论文笔记:Pre-training to Match for Unified Low-shot Relation Extraction

论文来源:ACL 2022
论文地址:https://aclanthology.org/2022.acl-long.397.pdf
论文代码:https://github.com/fc-liu/MCMN
(笔记不易,请勿恶意转载抄袭!!!)
目录
Abstract
Introduction
Multi-Choice Matching Networks
Multi-choice Prompt
Instance Encoder
Multi-choice Matching and Prediction
Training Loss
Training Strategies for Multi-Choice Matching Networks
Triplet-Paraphrase Construction
Triplet-Paraphrase Meta Pre-training
Online Task Adaptation
Experiments
Abstract
Low-shot RE旨在识别样本很少甚至没有样本的新关系。本文提出多选择匹配网络来统一低样本关系抽取。为了填充零样本和小样本关系抽取之间的差距,提出了triplet-paraphrase元训练,利用triplet-paraphrase预训练零样本标签匹配能力,利用元学习范式学习少样本实例概括能力。
Introduction
零样本RE和少样本RE要求模型具备不同的基本能力:零样本RE建立在标签语义匹配能力之上,这要求模型充分利用给定新关系的标签语义,并基于其底层语义匹配关系和查询实例;少样本RE是建立在实例语义概括能力之上,这要求模型通过概括少样本实例的关键信息来快速推广到新的关系。由于零样本RE和少样本RE之间的根本差异,现有的模型都是单独学习来处理两种情况下的RE任务。

本文提出通过回归关系抽取的本质来统一低样本RE。从根本上讲,关系提取可以看做一个多项选择任务,给定上下文中的两个实体,RE系统需要从一组预定义的关系类别中匹配最合适的关系,或者others,即与上述关系均不匹配。其中,完成多项选择匹配所需的信息可以从关系类别名称或从少量实例中概括出来。
基于此,本文提出了多选择匹配网络MCMN来统一低样本RE。如下图所示,MCMN将所有候选关系描述转换为多选择提示,然后将输入实例与多选择实例链接起来,并通过预先训练的编码器来获取输入实例和候选关系的语义表示,最后通过直接匹配关系表示和实例表示进行关系抽取。

为了使MCMN同时具备标签语义匹配能力和实例语义概括能力,引入三triplet-paraphrase元预训练对MCMN进行预训练。其中,包括两个关键部分:
- text-triple-text paraphrase模块:可以生成大规模伪关系抽取数据用来预训练MCMN的标签语义匹配能力;
- 一种元学习风格的训练算法,使MCMN具备实例语义概括能力,可以快速概括不同的关系提取任务。
具体而言,给定大规模原始文本,triplet-paraphrase首先通过OpenIE工具包抽取三元组,然后基于抽取的三元组使用RDF-to-text生成模型生成原始文本的paraphrases。这样,可以通过收集生成的句子和预测的三元组来获得大规模的伪标注数据。这样的语料库可以通过将paraphrases匹配到相应的预测,有效地预训练MCMN的标签语义匹配能力。此外,为了使MCMN具有实例语义概括能力,这种预训练是在元学习范式中进行的。也就是说,每次迭代都要求MCMN学习不同的关系抽取任务,MCMN就不能通过直接记忆特定的目标关系来过度匹配预训练语料库。
主要贡献:
- 提出MCMN,通过使用多选匹配范式从根本上实现关系抽取;
- 提出triplet-paraphrase元训练对MCMN进行预训练,使MCMN既具备了标签语义匹配能力,又具备了实例语义概括能力。
Multi-Choice Matching Networks
Multi-choice Prompt
从根本上说,关系提取器可以视为一个多项选择任务,通过直接链接所有关系名称或描述,为每个关系提取任务构造一个多选择提示,形式如下:
[C] rel1 [C] rel2 ... [C] rel N
其中,[C]为分隔符。例如Figure 2 中,将employee_of、ceo_of和others连接在一起,形成多项选择提示“[C] employee of [C] ceo of [C] others [SEP] [e1] Tim Cook [/e1] is the CEO of [e2] Apple [/e2] . [SEP]”。在获得多选项提示后,将其与输入句子一起输入实例编码器
Instance Encoder
编码前,将多选择提示与每个输入实例链接,用[SEP]标志将其分隔,并分别用[e1]、[/e1]、[e2]和[/e2]将头、尾实体包起来。例如Figure 2的示例,编码器的输入为“[CLS] [C] employee of [C] ceo of [C] others [SEP] [e1] Tim Cook [/e1] is the CEO of [e2] Apple [/e2] . [SEP]”,然后通过transformer encoder对整个句子进行编码:
Multi-choice Matching and Prediction
多选择匹配模块用来将输入实例匹配到对应的关系。对于每一种关系类型,使用[C]标记的隐藏层状态来表示关系:
其中,表示关系
,
表示第
个token[C]的隐藏层状态。
对于输入文本,简单地对[e1]和[e2]的隐藏状态取平均值得到实例表示
然后在实例和每个关系之间执行匹配操作:
在这个公式中,采用欧氏距离来度量相似度,每个关系对应的概率为
最后选择概率最大的关系作为预测
Training Loss
Training Strategies for Multi-Choice Matching Networks
Triplet-Paraphrase Construction
为了使MCMN具有标签语义匹配能力,需要结合关系句和关系类型的大规模数据进行预训练。但是现有的RE数据集中高度有限的关系类型可能导致特定关系的过拟合,不利于MCMN的推广。Triplet-Paraphrase从原始文本中为MCMN生成大规模的预训练数据。Triplet-Paraphrase模块的总体流程如下图(a)所示,它从大规模的原始文本中提取谓词作为关系描述,然后利用提取的关系三元组生成Paraphrase句子进行进一步的多选择匹配预训练。

