 文章目录 ReactOS系统NtReadFile函数的实现。NtReadFile函数的定义NtReadFile函数的实现 NtReadFile()是windows的一个系统调用,内核中有一个叫NtReadFile的函数 NtReadFile函数的定义 NTS…...

2020-11-06《04丨人工智能时代,新的职业机会在哪里?》
《香帅中国财富报告25讲》 04丨人工智能时代,新的职业机会在哪里? 1、新机会的三个诞生方向 前两讲我们都在说,人工智能的出现会极大地冲击现有的职业,从2020年开始,未来一二十年,可能有一半以上的职业都会…...
TensorRT-LLM七日谈 Day5
模型加载 在day2, 我们尝试了对于llama8B进行转换和推理,可惜最后因为OOM而失败,在day4,我们详细的过了一遍tinyllama的推理,值得注意的是,这两个模型的推理走的是不同的流程。llama8b需要显式的进行模型的转换,引擎的…...

使用Java Socket实现简单版本的Rpc服务
通过如下demo,希望大家可以快速理解RPC的简单案例。如果对socket不熟悉的话可以先看下我的上篇文章 Java Scoket实现简单的时间服务器-CSDN博客 对socket现有基础了解。 RPC简介 RPC(Remote Procedure Call,远程过程调用)是一种…...

P2P 网络 简单研究 1
起因, 目的: P2P 网络, 一道题。题目描述, 在下面。 P2P 网络,我以前只是听说过,并不深入。如果我有5台电脑的话,我也想深入研究一下。 P2P 简介: P2P(Peer-to-Peer)网络是一种分…...

RAG(检索增强生成)面经(1)
1、RAG有哪几个步骤? 1.1、文本分块 第一个步骤是文本分块(chunking),这是一个重要的步骤,尤其在构建与处理文档的大型文本的时候。分块作为一种预处理技术,将长文档拆分成较小的文本块,这些文…...

卫爱守护|守护青春,送出温暖
2024年10月10日,艾多美爱心志愿者来到校园。艾多美“卫艾守护”项目于吉林省白山市政务大厅会议室举办了捐赠仪式,东北区外事部经理黄山出席了捐赠仪式仪式,为全校女同学捐赠了青春关爱包。 此次捐赠,面向吉林省自山市第十八中学、…...

ubuntu-24.04.1 系统安装
使用VMware虚拟机上进行实现 官网下载地址: https://cn.ubuntu.com/download https://releases.ubuntu.com 操作系统手册: https://ubuntu.com/server/docs/ (里面包含安装文档) 安装指南(详细):…...

华为OD机试真题---生成哈夫曼树
华为OD机试中关于生成哈夫曼树的题目通常要求根据给定的叶子节点权值数组,构建一棵哈夫曼树,并按照某种遍历方式(如中序遍历)输出树中节点的权值序列。以下是对这道题目的详细解析和解答思路: 一、题目要求 给定一个…...

小红书新ID保持项目StoryMaker,面部特征、服装、发型和身体特征都能保持一致!(已开源)
继之前和大家介绍的小红书在ID保持以及风格转换方面相关的优秀工作,感兴趣的小伙伴可以点击以下链接阅读~ 近期,小红书又新开源了一款文生图身份保持项目:StoryMaker,是一种个性化解决方案,它不仅保留了面部的一致性&…...

Docker 环境下 GPU 监控实战:使用 Prometheus 实现 DCGM Exporter 部署与 GPU 性能监控
Docker 环境下 GPU 监控实战:使用 Prometheus 实现 DCGM Exporter 部署与 GPU 性能监控 文章目录 Docker 环境下 GPU 监控实战:使用 Prometheus 实现 DCGM Exporter 部署与 GPU 性能监控一 查看当前 GPU 信息二 dcgm-exporter 部署1)Docker r…...

联想小新打印机M7328w如何解决卡纸,卡了一个小角在里面,然后再次打印的时候,直接卡住,不能动了。灯显示红色。
1、今天打印一张纸,应该是不小心放歪了,打出来的也是有些斜,然后打出来缺少了个角。 图中的小纸就是从打印机的左边的角,用镊子取出来的,手不太好拿,所以拿个工具比较合适。 2、那么碰到这种卡纸应该如何处…...
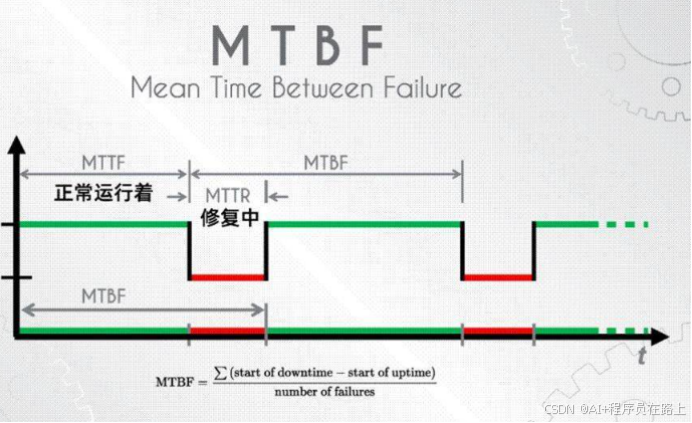
软件可靠性之MTTR、MTBF、MTTF、MTTD区别
一.概念解释 1.MTBF(Mean Time Between Failures):指两次故障之间的平均时间,通常用于衡量设备或系统的可靠性。 2.MTTF(Mean Time to Failure):指设备或系统的平均无故障运行时间。 3.MTTR&am…...