关系三元组提取: 大多数完整的句子至少包含一个关系三元组,包括主语、谓语和宾语。句子中的谓语对应的是主语和宾语之间的属性或者关系,可以看做是一种关系的具体表述。为了从开放域文本中提取大规模的三元组,使用OpenIE模型对Wikipedia的文章集合进行抽取。从原始文本中收集所有提取的谓词来表示对应的关系,防止模型过渡拟合特定的关系类型。然后将这些三元组用于Paraphrase生成和预训练。
Paraphrase生成:对于提取出来的三元组,首先用“[H], [R], [T]”将其包装起来,分别对应主语、谓语和宾语,然后输入包装好的三元组文本以生成Paraphrase文本。例如三元组 (an online service, known as, PlayNET)被包装为“[H] an online service [R] known as [T] PlayNET”,然后生成Paraphrase文本playnet is an online service。在生成paraphrase之后,将其与对应的谓词进行匹配,以便进行预训练。
Triplet-Paraphrase Meta Pre-training
预训练batch中的每个实例都包含paraphrase文本和相应的谓词span。如figure 3(a)所示,将当前mini-batch中的所有谓词链接为多选择提示,并按照Training Loss中的损失函数对MCMN进行预训练,其中,当是对应的谓词时,
,否则
。
Online Task Adaptation
在在线学习或者测试期间,针对不用的低样本任务采用不同的适应策略。对于Zero-shot RE,直接使用经过训练的MCMN来执行任务,对于Few-shot RE,对支持集执行在线任务元训练,如算法1。

Experiments
本文进行了三种任务上的实验:① Zero-shot RE;② Few-shot RE;③ Few-shot RE with NOTA,即查询集实例的关系类别不存在于支持集中。

消融实验

相关文章:
论文笔记:Pre-training to Match for Unified Low-shot Relation Extraction
论文来源:ACL 2022 论文地址:https://aclanthology.org/2022.acl-long.397.pdf 论文代码:https://github.com/fc-liu/MCMN (笔记不易,请勿恶意转载抄袭!!!) 目录 A…...

一篇文章带你快速了解linux中关于信号的核心内容
1. 信号概念 信号是操作系统用来通知进程某个特定事件已经发生的一种方式。它们是一种软件中断,可以被发送到进程以对其进行异步通知。 2. 信号处理的三种方式 执行默认动作执行自定义动作忽略 signal() 函数:将信号处理设置为 SIG_IGN,可…...

openEuler、Linux操作系统常见操作-(6)如何登录Linux
如何登录Linux Linux登陆方式主要有如下两种: 。本地登陆 。一个典型的Linux系统将运行六个虚拟控制台和一个图形控制台,openEuler目前暂未支持图形化界面; 可以通过CtrlAltF[1-6]在6个虚拟控制台之间进行切换。 远程登录 。默认情况下openEuler支持远程登录&…...

Python基础语法条件
注释 注释的作用 通过用自己熟悉的语言,在程序中对某些代码进行标注说明,这就是注释的作用,能够大大增强程序的可读性。 注释的分类及语法 注释分为两类:单行注释 和 多行注释。 单行注释 只能注释一行内容,语法如下…...
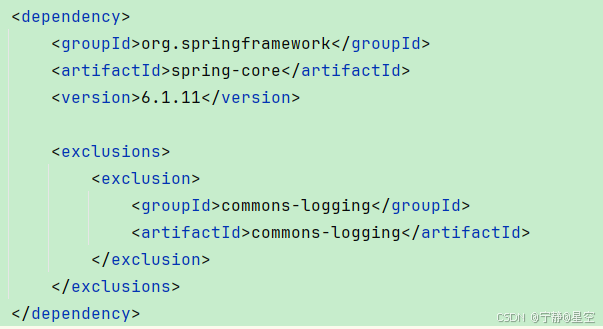
006-MAVEN 的使用
MAVEN 的使用 一、依赖范围二、依赖的传递性三、依赖的原则四、依赖的排除 一、依赖范围 在引入log4j 依赖的时候,有一个scope设置,这个scope设置的值就是对应的依赖范围(因为compile 是默认的依赖范围,所以有时也可以省略)。 Maven 提供了…...

npm使用时报错:Could not retrieve https://npm.taobao.org/mirrors/node/index.json.
在使用npm时报错,报错信息如下: 报错的原因:是原来的淘宝镜像地址过期了 解决办法:修改镜像地址。打开nvm的安装地址 -->settings.txt文件 -->配置下载源 1、将settings.txt文件中的 node_mirror: https://npm.taobao.or…...

软考中级网络工程师——高级配置
文章目录 IS-ISBGP(边境网关协议)-IBGP-EBGP配置BFD(双向转发侦测)与Router-Static联动BFD与OSPF联动BFD与VRRP(虚拟路由器冗余协议)联动VRRP配置(基于网关备份)FW基础配置FW高级配置DHCP路由策略 IS-IS 第一步:每一个路由设置环回口地址 第二部:配置接…...

Leetcode 第 141 场双周赛题解
Leetcode 第 141 场双周赛题解 Leetcode 第 141 场双周赛题解题目1:3314. 构造最小位运算数组 I思路代码复杂度分析 题目2:3315. 构造最小位运算数组 II思路代码复杂度分析 题目3:3316. 从原字符串里进行删除操作的最多次数思路代码复杂度分析…...

Linux性能调优,还可以从这些方面入手
linux是目前最常用的操作系统,下面是一些常见的 Linux 系统调优技巧,在进行系统调优时,需要根据具体的系统负载和应用需求进行调整,并进行充分的测试和监控,以确保系统的稳定性和性能。同时,调优过程中要谨…...

STM32的独立看门狗定时器(IWDG)技术介绍
在嵌入式系统中,确保系统的稳定性和可靠性至关重要。看门狗定时器(Watchdog Timer, WDT) 是一种常用的硬件机制,用于监控系统的运行状态,防止系统因软件故障或意外情况进入不可预期的状态。STM32系列微控制器提供了两种…...
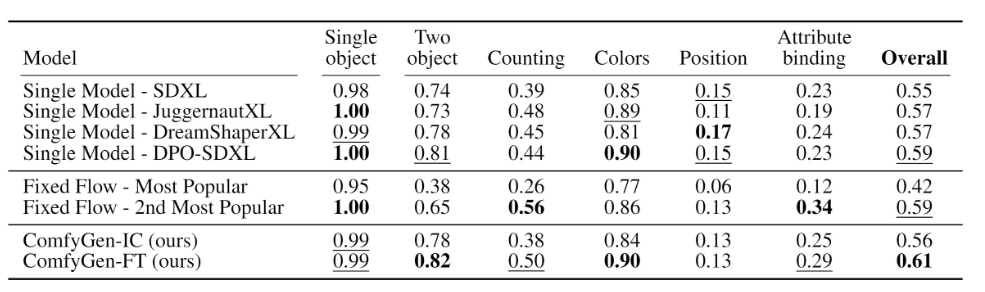
自动化生成工作流?英伟达提出ComfyGen:通过LLM来匹配给定的文本提示与合适的工作流程
ComfyGen的核心在于通过LLM来匹配给定的文本提示与合适的工作流程。该方法从500个来自用户的多样化提示生成图像,随后使用一系列美学预测模型对生成结果进行评分。这些评分与相应的工作流程形成了一个训练集,包含提示、工作流程及其得分的三元组。 然后…...
)
indicatorTree-v10练习(有问题)
目标:设计数据库表表格式,将“indicatorTree-v10.json”导入到数据库,再从数据库读取写为JSON文件。 其他要求:数据库要求为mysql数据库;编程语言暂时限定为C;JSON解析使用本文件夹中的cJSON.c和cJSON.h&am…...

python源码:指定麦克风/音响播放歌曲
前言 我使用pygame实现了指定麦克风/音响播放歌曲的功能,主要目的是解决直播过程的多源声道控制问题。 代码 # 查看自己的音频设备 # 请记住目标音频设备的具体名称 import pygame as mixer import pygame._sdl2 as sdl2mixer.init() # Initialize the mixer, thi…...
基于华为云智慧生活生态链设计的智能鱼缸
一. 引言 1.1 项目背景 随着智能家居技术的发展和人们对高品质生活的追求日益增长,智能鱼缸作为一种结合了科技与自然美的家居装饰品,正逐渐成为智能家居领域的新宠。本项目旨在设计一款基于华为云智慧生活生态链的智能鱼缸,它不仅能够提供…...