Qt-QDockWidget浮动窗口相关操作(49)
目录 描述 使用 描述 在 Qt 中,浮动窗⼝也称之为铆接部件。浮动窗⼝是通过 QDockWidget类 来实现浮动的功能。浮动窗口⼀般是位于核心部件的周围,可以有多个。 使用 创建我们可以参考下面的语法格式 使用起来也很简单,不过只能创建一个 Q…...

图形用户界面-GUI的基本概念和组件之一
前言 GUI(Graphical User Interface,图形用户界面,简称图形界面)编程实际是引用java.awt或javax.swing类包中的窗口类、控制组件类、布局类、事件类等,通过将控制组件类,如菜单、按钮、文本框等,…...

【MATLAB代码】基于RSSI原理的蓝牙定位程序(N个锚点、三维空间),源代码可直接复制
文章目录 介绍主要功能技术细节适用场景程序结构运行截图源代码详细教程:基于RSSI的蓝牙定位程序1. 准备工作2. 代码结构2.1 清理工作环境2.2 定义参数2.3 生成锚点坐标2.4 定义信号强度与距离的关系2.5 模拟未知点的位置2.6 定位函数2.7 绘图2.8 输出结果2.9 定义定位函数3. …...

Pyenv 介绍和安装指南 - Ubuntu 24
原文: https://www.qiulin-dev.top/articles/81aab753-0d0e-470c-b08f-2643c876841b 1. Pyenv 介绍 Pyenv 是一个非常流行的 Python 版本管理工具,它可以让你在同一台机器上安装并管理多个不同的 Python 版本,解决了不同项目需要不同 Python…...

zookeeper实现RMI服务,高可用,HA
这可不是目录 1.RMI原理与说明1.1含义1.2流程1.3rmi的简单实现1.4RMI的局限性 2.zookeeper实现RMI服务(高可用、HA)2.1实现原理2.2高可用分析2.3zookeeper实现2.3.1代码分析2.3.2公共部分2.3.3服务端2.3.4客户端2.3.5运行与部署2.3.6效果展示与说明 1.RM…...
)
H5扫码功能实战:如何在微信和原生浏览器中实现二维码解析(附完整代码)
H5扫码功能实战:如何在微信和原生浏览器中实现二维码解析 移动互联网时代,二维码已成为连接线上线下最重要的入口之一。作为前端开发者,我们经常需要在H5页面中实现扫码功能,但不同环境下的兼容性问题往往让人头疼。本文将深入探讨…...

Fish-Speech 1.5应用案例:从播客配音到语音提醒,实战分享
Fish-Speech 1.5应用案例:从播客配音到语音提醒,实战分享 1. 项目概述与核心优势 Fish-Speech 1.5作为新一代文本转语音(TTS)系统,凭借其创新的DualAR架构在语音合成领域脱颖而出。这个开源项目通过双自回归Transformer设计,主T…...

Alt App Installer革新:突破微软商店限制的Windows应用安装解决方案
Alt App Installer革新:突破微软商店限制的Windows应用安装解决方案 【免费下载链接】alt-app-installer A Program To Download And Install Microsoft Store Apps Without Store 项目地址: https://gitcode.com/gh_mirrors/alt/alt-app-installer 微软商店…...
)
手把手教你恢复误删的xfce4面板(附备份还原完整流程)
深度解析XFCE4面板管理:从误删恢复到高效备份的全方位指南 XFCE4作为Linux桌面环境中轻量高效的代名词,其面板系统却常常成为用户操作的"高危区域"。我曾亲眼见证一位开发者同事在演示前夕误删所有面板,手忙脚乱地尝试各种恢复方法…...

大麦抢票自动化终极指南:5分钟快速上手教程
大麦抢票自动化终极指南:5分钟快速上手教程 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 您是否曾因热门演唱会门票秒光而遗憾&#x…...

【模型手术室】第九篇:多模态微调 —— 让模型学会“看图说话”:从像素到行业认知的飞跃
专栏进度:09 / 10 (微调实战专题) 如果你使用的是 LLaVA、Qwen2-VL 或 DeepSeek-VL,它们原生具备识别猫狗和常识图片的能力。但如果你给它一张半导体无尘车间的传感器拓扑图,它大概率会胡言乱语。多模态微调的目标,就是建立“视觉…...

10.JVM-垃圾回收器
Serial 与 Serial Old核心特征:单线程、Stop The World (STW)。工作机制:它们在进行垃圾回收时,必须暂停所有其他的工作线程,直到它收集结束。Serial:新生代,采用标记-复制算法。Serial Old:老年…...

Rockchip Android 12编译踩坑记:手把手教你修改BoardConfig.mk生成userdata.img
Rockchip Android 12编译实战:从BoardConfig.mk修改到userdata.img生成的避坑指南 第一次在Rockchip平台上编译Android 12系统时,我遇到了一个令人抓狂的问题——编译过程看似顺利,但生成的固件烧写到设备后,系统始终无法正常启动…...
)
微信小程序蓝牙打印中文乱码?手把手教你GBK编码转换(附完整Demo)
微信小程序蓝牙打印中文乱码终极解决方案:从编码原理到完整实现 蓝牙打印机在零售、餐饮等行业的应用越来越广泛,而微信小程序作为轻量级应用平台,与蓝牙打印机的结合为商家提供了便捷的移动打印方案。但在实际开发中,开发者经常会…...

服装打版辅助新思路:Nano-Banana软萌拆拆屋结构化拆解应用
服装打版辅助新思路:Nano-Banana软萌拆拆屋结构化拆解应用 1. 引言:当服装设计遇见“拆解魔法” 想象一下,你是一位服装设计师,面对一件构思精巧的连衣裙,如何向打版师清晰地传达它的内部结构?是画一堆复…...