OJ-1015图像物体的边界
分析 思路 1.输入读取:读取网格的维度(M,N)和像素值到一个二维数组中。 2.迭代:遍历二维数组中的每个单元格。 3.边界检测:对于每个像素值为1的单元格,检查其八个相邻的单元格。如果任何相邻单元格的像素值为5,则增加边界计数。 4,边界计数调整:由于每…...

RAG 入门实践:从文档拆分到向量数据库与问答构建
本文将使用 Transformers 和 LangChain,选择在 Retrieval -> Chinese 中表现较好的编码模型进行演示,即 chuxin-llm/Chuxin-Embedding。 你还将了解 RecursiveCharacterTextSplitter 的递归工作原理。 一份值得关注的基准测试榜单:MTEB (M…...
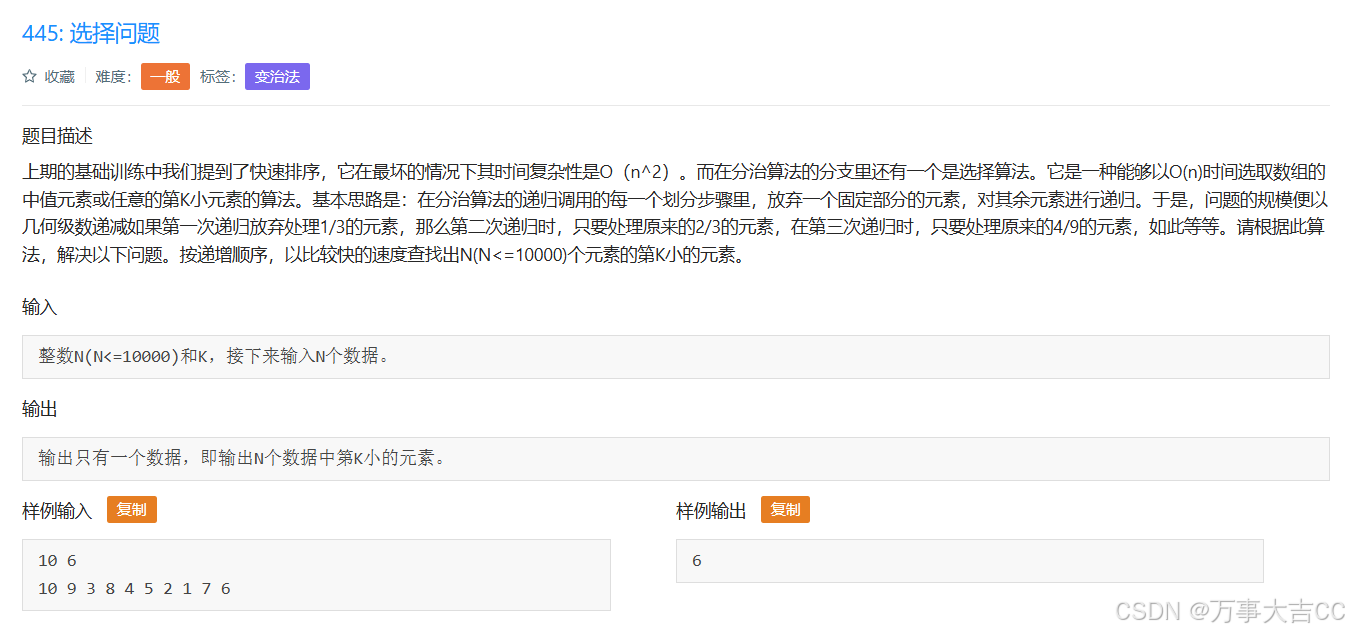
445: 选择问题
解法: 第k大的数据查找 a, b map(int, input().split()) l list(map(int, input().split())) l.sort() print(l[b-1])...

IP地址类型选择指南:动态IP、静态IP还是数据中心IP?
你是否曾经困惑于如何选择最适合业务需求的IP地址类型?面对动态IP、静态IP和数据中心IP这三种选择,你是否了解它们各自对你的跨境在线业务可能产生的深远影响? 在跨境电商领域,选择合适的IP类型对于业务的成功至关重要。动态IP、…...
基于Python flask的豆瓣电影可视化系统,豆瓣电影爬虫系统
博主介绍:✌Java徐师兄、7年大厂程序员经历。全网粉丝13w、csdn博客专家、掘金/华为云等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇🏻 不…...

面试不是一场遭遇战
引言 Ethan第一次跳槽时,把工作总结搞成简历,丢到BOSS,面了几场,结果都很糟。复盘下来,发现面试过程临场发挥太多,把攻坚战打成了遭遇战。 那面试要如何准备?什么情况下跳槽?有哪些大…...

ClawdBot个人AI助手5分钟快速部署:零基础搭建本地智能聊天机器人
ClawdBot个人AI助手5分钟快速部署:零基础搭建本地智能聊天机器人 1. 项目介绍 ClawdBot是一个可以在本地设备上运行的个人AI助手,基于vLLM提供后端模型能力。这个开源项目让用户能够快速搭建自己的智能聊天机器人,无需复杂的配置过程。 1.…...

别再为模糊监控头疼了!手把手教你用SRGAN+ResNet101搞定低清行人重识别
低清监控下的行人重识别实战:SRGAN与ResNet101的工程化融合方案 清晨的地铁站,监控摄像头捕捉到一个模糊的身影——黑色外套、深色背包,像素化的面部特征让传统识别系统束手无策。这正是当下安防领域最棘手的现实挑战:如何从低分辨…...

轻量部署开源网络性能测试工具:从环境搭建到性能调优全指南
轻量部署开源网络性能测试工具:从环境搭建到性能调优全指南 【免费下载链接】speedtest 项目地址: https://gitcode.com/gh_mirrors/spe/speedtest 在网络运维与开发过程中,准确掌握网络带宽性能是保障服务质量的关键。本文将介绍如何使用开源速…...

LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗
LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗 1. 当爬虫遇上大模型:数据采集的新思路 传统爬虫开发就像在迷宫里摸索前行——你需要手动解析每个网站的HTML结构,针对不同反爬机制编写特定规则,还要处理杂乱…...
)
Volcano调度算法全解析:从DRF公平分配到Binpack节点装箱(含权重调优技巧)
Volcano调度算法深度实战:从DRF公平分配到Binpack节点装箱 在Kubernetes生态中,资源调度一直是决定集群效率和稳定性的核心环节。当你的业务从简单的Web服务扩展到AI训练、大数据处理等复杂场景时,原生Kubernetes调度器的局限性就会凸显——它…...

YOLO12与Qt结合:跨平台目标检测应用开发
YOLO12与Qt结合:跨平台目标检测应用开发 1. 引言 想象一下,你开发了一个优秀的目标检测模型,能够在各种场景下准确识别物体。但当你想要把它部署到不同设备上时,却遇到了麻烦:Windows、macOS、Linux各有各的兼容性问…...

SeqGPT-560M代码补全能力展示:Python开发效率提升50%
SeqGPT-560M代码补全能力展示:Python开发效率提升50% 1. 引言 作为一名长期与代码打交道的开发者,我深知代码补全工具的重要性。好的补全工具不仅能减少敲击键盘的次数,更能帮助我们避免低级错误、保持编码思路的连贯性。最近体验了SeqGPT-…...

如何用RecastNavigation构建完整的游戏AI导航系统:从入门到实战
如何用RecastNavigation构建完整的游戏AI导航系统:从入门到实战 【免费下载链接】recastnavigation Navigation-mesh Toolset for Games 项目地址: https://gitcode.com/gh_mirrors/re/recastnavigation 想要为你的游戏打造智能的AI导航系统吗?Re…...

ReactPy虚拟DOM终极指南:Python如何高效更新网页内容
ReactPy虚拟DOM终极指南:Python如何高效更新网页内容 【免费下载链接】reactpy Its React, but in Python 项目地址: https://gitcode.com/gh_mirrors/re/reactpy ReactPy作为Python领域的创新框架,让开发者能够使用Python语法构建交互式Web界面&…...

终极存储设备容量检测指南:如何用F3工具3分钟识别假冒U盘和SD卡
终极存储设备容量检测指南:如何用F3工具3分钟识别假冒U盘和SD卡 【免费下载链接】f3 F3 - Fight Flash Fraud 项目地址: https://gitcode.com/gh_mirrors/f3/f3 在数字存储时代,容量造假已成为困扰用户的普遍问题。F3(Fight Flash Fra…...